Как известно, база данных – это хранилище структурированной информации, пассивное по своей сути. Бизнес-логика приложения реализуется где-то вне базы, в виде «набора действий для достижения требуемого результата». В случае внесения изменений в хранимый набор данных результатом должно стать новое состояние базы. В краткой форме это можно записать как-то так: событие → {действия} → результат. Изменим эту формулировку на: событие → правила → результат, и посмотрим, что из этого получится.
Если предметная область автоматизации представляет собой систему взаимодействующих значений, то ее можно описать ER-моделью, которая образована экземплярами всего четырех абстрактных сущностей: класс данных, атрибут класса, отношение классов и связь атрибутов. Такая модель не только образует логическую структуру базы данных, но обладает всеми свойствами программы, каковой по сути и является – в вычислительной среде, образованной методами упомянутых абстрактных сущностей.
Рассмотрим это смелое утверждение более подробно, начиная с самых общих определений. (Нижеследующий повтор общеизвестного необходим как минимум для обозначения смысла используемых терминов. Будет сухо и нудно — как и в любом другом теоретическом материале. Чтобы его слегка оживить, в текст вкраплены примеры.)
Практически любую объективно существующую предметную область можно рассматривать с информационной точки зрения как систему взаимодействующих значений. Сразу отметим, что отдельное значение никогда не является ни самостоятельным, ни самодостаточным, так как существует на правах некоторой характеристики объекта данных. Поэтому для точного описания предметной области в некотором ее состоянии необходима полная совокупность объектов данных с их значениями. При этом однотипные объекты описываются классом данных, и существуют на правах производных экземпляров этого класса – объектов класса.
Класс данных выражает собой отдельную понятийную сущность рассматриваемой предметной области и характеризуется пользовательским наименованием этой сущности. В свою очередь, любая понятийная сущность обладает некоторым уникальным набором собственных характеристик/свойств. Атрибут класса выражает собой отдельную характеристику сущности, именован пользовательским наименованием этой характеристики, обладает типом, определяющим множество (домен) допустимых ее значений, и выступает в качестве фабрики конкретных значений характеристики в объектах класса.
Соответственно, класс данных владеет набором атрибутов (класса), который он хранит в формате кортежа. Выступая в качестве фабрики объектов, класс формирует содержимое объекта в виде кортежа значений, который является экземпляром, производным от кортежа атрибутов. При этом каждое значение в кортеже значений объекта класса является экземпляром, производным от соответствующего атрибута класса.
Таким образом, вполне конкретная предметная область, существующая в виде множества объектов с их значениями, на уровне абстракции описывается системой классов с их атрибутами. И при этом данные и метаданные представляют собой персистентную структуру данных, хранимую в объектной базе данных.
В основу реализации связи объектов данных положен принцип симметрии. В соответствии с этим принципом связываемые объекты взаимно обмениваются своими идентификаторами. Идентификатор объекта (дескриптор IDO) глобален в пределах физической базы данных, и представляет собой простое целое число.
На уровне абстракции связь объектов описывается отношением классов. Декларация отношения реализуется созданием атрибута в каждом из двух связываемых отношением классов, которые взаимно адресуют друг друга. Каждый из атрибутов отношения типизирован оппозитным классом отношения (каждый класс считается самостоятельным пользовательским типом данных), вследствие чего доменом значений ссылочного атрибута является множество дескрипторов объектов оппозитного класса.
Отношение классов устанавливает меру количественного взаимодействия производных объектов этих классов. При всей простоте этого определения, отношения обладают столь разнообразным функциональным поведением и взаимной логической зависимостью, что эта обширная тема будет рассматриваться отдельно.
Пока же стоит упомянуть, что в отношении один-к-одному оба ссылочных атрибута абсолютно равноправны, а их значением в объектах данных будет единственный дескриптор партнера по связи. В отношении многие-к-одному атрибуты очевидным образом не равноправны: ни по формату хранимого значения, ни по порядку формирования значения. Если на стороне многие- значением атрибута [прямой ссылки] по-прежнему будет единственный дескриптор, то на стороне -один, как следствие строго соблюдения ссылочной симметрии, значением атрибута [обратной ссылки] будет множество дескрипторов, представляющее собой список вида ключ-значение. При этом значение атрибута обратной ссылки производно от значения атрибута прямой ссылки. Механизм реализации этой производности будет подробно рассмотрен ниже по тексту.
Под взаимодействием значений понимается их причинно-следственная функциональная связь. Эта связь существует только на понятийном уровне абстракции, где она принимает вид виртуального соединителя двух атрибутов. По аналогии с отношением классов, декларация связи атрибутов реализуется созданием двух сокетов (параллель с TCP-сокетами вполне уместна), каждый из которых принадлежит своему атрибуту, и размещается в его кортеже сокетов.
Отдельный сокет, описывающий свойства связи со стороны своего атрибута, является такой же персистентной структурой данных уровня абстракции, как класс и атрибут. Как и атрибуты отношения, сокеты, образующие соединитель, взаимно адресуют друг друга. Для этих целей декларация сокета содержит комплексный идентификатор (класс+атрибут+сокет) оппозитного сокета соединителя. Также декларация сокета содержит набор флагов, управляющих передачей и приемом значений через соединитель.
Логически, кортеж представляет собой простое перечисление однородных (с точки зрения кортежа) элементов, содержащих некоторое количество байт данных. Знания о содержимом и способах его формирования лежат за пределами кортежа. Кортеж лишь предоставляет место для размещения и долговременного хранения. Особенности внутренней реализации кортежа были рассмотрены здесь.
Элемент кортежа однозначно идентифицируется своим местом (порядковым номером) в кортеже, которое не изменяется никогда. При добавлении в кортеж, новый элемент занимает свое место раз и навсегда.
Содержимым элемента кортежа может быть как унитарное значение, так и другой кортеж. Это делает кортеж основным (и единственным) структурообразующим компонентом объектного представления. Так например, декларация класса представляет собой кортеж, элементами которого являются свойства класса, одним из которых является кортеж атрибутов класса.
Кортеж обладает способностью создавать собственный экземпляр, который представляет собой пустой кортеж, элементы которого не имеют содержимого. Эту способность использует например класс, как при создании классов-наследников, так и при создании своих производных объектов, в которых взаимная идентификация атрибутов и производных от них значений обеспечивается совпадением номеров элементов в соответствующих кортежах.
Неизменность места, занимаемого элементом в кортеже, лежит в основе системы внутренней идентификации объектных сущностей, которая в самом общем виде выглядит так:
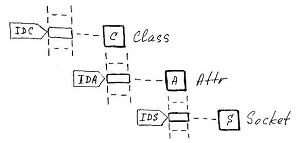
Каждая объектная сущность идентифицируется своим дескриптором – порядковым номером в соответствующем кортеже: IDC – класс, IDA – атрибут, IDS – сокет, IDO – объект (логически DAT объектов также следует рассматривать как кортеж). Логика также подсказывает, что классы являются элементами кортежа, специфичный владелец которого рассматривается в статье, посвященной отношениям классов.
Что примечательно – на уровне абстракции существуют сразу две модели, образованные различными сущностями этого уровня.
Совокупность хранимых деклараций классов, атрибутов и сокетов образует модель данных. Модель данных считается исполнительной, так как образующие ее сущности выполняют в отношении уровня данных функции фабрики объектов (класс) и фабрики значений (атрибут).
Модель приложения является виртуальной, и существует на правах формы представления модели данных. Модель приложения динамически создается визуальным конструктором, который использует ее для отображения существующей модели данных, и создания в ней новых деклараций, путем создания новых сущностей модели приложения. В образовании модели приложения, наряду с вещественными классом и атрибутом, принимают участие такие виртуальные сущности как отношение и соединитель. Виртуальные сущности не образуют хранимых деклараций, а создаются динамически из деклараций атрибутов и сокетов, частично инкапсулируя факт их существования. Виртуальных характер модели приложения ничуть не мешает рассматривать ее в качестве первичной модели предметной области.
В свою очередь, все перечисленные вещественные и виртуальные сущности уровня абстракции являются экземплярами объектных сущностей еще более высокого уровня абстракции – уровня мета-определений. На этом уровне структурно и программно реализованы такие сущности как: мета-кортеж, мета-класс, мета-атрибут, мета-отношение, мета-сокет и мета-соединитель.
Стоит лишний раз подчеркнуть, что все методы конструирования, с помощью которых создаются и изменяются обе модели (данных и приложения), а также все без исключения методы исполнения, используемые моделью данных применительно к объектам и значениям уровня данных, принадлежат сущностям уровня мета-определений. Уровень же моделей, обеспечивающий создание и исполнение всей бизнес-логики приложения, образован исключительно декларативными экземплярами мета-сущностей, и не содержит в себе исполняемого кода.
Методы конструирования, с помощью которых создаются экземпляры мета-сущностей и переопределяются значения тех или иных их свойств, представляются достаточно очевидными, и не требуют комментариев. Чего нельзя сказать об образующих пресловутую вычислительную среду методах исполнения, с помощью которых воздействия извне изменяют состояние данных в соответствии с правилами, декларированными в форме модели данных. Собственно говоря, вызов метода исполнения и является таким внешним воздействием. Всего же таких методов четыре: Create, Set, Get и Update.
Метод Create принадлежит мета-классу, и используется для создания производного объекта класса. Параметром метода является дескриптор IDC целевого класса. Метод Create создает объект как экземпляр кортежа атрибутов указанного класса, и регистрирует его в таблице аллокации DAT за очередным свободным дескриптором IDO.
Методы атрибута: Set, Get и Update, принадлежат мета-атрибуту, и позволяют оперировать значениями объектов данных. Метод Set отвечает за присвоение значения, метод Get — за выборку значения, а метод Update является событием, инициирующим атрибут на пере-формирование производного хранимого значения (смысл этого действия станет понятным несколько позже).
Для методов атрибута целевой объект идентифицируется дескриптором IDO, а собственно целевое значение доступно исключительно через атрибут класса, путь к которому представлен в дескрипторах IDC+IDA модели данных. Иными словами, все действия над значением совершаются от лица атрибута класса. Особенностью процесса исполнения методов атрибута является то, что в его ходе каждый из методов прибегает к перебору сокетов в кортеже атрибута, с вызовом аналогичного метода для целевого атрибута, адресуемого соединителем, при условии что в сокете установлен одноименный методу флаг.
Так как исполнение любого из трех методов: Create, Set или Update, изменит состояние данных, то их вызов возможен только в контексте транзакционной сессии. Вызов любого из этих трех методов является атомарным внешним воздействием на базу данных, которое легко формализуется в формат транзакции, с ее последующим сохранением в журнале.
Рассмотрим логику исполнения методов атрибута чуть более подробно.
Итак, вызван метод Set, которому передали адресные параметры, и указатель на присваиваемое значение (*value). В теле этого метода атрибут сформирует новое значение, выполнит его присвоение соответствующему элементу кортежа объекта, а далее начнет последовательный перебор сокетов из своего кортежа. Для каждого сокета, у которого установлен флаг Set [S], исходный атрибут вызовет метод Set применительно к атрибуту, путь к которому прописан в декларациях сокета. Отметим, что исполнение метода может завершиться досрочно, без обхода кортежа сокетов, если новое значение эквивалентно хранимому.
Делая производные вызовы Set, атрибут следует принципу изоляции – «выстрелил, и забыл», не заботясь о последствиях. Дальнейший ход событий определяется уже другими действующими лицами-атрибутами. При этом, что важно, транзакционный характер исполнения обеспечивает перманентную согласованность всех изменяемых значений, независимо от объема и «протяженности» изменений.
Рассмотрим формирование производного значения на примере из жизни счетов и накладных:

На схеме контурными стрелками обозначен пользовательский ввод значений, он же внешний вызов Set. Любое изменение значений атрибутов Количество или Цена активно передается атрибуту Сумма, который для формирования производного значения использует функционал, в данном случае – мультипликативный.
Функционалы — это предопределенные (для каждого типа значения) методы мета-атрибута, которые позволяют сформировать результирующее значение преобразованием значений-аргументов, полученных через соединители от одного или нескольких атрибутов-источников. Атрибуту назначают функционал путем присвоения его дескриптора (IDF), который представляет собой порядковый номер в общем списке функционалов.
Если атрибуту назначен функционал, то все вызовы Set и Get в адрес атрибута обрабатываются этим функционалом, при необходимости – с дополнительным опросом (Get) источников. Обратим внимание: для исключения первоисточника вызова из опросов, адресная часть вызова (IDC+IDA) перманентно включает в себя также и дескриптор сокета-получателя (+IDS).
Оба соединителя из приведенного выше примера были использованы в простой безусловной форме.
