В этой статье я представляю новую квазислучайную последовательность с низким расхождением, обеспечивающую значительное улучшение по сравнению с современными последовательностями, например, Соболя, Нидеррайтера и т.д.
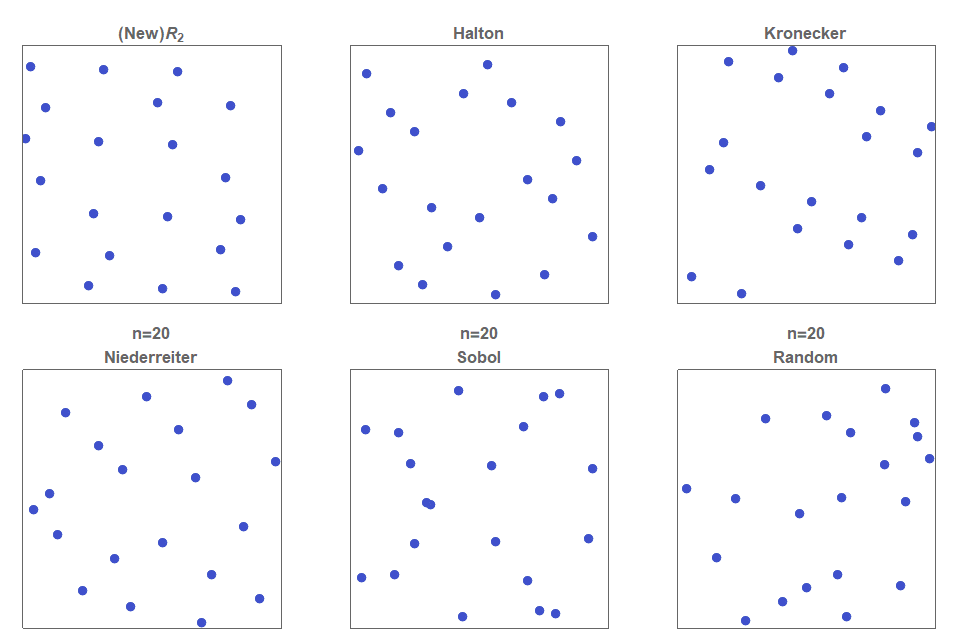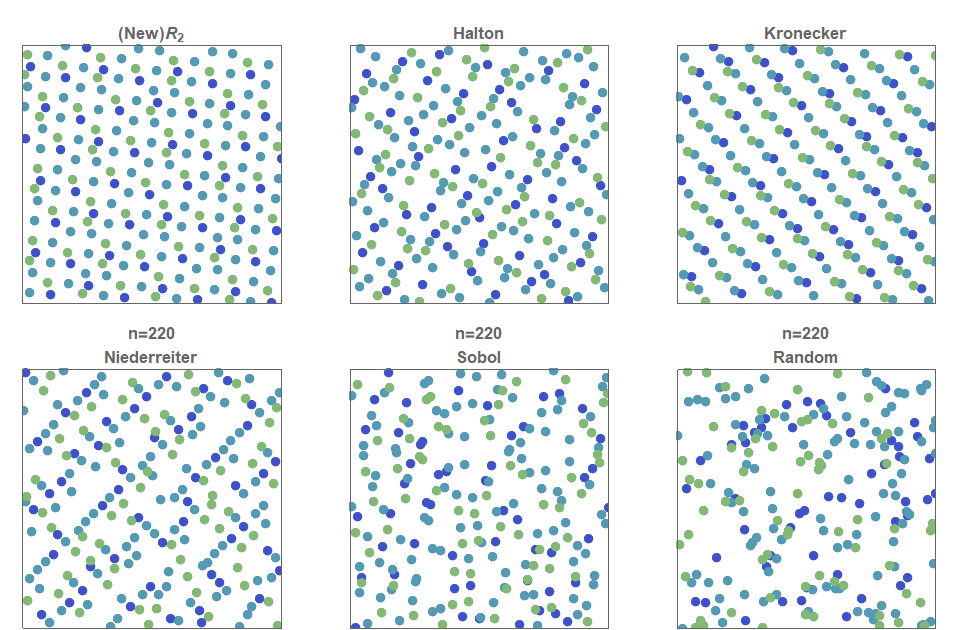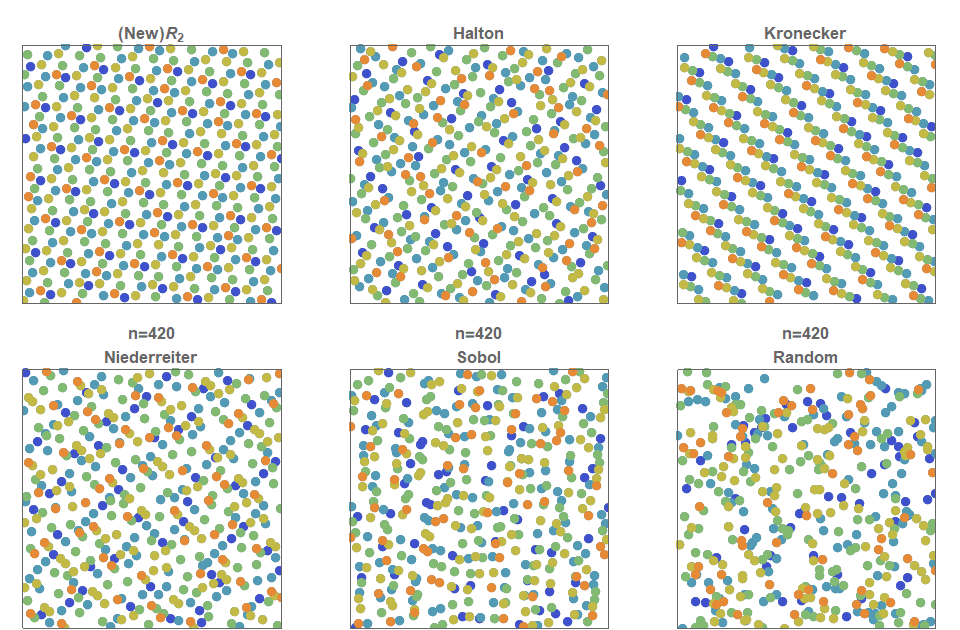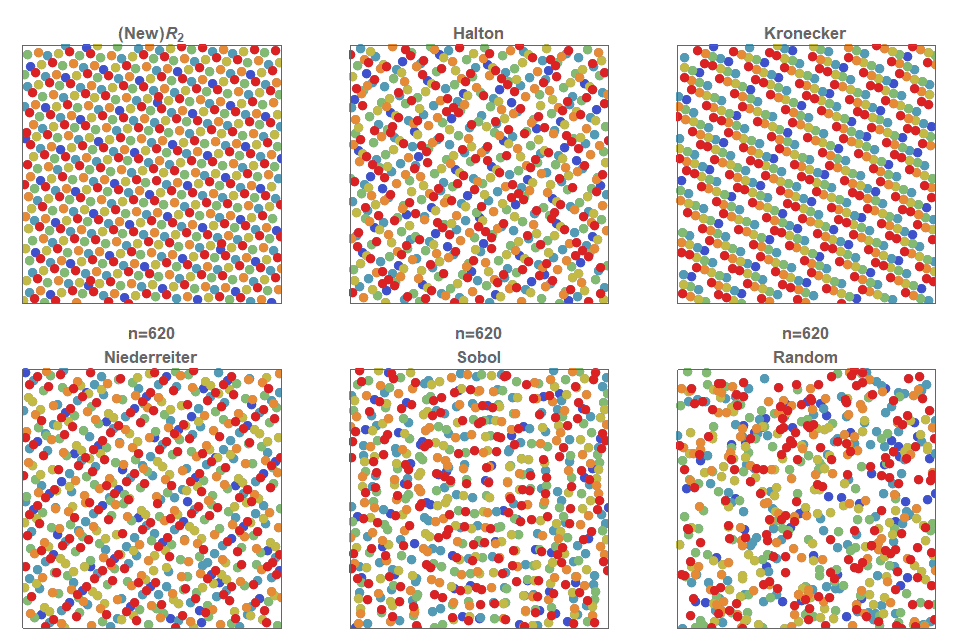
Рисунок 1. Сравнение различных квазислучайных последовательностей с низким расхождением. Заметьте, что предлагаемая мной -последовательность создаёт более равномерно распределённые точки, чем все остальные методы. Более того, все остальные методы требуют тщательного подбора базовых параметров, а в случае неправильного подбора приводят к вырожденности (например справа вверху)
-последовательность создаёт более равномерно распределённые точки, чем все остальные методы. Более того, все остальные методы требуют тщательного подбора базовых параметров, а в случае неправильного подбора приводят к вырожденности (например справа вверху)
Рассматриваемые в статье темы
Какое-то время назад этот пост был выложен на главной странице Hacker News. Можете прочитать там его обсуждение.
На рисунке 1 можно заметить, что при простом равномерном случайном сэмплировании точки внутри единичного квадрата наблюдается скапливание точек, а также возникают области совсем без точек («белый шум»). Квазислучайная последовательность с низким расхождением — это метод построения (бесконечных) последовательных точек детерминированным образом, который уменьшает вероятность скапливания (расхождения), в то же время обеспечивая равномерное покрытие всего пространства («синий шум»).
Методы создания полностью детерминированных квазислучайных последовательностей с низким расхождением в одном измерении очень хорошо изучены и в общем виде решены. В этом посте я в основном буду рассматривать открытые (бесконечные) последовательности, сначала в одном измерении, а затем перейду к более высоким размерностям. Фундаментальное преимущество открытых последовательностей (то есть расширяемых в ) заключается в том, что если итоговые ошибки на основании конечного количества членов слишком велики, то последовательность может быть расширена без отбрасывания всех предыдущих вычисленных точек. Существует множество способов построения открытых последовательностей. Разбить разные типы на категории можно по методу построения их базисных (гипер)параметров:
) заключается в том, что если итоговые ошибки на основании конечного количества членов слишком велики, то последовательность может быть расширена без отбрасывания всех предыдущих вычисленных точек. Существует множество способов построения открытых последовательностей. Разбить разные типы на категории можно по методу построения их базисных (гипер)параметров:
Ради краткости в этом посте я в основном буду сравнивать новую аддитивную рекурсивную-последовательность, которая относится к первой категории, то есть к рекурсивным методам, основанным на иррациональных числах (часто называемый последовательностями Кронекера, Вейля или Рихтмайера), являющимся решётками 1 ранга, и последовательность Холтона, которая основана на канонической одномерной последовательности ван дер Корпута. Каноническая рекурсивная последовательность Кронекера определяется как:
где — любое иррациональное число. Учтите, что запись
— любое иррациональное число. Учтите, что запись  обозначает дробную часть
обозначает дробную часть  . В вычислениях эта функция чаще выражается как
. В вычислениях эта функция чаще выражается как
При первые несколько членов последовательности
первые несколько членов последовательности  равны:
равны:
Важно заметить, что значение не влияет на общие характеристики последовательности, и почти во всех случаях приравнивается к нулю. Однако в вычислениях вариант
не влияет на общие характеристики последовательности, и почти во всех случаях приравнивается к нулю. Однако в вычислениях вариант  обеспечивает дополнительную степень свободы, что часто полезно. Если , то последовательность часто называют «последовательностью сдвинутой решётки». Несмотря на то, что по умолчанию
обеспечивает дополнительную степень свободы, что часто полезно. Если , то последовательность часто называют «последовательностью сдвинутой решётки». Несмотря на то, что по умолчанию  , я полагаю, что есть теоретические и практические соображения, по которым стандартным должно быть значение
, я полагаю, что есть теоретические и практические соображения, по которым стандартным должно быть значение  . Значение , дающее наименьшее возможное расхождение, если
. Значение , дающее наименьшее возможное расхождение, если  , где
, где  — это золотое сечение. То есть
— это золотое сечение. То есть
Интересно заметить, что существует бесконечное количество других значений, также позволяющих получить оптимальное расхождение, и все они связаны друг с другом преобразованием Мёбиуса
Теперь мы сравним этот рекурсивный метод с хорошо известными последовательностями ван дер Корпута с обратным порядком разрядов [ван дер Корпут, 1935]. Последовательности ван дер Корпута на самом деле являются семейством последовательностей, каждая из которых определяется уникальным гиперпараметром . Первые несколько членов последовательности при b=2 равны:
. Первые несколько членов последовательности при b=2 равны:
В следующем разделе мы сравним общие характеристики и эффективность каждой из этих последовательностей. Рассмотрим задачу вычисления определённого интеграла
Мы можем аппроксимировать его как:
На графике ниже показаны типичные кривые погрешностей для аппроксимации определённого интеграла, связанного с этой функцией,
для аппроксимации определённого интеграла, связанного с этой функцией, ![$f(x) = \textrm{exp}(\frac{-x^2}{2}), \; x \in [0,1]$](https://habrastorage.org/getpro/habr/formulas/3a2/f46/b1d/3a2f46b1d01eed3976e78a0159ff3d7e.svg) при: (i) квазислучайных точках из аддитивной рекурсии, где , (синие); (ii) квазислучайных точках из последовательности ван дер Корпута, (оранжевые); (iii) случайно выбранных точках, (зелёные); (iv) последовательности Соболя (красные).
