
Эта статья — часть «Хроники архитектуры программного обеспечения», серии статей об архитектуре ПО. В них я пишу о том, что узнал об архитектуре программного обеспечения, что я думаю об этом и как использую знания. Содержание этой статьи может иметь больше смысла, если вы прочитаете предыдущие статьи в серии.
В предыдущей статье серии я опубликовал карту концептов, которая показывает отношения между типами кода.
Но мне всегда казалось, что не всё очень хорошо там отражено, я просто не знал, как сделать это лучше. Речь об общем ядре.
Кроме того, возникло ещё несколько мыслей, которые я изложу в этой небольшой статье.
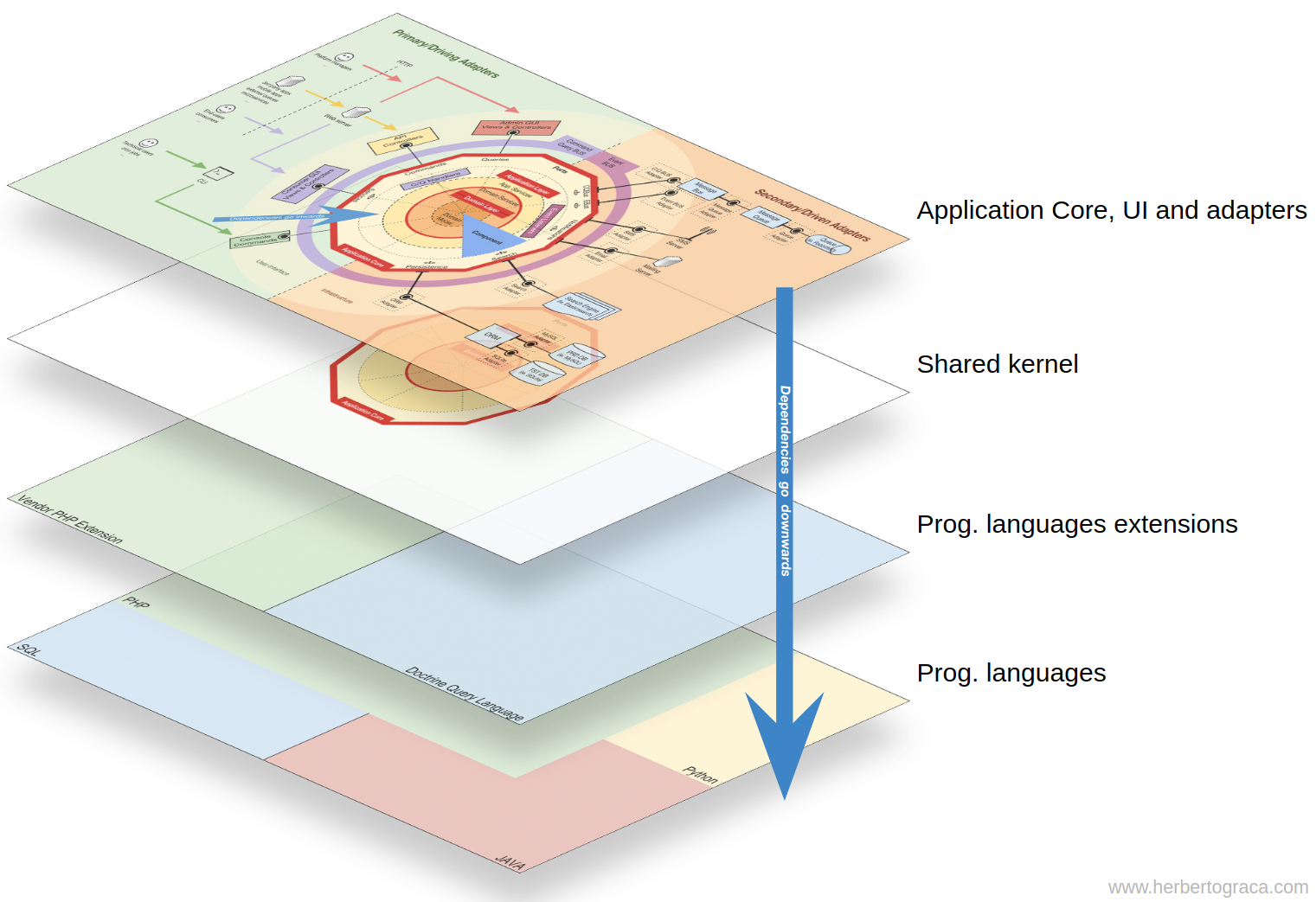
На инфографике из последней статьи в этой серии в самом центре диаграммы мы видим общее ядро. Похоже, что оно находится внутри доменного слоя и выше конических разделов, которые представляют собой ограниченные контексты.

Несмотря на его расположение, я не имел в виду, что общее ядро зависит от остальной части кода или что общее ядро является ещё одним слоем внутри уровня домена.
Что такое общее ядро?!
Общее ядро, по определению Эрика Эванса, отца DDD, является кодом, который команда разработчиков решает разделить между несколькими ограниченными контекстами:
[...] некоторое подмножество модели домена, которое две команды договорились использовать совместно. Конечно, наряду с этим подмножеством модели, общее ядро включает в себя подмножество кода или архитектуры базы данных, связанной с этой частью модели. Этот явно общий материал имеет особый статус и не должен изменяться без консультации с другой командой.
