На примере «JEP 110: HTTP/2 Client» (который в будущем появится в JDK) Сергей Куксенко из Oracle показывает, как команда его запускала, где смотрела и что крутила, чтобы сделать его быстрее.
Предлагаем вам расшифровку его доклада с JPoint 2017. В целом речь тут пойдет не про HTTP/2. Хотя, конечно, без ряда деталей по нему обойтись не удастся.
HTTP 2 — это новый стандарт, призванный заменить устаревший HTTP 1.1. Чем отличается реализация HTTP 2 от предыдущей версии с точки зрения производительности?
Ключевая вещь HTTP 2 — то, что у нас устанавливается одно единственное TCP-соединение. Потоки данных режутся на фреймы, и все эти фреймы отправляются через это соединение.
Также предусмотрен отдельный стандарт сжатия заголовков — RFC 7541 (HPACK). Он очень хорошо работает: позволяет ужать до 20 байт HTTP-шный header размером порядка килобайта. Для некоторых наших оптимизаций это важно.
В целом в новой версии есть много интересного — приоретизация запросов, server push (когда сервер сам посылает данные клиенту) и прочее. Однако в рамках этого повествования (с точки зрения производительности) это не важно. Кроме того, многие вещи остались прежними. Например, как выглядит протокол HTTP сверху: у нас те же методы GET и POST, те же значения полей заголовка HTTP, коды статуса и структура «запрос -> ответ -> финальный ответ». На самом деле если приглядеться, HTTP 2 — это всего навсего низкоуровневая транспортная подложка под HTTP 1.1, которая убирает его недостатки.
У нас есть проект HttpClient, который называется JEP 110. Он почти включен в JDK 9. Изначально этот клиент хотели сделать частью стандарта JDK 9, но возникли некоторые споры на уровне реализации API. И поскольку мы не успеваем к выходу JDK 9 финализировать HTTP API, решили сделать так, чтобы можно было его показать сообществу и обсудить.
В JDK 9 появляется новый модуль инкубатор (Incubator Modules a.k.a. JEP-11). Это песочница, куда с целью получения фидбека от комьюнити будут складываться новые API, которые еще не стандартизированы, но, по определению инкубатора, будут стандартизированы к следующей версии или убраны вообще («The incubation lifetime of an API is limited: It is expected that the API will either be standardized or otherwise made final in the next release, or else removed»). Все, кому интересно, могут ознакомиться с API и прислать свой фидбек. Возможно, к следующей версии — JDK 10 — где он станет стандартом, все будет исправлено.
HttpClient — первый модуль в инкубаторе. Впоследствии в инкубаторе будут появляться прочие вещи, связанные с клиентом.
Расскажу буквально на паре примеров про API (это именно клиентский API, который позволяет делать запрос). Основные классы:
Вот таким простым образом можно построить запрос:
Здесь мы указываем URL, задаем header и т.п. — получаем запрос.
Как можно послать запрос? Для клиента есть два вида API. Первый — синхронный запрос, когда мы блокируемся в месте этого вызова.
Запрос ушел, мы получили ответ, проинтерпретировали его как
Второй — асинхронный API, когда мы не хотим блокироваться в данном месте и, посылая асинхронный запрос, продолжаем выполнение, а с полученным CompletableFuture потом можем делать все, что захотим:
Клиенту можно задать тысячу и один конфигурационный параметр, по-разному сконфигурировать:
Основная фишка еще здесь в том, что клиентский API — универсальный. Он работает как со старым HTTP 1.1, так и с HTTP 2 без различения деталей. Для клиента можно указать работу по умолчанию со стандартом HTTP 2. Этот же параметр можно указать для каждого отдельного запроса.
Итак, у нас есть Java-библиотека — отдельный модуль, который базируется на стандартных классах JDK, и который нам надо оптимизировать (провести некую перформансную работу). Формально задача перформанса состоит в следующем: мы должны получить разумную производительность клиента за приемлемые затраты времени инженера.
С чего мы можем начать эту работу?
Начнем с бенчмаркинга. Вдруг там все и так хорошо — не придется читать спецификацию.
Написали бенчмарк. Хорошо, если у нас для сравнения есть какой-нибудь конкурент. Я в качестве клиента-конкурента взял Jetty Client. Сбоку прикрутил Jetty Server — просто потому, что мне хотелось, чтобы сервер был на Java. Написал GET и POST запросы разных размеров.

Возникает, естественно, вопрос — что мы меряем: throughput, latency (минимальный, средний). В ходе дискуссии мы решили, что это не сервер, а клиент. Это значит, что учет минимальных latency, gc-пауз и всего прочего в данном контексте не важен. Поэтому конкретно для этой работы мы решили ограничиться измерением общего throughput системы. Наша задача — его повысить.
Общий throughput системы — это обратная величина к среднему latency. То есть мы работали над средним latency, но при этом не напрягались с каждым отдельным запросом. Просто потому, что у клиента не такие требования, как у сервера.
Запускаем GET на 1 байт. Железо выписано. Получаем:

Я беру этот же бенчмарк для HTTPClient, запускаю на других операционных системах и железе (это уже более-менее серверные машинки). Получаю:

В Win64 все выглядит получше. Но даже в MacOS все не так плохо, как в Linux.
Проблема здесь:
Это открытие SocketChannel для соединения с сервером. Проблема заключается в отсутствии одной строки (я ее выделил в коде ниже):
В принципе, в интернете существует масса объяснений, как эти два алгоритма конфликтуют и почему они создают такую проблему. Я привожу ссылку на одну статью, которая мне понравилась: TCP Performance problems caused by interaction between Nagle’s Algorithm and Delayed ACK
Детальное описание этой проблемы — за рамками нашего разговора.
После того, как была добавлена единственная строчка с включением

Я не буду считать, сколько это в процентах.
Мораль: это не Java-проблема, это проблема TCP-стека и вопросов его конфигурации. Для многих областей существуют общеизвестные косяки. Настолько общеизвестные, что люди про них забывают. Про них желательно просто знать. Если вы новичок в этой области, вы легко нагуглите основные косяки, которые существуют. Проверить их можно очень быстро и без всяких проблем.
Необходимо знать (и не забывать) список общеизвестных косяков для вашей предметной области.
У нас есть первое изменение, и мне даже не пришлось читать спецификацию. Получилось 9600 запросов в секунду, но помним, что Jetty дает 11 тыс. Дальше профилируем при помощи любого профайлера.
Вот что я получил:

А это отфильтрованный вариант:

Мой бенчмарк занимает 93% времени CPU.
Посылка реквеста на сервер занимает 37%. Далее идет всякая внутренняя детализация, работа с фреймами, а в конце 19% — это запись в наш SocketChannel. Передаем данные и header запроса, как должно быть в HTTP. А потом мы читаем —
Далее мы должны прочитать пришедшие нам с сервера данные. Что же тогда это?
Если инженеры правильно назвали методы, а я им доверяю, то здесь они что-то отсылают на сервер, причем это требует столько же времени, сколько сама отправка наших запросов. Зачем при чтении ответа сервера мы что-то посылаем?
Чтобы ответить на этот вопрос, мне пришлось прочитать спецификацию.
Вообще очень много перформансных проблем решаются без знания спецификации. Где-то надо заменить
Но в нашем случае проблема действительно обнаружилась в спецификации: в стандарте HTTP 2 есть так называемый flow-control. Работает он следующим образом. У нас есть два пира: один посылает данные, другой — получает. У посылателя (отправителя) есть окошко — flow-control window размером в некоторое количество байт (предположим, 16 КБ).

Допустим, мы послали 8 КБ. Flow-control window уменьшается на эти 8 КБ.
После того как мы послали еще 8 КБ, flow-control window стало 0 КБ.

По стандарту в такой ситуации мы не имеем права ничего посылать. Если мы попробуем послать какие-то данные, получатель будет обязан интерпретировать эту ситуацию как ошибку протокола и закрыть connection. Это некая защита от DDOS-ов в ряде случаев, чтобы нам не посылали ничего лишнего, а посылатель подстраивался под пропускную способность получателя.
Когда получатель обработал принятые данные, он должен был послать специальный выделенный сигнал под названием WindowUpdate с указанием, на сколько байт увеличить flow-control window.

Когда WindowUpdate приходит посылателю, у него flow-control window увеличивается, мы можем посылать данные дальше.
Что у нас происходит в клиенте?
Мы получили данные с сервера — вот реальный кусок обработки:
Пришел некий
На самом деле в каждом таком месте работает два flow-control window. У нас есть flow-control window конкретно к этому потоку передачи данных (запросу), а также есть общий flow control window для всего connection. Поэтому мы должны послать два запроса WindowUpdate.
Как оптимизировать данную ситуацию?
Первое. В конце
Это маленькая оптимизация: если мы поймали флажок конца стрима, то для этого стрима WindowUpdate можем уже не посылать: мы уже не ждем никаких данных, сервер ничего не будет посылать.
Второе. Кто сказал, что мы должны посылать WindowUpdate каждый раз? Почему мы не можем, получив много реквестов, обработать пришедшие данные и только потом послать WindowUpdate пачкой на все пришедшие запросы?
Вот
У нас есть некий
Для запроса в 1 байт получаем:

Эффект будет даже для мегабайтных запросов, где много фреймов. Но он, естественно, не настолько заметен. На практике у меня были разные бенчмарки, запросы разного объема. Но здесь для каждого кейса я не стал рисовать графики, а подобрал простые примеры. Выжимка более подробных данных будет чуть позже.
Мы получили всего +23%, но Jetty уже обогнали.
Мораль: аккуратное чтение спецификации и логика — ваши друзья.
Здесь есть некий нюанс спецификации. Там с одной стороны сказано, что, получив дата-фрейм, мы должны отослать WindowUpdate. Но, внимательно прочитав спецификацию, мы увидим: там нет требования, что мы обязаны отсылать WindowUpdate на каждый полученный байт. Поэтому спецификация допускает такое пакетное обновления flow-control window.
Давайте изучим, как мы скалируемся (масштабируемся).
Для скалирования ноутбук не очень подходит — у него всего два настоящих и два фейковых ядра. Мы возьмем какую-нибудь серверную машину, в которой 48 хардварных тредов, и запустим бенчмарк.
Здесь по горизонтали — количество потоков, а по вертикали показан общий throughput.

