Японские кроссворды (также нонограммы) — логические головоломки, в которых зашифровано пиксельное изображение. Разгадывать кроссворд нужно с помощью чисел, расположенных слева от строк и сверху от столбцов.
Размер кроссвордов может доходить до 150x150. Игрок с помощью специальных логических приемов вычисляет цвет каждой клетки. Решение может занять как пару минут на кроссвордах для начинающих, так и десятки часов на сложных головоломках.
Хороший алгоритм может решить задачу намного быстрее. В тексте описано, как с помощью наиболее подходящих алгоритмов (которые вообще приводят к решению), а также их оптимизаций и использования особенностей C++ (которые уменьшают время работы в несколько десятков раз) написать решение, работающее почти мгновенно.
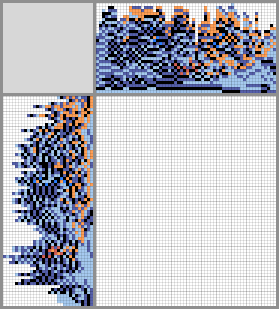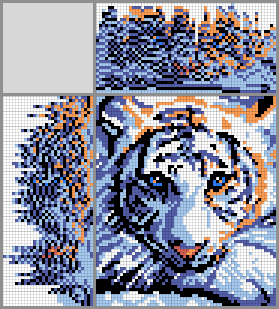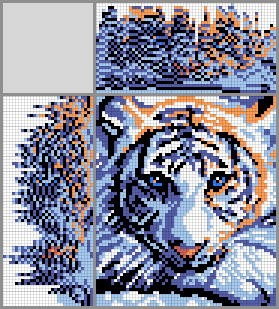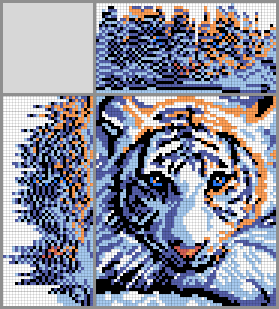
В мобильной версии Хабра формулы в тексте могут не показываться (не во всех мобильных браузерах) — пользуйтесь полной версией или другим мобильным браузером, если заметили проблемы с формулами
Правила игры
Изначально холст кроссворда белый. Для ванильных черно-белых кроссвордов нужно восстановить местоположения черных клеток.
В черно-белых кроссвордах количество чисел для каждой строки (слева от холста) или для каждого столбца (сверху от холста) показывает, сколько групп черных клеток находятся в соответствующих строке или столбце, а сами числа — сколько слитных клеток содержит каждая из этих групп. Набор чисел ![$[3, 2, 5]$](https://habrastorage.org/getpro/habr/formulas/68a/34b/e82/68a34be82f4f2b68434da05c62e69266.svg) значит, что в определенном ряду есть три последовательные группы из
значит, что в определенном ряду есть три последовательные группы из  ,
,  и
и  черных клеток подряд. Группы могут быть расположены в ряду как попало, не нарушая относительный порядок (цифры задают их длину, а позицию надо угадать), но они обязательно должны разделяться хотя бы одной белой клеткой.
черных клеток подряд. Группы могут быть расположены в ряду как попало, не нарушая относительный порядок (цифры задают их длину, а позицию надо угадать), но они обязательно должны разделяться хотя бы одной белой клеткой.

Корректный пример
В цветных кроссвордах у каждой группы еще есть свой цвет — любой, кроме белого, это фоновый цвет. Соседние группы разных цветов могут стоять вплотную, но для соседних групп одинаковых цветов разделение хотя бы одной белой клеткой еще обязательно.
Что не является японским кроссвордом
Каждое пиксельное изображение можно зашифровать в виде кроссворда. Но восстановить обратно может быть невозможно — получившаяся головоломка может либо иметь более одного решения, либо иметь одно решение, но не может быть решена логическим путем. Тогда оставшиеся клетки в процессе игры приходится отгадывать, используя квантовые компьютеры шаманские технологии.
Такие кроссворды являются не кроссвордами, а графоманией. Считается, что корректный кроссворд — такой, что логическим путем можно прийти к единственному решению.
"Логический путь" — это возможность восстановить каждую клетку одну за другой, рассматривая строку/столбец по отдельности, или их пересечение. Если такой возможности нет, количество рассматриваемых вариантов ответа может быть очень много, намного больше, чем человек сможет посчитать сам.