Между тем, функциональное поведение соединителя можно поставить в зависимость от действующих значений сторонних атрибутов, которые для исходного соединителя образуют своего рода "контекст исполнения". Для реализации связи с атрибутами-контекстами, в декларациях сокета предусмотрена возможность адресации трех дополнительных, так называемых "контекстных" сокетов. У каждого контекстного сокета есть свое, строго фиксированное назначение-аспект: блокирующий (lock), ссылочный (ref) и ключ (key), но вместе с тем это точно такие же экземпляры мета-сокета, как и "базовые" сокеты соединителя. Для адресации каждого контекстного сокета базовому достаточно двух дескрипторов: IDA+IDS.

Блокирующий lock-сокет разрешает передачу значения по соединителю, если возвращаемое им значение актуально, и блокирует в противном случае. Под актуальным понимается инициализированное значение атрибута-владельца сокета (lock-контекст), которое дополнительно оценивается еще и с точки зрения его типа: true для логики, не ноль для числа, и присутствует хотя бы один литерал (помимо пробела) для строки.
Ссылочный ref-сокет используется во внешних соединителях, связывающих атрибуты разных классов. Он предоставляет соединителю дескрипторы IDO объектов данных другого класса, используя в качестве источника значений соответствующий атрибут отношения (ref-контекст) в своем классе.
«Ключевой» key-сокет предоставляет соединителю значения ключа, и необходим для реализации работы со списками. В качестве источника значения ключа (key-контекст) по умолчанию используется базовый атрибут класса.
Без учета специфики ссылочного и ключевого аспектов, логика взаимодействия контекстных сокетов с базовым едина для всех трех контекстов. Так базовый сокет на каждой из сторон соединителя немедленно прервет исполнение текущего метода Set | Get, если хотя бы один из его действующих (то есть фактически декларированных и сохраняющих актуальность) контекстов содержит не актуальное значение. Иначе говоря, ref- и key- контексты перманентно обладают также свойствами lock-контекста. В этом нет ничего удивительного, если вспомнить, что значение любого типа можно привести к логическому типу.
Инициация условного соединителя со стороны его контекстов осуществляется путем вызова одного из двух внутренних методов исполнения: Reset и Unset, принадлежащих мета-сокету. Эти методы вызываются атрибутом-контекстом в ходе исполнения метода Set в адрес базового сокета соединителя по следующим правилам. Если текущее значение атрибута актуально, то перед любым его изменением атрибут вызовет метод Unset для всех своих сокетов, у которых установлен флаг Unset [U]. Далее, после присвоения нового значения, в повторном цикле обхода кортежа для вызова производных методов Set, атрибут вызовет метод Reset для тех своих сокетов, у которых установлен флаг Reset [R]. Иными словами, атрибут выполняет имитацию сначала де-инициализации своего действующего значения, со всеми вытекающими из этого последствиями для внешнего окружения атрибута, а затем выполняет инициализацию уже новым значением.
В свою очередь базовый сокет, при исполнении методов Unset | Reset, вызовет метод Set в адрес оппозитного атрибута соединителя с набором параметров (включая текущие значения действующих контекстов), имитирующим де-инициализацию (Unset) значения собственного атрибута-владельца, или его инициализацию (Reset) внешним значением. Такую имитацию несложно реализовать, если в параметрической части метода Set передавать не один указатель на значение, а два: на значение перед изменением, и на новое значение. Тогда в параметрах Set, производного от Unset | Reset, один из указателей всегда будет иметь значение NUL.
Для большей наглядности проиллюстрируем сказанное примерами.
Рассмотрим использование ссылочного ref-аспекта на следующем примере: Накладная в атрибуте Итого обобщает значение атрибута Сумма всех своих Записей. Здесь и далее на подобных схемах вертикальная линия разделяет пространства связанных отношением классов, а выступ на ней обозначает меру количественного взаимодействия классов как многие-к-одному. В нашем примере многие- это Запись.

Атрибут [Н] является атрибутом прямой ссылки отношения Записи с Накладной. В случае реализации отношения этот атрибут получает в качестве значения дескриптор IDO объекта Накладная.
При любом своем изменении значение Сумма активно передается атрибуту Итого, при этом базовый сокет соединителя использует декларацию ссылочного ref-сокета для обращения к атрибуту [Н]. Извлеченное ref-значение будет использовано в качестве адресного параметра (как указатель на целевой объект) метода Set, вызываемого в адрес атрибута Итого. Если же отношение не реализовано, производный Set не будет вызван.
При получении значения атрибутом [Н], последний методом Reset инициирует базовый сокет на вызов метода Set, значащими параметрами которого будет пара NUL → [текущее значение Суммы]. Если затем де-инициализировать значение [Н] (разорвать отношение), то атрибут методом Unset инициирует базовый сокет на вызов метода Set с параметрами [текущее значение Суммы] → NUL. Что приведет к тому, что текущее значение Суммы будет «изъято» из текущего значения атрибута Итого.
Обратим внимание: аддитивный функционал атрибута Итого «умеет» корректно изменять результирующее значение, получая на вход изменение значения атрибута-аргумента. Такое поведение, характерное для так называемых «ленивых» вычислений, лежит в основе реализации всех естественных функционалов. Применительно к приведенному примеру, атрибуту Итого нет необходимости прибегать к опросу Get всех частных Сумм при изменении какой-либо одной, ему достаточно учесть величину и направление изменения.
Возвращаясь к примеру: если уже инициализированный ранее ссылочный атрибут [Н] получит новое значение (Запись изымается из одной Накладной, и включается в состав другой), то этот атрибут вызовет Unset перед изменением, и Reset после изменения. Тем самым Сумма записи будет изъята из Итого первой Накладной, и добавлена в Итого второй. При любой комбинации внешних воздействий, система перманентно сохранит логическую согласованность значений.
Для иллюстрации работы блокирующего аспекта попросту дополним предыдущий пример: пусть по каждой товарной позиции предусмотрена фиксированная скидка, которая может быть выключена вручную.
Стоит отметить, что если создание блокирующего суб-соединителя делается в конструкторе вручную, то декларации всех ссылочных суб-соединителей создаются автоматически, при связывании внешним соединителем атрибутов разных классов. Далее, во всех примерах ссылочные суб-соединители не показываются. Также отметим, что в качестве блокирующего контекста можно использовать любой атрибут, так как значение любого типа автоматически приводится к логическому.
Следующий пример иллюстрирует работу key-контекста соединителя: объекты класса Запись формируют список курсов Валюты, который затем используется для выполнения обменных Операций с этой валютой.
 Атрибуты Дата в классах Запись и Операция являются источником ключа — key-контекстом для соответствующего соединителя.
Атрибуты Дата в классах Запись и Операция являются источником ключа — key-контекстом для соответствующего соединителя.
Атрибут Курс в классе Валюта хранит список, образованный парами Дата: Курс, который формируется назначенным атрибуту списковым функционалом из значений, которые активно (методом Set) передаются ему по соединителю из класса Запись. Отметим, что в параметрической части методов Set и Get под указатель на значение ключа перманентно выделено отдельное место.
В классе Операция атрибут Курс, используя в методе Get значение Дата как ключ, извлекает соответствующее значение из списка. Сам Get при этом инициируется активным методом Reset, порожденным изменением значения: или атрибута Дата или ссылочного атрибута, указателя на объект Валюта (соответствующий ссылочный атрибут на рисунке не показан).
Обратим внимание: в предыдущем примере соединитель Курс.[Валюта] → Курс.[Операция] не является активным, так как на стороне атрибута-источника не установлен флаг [S]. Соответственно, никакие изменения в списке курсов не будут активно транслироваться в уже имеющиеся Операции. Тем не менее, изменение значения любого из контекстов соединителя условно «активирует» его, так как сопровождается вызовом активных методов Reset | Unset. И хотя сам Get пассивен, тем не менее возвращенное им значение будет присвоено атрибуту Курс в ходе исполнения исходной транзакции на изменение Даты или ссылки на Валюту.
Соединитель, обладающий [S] флагом, является безусловно активным соединителем. Соединитель, лишенный собственной активности, но при этом обладающий активными контекстами (на что указывают флаги [R] и [U] в его контекстных сокетах) в дальнейшем называется полу-активным соединителем.
Соединитель, обладающий только флагом Get, считается пассивным соединителем. Если же у соединителя сбросить все флаги, то это равноценно его полному удалению из модели. И обратим внимание: именно флаг Get определяет не упомянутое ранее, но такое важное свойство соединителя как вектор передачи значения.
Благодаря транзакционному характеру исполнения, активные соединители гарантировано обеспечивают перманентную логическую согласованность значений связываемых атрибутов.
Но активный соединитель применим далеко не всегда. Чуть выше был приведен пример с курсами валют, в котором значение Курс.[Операция] будет согласовано с источником только на момент последнего срабатывания контекстов. И если на заданный день значение курса в списке курсов (Курс.[Валюта]) изменится, то это изменение само по себе уже не повлияет на хранимое значение Курса в Операции.
К тому же, не стоит забывать и о нештатных ситуациях. Например, когда функционально зависимый атрибут создается уже после того, как были сформированы значения атрибутов-аргументов. В этом случае восстановить согласованность данных можно только а принудительном порядке, используя Update.
Исполнительный метод Update, принадлежащий мета-атрибуту, предназначен для принудительного восстановления согласованности значений. Вызов этого метода в адрес атрибута указанного объекта данных, заставляет атрибут заново сформировать свое хранимое значение из значений атрибутов-аргументов в текущий момент времени.
Стоит отметить, что на практике бывают вполне конкретные ситуации, когда рассогласованность значений является следствием условий и правил реализации прикладной задачи. В этих ситуациях метод Update следует использовать как инструмент Событие реального времени прикладной задачи. Например, некоторое производное значение требуется сформировать внешним событием по состоянию на выбранный момент времени, и зафиксировать его в этом состоянии.
В самом первом примере, там где Количество и Цена активно образуют Сумму, обратим внимание на следующий факт: атрибут Сумма, в отличие от Количества и Цены, не может получить свое значение извне, внешним вводом. Этот явный запрет обусловлен требованиями согласованности и непротиворечивости данных, которые очевидным образом будут нарушены вводом в общем-то произвольного значения, не соответствующего действующим аргументам. Поэтому, при наличии активных внешних соединителей, атрибут автоматически теряет способность к интерфейсной редактируемости производных значений.
Между тем, эту способность можно восстановить, разрешив атрибуту реверс введенного значения в один из атрибутов-аргументов. Иными словами, нужно выбрать получателя корректирующего значения, а именно – соединитель, в который будет осуществлен реверс. В нашем примере представляется логичным, если получателем коррекции будет выбран атрибут Цена, для соединителя с которым разрешается вызов метода Set со стороны Суммы путем установки соответствующего флага [S] в Get-сокете, как показано на рисунке.
Отметим, что собственно исполнителем реверсивной передачи значения всегда является функционал атрибута, обладающий соответствующим алгоритмом для вычисления значения коррекции. Целевой атрибут для передачи он определяет через сокет, у которого флаги [S] и [G] установлены одновременно.
Реверс значения может быть реализован в адрес любого атрибута, обладающего способностью принять значение извне, и в том числе такого атрибута, который сам получил эту способность за счет включения реверса:

Получив ввод извне, атрибут Итого использует список обратных ссылок для реверсивной раздачи своего изменения атрибутам Сумма для всех объектов Работа из списка обратных ссылок (ref-контекст). Не стоит думать, что приведенный пример лишен практического смысла: здесь стоимость работ подгоняется под предельную сумму, озвученную заказчиком. Впрочем, стоит привести еще один пример распределения значений, также основанного на механизме реверса.

В каждом из классов атрибут Часы используется в качестве key-контекста к реверсивному соединителю, обеспечивая его тем самым базисными значениями для пропорционального распределения значения Сумма.
Сокет обладает свойством инверсии, которое включается установкой флага Inverse. Смысловое назначение и применение этого свойства различно для сокетов на разных сторонах соединителя.
Так если флаг инверсии установлен исходящему базовому сокету или контекстному сокету, то передаваемое через этот сокет значение будет инвертировано: положительное число станет отрицательным, а логическое значение изменится на противоположное.

Установка флага инверсии для входящего (Get-) сокета соединителя изменит операционное поведение функционала атрибута. Так значение, полученное через инверсный сокет, мультипликативный функционал числа будет рассматривать как делитель, а не как сомножитель. Аналогичным образом значение, поступившее через инверсный сокет, будет рассматриваться аддитивным функционалом как вычитаемое.
Самое примечательное состоит в том, что технология соединителей в полной мере используется также и для обеспечения внутренних потребностей самой модели данных. И в частности – для реализации взаимного обмена идентификаторами производных объектов классов, в рамках декларации отношения между этими классами и в соответствии с требованиями ссылочной симметрии. Ссылочные атрибуты, образующие отношение классов, очевидным образом находятся в прямой причинно-следственной зависимости, которая в модели данных выражается декларацией соединителя.
Помимо соединителя, для реализации отношения используются и так называемые служебные атрибуты. Эти атрибуты, выполняющие определенные утилитарные функции, декларированы непосредственно в кортеже мета-класса, а следовательно присутствуют в кортеже каждого пользовательского класса.