при: (i) квазислучайных точках из аддитивной рекурсии, где , (синие); (ii) квазислучайных точках из последовательности ван дер Корпута, (оранжевые); (iii) случайно выбранных точках, (зелёные); (iv) последовательности Соболя (красные).
Это показывает, что для точек решение со случайным сэмплированием приводит к погрешности
точек решение со случайным сэмплированием приводит к погрешности  , последовательность ван дер Корпута приводит к погрешности
, последовательность ван дер Корпута приводит к погрешности  , тогда как -последовательность приводит к погрешности
, тогда как -последовательность приводит к погрешности  , что в
, что в  10 раз лучше, чем погрешность ван дер Корпута и в 1000 раз лучше, чем (равномерное) случайное сэмплирование.
10 раз лучше, чем погрешность ван дер Корпута и в 1000 раз лучше, чем (равномерное) случайное сэмплирование.
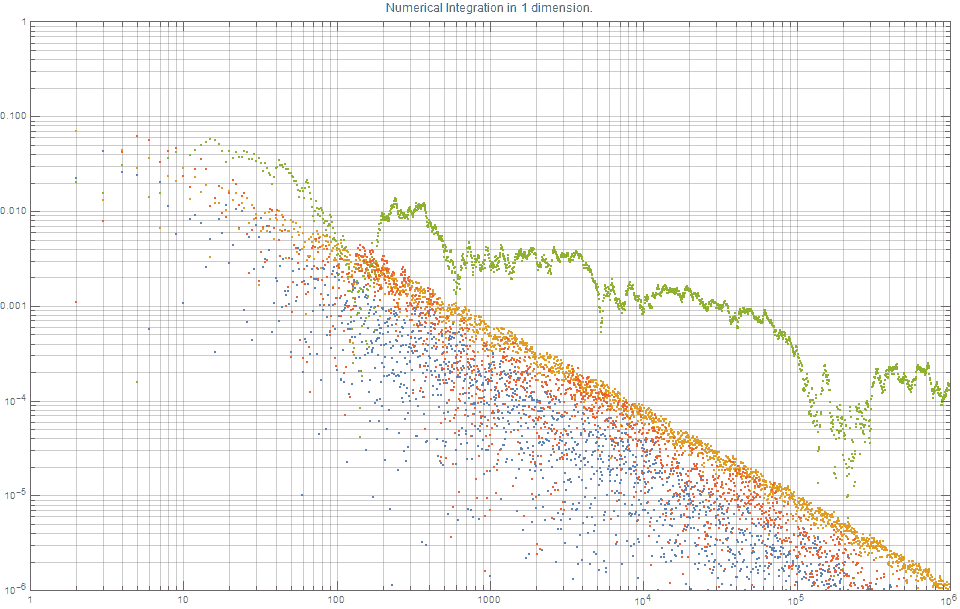
Рисунок 2. Сравнение одномерного численного интегрирования с помощью различных квазислучайных методов Монте-Карло. Чем меньше значения, тем лучше. Новая -последовательность (синяя) и последовательность Соболя (красная), очевидно, самые лучшие.
-последовательность (синяя) и последовательность Соболя (красная), очевидно, самые лучшие.
Здесь стоит упомянуть следующее:
Стоит также заметить, что хотя теоретически обеспечивает доказуемо оптимальный вариант,
теоретически обеспечивает доказуемо оптимальный вариант,  очень близок к оптимальному, а почти любое другое иррациональное значение обеспечивает превосходные кривые погрешностей для одномерного интегрирования. Именно поэтому очень часто используется
очень близок к оптимальному, а почти любое другое иррациональное значение обеспечивает превосходные кривые погрешностей для одномерного интегрирования. Именно поэтому очень часто используется  для любого простого числа. Более того, с точки зрения вычислений, выбранное случайное значение в интервале
для любого простого числа. Более того, с точки зрения вычислений, выбранное случайное значение в интервале ![$\alpha \in [0,1]$](https://habrastorage.org/getpro/habr/formulas/a63/055/bbc/a63055bbce28193d97b0e1a8784ad5b3.svg) почти абсолютно точно будет (в пределах машинной точности) иррациональным числом, а потому является хорошим выбором для последовательности с низким расхождением. Для визуальной разборчивости на показанном выше рисунке не показаны результаты последовательности Нидеррайтера, потому что они практически неотличимы от результатов последовательностей Соболя и . Последовательности Нидеррайтера и Соболя (вместе с их оптимизированным выбором параметров), которые использовались в этом посте, были вычислены в Mathematica с помощью того, что в документации называется «закрытыми проприетарными и полностью оптимизированными генераторами из библиотеки Intel MKL».
почти абсолютно точно будет (в пределах машинной точности) иррациональным числом, а потому является хорошим выбором для последовательности с низким расхождением. Для визуальной разборчивости на показанном выше рисунке не показаны результаты последовательности Нидеррайтера, потому что они практически неотличимы от результатов последовательностей Соболя и . Последовательности Нидеррайтера и Соболя (вместе с их оптимизированным выбором параметров), которые использовались в этом посте, были вычислены в Mathematica с помощью того, что в документации называется «закрытыми проприетарными и полностью оптимизированными генераторами из библиотеки Intel MKL».
Большинство современных методов построения низкого расхождения в более высоких измерениях просто комбинирует (покомпонентно) одномерных последовательностей. Для краткости в посте мы в основном будем рассматривать последовательность Холтона [Холтон, 1960 год], последовательность Соболя и -мерную последовательность Кронекера.
одномерных последовательностей. Для краткости в посте мы в основном будем рассматривать последовательность Холтона [Холтон, 1960 год], последовательность Соболя и -мерную последовательность Кронекера.
Последовательность Холтона строится простым использованием различных одномерных последовательностей ван дер Корпута, основание которых взаимно просто для всех других. То есть они являются попарными взаимно-простыми числами. Вне всяких сомнений, наиболее частым вариантом из-за своей очевидной простоты и логичности является выбор первых простых чисел. Распределение первых 625 точек, определяемых (2,3)-последовательностью Холтона, показано на рисунке 1. Хотя многие двухмерные последовательности Холтона являются прекрасными источниками последовательностей с низким расхождением, хорошо известно, что многие из них весьма проблематичны и не демонстрируют низкого расхождения. Например, на рисунке 3 показано, что (11,13)-последовательность Холтона создаёт очень заметные линии. Большие усилия были приложены к разработке методов выбора образцовых и проблематичных пар  . В более высоких измерениях проблема становится ещё сложнее.
. В более высоких измерениях проблема становится ещё сложнее.
При обобщении до более высоких размерностей рекурсивные методы Кронекера страдают ещё бОльшими трудностями. Хотя при использовании создаются превосходные одномерные последовательности, чрезвычайно трудно хотя бы найти пары простых чисел, которые можно использовать в качестве базиса для двухмерного случая не являющегося проблематичным! В качестве обходного пути предлагалось использовать другие хорошо известные иррациональные числа, например  . Они обеспечивают умеренно приемлемые результаты, но в общем случае не используются, потому что обычно не так хороши, как правильно подобранная последовательность Холтона. К решению этих проблемам вырождения прикладываются очень большие усилия.
. Они обеспечивают умеренно приемлемые результаты, но в общем случае не используются, потому что обычно не так хороши, как правильно подобранная последовательность Холтона. К решению этих проблемам вырождения прикладываются очень большие усилия.
В предлагаемых решениях используются skipping/burning, leaping/thinning. А для кодирования (скрэмблинга) конечных последовательностей используется другая техника, часто применяемая для преодоления этой проблемы. Скрэмблинг невозможно использовать для создания открытой (бесконечной) последовательности с низким расхождением.
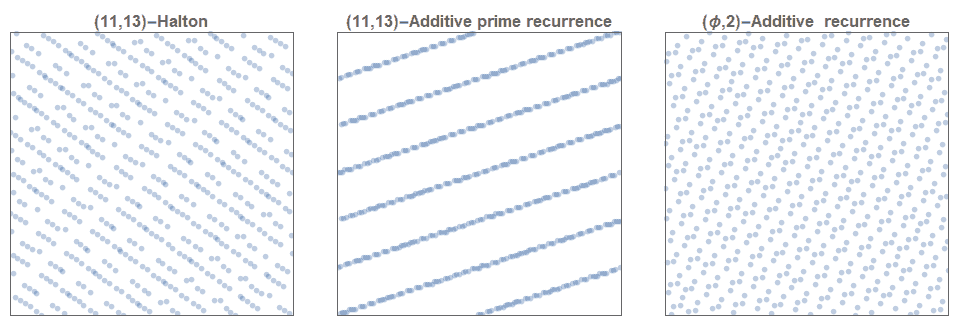
Рисунок 3. (11,13)-последовательность Холтона очевидно не является последовательностью с низким расхождением (слева). Не является ею и аддитивная рекурсивная (11,13)-последовательность (посередине). Некоторые двухмерные аддитивные рекурсивные последовательности, которые используют хорошо известные иррациональные числа, достаточно хороши (справа).
Аналогично, несмотря на в целом лучшие результаты последовательности Соболя, её сложность и, что более важно, необходимость очень тщательного выбора гиперпараметров делает её не такой дружелюбной.
Итак, повторим, в измерениях:
tl;dr В этой части я расскажу о том, как строить новый класс-мерной открытой (бесконечной) последовательности с низким расхождением, не требующий выбора базисных параметров, имеющий превосходные свойства низкого расхождения.
Существует множество способов обобщения последовательности Фибоначчи и/или золотого сечения. Предложенный ниже метод обобщения золотого сечения не нов [Крчадинац, 2005 год]. Кроме того, характеристический многочлен связан с многими областями алгебры, в том числе числами Перрона и с числами Пизо-Виджаярагхавана. Однако нова в нём явная связь между этой обобщённой формой и построением высокоразмерных последовательностей с низким расхождением. Мы определяем обобщённый вид золотого сечения как уникальный положительный корень
как уникальный положительный корень  . То есть,
. То есть,
Для ,
,  , что является каноничным золотым сечением.
, что является каноничным золотым сечением.
Для ,
,  . Это значение часто называется пластической константой и оно обладает красивыми свойствами (см. также здесь). Предполагается, что это значение с наибольшей вероятностью является оптимальным для соответствующей двухмерной задачи [Хенсли, 2002 год].
. Это значение часто называется пластической константой и оно обладает красивыми свойствами (см. также здесь). Предполагается, что это значение с наибольшей вероятностью является оптимальным для соответствующей двухмерной задачи [Хенсли, 2002 год].
Для ,
, 
Для , хотя корни этого уравнения не имеют замкнутого алгебраического вида, мы можем с лёгкостью получить численную аппроксимацию или стандартными способами, например методом Ньютона, или заметив, что для следующей последовательности
, хотя корни этого уравнения не имеют замкнутого алгебраического вида, мы можем с лёгкостью получить численную аппроксимацию или стандартными способами, например методом Ньютона, или заметив, что для следующей последовательности  :
:
Эта особая последовательность констант была названа в 1928 году архитектором и монахом Гансом ван де Лааном "гармоническими числами". Эти особые значения можно очень элегантно выразить следующим образом:
Также у нас есть следующее очень элегантное свойство:
Эта последовательность, иногда называемая обобщённой или отложенной последовательностью Фибоначчи, изучена достаточно глубоко [Как, 2004 год, Уилсон, 1993 год], а последовательность для часто называется последовательностью Падована [Стюарт, 1996 год, OEIS A000931], а последовательность перечислена в [OEIS A079398]. Как сказано выше, основная задача этого поста — описать явную связь между этой обобщённой последовательностью и построением -мерных последовательностей с низким расхождением.
