Comments 15
Для меня, одним из обязательных требований, к "чистой" архитектуре, является грамотное разделение кода приложения по слоям.
Я бы сказал что разделение на контексты намного важнее, поскольку каждый контекст может иметь свой набор слоев, свои подходы и свои ограничения, которые дают в итоге оптимальное соотношение сложности реализации и гибкости.
Грамотная спроектирвоанная система слоёв, невероятно упрощает тестирование.
Упрощает тестирование снижение связанности системы. Если мы берем распространенные подходы, которые можно увидеть в 4/5 проектов, то слои там мало чем помогают.
Лично я никогда не встречал код-лазанью, зато видел очень много лапшекода.
А я встречал, и довольно часто. Особенно когда разработчики начинают загоняться по слоям, именно начинают (я и сам так делал). Это когда для внесения простых изменений приходится "прорезать" все слои. Пример — вывести новое поле на UI когда затрагиваются буквально все слои. Это простой способ проверить уровень связанности слоев между собой. В целом если разделение на слои не позволяет вам получить ту самую гибкость — стоит пересмотреть подход.
У Матиаса есть статья на тему лазанья кода, но она ничего на самом деле не объясняет (единственная полезная фраза — это на тему постоянного пересмотра правил и ограничений).
они и дают возможность создавать чистые доменные модели
Следует конкретизировать что речь идет исключительно о persistence ignorance и устранении влияния инфраструктуры, хранилища данных, на вашу доменную модель. И как бы мы не обмазывались в слоеном, ограничения реляционных СУБД на то как происходит проектирование модели данных это никак не снимает. То есть опять же слои тут второстепенная штука. Конечно же выделение каких-то слоев подразумевается но вся соль в "каких-то", то есть важна конкретика.
Тесты для доменной модели должны быть исключительно модульными
Было бы неплохо приводить ссылки на конкретное определение "модульных тестов" ибо их множество. Лично я предпочитаю называть их "изолированными" поскольку так проще объяснять почему тот или иной тест не является изолированным (с модульными путаница выходит, ибо модули есть, а тот факт что мы зависимости не подменили как-то мелочь)
директории для каждого из агрегата(Aggregate root)
У меня вопрос на кого рассчитана эта статья… Те кто знают что такое агрегаты и могут спокойно их выделять, находить корни агрегатов и делать грамотную декомпозицию врядли нуждаются в подобных статьях где рассказываются какие-то уж совсем примитивные вещи. Мне наверное этим и не нравятся статьи Матиаса. Он из сложного вопроса часто берет самое простое.
Прикладной слой
существуют варианты при которых этот слой можно даже не вводить. Правда альтернатива — больше про event-driven подходы и многих это пугает.
надо покрывать интеграционными тестами
Но это не точно. В целом весь этот слой уже должен затрагиваться приемочными e2e сценариями. Хотя на некоторые вещи конечно написать интеграционные тесты стоит (интеграция с вещами которыми владеете не вы, сторонние сервисы и т.д.).
Все фреймворки и бибилотеки взаимодействующие с внешнем миром(файловой системой, сетью или базой) должны вызываться в инфраструктурном слое.
стоит так же помнить о таком чудестном правиле как "принцип стабильных зависимостей". Например если мы подключили библиотеку Money и считаем ее стабильнее нашего кода (то есть с бухты барахты она не поменяется) — нет никаких проблем с тем что бы использовать эту библиотеку в нашем слое с бизнес логикой. Как никак, стандартная библиотека это тоже зависимость, но мы почему-то не паримся когда на нее завязываемся.
То есть основная мысль — направление зависимости должно быть направлено от менее стабильных к более стабильным компонентам (стабильность тут выражается в том как часто меняется интерфейс в силу изменений требований).
Практическая реализация в большинстве ооп языков заключается в выделинии публичного интерфейса для всех вещей, от которых вы можете зависеть
опущен очень важный момент — кому принадлежит интерфейс. Интерфейс не должен принадлежать модулю, который имплементит этот интерфейс. Либо ложим интерфейс там где его потребляем, либо в какой-то промежуточный модуль. Именно так появляется инверсия зависимостей.