Здесь видно, что до четырех тредов мы скалируемся очень хорошо. Но дальше скалируемость становится очень плохой.
Казалось бы, зачем это нам? У нас один клиент; мы из одного треда получим необходимые данные с сервера и забудем об этом. Но во-первых, у нас есть асинхронная версия API. К ней мы еще придем. Там наверняка будут какие-то треды. Во-вторых, в нашем мире сейчас кругом все многоядерное, и иметь возможность хорошо работать с многими тредами в нашей библиотеке — просто полезно — хотя бы потому, что когда кто-то начнет жаловаться на производительность однопоточной версии, ему можно будет посоветовать перейти на многопоточную и получить бенефит. Поэтому давайте искать виновного в плохой скалируемости. Я обычно делаю это так:
Я просто пишу стектрейсы в файл. В реальности этого мне хватает в 90% случаев, когда я работаю с блокировками без всяких профилеровщиков. Только в каких-то сложных трюковых кейсах я запускаю Mission control или что-то еще и смотрю распределение блокировок.
В логе можно посмотреть, в каком состоянии у меня различные треды:

Здесь нас интересуют именно блокировки, а не waiting, когда мы ожидаем событий. Блокировок 30 тыс. штук, что достаточно много на фоне 200 тыс. runnable.
А вот такая командная строчка нам просто покажет виновного (ничего дополнительно не нужно — только command line):

Виновник пойман. Это метод внутри нашей библиотеки, который посылает фрейм данных на сервер. Давайте разбираться.
Тут у нас глобальный монитор:

А вот эта ветка —
— начало инициирования запроса. Это отправление самого первого header на сервер (тут требуются некоторые дополнительные действия, я сейчас о них еще буду рассказывать).
Это отправка на сервер всех остальных фреймов:

Все это под global lock!
Сам

Но вот этот метод занимает 1%:

Попытаемся понять, что можно вынести из-под глобальной блокировки.
Регистрация нового стрима из-под блокировки вынесена быть не может. Стандарт HTTP накладывает ограничение на нумерацию стримов. В
Вторая проблема, которая не выносится из-под блокировки:
Здесь происходит сжатие заголовка.
В обычном виде у нас заголовок приставлен обычной мапой — ключ-значение (из стринга в стринг). В
Метод

Ничто не мешает нам вынести из под блокировки

Здесь есть некоторые нюансы реализации.
Так оказалось, что
Если мы попробуем вынести из-под блокировки
Сделаем первое, что приходит в голову, — очередь Queue. Будем класть байт-буфера в эту очередь в правильном порядке, и пусть другой тред из нее читает.
В этом случае метод
Итак, мы убрали одну из самых тяжелых операций наружу и запустили дополнительный тред. Размер критической секции стал меньше на 60%.
Но у реализации есть и минусы:
Давайте решим первую проблему, связанную с порядком фреймов.
Вполне очевидная идея —
У нас есть неразрывный кусочек байт-буферов, который нельзя перемешивать ни с чем; мы сложим его в массив, а сам массив — в очередь. Тогда эти массивы между собой перемешивать можно, а там, где нам требуется фиксированный порядок, мы его обеспечиваем:
Плюсы:
Но и здесь остался еще один минус. По-прежнему отсылающий поток часто засыпает и долго просыпается.
Давайте сделаем так:

У нас будет немного своя очередь. В нее мы складываем полученные массивы байт-буферов. После этого между всеми тредами, которые вышли из-под блокировки, устроим соревнование. Кто победил, тот пусть в сокет и пишет. А остальные пусть работают дальше.
Надо отметить, что в методе
Каждая из трех представленных оптимизаций позволяла очень хорошо снимать проблему со скалированием. Примерно вот так (отражен общий эффект):

Мораль: Блокировки — зло!
Все знают, что от блокировок нужно избавляться. Тем более что concurrent-библиотека становится все более продвинутой и интересной.
В теории у нас есть HTTP Client, рассчитанный под 100% использование ByteBufferPool. Но на практике… Тут же баги, здесь — что-то упало, там — фрейм недоработался… А если ByteBuffer в пул обратно не вернул, функционал не сломался… В общем инженерам оказалось некогда с этим разбираться. И у нас получилась недоделанная версия, заточенная на пулы. Имеем (и плачем):
Мы получаем все минусы работы с пулами, а заодно — все минусы работы без пулов. Плюсов в этой версии нет. Нам надо двигаться вперед: или сделать нормальный полноценный пул, чтобы все ByteBuffer в него возвращались после использования, или вообще выпилить пулы, но при этом они у нас есть даже в public API.
Что люди думают про пулы? Вот что можно услышать:
Прежде чем вернемся к вопросу пулов, нам нужно решить подвопрос — что мы используем в рамках нашей задачи с HTTPClient: DirectByteBuffer или HeapByteBuffer?
Сначала изучаем вопрос теоретически:
Действительно, для передачи данных в сокет DirectByteBuffer лучше. Потому что если мы по цепочке Write-ов дойдем до nio, мы увидим код, где из HeapByteBuffer все копируется во внутренние DirectByteBuffer-а. И если у нас пришел DirectByteBuffer, мы ничего не копируем.
Но у нас есть и другая штука — SSL-соединение. Сам стандарт HTTP 2 позволяет работать как с plain connection, так и с SSL connection, но декларируется, что SSL должен быть стандартом де-факто для нового веба. Если точно так же проследить цепочку того, как это реализовано в OpenJDK, выясняется, что теоретически SSLEngine лучше работает с HeapByteBuffer, потому что он может достучаться до массива byte[] и там энкриптить. А в случае с DirectByteBuffer он должен сначала скопировать сюда, а потом обратно.
А измерения показывают, что HeapByteBuffer всегда быстрее:
Т.е. HeapByteBuffer — наш выбор!
Как ни странно, чтение и копирование из DirectByteBuffer дороже, потому что там остаются чеки. Код там не очень хорошо векторизуется, поскольку работает через unsafe. А в HeapByteBuffer — intrinsic (даже не векторизация). И скоро он будет работать еще лучше.
Поэтому даже если бы HeapByteBuffer был на 2-3% медленнее, чем DirectByteBuffer, возможно, не имело бы смысла заниматься DirectByteBuffer. Так давайте избавимся от проблемы.
Сделаем различные варианты.
Плюсы варианта 1:
Минусы:
GC сделает всю работу, тем более у нас не DirectByteBuffer, а HeapByteBuffer.
Плюсы:
Но две проблемы:
Ради эксперимента делаем смешанный вариант. Про него я расскажу немного подробнее. Здесь выбираем подход в зависимости от данных.
Исходящие данные:
Входящие данные:
В целом в стандарте HTTP 2 есть девять видов фреймов. Если пришли восемь из них (все, кроме данных), то мы байт-буфера там же декодируем и нам ничего из него копировать не надо, и мы возвращаем байт-буфера обратно в пул. А если пришли данные, мы выполняем slice, чтобы не надо было ничего копировать, а потом просто его бросаем — он будет собираться GC.
Ну и отдельный пул для зашифрованных буферов SSL-соединения, потому что там свой размер.
Плюсы смешанного варианта:
Минус — один: выше «allocation pressure».
Мы сделали три варианта, проверили, поправили баги, добились функциональной работы. Измеряем. Смотрим аллокации данных. У меня было 32 сценария измерений, но я не хотел здесь рисовать 32 графика. Я покажу просто усредненный по всем измерениям диапазон. Здесь baseline — первоначальный недоделанный код (я его взял за 100%). Мы измеряли изменение allocation rate по отношению к baseline в каждой из трех модификаций.

Вариант, где все идет в пул, предсказуемо аллоцирует меньше. Вариант, не требующий никаких пулов, аллоцирует в восемь раз больше памяти, чем вариант без пулов. Но так ли нам нужна память для allocation rate? Померяем GC-паузу:

С такими GC-паузами на allocation rate это не влияет.
Видно, что первый вариант (в пул по максимуму) дает 25% ускорения. Отсутствие пулов по максимуму дает 27% ускорения, а смешанный вариант дает по максимуму 36% ускорения. Любой правильно доделанный вариант уже дает увеличение производительности.
На ряде сценариев смешанный вариант дает примерно на 10% больше, чем вариант с пулами или вариант вообще без пулов, поэтому на нем и было решено остановиться.
Мораль: здесь пришлось попробовать различные варианты, но реальной необходимости тотально работать с пулами с протаскиванием их в public API не было.
Выше описаны четыре переделки, о которых я хотел рассказать в ракурсе работы с блокирующими вызовами. Дальше я буду говорить немного про другое, но сначала хочется сделать промежуточный срез.
Вот сравнение HttpClient и JettyClient на разных типах соединений и объемах данных. Столбики — это срезы; чем выше — тем быстрее.
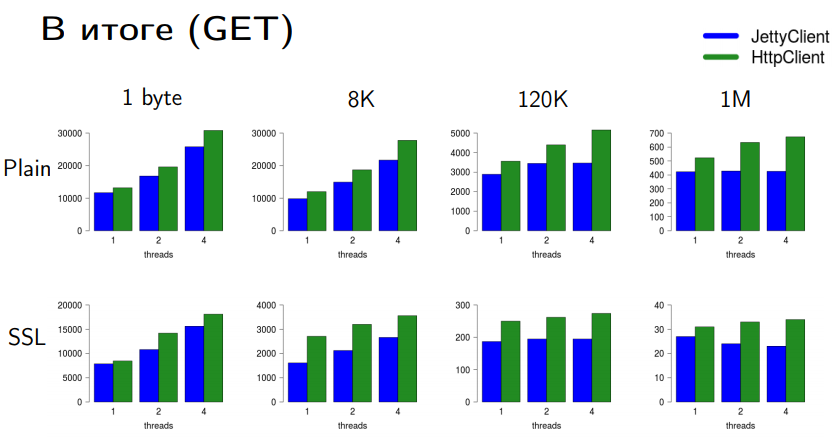
Для GET-запросов мы достаточно хорошо обогнали Jetty. Я ставлю галочку. У нас есть приемлемый перформанс с приемлемыми затратами. В принципе, там можно выжимать еще, но надо когда-то остановиться, иначе в Java 9 или Java 10 вы этот HttpClient не увидите.
С POST-запросами все не так оптимистично. При отсылке больших данных в PLAIN-соединении Jetty все равно чуть-чуть выигрывает. Но при отсылке небольших данных и при SSL-закодированном соединении у нас тоже никаких проблем.

