Comments 9
Странно, что различные типы систем — мониторинг, поиск аномалий и оповещения используются как синонимы.
По мне лучше было бы увидеть описание не архитектуры, а то как именно выполняется поиск аномалий: если параметры статических методов подкручивать ручками, как рекомендует Google, то это не сильно лучше черного ящика, т.к. такие параметры требуют знания статистики и предполагаемого характера измеряемых величин.
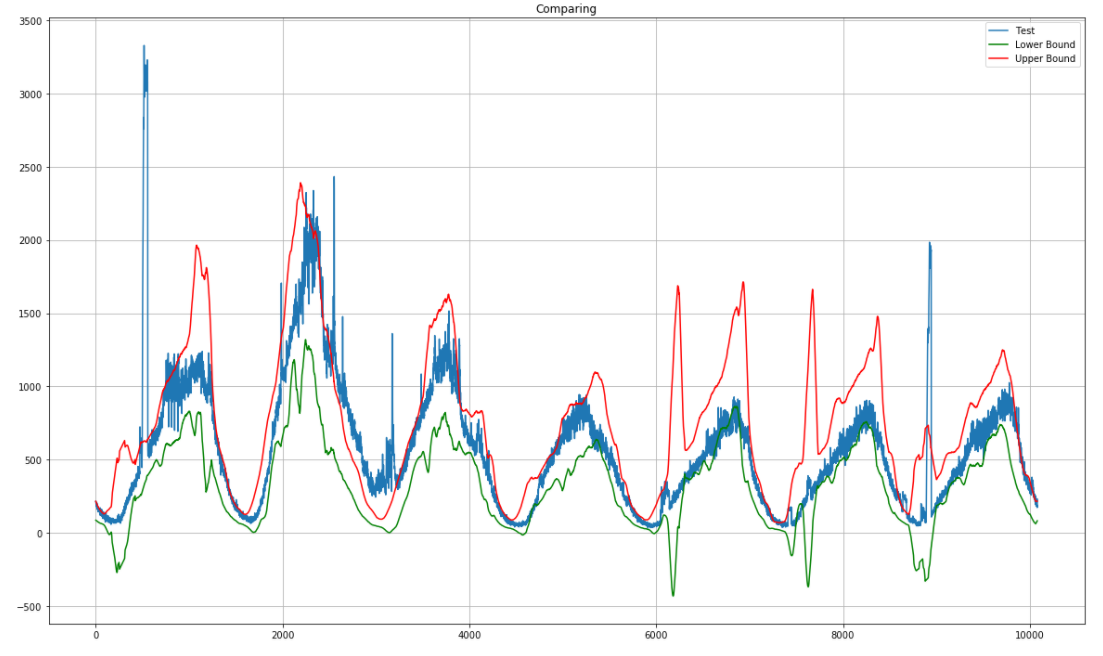
Перед сглаживаем явные выбросы желательно удалять, чтобы избежать чрезмерного допустимого интервала, как, например, в последнем сезоне здесь.
P.S. И было бы гуд дать заревьюить артиклу нейтиву.
По мне лучше было бы увидеть описание не архитектуры, а то как именно выполняется поиск аномалий: если параметры статических методов подкручивать ручками, как рекомендует Google, то это не сильно лучше черного ящика, т.к. такие параметры требуют знания статистики и предполагаемого характера измеряемых величин.
Перед сглаживаем явные выбросы желательно удалять, чтобы избежать чрезмерного допустимого интервала, как, например, в последнем сезоне здесь.
{kind=link}
P.S. И было бы гуд дать заревьюить артиклу нейтиву.
Да, у меня были сложности с тем как на русском определить термины. Это сложно.
Monitoring, Anomalies, Alerts это разные термины.
Поэтому возможна путаница.
В некотором смысле параметры все равно приходится подкручивать ручками. Падение на 40% от среднего на сайтах с десятками тысяч пользователей — проблема. На других брендах где среднее порядка сотни на часовом интервале падение на 40% норма. Это тонкий баланс. Универсальные алгоритмы и подходы как правило работают плохо. И в то же время хочется быть как можно более универсальным.
Да, я чищу явные выбросы. Просматриваю метрики и ищу слишком сильную динамику подьема. Но там еще есть свой технический долг :)
Monitoring, Anomalies, Alerts это разные термины.
Поэтому возможна путаница.
В некотором смысле параметры все равно приходится подкручивать ручками. Падение на 40% от среднего на сайтах с десятками тысяч пользователей — проблема. На других брендах где среднее порядка сотни на часовом интервале падение на 40% норма. Это тонкий баланс. Универсальные алгоритмы и подходы как правило работают плохо. И в то же время хочется быть как можно более универсальным.
