Во всех задачах обучения искусственного интеллекта присутствует одно пренеприятнейшее явление — ошибки в разметке обучающей последовательности. Ошибки эти неизбежны, так как вся разметка производится вручную, ибо если есть способ разметить реальные данные программно, то зачем нам ещё кого-то учить их размечать и тратить время и деньги на создание абсолютно ненужной конструкции!
Задача найти и удалить фейковые маски в большой обучающей последовательности достаточно сложна. Можно просмотреть их все вручную, но и это не спасёт от повторных ошибок. Но если внимательно приглядеться к предложенным в предыдущих постах инструментам исследования нейронных сетей, то оказывается есть простой и эффективный способ обнаружить и извлечь все артефакты из обучающей последовательности.
И в этом посте есть конкретный пример, очевидно, что простой, на эллипсах и полигонах, для обычной U-net, опять такое лего в песочнице, но необычайно конкретный, полезный и эффективный. Мы покажем как простой метод выявляет и находит почти все артефакты, всю ложь обучающей последовательности.

Итак, начнём!
Как и ранее, мы будем изучать последовательности пар картинка/маска. На картинке в разных четвертях, выбранных случайно, будем размещать эллипс случайного размера и четырёхугольник тоже произвольного размера и оба окраcим в один цвет, тоже случайно выбранный их двух. Во второй оставшийся цвет окрасим фон. Размеры и эллипса и четырёхугольника конечно же ограничены.
Но в данном случае внесём в программу генерации пар изменения и подготовим вместе с полностью правильной маской ещё и неправильную, отравленную ложью — в приблизительно одном проценте случаев заменим в маске четырёхугольник на эллипс, т.е. истинным объектом для сегментации обозначим на ложных масках эллипс, а не четырёхугольник.
Примеры случайных 10

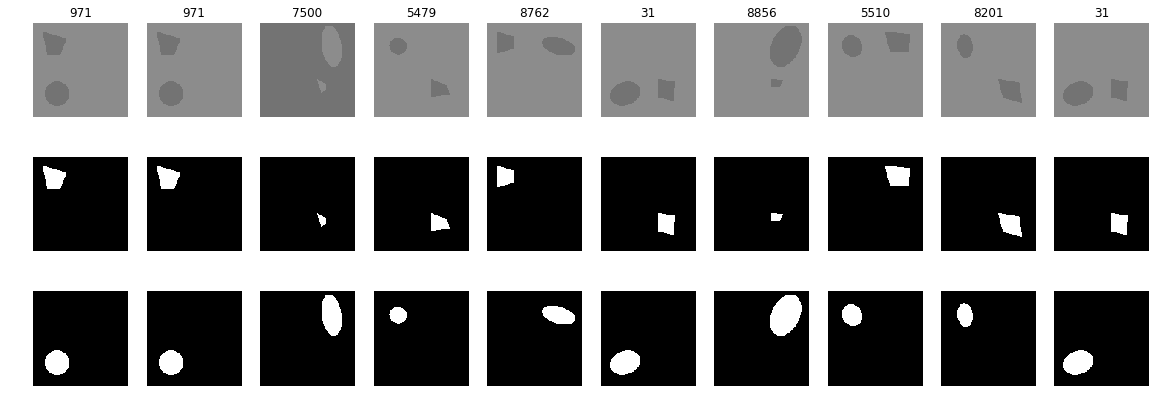
Примеры случайных 10, но из ошибочной разметки. Верхняя маска истинная, нижняя ложная и на картинках указаны номера в обучающей последовательности.
для сегментации возьмём те же самые программы расчёта метрики и потерь и ту же простую U-net, только не будем использовать Dropout.
Программа генерации картинок и масок — истинной и фальшивой. В массив помещается первым слоем картинка, вторым истинная маска и третьим слоем ложная маска.
Основная программа расчётов. Мы внесли небольшие изменения в такую же программу из предыдущего поста и некоторые переменные требуют пояснений и комментария.