Почему у нас не скалируются данные при большом размере post-а? Здесь мы упираемся в две проблемы сериализации: в случае SSL-соединения это lock на запись в сокет — он глобальный для записи в данный конкретный SocketChannel. Мы не можем писать в сокет параллельно. Хоть мы и часть JDK, библиотека nio для нас — внешний модуль, где мы ничего менять не можем. Поэтому когда мы пишем много, мы упираемся в этот bottleneck.
С SSL (с encryption) та же ситуация. У SSLEngine есть encryption / decryption. Они могут работать параллельно. Но encryption обязан работать последовательно, даже если я посылаю данные из многих тредов. Это особенность SSL-протокола. И это еще одна точка сериализации. С этим ничего нельзя сделать, если только не переходить на какие-нибудь нативные OpenSSL-стандарты.
Давайте посмотрим на асинхронные запросы.
Можем ли мы сделать такую совершенно простую версию асинхронного API?
Я дал свой executor — тут он выписан (executor конфигурируется в клиенте; у меня есть некоторый дефолтный executor, но вы, как пользователь этого клиента, можете дать туда любой executor).
Увы, нельзя просто так взять и написать асинхронный API:

Проблема в том, что в блокирующих запросах мы часто чего-то ждем.
Здесь очень утрированная картинка. В реальности там дерево запросов — ждун тут, ждун там… они расставлены в разных местах.

Когда мы ждем, мы сидим на wait или на condition. Если мы ждем в блокирующем API, а при этом мы закинули в Async executor, значит мы отобрали у executor тред.
С одной стороны, это просто неэффективно. С другой — мы написали API, который позволяет дать нашему API любой внешний executor. Это по определению должно работать с fixed thread pool (если пользователь может дать туда любой executor, значит мы должны иметь возможность работать хотя бы в одном треде).
В реальности это была стандартная ситуация, когда у меня все треды из моего executor-а заблокировались. Они ждут ответа от сервера, а сервер ждет и ничего не посылает, пока я ему тоже что-то не пришлю. Мне надо кое-что послать со стороны клиента, а у меня в executor-е нет тредов. Все. Приехали.
Надо пилить всю цепочку запросов, чтобы каждая точка ожидания была завернута в отдельный CompletableFuture. Примерно так:
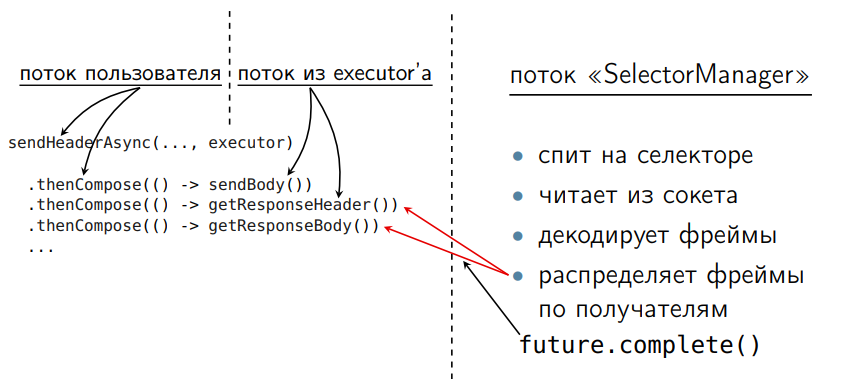
У нас есть поток пользователя слева. Там мы строим цепочку запросов. Здесь метод thenCompose, в который пришел один future, пришел второй future. C другой стороны, у нас есть thread-поток SelectorManager. Он был и в последовательной версии, просто его не надо было оптимизировать. Он читает из сокета, декодирует фрейм и делает complete.
Когда мы пришли в thenCompose и видим, что у нас future, который мы ждем, еще не завершен, мы не блокируемся (это асинхронная обработка CompletableFuture), а уходим. Тред вернется в executor, продолжит работать что-то еще, что требуется для этого executor-а, а потом мы зашедулим это исполнение дальше. Это ключевая фишка CompletableFuture, которая позволяет эффективно писать такие вещи. Мы не крадем тред из работы. У нас всегда есть кому работать. И это эффективнее с точки зрения перформанса.
Выпиливаем все блокировки на condition или wait, переходим на CompletableFuture. Когда CompletableFuture завершен, тогда тред ставится на исполнение. Получаем +40% к обработке асинхронных запросов.
У нас очень популярен жанр пазлеров. Я не очень люблю пазлеры, но хочу спросить. Предположим, у нас есть два потока и есть CompletableFuture. В одном потоке мы пристраиваем цепочку действий — thenSomething. Под этим «Something» я подразумеваю Compose, Combine, Apply — любые операции с CompletableFuture. А из второго потока мы делаем завершение этого CompletableFuture.
Метод foo — наше действие, которое должно сработать — в каком потоке выполнится?

Правильный ответ — С.
Если мы достраиваем цепочку — т.е. зовем метод thenSomething — и CompletableFuture был к этому моменту уже завершен, то метод foo вызовется в первом потоке. А если CompletableFuture еще не был завершен, он вызовется из complete по цепочке, т.е. из второго потока. С этой ключевой особенностью мы сейчас будем разбираться целых два раза.
Итак, мы в пользовательском коде строим цепочку запросов. Мы хотим, чтобы юзер послал мне sendAsync. Т.е. я хочу в треде пользователя, где мы делаем sendAsync, построить цепочку запросов и отдать финальный CompletableFuture пользователю. А там у меня в executor пойдут работать мои треды, посылка данных, ожидание.
Я кручу и пилю Java-код на локалхосте. И что выясняется: иногда я не успеваю достроить цепочку запросов, а CompletableFuture уже завершен:

На этой машине у меня всего четыре хардварных треда (а их может быть несколько десятков), и даже тут он не успевает достроить. Я измерил — это происходит в 3% случаев. Попытка достроить цепочку запросов дальше приводит к тому, что часть действий по этой цепочке, типа отсылки и получения данных, вызывается в пользовательском ходе, хотя я этого не хочу. Изначально я хочу, чтобы вся эта цепочка была скрыта, т.е. пользователь ее не должен видеть. Я хочу, чтобы она работала в executor-е.
Конечно, у нас есть методы, которые делают Compose Async. Если вместо thenCompose я позову метод
Плюсы реализации:
Минусы:
Вот такой вот трюк был использован:
Мы сначала берем пустой незавершенный CompletableFuture, к нему строим всю цепочку действий, которые нам нужно выполнить, и запустим выполнение. После этого мы завершим CompletableFuture — сделаем
Есть еще одна проблема, связанная с CompletableFuture:

У нас есть CompletableFuture и выделенный поток SelectorManager этот CompletableFuture завершает. Мы не можем писать здесь
Это просто опасно.

У нас есть

Но сделав
Мы очень часто вынуждены переключать исполнение с треда на executor на другой тред из этого же executor по цепочке. Но мы не хотим делать переключение с SelectorManager на executor или с какого-нибудь пользовательского треда на executor. И внутри executor-а мы не хотим, чтобы наши задачи мигрировали. От этого страдает перформанс.
Мы можем не делать

Но здесь та же самая проблема. В обоих вариантах мы обезопасили нашу работу, в нашем треде ничего не запустится, но эта миграция — дороговата.
Плюсы:
Минусы:
Вот еще один трюк: давайте проверим, может быть у нас CompletableFuture уже завершен? Если CompletableFuture еще не завершен — уходим в Async. А если он завершен — значит я точно знаю, что построение цепочки к уже завершенному CompletableFuture будет исполняться в моем треде, а я уже в этом треде executor так и делаю.

Это чисто оптимизация, которая снимает лишние вещи.
И это дает еще 16% производительности к асинхронным запросам.
В итоге все эти три оптимизации по CompletableFuture разогнали асинхронные запросы примерно на 80%.
Мораль: Изучать новое.
CompletableFuture (since 1.8)
Последнее исправление так и не было сделано в коде самого HTTP Client просто потому, что оно связано с Public API. Но проблему можно обойти. Про это я вам и расскажу.

Итак, у нас есть билдер клиента, ему можно дать executor. Если мы при создании HTTP Client не дали ему executor, тут сказано, что по умолчанию используется
Давайте посмотрим, что такое

В
До того, как я сделал исправления из предыдущего пункта (пятая переделка), я мерил, и выяснилось, что на один запрос
Я выпилил все ожидания, блокировки, сделал «Пятую переделку». У меня треды больше не блокируются, не тратятся, но они работают. Все равно на один запрос через
На самом деле для таких вещей
В этом случае надо исправлять ThreadPool executor. Надо измерять варианты. Но я просто покажу перформансные результаты для одного, который оказался наилучшим кандидатом на исправление