Неправильная нонограмма — решение единственное, но решить нормально нельзя. Оранжевым помечены "нерешаемые" клетки. Взято из Wikipedia.
Такое ограничение объясняется так — в самом общем случае японский кроссворд это NP-полная задача. Однако, NP-полной задачей разгадывание не становится, если есть алгоритм, в каждый момент времени однозначно указывающий, какие клетки открыть далее. Все методы разгадывания кроссвордов, применяемые человеком (за исключением метода Монте-Карло проб и ошибок), основываются именно на этом.
У наиболее православных кроссвордов ширина и высота делится на 5, нет рядов, которых можно посчитать мгновенно (такие, где либо цветные клетки забивают все места, либо их нет совсем), и ограничено количество дополнительных цветов. Эти требования не обязательные.
Наипростейший неправильный кроссворд:
|1 1| --+---+ 1| | 1| | --+---+
Часто не решаются взад закодированные пиксельные арты, в которых используется "шахматный порядок" для имитации градиента. Лучше понять будет, если вы наберете в поиске "pixelart gradient". Градиент как раз похож на этот фейловый кроссворд 2x2.
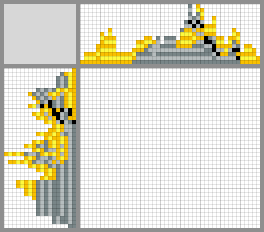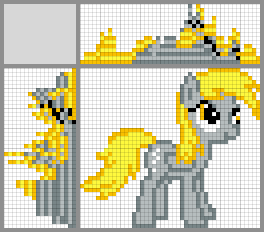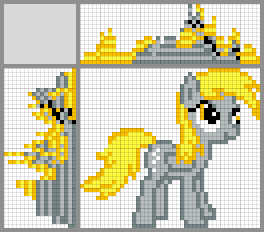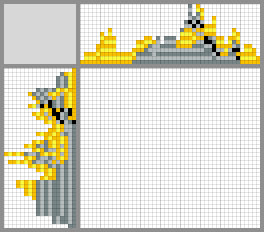
Возможные варианты решений
У нас есть размер кроссворда, описание цветов и всех строк и столбцов. Как можно собрать из этого картинку:
Полный перебор
Для каждой клетки перебираем все возможные состояния и проверяем на удовлетворительность. Сложность такого решения для черно-белого кроссворда  , для цветного
, для цветного  . По аналогии с клоунской сортировкой это решение можно тоже назвать клоунским. Оно годится для размера 5x5.
. По аналогии с клоунской сортировкой это решение можно тоже назвать клоунским. Оно годится для размера 5x5.
Backtracking
Перебираются все возможные методы расстановки горизонтальных групп клеток. Ставим группу клеток в строке, проверяем, что она не ломает описание групп столбцов. Если ломает — ставим дальше на 1 клетку, опять проверяем. Поставили — переходим к следующей группе. Если группу поставить нельзя никак — откатываем две группы, переставляем предыдущую группу, и так далее, пока не поставим последнюю группу успешно.
Отдельно для каждого ряда
Это решение намного лучше и оно истинно верное. Мы можем проанализировать каждую строку и каждый столбец по отдельности. У каждого ряда попытаемся раскрыть максимум информации.
Алгоритм для каждой клетки в ряду узнает больше информации — может оказаться, что в какой-то цвет клетку окрасить невозможно, группы не сойдутся. Сразу строку полностью раскрыть нельзя, но полученная информация "поможет" раскрыться лучше нескольким столбцам, а когда мы начнем их анализировать, те опять "помогут" строкам, и так в течение нескольких итераций, пока для всех клеток не останется один возможный цвет.
Истинно верное решение
Одна строка, два цвета
Эффективное отгадывание черно-белого "однострочника", для которого некоторые клетки уже отгаданы — весьма жесткая задача. Она встречалась в таких местах, как:
- Четвертьфинал ACM ICPC 2006 — задачу можно попробовать решить самому. Тайм-лимит 1 секунда, ограничение количества групп 400, длины ряда тоже 400. Имеет сильно высокий уровень сложности по сравнению с другими задачами.
