Comments 20
Спасибо, очень интересно!
Идея любопытная, поэтому не очень верится, что ее опубликовали только в Астрофизическом бюллетене. Может быть кто-то уже делал что-то похожее? Или на это нет спроса в сообществе?
Идея любопытная, поэтому не очень верится, что ее опубликовали только в Астрофизическом бюллетене. Может быть кто-то уже делал что-то похожее? Или на это нет спроса в сообществе?
Здравствуйте! Изначально этот проект был создан для астрофизической школы. Моим научным руководителем был Олег Верходанов, который и является одним из авторов статьи про поиск кандидатов в скопления галактик.
Главная идея нашего проекта заключалась в использовании методов машинного обучения для эффективного поиска скоплений галактик на изображениях, что ранее не применяли в похожих исследованиях.
Главная идея нашего проекта заключалась в использовании методов машинного обучения для эффективного поиска скоплений галактик на изображениях, что ранее не применяли в похожих исследованиях.
А финальные картинки — это результат работы сети? Уж больно интересный визуальный эффект получился на правой. Не соображу сходу, как такое получить просто из изображения.
Здравствуйте! Результатом работы сети являются не изображения, а коэффициенты (в нашем случае 0,35 и 0,87).
Если коэффициент больше 0,5, на изображении галактики или их скопления. Иначе на изображении отсутствуют интересующие нас объекты.
Если коэффициент больше 0,5, на изображении галактики или их скопления. Иначе на изображении отсутствуют интересующие нас объекты.
А картинка — это то самое ортогональное разложение? Можно где-нибудь почитать, как оно делается? Какие-то мысли изображения навевают, но до конца сообразить не могу. Надо пробовать.
Вообще же тема интересная.
Вообще же тема интересная.
Информация про то, как работает GLESP здесь: cyberleninka.ru/article/n/paket-analiza-dannyh-glesp-dlya-kart-reliktovogo-izlucheniya-na-polnoy-sfere-i-ego-realizatsiya-v-ramkah-sistemy-obrabotki-fadps и здесь: cyberleninka.ru/article/n/baza-dannyh-kart-protyazhennogo-izlucheniya-i-sistema-dostupa-k-nim.
А почему вы не решали задачу сегментации, раз вам все же нужно находить сами скопления?
Получается что данный эффект позволяет отличить звезды от галактик и их скоплений на очень больших расстояниях?
Это прекрасно.
А как все же вы без учителя определяли, есть ли скопления? Как получали эти коэффициенты?
пс. изображённая на рисунке сеть это не Inception, а сильно более простая сеть типа LeNet.
Судя по схеме на выходе классификация изображений по этому коэффициенту.
Это и так можно в статье прочитать, и смысла в этом как-то не видно. На схеме обыкновенный LeNet для классификации рукописных цифр. Если выборка неразмеченная, то можно что-то интересное придумать только с автокодировщиками или подобными архитектурами, но никак не с той, что представлена.
По сути, детали исследования в статье обфусцированы, как и в большинстве научных статей.
Обучали нейросеть мы очень просто: у нас был архив из 6 135 изображений с скоплениями галактик, полученными в результате миссии Planck, и 10 000 изображений без скоплений.
И да, вы правы. Здесь будет более уместна эта схема: habrastorage.org/webt/oo/lp/11/oolp11ghgcxncno4crk9akmfnzw.jpeg
И да, вы правы. Здесь будет более уместна эта схема: habrastorage.org/webt/oo/lp/11/oolp11ghgcxncno4crk9akmfnzw.jpeg
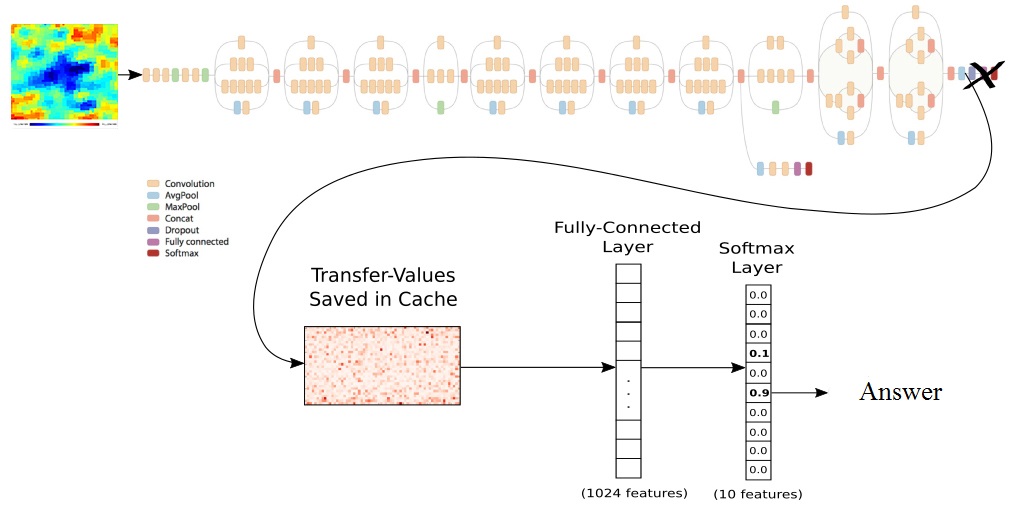{kind=link}
И чем вам для такой относительно несложной задачи edge-detection не угодил?
Можно попробовать использовать Unet + Semi-Supervised
Сетка наличие скопления галактик определяет, случайно, не по наличию плотных красных объектов на картинке? А просто удачно подобранный threshold по доли таких областей на картинке не будет ли работать лучше?
Sign up to leave a comment.
Как мы учили ИИ распознавать скопления галактик