Два треда — это оптимальный вариант, потому что запись в сокет — это bottleneck, который не может быть распараллелен, и SSLEngine тоже не может работать в параллели. Цифры говорят сами за себя.
Мораль: Не все ThreadPool’ы одинаково полезны.
С переделками HTTP 2 Client у меня все.
Если честно, читая документацию, я очень много ругался на Java API. Особенно в части про байт-буфера, сокеты и прочее. Но у меня правила игры были таковы, что я не должен был их менять. Для меня JDK — это внешняя библиотека, на базе которой строится этот API.
Но товарищ Norman Maurer оказался не таким стесненным рамками, как я. И он написал интересную презентацию — для тех, кто хочет копнуть глубже: Writing Highly Performant Network Frameworks on the JVM — A Love-Hate Relationship.
Он ругает базовый API JDK как раз в районе сокетов, API и прочего. И описывает, чего они хотели поменять и чего им не хватало на уровне JDK, когда они писали Netty. Это все те же проблемы, что встретил я, но не мог починить в рамках заданных правил игры.
Если вы любите смаковать все детали разработки на Java так же, как и мы, наверняка вам будут интересны вот эти доклады на нашей апрельской конференции JPoint 2018:
Предлагаем вам расшифровку его доклада с JPoint 2017. В целом речь тут пойдет не про HTTP/2. Хотя, конечно, без ряда деталей по нему обойтись не удастся.
HTTP/2 (a. k. a. RFC 7540)
HTTP 2 — это новый стандарт, призванный заменить устаревший HTTP 1.1. Чем отличается реализация HTTP 2 от предыдущей версии с точки зрения производительности?
Ключевая вещь HTTP 2 — то, что у нас устанавливается одно единственное TCP-соединение. Потоки данных режутся на фреймы, и все эти фреймы отправляются через это соединение.
Также предусмотрен отдельный стандарт сжатия заголовков — RFC 7541 (HPACK). Он очень хорошо работает: позволяет ужать до 20 байт HTTP-шный header размером порядка килобайта. Для некоторых наших оптимизаций это важно.
В целом в новой версии есть много интересного — приоретизация запросов, server push (когда сервер сам посылает данные клиенту) и прочее. Однако в рамках этого повествования (с точки зрения производительности) это не важно. Кроме того, многие вещи остались прежними. Например, как выглядит протокол HTTP сверху: у нас те же методы GET и POST, те же значения полей заголовка HTTP, коды статуса и структура «запрос -> ответ -> финальный ответ». На самом деле если приглядеться, HTTP 2 — это всего навсего низкоуровневая транспортная подложка под HTTP 1.1, которая убирает его недостатки.
HTTP API (a.k.a. JEP 110, HttpClient)
У нас есть проект HttpClient, который называется JEP 110. Он почти включен в JDK 9. Изначально этот клиент хотели сделать частью стандарта JDK 9, но возникли некоторые споры на уровне реализации API. И поскольку мы не успеваем к выходу JDK 9 финализировать HTTP API, решили сделать так, чтобы можно было его показать сообществу и обсудить.
В JDK 9 появляется новый модуль инкубатор (Incubator Modules a.k.a. JEP-11). Это песочница, куда с целью получения фидбека от комьюнити будут складываться новые API, которые еще не стандартизированы, но, по определению инкубатора, будут стандартизированы к следующей версии или убраны вообще («The incubation lifetime of an API is limited: It is expected that the API will either be standardized or otherwise made final in the next release, or else removed»). Все, кому интересно, могут ознакомиться с API и прислать свой фидбек. Возможно, к следующей версии — JDK 10 — где он станет стандартом, все будет исправлено.
- module: jdk.incubator.httpclient
- package: jdk.incubator.http
HttpClient — первый модуль в инкубаторе. Впоследствии в инкубаторе будут появляться прочие вещи, связанные с клиентом.
Расскажу буквально на паре примеров про API (это именно клиентский API, который позволяет делать запрос). Основные классы:
- HttpClient (его Builder);
- HttpRequest (его Builder);
- HttpResponse, который мы не строим, а просто получаем обратно.
Вот таким простым образом можно построить запрос:
HttpRequest getRequest = HttpRequest .newBuilder(URI.create("https://jpoint.ru/")) .header("X-header", "value") .GET() .build();
HttpRequest postRequest = HttpRequest .newBuilder(URI.create("https://jpoint.ru/")) .POST(fromFile(Paths.get("/abstract.txt"))) .build();
Здесь мы указываем URL, задаем header и т.п. — получаем запрос.
Как можно послать запрос? Для клиента есть два вида API. Первый — синхронный запрос, когда мы блокируемся в месте этого вызова.
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = ...;
HttpResponse response =
// synchronous/blocking
client.send(request, BodyHandler.asString());
if (response.statusCode() == 200) {
String body = response.body();
...
}
...
Запрос ушел, мы получили ответ, проинтерпретировали его как
string (handler у нас здесь может быть разный — string, byte, можно свой написать) и обработали.Второй — асинхронный API, когда мы не хотим блокироваться в данном месте и, посылая асинхронный запрос, продолжаем выполнение, а с полученным CompletableFuture потом можем делать все, что захотим:
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = ...;
CompletableFuture> responseFuture =
// asynchronous
client.sendAsync(request, BodyHandler.asString());
...
Клиенту можно задать тысячу и один конфигурационный параметр, по-разному сконфигурировать:
HttpClient client = HttpClient.newBuilder()
.authenticator(someAuthenticator)
.sslContext(someSSLContext)
.sslParameters(someSSLParameters)
.proxy(someProxySelector)
.executor(someExecutorService)
.followRedirects(HttpClient.Redirect.ALWAYS)
.cookieManager(someCookieManager)
.version(HttpClient.Version.HTTP_2)</b>
.build();
Основная фишка еще здесь в том, что клиентский API — универсальный. Он работает как со старым HTTP 1.1, так и с HTTP 2 без различения деталей. Для клиента можно указать работу по умолчанию со стандартом HTTP 2. Этот же параметр можно указать для каждого отдельного запроса.
Постановка задачи
Итак, у нас есть Java-библиотека — отдельный модуль, который базируется на стандартных классах JDK, и который нам надо оптимизировать (провести некую перформансную работу). Формально задача перформанса состоит в следующем: мы должны получить разумную производительность клиента за приемлемые затраты времени инженера.
Выбираем подход
С чего мы можем начать эту работу?
- Можем сесть читать спецификацию HTTP 2. Это полезно.
- Можем начать изучать сам клиент и переписывать говнокод, который найдем.
- Можем просто посмотреть на этот клиент и переписать его целиком.
- Можем побенчмаркать.
Начнем с бенчмаркинга. Вдруг там все и так хорошо — не придется читать спецификацию.
Бенчмарки
Написали бенчмарк. Хорошо, если у нас для сравнения есть какой-нибудь конкурент. Я в качестве клиента-конкурента взял Jetty Client. Сбоку прикрутил Jetty Server — просто потому, что мне хотелось, чтобы сервер был на Java. Написал GET и POST запросы разных размеров.
Возникает, естественно, вопрос — что мы меряем: throughput, latency (минимальный, средний). В ходе дискуссии мы решили, что это не сервер, а клиент. Это значит, что учет минимальных latency, gc-пауз и всего прочего в данном контексте не важен. Поэтому конкретно для этой работы мы решили ограничиться измерением общего throughput системы. Наша задача — его повысить.
Общий throughput системы — это обратная величина к среднему latency. То есть мы работали над средним latency, но при этом не напрягались с каждым отдельным запросом. Просто потому, что у клиента не такие требования, как у сервера.
Переделка 1. Конфигурация TCP
Запускаем GET на 1 байт. Железо выписано. Получаем:
Я беру этот же бенчмарк для HTTPClient, запускаю на других операционных системах и железе (это уже более-менее серверные машинки). Получаю:
В Win64 все выглядит получше. Но даже в MacOS все не так плохо, как в Linux.
Проблема здесь:
SocketChannel chan;
...
try {
chan = SocketChannel.open();
int bufsize = client.getReceiveBufferSize(); chan.setOption(StandardSocketOptions.SO_RCVBUF, bufsize);
} catch (IOException e) {
throw new InternalError(e);
}
Это открытие SocketChannel для соединения с сервером. Проблема заключается в отсутствии одной строки (я ее выделил в коде ниже):
SocketChannel chan;
...
try {
chan = SocketChannel.open();
int bufsize = client.getReceiveBufferSize(); chan.setOption(StandardSocketOptions.SO_RCVBUF, bufsize);
chan.setOption(StandardSocketOptions.TCP_NODELAY, true); <-- !!!
} catch (IOException e) {
throw new InternalError(e);
}
TCP_NODELAY — это «привет» из прошлого века. Существуют различные алгоритмы TCP-стека. В данном контексте их два: Nagle’s Algorithm и Delayed ACK. При некоторых условиях они способны клэшиться, вызывая резкое замедление передачи данных. Это настолько известная проблема для стека TCP, что люди включают TCP_NODELAY, который выключает Nagle’s Algorithm, по умолчанию. Но иногда даже эксперт (а писали этот код реальные эксперты TCP) могут просто об этом забыть и не вписать эту командную строку.В принципе, в интернете существует масса объяснений, как эти два алгоритма конфликтуют и почему они создают такую проблему. Я привожу ссылку на одну статью, которая мне понравилась: TCP Performance problems caused by interaction between Nagle’s Algorithm and Delayed ACK
Детальное описание этой проблемы — за рамками нашего разговора.