Тут находится индикатор ложности маски. Если 1, то маска из F_msks не совпадает с маской из f_msks. Это индикатор того, что мы собственно и будем искать — ложные маски.
Индикатор того, что эта картинка отобрана в шпаргалку.
Строим последовательности пар картинка/маска для тренировки и ещё одну последовательность для проверки. Т.е. проверять будем на новой, независимой последовательности в 10000 пар. Выводим на экран и визуально выборочно проверяем случайные картинки с истинной и ложной масками. Сами картинки выше показаны.
В данном конкретном случае получились 93 фальшивые маски, на которых в качестве true positive отмечен эллипс, а не четырёхугольник.
Запускаем тренировку на правильном множестве, в качестве маски используем f_msks
Шпаргалка получилась всего в 404 картинки и на независимой тестовой последовательности получили приемлемую точность.
Теперь заново компилируем сеть и тренируем на той же самой обучающей последовательности, но в качестве масок подаем на вход F_msks с 1% ложных масок
Получили шпаргалку в 727 картинок, что существенно больше и точность предсказаний тестовой, той же самой, что в предыдущем тесте последовательности, снизилась с 0.98953 до 0.9525. Мы добавили лжи в тренировочную последовательность меньше чем на 1%, всего 93 маски из 10000 были ложью, но результат ухудшился на 3.7%. И это уже не просто ложь, это самое настоящее коварство! И шпаргалка увеличилась с всего 404 до уже 727 картинок.
Успокаивает и радует только одно
Поясню эту длинную формулу, мы берём пересечение множества выбранных в шпаргалку картинок с множеством ложных картинок и видим, что все 93 ложные картинки алгоритм выбрал в шпаргалку.
Задача упростилась существенно, это не 10000 картинок просматривать вручную, это всего 727 и вся ложь концентрировано сосредоточена тут.
Но есть и ещё интересней и полезней способ. Мы, когда составляли шпаргалку, включали в неё только те пары картинка/маска, чьё предсказание меньше порога и нашем данном конкретном случае мы сохраняли значение точности предсказания в массив v_false. Посмотрим пары из обучающей последовательности у которых очень маленькое значение предсказания, например меньше чем 0.1 и посмотрим, сколько там лжи
Как видим основная часть из ложных масок, 89 из 93, попала в эти маски
Таким образом, если проверить всего 382 маски вручную, и это из 10 000 штук, большая часть ложных масок будет нами выявлена и уничтожена без какой-либо жалости.
Если же есть возможность просматривать картинки и маски во время принятия решения об их включении в состав шпаргалки, то начиная с некоторого шага, все ложные маски, всё вранье будет определяться минимальным уровнем предсказания уже немного обученной сети, а правильные маски будут иметь предсказание больше этого уровня.
Если в каком-то придуманном мире истина всегда четырёхугольная, а ложь овальная и какая-то неизвестная сущность решила исказить правду и назвала некоторые эллипсы истиной, а четырёхугольники ложью, то, воспользовавшись искусственным интеллектом и природным умением составлять шпаргалки, местная инквизиция быстро и легко найдёт и искоренит ложь и коварство полностью и подчистую.
P.S. Умение детектить овалы, треугольники, простые полигоны является необходимым условием создания любого ИИ, управляющего автомобилем. Не умеете искать овалы и треугольники — не найдете все дорожные знаки и уедет ваш ИИ на автомобиле не туда.
Задача найти и удалить фейковые маски в большой обучающей последовательности достаточно сложна. Можно просмотреть их все вручную, но и это не спасёт от повторных ошибок. Но если внимательно приглядеться к предложенным в предыдущих постах инструментам исследования нейронных сетей, то оказывается есть простой и эффективный способ обнаружить и извлечь все артефакты из обучающей последовательности.