Источником значения для ссылочного соединителя является служебный атрибут Own. Этот атрибут типизирован дескриптором собственного класса. Когда класс создает производный объект, то в качестве значения атрибута Own он сохраняет дескриптор IDO этого объекта.
Еще один служебный атрибут – Del, по умолчанию используется в качестве lock-контекста для всех без исключения исходящих внешних соединителей, связывающих атрибуты разных классов. Эта декларация обеспечивает адекватное поведение удаляемого объекта, а именно – изъятие (Unset) значения атрибутов-аргументов из значений атрибутов-получателей, локализованных в других классах.
Ну а собственно сам ссылочный атрибут выступает в качестве ref-контекста активного ссылочного соединителя, предоставляя ему дескриптор IDO целевого объекта.
Значение списка обратных ссылок формируется списковым функционалом из пар ключ-значение, где значением является IDO объекта-владельца прямой ссылки, а в качестве источника ключа (key-контекст) по умолчанию используется базовый атрибут класса. Таким образом, формирование списка обратных ссылок по сути ничем не отличается от формирования списка курсов из примера выше, в котором lock-контекст Del, и ref-контекст [B] также присутствуют, но не были показаны на схеме.

Стоит лишний раз подчеркнуть, что вся эта конструкция, включающая в себя служебные атрибуты и ссылочный соединитель, создается конструктором отношения автоматически.
Несмотря на наличие у сокета соединителя методов Unset/Reset, собственной функциональностью соединитель не обладает. Логически связывая атрибуты, соединитель является всего лишь декларацией наличия и характера причинно-следственной зависимости производных значений. Реализация же самой этой зависимости осуществляется исключительно методами атрибута. Поэтому, под функциональностью соединителя следует понимать комплексное декларативное свойство описываемой им зависимости.
Будучи сущностью сугубо виртуальной, соединитель образован экземплярами мета-сокета, которые логически связаны между собой взаимной адресацией. Соответственно, характер декларируемой зависимости атрибутов определяется как комбинацией сокетов, образующих соединитель, так и установкой флагов отдельного экземпляра. Отдельный сокет может быть связан с четырьмя другими сокетами, за каждым из которых закреплен строго однозначный функциональный аспект: базовый (оппозитный) (base-), блокирующий (lock-), ссылочный (ref-) и дополнительный (key-). Соответственно, адресная часть свойств мета-сокета включает в себя три маршрута в терминах IDA+IDE+IDS (смысл дескриптора IDE станет ясен позднее), из которых указатель на base-сокет дополнен дескриптором IDC. Свойство мета-сокета, определяющее его передаточную функцию, включает в себя пять флагов: Set, Get, Reset, Unset, Inverse.
Ранее не упоминалось, но декларация мета-сокета включает в себя также дескриптор функционала IDF. Атрибут позволяет сформировать свое значение единственным способом, поэтому у входящего сокета (Get-) это свойство не используется. Но исходящий сокет, а также контекстные сокеты сложного соединителя, могут использовать не только хранимое значение атрибута, но и преобразованное значение, полученное через функционал.
Во всех рассматриваемых ранее примерах по умолчанию предполагалось, что атрибуты класса оперируют персистентными значениями, которые хранятся в базе данных в кортежах объектов класса. Факт долговременного хранения производных значений позволяет характеризовать такие атрибуты как статические. Для статических атрибутов выборка данных, реализуемая исполнением метода Get, сводится к простому извлечению и возврату хранимого значения, независимо от всех прочих условий, включая наличие у атрибута входящих соединителей.
Из этого правила есть одно небольшое исключение. Это исключение применяется к статическим атрибутам, хранимое значение которых по тем или иным причинам не было инициализировано (например, если атрибут создан что называется «задним числом»). В этом случае метод Get делает попытку сформировать возвращаемое значение путем опроса входящих соединителей производными Get. При этом, даже если такое значение и получено, то оно не становится хранимым, так как выборка по определению не может изменить состояние базы данных. Несколько выше рассматривалась совсем другая ситуация: в полу-активном соединителе Get порождается активными Unset/Reset, и возвращаемое им значение закономерно становится хранимым.
Исключение неожиданно может стать правилом, при определенных условиях. Совершенно необязательно использовать хранимое значение, если его можно сформировать динамически, на основе входящих соединителей к атрибутам-аргументам. Для придания атрибуту такого поведения достаточно установить соответствующий флаг в его свойствах.
При реализации выборки динамический атрибут игнорирует хранимое значение, даже если таковое и существует в объекте данных, и использует для формирования значения исключительно назначенные ему функционалы и причинно-следственные связи, выраженные соединителями. При опросе производные вызовы Get будут сделаны только для тех сокетов из кортежа, у которых установлен флаг Get [G].

Отметим, что даже при наличии входящих соединителей далеко не все атрибуты можно перевести в динамическую форму. Базовые характеристики сущностей, ссылочные значения, а также все списки, могут существовать только статически. И не стоит забывать, что прямо или опосредственно, но значение динамического атрибута формируется из хранимых значений.
Так как динамический атрибут не образует хранимого значения, то все его входящие соединители принудительно переводятся в неактивную форму сбросом флагов Set | Unset | Reset во всех сокетах. Это позволяет автоматически исключить излишний вызов активного метода в адрес динамического атрибута. Во всем остальном поведение динамического атрибута соответствует всем рассмотренным ранее правилам и примерам и, что принципиально важно, обеспечивает безусловную логическую согласованность данных.
Использование динамических атрибутов закономерно уменьшает объем хранимых данных, но смысл их применения заключается не в этом. Если убрать из рассмотрения дисковые операции, то в модели данных, образованной только статическими атрибутами, время исполнения выборки значения на порядки меньше времени исполнения атомарной транзакции, продолжительность которой к тому же зависит от объема последующих зависимостей. Этот дисбаланс частично компенсируется количественным соотношением выборок и транзакций – выборок обычно на порядок больше.
Использование динамических атрибутов позволяет разработчику приложения сместить баланс времени исполнения в сторону увеличения длительности выборки за счет уменьшения длительности транзакции. В самом деле, если некоторый атрибут обобщает значения некоторого множества значений других атрибутов, то делать это он будет в каждой транзакции, изменяющей это множество. И если этот атрибут используется в достаточно редких отчетах, то есть все основания перевести его в динамическую форму.
Производным значением атрибута может быть как единичное (атомарное) значение, так и множество однотипных значений в формате кортежа, рассматриваемых как тривиальный массив (перечисление). Следует отметить, что идея массива значений в качестве значения характеристики понятийной сущности присутствует изначально, а значит его использование – всего лишь более точное соответствие модели данных целевой предметной области.
Декларация массива в свойствах атрибута, также как и его реализация, также принимает форму кортежа, элементы которого содержат пользовательские наименования элементов массива. Если кортеж наименований не инициализирован, то это означает, что атрибут оперирует единичным значением, и считается атомарным. В противном случае атрибут считается перечислимым. При создании атрибута в первую очередь выбирается и устанавливается именно это его свойство, определяющее форму существования производного значения. Логично предположить, что при выборе перечислимой формы сразу создается два элемента, по умолчанию именуемые попросту и без затей: “1“ и “2“.
Для идентификации отдельного элемента массива как в декларациях атрибута, так и в массиве значений, используется порядковый номер элемента – дескриптор IDE. Для этого дескриптора перманентно, в целях унификации, в формате полного маршрута зарезервировано отдельное место, что придает этому формату следующий вид: IDC+IDA+IDE+IDS. Если маршрут применяется к атомарному атрибуту, то значение IDE попросту игнорируется. Если значение IDE равно 0, но маршрут адресует перечислимый атрибут, то в область его действия попадает каждое значение массива последовательно.
При создании модели приложения использование перечислимой формы атрибута дает определенные преимущества. Так процедура создания нового атрибута несколько сложнее добавления элемента в массив. Но что более существенно, технология соединителей допускает так называемые групповые операции с массивами. Если в свойствах сокета в кортеже атрибута-массива не установлен дескриптор IDE, “привязывающий" его к конкретному элементу массива, то действие этого сокета распространяется одинаково на все элементы массива. Это правило позволяет, в частности, обеспечить передачу значений из массива в массив одним соединителем.
Список образован парами ключ-значение, при этом типы значения ключа и собственно значения одинаковы для всех элементов списка, что неудивительно, если вспомнить механизм их образования на рассмотренных выше примерах списка обратных ссылок и Валюта.{Курс}. Номинально, никаких прямых ограничений на использование типов значений как в качестве ключа, так и в качестве собственно значения, не накладывается. Так для атрибута обратной ссылки значением является дескриптор IDO объекта класса. С точки зрения логического представления список линеен, однороден, и упорядочен по возрастанию значения ключа.
Все списки являются экземплярами еще одного, ранее не упомянутого члена уровня мета-определений – мета-списка. Мета-список владеет полным набором методов управления списком, и обеспечивает: создание списка, вставку и удаление элементов, выборку данных и получение численных характеристик списка. Физически же список реализован в виде B-дерева, корень, узлы и листья которого являются экземплярами мета-кортежа, которые в свою очередь хранятся в объектах данных.
На уровне модели данных мета-список не создает производных экземпляров. Вместо этого атрибутам класса назначаются различные функционалы из семейства списковых функционалов, которые собственно и осуществляют прямую работу со списками, используя для этого методы мета-списка. Списковые функционалы определены отдельно для каждой пары типов ключа и значения, что позволяет не только учитывать специфику типа, но и расширить палитру способов управления значениями в списке.
Система типов значений образует естественную иерархию, в которой домен типа-предка включает в себя домены значений всех своих потомков. Иными словами атрибут, типизированный предком, может принять любое значение типа-наследника, при необходимости приводя его к внутренней форме представления своего типа.

Всеобщий предок – неопределенный тип [U]. Фактически – это временный тип, позволяющий создать атрибут только как форму существования значения: атомарную или перечислимую, с отложенным назначением типа. Неопределенность типа может сохранятся сколь угодно долго, но при создании входящего соединителя к такому атрибуту, конструктор модели автоматически изменит Undefined Type на тип атрибута-аргумента.
К логическому типу [L] можно привести любое значение, рассматривая его со следующей точки зрения: значение фактически существует – true, или оно не инициализировано – false. Ко второму случаю также относятся такие частности как ноль для числа, и отсутствие других литералов кроме пробела для строки.
Для типа String [S] значением является последовательность литералов произвольной длины. При этом тип кодировки (ASCII или UTF) един для всей базы данных, и устанавливается при ее генерации. Но при необходимости можно создать под-домены (подтипы) для разных кодировок. На порядок хранения значения String это не влияет.
Тип Numeric [N] объединяет в себе все вещественные численные значения, рассматриваемые в десятичной системе исчисления с плавающей или фиксированной десятичной точкой. Из него выделен тип Integer [I] –- все множество целых положительных чисел, из которого в свою очередь выделен тип Date [D] – целые числа в календарной системе исчисления.
Тип Complex [C], он же User Defined Type [UDT] является абстрактным прототипом-доменом, объединяющим множество создаваемых пользователем комплексных типов значений – классов данных. Домен значений класса, включает в себя домены значений всех классов, порожденных наследованием от этого класса. В качестве значения домена, образованного классом, в равной степени могут рассматриваться как собственно производный от класса объект данных, так и указатель на него – дескриптор IDO этого объекта.
Тип External [Ex] включает в себя все множество значений, никак не интерпретируемых объектной моделью данных, и в силу этого условно считающихся значениями неопределенного типа, хранимых как непрерывная последовательность байт известной длины. Атрибут типа External реализует транзакционное присвоение, долговременное хранение и выборку таких значений, без возможности их преобразования и передачи по соединителям. Составной частью домена External является домен Image, значения которого используются в том числе в визуальном интерфейсе конструктора модели и интерфейсе приложения.
Для типов Numeric [N] и Date [D], метрика определяет точность существования (хранения/представления) значения. Для типа Numeric точность представляет собой количество знаков после десятичной точки. Для типа Date точность – это количество знаков из шаблона CYMDhms, образующих итоговый шаблон атрибута, по которому выравнивается результирующее значение.
Как уже упоминалось, функционал – это предопределенный метод, идентифицируемый дескриптором IDF. Исходное множество функционалов включает в себя самые примитивные, но наиболее часто используемые методы формирования значений, но это множество может быть легко расширено путем добавления в него новых функционалов. Для каждого типа значений существует свой набор естественных функционалов:
— для Logical – аддитивный (логическое ИЛИ) и мультипликативный (логическое И);
— для String – аддитивный (конкатенация);
— для Numeric – аддитивный, мультипликативный, минимум, максимум;
— для Integer – аддитивный, мультипликативный, минимум, максимум;
— для Date – аддитивный (сдвиг), минимум, максимум;
— для Complex – аддитивный (присвоение), Autoset;
Все перечисленные функционалы допускают получение значения из множества источников (соединителей). Роль функционала присвоения значения из единственного источника по умолчанию играет аддитивный функционал. Для всех типов, за исключением Logical и External, существуют списковые функционалы. Отдельно стоит также кратко упомянуть интервальный функционал, который обеспечивает формирование интервальных значений, и средствами которого реализуются как внутренние зависимости значений, образующих интервал, так и операции над интервальными значениями. Логично будет предположить, что интервальное значение является комплексным, и имеет перечислимую форму.