- International Olympiad in Informatics 2016 — условие, сдать задачу. Тайм-лимит 2 секунды, ограничение кол-ва групп 100, длины ряда 200'000. Такие ограничения оверкилл, но решение задачи с ограничениями ACM набирает 80/100 баллов в этой задаче. Тут тоже уровень не подкачал, школьники со всего мира с жестоким уровнем IQ тренируются несколько лет решать разную жесть, потом проходят на эту олимпиаду (пройти должны только 4 человека от страны), решают 2 тура по 5 часов
и в случае epic win (бронза в разные годы за 138-240 баллов из 600) поступление в Оксфорд, потом офферы от понятных компаний в отдел поиска, долгая и счастливая жизнь в обнимку с дакимакурой.
Монохромный однострочник тоже можно решать по-разному, и за  (перебор всех вариантов, проверка на корректность, выделение клеток, которые имеют один и тот же цвет во всех вариантах), и еще как-то менее тупо.
(перебор всех вариантов, проверка на корректность, выделение клеток, которые имеют один и тот же цвет во всех вариантах), и еще как-то менее тупо.
Основная идея в том, чтобы использовать аналог бэктрекинга, но без лишних вычислений. Если мы как-то поставили несколько групп и сейчас находимся в какой-то клетке, то требуется узнать, можно ли поставить оставшиеся группы, начиная с текущей клетки.
def EpicWin(group, cell): if cell >= last_cell: # Условие выигрыша return group == group_size win = False # Можем ли вставить группу в этой позиции if group < group_size # Группы еще есть and CanInsertBlack(cell, len[group]) # Вставка черной группы and CanInsertWhite(cell + len[group], 1) # Вставка белой клетки and EpicWin(group + 1, cell + len[group] + 1): # Можно заполнить далее win = True can_place_black[cell .. (cell + len[group] - 1)] = True can_place_white[cell + len[group]] = True; # Можем ли вставить белую клетку в этой позиции if CanInsertWhite(cell, 1) and EpicWin(group, cell + 1): win = True can_place_white[cell] = True return win EpicWin(0, 0)
Такой подход называется динамическим программированием. Псевдокод упрощен, и там даже запоминание вычисленных значений не производится.
Функции CanInsertBlack/CanInsertWhite нужны, чтобы проверить, можно ли теоретически поставить группу нужного размера в нужное место. Все что им надо сделать — проверить, что в указанном интервале клеток нет "100% белой" клетки (для первой функции) или "100% черной" (для второй). Значит, они могут работать за  , это можно сделать с помощью частичных сумм:
, это можно сделать с помощью частичных сумм:
white_counter = [ 0, 0, ..., 0 ] # Массив длины n def PrecalcWhite(): for i in range(0, (n-1)): if is_anyway_white[i]: # 1, если i-ая клетка 100% белая white_counter[i]++ if i > 0: white_counter[i] += white_counter[i - 1] def CanInsertBlack(cell, len): # Опускаем проверку корректности границ [cell, cell + len - 1] ans = white_counter[cell + len - 1] if cell > 0: ans -= white_counter[cell - 1] # В ans - количество белых клеток от cell до (cell + len - 1) return ans == 0
Такое же колдунство с частичными суммами ждет строки вида
can_place_black[cell .. (cell + len[group] - 1)] = True
Тут можно вместо = True увеличивать число на 1. А если нам надо произвести много прибавлений на отрезке в неком массиве  , и притом этот массив мы никак не используем перед разными прибавлениями (про такое говорят, что эта задача "решается оффлайн"), то вместо цикла:
, и притом этот массив мы никак не используем перед разными прибавлениями (про такое говорят, что эта задача "решается оффлайн"), то вместо цикла:
# Много раз такой код for i in range(L, R + 1): array[i]++
Можно сделать так:
# Много раз такой код array[L]++ array[R + 1]-- # После всех прибавлений for i in range(1, n): array[i] += array[i - 1]
Таким образом, работает весь алгоритм за  , где
, где  — количество групп черных клеток,
— количество групп черных клеток,  — длина строки. И мы проходим на полуфинал ACM ICPC или получаем бронзу межнара. Решение ACM (Java). Решение IOI (C++).
— длина строки. И мы проходим на полуфинал ACM ICPC или получаем бронзу межнара. Решение ACM (Java). Решение IOI (C++).
Одна строка, много цветов
При переходе на многоцветные нонограммы, которых еще непонятно, как решать, мы узнаем страшную правду — оказывается, на каждую строку магическим образом влияют все столбцы! Это понятнее через пример:

Источник — Методы решения японских кроссвордов
В то время как двухцветные нонограммы нормально обходились без этого, им не надо было оглядываться на ортогональных друзей.