И в этом посте есть конкретный пример, очевидно, что простой, на эллипсах и полигонах, для обычной U-net, опять такое лего в песочнице, но необычайно конкретный, полезный и эффективный. Мы покажем как простой метод выявляет и находит почти все артефакты, всю ложь обучающей последовательности.
Итак, начнём!
Как и ранее, мы будем изучать последовательности пар картинка/маска. На картинке в разных четвертях, выбранных случайно, будем размещать эллипс случайного размера и четырёхугольник тоже произвольного размера и оба окраcим в один цвет, тоже случайно выбранный их двух. Во второй оставшийся цвет окрасим фон. Размеры и эллипса и четырёхугольника конечно же ограничены.
Но в данном случае внесём в программу генерации пар изменения и подготовим вместе с полностью правильной маской ещё и неправильную, отравленную ложью — в приблизительно одном проценте случаев заменим в маске четырёхугольник на эллипс, т.е. истинным объектом для сегментации обозначим на ложных масках эллипс, а не четырёхугольник.
Примеры случайных 10
Примеры случайных 10, но из ошибочной разметки. Верхняя маска истинная, нижняя ложная и на картинках указаны номера в обучающей последовательности.
для сегментации возьмём те же самые программы расчёта метрики и потерь и ту же простую U-net, только не будем использовать Dropout.
Библиотеки
import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import NoNorm %matplotlib inline import math from tqdm import tqdm #from joblib import Parallel, delayed from skimage.draw import ellipse, polygon from keras import Model from keras.optimizers import Adam from keras.layers import Input,Conv2D,Conv2DTranspose,MaxPooling2D,concatenate from keras.layers import BatchNormalization,Activation,Add,Dropout from keras.losses import binary_crossentropy from keras import backend as K from keras.models import load_model import tensorflow as tf import keras as keras w_size = 128 train_num = 10000 radius_min = 10 radius_max = 30
Функции метрики и потерь
def dice_coef(y_true, y_pred): y_true_f = K.flatten(y_true) y_pred = K.cast(y_pred, 'float32') y_pred_f = K.cast(K.greater(K.flatten(y_pred), 0.5), 'float32') intersection = y_true_f * y_pred_f score = 2. * K.sum(intersection) / (K.sum(y_true_f) + K.sum(y_pred_f)) return score def dice_loss(y_true, y_pred): smooth = 1. y_true_f = K.flatten(y_true) y_pred_f = K.flatten(y_pred) intersection = y_true_f * y_pred_f score = (2. * K.sum(intersection) + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth) return 1. - score def bce_dice_loss(y_true, y_pred): return binary_crossentropy(y_true, y_pred) + dice_loss(y_true, y_pred) def get_iou_vector(A, B): # Numpy version batch_size = A.shape[0] metric = 0.0 for batch in range(batch_size): t, p = A[batch], B[batch] true = np.sum(t) pred = np.sum(p) # deal with empty mask first if true == 0: metric += (pred == 0) continue # non empty mask case. Union is never empty # hence it is safe to divide by its number of pixels intersection = np.sum(t * p) union = true + pred - intersection iou = intersection / union # iou metrric is a stepwise approximation of the real iou over 0.5 iou = np.floor(max(0, (iou - 0.45)*20)) / 10 metric += iou # teake the average over all images in batch metric /= batch_size return metric def my_iou_metric(label, pred): # Tensorflow version return tf.py_func(get_iou_vector, [label, pred > 0.5], tf.float64) from keras.utils.generic_utils import get_custom_objects get_custom_objects().update({'bce_dice_loss': bce_dice_loss }) get_custom_objects().update({'dice_loss': dice_loss }) get_custom_objects().update({'dice_coef': dice_coef }) get_custom_objects().update({'my_iou_metric': my_iou_metric })