После того, как была добавлена единственная строчка с включением
TCP_NODELAY, мы получили примерно такой прирост производительности:Я не буду считать, сколько это в процентах.
Мораль: это не Java-проблема, это проблема TCP-стека и вопросов его конфигурации. Для многих областей существуют общеизвестные косяки. Настолько общеизвестные, что люди про них забывают. Про них желательно просто знать. Если вы новичок в этой области, вы легко нагуглите основные косяки, которые существуют. Проверить их можно очень быстро и без всяких проблем.
Необходимо знать (и не забывать) список общеизвестных косяков для вашей предметной области.
Переделка 2. Flow-control window
У нас есть первое изменение, и мне даже не пришлось читать спецификацию. Получилось 9600 запросов в секунду, но помним, что Jetty дает 11 тыс. Дальше профилируем при помощи любого профайлера.
Вот что я получил:
А это отфильтрованный вариант:
Мой бенчмарк занимает 93% времени CPU.
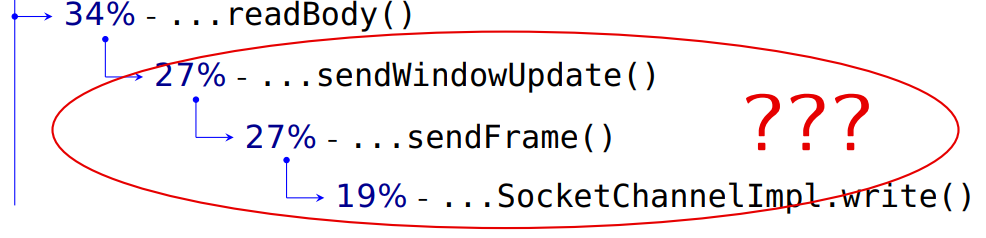
Посылка реквеста на сервер занимает 37%. Далее идет всякая внутренняя детализация, работа с фреймами, а в конце 19% — это запись в наш SocketChannel. Передаем данные и header запроса, как должно быть в HTTP. А потом мы читаем —
readBody().Далее мы должны прочитать пришедшие нам с сервера данные. Что же тогда это?
Если инженеры правильно назвали методы, а я им доверяю, то здесь они что-то отсылают на сервер, причем это требует столько же времени, сколько сама отправка наших запросов. Зачем при чтении ответа сервера мы что-то посылаем?
Чтобы ответить на этот вопрос, мне пришлось прочитать спецификацию.
Вообще очень много перформансных проблем решаются без знания спецификации. Где-то надо заменить
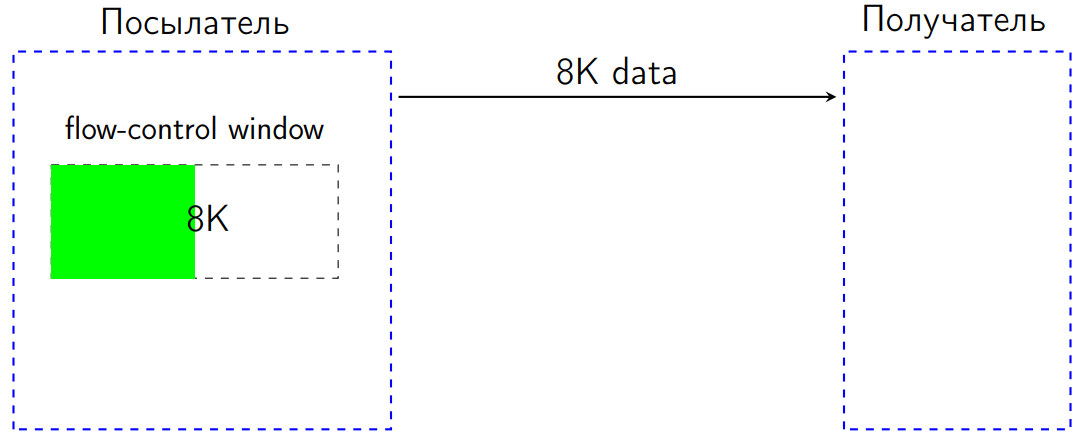
ArrayList на LinkedList или наоборот, или Integer на int и так далее. И в этом смысле очень хорошо, если есть бенчмарк. Меряешь — исправляешь — работает. И ты не вдаешься в детали, как оно там работает согласно спецификации.Но в нашем случае проблема действительно обнаружилась в спецификации: в стандарте HTTP 2 есть так называемый flow-control. Работает он следующим образом. У нас есть два пира: один посылает данные, другой — получает. У посылателя (отправителя) есть окошко — flow-control window размером в некоторое количество байт (предположим, 16 КБ).
Допустим, мы послали 8 КБ. Flow-control window уменьшается на эти 8 КБ.
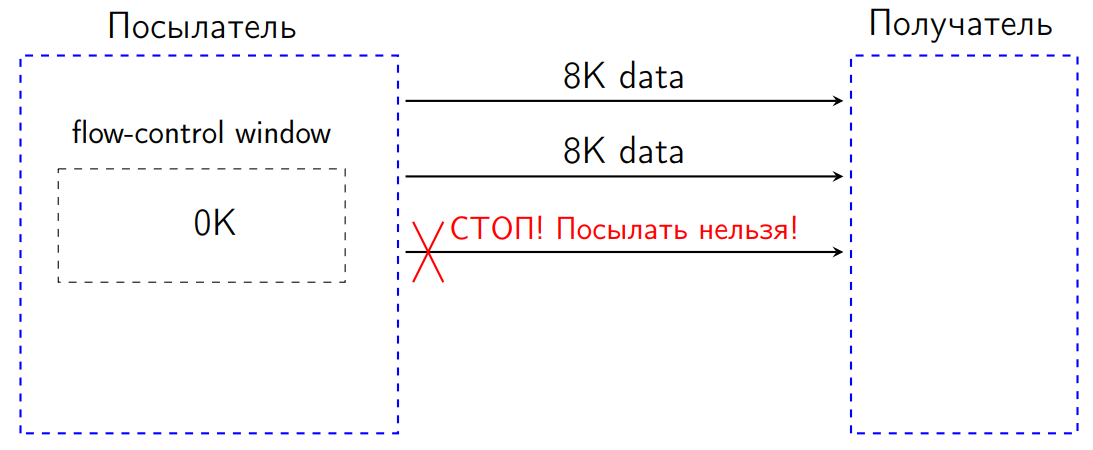
После того как мы послали еще 8 КБ, flow-control window стало 0 КБ.
По стандарту в такой ситуации мы не имеем права ничего посылать. Если мы попробуем послать какие-то данные, получатель будет обязан интерпретировать эту ситуацию как ошибку протокола и закрыть connection. Это некая защита от DDOS-ов в ряде случаев, чтобы нам не посылали ничего лишнего, а посылатель подстраивался под пропускную способность получателя.
Когда получатель обработал принятые данные, он должен был послать специальный выделенный сигнал под названием WindowUpdate с указанием, на сколько байт увеличить flow-control window.
Когда WindowUpdate приходит посылателю, у него flow-control window увеличивается, мы можем посылать данные дальше.
Что у нас происходит в клиенте?
Мы получили данные с сервера — вот реальный кусок обработки:
// process incoming data frames
...
DataFrame dataFrame;
do {
DataFrame dataFrame = inputQueue.take();
...
int len = dataFrame.getDataLength();
sendWindowUpdate(0, len); // update connection window sendWindowUpdate(streamid, len); //update stream window
} while (!dataFrame.getFlag(END_STREAM));
...
Пришел некий
dataFrame — фрейм данных. Мы посмотрели, сколько там данных, обработали их и послали обратно WindowUpdate, чтобы увеличить flow-control window на нужное значение.На самом деле в каждом таком месте работает два flow-control window. У нас есть flow-control window конкретно к этому потоку передачи данных (запросу), а также есть общий flow control window для всего connection. Поэтому мы должны послать два запроса WindowUpdate.
Как оптимизировать данную ситуацию?
Первое. В конце
while у нас есть флажок, который говорит, что нам прислали последний фрейм данных. По стандарту это значит, что больше никакие данные не придут. И мы делаем так:// process incoming data frames
...
DataFrame dataFrame;
do {
DataFrame dataFrame = inputQueue.take();
…
int len = dataFrame.getDataLength();
connectionWindowUpdater.update(len);
if (dataFrame.getFlag(END_STREAM)) {
break;
}
streamWindowUpdater.update(len);
}
while (true);
...
Это маленькая оптимизация: если мы поймали флажок конца стрима, то для этого стрима WindowUpdate можем уже не посылать: мы уже не ждем никаких данных, сервер ничего не будет посылать.
Второе. Кто сказал, что мы должны посылать WindowUpdate каждый раз? Почему мы не можем, получив много реквестов, обработать пришедшие данные и только потом послать WindowUpdate пачкой на все пришедшие запросы?
Вот
WindowUpdater, который работает на конкретное flow-control window:final AtomicInteger received;
final int threshold;
...
void update(int delta) {
if (received.addAndGet(delta) > threshold) {
synchronized (this) {
int tosend = received.get();
if( tosend > threshold) {
received.getAndAdd(-tosend);
sendWindowUpdate(tosend);
}
}
}
}
У нас есть некий
threshold. Мы получаем данные, ничего не посылаем. Как только мы набрали данных до этого threshold, мы отправляем все WindowUpdate. Тут присутствует некая эвристика, которая хорошо работает, когда значение threshold близко к половине flow-control window. Если у нас это окно изначально было 64 КБ, а получаем мы по 8 КБ, то как только мы получили несколько дата-фреймов суммарным объемом 32 КБ, посылаем window updater сразу на 32 КБ. Обычная пакетная обработка. Для хорошей синхронизации делаем еще совершенно обычный дабл-чек.Для запроса в 1 байт получаем:
Эффект будет даже для мегабайтных запросов, где много фреймов. Но он, естественно, не настолько заметен. На практике у меня были разные бенчмарки, запросы разного объема. Но здесь для каждого кейса я не стал рисовать графики, а подобрал простые примеры. Выжимка более подробных данных будет чуть позже.
Мы получили всего +23%, но Jetty уже обогнали.
Мораль: аккуратное чтение спецификации и логика — ваши друзья.
Здесь есть некий нюанс спецификации. Там с одной стороны сказано, что, получив дата-фрейм, мы должны отослать WindowUpdate. Но, внимательно прочитав спецификацию, мы увидим: там нет требования, что мы обязаны отсылать WindowUpdate на каждый полученный байт. Поэтому спецификация допускает такое пакетное обновления flow-control window.
Переделка 3. Блокировки
Давайте изучим, как мы скалируемся (масштабируемся).
Для скалирования ноутбук не очень подходит — у него всего два настоящих и два фейковых ядра. Мы возьмем какую-нибудь серверную машину, в которой 48 хардварных тредов, и запустим бенчмарк.
Здесь по горизонтали — количество потоков, а по вертикали показан общий throughput.
Здесь видно, что до четырех тредов мы скалируемся очень хорошо. Но дальше скалируемость становится очень плохой.
Казалось бы, зачем это нам? У нас один клиент; мы из одного треда получим необходимые данные с сервера и забудем об этом. Но во-первых, у нас есть асинхронная версия API. К ней мы еще придем. Там наверняка будут какие-то треды. Во-вторых, в нашем мире сейчас кругом все многоядерное, и иметь возможность хорошо работать с многими тредами в нашей библиотеке — просто полезно — хотя бы потому, что когда кто-то начнет жаловаться на производительность однопоточной версии, ему можно будет посоветовать перейти на многопоточную и получить бенефит. Поэтому давайте искать виновного в плохой скалируемости. Я обычно делаю это так:
#!/bin/bash
(java -jar benchmarks.jar BenchHttpGet.get -t 4 -f 0 &> log.log) &
JPID=$!
sleep 5 while kill -3 $JPID;
do
:
done
Я просто пишу стектрейсы в файл. В реальности этого мне хватает в 90% случаев, когда я работаю с блокировками без всяких профилеровщиков. Только в каких-то сложных трюковых кейсах я запускаю Mission control или что-то еще и смотрю распределение блокировок.
В логе можно посмотреть, в каком состоянии у меня различные треды:
Здесь нас интересуют именно блокировки, а не waiting, когда мы ожидаем событий. Блокировок 30 тыс. штук, что достаточно много на фоне 200 тыс. runnable.
А вот такая командная строчка нам просто покажет виновного (ничего дополнительно не нужно — только command line):
Виновник пойман. Это метод внутри нашей библиотеки, который посылает фрейм данных на сервер. Давайте разбираться.
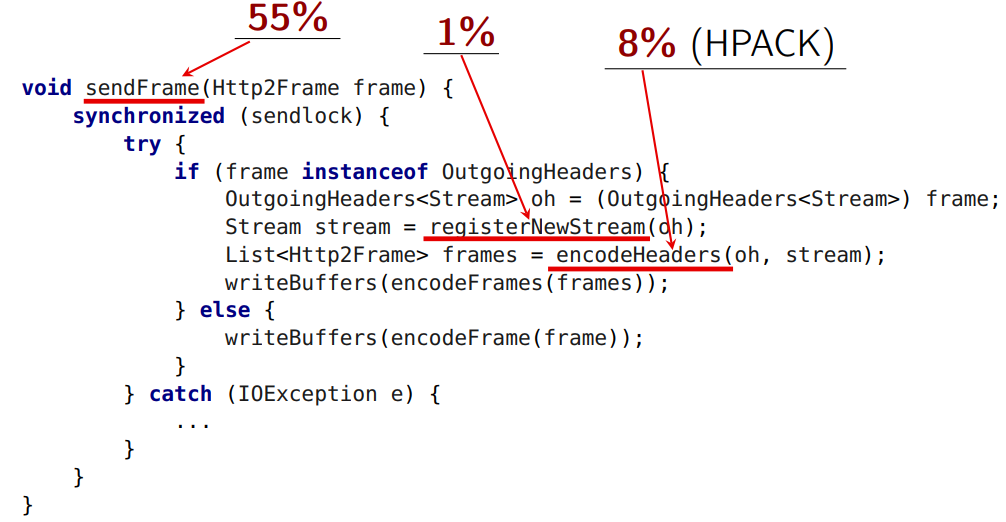
void sendFrame(Http2Frame frame) {
synchronized (sendlock) {
try {
if (frame instanceof OutgoingHeaders) {
OutgoingHeaders oh = (OutgoingHeaders) frame;
Stream stream = registerNewStream(oh);
List frames = encodeHeaders(oh, stream); writeBuffers(encodeFrames(frames));
} else {
writeBuffers(encodeFrame(frame));
}
} catch (IOException e) {
...
}
}
}
Тут у нас глобальный монитор:
А вот эта ветка —
— начало инициирования запроса. Это отправление самого первого header на сервер (тут требуются некоторые дополнительные действия, я сейчас о них еще буду рассказывать).
Это отправка на сервер всех остальных фреймов:
Все это под global lock!
Сам
sendFrame у нас занимает в среднем 55% времени. Но вот этот метод занимает 1%:
Попытаемся понять, что можно вынести из-под глобальной блокировки.
Регистрация нового стрима из-под блокировки вынесена быть не может. Стандарт HTTP накладывает ограничение на нумерацию стримов. В
registerNewStream новый стрим получает номер. И если для передачи своих данных я инициировал стримы с номерами 15, 17, 19, 21 и послал 21, а потом 15, это будет ошибка протокола. Посылать их я должен в порядке возрастания номера. Если я вынесу их из-под лока, они могут быть посланы не в том порядке, в котором я жду.Вторая проблема, которая не выносится из-под блокировки:
Здесь происходит сжатие заголовка.
В обычном виде у нас заголовок приставлен обычной мапой — ключ-значение (из стринга в стринг). В
encodeHeaders происходит сжатие заголовка. И здесь вторые грабли стандарта HTTP 2 — алгоритм HPACK, который работает с сжатием, statefull. Т.е. у него есть состояние (поэтому очень хорошо сжимает). Если у меня отсылается два запроса (два header-а), при этом сначала я сжал один, потом второй, то сервер обязан их получить в том же порядке. Если он их получит в другом порядке, то не сможет декодировать. Это проблема — точка сериализации. Все кодирования всех HTTP-запросов обязаны проходить через единую точку сериализации, они не могут работать в параллели, да еще после этого закодированные фреймы должны отсылаться. Метод
encodeFrame занимает 6% времени, и его теоретически можно вынести из под блокировки.encodeFrames скидывает фрейм в байт-буфер в том виде, в котором это определено спецификацией (до этого мы подготавливали внутреннюю структуру фреймов). Это занимает 6% времени.Ничто не мешает нам вынести из под блокировки
encodeFrames, кроме метода, где происходит собственно запись в сокет:Здесь есть некоторые нюансы реализации.
Так оказалось, что
encodeFrames может закодировать фрейм не в один, а в несколько байт-буферов. Это связано в первую очередь с эффективностью (чтобы не делать слишком много копирования).Если мы попробуем вынести из-под блокировки
writeBuffers, и writeBuffers от двух фреймов перемешаются, мы не сможем декодировать фрейм. Т.е. мы должны обеспечить какую-то атомарность. При этом внутри writeBuffers выполняется socketWrite, а там стоит своя глобальная блокировка на запись в сокет.Сделаем первое, что приходит в голову, — очередь Queue. Будем класть байт-буфера в эту очередь в правильном порядке, и пусть другой тред из нее читает.
В этом случае метод
writeBuffers вообще «уезжает» из этого треда. Его нет нужды держать под данной блокировкой (там есть своя глобальная блокировка). Нам главное — обеспечить порядок байт-буферов, которые туда приезжают.Итак, мы убрали одну из самых тяжелых операций наружу и запустили дополнительный тред. Размер критической секции стал меньше на 60%.
Но у реализации есть и минусы:
- для некоторых фреймов в стандарте HTTP 2 существует ограничение по порядку. Но другие фреймы по спецификации можно отправить раньше. Тот же WindowUpdate я могу отослать раньше других. И это хотелось бы сделать, потому что сервер-то стоит — он же ждет (у него flow-control window = 0). Однако реализация не позволяет это сделать;
- вторая проблема заключается в том, что когда у нас очередь пуста, отсылающий поток засыпает и долго просыпается.
Давайте решим первую проблему, связанную с порядком фреймов.
Вполне очевидная идея —
Deque<ByteBuffer[]>.У нас есть неразрывный кусочек байт-буферов, который нельзя перемешивать ни с чем; мы сложим его в массив, а сам массив — в очередь. Тогда эти массивы между собой перемешивать можно, а там, где нам требуется фиксированный порядок, мы его обеспечиваем:
- ByteBuffer[] — атомарная последовательность буферов;
- WindowUpdateFrame — мы можем положить в начало очереди и вынести его вообще из-под блокировки (у него нет ни кодирования проток��лов, ни нумерации);
- DataFrame — тоже можно вынести из-под блокировки и положить в конец очереди. В итоге блокировка становится все меньше и меньше.
Плюсы:
- меньше блокировок;
- ранняя отправка Window Update позволяет серверу раньше отсылать данные.
Но и здесь остался еще один минус. По-прежнему отсылающий поток часто засыпает и долго просыпается.
Давайте сделаем так:
У нас будет немного своя очередь. В нее мы складываем полученные массивы байт-буферов. После этого между всеми тредами, которые вышли из-под блокировки, устроим соревнование. Кто победил, тот пусть в сокет и пишет. А остальные пусть работают дальше.
Надо отметить, что в методе
flush() оказалась и другая оптимизация, которая дает эффект: если у меня много мелких данных (например, 10 массивов по три-четыре буфера) и зашифрованное SSL-соединение, он может из очереди брать не по одному массиву, а более крупными кусками, и отправлять их в SSLEngine. В этом случае затраты на кодирование резко снижаются.Каждая из трех представленных оптимизаций позволяла очень хорошо снимать проблему со скалированием. Примерно вот так (отражен общий эффект):
Мораль: Блокировки — зло!
Все знают, что от блокировок нужно избавляться. Тем более что concurrent-библиотека становится все более продвинутой и интересной.
Переделка 4. Пул или GC?
В теории у нас есть HTTP Client, рассчитанный под 100% использование ByteBufferPool. Но на практике… Тут же баги, здесь — что-то упало, там — фрейм недоработался… А если ByteBuffer в пул обратно не вернул, функционал не сломался… В общем инженерам оказалось некогда с этим разбираться. И у нас получилась недоделанная версия, заточенная на пулы. Имеем (и плачем):
- только 20% буферов возвращается в пул;
- ByteBufferPool.getBuffer() занимает 12% времени.
Мы получаем все минусы работы с пулами, а заодно — все минусы работы без пулов. Плюсов в этой версии нет. Нам надо двигаться вперед: или сделать нормальный полноценный пул, чтобы все ByteBuffer в него возвращались после использования, или вообще выпилить пулы, но при этом они у нас есть даже в public API.
Что люди думают про пулы? Вот что можно услышать:
- Пул не нужен, пулы вообще вредны! e.g. Dr. Cliff Click, Brian Goetz, Sergey Kuksenko, Aleksey Shipil¨ev,…
- некоторые утверждают, будто пул — это круто и у них проявился эффект. Пул нужен! e.g. Netty (blog.twitter.com/2013/netty-4-at-twitter-reduced-gc-overhead),…
DirectByteBuffer или HeapByteBuffer
Прежде чем вернемся к вопросу пулов, нам нужно решить подвопрос — что мы используем в рамках нашей задачи с HTTPClient: DirectByteBuffer или HeapByteBuffer?
Сначала изучаем вопрос теоретически:
- DirectByteBuffer лучше для I/O.
sun.nio.* копирует HeapByteBuffer в DirectByteBuffer;
- HeapByteBuffer лучше для SSL.
SSLEngine работает напрямую с byte[] в случае HeapByteBuffer.
Действительно, для передачи данных в сокет DirectByteBuffer лучше. Потому что если мы по цепочке Write-ов дойдем до nio, мы увидим код, где из HeapByteBuffer все копируется во внутренние DirectByteBuffer-а. И если у нас пришел DirectByteBuffer, мы ничего не копируем.
Но у нас есть и другая штука — SSL-соединение. Сам стандарт HTTP 2 позволяет работать как с plain connection, так и с SSL connection, но декларируется, что SSL должен быть стандартом де-факто для нового веба. Если точно так же проследить цепочку того, как это реализовано в OpenJDK, выясняется, что теоретически SSLEngine лучше работает с HeapByteBuffer, потому что он может достучаться до массива byte[] и там энкриптить. А в случае с DirectByteBuffer он должен сначала скопировать сюда, а потом обратно.
А измерения показывают, что HeapByteBuffer всегда быстрее:
- PlainConnection — HeapByteBuffer «быстрее» на 0%-1% — я взял в кавычки, потому что 0 — 1% — это не быстрее. Но выигрыша от использования DirectByteBuffer нет, а проблем больше;
- SSLConnection — HeapByteBuffer быстрее на 2%-3%
Т.е. HeapByteBuffer — наш выбор!
Как ни странно, чтение и копирование из DirectByteBuffer дороже, потому что там остаются чеки. Код там не очень хорошо векторизуется, поскольку работает через unsafe. А в HeapByteBuffer — intrinsic (даже не векторизация). И скоро он будет работать еще лучше.
Поэтому даже если бы HeapByteBuffer был на 2-3% медленнее, чем DirectByteBuffer, возможно, не имело бы смысла заниматься DirectByteBuffer. Так давайте избавимся от проблемы.
Сделаем различные варианты.
Вариант 1: Все в пул
- Пишем нормальный пул. Четко отслеживаем жизненные пути всех буферов, чтобы они возвращались обратно в пул.
- Оптимизируем сам пул (на базе ConcurrentLinkedQueue).
- Разделяем пулы (по размеру буфера). Возникает вопрос, какого размера должны быть буфера. Я читал, что в Jetty сделан универсальный ByteBufferPool, который позволяет работать с байт-буферами разного размера с гранулярностью в 1 КБ. Нам же нужно просто три разных ByteBufferPool, каждый работает со своим размером. И если пул работает с буферами только одного размера, все становится гораздо проще:
- SSL пакеты (SSLSession.getPacketBufferSize());
- кодирование заголовков (MAX_FRAME_SIZE);
- все остальное.
Плюсы варианта 1:
- меньше «allocation pressure»
Минусы:
- реально сложный код. Почему инженеры не доделали это решение в первый раз? Потому что оценить, как ByteBuffer пробирается туда-сюда, когда его можно безопасно вернуть в пул, чтобы ничего не испортилось, та еще проблема. Я видел потуги некоторых людей, пытавшихся к этим буферам прикрутить референс-каунтинг. Я настучал им по голове. Это делало код еще сложнее, но проблемы не решало;