Каждый списковый функционал представляет собой функцию-обертку, инкапсулирующую мета-список и использующую методы мета-списка, внутреннюю реализацию части из которых функционал переопределяет под собственные цели и задачи. Все семейство списковых функционалов включает в себя несколько групп.
Функционалы, создающие и изменяющие список, отождествляются с собственно списком, точнее – его функциональным типом. Помимо "простого" списка, в эту группу входят "уникальный" список (списку запрещено иметь дублирующие значения ключей), а также две его логических модификации, оперирующие численными значениями: "тотализационный" список (значения с одинаковым ключом суммируются) и его последующая модификация – "интегральный" (значения с одинаковым ключом суммируются с прибавлением значения предшествующего элемента). Эти функционалы назначаются непосредственно атрибуту в качестве его входящего функционала, тем самым делая атрибут списковым. Функционалам этой группы для формирования собственно списка необходим как минимум один входящий активный соединитель – источник ключа и значения.
Функционалы выборки, возвращающие значение из списка, всегда назначаются исходящему сокету соединителя, локализованному в кортеже спискового атрибута. Хотя при этом и имитируется «приписка» такого функционала к атрибуту-получателю. Собственно сам key-контекст (источник ключа), может быть декларирован для любого из базовых сокетов этого соединителя.
Функционалы, осуществляющие выборку значения по ключу, различаются по условию позиционирования: "равно" (точное позиционирование), "меньше" (позиционирование на логически предшествующий элемент), "больше" (аналогично, только последующий), "равно или меньше" и "равно или больше" (если не точно, то предшествующий или последующий). Если нет элемента, удовлетворяющего условию, функционал вернет эквивалент "пустого" значения. Аналогичная им подгруппа функционалов вместо значения возвращает позицию элемента – его порядковый номер в списке. Еще одна подгруппа функционалов ("первый/последний/N" – "ключ/значение") возвращает запрошенное из первого, последнего, или указанного (N) элементов списка.
Отнюдь не все задачи можно решить, комбинируя примитивные функционалы. Для реализации сложных алгоритмов в свойствах атрибута предусмотрен контейнер Script, в котором можно разместить произвольный скрипт (например, на языке Python) на правах частного функционала конкретного экземпляра атрибута. Практика создания различных приложений неожиданно показала, что к этому средству приходится прибегать достаточно редко. Отметим, что в теле скрипта статического атрибута допускается использование активных методов, адресованных классу (Create) или атрибуту класса (Set или Update). Для скрипта динамического атрибута допустим только вызов метода Get.
Атрибут класса является экземпляром мета-атрибута. Атрибут характеризуется пользовательским наименованием (Name), уникальным в пределах собственного класса, типом значения (Type), метрикой типа (Metric), а также флагом Dynamic. Помимо этого, атрибут владеет дескриптором функционала IDF, контейнером Script, и двумя кортежами: элементов массива (Item list) и сокетов (Socket list). В кортеже собственного класса атрибут идентифицируется дескриптором IDA.
В модели данных атрибут выполняет функцию фабрики значений, и с этой точки зрения является центральным действующим лицом вычислительной среды объектного управления данными. Для выполнения операций над значениями атрибут использует методы Set, Get и Update, а также набор типозависимых функционалов.
Атрибуты, связанные между собой соединителями, образуют топологию, чем-то напоминающую топологию нейросети. Вспомним отправную точку – предметная область рассматривается как система взаимодействующих значений. Соответственно, идеальная аппаратная платформа для такой сети выглядит как множество независимых примитивных процессоров, взаимно связанных последовательными каналами. В такой аппаратной среде можно моделировать самые различные процессы.
Служебные атрибуты перманентно присутствуют в кортеже любого класса, где занимают строго фиксированные позиции. Эти атрибуты используются моделью данных для решения ее собственных задач. Так упомянутые ранее атрибуты Del и Own, обеспечивают реализацию симметричной связи объектов классов. Еще один, не упомянутый ранее, служебный атрибут – Type, в объекте класса хранит структурный тип объекта – дескриптор IDC класса-фабрики.
Класс данных является экземпляром мета-класса независимо от того, каким способом этот экземпляр был получен. Класс характеризуется пользовательским наименованием (Name), уникальным в полном множестве классов, визуальным образом (Image), а также кортежем атрибутов (Attribute list). В полном множестве классов отдельный класс идентифицируется дескриптором IDC. Если класс был создан наследованием от другого класса-предка, то в свойстве Parent класс хранит IDC класса-предка.
В вычислительной среде объектного управления класс выполняет функцию фабрики объектов, используя для этого метод мета-класса Create. Объект класса создается как экземпляр кортежа атрибутов класса.
Удаление объекта не является прерогативой класса. Объект логически удаляется инициализацией значения служебного атрибута Del, который, в целях обеспечения логической целостности, автоматически присутствует во всех внешних соединителях в качестве lock-контекста. Инициализация Del влечет за собой де-инициализацию всех действующих связей объекта, переводя объект в изолированное состояние. Впоследствии, логически изолированный объект будет удален физически сборщиком мусора.
Класс данных может быть создан не только как экземпляр мета-класса, но и наследованием от другого класса. Предметом наследования является полный кортеж атрибутов класса-предка, который перманентно присутствует в кортеже атрибутов класса-наследника. Это позволяет классу-предку включить в свой домен все без исключения объекты, порожденные как прямыми, так и опосредствованными его наследниками, независимо от глубины наследования. Унаследованный кортеж является естественным интерфейсом ко всем объектам в домене класса-предка.
Механизм реализации наследования кортежа атрибутов исключительно прост: в классе-наследнике создается экземпляр (!) кортежа атрибутов предка. Этот экземпляр по определению не содержит значений, так как необходимости дублировать декларации атрибутов нет – требуемые декларации можно получить, обратившись к кортежу класса-предка. Класс-наследник сформирует у себя полную декларацию атрибута только в том случае, если внесет в нее свои частные изменения, или если создаст новый собственный атрибут. Когда новый атрибут создается в классе-предке, то, предварительно, в полном множестве его наследников определяется максимальный размер кортежа атрибутов, после чего создаваемому атрибуту выделяется элемент в кортеже предка за пределами этого размера. Тем самым новый атрибут предка автоматически становится доступен всем его наследникам. Образующимися при этом в кортежах не инициализированными элементами можно пренебречь, так как места они практически не занимают.
Полиморфизм наследников реализуется переопределением правил получения значения для унаследованных атрибутов, с сохранением их типа. При этом запрещено изменять унаследованные соединители, которые, при необходимости, следует де-активировать и создать новые.
Забегая вперед стоит упомянуть, что пользовательский класс данных, являясь комплексной сущностью, обладает множеством форм его интерфейсного (и в том числе визуального) представления. Класс-потомок в полной мере наследует формы представления предка, с возможностью их переопределения. Естественное сочетание полиморфизма с "полиформизмом" является мощным инструментом разработки приложения.
В общей массе атрибутов класса всегда можно выделить такой, значение которого используется для пользовательской идентификации конкретного объекта этого класса, как например атрибут Наименование в классе Контрагент. Такой атрибут выполняет функцию базового атрибута класса.
Логично предположить, что именно базовый атрибут должен автоматически использоваться в качестве key-контекста для любого соединителя к списковому функционалу, включая списки обратных ссылок. Для этого базовый атрибут должен иметь фиксированную позицию в кортеже любого класса, а именно – размещаться сразу после служебных атрибутов.
Из всех существующих типов значений только два типа – String и Date, могут быть осмысленно назначены базовому атрибуту при его создании. Эти два варианта типизации и предопределяют существование двух классов-прототипов: Именованного класса и класса-События, с соответствующими базовыми атрибутами.
Классы-прототипы удобно использовать в качестве шаблонов при создании разработчиком пользовательских классов, что не только представляется логичным, но и дает небольшой выигрыш: создаваемый класс сразу включает в себя базовый атрибут нужного типа с необходимым наименованием.
Уже неоднократно проверено – обычную программу мышкой не создашь. В случае же использования модели приложения/данных все строго наоборот: текстовая нотация выглядит как унылое, мало информативное перечисление деклараций. Зато в визуальной среде те же самые декларации выглядят естественно и весьма наглядно: есть отображаемое целиком или частично общее пространство связанных отношениями классов, а переход в визуальное пространство класса открывает множество его атрибутов с их связями. Впрочем, принципы интерфейсного представления и механизмы его реализации – это тоже тема для отдельной статьи.
Исполнительная модель данных создается и изменяется через свою форму представления – модель приложения. В качестве редактора этой модели выступает визуальный конструктор, оперирующий образами сущностей модели. Переход из пользовательского интерфейса приложения в визуальную среду конструктора и возврат обратно, в среду исполнения приложения с сохранением текущего состояния интерфейса, осуществляется одномоментно горячей клавишей. При этом все сделанные конструктором изменения вступают в силу немедленно. Если что-то сделано не так, то это станет очевидно сразу: в виде ошибочного результата или отсутствия реакции на интерфейсное событие, без прерывания работы приложения.
Конструктор создает новые компоненты модели как декларативные экземпляры мета-сущностей, при этом полностью скрывая реальные дескрипторы производных экземпляров. Исходный набор базисных мета-сущностей невелик, что позволяет легко контролировать логическую непротиворечивость вновь создаваемых деклараций уже существующим в модели путем простого исключения из доступа конфликтующего инструмента редактора или конструкционного компонента.
Действующая модель данных представляет собой простую декларацию вида сущность-свойство, а значит может быть экспортирована в текстовый формат: XML, JSON, или в форме последовательности транзакций по созданию ее компонент. В текстовое представление внутренние дескрипторы не экспортируются, вместо них используются пользовательские наименования классов и атрибутов.
Модель данных описывает информационную систему, обладающую состояниями. Соответственно, ее невозможно использовать для реализации драйвера, например.
Также с ее помощью невозможно реализовать отдельный алгоритм или подпрограмму – модель данных описывает предметную область только целиком.
По соображениям производительности (из-за отсутствия соответствующих аппаратных средств) модель данных невозможно использовать для прямого моделирования физических процессов в реальном времени. Хотя такой потенциал есть.
Представляются лишенными смысла попытки создать универсальную модель «всего на свете». Прикладная программа всегда отражает предметную область только со строго определенной точки зрения и в определенных границах. И для другой точки зрения та же самая предметная область может выглядеть уже иначе.
Во всем остальном вычислительная среда на основе модели данных предназначена для решения тех же самых задач, которые решаются на основе всех прочих баз данных. Но при этом отличается некоторыми полезными свойствами.
Согласитесь, визуальная модель приложения дает более наглядное восприятие бизнес-логики.
Ссылочная симметрия позволяет использовать всю мощь методов естественной навигации, как в данных, так и в мета-данных.
Исполнительная модель данных, образующая приложение, – это всего лишь хранимая в базе данных декларация, абсолютно не зависящая ни от архитектуры процессора, ни от операционной системы.
Скорость разработки, алгоритмическая надежность, строгая ссылочная целостность, перманентная согласованность, – все это есть прямое следствие интеграции бизнес-логики непосредственно в логическую структуру базы данных. И при этом коренным образом меняется подход к реализации интерфейса приложения, что подлежит отдельному подробному рассмотрению.
Природа демонстрирует нам свое бесконечное разнообразие, полученное бесконечным же комбинированием элементов в общем-то совсем крохотного базисного набора (кивок в сторону ДНК). Это ее самый любимый прием.
Всего четыре абстрактных сущности образуют базис, которого достаточно, чтобы информационно описать любую предметную область. Декларативных экземпляров всего трех мета-сущностей вполне достаточно, чтобы это описание формализовать в виде модели данных. И, в вычислительной среде объектного представления, образованной шестью исполнительными методами мета-сущностей, модель будет вести себя как программа, давая требуемый результат.
Все выше изложенное – всего лишь дальнейшее развитие реляционной модели Э.Ф.Кодда, а также идей К.Дейта по объединению реляционных и объектных технологий. Суть реляционной модели осталась прежней: таблицы, колонки, связь таблиц. В нее просто добавили столь естественный, но почему-то не упомянутый Коддом четвертый элемент – связь колонок в таблицах.
Если предметная область автоматизации представляет собой систему взаимодействующих значений, то ее можно описать ER-моделью, которая образована экземплярами всего четырех абстрактных сущностей: класс данных, атрибут класса, отношение классов и связь атрибутов. Такая модель не только образует логическую структуру базы данных, но обладает всеми свойствами программы, каковой по сути и является – в вычислительной среде, образованной методами упомянутых абстрактных сущностей.