Обычная U-net
def build_model(input_layer, start_neurons): # 128 -> 64 conv1 = Conv2D(start_neurons * 1, (3, 3), activation="relu", padding="same")(input_layer) conv1 = Conv2D(start_neurons * 1, (3, 3), activation="relu", padding="same")(conv1) pool1 = Conv2D(start_neurons * 1, (2, 2), strides=(2, 2), activation="relu", padding="same")(conv1) # pool1 = Dropout(0.25)(pool1) # 64 -> 32 conv2 = Conv2D(start_neurons * 2, (3, 3), activation="relu", padding="same")(pool1) conv2 = Conv2D(start_neurons * 2, (3, 3), activation="relu", padding="same")(conv2) pool2 = Conv2D(start_neurons * 1, (2, 2), strides=(2, 2), activation="relu", padding="same")(conv2) # pool2 = Dropout(0.5)(pool2) # 32 -> 16 conv3 = Conv2D(start_neurons * 4, (3, 3), activation="relu", padding="same")(pool2) conv3 = Conv2D(start_neurons * 4, (3, 3), activation="relu", padding="same")(conv3) pool3 = Conv2D(start_neurons * 1, (2, 2), strides=(2, 2), activation="relu", padding="same")(conv3) # pool3 = Dropout(0.5)(pool3) # 16 -> 8 conv4 = Conv2D(start_neurons * 8, (3, 3), activation="relu", padding="same")(pool3) conv4 = Conv2D(start_neurons * 8, (3, 3), activation="relu", padding="same")(conv4) pool4 = Conv2D(start_neurons * 1, (2, 2), strides=(2, 2), activation="relu", padding="same")(conv4) # pool4 = Dropout(0.5)(pool4) # Middle convm = Conv2D(start_neurons * 16, (3, 3), activation="relu", padding="same")(pool4) convm = Conv2D(start_neurons * 16, (3, 3) , activation="relu", padding="same")(convm) # 8 -> 16 deconv4 = Conv2DTranspose(start_neurons * 8, (3, 3), strides=(2, 2), padding="same")(convm) uconv4 = concatenate([deconv4, conv4]) # uconv4 = Dropout(0.5)(uconv4) uconv4 = Conv2D(start_neurons * 8, (3, 3) , activation="relu", padding="same")(uconv4) uconv4 = Conv2D(start_neurons * 8, (3, 3) , activation="relu", padding="same")(uconv4) # 16 -> 32 deconv3 = Conv2DTranspose(start_neurons * 4, (3, 3), strides=(2, 2), padding="same")(uconv4) uconv3 = concatenate([deconv3, conv3]) # uconv3 = Dropout(0.5)(uconv3) uconv3 = Conv2D(start_neurons * 4, (3, 3) , activation="relu", padding="same")(uconv3) uconv3 = Conv2D(start_neurons * 4, (3, 3) , activation="relu", padding="same")(uconv3) # 32 -> 64 deconv2 = Conv2DTranspose(start_neurons * 2, (3, 3), strides=(2, 2), padding="same")(uconv3) uconv2 = concatenate([deconv2, conv2]) # uconv2 = Dropout(0.5)(uconv2) uconv2 = Conv2D(start_neurons * 2, (3, 3) , activation="relu", padding="same")(uconv2) uconv2 = Conv2D(start_neurons * 2, (3, 3) , activation="relu", padding="same")(uconv2) # 64 -> 128 deconv1 = Conv2DTranspose(start_neurons * 1, (3, 3), strides=(2, 2), padding="same")(uconv2) uconv1 = concatenate([deconv1, conv1]) # uconv1 = Dropout(0.5)(uconv1) uconv1 = Conv2D(start_neurons * 1, (3, 3) , activation="relu", padding="same")(uconv1) uconv1 = Conv2D(start_neurons * 1, (3, 3) , activation="relu", padding="same")(uconv1) # uncov1 = Dropout(0.5)(uconv1) output_layer = Conv2D(1, (1,1), padding="same", activation="sigmoid")(uconv1) return output_layer input_layer = Input((w_size, w_size, 1)) output_layer = build_model(input_layer, 27) model = Model(input_layer, output_layer) model.compile(loss=bce_dice_loss, optimizer=Adam(lr=1e-4), metrics=[my_iou_metric]) model.summary()
Программа генерации картинок и масок — истинной и фальшивой. В массив помещается первым слоем картинка, вторым истинная маска и третьим слоем ложная маска.