На картинке видно, что у левого примера три крайние правые клетки пустые, потому что поломается конфигурация, если окрасить эти клетки в те цвета, в которых окрасить себя не-белый цвет.
Но этот прикол математически разрешим — надо каждой клетке выдать число, где  -й бит будет означать, можно ли дать этой клетке -й цвет. Изначально у всех клеток значение
-й бит будет означать, можно ли дать этой клетке -й цвет. Изначально у всех клеток значение  . Решение динамики поменяется не очень сильно.
. Решение динамики поменяется не очень сильно.
Можно будет наблюдать следующий эффект: в этом же левом примере, по версии строк, крайняя справа клетка может иметь либо синий либо белый цвет.
По версии столбцов, эта клетка имеет либо зеленый, либо белый цвет.
По версии здравого смысла, эта клетка будет иметь только белый цвет. И дальше мы продолжаем вычислять ответ.
Если считать нулевой бит "белым", первый "синим", второй "зеленый", то строка вычислила для последней клетки состояние  , а столбец
, а столбец  . Значит, реально у этой клетки состояние
. Значит, реально у этой клетки состояние 
source = [...] # Начальные состояния result = [0, 0, ..., 0] # Итоговые состояния len = [...] # Длины групп клеток clrs = [...] # Цвета групп клеток def CanInsertColor(color, cell, len): for i in range(cell, cell + len): if (source[i] & (1 << color)) == 0: # В некоторой клетке цвет color поставить не можем return False; return True def PlaceColor(color, cell, len): for i in range(cell, cell + len): result[i] |= (1 << color) # Добавляем цвет color операцией OR def EpicWinExtended(group, cell): if cell >= last_cell: # Условие выигрыша return group == group_size win = False # Можем ли вставить группу в этой позиции if group < group_size # Группы еще есть and CanInsertColor(clrs[group], cell, len[group]) # Вставка черной группы and SequenceCheck() # Если следующая группа имеет тот же цвет, проверяем # что можем после этой группы поставить белую клетку and EpicWin(group + 1, cell + len[group]): # Можно заполнить далее win = True PlaceColor(clrs[group], cell, len[group]) PlaceColor(0, cell + len[group], 1) # Белая клетка - только если нужно # Можем ли вставить белую клетку в этой позиции # Белая клетка - бит 0 if CanInsertWhite(0, cell, 1) and EpicWinExtended(group, cell + 1): win = True PlaceColor(0, cell, 1) return win
Много строк, много цветов
Постоянно делаем обновление состояний всех строк и столбцов, описанное в прошлом пункте, пока не останется ни одной клетки с больше чем одним битом. В каждой итерации после обновления всех строк и столбцов, обновляем состояния всех клеток в них через взаимный AND.
Первые результаты
Допустим, что код мы писали не как дятлы, то есть никуда по ошибке объекты не копируем вместо передачи по ссылке, нигде в алгоритме не косячим, велосипедов не изобретаем, для битовых операций используем __builtin_popcount и __builtin_ctz (особенности gcc), все аккуратно и чисто.
Посмотрим на время работы программы, которая считывает из файла головоломку и решает ее полностью. Стоит оценить достоинства машинки, на которой все это добро писалось и тестировалась:
RAM - 4GB Процессор - AMD E1-2500, частота 1400MHz Кэш L1 - 128KiB, 1GHz Кэш L2 - 1MiB, 1GHz Ядер - 2, потоков - 2 Представлен как «малопроизводительная SoC для компактных ноутбуков» в середине 2013 года Стоимость процессора 28 долларов
Понятно, что такой суперкомпьютер был выбран, потому что оптимизации на нем имеют больший эффект, чем на летающей шайтан-машине.
Итак, после прогона нашего алгоритма на самом сложном кроссворде (по версии nonograms.ru), получаем не очень хороший результат — от 47 до 60 секунд (в это входит считывание из файла и решение). Надо заметить, что "сложность" на сайте посчитана хорошо — этот же кроссворд во всех версиях программы так же был самым тяжелым, другие наиболее сложные кроссворды по мнению архива держались в топе по времени.

Для быстрого тестирования была сделана функциональность для бенчмарка. Для получения данных для него я специальным скриптом спарсил 4683 цветных кроссворда (из 10906) и 1406 черно-белых (из 8293) с nonograms.ru (это один из крупнейших архивов нонограмм в интернете) и сохранил их в формате, понятном программе. Можно считать, что эти кроссворды являются случайной выборкой, поэтому бенчмарк показал бы адекватные средние значения. Также номера пары дюжин самых "сложных" кроссвордов (также самых больших по размеру и количеству цветов) записал в скрипт для загрузки ручками.