- реально плохая «локальность данных»;
- затраты на пул (а еще мешает скалируемости);
- частое копирование данных, в том числе:
- практическая невозможность использования
ByteBuffer.slice()иByteBuffer.wrap(). Если у нас есть ByteBuffer, из которого надо вырезать какую-то серединку, мы можем либо скопировать его, либо сделать slice(). slice() не копирует данные. Мы вырезаем кусок, но переиспользуем тот же массив данных. Мы сокращаем копирование, но с пулами полная каша. Теоретически это можно довести до ума, но здесь уже точно без референс-каунтинга не обойтись. Допустим, я прочитал из сети кусок 128 КБ, там лежит пять дата-фреймов, каждый по 128 Байт, и мне из них надо вырезать данные и отдать их пользователю. И неизвестно, когда пользователь их вернет. А ведь все это — единый байт-буфер. Надо чтобы все пять кусков померли и тогда байт-буфер вернется. Никто из участников не взялся это реализовать, поэтому мы честно копировали данные. Думаю, затраты на борьбу с копированием не стоят возрастающей сложности кода.
Вариант 2: Нет пулам — есть же GC
GC сделает всю работу, тем более у нас не DirectByteBuffer, а HeapByteBuffer.
- убираем все пулы, в том числе из Public API, потому что в реальности они не несут в себе никакой функциональности, кроме какой-то внутренней технической реализации.
- ну и, естественно, поскольку у нас теперь все собирает GC, нам не нужно копировать данные — мы активно используем
ByteBuffer.slice()/wrap()— режем и заворачиваем буфера.
Плюсы:
- код реально стал проще для понимания;
- нет пулов в «public API»;
- у нас хорошая «локальность данных»;
- значительное сокращение затрат на копирование, все так работает;
- нет затрат на пул.
Но две проблемы:
- во-первых, аллокация данных — выше «allocation pressure»
- и вторая проблема в том, что мы нередко не знаем, какой буфер нам нужен. Мы читаем из сети, из I/O, из сокета, мы аллоцируем буфер в 32 КБ, ну пусть даже в 16 КБ. А из сети прочитали 12 Байт. И что нам с этим буфером дальше делать? Только выкидывать. Получаем неэффективное использование памяти (когда требуемый размер буфера неизвестен) — ради 12 Байт аллоцировали 16 КБ.
Вариант 3: Смешиваем
Ради эксперимента делаем смешанный вариант. Про него я расскажу немного подробнее. Здесь выбираем подход в зависимости от данных.
Исходящие данные:
- пользовательские данные. Мы знаем их размер, за исключением кодирования в алгоритме HPACK, поэтому всегда аллоцируем буфера нужного размера — у нас нет неэффективного расходования памяти. Мы можем делать всякие нарезки и заворачивания без лишнего копирования — и пусть GC соберет.
- для сжатия HTTP-заголовков — отдельный пул, откуда берется байт-буфер и потом туда же возвращается.
- все остальное — буфера требуемого размера (GC соберет)
Входящие данные:
- чтение из сокета — буфер из пула какого-то нормального размера — 16 или 32 КБ;
- пришли данные (DataFrame) —
slice()(GC соберет);
- все остальное — возвращаем в пул.
В целом в стандарте HTTP 2 есть девять видов фреймов. Если пришли восемь из них (все, кроме данных), то мы байт-буфера там же декодируем и нам ничего из него копировать не надо, и мы возвращаем байт-буфера обратно в пул. А если пришли данные, мы выполняем slice, чтобы не надо было ничего копировать, а потом просто его бросаем — он будет собираться GC.
Ну и отдельный пул для зашифрованных буферов SSL-соединения, потому что там свой размер.
Плюсы смешанного варианта:
- средняя сложность кода (в чем-то, но в основном он проще, чем первый вариант с пулами, потому что меньше надо отслеживать);
- нет пулов в «public API»;
- хорошая «локальность данных»;
- нет затрат на копирование;
- приемлемые затраты на пул;
- приемлемое использование памяти.
Минус — один: выше «allocation pressure».
Сравнение вариантов
Мы сделали три варианта, проверили, поправили баги, добились функциональной работы. Измеряем. Смотрим аллокации данных. У меня было 32 сценария измерений, но я не хотел здесь рисовать 32 графика. Я покажу просто усредненный по всем измерениям диапазон. Здесь baseline — первоначальный недоделанный код (я его взял за 100%). Мы измеряли изменение allocation rate по отношению к baseline в каждой из трех модификаций.
Вариант, где все идет в пул, предсказуемо аллоцирует меньше. Вариант, не требующий никаких пулов, аллоцирует в восемь раз больше памяти, чем вариант без пулов. Но так ли нам нужна память для allocation rate? Померяем GC-паузу:
С такими GC-паузами на allocation rate это не влияет.
Видно, что первый вариант (в пул по максимуму) дает 25% ускорения. Отсутствие пулов по максимуму дает 27% ускорения, а смешанный вариант дает по максимуму 36% ускорения. Любой правильно доделанный вариант уже дает увеличение производительности.
На ряде сценариев смешанный вариант дает примерно на 10% больше, чем вариант с пулами или вариант вообще без пулов, поэтому на нем и было решено остановиться.
Мораль: здесь пришлось попробовать различные варианты, но реальной необходимости тотально работать с пулами с протаскиванием их в public API не было.
- Не ориентироваться на «urban legends»
- Знать мнения авторитетов
- Но нередко «истина где-то рядом»
Промежуточные итоги
Выше описаны четыре переделки, о которых я хотел рассказать в ракурсе работы с блокирующими вызовами. Дальше я буду говорить немного про другое, но сначала хочется сделать промежуточный срез.
Вот сравнение HttpClient и JettyClient на разных типах соединений и объемах данных. Столбики — это срезы; чем выше — тем быстрее.
Для GET-запросов мы достаточно хорошо обогнали Jetty. Я ставлю галочку. У нас есть приемлемый перформанс с приемлемыми затратами. В принципе, там можно выжимать еще, но надо когда-то остановиться, иначе в Java 9 или Java 10 вы этот HttpClient не увидите.
С POST-запросами все не так оптимистично. При отсылке больших данных в PLAIN-соединении Jetty все равно чуть-чуть выигрывает. Но при отсылке небольших данных и при SSL-закодированном соединении у нас тоже никаких проблем.
Почему у нас не скалируются данные при большом размере post-а? Здесь мы упираемся в две проблемы сериализации: в случае SSL-соединения это lock на запись в сокет — он глобальный для записи в данный конкретный SocketChannel. Мы не можем писать в сокет параллельно. Хоть мы и часть JDK, библиотека nio для нас — внешний модуль, где мы ничего менять не можем. Поэтому когда мы пишем много, мы упираемся в этот bottleneck.
С SSL (с encryption) та же ситуация. У SSLEngine есть encryption / decryption. Они могут работать параллельно. Но encryption обязан работать последовательно, даже если я посылаю данные из многих тредов. Это особенность SSL-протокола. И это еще одна точка сериализации. С этим ничего нельзя сделать, если только не переходить на какие-нибудь нативные OpenSSL-стандарты.
Переделка 5. Асинхронный API
Давайте посмотрим на асинхронные запросы.
Можем ли мы сделать такую совершенно простую версию асинхронного API?
public <T> HttpResponse<T>
send(HttpRequest req, HttpResponse.BodyHandler<T> responseHandler) {
...
}
public <T> CompletableFuture<HttpResponse<T>>
sendAsync(HttpRequest req, HttpResponse.BodyHandler<T> responseHandler) {
return CompletableFuture.supplyAsync(() -> send(req, responseHandler), executor);
}
Я дал свой executor — тут он выписан (executor конфигурируется в клиенте; у меня есть некоторый дефолтный executor, но вы, как пользователь этого клиента, можете дать туда любой executor).
Увы, нельзя просто так взять и написать асинхронный API:
Проблема в том, что в блокирующих запросах мы часто чего-то ждем.
Здесь очень утрированная картинка. В реальности там дерево запросов — ждун тут, ждун там… они расставлены в разных местах.
Шаг 1 — переход на CompletableFuture
Когда мы ждем, мы сидим на wait или на condition. Если мы ждем в блокирующем API, а при этом мы закинули в Async executor, значит мы отобрали у executor тред.
С одной стороны, это просто неэффективно. С другой — мы написали API, который позволяет дать нашему API любой внешний executor. Это по определению должно работать с fixed thread pool (если пользователь может дать туда любой executor, значит мы должны иметь возможность работать хотя бы в одном треде).
В реальности это была стандартная ситуация, когда у меня все треды из моего executor-а заблокировались. Они ждут ответа от сервера, а сервер ждет и ничего не посылает, пока я ему тоже что-то не пришлю. Мне надо кое-что послать со стороны клиента, а у меня в executor-е нет тредов. Все. Приехали.
Надо пилить всю цепочку запросов, чтобы каждая точка ожидания была завернута в отдельный CompletableFuture. Примерно так:
У нас есть поток пользователя слева. Там мы строим цепочку запросов. Здесь метод thenCompose, в который пришел один future, пришел второй future. C другой стороны, у нас есть thread-поток SelectorManager. Он был и в последовательной версии, просто его не надо было оптимизировать. Он читает из сокета, декодирует фрейм и делает complete.
Когда мы пришли в thenCompose и видим, что у нас future, который мы ждем, еще не завершен, мы не блокируемся (это асинхронная обработка CompletableFuture), а уходим. Тред вернется в executor, продолжит работать что-то еще, что требуется для этого executor-а, а потом мы зашедулим это исполнение дальше. Это ключевая фишка CompletableFuture, которая позволяет эффективно писать такие вещи. Мы не крадем тред из работы. У нас всегда есть кому работать. И это эффективнее с точки зрения перформанса.