— «Общее ядро», вики по DDD от Уорда Каннингема
Таким образом, это может быть любой тип кода: код доменного уровня, код прикладного уровня, библиотеки… что угодно.

Однако в контексте нашей карты концептов я представляю его как подмножество, как конкретный тип кода. В моей карте концептов общее ядро содержит код уровней домена и приложения, который совместно используется в ограниченных контекстах, чтобы была возможной связь между ограниченными контекстами.
Например, это означает, что события запускаются в одном или нескольких ограниченных контекстах и прослушиваются в других ограниченных контекстах. Вместе с этими событиями нам необходимо совместно использовать все типы данных, которые используются этими событиями, например: идентификаторы сущностей, объекты значений, перечисления и т. д. Сложные объекты, такие как сущности, не должны использоваться событиями напрямую, так как их может быть трудно сериализовать/десериализовать в/из очереди, поэтому общий код не должен сильно распространяться.
Конечно, если у нас многоязычная система из микросервисов, то общее ядро должно быть описательным, на JSON, XML, YAML и т.д., чтобы все микросервисы могли его понять.
В результате это общее ядро полностью отделено от остальной части кодовой базы, от компонентов. Это здорово, ведь тогда компоненты, хотя и связаны с общим ядром, отделены друг от друга. Общий код явно идентифицируется и легко извлекается в отдельную библиотеку.
Это также очень удобно, если мы решаем извлечь один из ограниченных контекстов в микросервис, отделённый от монолита. Мы точно знаем, что является общим и можем просто извлечь общее ядро в библиотеку, которая будет установлена как в монолит, так и в микросервис.
Итак, подводя итог, в моей карте концептов ядро приложения зависит от общего ядра, которое содержит код из уровней домена и приложения, который совместно используется ограниченными контекстами.
Когда языка недостаточно…
Итак, у нас есть код приложения со всеми концентрическими слоями, а ядро приложения зависит от общего ядра, которое находится под всем этим кодом.
Мы также можем сказать, что весь этот код зависит от используемого языка(ов) программирования, но это настолько очевидный факт, что мы склонны полностью игнорировать его.
Однако возникает вопрос: «Что делать, если языковых конструкций недостаточно?!» Ну, очевидно, мы сами создаем эти языковые конструкции и таким образом компенсируем недостатки языка. Но у меня есть важные последующие вопросы: «Как и где обосновать существование этого кода? Как можно чётко указать, когда и каким образом его использовать?».
Что я видел и делал сам — это пакет под названием Utils или Commons, где размещён этот код. Но в итоге заканчивается тем, что мы сбрасываем туда весь код, который не знаем, куда положить! Все виды кода разного назначения и удобства использования (завёрнутый в адаптер, используемый напрямую...) в конечном итоге сбрасываются туда. У пакета нет концептуального значения, никакой согласованности, никакой связности, никакой ясности, много двусмысленностей.
Я хочу отказаться от пакетов Utils и Commons!
У всех пакетов должна быть концептуальная сплочённость! Должно быть ясно, когда и как использовать пакет! Никакой двусмысленности!
Например, если приложение каким-то особым способом взаимодействует с интерфейсом командной строки, то вместо размещения в пространстве имён ‘Acme/Util/SpecialCli’ можно поместить его в ‘Acme/App/Infrastructure/Cli/SpecialCli’. Это говорит, что данный пакет связан с CLI, он является частью инфраструктуры приложения App компании Acme. Принадлежность к инфраструктуре App также говорит, что в ядре приложения есть порт, которому соответствует этот пакет.
Как вариант, если мы видим этот пакет как нечто такое, чего не хватает самому языку, можно поместить его в соответствующее пространство имён, например ‘Acme/PhpExtension/SpecialCli’. Это показывает, что данный пакет следует рассматривать как часть самого языка, и поэтому его код должен использоваться непосредственно в базе кода как любая языковая конструкция. Конечно, если другая компания зависит от этого пакета, для них может быть разумным не зависеть непосредственно от него, а безопаснее создать порт/адаптер, чтобы они могли поменять его на что-то другое. Но если мы владеем пакетом, то можем рассматривать его как часть языка, поскольку риск необходимости замены его на другую альтернативу не так уж велик. Всегда дело в компромиссах.
Ещё один пример того, что можно рассмотреть как часть языка — уникальные идентификаторы UUID в PHP. Их вполне можно представить вне языка, потому что там каждый раз новая версия и это кошмар с поддержкой кода, но это вполне общая концепция, широкое и достаточно последовательное понятие, чтобы являться частью языка.
Так почему бы не создать реализацию UUID и не использовать её, словно часть самого PHP, как мы используем объект DateTime?! Пока мы контролируем реализацию, я не вижу никаких недостатков.
Как насчет Doctrine Query Language (DQL)? (Doctrine — это порт Hibernate на PHP) можем ли мы рассматривать DQL, как будто это SQL, Elasticsearch QL или Mongo QL?
Вывод
Итак, на макроуровне я вижу четыре основных типа кода и думаю, что важно явно проявить их в организации кодовой базы, чтобы в итоге не остаться с большой кучей грязи.
Для меня неоспоримая истина, что архитектура всегда существует, вопрос только в том, контролируем мы её или нет?!
Так что давайте чётко организуем код в соответствии с архитектурой, полностью или частично по карте концептов — моей или другой. Главное, логично организовать код, чтобы проект явным образом сообщал о своей архитектуре через структуру и организацию кода.