Оптимизация
Здесь показаны возможные приемы для оптимизации, которые были сделаны (1)во время написания всего алгоритма, (2)для ужимания времени работы с полминуты до долей секунды, (3)те оптимизации, которые могут быть полезны далее.
Во время написания алгоритма
- Специальные функции для битовых операций, в нашем случае
__builtin_popcountдля подсчета единиц в двоичной записи числа, и__builtin_ctzдля количества нулей перед первой самой младшей единицей. Таких функций может не оказаться в некоторых компиляторах. Для Windows подойдут такие аналоги:
#ifdef _MSC_VER # include <intrin.h> # define __builtin_popcount __popcnt #endif
- Организация массивов — меньший размер стоит вначале. Например, лучше использовать массив [2][3][500][1024], чем [1024][500][3][2].
- Самое главное — общая адекватность кода и избегание лишних забот для вычислений.
Что уменьшает время работы
- Флаг -O2 при компиляции.
- Чтобы не бросать в алгоритм полностью решенную строку/столбец заново, можно в отдельном std::vector/массиве завести флаги для каждого ряда, помечать их при полном решении, и не давать идти дальше, если решать уже нечего.
- Специфика многоповторного решения задачи на динамику предполагает, что специальный массив, который содержит флаги, помечающие уже "вычисленные" куски задачи, следует обнулять каждый раз при новом решении. В нашем случае это двумерный массив/вектор, где первое измерение — количество групп, второе — текущая клетка (см. псевдокод EpicWin сверху, где этого массива нет, но идея ясна). Вместо обнуления можно сделать так — пусть у нас будет переменная-"таймер", а массив состоит из чисел, показывающих последнее "время", когда этот кусок пересчитывался в последний раз. При запуске новой задачи "таймер" увеличивается на 1. Вместо проверки булевого флага следует проверять равенство элемента массива и "таймера". Это эффективно особенно в тех случаях, когда далеко не все возможные состояния покрываются алгоритмом (а значит, обнуление массива "считали ли мы уже это" занимает здоровый кусок времени).
- Замена несложных однотипных операций (циклы с присваиванием и т.д.) на аналоги в STL или более адекватные вещи. Иногда работает быстрее велосипеда.
std::vector<bool>в С++ сжимает все булевые значения до отдельных битов в числах, что работает при доступе чуть медленнее, чем если бы это было обычное значение по адресу. Если программа ну очень-очень часто обращается к таким значениям, то замена bool на целочисленный тип может хорошо повлиять на производительность.- Остальные слабые места можно искать через профайлеры и править их. Я сам использую Valgrind, его анализ производительности удобно смотреть через kCachegrind. Профайлеры встроены во многие IDE.
Этих правок оказалось достаточно, чтобы получить такие данные на бенчмарке:
izaron@izaron:~/nonograms/build$ ./nonograms_solver -x ../../nonogram/source2/ -e [2018-08-04 22:57:40.432] [Nonograms] [info] Starting a benchmark... [2018-08-04 22:58:03.820] [Nonograms] [info] Average time: 0.00497556, Median time: 0.00302781, Max time: 0.215925 [2018-08-04 22:58:03.820] [Nonograms] [info] Top 10 heaviest nonograms: [2018-08-04 22:58:03.820] [Nonograms] [info] 0.215925 seconds, file 9596 [2018-08-04 22:58:03.820] [Nonograms] [info] 0.164579 seconds, file 4462 [2018-08-04 22:58:03.820] [Nonograms] [info] 0.105828 seconds, file 15831 [2018-08-04 22:58:03.820] [Nonograms] [info] 0.08827 seconds, file 18353 [2018-08-04 22:58:03.820] [Nonograms] [info] 0.0874717 seconds, file 10590 [2018-08-04 22:58:03.820] [Nonograms] [info] 0.0831248 seconds, file 4649 [2018-08-04 22:58:03.820] [Nonograms] [info] 0.0782811 seconds, file 11922 [2018-08-04 22:58:03.820] [Nonograms] [info] 0.0734325 seconds, file 4655 [2018-08-04 22:58:03.820] [Nonograms] [info] 0.071352 seconds, file 10828 [2018-08-04 22:58:03.820] [Nonograms] [info] 0.0708263 seconds, file 11824