def next_pair_f(idx): img_l = np.ones((w_size, w_size, 1), dtype='float')*0.45 img_h = np.ones((w_size, w_size, 1), dtype='float')*0.55 img = np.zeros((w_size, w_size, 3), dtype='float') i0_qua = math.trunc(np.random.sample()*4.) i1_qua = math.trunc(np.random.sample()*4.) while i0_qua == i1_qua: i1_qua = math.trunc(np.random.sample()*4.) _qua = np.int(w_size/4) qua = np.array([[_qua,_qua],[_qua,_qua*3],[_qua*3,_qua*3],[_qua*3,_qua]]) p = np.random.sample() - 0.5 r = qua[i0_qua,0] c = qua[i0_qua,1] r_radius = np.random.sample()*(radius_max-radius_min) + radius_min c_radius = np.random.sample()*(radius_max-radius_min) + radius_min rot = np.random.sample()*360 rr, cc = ellipse( r, c, r_radius, c_radius, rotation=np.deg2rad(rot), shape=img_l.shape ) p0 = np.rint(np.random.sample()*(radius_max-radius_min) + radius_min) p1 = qua[i1_qua,0] - (radius_max-radius_min) p2 = qua[i1_qua,1] - (radius_max-radius_min) p3 = np.rint(np.random.sample()*radius_min) p4 = np.rint(np.random.sample()*radius_min) p5 = np.rint(np.random.sample()*radius_min) p6 = np.rint(np.random.sample()*radius_min) p7 = np.rint(np.random.sample()*radius_min) p8 = np.rint(np.random.sample()*radius_min) poly = np.array(( (p1, p2), (p1+p3, p2+p4+p0), (p1+p5+p0, p2+p6+p0), (p1+p7+p0, p2+p8), (p1, p2), )) rr_p, cc_p = polygon(poly[:, 0], poly[:, 1], img_l.shape) if p > 0: img[:,:,:1] = img_l.copy() img[rr, cc,:1] = img_h[rr, cc] img[rr_p, cc_p,:1] = img_h[rr_p, cc_p] else: img[:,:,:1] = img_h.copy() img[rr, cc,:1] = img_l[rr, cc] img[rr_p, cc_p,:1] = img_l[rr_p, cc_p] img[:,:,1] = 0. img[:,:,1] = 0. img[rr_p, cc_p,1] = 1. img[:,:,2] = 0. p_f = np.random.sample()*1000. if p_f > 10: img[rr_p, cc_p,2] = 1. else: img[rr, cc,2] = 1. i_false[idx] = 1 return img
Программа расчета шпаргалки
def make_sh(f_imgs, f_msks, val_len): precision = 0.85 batch_size = 50 t = tqdm() t_batch_size = 50 raw_len = val_len id_train = 1 #id_select = 1 v_false = np.zeros((train_num), dtype='float') while True: if id_train == 1: fit = model.fit(f_imgs[m2_select>0], f_msks[m2_select>0], batch_size=batch_size, epochs=1, verbose=0 ) current_accu = fit.history['my_iou_metric'][0] current_loss = fit.history['loss'][0] if current_accu > precision: id_train = 0 else: t_pred = model.predict( f_imgs[raw_len: min(raw_len+t_batch_size,f_imgs.shape[0])], batch_size=batch_size ) for kk in range(t_pred.shape[0]): val_iou = get_iou_vector( f_msks[raw_len+kk].reshape(1,w_size,w_size,1), t_pred[kk].reshape(1,w_size,w_size,1) > 0.5) v_false[raw_len+kk] = val_iou if val_iou < precision*0.95: new_img_test = 1 m2_select[raw_len+kk] = 1 val_len += 1 break raw_len += (kk+1) id_train = 1 t.set_description("Accuracy {0:6.4f} loss {1:6.4f} selected img {2:5d} tested img {3:5d} ". format(current_accu, current_loss, val_len, raw_len)) t.update(1) if raw_len >= train_num: break t.close() return v_false
Основная программа расчётов. Мы внесли небольшие изменения в такую же программу из предыдущего поста и некоторые переменные требуют пояснений и комментария.