Для двух измерений эта обобщённая последовательность при показана на рисунке 1. Точки очевидно распределены намного равномернее в -последовательности, чем в (2, 3)-последовательности Холтона, последовательности Кронекера, основанной на
показана на рисунке 1. Точки очевидно распределены намного равномернее в -последовательности, чем в (2, 3)-последовательности Холтона, последовательности Кронекера, основанной на  , последовательностях Нидеррайтера и Соболя. (Из-за сложности последовательностей Нидеррайтера и Соболя они были вычислены в Mathematica с помощью проприетарного кода, предоставленного Intel.) Такой тип последовательности, в котором базисный вектор
, последовательностях Нидеррайтера и Соболя. (Из-за сложности последовательностей Нидеррайтера и Соболя они были вычислены в Mathematica с помощью проприетарного кода, предоставленного Intel.) Такой тип последовательности, в котором базисный вектор  является функцией от единственного вещественного значения, часто называется последовательностью Коробова [Коробов, 1959 год]
является функцией от единственного вещественного значения, часто называется последовательностью Коробова [Коробов, 1959 год]
Снова посмотрите на рисунок 1, чтобы сравнить различные двухмерные квазислучайные последовательности с низким расхождением.
В одном измерении псевдокод для-ного члена ( = 1,2,3,….) определяется как
В двух измерениях псевдокод для координат и  -ного члена ( = 1,2,3,….) определяются как
-ного члена ( = 1,2,3,….) определяются как
Псевдокод в трёх измерениях для координат, и  -ного члена ( = 1,2,3,….) определяется как
-ного члена ( = 1,2,3,….) определяется как
Шаблон кода на python. (учтите, что массивы и циклы Python начинаются с нуля!)
Я написал код таким образом, чтобы он соответствовал математическим обозначениям, использованным в этом посте. Однако по причинам соглашений в программировании и/или эффективности стоит упомянуть некоторые модификации. Во-первых, поскольку является аддитивной рекурсивной последовательностью, альтернативная формулировка , которая не требует умножения с плавающей запятой и сохраняет высокую точность для очень больших , имеет вид
Во-вторых, в языках, имеющих возможность векторизации, код дробной функции можно векторизировать следующим образом:
Наконец, мы можем заменить эти сложения чисел с плавающей точкой и целых чисел, умножив все константы на , а затем соответствующим образом изменив функцию frac(.). Вот демонстрации с исходным кодом, созданные другими людьми на основе этой последовательности:
, а затем соответствующим образом изменив функцию frac(.). Вот демонстрации с исходным кодом, созданные другими людьми на основе этой последовательности:
Хотя стандартный технический анализ вычисления расхождения заключается в оценке -расхождения, мы сначала упомянем пару других геометрических (и, возможно, гораздо более интуитивно понятных!) способов демонстрации того, насколько новая последовательность предпочтительнее других стандартных методов. Если мы обозначим расстояние между точками
-расхождения, мы сначала упомянем пару других геометрических (и, возможно, гораздо более интуитивно понятных!) способов демонстрации того, насколько новая последовательность предпочтительнее других стандартных методов. Если мы обозначим расстояние между точками  и
и  за
за  , а
, а  , тогда график ниже показывает, как варьируется
, тогда график ниже показывает, как варьируется  для -последовательности, (2,3)- последовательности Холтона, Соболя, Нидеррайтера и случайных последовательностей. Это можно увидеть на рисунке 6.
для -последовательности, (2,3)- последовательности Холтона, Соболя, Нидеррайтера и случайных последовательностей. Это можно увидеть на рисунке 6.
Как и в предыдущем рисунке, величина минимального расстояния нормализована коэффициентом . Можно заметить, что после
. Можно заметить, что после  точек в случайной последовательности (зелёная) почти наверняка появятся две точки, находящиеся чрезвычайно близко друг к другу. Также видно, что хотя (2,3)-последовательность Холтона гораздо лучше, чем случайное сэмплирование, она тоже, к сожалению, асимптотически снижается к нулю. Для последовательности Соболя причина снижению к нулю нормализованного
точек в случайной последовательности (зелёная) почти наверняка появятся две точки, находящиеся чрезвычайно близко друг к другу. Также видно, что хотя (2,3)-последовательность Холтона гораздо лучше, чем случайное сэмплирование, она тоже, к сожалению, асимптотически снижается к нулю. Для последовательности Соболя причина снижению к нулю нормализованного  заключается в том, что сам Соболь показал — последовательность Соболя падает со скоростью
заключается в том, что сам Соболь показал — последовательность Соболя падает со скоростью  —, что хорошо, но очевидно намного хуже, чем , которая снижается только на .
—, что хорошо, но очевидно намного хуже, чем , которая снижается только на .
Для последовательности (синяя) минимальное расстояние между двумя точками постоянно попадает в интервал от
(синяя) минимальное расстояние между двумя точками постоянно попадает в интервал от  до
до  . Заметьте, что оптимальный диаметр 0.868 соответствует коэффициенту упаковки в 59.2%. Сравните это с другими упаковками кругов.
. Заметьте, что оптимальный диаметр 0.868 соответствует коэффициенту упаковки в 59.2%. Сравните это с другими упаковками кругов.
Также заметьте, что Bridson Poisson disc sampling, которая не является расширяемой до и обычно является рекомендуемой по умолчанию, всё равно создаёт коэффициент упаковки 49.4%. Стоит учесть, что концепция тесно связывает последовательности с низким расхождением с плохо аппроксимируемыми числами/векторами в измерениях [Хенсли, 2001 год]. Хотя нам мало известно о плохо аппроксимируемых числах в двух измерениях, построение может предоставить нам новый взгляд на плохо аппроксимируемые числа в более высоких размерностях.
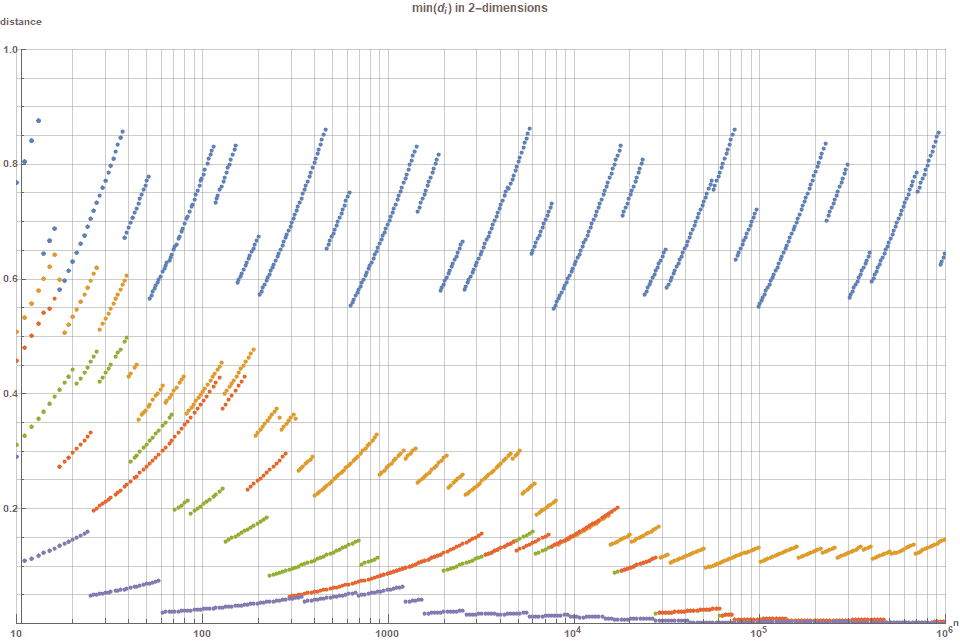
Рисунок 4. Минимальное попарное расстояние для различных последовательностей с низким расхождением. Заметьте, что-последовательность (синяя) постоянно остаётся наилучшим вариантом; кроме того, это единственная последовательность, в которой нормализованное расстояние не стремится к нулю при  . Последовательность Холтона (оранжевая) занимает второе место, а последовательности Соболя (зелёная) и Нидеррайтера (красная) не так хороши, но всё равно намного лучше, чем случайная (фиолетовая). Чем больше, тем лучше, потому что это соответствует бОльшему расстоянию упаковки.
. Последовательность Холтона (оранжевая) занимает второе место, а последовательности Соболя (зелёная) и Нидеррайтера (красная) не так хороши, но всё равно намного лучше, чем случайная (фиолетовая). Чем больше, тем лучше, потому что это соответствует бОльшему расстоянию упаковки.
Ещё один способ визуализации равномерности распределения точек — создание диаграммы Вороного из первых точек двумерной последовательности с последующим раскрашиванием каждой области в зависимости от её площади. На рисунке ниже показаны цветовые диаграммы Вороного для (i) -последовательности; (ii) (2,3)-последовательности Холтона, (iii) рекурсии на основе простых чисел; и (iv) простого случайного сэмплирования. Для всех фигур использована одинаковая цветовая шкала. Здесь снова очевидно, что -последовательность обеспечивает намного более равномерное распределение, чем последовательность Холтона или простое случайное сэмплирование. Картина та же самая, что и выше, только раскрашена согласно количеству вершин в каждой ячейке Вороного. Здесь не только очевидно, что -последовательность обеспечивает более равномерное распределение, чем Холтон или простое случайное сэмплирование, но и более заметен тот факт, что ключевые значения состоят только из шестиугольников! Если мы рассмотрим обобщённую последовательность Фибоначчи, то  . То есть
. То есть  :
:
Все значения, в которых или
или  , состоят только из шестиугольников.
, состоят только из шестиугольников.
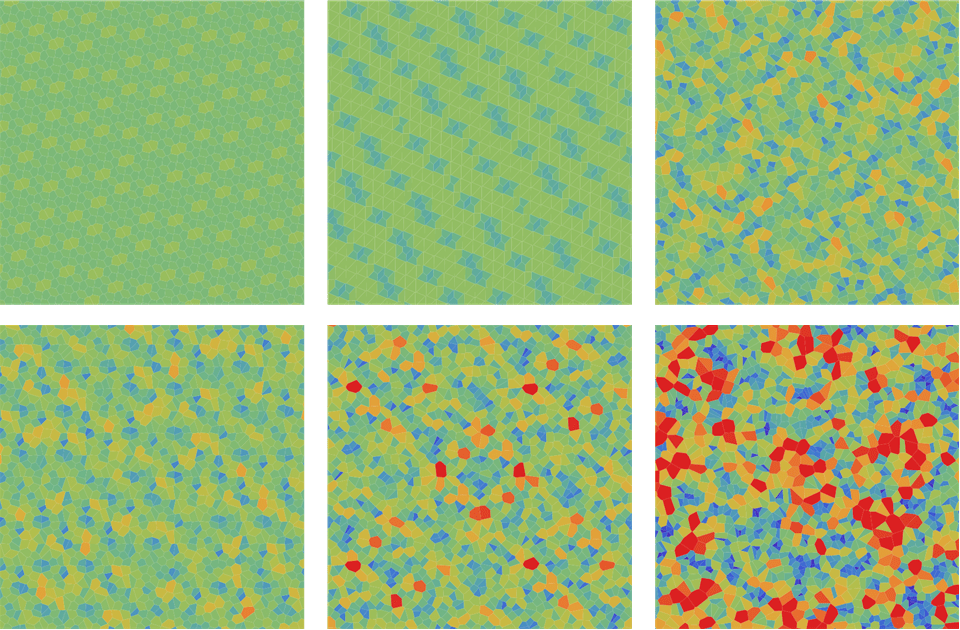
Рисунок 4. Визуализация формы диаграмм Вороного на основании площади каждого многоугольника Вороного для (i)-последовательности; (ii) (2,3)-последовательности на основе простых чисел; (iii) (2,3)-последовательности Холтона, (iv) Нидеррайтера; (v) Соболя; и (iv) простое случайное сэмплирование. Цвета обозначают количество сторон каждого многоугольника Вороного. Повторюсь: очевидно, что -последовательность обеспечивает гораздо более равномерное распределение, чем любые другие последовательности с низким расхождением.