izaron@izaron:~/nonograms/build$ ./nonograms_solver -x ../../nonogram/source/ -e -b [2018-08-04 22:59:56.308] [Nonograms] [info] Starting a benchmark... [2018-08-04 23:00:09.781] [Nonograms] [info] Average time: 0.0095679, Median time: 0.00239274, Max time: 0.607341 [2018-08-04 23:00:09.781] [Nonograms] [info] Top 10 heaviest nonograms: [2018-08-04 23:00:09.781] [Nonograms] [info] 0.607341 seconds, file 5126 [2018-08-04 23:00:09.781] [Nonograms] [info] 0.458932 seconds, file 19510 [2018-08-04 23:00:09.781] [Nonograms] [info] 0.452245 seconds, file 5114 [2018-08-04 23:00:09.781] [Nonograms] [info] 0.19975 seconds, file 18627 [2018-08-04 23:00:09.781] [Nonograms] [info] 0.163028 seconds, file 5876 [2018-08-04 23:00:09.781] [Nonograms] [info] 0.161675 seconds, file 17403 [2018-08-04 23:00:09.781] [Nonograms] [info] 0.153693 seconds, file 12771 [2018-08-04 23:00:09.781] [Nonograms] [info] 0.146731 seconds, file 5178 [2018-08-04 23:00:09.781] [Nonograms] [info] 0.142732 seconds, file 18244 [2018-08-04 23:00:09.781] [Nonograms] [info] 0.136131 seconds, file 19385
Можно заметить, что в среднем черно-белые кроссворды "сложнее" цветных. Это подтверждает наблюдения любителей игры, которые также считают, что "цветные" решаются в среднем легче.
Таким образом, без радикальных правок (таких как переписывание всего кода на на С или ассемблерных вставок с fastcall и опусканием указателя фрейма) можно достичь высокой производительностью, заметим, на весьма скромном компьютере. К оптимизациям может быть применим принцип Парето — окажется, что мелкая оптимизация влияет сильно, потому что этот кусок кода критичен и вызывается очень часто.
Дальнейшая оптимизация
Следующие методы могут сильно улучшить производительность программы. Некоторые из них работают не во всех случаях, а при некоторых условиях.
- Переписывание кода на C-style и прочий 1972 год. Заменяем ifstream на сишный аналог, векторы на массивы, учим все опции компилятора и боремся за каждый такт процессора.
- Распараллеливание. Например, в коде есть кусок, где последовательно обновляются строки, потом столбцы:
... if (!UpdateGroupsState(solver, dead_rows, row_groups, row_masks)) { return false; } if (!UpdateGroupsState(solver, dead_cols, col_groups, col_masks)) { return false; } return true;
Эти функции независимы друг от друга и у них нет общей памяти, кроме переменной solver (тип OneLineSolver), так что можно создать два объекта "решателя" (здесь очевидно только один — solver) и запустить два потока в этой же функции. Эффект такой — в цветных кроссвордах "самый тяжелый" решается в два раза быстрее, в черно-белых такой же на треть быстрее, а среднее время увеличилось, за счет сравнительно больших затрат на создание потоков.
Но вообще я бы не советовал делать прямо так в текущей программе и спокойно использовать — во-первых, создание потоков затратная операция, не стоит постоянно создавать потоки для микросекундных задач, во-вторых, при некоторой комбинации аргументов программы, потоки могут обращаться одновременно к какой-то внешней памяти, например при создании картинок решения — это надо бы учесть и обезопасить.
Если бы задача была серьезной и у меня было бы много данных и многоядерные машины, я бы пошел еще дальше — можно завести несколько постоянных потоков, у каждого будет свой объект OneLineSolver, и еще одна thread-safe структура, которая рулит распределением работы и по запросу к ней выдает референс на очередную строку/столбец для решения. Потоки после решения очередной задачи обращаются к структуре заново, чтобы решать что-то еще. Какую-то задачу-нонограмму в принципе можно начать решать, не закончив предыдущей, например когда эта структура занимается взаимным AND всех клеток, и тогда какие-то потоки свободны и ничего не делают. Еще распараллеливание можно провести на графическом процессоре через CUDA — вариантов много.