i_false = np.zeros((train_num), dtype='int')
Тут находится индикатор ложности маски. Если 1, то маска из F_msks не совпадает с маской из f_msks. Это индикатор того, что мы собственно и будем искать — ложные маски.
m2_select = np.zeros((train_num), dtype='int')
Индикатор того, что эта картинка отобрана в шпаргалку.
batch_size = 50 val_len = batch_size + 1 # i_false - false mask marked as 1 i_false = np.zeros((train_num), dtype='int') # t_imgs, t_msks -test images and masks _txy = [next_pair_f(idx) for idx in range(train_num)] t_imgs = np.array(_txy)[:,:,:,:1].reshape(-1,w_size ,w_size ,1) t_msks = np.array(_txy)[:,:,:,1].reshape(-1,w_size ,w_size ,1) # m2_select - initial 51 pair m2_select = np.zeros((train_num), dtype='int') for k in range(val_len): m2_select[k] = 1 # i_false - false mask marked as 1 i_false = np.zeros((train_num), dtype='int') _txy = [next_pair_f(idx) for idx in range(train_num)] f_imgs = np.array(_txy)[:,:,:,:1].reshape(-1,w_size ,w_size ,1) f_msks = np.array(_txy)[:,:,:,1].reshape(-1,w_size ,w_size ,1) # F_msks - mask array with ~1% false mask F_msks = np.array(_txy)[:,:,:,2].reshape(-1,w_size ,w_size ,1) fig, axes = plt.subplots(2, 10, figsize=(20, 5)) for k in range(10): kk = np.random.randint(train_num) axes[0,k].set_axis_off() axes[0,k].imshow(f_imgs[kk].squeeze(), cmap="gray", norm=NoNorm()) axes[1,k].set_axis_off() axes[1,k].imshow(f_msks[kk].squeeze(), cmap="gray", norm=NoNorm()) plt.show(block=True) false_num = np.arange(train_num)[i_false>0] fig, axes = plt.subplots(3, 10, figsize=(20, 7)) for k in range(10): kk = np.random.randint(false_num.shape[0]) axes[0,k].set_axis_off() axes[0,k].set_title(false_num[kk]) axes[0,k].imshow(f_imgs[false_num[kk]].squeeze(), cmap="gray", norm=NoNorm()) axes[1,k].set_axis_off() axes[1,k].imshow(f_msks[false_num[kk]].squeeze(), cmap="gray", norm=NoNorm()) axes[2,k].set_axis_off() axes[2,k].imshow(F_msks[false_num[kk]].squeeze(), cmap="gray", norm=NoNorm()) plt.show(block=True)
Строим последовательности пар картинка/маска для тренировки и ещё одну последовательность для проверки. Т.е. проверять будем на новой, независимой последовательности в 10000 пар. Выводим на экран и визуально выборочно проверяем случайные картинки с истинной и ложной масками. Сами картинки выше показаны.
В данном конкретном случае получились 93 фальшивые маски, на которых в качестве true positive отмечен эллипс, а не четырёхугольник.
Запускаем тренировку на правильном множестве, в качестве маски используем f_msks
input_layer = Input((w_size, w_size, 1)) output_layer = build_model(input_layer, 25) model = Model(input_layer, output_layer) model.compile(loss=bce_dice_loss, optimizer=Adam(lr=1e-4), metrics=[my_iou_metric]) v_false = make_sh(f_imgs, f_msks, val_len) t_pred = model.predict(t_imgs,batch_size=batch_size) print (get_iou_vector(t_msks,t_pred.reshape(-1,w_size ,w_size ,1)))
Accuracy 0.9807 loss 0.0092 selected img 404 tested img 10000 : : 1801it [08:13, 3.65it/s] 0.9895299999999841
Шпаргалка получилась всего в 404 картинки и на независимой тестовой последовательности получили приемлемую точность.