Рассмотрим это смелое утверждение более подробно, начиная с самых общих определений. (Нижеследующий повтор общеизвестного необходим как минимум для обозначения смысла используемых терминов. Будет сухо и нудно — как и в любом другом теоретическом материале. Чтобы его слегка оживить, в текст вкраплены примеры.)
Практически любую объективно существующую предметную область можно рассматривать с информационной точки зрения как систему взаимодействующих значений. Сразу отметим, что отдельное значение никогда не является ни самостоятельным, ни самодостаточным, так как существует на правах некоторой характеристики объекта данных. Поэтому для точного описания предметной области в некотором ее состоянии необходима полная совокупность объектов данных с их значениями. При этом однотипные объекты описываются классом данных, и существуют на правах производных экземпляров этого класса – объектов класса.
Классы и атрибуты
Класс данных выражает собой отдельную понятийную сущность рассматриваемой предметной области и характеризуется пользовательским наименованием этой сущности. В свою очередь, любая понятийная сущность обладает некоторым уникальным набором собственных характеристик/свойств. Атрибут класса выражает собой отдельную характеристику сущности, именован пользовательским наименованием этой характеристики, обладает типом, определяющим множество (домен) допустимых ее значений, и выступает в качестве фабрики конкретных значений характеристики в объектах класса.
Соответственно, класс данных владеет набором атрибутов (класса), который он хранит в формате кортежа. Выступая в качестве фабрики объектов, класс формирует содержимое объекта в виде кортежа значений, который является экземпляром, производным от кортежа атрибутов. При этом каждое значение в кортеже значений объекта класса является экземпляром, производным от соответствующего атрибута класса.
Таким образом, вполне конкретная предметная область, существующая в виде множества объектов с их значениями, на уровне абстракции описывается системой классов с их атрибутами. И при этом данные и метаданные представляют собой персистентную структуру данных, хранимую в объектной базе данных.
Отношение классов
В основу реализации связи объектов данных положен принцип симметрии. В соответствии с этим принципом связываемые объекты взаимно обмениваются своими идентификаторами. Идентификатор объекта (дескриптор IDO) глобален в пределах физической базы данных, и представляет собой простое целое число.
На уровне абстракции связь объектов описывается отношением классов. Декларация отношения реализуется созданием атрибута в каждом из двух связываемых отношением классов, которые взаимно адресуют друг друга. Каждый из атрибутов отношения типизирован оппозитным классом отношения (каждый класс считается самостоятельным пользовательским типом данных), вследствие чего доменом значений ссылочного атрибута является множество дескрипторов объектов оппозитного класса.
Отношение классов устанавливает меру количественного взаимодействия производных объектов этих классов. При всей простоте этого определения, отношения обладают столь разнообразным функциональным поведением и взаимной логической зависимостью, что эта обширная тема будет рассматриваться отдельно.
Пока же стоит упомянуть, что в отношении один-к-одному оба ссылочных атрибута абсолютно равноправны, а их значением в объектах данных будет единственный дескриптор партнера по связи. В отношении многие-к-одному атрибуты очевидным образом не равноправны: ни по формату хранимого значения, ни по порядку формирования значения. Если на стороне многие- значением атрибута [прямой ссылки] по-прежнему будет единственный дескриптор, то на стороне -один, как следствие строго соблюдения ссылочной симметрии, значением атрибута [обратной ссылки] будет множество дескрипторов, представляющее собой список вида ключ-значение. При этом значение атрибута обратной ссылки производно от значения атрибута прямой ссылки. Механизм реализации этой производности будет подробно рассмотрен ниже по тексту.
Связь атрибутов
Под взаимодействием значений понимается их причинно-следственная функциональная связь. Эта связь существует только на понятийном уровне абстракции, где она принимает вид виртуального соединителя двух атрибутов. По аналогии с отношением классов, декларация связи атрибутов реализуется созданием двух сокетов (параллель с TCP-сокетами вполне уместна), каждый из которых принадлежит своему атрибуту, и размещается в его кортеже сокетов.
Отдельный сокет, описывающий свойства связи со стороны своего атрибута, является такой же персистентной структурой данных уровня абстракции, как класс и атрибут. Как и атрибуты отношения, сокеты, образующие соединитель, взаимно адресуют друг друга. Для этих целей декларация сокета содержит комплексный идентификатор (класс+атрибут+сокет) оппозитного сокета соединителя. Также декларация сокета содержит набор флагов, управляющих передачей и приемом значений через соединитель.
Кортеж
Логически, кортеж представляет собой простое перечисление однородных (с точки зрения кортежа) элементов, содержащих некоторое количество байт данных. Знания о содержимом и способах его формирования лежат за пределами кортежа. Кортеж лишь предоставляет место для размещения и долговременного хранения. Особенности внутренней реализации кортежа были рассмотрены здесь.
Элемент кортежа однозначно идентифицируется своим местом (порядковым номером) в кортеже, которое не изменяется никогда. При добавлении в кортеж, новый элемент занимает свое место раз и навсегда.
Содержимым элемента кортежа может быть как унитарное значение, так и другой кортеж. Это делает кортеж основным (и единственным) структурообразующим компонентом объектного представления. Так например, декларация класса представляет собой кортеж, элементами которого являются свойства класса, одним из которых является кортеж атрибутов класса.
Кортеж обладает способностью создавать собственный экземпляр, который представляет собой пустой кортеж, элементы которого не имеют содержимого. Эту способность использует например класс, как при создании классов-наследников, так и при создании своих производных объектов, в которых взаимная идентификация атрибутов и производных от них значений обеспечивается совпадением номеров элементов в соответствующих кортежах.
Система идентификации
Неизменность места, занимаемого элементом в кортеже, лежит в основе системы внутренней идентификации объектных сущностей, которая в самом общем виде выглядит так:
Каждая объектная сущность идентифицируется своим дескриптором – порядковым номером в соответствующем кортеже: IDC – класс, IDA – атрибут, IDS – сокет, IDO – объект (логически DAT объектов также следует рассматривать как кортеж). Логика также подсказывает, что классы являются элементами кортежа, специфичный владелец которого рассматривается в статье, посвященной отношениям классов.
Модели и мета-сущности
Что примечательно – на уровне абстракции существуют сразу две модели, образованные различными сущностями этого уровня.
Совокупность хранимых деклараций классов, атрибутов и сокетов образует модель данных. Модель данных считается исполнительной, так как образующие ее сущности выполняют в отношении уровня данных функции фабрики объектов (класс) и фабрики значений (атрибут).
Модель приложения является виртуальной, и существует на правах формы представления модели данных. Модель приложения динамически создается визуальным конструктором, который использует ее для отображения существующей модели данных, и создания в ней новых деклараций, путем создания новых сущностей модели приложения. В образовании модели приложения, наряду с вещественными классом и атрибутом, принимают участие такие виртуальные сущности как отношение и соединитель. Виртуальные сущности не образуют хранимых деклараций, а создаются динамически из деклараций атрибутов и сокетов, частично инкапсулируя факт их существования. Виртуальных характер модели приложения ничуть не мешает рассматривать ее в качестве первичной модели предметной области.
В свою очередь, все перечисленные вещественные и виртуальные сущности уровня абстракции являются экземплярами объектных сущностей еще более высокого уровня абстракции – уровня мета-определений. На этом уровне структурно и программно реализованы такие сущности как: мета-кортеж, мета-класс, мета-атрибут, мета-отношение, мета-сокет и мета-соединитель.
Стоит лишний раз подчеркнуть, что все методы конструирования, с помощью которых создаются и изменяются обе модели (данных и приложения), а также все без исключения методы исполнения, используемые моделью данных применительно к объектам и значениям уровня данных, принадлежат сущностям уровня мета-определений. Уровень же моделей, обеспечивающий создание и исполнение всей бизнес-логики приложения, образован исключительно декларативными экземплярами мета-сущностей, и не содержит в себе исполняемого кода.
Методы исполнения
Методы конструирования, с помощью которых создаются экземпляры мета-сущностей и переопределяются значения тех или иных их свойств, представляются достаточно очевидными, и не требуют комментариев. Чего нельзя сказать об образующих пресловутую вычислительную среду методах исполнения, с помощью которых воздействия извне изменяют состояние данных в соответствии с правилами, декларированными в форме модели данных. Собственно говоря, вызов метода исполнения и является таким внешним воздействием. Всего же таких методов четыре: Create, Set, Get и Update.
Метод Create принадлежит мета-классу, и используется для создания производного объекта класса. Параметром метода является дескриптор IDC целевого класса. Метод Create создает объект как экземпляр кортежа атрибутов указанного класса, и регистрирует его в таблице аллокации DAT за очередным свободным дескриптором IDO.
Методы атрибута: Set, Get и Update, принадлежат мета-атрибуту, и позволяют оперировать значениями объектов данных. Метод Set отвечает за присвоение значения, метод Get — за выборку значения, а метод Update является событием, инициирующим атрибут на пере-формирование производного хранимого значения (смысл этого действия станет понятным несколько позже).
Для методов атрибута целевой объект идентифицируется дескриптором IDO, а собственно целевое значение доступно исключительно через атрибут класса, путь к которому представлен в дескрипторах IDC+IDA модели данных. Иными словами, все действия над значением совершаются от лица атрибута класса. Особенностью процесса исполнения методов атрибута является то, что в его ходе каждый из методов прибегает к перебору сокетов в кортеже атрибута, с вызовом аналогичного метода для целевого атрибута, адресуемого соединителем, при условии что в сокете установлен одноименный методу флаг.
Так как исполнение любого из трех методов: Create, Set или Update, изменит состояние данных, то их вызов возможен только в контексте транзакционной сессии. Вызов любого из этих трех методов является атомарным внешним воздействием на базу данных, которое легко формализуется в формат транзакции, с ее последующим сохранением в журнале.
Рассмотрим логику исполнения методов атрибута чуть более подробно.
Присвоение значения
Итак, вызван метод Set, которому передали адресные параметры, и указатель на присваиваемое значение (*value). В теле этого метода атрибут сформирует новое значение, выполнит его присвоение соответствующему элементу кортежа объекта, а далее начнет последовательный перебор сокетов из своего кортежа. Для каждого сокета, у которого установлен флаг Set [S], исходный атрибут вызовет метод Set применительно к атрибуту, путь к которому прописан в декларациях сокета. Отметим, что исполнение метода может завершиться досрочно, без обхода кортежа сокетов, если новое значение эквивалентно хранимому.
Делая производные вызовы Set, атрибут следует принципу изоляции – «выстрелил, и забыл», не заботясь о последствиях. Дальнейший ход событий определяется уже другими действующими лицами-атрибутами. При этом, что важно, транзакционный характер исполнения обеспечивает перманентную согласованность всех изменяемых значений, независимо от объема и «протяженности» изменений.
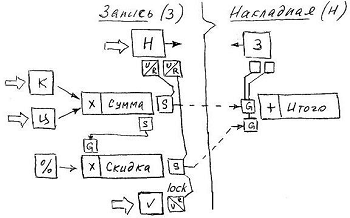
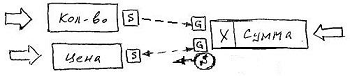
Рассмотрим формирование производного значения на примере из жизни счетов и накладных:
На схеме контурными стрелками обозначен пользовательский ввод значений, он же внешний вызов Set. Любое изменение значений атрибутов Количество или Цена активно передается атрибуту Сумма, который для формирования производного значения использует функционал, в данном случае – мультипликативный.
Функционалы — это предопределенные (для каждого типа значения) методы мета-атрибута, которые позволяют сформировать результирующее значение преобразованием значений-аргументов, полученных через соединители от одного или нескольких атрибутов-источников. Атрибуту назначают функционал путем присвоения его дескриптора (IDF), который представляет собой порядковый номер в общем списке функционалов.
Если атрибуту назначен функционал, то все вызовы Set и Get в адрес атрибута обрабатываются этим функционалом, при необходимости – с дополнительным опросом (Get) источников. Обратим внимание: для исключения первоисточника вызова из опросов, адресная часть вызова (IDC+IDA) перманентно включает в себя также и дескриптор сокета-получателя (+IDS).
Зависимый соединитель
Оба соединителя из приведенного выше примера были использованы в простой безусловной форме.
Между тем, функциональное поведение соединителя можно поставить в зависимость от действующих значений сторонних атрибутов, которые для исходного соединителя образуют своего рода "контекст исполнения". Для реализации связи с атрибутами-контекстами, в декларациях сокета предусмотрена возможность адресации трех дополнительных, так называемых "контекстных" сокетов. У каждого контекстного сокета есть свое, строго фиксированное назначение-аспект: блокирующий (lock), ссылочный (ref) и ключ (key), но вместе с тем это точно такие же экземпляры мета-сокета, как и "базовые" сокеты соединителя. Для адресации каждого контекстного сокета базовому достаточно двух дескрипторов: IDA+IDS.