- Использование классических структур данных. Обратите внимание — когда я показывал псевдокод решения для цветных нонограмм, функции CanInsertColor и PlaceColor работают вовсе не за , в отличие от черно-белых нонограмм. Выглядит в программе это так:
bool OneLineSolver::CanPlaceColor(const vector<int>& cells, int color, int lbound, int rbound) { // Went out of the border if (rbound >= cells.size()) { return false; } // We can paint a block of cells with a certain color if and only if it is // possible for all cells to have this color (that means, if every cell // from the block has color-th bit set to 1) int mask = 1 << color; for (int i = lbound; i <= rbound; ++i) { if (!(cells[i] & mask)) { return false; } } return true; } void OneLineSolver::SetPlaceColor(int color, int lbound, int rbound) { // Every cell from the block now can have this color for (int i = lbound; i <= rbound; ++i) { result_cells_[i] |= (1 << color); } }
То есть работает за линию, за  (Позже будет объяснение смысла именно такого кода).
(Позже будет объяснение смысла именно такого кода).
Посмотрим, как можно получить лучшую сложность. Возьмем CanPlaceColor. Эта функция проверяет, что среди всех чисел вектора в отрезке ![$[lbound, rbound]$](https://habrastorage.org/getpro/habr/formulas/4a3/7cc/a6b/4a37cca6b014ffcd18897f2ee518129a.svg) бит номер
бит номер  установлен в 1. Эквивалентно этому можно взять
установлен в 1. Эквивалентно этому можно взять  всех чисел этого отрезка и проверить бит номер . Используя тот факт, что операция коммутативная, также как сумма, минимум/максимум, произведение, или операция
всех чисел этого отрезка и проверить бит номер . Используя тот факт, что операция коммутативная, также как сумма, минимум/максимум, произведение, или операция  , для быстрого подсчета всего отрезка можно использовать почти любую структуру данных, работающую с коммутативными операциями на отрезке. Это:
, для быстрого подсчета всего отрезка можно использовать почти любую структуру данных, работающую с коммутативными операциями на отрезке. Это:
- SQRT-декомпозиция. Предподсчет
 , запрос . Статья на Хабре.
, запрос . Статья на Хабре. - Дерево отрезков. Предподсчет
 , запрос
, запрос  . Сотни статей в интернете.
. Сотни статей в интернете. - Разреженная таблица (Sparse Table). Предподсчет , запрос . Статья.
К сожалению, особо сильные колдунства как алгоритм Фарака-Колтона и Бендера (предподсчет , запрос ) использовать нельзя, так как вкурив статьи, можно понять, они созданы только для таких операций  , что
, что  , то есть результат коммутативной операции — один из аргументов (жаль, а так хотелось...)
, то есть результат коммутативной операции — один из аргументов (жаль, а так хотелось...)
Теперь возьмем SetPlaceColor. Тут надо произвести операцию на отрезке массива. Это тоже можно делать с SQRT-декомпозицией или деревом отрезков с ленивым обновлением (оно же "с проталкиванием"). А для обеих функций одновременно можно еще использовать убер-структуру декартово дерево по неявному ключу с обновлением и запросом за логарифм.
Еще можно использовать расширение алгоритма для черного-белого кроссворда — частичные суммы для всех цветов.
Итак, возникает вопрос — почему мы не используем все это богатство комплюктерн саенс, а делаем за линию? На это есть несколько ответов:
- Меньшая сложность вычислений не значит меньшее время работы. Алгоритм за
 может потребовать различных преподсчетов, выделений памяти, другой тряски ресурсов — у этого алгоритма может быть довольно высокая константа (не в смысле magic number в нейроночках, а аффект по времени работы). Очевидно, что если
может потребовать различных преподсчетов, выделений памяти, другой тряски ресурсов — у этого алгоритма может быть довольно высокая константа (не в смысле magic number в нейроночках, а аффект по времени работы). Очевидно, что если  , то условный алгоритм за
, то условный алгоритм за  будет работать условные 10 секунд, а условный алгоритм за условные 0.150 секунд, но все может поменяться при достаточно маленьких
будет работать условные 10 секунд, а условный алгоритм за условные 0.150 секунд, но все может поменяться при достаточно маленьких  , особенно когда таких вычислений много. Еще непонятнее, когда сложности очень похожие и одной сложности сложно перебить другую сложность (сложные приколы):
, особенно когда таких вычислений много. Еще непонятнее, когда сложности очень похожие и одной сложности сложно перебить другую сложность (сложные приколы):  versus
versus  . В нашей задаче (длина ряда) очень маленькое — в среднем около 15-30.