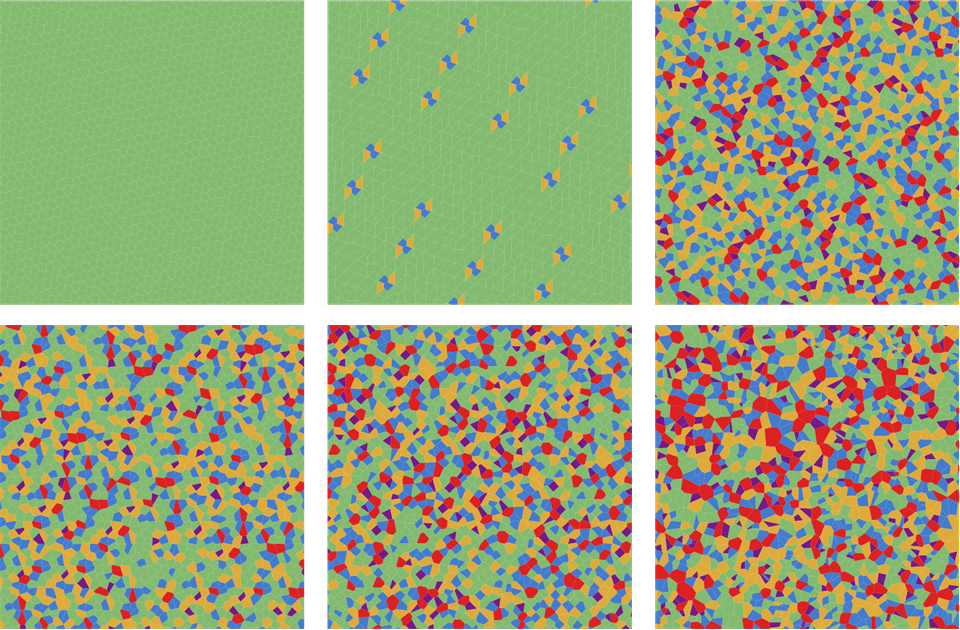
Рисунок 5. Визуализация формы диаграмм Вороного на основании числа сторон каждого многоугольника Вороного для (i)-последовательности; (ii) (2,3)-последовательности на основании простых чисел; (iii) (2,3)-последовательности Холтона, (iv) Нидеррайтера; (v) Соболя; и (iv) простого случайного сэмплирования. Цвета обозначают количество сторон каждого многоугольника Вороного. Повторюсь: очевидно, что -последовательность обеспечивает гораздо более равномерное распределение, чем любые другие последовательности с низким расхождением.
Триангуляция Делоне, являющаяся подобием графа Вороного, предоставляет возможность по-другому посмотреть на эти распределения. Однако более важно то, что триангуляция Делоне обеспечивает новый метод создания квазипериодического тайлинга (мозаичного разбиения) плоскости. Триангуляция Делоне-последовательности обеспечивает гораздо более равномерный паттерн, чем последовательность Холтона или случайная выборка. В частности, если выполняется триангуляция Делоне распределений точек, где равно любому из обобщённой последовательности Фибоначчи:  , то триангуляция Делоне состоит только из трёх одинаково парных треугольников, то есть из параллелограммов (ромбоидов)! (За исключением треугольников, имеющих общую вершину с выпуклой оболочкой.) Более того,
, то триангуляция Делоне состоит только из трёх одинаково парных треугольников, то есть из параллелограммов (ромбоидов)! (За исключением треугольников, имеющих общую вершину с выпуклой оболочкой.) Более того,

Рисунок 6. Визуализация триангуляции Делоне для (i)-последовательности; (ii) (2,3)-последовательности Холтона, (iii) рекурсии на основе простых чисел; и (iv) простого случайного сэмплирования. Цвета обозначают область каждого треугольника. Во всех четырёх графиках использован одинаковый масштаб. И здесь снова очевидно, что -последовательность обеспечивает гораздо более равномерное распределение, чем любые другие последовательности с низким расхождением.
Заметьте, что основана на  , являющемся наименьшим числом Пизо, (а
, являющемся наименьшим числом Пизо, (а  — это наибольшее число Пизо). Связь квазипериодического тайлинга с квадратичными и кубическими числами Пизо не нова [Элкхаррат и Масакова], но я считаю, что впервые квазипериодический тайлинг был создан на основании
— это наибольшее число Пизо). Связь квазипериодического тайлинга с квадратичными и кубическими числами Пизо не нова [Элкхаррат и Масакова], но я считаю, что впервые квазипериодический тайлинг был создан на основании  .
.
Показанная ниже анимация демонстрирует, как сетка Делоне для последовательности меняется при постепенном добавлении точек. Заметьте, что когда количество точек равно члену обобщённой последовательности Фибоначчи, то вся сетка Делоне состоит только из красных, синих и жёлтых параллелограммов (ромбоидов), выстроенных в двояком квазипериодическом виде.
Рисунок 7.
Хотя расположение красных параллелограммов демонстрирует значительную регулярность, можно чётко увидеть, что синие и жёлтые параллелограммы размещены в квазипериодическом виде. Спектр Фурье этой решётки можно увидеть на рисунке 11, он представляет собой классические точечные спектры. (Заметьте, что рекурсивная последовательность на основе простых чисел тоже кажется квазипериодической в том смысле, что это упорядоченный неповторяющийся паттерн. Однако её паттерн в интервале не так постоянен, а также критически зависит от выбора базисных параметров. Поэтому мы сосредоточим наш интерес в квазипериодических тайлингах только последовательностью .) Она состоит всего из трёх треугольников: красного, жёлтого, синего. Учтите, что в этой последовательности все параллелограммы каждого цвета имеют одинаковый размер и форму. Соотношение площадей этих отдельных треугольников невероятно элегантно. А именно
То же относится и к относительной частоте треугольников:
Из этого следует, что общая относительная площадь, покрываемая этими тремя треугольниками в пространстве, равна:
Можно также предположить, что мы можем создать этот квазипериодический тайлинг через подстановку на основании последовательности A. То есть
Для трёх измерений, если мы рассмотрим обобщённую последовательность Фибоначчи, то . То есть
. То есть
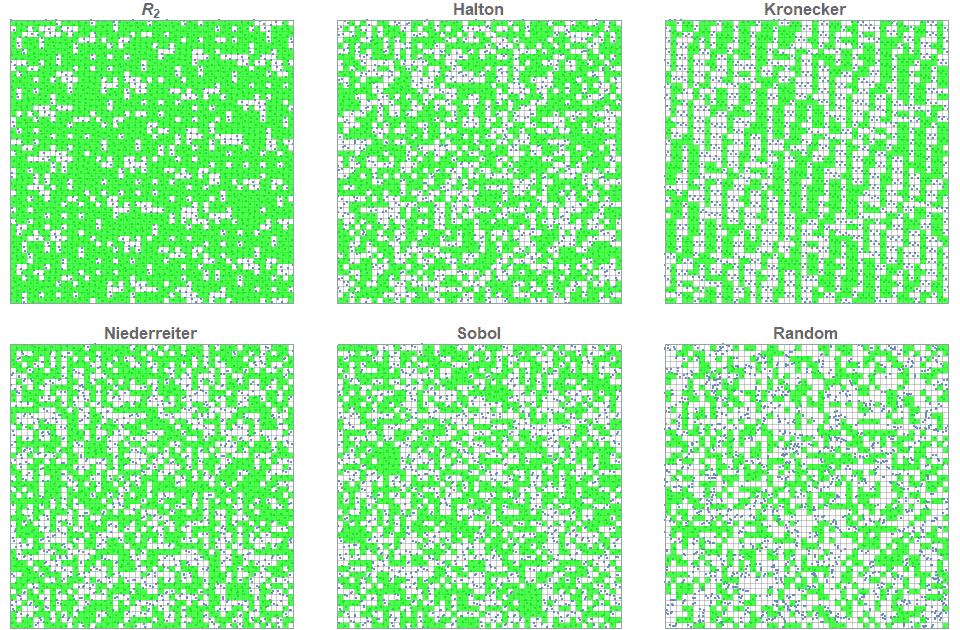
На рисунке ниже показаны первые точек для каждой двухмерной последовательности с низким расхождением. Более того, каждая из ячеек 50×50=2500 раскрашена зелёным, только если она содержит ровно 1 точку. То есть чем больше зелёных квадратов, тем равномернее распределение 2500 точек по 2500 ячеек. Процент зелёных ячеек для каждого из рисунков следующий: (75%), Холтон (54%), Кронекер (48%), Нидеррайтер (54%), Соболь (49%) и случайная (38%).
точек для каждой двухмерной последовательности с низким расхождением. Более того, каждая из ячеек 50×50=2500 раскрашена зелёным, только если она содержит ровно 1 точку. То есть чем больше зелёных квадратов, тем равномернее распределение 2500 точек по 2500 ячеек. Процент зелёных ячеек для каждого из рисунков следующий: (75%), Холтон (54%), Кронекер (48%), Нидеррайтер (54%), Соболь (49%) и случайная (38%).
Просто ради интереса, по просьбе одного из читателей News Hacker я смоделировал, как все эти квазислучайные распределения точек могут звучать! Я использовал функцию Listplay из Mathematica: “ListPlay[{a1,a2,…}] создаёт объект, воспроизводящийся как звук, амплитуда которого задаётся как последовательность уровней.” Поэтому без всяких комментариев я предоставлю вам самим решать, какие из них вам больше нравятся среди одномерных квазислучайных распределений (моно) и двухмерных квазислучайных распределений (стерео).
Некоторые последовательности с низким расхождением демонстрируют то, что называется «многоклассовым низким расхождением». До этого момента мы предполагали, что когда нам нужно как можно равномернее распределить точек, то все точки одинаковы и неотличимы друг от друга. Однако во многих ситуациях существуют разные типы точек. Рассмотрим задачу равномерного распределения так, чтобы были равномерно распределены не только все точки, но и точки одного класса. В частности, предположим, что есть  точек типа
точек типа  , (где
, (где  ), тогда распределение мультимножества с низким распределением — это такое распределение, в котором каждая из точек равномерно распределена. В нашем случае мы обнаружили, что -последовательность и последовательность Холтона легко адаптировать под последовательности мультимножеств с низким расхождением, просто размещая попеременно точки каждого типа.
), тогда распределение мультимножества с низким распределением — это такое распределение, в котором каждая из точек равномерно распределена. В нашем случае мы обнаружили, что -последовательность и последовательность Холтона легко адаптировать под последовательности мультимножеств с низким расхождением, просто размещая попеременно точки каждого типа.
На рисунке ниже показано, как распределяются точек, при том что 75 имеют синий цвет, 40 — оражневый, 25 — зелёный, а 10 — красный. Для аддитивной рекурсивной последовательности это решается тривиально: первые 75 членов просто соответствуют синим, следующие 40 — оранжевым, следующие 25 — зелёным, а последние 10 — красным точкам. Эта техника почти срабатывает для последовательностей Холтона и Кронекера, но очень плохо показывает себя в последовательностях Нидеррайтера и Соболя. Более того, не существует известных техник для постоянной генерации многомасштабных распределений точек в последовательностях Нидеррайтера и Соболя. Это показывает, что распределения многоклассовых точек, например, таких, как глаза кур, можно теперь описывать и строить непосредственно с помощью последовательностей с низким расхождением.
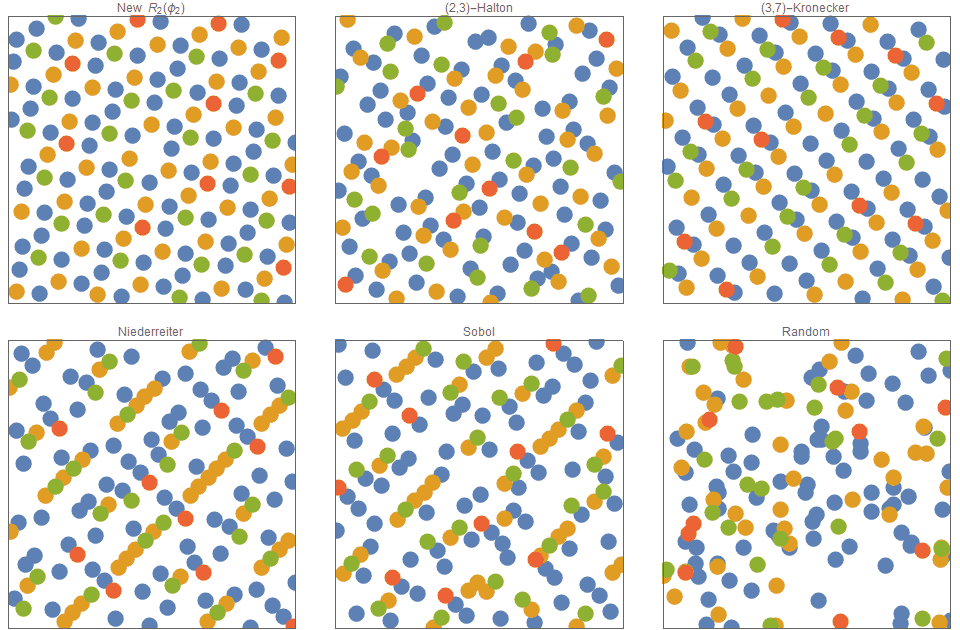
Рисунок 9. Многомасштабные последовательности с низким расхождением. В последовательности равномерно распределены не только все точки, но и точки каждого отдельного цвета.