Блокирующий lock-сокет разрешает передачу значения по соединителю, если возвращаемое им значение актуально, и блокирует в противном случае. Под актуальным понимается инициализированное значение атрибута-владельца сокета (lock-контекст), которое дополнительно оценивается еще и с точки зрения его типа: true для логики, не ноль для числа, и присутствует хотя бы один литерал (помимо пробела) для строки.
Ссылочный ref-сокет используется во внешних соединителях, связывающих атрибуты разных классов. Он предоставляет соединителю дескрипторы IDO объектов данных другого класса, используя в качестве источника значений соответствующий атрибут отношения (ref-контекст) в своем классе.
«Ключевой» key-сокет предоставляет соединителю значения ключа, и необходим для реализации работы со списками. В качестве источника значения ключа (key-контекст) по умолчанию используется базовый атрибут класса.
Без учета специфики ссылочного и ключевого аспектов, логика взаимодействия контекстных сокетов с базовым едина для всех трех контекстов. Так базовый сокет на каждой из сторон соединителя немедленно прервет исполнение текущего метода Set | Get, если хотя бы один из его действующих (то есть фактически декларированных и сохраняющих актуальность) контекстов содержит не актуальное значение. Иначе говоря, ref- и key- контексты перманентно обладают также свойствами lock-контекста. В этом нет ничего удивительного, если вспомнить, что значение любого типа можно привести к логическому типу.
Методы сокета
Инициация условного соединителя со стороны его контекстов осуществляется путем вызова одного из двух внутренних методов исполнения: Reset и Unset, принадлежащих мета-сокету. Эти методы вызываются атрибутом-контекстом в ходе исполнения метода Set в адрес базового сокета соединителя по следующим правилам. Если текущее значение атрибута актуально, то перед любым его изменением атрибут вызовет метод Unset для всех своих сокетов, у которых установлен флаг Unset [U]. Далее, после присвоения нового значения, в повторном цикле обхода кортежа для вызова производных методов Set, атрибут вызовет метод Reset для тех своих сокетов, у которых установлен флаг Reset [R]. Иными словами, атрибут выполняет имитацию сначала де-инициализации своего действующего значения, со всеми вытекающими из этого последствиями для внешнего окружения атрибута, а затем выполняет инициализацию уже новым значением.
В свою очередь базовый сокет, при исполнении методов Unset | Reset, вызовет метод Set в адрес оппозитного атрибута соединителя с набором параметров (включая текущие значения действующих контекстов), имитирующим де-инициализацию (Unset) значения собственного атрибута-владельца, или его инициализацию (Reset) внешним значением. Такую имитацию несложно реализовать, если в параметрической части метода Set передавать не один указатель на значение, а два: на значение перед изменением, и на новое значение. Тогда в параметрах Set, производного от Unset | Reset, один из указателей всегда будет иметь значение NUL.
Для большей наглядности проиллюстрируем сказанное примерами.
Примеры исполнения
Рассмотрим использование ссылочного ref-аспекта на следующем примере: Накладная в атрибуте Итого обобщает значение атрибута Сумма всех своих Записей. Здесь и далее на подобных схемах вертикальная линия разделяет пространства связанных отношением классов, а выступ на ней обозначает меру количественного взаимодействия классов как многие-к-одному. В нашем примере многие- это Запись.
Атрибут [Н] является атрибутом прямой ссылки отношения Записи с Накладной. В случае реализации отношения этот атрибут получает в качестве значения дескриптор IDO объекта Накладная.
При любом своем изменении значение Сумма активно передается атрибуту Итого, при этом базовый сокет соединителя использует декларацию ссылочного ref-сокета для обращения к атрибуту [Н]. Извлеченное ref-значение будет использовано в качестве адресного параметра (как указатель на целевой объект) метода Set, вызываемого в адрес атрибута Итого. Если же отношение не реализовано, производный Set не будет вызван.
При получении значения атрибутом [Н], последний методом Reset инициирует базовый сокет на вызов метода Set, значащими параметрами которого будет пара NUL → [текущее значение Суммы]. Если затем де-инициализировать значение [Н] (разорвать отношение), то атрибут методом Unset инициирует базовый сокет на вызов метода Set с параметрами [текущее значение Суммы] → NUL. Что приведет к тому, что текущее значение Суммы будет «изъято» из текущего значения атрибута Итого.
Обратим внимание: аддитивный функционал атрибута Итого «умеет» корректно изменять результирующее значение, получая на вход изменение значения атрибута-аргумента. Такое поведение, характерное для так называемых «ленивых» вычислений, лежит в основе реализации всех естественных функционалов. Применительно к приведенному примеру, атрибуту Итого нет необходимости прибегать к опросу Get всех частных Сумм при изменении какой-либо одной, ему достаточно учесть величину и направление изменения.
Возвращаясь к примеру: если уже инициализированный ранее ссылочный атрибут [Н] получит новое значение (Запись изымается из одной Накладной, и включается в состав другой), то этот атрибут вызовет Unset перед изменением, и Reset после изменения. Тем самым Сумма записи будет изъята из Итого первой Накладной, и добавлена в Итого второй. При любой комбинации внешних воздействий, система перманентно сохранит логическую согласованность значений.
Для иллюстрации работы блокирующего аспекта попросту дополним предыдущий пример: пусть по каждой товарной позиции предусмотрена фиксированная скидка, которая может быть выключена вручную.
Стоит отметить, что если создание блокирующего суб-соединителя делается в конструкторе вручную, то декларации всех ссылочных суб-соединителей создаются автоматически, при связывании внешним соединителем атрибутов разных классов. Далее, во всех примерах ссылочные суб-соединители не показываются. Также отметим, что в качестве блокирующего контекста можно использовать любой атрибут, так как значение любого типа автоматически приводится к логическому.
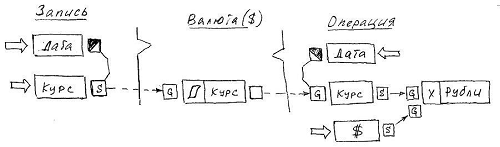
Следующий пример иллюстрирует работу key-контекста соединителя: объекты класса Запись формируют список курсов Валюты, который затем используется для выполнения обменных Операций с этой валютой.
Атрибут Курс в классе Валюта хранит список, образованный парами Дата: Курс, который формируется назначенным атрибуту списковым функционалом из значений, которые активно (методом Set) передаются ему по соединителю из класса Запись. Отметим, что в параметрической части методов Set и Get под указатель на значение ключа перманентно выделено отдельное место.
В классе Операция атрибут Курс, используя в методе Get значение Дата как ключ, извлекает соответствующее значение из списка. Сам Get при этом инициируется активным методом Reset, порожденным изменением значения: или атрибута Дата или ссылочного атрибута, указателя на объект Валюта (соответствующий ссылочный атрибут на рисунке не показан).
Активность соединителя
Обратим внимание: в предыдущем примере соединитель Курс.[Валюта] → Курс.[Операция] не является активным, так как на стороне атрибута-источника не установлен флаг [S]. Соответственно, никакие изменения в списке курсов не будут активно транслироваться в уже имеющиеся Операции. Тем не менее, изменение значения любого из контекстов соединителя условно «активирует» его, так как сопровождается вызовом активных методов Reset | Unset. И хотя сам Get пассивен, тем не менее возвращенное им значение будет присвоено атрибуту Курс в ходе исполнения исходной транзакции на изменение Даты или ссылки на Валюту.
Соединитель, обладающий [S] флагом, является безусловно активным соединителем. Соединитель, лишенный собственной активности, но при этом обладающий активными контекстами (на что указывают флаги [R] и [U] в его контекстных сокетах) в дальнейшем называется полу-активным соединителем.
Соединитель, обладающий только флагом Get, считается пассивным соединителем. Если же у соединителя сбросить все флаги, то это равноценно его полному удалению из модели. И обратим внимание: именно флаг Get определяет не упомянутое ранее, но такое важное свойство соединителя как вектор передачи значения.
Логическая согласованность
Благодаря транзакционному характеру исполнения, активные соединители гарантировано обеспечивают перманентную логическую согласованность значений связываемых атрибутов.
Но активный соединитель применим далеко не всегда. Чуть выше был приведен пример с курсами валют, в котором значение Курс.[Операция] будет согласовано с источником только на момент последнего срабатывания контекстов. И если на заданный день значение курса в списке курсов (Курс.[Валюта]) изменится, то это изменение само по себе уже не повлияет на хранимое значение Курса в Операции.
К тому же, не стоит забывать и о нештатных ситуациях. Например, когда функционально зависимый атрибут создается уже после того, как были сформированы значения атрибутов-аргументов. В этом случае восстановить согласованность данных можно только а принудительном порядке, используя Update.
Событие Update
Исполнительный метод Update, принадлежащий мета-атрибуту, предназначен для принудительного восстановления согласованности значений. Вызов этого метода в адрес атрибута указанного объекта данных, заставляет атрибут заново сформировать свое хранимое значение из значений атрибутов-аргументов в текущий момент времени.
Стоит отметить, что на практике бывают вполне конкретные ситуации, когда рассогласованность значений является следствием условий и правил реализации прикладной задачи. В этих ситуациях метод Update следует использовать как инструмент Событие реального времени прикладной задачи. Например, некоторое производное значение требуется сформировать внешним событием по состоянию на выбранный момент времени, и зафиксировать его в этом состоянии.
Реверс значения
В самом первом примере, там где Количество и Цена активно образуют Сумму, обратим внимание на следующий факт: атрибут Сумма, в отличие от Количества и Цены, не может получить свое значение извне, внешним вводом. Этот явный запрет обусловлен требованиями согласованности и непротиворечивости данных, которые очевидным образом будут нарушены вводом в общем-то произвольного значения, не соответствующего действующим аргументам. Поэтому, при наличии активных внешних соединителей, атрибут автоматически теряет способность к интерфейсной редактируемости производных значений.
Между тем, эту способность можно восстановить, разрешив атрибуту реверс введенного значения в один из атрибутов-аргументов. Иными словами, нужно выбрать получателя корректирующего значения, а именно – соединитель, в который будет осуществлен реверс. В нашем примере представляется логичным, если получателем коррекции будет выбран атрибут Цена, для соединителя с которым разрешается вызов метода Set со стороны Суммы путем установки соответствующего флага [S] в Get-сокете, как показано на рисунке.
Отметим, что собственно исполнителем реверсивной передачи значения всегда является функционал атрибута, обладающий соответствующим алгоритмом для вычисления значения коррекции. Целевой атрибут для передачи он определяет через сокет, у которого флаги [S] и [G] установлены одновременно.
Реверс значения может быть реализован в адрес любого атрибута, обладающего способностью принять значение извне, и в том числе такого атрибута, который сам получил эту способность за счет включения реверса:
Получив ввод извне, атрибут Итого использует список обратных ссылок для реверсивной раздачи своего изменения атрибутам Сумма для всех объектов Работа из списка обратных ссылок (ref-контекст). Не стоит думать, что приведенный пример лишен практического смысла: здесь стоимость работ подгоняется под предельную сумму, озвученную заказчиком. Впрочем, стоит привести еще один пример распределения значений, также основанного на механизме реверса.
В каждом из классов атрибут Часы используется в качестве key-контекста к реверсивному соединителю, обеспечивая его тем самым базисными значениями для пропорционального распределения значения Сумма.
Инверсия сокета
Сокет обладает свойством инверсии, которое включается установкой флага Inverse. Смысловое назначение и применение этого свойства различно для сокетов на разных сторонах соединителя.
Так если флаг инверсии установлен исходящему базовому сокету или контекстному сокету, то передаваемое через этот сокет значение будет инвертировано: положительное число станет отрицательным, а логическое значение изменится на противоположное.
Установка флага инверсии для входящего (Get-) сокета соединителя изменит операционное поведение функционала атрибута. Так значение, полученное через инверсный сокет, мультипликативный функционал числа будет рассматривать как делитель, а не как сомножитель. Аналогичным образом значение, поступившее через инверсный сокет, будет рассматриваться аддитивным функционалом как вычитаемое.
Реализация отношения
Самое примечательное состоит в том, что технология соединителей в полной мере используется также и для обеспечения внутренних потребностей самой модели данных. И в частности – для реализации взаимного обмена идентификаторами производных объектов классов, в рамках декларации отношения между этими классами и в соответствии с требованиями ссылочной симметрии. Ссылочные атрибуты, образующие отношение классов, очевидным образом находятся в прямой причинно-следственной зависимости, которая в модели данных выражается декларацией соединителя.
Помимо соединителя, для реализации отношения используются и так называемые служебные атрибуты. Эти атрибуты, выполняющие определенные утилитарные функции, декларированы непосредственно в кортеже мета-класса, а следовательно присутствуют в кортеже каждого пользовательского класса.