. В нашей задаче (длина ряда) очень маленькое — в среднем около 15-30. - Запросов может оказаться достаточно мало, чтобы предпосчеты были бесполезными и жрали ресурсы просто так.
То есть объяснение простое — оба этих пункта выполняются и вставка этих чудес программерской мысли вместо тупого алгоритма либо очень слабо оптимизирует программу, либо только увеличивает время работы из-за специфики вычислений — очень маленького и не такого большого количества запросов, чтобы они грузили процессор. Факт про запросы доказывает то, что по мнению профайлера те функции занимают ~25% и ~11% времени соответственно, то есть довольно мало для такого потенциально слабого места программы. Даже если у нас из-за этого возникает большая оценка сложности алгоритма, стоит понимать, что в таких типах задач это оценка сверху, а реальное время работы на рандомном кроссворде всегда премного ниже.
Но не стоит забывать про структуры данных — они могут пригодиться в других случаях, так что я включил их в список оптимизаций. Переходим к следующему по списку.
- Правки алгоритма. Может оказаться так, что в среднем алгоритм на этих входных данных очень неплохо начинает работать, если поменять что-то неочевидное. В нашем случае этим может быть такое: логично же предположить, что если мы успешно обновили данные в строке, то обновленные в нем клетки скорее всего "триггерят" соответствующие столбцы? Значит, лучше эти столбцы обновить быстрее всех, сразу после этой строки! То есть образуется очередь из таких подзадач. Я не пробовал именно такой алгоритм, может это реально быстрее на нашем датасете.
- Внезапные изменения техзадания (окажется, что поступают кроссворды по 1337 цветов или размером 1000x1000) тоже требуют оптимизации. Для большого количество цветов можно использовать быстрый std::bitset, для размера — те же структуры данных, и так далее.
В общем, вот такие прикольные оптимизации. "Пихание" бедного алгоритма в зависимости от условий это весело и познавательно. Можно узнать про разные крутые вещи, как встроенное декартово дерево по неявному ключу в C++ (это rope, но велосипедная писанина практически всегда работает быстрее), особые встроенные сорта деревьев и спрятанный hashtable, работающий в 3-6 раза быстрее по вставке/удалению и в 4-10 раз по записи/чтению, чем unordered_map. Не говоря уже про различные нестандартные мазафаки со стороны, например из boost.
ROFL Omitting Format Language

Вдохновившись гениями давно минувших дней и их мыслительными продуктами, в частности совершенно новыми алгоритмами архивации и операционками с нескучными обоями, я также придумал принципиально новый формат картинок, основанный на японских кроссвордах и эффекте Даннинга-Крюгера.
ROFL — рекурсивный акроним, прямо как "GNU's Not Unix". Собственно, смысл формата в том, что картинка кодируется в виде японского кроссворда, а редактор, чтобы прочитать ее, должен решить этот кроссворд. Отсюда и слово Omitting в названии — формат как бы скрывает истинное положение дел в картинке (что, кстати, может быть полезным в криптографии: можно передавать японские кроссворды с зашифрованными в нем паролями — все хакеры повесятся).
Лучше, если формат был бы похож на Matroska — в начале файла 4 байта [52][4F][46][4C], затем в трех байтах размер картинки и количество цветов, потом описание цветов, потом цвета, каждый по 3 байта, и потом описание всех групп — длина, количество клеток и цвет.
Формат свободный, лицензия MIT, финансовые отчисления добровольные — мне на кофе, как автору.
Исходники
Исходники программы лежат на GitHub. У программы есть множество возможных аргументов, генерация кроссворда из картинки, генерация картинок из кроссворда (кстати, почти все картинки в статье сгенерированы через этот код). Дополнительными библиотеками были Magick++ и args.
В репозитории картинки для кроссворда я добавил несколько примеров, взятых из интернета (они не являются частью проекта). Спарсенные тысячи с nonograms.ru никуда не выкладывал и не буду, чтобы их не потырили, потому что они могут быть защищены правами и тырятеля могут ожидать интересные последствия.
Особую благодарность хочу выразить автору nonograms.ru Чугунному К.А. KyberPrizrak, за создание прекрасного, лучшего и одного из крупнейших в интернете сайта по нонограммам, и за разрешение использовать материалы для статьи! Все примеры в этой статье я взял с nonograms.ru, вот список источников.