В областях компьютерной графики и физики очень часто нужно как можно равномернее распределять точки на поверхности трёхмерной сферы. При использовании открытых (бесконечных) квазислучайных последовательностей эта задача сводится всего лишь к размещению квазислучайных точек, равномерно распределённых в единичном квадрате, на поверхности сферы с помощью равновеликой проекции Ламберта. Стандартное преобразование проекции Ламберта, размещающее точку![$(u,v) \in U[0,1] \to (x,y,z)\in S^2$](https://habrastorage.org/getpro/habr/formulas/52e/c41/0b8/52ec410b8f2b78b7eda3a99f14eee20d.svg) имеет вид:
имеет вид:
 -последовательность полностью открыта, она позволяет привязывать бесконечную последовательность точек к поверхности сферы, по одной точке за раз. Это контрастирует с другими методами, например с решёткой спирали Фибоначчи, которые требуют заранее знать количество точек. При визуальном осмотре мы снова можем чётко увидеть, что для
-последовательность полностью открыта, она позволяет привязывать бесконечную последовательность точек к поверхности сферы, по одной точке за раз. Это контрастирует с другими методами, например с решёткой спирали Фибоначчи, которые требуют заранее знать количество точек. При визуальном осмотре мы снова можем чётко увидеть, что для  новая -последовательность гораздо лучше распределена, чем наложение Холтона или сэмплирование Кронекера, которые, в свою очередь, гораздо равномернее случайного сэмплирования.
новая -последовательность гораздо лучше распределена, чем наложение Холтона или сэмплирование Кронекера, которые, в свою очередь, гораздо равномернее случайного сэмплирования.
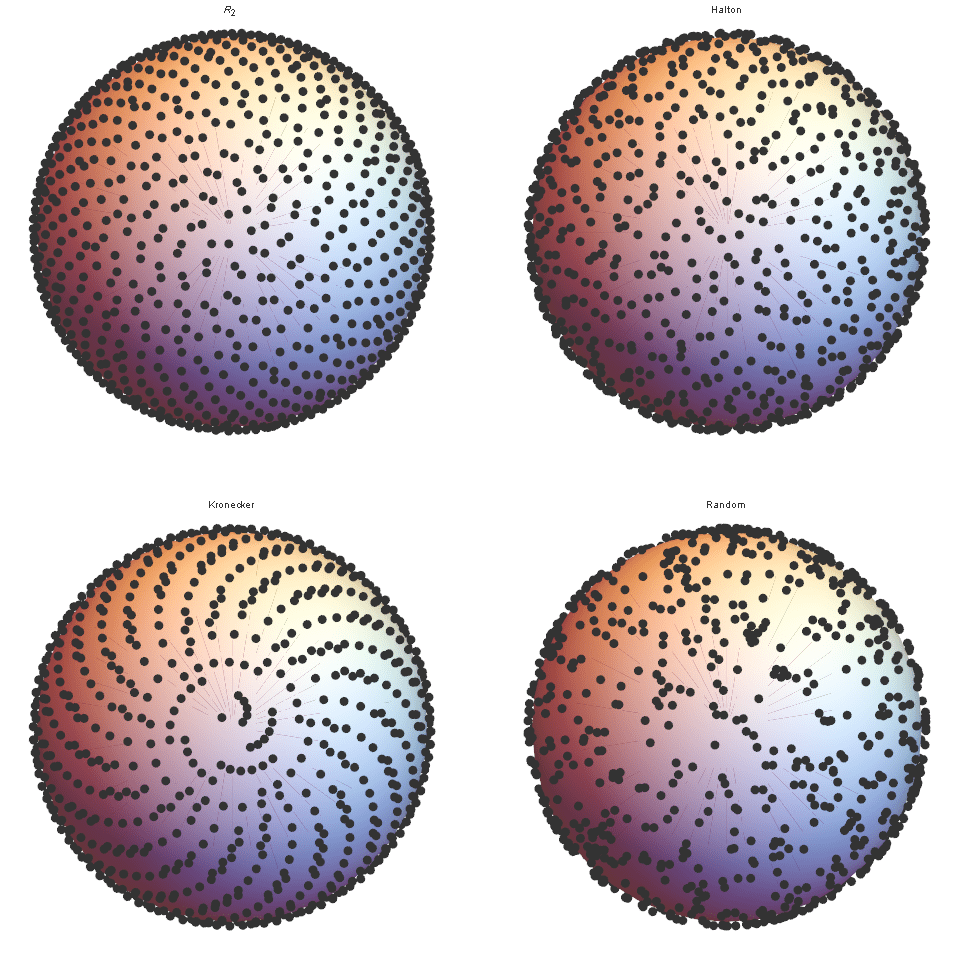
Рисунок 10.
Большинство современных техник дизеринга (например, дизеринг Флойда-Стейнберга) основано на распределении ошибок, что не очень подходит для параллельной обработки и/или непосредственной оптимизации в GPU. В таких случаях превосходные характеристики производительности показывает точечный дизеринг со статическими масками дизеринга (т.е. полностью зависимыми от целевого изображения). Вероятно наиболее известные и широко используемые маски дизеринга основаны на матрицах Байера, однако более новые пытаются ближе имитировать характеристики синего шума. Нетривиальная сложность создания масок дизеринга на основании последовательностей с низким расхождением и/или синего шума, заключается в том, что эти последовательности с низким расхождением проецируют целочисленное в двухмерную точку в интервале
в двухмерную точку в интервале  . Но для маски дизеринга требуется функция, которая проецирует двухмерные целочисленные координаты растеризированной маски в вещественные яркость/пороговое значение в интервале
. Но для маски дизеринга требуется функция, которая проецирует двухмерные целочисленные координаты растеризированной маски в вещественные яркость/пороговое значение в интервале  . Я предлагаю следующий подход, основанный на -последовательности. Для каждого пикселя (x,y) в маске мы присваиваем его яркости значение
. Я предлагаю следующий подход, основанный на -последовательности. Для каждого пикселя (x,y) в маске мы присваиваем его яркости значение  , где:
, где:
То есть , а значит
, а значит
Более того, если добавлена функция треугольной волны для устранения разрывности, вызванной функцией frac(.) на каждой целочисленной границе:
то маска и её график фурье/частотограмма ещё больше улучшаются. Также мы заметим, что поскольку
то вид приведённого выше выражения связан со следующим конгруэнтным уравнением
Стоит заметить, что эту структуру также предлагал Миттринг, но он находит коэффициенты эмпирически (и не воспроизводит окончательные значения). Более того, это помогает в понимании того, почему так хорошо работает эмпирическая формула Хорхе Хименеса, использованная при создании «Call of Duty» (часто её называют «Interleaved Gradient Noise»).
Однако для неё требуется 3 умножения с плавающей запятой и два оператора %1, а предыдущая формула показывает, что мы можем сделать это всего двумя умножениями с плавающей точкой и одной операцией %1. Но важнее то, что этот пост даёт более чёткое математическое понимание того, почему маска дизеринга в таком виде настолько эффективна, если не оптимальна. Результаты этой матрицы дизеринга показаны ниже на примере классического тестового изображения «Lena» 256×256, а также шахматного тестового паттерна. Также показаны результаты использования стандартных масок дизеринга Байера, а также один пример с синим шумом. Два наиболее распространённых метода синего шума — это Void-and-Cluster и Poisson disc sampling. Для краткости я показал только результаты метода Void and cluster. [Питерс]. Interleaved gradient noise работает лучше, чем Байер и синий шум, но не так хорошо, как-дизеринг. Можно увидеть, что дизеринг Байера демонстрирует заметный диссонанс белого в светло-серых областях. Дизеринг -последовательностью и синим шумом в общем виде сравнимы, хотя можно разобрать незначительные отличия. Стоит заметить некоторые аспекты R-дизеринга:
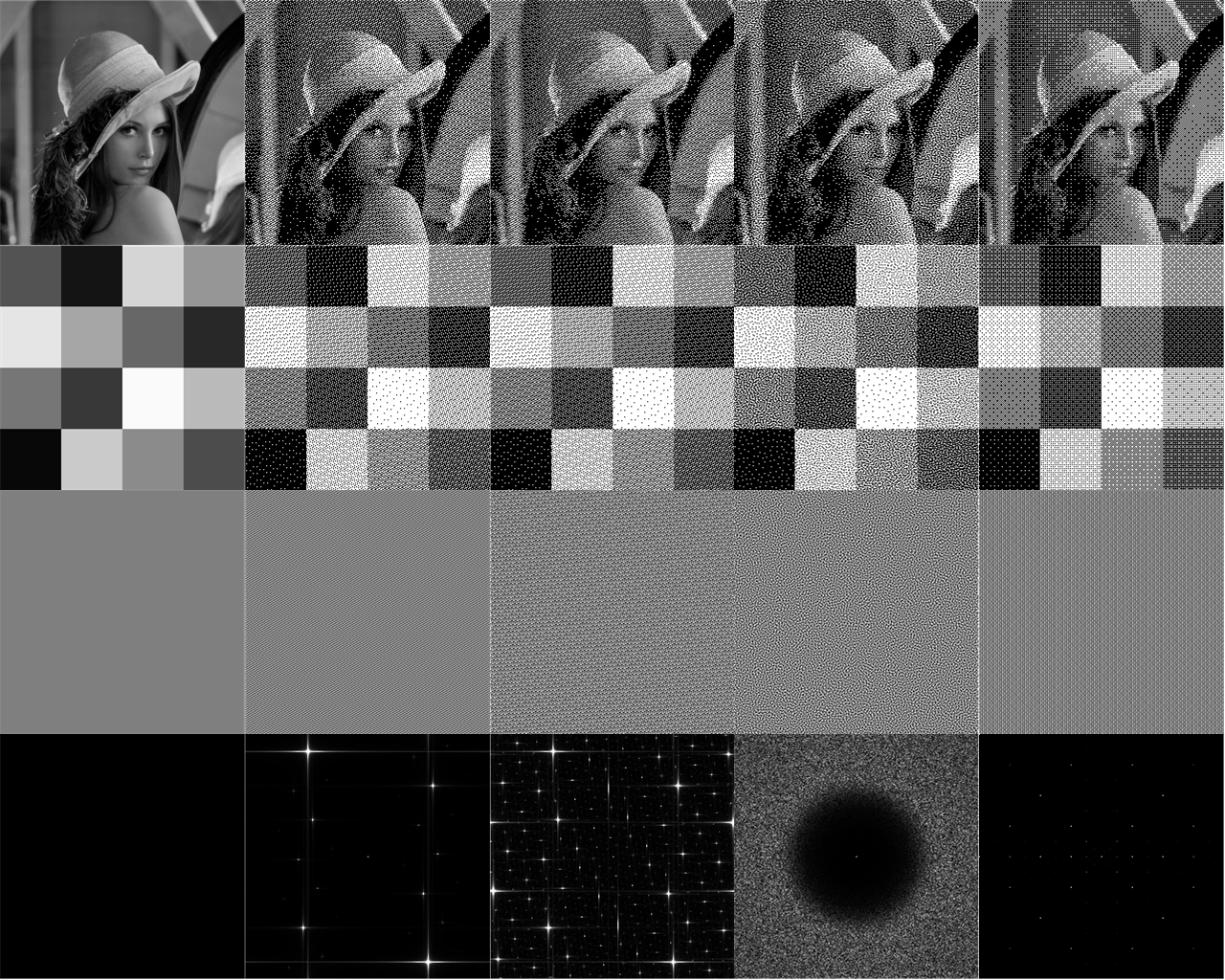
Рисунок 11. Слева направо: (i) Исходное изображение (ii) R-последовательность, скомбинированная с функцией треугольной волны; (iii) R-последовательность отдельно; (iv) маска дизеринга синего шума и (v) стандартный Байер. Маски дизеринга R-последовательности вполне конкурентны против других современных масок. Заметьте, что R2 показывает лучшее качество на лице и плечах Лены. Кроме того, в отличие от масок синего шума, R-маска дизеринга так проста, что не требует предварительных вычислений.