Большинство же воспринимают DIP как "лепим интерфейсе для всего подряд". Даже если не подразумевается более одной имплементации. Да и если разработчики не особо заморачиваются с такими вещами как контракты (а в случае с php можно лишь очень скупо описать контракт за счет языковых средств), то это просто может превратиться в бездумный культ карго.
Намного интереснее форсить мысль о том что в целом зависимости это не очень хорошо и нужно прилагать немало усилий что бы от них избавляться. Это и с тестированием намного больше помогает и вообще позволяет чуть по другому на проблемы смотреть.
Можно много эксперементировать, прежде чем принимать такие важные решения, как, к примеру «используемая СУБД»
для этого надо не бояться не юзать ORM когда придется. Большинство по какой-то причине к этому не готовы. Да и популярные решения этому не способствуют… Хотя такой опыт, как по мне, должен быть у каждого разработчика, просто что бы знать какие плюсы и минусы какой подход в себе несет.
Можно отложить решение об используемом фреймворке.
возвращаясь к тому на кого нацелена эта статья… ума не приложу просто.
Также можно ознакомиться с Deptrac — инструмент, помогающий соблюдать правила использования слоев и зависиомостей.
Deptrac отличный интерфейс, но с ним можно мухлевать. Он все же не очень догадливый в плане используемых типов.
У меня есть опыт написания плагинов для phan (можно и под phpstan) который анализирует что где юзается. За счет того что эти решения намного более качественно определяют типы, то и уровень контроля можно вводить неплохо.
Прикладной слой
… ответственен за все необходимые взаимодействия — использует данные из команды для создания(или извлечения из базы) агрегата, выполняет над ним какие то операции, может сохранить агрегат после этого.
Серьезно? Модели в контроллерах сохраняются?
Если не цитировать полностью, то посыл был сохранять в слое Домена.
Application Layer
This is a thin layer which coordinates the application
activity. It does not contain business logic. It does not
hold the state of the business objects, but it can hold
the state of an application task progress.
Сама последовательность слоев вводит в ступор
Слой 1 — Домен(модель/ядро)
Слой 2 — (обёртка для домена): Прикладной слой
Слой 3(обертка для прикладного) — Инфраструктура
Не припомню ни одного описания схемы Infrastructure->Application->Domain.
Классика из книжки Presentation->Application->Domain->Infrastructure:
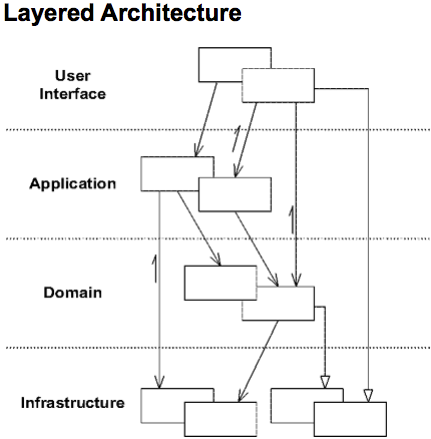
Надеюсь в Описании инфраструктурного слоя
Работы с HTTP
Имеются ввиду все же библиотеки curl/Guzzle, и речь не о контроллерах.
Пишу это чтобы акцентировать внимание, т.к. по тексту это не ясно, но это очень важно для понимания.
Серьезно? Модели в контроллерах сохраняются?
это не контроллеры, это сервисы уровня приложения. Можете еще раз перечитать в чем отличие. Это имплементация юзкейса если хотите. И это именно та штука которая знает границу бизнес транзакции и, как следствие, знает когда надо коммитить транзакцию.
то посыл был сохранять в слое Домена.
нет, слой домена ничего не знает о хранении данных, максимум там есть интерфейсы сервисов которые уже занимаются этим делом и лежат в слое инфраструктуры. Но опять же domain layer не обязан знать границы бизнес транзакций. Но может (не зря ж мы агрегаты делаем), но как я говорил в таком случае штуки типа "отправить email-ы" надо переводить на какие-то более высокие материи вроде доменных ивентов. К этому не все готовы.
Имеются ввиду все же библиотеки curl/Guzzle, и речь не о контроллерах.