Выпиливаем все блокировки на condition или wait, переходим на CompletableFuture. Когда CompletableFuture завершен, тогда тред ставится на исполнение. Получаем +40% к обработке асинхронных запросов.
Шаг 2 — задержанный запуск
У нас очень популярен жанр пазлеров. Я не очень люблю пазлеры, но хочу спросить. Предположим, у нас есть два потока и есть CompletableFuture. В одном потоке мы пристраиваем цепочку действий — thenSomething. Под этим «Something» я подразумеваю Compose, Combine, Apply — любые операции с CompletableFuture. А из второго потока мы делаем завершение этого CompletableFuture.
Метод foo — наше действие, которое должно сработать — в каком потоке выполнится?
Правильный ответ — С.
Если мы достраиваем цепочку — т.е. зовем метод thenSomething — и CompletableFuture был к этому моменту уже завершен, то метод foo вызовется в первом потоке. А если CompletableFuture еще не был завершен, он вызовется из complete по цепочке, т.е. из второго потока. С этой ключевой особенностью мы сейчас будем разбираться целых два раза.
Итак, мы в пользовательском коде строим цепочку запросов. Мы хотим, чтобы юзер послал мне sendAsync. Т.е. я хочу в треде пользователя, где мы делаем sendAsync, построить цепочку запросов и отдать финальный CompletableFuture пользователю. А там у меня в executor пойдут работать мои треды, посылка данных, ожидание.
Я кручу и пилю Java-код на локалхосте. И что выясняется: иногда я не успеваю достроить цепочку запросов, а CompletableFuture уже завершен:
На этой машине у меня всего четыре хардварных треда (а их может быть несколько десятков), и даже тут он не успевает достроить. Я измерил — это происходит в 3% случаев. Попытка достроить цепочку запросов дальше приводит к тому, что часть действий по этой цепочке, типа отсылки и получения данных, вызывается в пользовательском ходе, хотя я этого не хочу. Изначально я хочу, чтобы вся эта цепочка была скрыта, т.е. пользователь ее не должен видеть. Я хочу, чтобы она работала в executor-е.
Конечно, у нас есть методы, которые делают Compose Async. Если вместо thenCompose я позову метод
thenComposeAsync(), в пользовательский поток я свои действия, конечно же, не переведу. Плюсы реализации:
- ничего не попадает в пользовательский поток;
Минусы:
- слишком частое переключение с одного потока из executor’а на другой поток из executor’а (дорого). В пользовательский код ничего не попадает, но методы
thenComposeAsync,thenApplyAsyncи вообще любые методы с окончанием Async переключаем выполнение CompletableFuture на другой тред из этого же executor-а, даже если мы пришли из треда нашего executor-а (в Async), если это fork-join по умолчанию или если это явно заданный executor. Однако если CompletableFuture уже завершен, какой смысл переключаться с этого треда? Это переключение с одного тред-а на другой — бесполезная трата ресурсов.
Вот такой вот трюк был использован:
CompletableFuture<Void> start = new CompletableFuture<>();
start.thenCompose(v -> sendHeader())
.thenCompose(() -> sendBody())
.thenCompose(() -> getResponseHeader())
.thenCompose(() -> getResponseBody())
...;
start.completeAsync( () -> null, executor); // !!! trigger execution
Мы сначала берем пустой незавершенный CompletableFuture, к нему строим всю цепочку действий, которые нам нужно выполнить, и запустим выполнение. После этого мы завершим CompletableFuture — сделаем
completeAsync — с переходом сразу в наш executor. Это даст нам еще 10% производительности к асинхронным запросам.Шаг 3 — трюки с complete()
Есть еще одна проблема, связанная с CompletableFuture:
У нас есть CompletableFuture и выделенный поток SelectorManager этот CompletableFuture завершает. Мы не можем писать здесь
future.complete. Проблема заключается в том, что поток SelectorManager — внутренний, он обрабатывает все чтения из сокета. А мы отдаем его пользователю CompletableFuture. И он к нему может прицепить цепочку своих действий. Если мы с помощью response.complete на SelectorManager запустим выполнение пользовательских действий, то пользователь может убить нам наш выделенный поток SelectorManager, который должен заниматься правильной работой, и лишнего там выполняться не должно. Мы должны каким-то образом перевести исполнение — взять из того потока и просунуть в наш executor, где у нас есть кучка тредов. Это просто опасно.
У нас есть
completeAsync.Но сделав
completeAsync, мы получаем ту же проблему. Мы очень часто вынуждены переключать исполнение с треда на executor на другой тред из этого же executor по цепочке. Но мы не хотим делать переключение с SelectorManager на executor или с какого-нибудь пользовательского треда на executor. И внутри executor-а мы не хотим, чтобы наши задачи мигрировали. От этого страдает перформанс.
Мы можем не делать
CompleteAsync. С той стороны мы всегда можем сделать переход в Async. Но здесь та же самая проблема. В обоих вариантах мы обезопасили нашу работу, в нашем треде ничего не запустится, но эта миграция — дороговата.
Плюсы:
- ничего не попадает в поток «SelectorManager»
Минусы:
- частое переключение с одного потока из executor’а на другой поток из executor’а (дорого)
Вот еще один трюк: давайте проверим, может быть у нас CompletableFuture уже завершен? Если CompletableFuture еще не завершен — уходим в Async. А если он завершен — значит я точно знаю, что построение цепочки к уже завершенному CompletableFuture будет исполняться в моем треде, а я уже в этом треде executor так и делаю.
Это чисто оптимизация, которая снимает лишние вещи.
И это дает еще 16% производительности к асинхронным запросам.
В итоге все эти три оптимизации по CompletableFuture разогнали асинхронные запросы примерно на 80%.
Мораль: Изучать новое.
CompletableFuture (since 1.8)
Переделка 6
Последнее исправление так и не было сделано в коде самого HTTP Client просто потому, что оно связано с Public API. Но проблему можно обойти. Про это я вам и расскажу.
Итак, у нас есть билдер клиента, ему можно дать executor. Если мы при создании HTTP Client не дали ему executor, тут сказано, что по умолчанию используется
CachedThreadPool().Давайте посмотрим, что такое
CachedThreadPool(). Я специально подчеркнул, что интересно:В
CachedThreadPool() есть один плюс и один минус. По большому счету это один и тот же плюс и минус. Проблема в том, что когда у CachedThreadPool() закончились треды, он создает новые. С одной стороны, это хорошо — наша задача не сидит в очереди, не ждет, она может сразу исполняться. С другой стороны, это плохо, потому что создается новый поток.До того, как я сделал исправления из предыдущего пункта (пятая переделка), я мерил, и выяснилось, что на один запрос
CachedThreadPool() создавал 20 тредов — было слишком много ожидания. 100 одновременных потоков выдавали out of memory exception. Это не работало — даже на серверах, которые доступны у нас в лабе.Я выпилил все ожидания, блокировки, сделал «Пятую переделку». У меня треды больше не блокируются, не тратятся, но они работают. Все равно на один запрос через
CachedThreadPool() создается в среднем 12 потоков. На 100 одновременных запросов создалось 800 тредов. Оно скрипело, но работало.На самом деле для таких вещей
CachedThreadPool() executor использовать нельзя. Если у вас очень маленькие таски, их очень много, CachedThreadPool() executor подойдет. Но в общем случае — нет. Он создаст вам много тредов, вы потом будете их разгребать. В этом случае надо исправлять ThreadPool executor. Надо измерять варианты. Но я просто покажу перформансные результаты для одного, который оказался наилучшим кандидатом на исправление
CachedThreadPool() с двумя тредами:Два треда — это оптимальный вариант, потому что запись в сокет — это bottleneck, который не может быть распараллелен, и SSLEngine тоже не может работать в параллели. Цифры говорят сами за себя.
Мораль: Не все ThreadPool’ы одинаково полезны.
С переделками HTTP 2 Client у меня все.
Если честно, читая документацию, я очень много ругался на Java API. Особенно в части про байт-буфера, сокеты и прочее. Но у меня правила игры были таковы, что я не должен был их менять. Для меня JDK — это внешняя библиотека, на базе которой строится этот API.
Но товарищ Norman Maurer оказался не таким стесненным рамками, как я. И он написал интересную презентацию — для тех, кто хочет копнуть глубже: Writing Highly Performant Network Frameworks on the JVM — A Love-Hate Relationship.
Он ругает базовый API JDK как раз в районе сокетов, API и прочего. И описывает, чего они хотели поменять и чего им не хватало на уровне JDK, когда они писали Netty. Это все те же проблемы, что встретил я, но не мог починить в рамках заданных правил игры.
Если вы любите смаковать все детали разработки на Java так же, как и мы, наверняка вам будут интересны вот эти доклады на нашей апрельской конференции JPoint 2018:
- Аппаратная транзакционная память в Java (Никита Коваль, Devexperts)
- Анализ программ: как понять, что ты хороший программист (Алексей Кудрявцев, JetBrains)
- Профилируем с точностью до микросекунд и инструкций процессора (Сергей Мельников, Райффайзенбанк)
- Java EE 8 finally final! And now EE4J? (David Delabassée, Oracle)