Аналогично предыдущему разделу, но для пяти (5) измерений, график ниже показывает (глобальное) минимальное расстояние между любыми двумя точками для -последовательности, (2,3,5,7,11)-последовательности Холтона и случайной последовательности. На этот раз нормализованная величина минимального расстояния нормализована на коэффициент
-последовательности, (2,3,5,7,11)-последовательности Холтона и случайной последовательности. На этот раз нормализованная величина минимального расстояния нормализована на коэффициент ![$1/ \sqrt[5]{n}$](https://habrastorage.org/getpro/habr/formulas/952/60a/a04/95260aa041d0b739c6cd647842dea6ab.svg) . Можно увидеть, что вследствие «проклятия размерностей» случайное распределение лучше, чем все последовательности с низким расхождением — за исключением
. Можно увидеть, что вследствие «проклятия размерностей» случайное распределение лучше, чем все последовательности с низким расхождением — за исключением  -последовательности. В -последовательности даже при
-последовательности. В -последовательности даже при  точках минимальное расстояние между двумя точками всё ещё постоянно находится рядом с
точках минимальное расстояние между двумя точками всё ещё постоянно находится рядом с  и всегда выше
и всегда выше  .
.
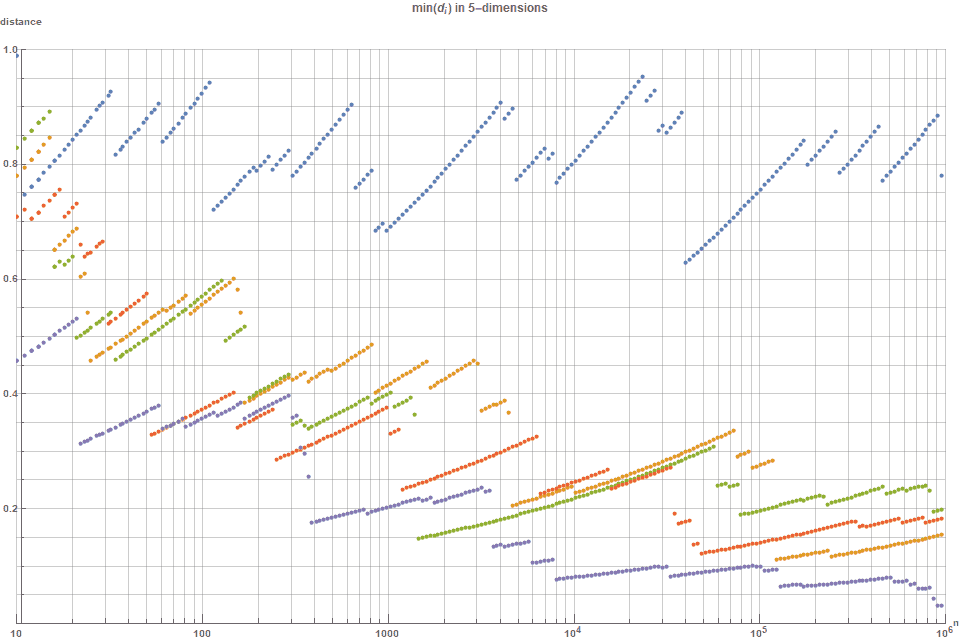
Рисунок 12. Это показывает, что R-последовательность (синяя) постоянно лучше Холтона (оранжевая); Соболя (зелёная); Нидеррайтера (красная); и случайной (фиолетовая). Учтите, что чем больше, тем лучше, потому что это соответствует бОльшему расстоянию упаковки.
На следующем графике показаны типичные кривые погрешностей для аппроксимации определённого интеграла, связанного с гауссовой функцией половинной ширины  ,
, ![$f(x) = \textrm{exp}(\frac{-x^2}{2d}), \; x \in [0,1] $](https://habrastorage.org/getpro/habr/formulas/78d/3c4/dbd/78d3c4dbdbec237b142beac8a59833a5.svg) , при этом: (i)
, при этом: (i)  (синяя); (ii) последовательность Холтона (оранжевая); (iii) случайная (зелёная); (iv) Соболь (красная). График показывает, что для точек разница между случайным сэмплированием и последовательностью Холтона теперь меньше. Однако, как было показано на одномерном случае, -последовательность и Соболь постоянно лучше последовательности Холтона. Это также даёт нам понять, что последовательность Соболя незначительно лучше -последовательности.
(синяя); (ii) последовательность Холтона (оранжевая); (iii) случайная (зелёная); (iv) Соболь (красная). График показывает, что для точек разница между случайным сэмплированием и последовательностью Холтона теперь меньше. Однако, как было показано на одномерном случае, -последовательность и Соболь постоянно лучше последовательности Холтона. Это также даёт нам понять, что последовательность Соболя незначительно лучше -последовательности.
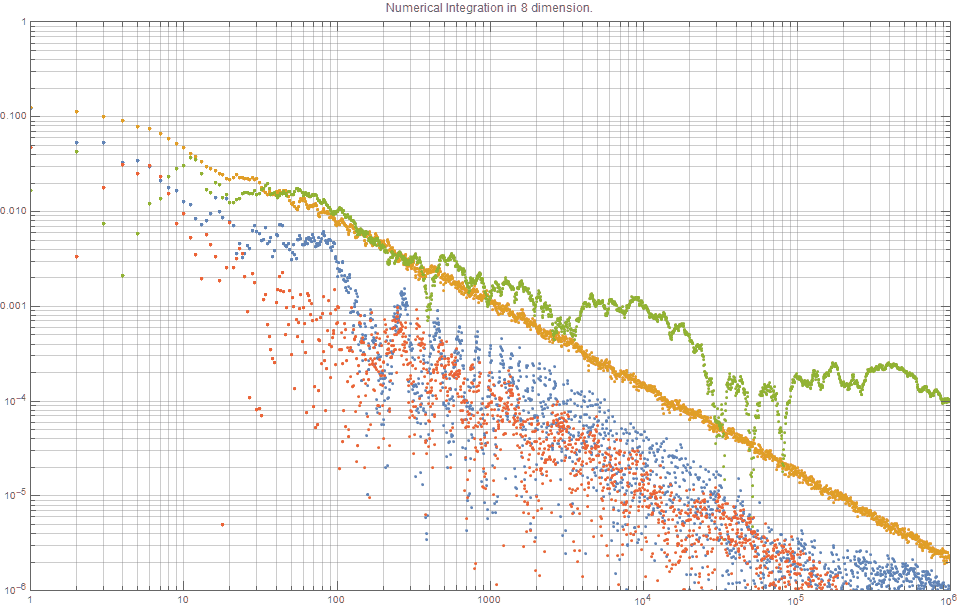
Рисунок 13. Квазислучайные методы Монте-Карло для 8-мерного интегрирования. Чем меньше значения, тем лучше. Новая R-последовательность и последовательность Соболя показывают себя значительно лучше, чем последовательность Холтона.
Рисунок 1. Сравнение различных квазислучайных последовательностей с низким расхождением. Заметьте, что предлагаемая мной
-последовательность создаёт более равномерно распределённые точки, чем все остальные методы. Более того, все остальные методы требуют тщательного подбора базовых параметров, а в случае неправильного подбора приводят к вырожденности (например справа вверху)Рассматриваемые в статье темы
- Последовательности с низким расхождением в одном измерении
- Методы с низким расхождением в двух измерениях
- Расстояние упаковки
- Множества с многоклассовым низким расхождением
- Квазислучайные последовательности на поверхности сферы
- Квазипериодический тайлинг плоскости
- Маски дизеринга в компьютерной графике
Какое-то время назад этот пост был выложен на главной странице Hacker News. Можете прочитать там его обсуждение.
Введение: случайное против квазислучайного
На рисунке 1 можно заметить, что при простом равномерном случайном сэмплировании точки внутри единичного квадрата наблюдается скапливание точек, а также возникают области совсем без точек («белый шум»). Квазислучайная последовательность с низким расхождением — это метод построения (бесконечных) последовательных точек детерминированным образом, который уменьшает вероятность скапливания (расхождения), в то же время обеспечивая равномерное покрытие всего пространства («синий шум»).
Квазислучайные последовательности в одном измерении
Методы создания полностью детерминированных квазислучайных последовательностей с низким расхождением в одном измерении очень хорошо изучены и в общем виде решены. В этом посте я в основном буду рассматривать открытые (бесконечные) последовательности, сначала в одном измерении, а затем перейду к более высоким размерностям. Фундаментальное преимущество открытых последовательностей (то есть расширяемых в
) заключается в том, что если итоговые ошибки на основании конечного количества членов слишком велики, то последовательность может быть расширена без отбрасывания всех предыдущих вычисленных точек. Существует множество способов построения открытых последовательностей. Разбить разные типы на категории можно по методу построения их базисных (гипер)параметров:- иррациональные дроби: Кронекер, Рихтмайер, Рэмшоу
- (взаимно) простые числа: Ван дер Корпут, Холтон, Форе
- Несводимые полиномы: Нидеррайтер
- Примитивные многочлены: Соболь
Ради краткости в этом посте я в основном буду сравнивать новую аддитивную рекурсивную
-последовательность, которая относится к первой категории, то есть к рекурсивным методам, основанным на иррациональных числах (часто называемый последовательностями Кронекера, Вейля или Рихтмайера), являющимся решётками 1 ранга, и последовательность Холтона, которая основана на канонической одномерной последовательности ван дер Корпута. Каноническая рекурсивная последовательность Кронекера определяется как: 
где
— любое иррациональное число. Учтите, что запись обозначает дробную часть . В вычислениях эта функция чаще выражается как
При
первые несколько членов последовательности равны:
Важно заметить, что значение
не влияет на общие характеристики последовательности, и почти во всех случаях приравнивается к нулю. Однако в вычислениях вариант обеспечивает дополнительную степень свободы, что часто полезно. Если , то последовательность часто называют «последовательностью сдвинутой решётки». Несмотря на то, что по умолчанию , я полагаю, что есть теоретические и практические соображения, по которым стандартным должно быть значение . Значение , дающее наименьшее возможное расхождение, если , где — это золотое сечение. То есть
Интересно заметить, что существует бесконечное количество других значений
, также позволяющих получить оптимальное расхождение, и все они связаны друг с другом преобразованием Мёбиуса
Теперь мы сравним этот рекурсивный метод с хорошо известными последовательностями ван дер Корпута с обратным порядком разрядов [ван дер Корпут, 1935]. Последовательности ван дер Корпута на самом деле являются семейством последовательностей, каждая из которых определяется уникальным гиперпараметром
. Первые несколько членов последовательности при b=2 равны:![$t_n^{[2]} = \frac{1}{2}, \frac{1}{4},\frac{3}{4}, \frac{1}{8}, \frac{5}{8}, \frac{3}{8}, \frac{7}{8}, \frac{1}{16},\frac{9}{16},\frac{5}{16},\frac{13}{16}, \frac{3}{16}, \frac{11}{16}, \frac{7}{16}, \frac{15}{16},…$](https://habrastorage.org/getpro/habr/formulas/b0c/fe1/b6a/b0cfe1b6aa488fcd8ef81fa80461899a.svg)
В следующем разделе мы сравним общие характеристики и эффективность каждой из этих последовательностей. Рассмотрим задачу вычисления определённого интеграла

Мы можем аппроксимировать его как:
![$A \simeq A_n = \frac{1}{n} \sum_{i=1}^{n} f(x_i), \quad x_i \in [0,1]$](https://habrastorage.org/getpro/habr/formulas/d84/b9c/727/d84b9c72759626c3e617a5de26e621d0.svg)
- Если
 равны
равны  , это это формула прямоугольников;
, это это формула прямоугольников; - Если выбираются случайным образом, то это метод Монте-Карло; а
- Если являются элементами последовательности с низким расхождением, то это метод квази-Монте-Карло.
На графике ниже показаны типичные кривые погрешностей
для аппроксимации определённого интеграла, связанного с этой функцией, при: (i) квазислучайных точках из аддитивной рекурсии, где , (синие); (ii) квазислучайных точках из последовательности ван дер Корпута, (оранжевые); (iii) случайно выбранных точках, (зелёные); (iv) последовательности Соболя (красные).Это показывает, что для
точек решение со случайным сэмплированием приводит к погрешности , последовательность ван дер Корпута приводит к погрешности , тогда как -последовательность приводит к погрешности , что в 10 раз лучше, чем погрешность ван дер Корпута и в 1000 раз лучше, чем (равномерное) случайное сэмплирование.Рисунок 2. Сравнение одномерного численного интегрирования с помощью различных квазислучайных методов Монте-Карло. Чем меньше значения, тем лучше. Новая
-последовательность (синяя) и последовательность Соболя (красная), очевидно, самые лучшие.Здесь стоит упомянуть следующее:
- это соответствует знанию о том, что погрешности для равномерного случайного сэмплирования асимптотически снижаются к , а погрешность для обеих квазислучайных последовательностей стремится к
 .