Источником значения для ссылочного соединителя является служебный атрибут Own. Этот атрибут типизирован дескриптором собственного класса. Когда класс создает производный объект, то в качестве значения атрибута Own он сохраняет дескриптор IDO этого объекта.
Еще один служебный атрибут – Del, по умолчанию используется в качестве lock-контекста для всех без исключения исходящих внешних соединителей, связывающих атрибуты разных классов. Эта декларация обеспечивает адекватное поведение удаляемого объекта, а именно – изъятие (Unset) значения атрибутов-аргументов из значений атрибутов-получателей, локализованных в других классах.
Ну а собственно сам ссылочный атрибут выступает в качестве ref-контекста активного ссылочного соединителя, предоставляя ему дескриптор IDO целевого объекта.
Значение списка обратных ссылок формируется списковым функционалом из пар ключ-значение, где значением является IDO объекта-владельца прямой ссылки, а в качестве источника ключа (key-контекст) по умолчанию используется базовый атрибут класса. Таким образом, формирование списка обратных ссылок по сути ничем не отличается от формирования списка курсов из примера выше, в котором lock-контекст Del, и ref-контекст [B] также присутствуют, но не были показаны на схеме.
Стоит лишний раз подчеркнуть, что вся эта конструкция, включающая в себя служебные атрибуты и ссылочный соединитель, создается конструктором отношения автоматически.
Функциональность соединителя
Несмотря на наличие у сокета соединителя методов Unset/Reset, собственной функциональностью соединитель не обладает. Логически связывая атрибуты, соединитель является всего лишь декларацией наличия и характера причинно-следственной зависимости производных значений. Реализация же самой этой зависимости осуществляется исключительно методами атрибута. Поэтому, под функциональностью соединителя следует понимать комплексное декларативное свойство описываемой им зависимости.
Будучи сущностью сугубо виртуальной, соединитель образован экземплярами мета-сокета, которые логически связаны между собой взаимной адресацией. Соответственно, характер декларируемой зависимости атрибутов определяется как комбинацией сокетов, образующих соединитель, так и установкой флагов отдельного экземпляра. Отдельный сокет может быть связан с четырьмя другими сокетами, за каждым из которых закреплен строго однозначный функциональный аспект: базовый (оппозитный) (base-), блокирующий (lock-), ссылочный (ref-) и дополнительный (key-). Соответственно, адресная часть свойств мета-сокета включает в себя три маршрута в терминах IDA+IDE+IDS (смысл дескриптора IDE станет ясен позднее), из которых указатель на base-сокет дополнен дескриптором IDC. Свойство мета-сокета, определяющее его передаточную функцию, включает в себя пять флагов: Set, Get, Reset, Unset, Inverse.
Ранее не упоминалось, но декларация мета-сокета включает в себя также дескриптор функционала IDF. Атрибут позволяет сформировать свое значение единственным способом, поэтому у входящего сокета (Get-) это свойство не используется. Но исходящий сокет, а также контекстные сокеты сложного соединителя, могут использовать не только хранимое значение атрибута, но и преобразованное значение, полученное через функционал.
Выборка значения
Во всех рассматриваемых ранее примерах по умолчанию предполагалось, что атрибуты класса оперируют персистентными значениями, которые хранятся в базе данных в кортежах объектов класса. Факт долговременного хранения производных значений позволяет характеризовать такие атрибуты как статические. Для статических атрибутов выборка данных, реализуемая исполнением метода Get, сводится к простому извлечению и возврату хранимого значения, независимо от всех прочих условий, включая наличие у атрибута входящих соединителей.
Из этого правила есть одно небольшое исключение. Это исключение применяется к статическим атрибутам, хранимое значение которых по тем или иным причинам не было инициализировано (например, если атрибут создан что называется «задним числом»). В этом случае метод Get делает попытку сформировать возвращаемое значение путем опроса входящих соединителей производными Get. При этом, даже если такое значение и получено, то оно не становится хранимым, так как выборка по определению не может изменить состояние базы данных. Несколько выше рассматривалась совсем другая ситуация: в полу-активном соединителе Get порождается активными Unset/Reset, и возвращаемое им значение закономерно становится хранимым.
Динамические атрибуты
Исключение неожиданно может стать правилом, при определенных условиях. Совершенно необязательно использовать хранимое значение, если его можно сформировать динамически, на основе входящих соединителей к атрибутам-аргументам. Для придания атрибуту такого поведения достаточно установить соответствующий флаг в его свойствах.
При реализации выборки динамический атрибут игнорирует хранимое значение, даже если таковое и существует в объекте данных, и использует для формирования значения исключительно назначенные ему функционалы и причинно-следственные связи, выраженные соединителями. При опросе производные вызовы Get будут сделаны только для тех сокетов из кортежа, у которых установлен флаг Get [G].
Отметим, что даже при наличии входящих соединителей далеко не все атрибуты можно перевести в динамическую форму. Базовые характеристики сущностей, ссылочные значения, а также все списки, могут существовать только статически. И не стоит забывать, что прямо или опосредственно, но значение динамического атрибута формируется из хранимых значений.
Так как динамический атрибут не образует хранимого значения, то все его входящие соединители принудительно переводятся в неактивную форму сбросом флагов Set | Unset | Reset во всех сокетах. Это позволяет автоматически исключить излишний вызов активного метода в адрес динамического атрибута. Во всем остальном поведение динамического атрибута соответствует всем рассмотренным ранее правилам и примерам и, что принципиально важно, обеспечивает безусловную логическую согласованность данных.
Балансировка производительности
Использование динамических атрибутов закономерно уменьшает объем хранимых данных, но смысл их применения заключается не в этом. Если убрать из рассмотрения дисковые операции, то в модели данных, образованной только статическими атрибутами, время исполнения выборки значения на порядки меньше времени исполнения атомарной транзакции, продолжительность которой к тому же зависит от объема последующих зависимостей. Этот дисбаланс частично компенсируется количественным соотношением выборок и транзакций – выборок обычно на порядок больше.
Использование динамических атрибутов позволяет разработчику приложения сместить баланс времени исполнения в сторону увеличения длительности выборки за счет уменьшения длительности транзакции. В самом деле, если некоторый атрибут обобщает значения некоторого множества значений других атрибутов, то делать это он будет в каждой транзакции, изменяющей это множество. И если этот атрибут используется в достаточно редких отчетах, то есть все основания перевести его в динамическую форму.
Массив значений
Производным значением атрибута может быть как единичное (атомарное) значение, так и множество однотипных значений в формате кортежа, рассматриваемых как тривиальный массив (перечисление). Следует отметить, что идея массива значений в качестве значения характеристики понятийной сущности присутствует изначально, а значит его использование – всего лишь более точное соответствие модели данных целевой предметной области.
Декларация массива в свойствах атрибута, также как и его реализация, также принимает форму кортежа, элементы которого содержат пользовательские наименования элементов массива. Если кортеж наименований не инициализирован, то это означает, что атрибут оперирует единичным значением, и считается атомарным. В противном случае атрибут считается перечислимым. При создании атрибута в первую очередь выбирается и устанавливается именно это его свойство, определяющее форму существования производного значения. Логично предположить, что при выборе перечислимой формы сразу создается два элемента, по умолчанию именуемые попросту и без затей: “1“ и “2“.
Для идентификации отдельного элемента массива как в декларациях атрибута, так и в массиве значений, используется порядковый номер элемента – дескриптор IDE. Для этого дескриптора перманентно, в целях унификации, в формате полного маршрута зарезервировано отдельное место, что придает этому формату следующий вид: IDC+IDA+IDE+IDS. Если маршрут применяется к атомарному атрибуту, то значение IDE попросту игнорируется. Если значение IDE равно 0, но маршрут адресует перечислимый атрибут, то в область его действия попадает каждое значение массива последовательно.
При создании модели приложения использование перечислимой формы атрибута дает определенные преимущества. Так процедура создания нового атрибута несколько сложнее добавления элемента в массив. Но что более существенно, технология соединителей допускает так называемые групповые операции с массивами. Если в свойствах сокета в кортеже атрибута-массива не установлен дескриптор IDE, “привязывающий" его к конкретному элементу массива, то действие этого сокета распространяется одинаково на все элементы массива. Это правило позволяет, в частности, обеспечить передачу значений из массива в массив одним соединителем.
Список значений
Список образован парами ключ-значение, при этом типы значения ключа и собственно значения одинаковы для всех элементов списка, что неудивительно, если вспомнить механизм их образования на рассмотренных выше примерах списка обратных ссылок и Валюта.{Курс}. Номинально, никаких прямых ограничений на использование типов значений как в качестве ключа, так и в качестве собственно значения, не накладывается. Так для атрибута обратной ссылки значением является дескриптор IDO объекта класса. С точки зрения логического представления список линеен, однороден, и упорядочен по возрастанию значения ключа.
Все списки являются экземплярами еще одного, ранее не упомянутого члена уровня мета-определений – мета-списка. Мета-список владеет полным набором методов управления списком, и обеспечивает: создание списка, вставку и удаление элементов, выборку данных и получение численных характеристик списка. Физически же список реализован в виде B-дерева, корень, узлы и листья которого являются экземплярами мета-кортежа, которые в свою очередь хранятся в объектах данных.
На уровне модели данных мета-список не создает производных экземпляров. Вместо этого атрибутам класса назначаются различные функционалы из семейства списковых функционалов, которые собственно и осуществляют прямую работу со списками, используя для этого методы мета-списка. Списковые функционалы определены отдельно для каждой пары типов ключа и значения, что позволяет не только учитывать специфику типа, но и расширить палитру способов управления значениями в списке.
Типизация значений
Система типов значений образует естественную иерархию, в которой домен типа-предка включает в себя домены значений всех своих потомков. Иными словами атрибут, типизированный предком, может принять любое значение типа-наследника, при необходимости приводя его к внутренней форме представления своего типа.
Всеобщий предок – неопределенный тип [U]. Фактически – это временный тип, позволяющий создать атрибут только как форму существования значения: атомарную или перечислимую, с отложенным назначением типа. Неопределенность типа может сохранятся сколь угодно долго, но при создании входящего соединителя к такому атрибуту, конструктор модели автоматически изменит Undefined Type на тип атрибута-аргумента.
К логическому типу [L] можно привести любое значение, рассматривая его со следующей точки зрения: значение фактически существует – true, или оно не инициализировано – false. Ко второму случаю также относятся такие частности как ноль для числа, и отсутствие других литералов кроме пробела для строки.
Для типа String [S] значением является последовательность литералов произвольной длины. При этом тип кодировки (ASCII или UTF) един для всей базы данных, и устанавливается при ее генерации. Но при необходимости можно создать под-домены (подтипы) для разных кодировок. На порядок хранения значения String это не влияет.
Тип Numeric [N] объединяет в себе все вещественные численные значения, рассматриваемые в десятичной системе исчисления с плавающей или фиксированной десятичной точкой. Из него выделен тип Integer [I] –- все множество целых положительных чисел, из которого в свою очередь выделен тип Date [D] – целые числа в календарной системе исчисления.
Тип Complex [C], он же User Defined Type [UDT] является абстрактным прототипом-доменом, объединяющим множество создаваемых пользователем комплексных типов значений – классов данных. Домен значений класса, включает в себя домены значений всех классов, порожденных наследованием от этого класса. В качестве значения домена, образованного классом, в равной степени могут рассматриваться как собственно производный от класса объект данных, так и указатель на него – дескриптор IDO этого объекта.
Тип External [Ex] включает в себя все множество значений, никак не интерпретируемых объектной моделью данных, и в силу этого условно считающихся значениями неопределенного типа, хранимых как непрерывная последовательность байт известной длины. Атрибут типа External реализует транзакционное присвоение, долговременное хранение и выборку таких значений, без возможности их преобразования и передачи по соединителям. Составной частью домена External является домен Image, значения которого используются в том числе в визуальном интерфейсе конструктора модели и интерфейсе приложения.
Метрика типа
Для типов Numeric [N] и Date [D], метрика определяет точность существования (хранения/представления) значения. Для типа Numeric точность представляет собой количество знаков после десятичной точки. Для типа Date точность – это количество знаков из шаблона CYMDhms, образующих итоговый шаблон атрибута, по которому выравнивается результирующее значение.
Примитивные функционалы
Как уже упоминалось, функционал – это предопределенный метод, идентифицируемый дескриптором IDF. Исходное множество функционалов включает в себя самые примитивные, но наиболее часто используемые методы формирования значений, но это множество может быть легко расширено путем добавления в него новых функционалов. Для каждого типа значений существует свой набор естественных функционалов:
— для Logical – аддитивный (логическое ИЛИ) и мультипликативный (логическое И);
— для String – аддитивный (конкатенация);
— для Numeric – аддитивный, мультипликативный, минимум, максимум;
— для Integer – аддитивный, мультипликативный, минимум, максимум;
— для Date – аддитивный (сдвиг), минимум, максимум;
— для Complex – аддитивный (присвоение), Autoset;
Все перечисленные функционалы допускают получение значения из множества источников (соединителей). Роль функционала присвоения значения из единственного источника по умолчанию играет аддитивный функционал. Для всех типов, за исключением Logical и External, существуют списковые функционалы. Отдельно стоит также кратко упомянуть интервальный функционал, который обеспечивает формирование интервальных значений, и средствами которого реализуются как внутренние зависимости значений, образующих интервал, так и операции над интервальными значениями. Логично будет предположить, что интервальное значение является комплексным, и имеет перечислимую форму.