в статье не предлагается выделять отдельный ui layer поскольку он является частью инфраструктуры. "порты и адаптеры" в заголовке как бы намекают, хотя статья этот вопрос вообще не раскрывает. Вы можете разделять слой инфраструктуры и выделять там и UI layer, и DAL и т.д. но это уже вам решать. Опять же если сразу идти по пути полного разделения то будем есть лазанью.
В целом достаточно только двух слоев, намного важнее направление зависимостей между ними соблюдать.
«порты и адаптеры» в заголовке как бы намекают, хотя статья этот вопрос вообще не раскрываетеще есть 3 часть, она целиком про порты и адаптеры
это не контроллеры, это сервисы уровня приложения. И это именно та штука которая знает границу бизнес транзакции и, как следствие, знает когда надо коммитить транзакцию.
Спасибо за перевод с русского на русский. Теперь понял о чем шла речь. Со сложной бизнес логикой приходилось разделять «доменные сервисы» и «сервисы уровня приложения», но как то иерархически их не выделял. С одной стороны логично, с другой есть риск запутаться окончательно и запутать других.
в статье не предлагается выделять отдельный ui layer поскольку он является частью инфраструктуры.
Вот это не очень понятно. На картинке UI и Infrastructure в разных концах. Я разделяю это так: UI — то, что сделало запрос приложению (это интерфейс/вызов апи, консольные команды, какие то хуки), и Infrastructure — все внешние системы, взаимодействие с которыми инициировало уже приложение.
есть риск запутаться окончательно и запутать других.
когда я применял подобное для команды существовали простое ограничение: в сервисах уровня приложения должна отсутствовать логика (никаких if-ов или циклов с условиями, никаких исключений). Вся логика делигируется на уровень ниже.
У такого подхода есть масса плюсов и минусов. Основной плюс — можно почитать в одном месте что происходит при какой-то операции. Кому email-ы отправлюятся, ну и все смежные вещи. Но так или иначе минусы тоже не маленькие. Скажем, если вам надо поменять тригер для отправки нотификаций — придется убирать в одном месте и добавлять в другом.
Последний год я больше использую event driven подходы. Я как бы теряю возможность быстро глянуть что происходит в одной конкретной операции (хотя логирование позволяет всю картинку восстановить + есть мысли на счет того что бы генерить полную картину из кода, но пока в зачаточном виде), но зато очень легко можно менять местами какие-то элементы операций, делать цепочки операций (почти саги) и в целом с таким подходом код упрощается. Но я подозреваю что такой подход будет комфортен не всем.
Вот это не очень понятно. На картинке UI и Infrastructure в разных концах.
вы можете воспринимать инфраструктуру как оболочку приложения, леса своеобразные. То есть да, UI и скажем доступ в базу — это разные цонцы, но если представить это все как луковицу, то это окажется один и тот же слой.
Серьезно? Модели в контроллерах сохраняются?Нет, это не контроллер. Это, к примеру, сервисы, которые вызываются из контроллера или обработчики команд, сформированных в контроллере из внешнего запроса.Например, метод репозитория `save` я вызываю именно в этом слое. Да и в статье говорится как раз об этом: It then often persists the aggregate
Если не цитировать полностью, то посыл был сохранять в слое Домена.
Не припомню ни одного описания схемы Infrastructure->Application->Domain.Картинка хорошая и правильная, но она не противоречит тому что написано в статье. Просто в ней слой Presentation(обозначен как UI, но по факту это может быть вызов из консоли, запуск воркера, вызов API и т.д) выделен отдельно от Infrastructure, это более популярный подход я тоже так делаю, однако в статье он почему то не выделяется как отдельный. Но по факту — это тоже взаимодействие с внешним миром, так что можно отнести это к инфраструктуре, принципиальной ошибки нет.
Классика из книжки Presentation->Application->Domain->Infrastructure
Имеются ввиду все же библиотеки curl/Guzzle, и речь не о контроллерах..Если не выделять Pressentation от Infrastructure, то получится что в Infrastructure будет и то и другое. А если делать такое разделение, то получится так как вы и сказали, всё верно.
Немного забыл за это время где показано что Infrastructure знает о Presentation?
Схаматически, все что в одном слое/кольце может взаимодействовать друг с другом.
Matthias Noback Об Идеальной Архитектуре — Слои, Порты и Адаптеры(Часть 2 — Слои)