. - Результаты для
 -последовательности (синей) и последовательности Соболя (красной) — лучшие.
-последовательности (синей) и последовательности Соболя (красной) — лучшие. - График демонстрирует, что последовательность ван дер Корпута обеспечивает хорошие, но невероятно постоянные результаты для задач интегрирования!
- Здесь видно, что для всех значений последовательность даёт результаты лучше, чем последовательность ван дер Корпута.
Новая последовательность, которая является последовательностью Кронекера с использованием золотого сечения, является одним из лучших вариантов для одномерных квазислучайных методов интегрирования Монте-Карло (Quasirandom Monte Carlo, QMC).
Стоит также заметить, что хотя
теоретически обеспечивает доказуемо оптимальный вариант, очень близок к оптимальному, а почти любое другое иррациональное значение обеспечивает превосходные кривые погрешностей для одномерного интегрирования. Именно поэтому очень часто используется для любого простого числа. Более того, с точки зрения вычислений, выбранное случайное значение в интервале почти абсолютно точно будет (в пределах машинной точности) иррациональным числом, а потому является хорошим выбором для последовательности с низким расхождением. Для визуальной разборчивости на показанном выше рисунке не показаны результаты последовательности Нидеррайтера, потому что они практически неотличимы от результатов последовательностей Соболя и . Последовательности Нидеррайтера и Соболя (вместе с их оптимизированным выбором параметров), которые использовались в этом посте, были вычислены в Mathematica с помощью того, что в документации называется «закрытыми проприетарными и полностью оптимизированными генераторами из библиотеки Intel MKL».Квазислучайные последовательности в двух измерениях
Большинство современных методов построения низкого расхождения в более высоких измерениях просто комбинирует (покомпонентно)
одномерных последовательностей. Для краткости в посте мы в основном будем рассматривать последовательность Холтона [Холтон, 1960 год], последовательность Соболя и -мерную последовательность Кронекера.Последовательность Холтона строится простым использованием
различных одномерных последовательностей ван дер Корпута, основание которых взаимно просто для всех других. То есть они являются попарными взаимно-простыми числами. Вне всяких сомнений, наиболее частым вариантом из-за своей очевидной простоты и логичности является выбор первых простых чисел. Распределение первых 625 точек, определяемых (2,3)-последовательностью Холтона, показано на рисунке 1. Хотя многие двухмерные последовательности Холтона являются прекрасными источниками последовательностей с низким расхождением, хорошо известно, что многие из них весьма проблематичны и не демонстрируют низкого расхождения. Например, на рисунке 3 показано, что (11,13)-последовательность Холтона создаёт очень заметные линии. Большие усилия были приложены к разработке методов выбора образцовых и проблематичных пар . В более высоких измерениях проблема становится ещё сложнее.При обобщении до более высоких размерностей рекурсивные методы Кронекера страдают ещё бОльшими трудностями. Хотя при использовании
создаются превосходные одномерные последовательности, чрезвычайно трудно хотя бы найти пары простых чисел, которые можно использовать в качестве базиса для двухмерного случая не являющегося проблематичным! В качестве обходного пути предлагалось использовать другие хорошо известные иррациональные числа, например . Они обеспечивают умеренно приемлемые результаты, но в общем случае не используются, потому что обычно не так хороши, как правильно подобранная последовательность Холтона. К решению этих проблемам вырождения прикладываются очень большие усилия.В предлагаемых решениях используются skipping/burning, leaping/thinning. А для кодирования (скрэмблинга) конечных последовательностей используется другая техника, часто применяемая для преодоления этой проблемы. Скрэмблинг невозможно использовать для создания открытой (бесконечной) последовательности с низким расхождением.
Рисунок 3. (11,13)-последовательность Холтона очевидно не является последовательностью с низким расхождением (слева). Не является ею и аддитивная рекурсивная (11,13)-последовательность (посередине). Некоторые двухмерные аддитивные рекурсивные последовательности, которые используют хорошо известные иррациональные числа, достаточно хороши (справа).
Аналогично, несмотря на в целом лучшие результаты последовательности Соболя, её сложность и, что более важно, необходимость очень тщательного выбора гиперпараметров делает её не такой дружелюбной.
Итак, повторим, в
измерениях:- типичные последовательности Кронекера требуют выбора линейно независимых иррациональных чисел;
- последовательность Холтона требует взаимно-простых попарно целых чисел; а
- последовательность Соболя требует выбора направляющих чисел.
Новая последовательность— единственная
Обобщение золотого сечения
tl;dr В этой части я расскажу о том, как строить новый класс
-мерной открытой (бесконечной) последовательности с низким расхождением, не требующий выбора базисных параметров, имеющий превосходные свойства низкого расхождения.Существует множество способов обобщения последовательности Фибоначчи и/или золотого сечения. Предложенный ниже метод обобщения золотого сечения не нов [Крчадинац, 2005 год]. Кроме того, характеристический многочлен связан с многими областями алгебры, в том числе числами Перрона и с числами Пизо-Виджаярагхавана. Однако нова в нём явная связь между этой обобщённой формой и построением высокоразмерных последовательностей с низким расхождением. Мы определяем обобщённый вид золотого сечения
как уникальный положительный корень . То есть,Для
, , что является каноничным золотым сечением.Для
, . Это значение часто называется пластической константой и оно обладает красивыми свойствами (см. также здесь). Предполагается, что это значение с наибольшей вероятностью является оптимальным для соответствующей двухмерной задачи [Хенсли, 2002 год].Для
, Для
, хотя корни этого уравнения не имеют замкнутого алгебраического вида, мы можем с лёгкостью получить численную аппроксимацию или стандартными способами, например методом Ньютона, или заметив, что для следующей последовательности :

Эта особая последовательность констант
была названа в 1928 году архитектором и монахом Гансом ван де Лааном "гармоническими числами". Эти особые значения можно очень элегантно выразить следующим образом:
![$\phi_2 = \sqrt[3]{1+\sqrt[3]{1+\sqrt[3]{1+\sqrt[3]{1+\sqrt[3]{1+…}}}}}$](https://habrastorage.org/getpro/habr/formulas/4e8/e20/abb/4e8e20abbe274d30ba1c8be5bbbfb425.svg)
![$\phi_3 = \sqrt[4]{1+\sqrt[4]{1+\sqrt[4]{1+\sqrt[4]{1+\sqrt[4]{1+…}}}}}$](https://habrastorage.org/getpro/habr/formulas/31a/884/06f/31a88406fe92ebdb6d6dcd35ee75b2b5.svg)
Также у нас есть следующее очень элегантное свойство:

Эта последовательность, иногда называемая обобщённой или отложенной последовательностью Фибоначчи, изучена достаточно глубоко [Как, 2004 год, Уилсон, 1993 год], а последовательность для
часто называется последовательностью Падована [Стюарт, 1996 год, OEIS A000931], а последовательность перечислена в [OEIS A079398]. Как сказано выше, основная задача этого поста — описать явную связь между этой обобщённой последовательностью и построением -мерных последовательностей с низким расхождением.Основной результат: следующая беспараметрическая



Для двух измерений эта обобщённая последовательность при
показана на рисунке 1. Точки очевидно распределены намного равномернее в -последовательности, чем в (2, 3)-последовательности Холтона, последовательности Кронекера, основанной на , последовательностях Нидеррайтера и Соболя. (Из-за сложности последовательностей Нидеррайтера и Соболя они были вычислены в Mathematica с помощью проприетарного кода, предоставленного Intel.) Такой тип последовательности, в котором базисный вектор является функцией от единственного вещественного значения, часто называется последовательностью Коробова [Коробов, 1959 год]Снова посмотрите на рисунок 1, чтобы сравнить различные двухмерные квазислучайные последовательности с низким расхождением.
Код и демонстрации
В одном измерении псевдокод для
-ного члена ( = 1,2,3,….) определяется какg = 1.6180339887498948482
a1 = 1.0/g
x[n] = (0.5+a1*n) %1
В двух измерениях псевдокод для координат
и -ного члена ( = 1,2,3,….) определяются как g = 1.32471795724474602596
a1 = 1.0/g
a2 = 1.0/(g*g)
x[n] = (0.5+a1*n) %1
y[n] = (0.5+a2*n) %1
Псевдокод в трёх измерениях для координат
, и -ного члена ( = 1,2,3,….) определяется как g = 1.22074408460575947536
a1 = 1.0/g
a2 = 1.0/(g*g)
a3 = 1.0/(g*g*g)
x[n] = (0.5+a1*n) %1
y[n] = (0.5+a2*n) %1
z[n] = (0.5+a3*n) %1
Шаблон кода на python. (учтите, что массивы и циклы Python начинаются с нуля!)