Да, я чищу явные выбросы. Просматриваю метрики и ищу слишком сильную динамику подьема. Но там еще есть свой технический долг :)
У меня сейчас интересный проект отпочковавшийся от этой системы. Это магистерская работа для нашего интерна. Мы можем представить метрики как матрицы, и идти по ним конволюционными ядрами, которые подстроены под поиск градиента (падения или подъема).

В прошлом году были удачные академические публикации о применении этого метода с финансовыми рынками. Я писал о своем воспроизведении на английском тут.
Я напишу если этот подход будет удачным. Но теоретически все должно получиться.
В прошлом году были удачные академические публикации о применении этого метода с финансовыми рынками. Я писал о своем воспроизведении на английском тут.
Я напишу если этот подход будет удачным. Но теоретически все должно получиться.
Что вы имели в виду под «описание не архитектуры, а то как именно выполняется поиск аномалий»? Я опишу подробнее.
Возьмем одну метрику и соответствующий ей временной ряд. Каков алгоритм поиска аномалий в нем? Понятно, что ряд предварительно сглаживается, но как выбираются параметры сглаживания? Далее, насколько я понял, каким то образом строится допустимый интервал. Каким образом? Тут (Отклонение от «повседневного») я описал встреченные мной варианты.
Сам я хочу использовать сглаженный ряд плюс-минус стандартное отклонение на исследуемом участке за текущий и пару предыдущих периодов, считая что сезонность данных — неделя. При этом, если в периоде был обнаружен пик или сдвиг, то такой период не учитывать.
Сам я хочу использовать сглаженный ряд плюс-минус стандартное отклонение на исследуемом участке за текущий и пару предыдущих периодов, считая что сезонность данных — неделя. При этом, если в периоде был обнаружен пик или сдвиг, то такой период не учитывать.
Очень хорошая статья.
Я пробовал несколько подходов, ARIMA, Twitter ESDA. Но по факту лучше всего оказалось считать моделью данные с предыдущей недели пройденные скользящими средними и разбросом с окном 60 минут (гранулярность 1 минута). Баундариз считается как значение трех значений скользящего разброса по обеим сторонам.
В дальнейшем я хочу считать модель по данным 4 недель, усредняя их и давая уменьшающиеся веса по мере удаленности.
Если на той неделе был инцидент, то я пока просто не беру эту неделю, хотя писал функцию которая вырезает этот кусок из предыдущих недель. Аутлаером считается то, что выходит за границы.
Я пробовал несколько подходов, ARIMA, Twitter ESDA. Но по факту лучше всего оказалось считать моделью данные с предыдущей недели пройденные скользящими средними и разбросом с окном 60 минут (гранулярность 1 минута). Баундариз считается как значение трех значений скользящего разброса по обеим сторонам.
В дальнейшем я хочу считать модель по данным 4 недель, усредняя их и давая уменьшающиеся веса по мере удаленности.
Если на той неделе был инцидент, то я пока просто не беру эту неделю, хотя писал функцию которая вырезает этот кусок из предыдущих недель. Аутлаером считается то, что выходит за границы.
Интересно, почему именно инфлюкс?
Скорее всего потому, что метрики уже писались в Инфлюкс для визуализации в Графане. Плюс мы умеем хорошо готовить эту базу.
Но у нее есть тоже свои особенности, которые надо учитывать. Или вот например свежее, поначалу я грешил на графану, почему и открыл issue там но
github.com/grafana/grafana/issues/11482
Хотя проблема наблюдалась только в графане, моя система не имела проблем.
По большому счету сделать коннектор к другой базе не проблема, там достаточно имплементировать интерфеис, который должен возвращать данные в формате pandas.DataFrame
Но у нее есть тоже свои особенности, которые надо учитывать. Или вот например свежее, поначалу я грешил на графану, почему и открыл issue там но
github.com/grafana/grafana/issues/11482
Хотя проблема наблюдалась только в графане, моя система не имела проблем.
По большому счету сделать коннектор к другой базе не проблема, там достаточно имплементировать интерфеис, который должен возвращать данные в формате pandas.DataFrame
Можете попробовать хранить данные в VictoriaMetrics вместо InfluxDB:
- Она поддерживает запись данных по Influx line protocol.
- Из нее легко доставать записанные данные через
/api/v1/export. См. https://medium.com/@valyala/analyzing-prometheus-data-with-external-tools-5f3e5e147639 . - Она работает быстрее и требует меньше оперативной памяти по сравнению с InfluxDB.
Вот тут можно почитать дополнительный материал по VictoriaMetrics — https://github.com/VictoriaMetrics/VictoriaMetrics/wiki/Articles
Sign up to leave a comment.
Never Fail Twice, или как построить мониторинговую систему с нуля