Теперь заново компилируем сеть и тренируем на той же самой обучающей последовательности, но в качестве масок подаем на вход F_msks с 1% ложных масок
input_layer = Input((w_size, w_size, 1)) output_layer = build_model(input_layer, 25) model = Model(input_layer, output_layer) model.compile(loss=bce_dice_loss, optimizer=Adam(lr=1e-4), metrics=[my_iou_metric]) v_false = make_sh(f_imgs, F_msks, val_len) t_pred = model.predict(t_imgs,batch_size=batch_size) print (get_iou_vector(t_msks,t_pred.reshape(-1,w_size ,w_size ,1)))
Accuracy 0.9821 loss 0.0324 selected img 727 tested img 10000 : : 1679it [25:44, 1.09it/s] 0.9524099999999959
Получили шпаргалку в 727 картинок, что существенно больше и точность предсказаний тестовой, той же самой, что в предыдущем тесте последовательности, снизилась с 0.98953 до 0.9525. Мы добавили лжи в тренировочную последовательность меньше чем на 1%, всего 93 маски из 10000 были ложью, но результат ухудшился на 3.7%. И это уже не просто ложь, это самое настоящее коварство! И шпаргалка увеличилась с всего 404 до уже 727 картинок.
Успокаивает и радует только одно
print (len(set(np.arange(train_num)[m2_select>0]).intersection(set(np.arange(train_num)[i_false>0])))) 93
Поясню эту длинную формулу, мы берём пересечение множества выбранных в шпаргалку картинок с множеством ложных картинок и видим, что все 93 ложные картинки алгоритм выбрал в шпаргалку.
Задача упростилась существенно, это не 10000 картинок просматривать вручную, это всего 727 и вся ложь концентрировано сосредоточена тут.
Но есть и ещё интересней и полезней способ. Мы, когда составляли шпаргалку, включали в неё только те пары картинка/маска, чьё предсказание меньше порога и нашем данном конкретном случае мы сохраняли значение точности предсказания в массив v_false. Посмотрим пары из обучающей последовательности у которых очень маленькое значение предсказания, например меньше чем 0.1 и посмотрим, сколько там лжи
print (len(set(np.arange(train_num)[v_false<0.01]).intersection(set(np.arange(train_num)[i_false>0])))) 89
Как видим основная часть из ложных масок, 89 из 93, попала в эти маски
np.arange(train_num)[v_false<0.01].shape (382,)
Таким образом, если проверить всего 382 маски вручную, и это из 10 000 штук, большая часть ложных масок будет нами выявлена и уничтожена без какой-либо жалости.
Если же есть возможность просматривать картинки и маски во время принятия решения об их включении в состав шпаргалки, то начиная с некоторого шага, все ложные маски, всё вранье будет определяться минимальным уровнем предсказания уже немного обученной сети, а правильные маски будут иметь предсказание больше этого уровня.
Подведём итоги
Если в каком-то придуманном мире истина всегда четырёхугольная, а ложь овальная и какая-то неизвестная сущность решила исказить правду и назвала некоторые эллипсы истиной, а четырёхугольники ложью, то, воспользовавшись искусственным интеллектом и природным умением составлять шпаргалки, местная инквизиция быстро и легко найдёт и искоренит ложь и коварство полностью и подчистую.
P.S. Умение детектить овалы, треугольники, простые полигоны является необходимым условием создания любого ИИ, управляющего автомобилем. Не умеете искать овалы и треугольники — не найдете все дорожные знаки и уедет ваш ИИ на автомобиле не туда.