Функционалы списка
Каждый списковый функционал представляет собой функцию-обертку, инкапсулирующую мета-список и использующую методы мета-списка, внутреннюю реализацию части из которых функционал переопределяет под собственные цели и задачи. Все семейство списковых функционалов включает в себя несколько групп.
Функционалы, создающие и изменяющие список, отождествляются с собственно списком, точнее – его функциональным типом. Помимо "простого" списка, в эту группу входят "уникальный" список (списку запрещено иметь дублирующие значения ключей), а также две его логических модификации, оперирующие численными значениями: "тотализационный" список (значения с одинаковым ключом суммируются) и его последующая модификация – "интегральный" (значения с одинаковым ключом суммируются с прибавлением значения предшествующего элемента). Эти функционалы назначаются непосредственно атрибуту в качестве его входящего функционала, тем самым делая атрибут списковым. Функционалам этой группы для формирования собственно списка необходим как минимум один входящий активный соединитель – источник ключа и значения.
Функционалы выборки, возвращающие значение из списка, всегда назначаются исходящему сокету соединителя, локализованному в кортеже спискового атрибута. Хотя при этом и имитируется «приписка» такого функционала к атрибуту-получателю. Собственно сам key-контекст (источник ключа), может быть декларирован для любого из базовых сокетов этого соединителя.
Функционалы, осуществляющие выборку значения по ключу, различаются по условию позиционирования: "равно" (точное позиционирование), "меньше" (позиционирование на логически предшествующий элемент), "больше" (аналогично, только последующий), "равно или меньше" и "равно или больше" (если не точно, то предшествующий или последующий). Если нет элемента, удовлетворяющего условию, функционал вернет эквивалент "пустого" значения. Аналогичная им подгруппа функционалов вместо значения возвращает позицию элемента – его порядковый номер в списке. Еще одна подгруппа функционалов ("первый/последний/N" – "ключ/значение") возвращает запрошенное из первого, последнего, или указанного (N) элементов списка.
Программная вставка
Отнюдь не все задачи можно решить, комбинируя примитивные функционалы. Для реализации сложных алгоритмов в свойствах атрибута предусмотрен контейнер Script, в котором можно разместить произвольный скрипт (например, на языке Python) на правах частного функционала конкретного экземпляра атрибута. Практика создания различных приложений неожиданно показала, что к этому средству приходится прибегать достаточно редко. Отметим, что в теле скрипта статического атрибута допускается использование активных методов, адресованных классу (Create) или атрибуту класса (Set или Update). Для скрипта динамического атрибута допустим только вызов метода Get.
Функциональность атрибута
Атрибут класса является экземпляром мета-атрибута. Атрибут характеризуется пользовательским наименованием (Name), уникальным в пределах собственного класса, типом значения (Type), метрикой типа (Metric), а также флагом Dynamic. Помимо этого, атрибут владеет дескриптором функционала IDF, контейнером Script, и двумя кортежами: элементов массива (Item list) и сокетов (Socket list). В кортеже собственного класса атрибут идентифицируется дескриптором IDA.
В модели данных атрибут выполняет функцию фабрики значений, и с этой точки зрения является центральным действующим лицом вычислительной среды объектного управления данными. Для выполнения операций над значениями атрибут использует методы Set, Get и Update, а также набор типозависимых функционалов.
Атрибуты, связанные между собой соединителями, образуют топологию, чем-то напоминающую топологию нейросети. Вспомним отправную точку – предметная область рассматривается как система взаимодействующих значений. Соответственно, идеальная аппаратная платформа для такой сети выглядит как множество независимых примитивных процессоров, взаимно связанных последовательными каналами. В такой аппаратной среде можно моделировать самые различные процессы.
Служебные атрибуты
Служебные атрибуты перманентно присутствуют в кортеже любого класса, где занимают строго фиксированные позиции. Эти атрибуты используются моделью данных для решения ее собственных задач. Так упомянутые ранее атрибуты Del и Own, обеспечивают реализацию симметричной связи объектов классов. Еще один, не упомянутый ранее, служебный атрибут – Type, в объекте класса хранит структурный тип объекта – дескриптор IDC класса-фабрики.
Функциональность класса
Класс данных является экземпляром мета-класса независимо от того, каким способом этот экземпляр был получен. Класс характеризуется пользовательским наименованием (Name), уникальным в полном множестве классов, визуальным образом (Image), а также кортежем атрибутов (Attribute list). В полном множестве классов отдельный класс идентифицируется дескриптором IDC. Если класс был создан наследованием от другого класса-предка, то в свойстве Parent класс хранит IDC класса-предка.
В вычислительной среде объектного управления класс выполняет функцию фабрики объектов, используя для этого метод мета-класса Create. Объект класса создается как экземпляр кортежа атрибутов класса.
Удаление объекта не является прерогативой класса. Объект логически удаляется инициализацией значения служебного атрибута Del, который, в целях обеспечения логической целостности, автоматически присутствует во всех внешних соединителях в качестве lock-контекста. Инициализация Del влечет за собой де-инициализацию всех действующих связей объекта, переводя объект в изолированное состояние. Впоследствии, логически изолированный объект будет удален физически сборщиком мусора.
Наследование классов
Класс данных может быть создан не только как экземпляр мета-класса, но и наследованием от другого класса. Предметом наследования является полный кортеж атрибутов класса-предка, который перманентно присутствует в кортеже атрибутов класса-наследника. Это позволяет классу-предку включить в свой домен все без исключения объекты, порожденные как прямыми, так и опосредствованными его наследниками, независимо от глубины наследования. Унаследованный кортеж является естественным интерфейсом ко всем объектам в домене класса-предка.
Механизм реализации наследования кортежа атрибутов исключительно прост: в классе-наследнике создается экземпляр (!) кортежа атрибутов предка. Этот экземпляр по определению не содержит значений, так как необходимости дублировать декларации атрибутов нет – требуемые декларации можно получить, обратившись к кортежу класса-предка. Класс-наследник сформирует у себя полную декларацию атрибута только в том случае, если внесет в нее свои частные изменения, или если создаст новый собственный атрибут. Когда новый атрибут создается в классе-предке, то, предварительно, в полном множестве его наследников определяется максимальный размер кортежа атрибутов, после чего создаваемому атрибуту выделяется элемент в кортеже предка за пределами этого размера. Тем самым новый атрибут предка автоматически становится доступен всем его наследникам. Образующимися при этом в кортежах не инициализированными элементами можно пренебречь, так как места они практически не занимают.
Полиморфизм наследников реализуется переопределением правил получения значения для унаследованных атрибутов, с сохранением их типа. При этом запрещено изменять унаследованные соединители, которые, при необходимости, следует де-активировать и создать новые.
Забегая вперед стоит упомянуть, что пользовательский класс данных, являясь комплексной сущностью, обладает множеством форм его интерфейсного (и в том числе визуального) представления. Класс-потомок в полной мере наследует формы представления предка, с возможностью их переопределения. Естественное сочетание полиморфизма с "полиформизмом" является мощным инструментом разработки приложения.
Базовый атрибут и прототипы классов
В общей массе атрибутов класса всегда можно выделить такой, значение которого используется для пользовательской идентификации конкретного объекта этого класса, как например атрибут Наименование в классе Контрагент. Такой атрибут выполняет функцию базового атрибута класса.
Логично предположить, что именно базовый атрибут должен автоматически использоваться в качестве key-контекста для любого соединителя к списковому функционалу, включая списки обратных ссылок. Для этого базовый атрибут должен иметь фиксированную позицию в кортеже любого класса, а именно – размещаться сразу после служебных атрибутов.
Из всех существующих типов значений только два типа – String и Date, могут быть осмысленно назначены базовому атрибуту при его создании. Эти два варианта типизации и предопределяют существование двух классов-прототипов: Именованного класса и класса-События, с соответствующими базовыми атрибутами.
Классы-прототипы удобно использовать в качестве шаблонов при создании разработчиком пользовательских классов, что не только представляется логичным, но и дает небольшой выигрыш: создаваемый класс сразу включает в себя базовый атрибут нужного типа с необходимым наименованием.
Конструктор модели
Уже неоднократно проверено – обычную программу мышкой не создашь. В случае же использования модели приложения/данных все строго наоборот: текстовая нотация выглядит как унылое, мало информативное перечисление деклараций. Зато в визуальной среде те же самые декларации выглядят естественно и весьма наглядно: есть отображаемое целиком или частично общее пространство связанных отношениями классов, а переход в визуальное пространство класса открывает множество его атрибутов с их связями. Впрочем, принципы интерфейсного представления и механизмы его реализации – это тоже тема для отдельной статьи.
Исполнительная модель данных создается и изменяется через свою форму представления – модель приложения. В качестве редактора этой модели выступает визуальный конструктор, оперирующий образами сущностей модели. Переход из пользовательского интерфейса приложения в визуальную среду конструктора и возврат обратно, в среду исполнения приложения с сохранением текущего состояния интерфейса, осуществляется одномоментно горячей клавишей. При этом все сделанные конструктором изменения вступают в силу немедленно. Если что-то сделано не так, то это станет очевидно сразу: в виде ошибочного результата или отсутствия реакции на интерфейсное событие, без прерывания работы приложения.
Конструктор создает новые компоненты модели как декларативные экземпляры мета-сущностей, при этом полностью скрывая реальные дескрипторы производных экземпляров. Исходный набор базисных мета-сущностей невелик, что позволяет легко контролировать логическую непротиворечивость вновь создаваемых деклараций уже существующим в модели путем простого исключения из доступа конфликтующего инструмента редактора или конструкционного компонента.
Действующая модель данных представляет собой простую декларацию вида сущность-свойство, а значит может быть экспортирована в текстовый формат: XML, JSON, или в форме последовательности транзакций по созданию ее компонент. В текстовое представление внутренние дескрипторы не экспортируются, вместо них используются пользовательские наименования классов и атрибутов.
Область применения
Модель данных описывает информационную систему, обладающую состояниями. Соответственно, ее невозможно использовать для реализации драйвера, например.
Также с ее помощью невозможно реализовать отдельный алгоритм или подпрограмму – модель данных описывает предметную область только целиком.
По соображениям производительности (из-за отсутствия соответствующих аппаратных средств) модель данных невозможно использовать для прямого моделирования физических процессов в реальном времени. Хотя такой потенциал есть.
Представляются лишенными смысла попытки создать универсальную модель «всего на свете». Прикладная программа всегда отражает предметную область только со строго определенной точки зрения и в определенных границах. И для другой точки зрения та же самая предметная область может выглядеть уже иначе.
Во всем остальном вычислительная среда на основе модели данных предназначена для решения тех же самых задач, которые решаются на основе всех прочих баз данных. Но при этом отличается некоторыми полезными свойствами.
Согласитесь, визуальная модель приложения дает более наглядное восприятие бизнес-логики.
Ссылочная симметрия позволяет использовать всю мощь методов естественной навигации, как в данных, так и в мета-данных.
Исполнительная модель данных, образующая приложение, – это всего лишь хранимая в базе данных декларация, абсолютно не зависящая ни от архитектуры процессора, ни от операционной системы.
Скорость разработки, алгоритмическая надежность, строгая ссылочная целостность, перманентная согласованность, – все это есть прямое следствие интеграции бизнес-логики непосредственно в логическую структуру базы данных. И при этом коренным образом меняется подход к реализации интерфейса приложения, что подлежит отдельному подробному рассмотрению.
Резюме
Природа демонстрирует нам свое бесконечное разнообразие, полученное бесконечным же комбинированием элементов в общем-то совсем крохотного базисного набора (кивок в сторону ДНК). Это ее самый любимый прием.
Всего четыре абстрактных сущности образуют базис, которого достаточно, чтобы информационно описать любую предметную область. Декларативных экземпляров всего трех мета-сущностей вполне достаточно, чтобы это описание формализовать в виде модели данных. И, в вычислительной среде объектного представления, образованной шестью исполнительными методами мета-сущностей, модель будет вести себя как программа, давая требуемый результат.
Все выше изложенное – всего лишь дальнейшее развитие реляционной модели Э.Ф.Кодда, а также идей К.Дейта по объединению реляционных и объектных технологий. Суть реляционной модели осталась прежней: таблицы, колонки, связь таблиц. В нее просто добавили столь естественный, но почему-то не упомянутый Коддом четвертый элемент – связь колонок в таблицах.