import numpy as np # Using the above nested radical formula for g=phi_d # or you could just hard-code it. # phi(1) = 1.61803398874989484820458683436563 # phi(2) = 1.32471795724474602596090885447809 def phi(d): x=2.0000 for i in range(10): x = pow(1+x,1/(d+1)) return x
# Number of dimensions. d=2 # number of required points n=50 g = phi(d) alpha = np.zeros(d) for j in range(d): alpha[j] = pow(1/g,j+1) %1 z = np.zeros((n, d)) # This number can be any real number. # Common default setting is typically seed=0 # But seed = 0.5 is generally better. for i in range(n): z[i] = (seed + alpha*(i+1)) %1 print(z)
Я написал код таким образом, чтобы он соответствовал математическим обозначениям, использованным в этом посте. Однако по причинам соглашений в программировании и/или эффективности стоит упомянуть некоторые модификации. Во-первых, поскольку
является аддитивной рекурсивной последовательностью, альтернативная формулировка , которая не требует умножения с плавающей запятой и сохраняет высокую точность для очень больших , имеет видz[i+1] = (z[i]+alpha) %1
Во-вторых, в языках, имеющих возможность векторизации, код дробной функции можно векторизировать следующим образом:
for i in range(n): z[i] = seed + alpha*(i+1) z = z %1
Наконец, мы можем заменить эти сложения чисел с плавающей точкой и целых чисел, умножив все константы на
, а затем соответствующим образом изменив функцию frac(.). Вот демонстрации с исходным кодом, созданные другими людьми на основе этой последовательности:- beta.observablehq.com/@jrus/plastic-sequence, разработчик Джейком Рус:
- www.shadertoy.com/view/4dtBWH, разработчик @Штирнерс Хост (XGKICK):
Минимальное расстояние упаковки
Новая
Хотя стандартный технический анализ вычисления расхождения заключается в оценке
-расхождения, мы сначала упомянем пару других геометрических (и, возможно, гораздо более интуитивно понятных!) способов демонстрации того, насколько новая последовательность предпочтительнее других стандартных методов. Если мы обозначим расстояние между точками и за , а , тогда график ниже показывает, как варьируется для -последовательности, (2,3)- последовательности Холтона, Соболя, Нидеррайтера и случайных последовательностей. Это можно увидеть на рисунке 6.Как и в предыдущем рисунке, величина минимального расстояния нормализована коэффициентом
. Можно заметить, что после точек в случайной последовательности (зелёная) почти наверняка появятся две точки, находящиеся чрезвычайно близко друг к другу. Также видно, что хотя (2,3)-последовательность Холтона гораздо лучше, чем случайное сэмплирование, она тоже, к сожалению, асимптотически снижается к нулю. Для последовательности Соболя причина снижению к нулю нормализованного заключается в том, что сам Соболь показал — последовательность Соболя падает со скоростью —, что хорошо, но очевидно намного хуже, чем , которая снижается только на .Для последовательности
(синяя) минимальное расстояние между двумя точками постоянно попадает в интервал от до . Заметьте, что оптимальный диаметр 0.868 соответствует коэффициенту упаковки в 59.2%. Сравните это с другими упаковками кругов.Также заметьте, что Bridson Poisson disc sampling, которая не является расширяемой до
и обычно является рекомендуемой по умолчанию, всё равно создаёт коэффициент упаковки 49.4%. Стоит учесть, что концепция тесно связывает последовательности с низким расхождением с плохо аппроксимируемыми числами/векторами в измерениях [Хенсли, 2001 год]. Хотя нам мало известно о плохо аппроксимируемых числах в двух измерениях, построение может предоставить нам новый взгляд на плохо аппроксимируемые числа в более высоких размерностях.Рисунок 4. Минимальное попарное расстояние для различных последовательностей с низким расхождением. Заметьте, что
-последовательность (синяя) постоянно остаётся наилучшим вариантом; кроме того, это единственная последовательность, в которой нормализованное расстояние не стремится к нулю при . Последовательность Холтона (оранжевая) занимает второе место, а последовательности Соболя (зелёная) и Нидеррайтера (красная) не так хороши, но всё равно намного лучше, чем случайная (фиолетовая). Чем больше, тем лучше, потому что это соответствует бОльшему расстоянию упаковки.Диаграммы Вороного
Ещё один способ визуализации равномерности распределения точек — создание диаграммы Вороного из первых
точек двумерной последовательности с последующим раскрашиванием каждой области в зависимости от её площади. На рисунке ниже показаны цветовые диаграммы Вороного для (i) -последовательности; (ii) (2,3)-последовательности Холтона, (iii) рекурсии на основе простых чисел; и (iv) простого случайного сэмплирования. Для всех фигур использована одинаковая цветовая шкала. Здесь снова очевидно, что -последовательность обеспечивает намного более равномерное распределение, чем последовательность Холтона или простое случайное сэмплирование. Картина та же самая, что и выше, только раскрашена согласно количеству вершин в каждой ячейке Вороного. Здесь не только очевидно, что -последовательность обеспечивает более равномерное распределение, чем Холтон или простое случайное сэмплирование, но и более заметен тот факт, что ключевые значения состоят только из шестиугольников! Если мы рассмотрим обобщённую последовательность Фибоначчи, то . То есть :
Все значения, в которых
или , состоят только из шестиугольников.Рисунок 4. Визуализация формы диаграмм Вороного на основании площади каждого многоугольника Вороного для (i)
-последовательности; (ii) (2,3)-последовательности на основе простых чисел; (iii) (2,3)-последовательности Холтона, (iv) Нидеррайтера; (v) Соболя; и (iv) простое случайное сэмплирование. Цвета обозначают количество сторон каждого многоугольника Вороного. Повторюсь: очевидно, что -последовательность обеспечивает гораздо более равномерное распределение, чем любые другие последовательности с низким расхождением.При определённых значениях
Рисунок 5. Визуализация формы диаграмм Вороного на основании числа сторон каждого многоугольника Вороного для (i)
-последовательности; (ii) (2,3)-последовательности на основании простых чисел; (iii) (2,3)-последовательности Холтона, (iv) Нидеррайтера; (v) Соболя; и (iv) простого случайного сэмплирования. Цвета обозначают количество сторон каждого многоугольника Вороного. Повторюсь: очевидно, что -последовательность обеспечивает гораздо более равномерное распределение, чем любые другие последовательности с низким расхождением.Квазислучайный тайлинг Делоне для плоскости
Триангуляция Делоне, являющаяся подобием графа Вороного, предоставляет возможность по-другому посмотреть на эти распределения. Однако более важно то, что триангуляция Делоне обеспечивает новый метод создания квазипериодического тайлинга (мозаичного разбиения) плоскости. Триангуляция Делоне
-последовательности обеспечивает гораздо более равномерный паттерн, чем последовательность Холтона или случайная выборка. В частности, если выполняется триангуляция Делоне распределений точек, где равно любому из обобщённой последовательности Фибоначчи: , то триангуляция Делоне состоит только из трёх одинаково парных треугольников, то есть из параллелограммов (ромбоидов)! (За исключением треугольников, имеющих общую вершину с выпуклой оболочкой.) Более того,При значенияхтриангуляция Делоне
Рисунок 6. Визуализация триангуляции Делоне для (i)
-последовательности; (ii) (2,3)-последовательности Холтона, (iii) рекурсии на основе простых чисел; и (iv) простого случайного сэмплирования. Цвета обозначают область каждого треугольника. Во всех четырёх графиках использован одинаковый масштаб. И здесь снова очевидно, что -последовательность обеспечивает гораздо более равномерное распределение, чем любые другие последовательности с низким расхождением.Заметьте, что
основана на , являющемся наименьшим числом Пизо, (а — это наибольшее число Пизо). Связь квазипериодического тайлинга с квадратичными и кубическими числами Пизо не нова [Элкхаррат и Масакова], но я считаю, что впервые квазипериодический тайлинг был создан на основании .Показанная ниже анимация демонстрирует, как сетка Делоне для последовательности
меняется при постепенном добавлении точек. Заметьте, что когда количество точек равно члену обобщённой последовательности Фибоначчи, то вся сетка Делоне состоит только из красных, синих и жёлтых параллелограммов (ромбоидов), выстроенных в двояком квазипериодическом виде.Рисунок 7.
Хотя расположение красных параллелограммов демонстрирует значительную регулярность, можно чётко увидеть, что синие и жёлтые параллелограммы размещены в квазипериодическом виде. Спектр Фурье этой решётки можно увидеть на рисунке 11, он представляет собой классические точечные спектры. (Заметьте, что рекурсивная последовательность на основе простых чисел тоже кажется квазипериодической в том смысле, что это упорядоченный неповторяющийся паттерн. Однако её паттерн в интервале
не так постоянен, а также критически зависит от выбора базисных параметров. Поэтому мы сосредоточим наш интерес в квазипериодических тайлингах только последовательностью .) Она состоит всего из трёх треугольников: красного, жёлтого, синего. Учтите, что в этой последовательности все параллелограммы каждого цвета имеют одинаковый размер и форму. Соотношение площадей этих отдельных треугольников невероятно элегантно. А именно
То же относится и к относительной частоте треугольников:

Из этого следует, что общая относительная площадь, покрываемая этими тремя треугольниками в пространстве, равна:

Можно также предположить, что мы можем создать этот квазипериодический тайлинг через подстановку на основании последовательности A. То есть

Для трёх измерений, если мы рассмотрим обобщённую последовательность Фибоначчи, то
. То есть 
При определённых значениях3D-сетка Делоне, связанная с последовательностью
, задаёт квазипериодическую кристаллическую решётку.
Дискретизированная упаковка, часть 2
На рисунке ниже показаны первые
точек для каждой двухмерной последовательности с низким расхождением. Более того, каждая из ячеек 50×50=2500 раскрашена зелёным, только если она содержит ровно 1 точку. То есть чем больше зелёных квадратов, тем равномернее распределение 2500 точек по 2500 ячеек. Процент зелёных ячеек для каждого из рисунков следующий: (75%), Холтон (54%), Кронекер (48%), Нидеррайтер (54%), Соболь (49%) и случайная (38%).Звуковые волны
Просто ради интереса, по просьбе одного из читателей News Hacker я смоделировал, как все эти квазислучайные распределения точек могут звучать! Я использовал функцию Listplay из Mathematica: “ListPlay[{a1,a2,…}] создаёт объект, воспроизводящийся как звук, амплитуда которого задаётся как последовательность уровней.” Поэтому без всяких комментариев я предоставлю вам самим решать, какие из них вам больше нравятся среди одномерных квазислучайных распределений (моно) и двухмерных квазислучайных распределений (стерео).
| Моно | Стерео | |
|---|---|---|
| Случайная | ||
| Соболь | ||
| Нидеррайтер | ||
| Холтон | ||
| Кронекер | ||
| R |
Множества с многоклассовым низким расхождением
Некоторые последовательности с низким расхождением демонстрируют то, что называется «многоклассовым низким расхождением». До этого момента мы предполагали, что когда нам нужно как можно равномернее распределить
точек, то все точки одинаковы и неотличимы друг от друга. Однако во многих ситуациях существуют разные типы точек. Рассмотрим задачу равномерного распределения так, чтобы были равномерно распределены не только все точки, но и точки одного класса. В частности, предположим, что есть точек типа , (где ), тогда распределение мультимножества с низким распределением — это такое распределение, в котором каждая из точек равномерно распределена. В нашем случае мы обнаружили, что -последовательность и последовательность Холтона легко адаптировать под последовательности мультимножеств с низким расхождением, просто размещая попеременно точки каждого типа.На рисунке ниже показано, как распределяются
точек, при том что 75 имеют синий цвет, 40 — оражневый, 25 — зелёный, а 10 — красный. Для аддитивной рекурсивной последовательности это решается тривиально: первые 75 членов просто соответствуют синим, следующие 40 — оранжевым, следующие 25 — зелёным, а последние 10 — красным точкам. Эта техника почти срабатывает для последовательностей Холтона и Кронекера, но очень плохо показывает себя в последовательностях Нидеррайтера и Соболя. Более того, не существует известных техник для постоянной генерации многомасштабных распределений точек в последовательностях Нидеррайтера и Соболя. Это показывает, что распределения многоклассовых точек, например, таких, как глаза кур, можно теперь описывать и строить непосредственно с помощью последовательностей с низким расхождением.Последовательность
Рисунок 9. Многомасштабные последовательности с низким расхождением. В последовательности
равномерно распределены не только все точки, но и точки каждого отдельного цвета.Квазислучайные точки на сфере
В областях компьютерной графики и физики очень часто нужно как можно равномернее распределять точки на поверхности трёхмерной сферы. При использовании открытых (бесконечных) квазислучайных последовательностей эта задача сводится всего лишь к размещению квазислучайных точек, равномерно распределённых в единичном квадрате, на поверхности сферы с помощью равновеликой проекции Ламберта. Стандартное преобразование проекции Ламберта, размещающее точку
имеет вид:

-последовательность полностью открыта, она позволяет привязывать бесконечную последовательность точек к поверхности сферы, по одной точке за раз. Это контрастирует с другими методами, например с решёткой спирали Фибоначчи, которые требуют заранее знать количество точек. При визуальном осмотре мы снова можем чётко увидеть, что для новая -последовательность гораздо лучше распределена, чем наложение Холтона или сэмплирование Кронекера, которые, в свою очередь, гораздо равномернее случайного сэмплирования.Рисунок 10.
Дизеринг в компьютерной графике
Большинство современных техник дизеринга (например, дизеринг Флойда-Стейнберга) основано на распределении ошибок, что не очень подходит для параллельной обработки и/или непосредственной оптимизации в GPU. В таких случаях превосходные характеристики производительности показывает точечный дизеринг со статическими масками дизеринга (т.е. полностью зависимыми от целевого изображения). Вероятно наиболее известные и широко используемые маски дизеринга основаны на матрицах Байера, однако более новые пытаются ближе имитировать характеристики синего шума. Нетривиальная сложность создания масок дизеринга на основании последовательностей с низким расхождением и/или синего шума, заключается в том, что эти последовательности с низким расхождением проецируют целочисленное
в двухмерную точку в интервале . Но для маски дизеринга требуется функция, которая проецирует двухмерные целочисленные координаты растеризированной маски в вещественные яркость/пороговое значение в интервале . Я предлагаю следующий подход, основанный на -последовательности. Для каждого пикселя (x,y) в маске мы присваиваем его яркости значение , где:


То есть
, а значит
Более того, если добавлена функция треугольной волны для устранения разрывности, вызванной функцией frac(.) на каждой целочисленной границе:

![$I(x,y) = T \left[ \alpha_1 x + \alpha_2 y \; ( \textrm{mod} 1) \right];$](https://habrastorage.org/getpro/habr/formulas/ea7/412/4bf/ea74124bf1c194455fe49862b754b648.svg)
то маска и её график фурье/частотограмма ещё больше улучшаются. Также мы заметим, что поскольку

то вид приведённого выше выражения связан со следующим конгруэнтным уравнением

R-маски дизеринга создают результаты, конкурирующие с современными методами на основе масок синего шума. Но в отличие от масок синего шума, их не обязательно вычислять заранее, потому что их можно вычислять в реальном времени.
Стоит заметить, что эту структуру также предлагал Миттринг, но он находит коэффициенты эмпирически (и не воспроизводит окончательные значения). Более того, это помогает в понимании того, почему так хорошо работает эмпирическая формула Хорхе Хименеса, использованная при создании «Call of Duty» (часто её называют «Interleaved Gradient Noise»).
![$I(x,y) = (\textrm{FractionalPart}[52.9829189*\textrm{FractionalPart}[0.06711056*x + 0.00583715*y]]$](https://habrastorage.org/getpro/habr/formulas/eff/5c6/7d6/eff5c67d667f94e0e15013cd3b55a08e.svg)
Однако для неё требуется 3 умножения с плавающей запятой и два оператора %1, а предыдущая формула показывает, что мы можем сделать это всего двумя умножениями с плавающей точкой и одной операцией %1. Но важнее то, что этот пост даёт более чёткое математическое понимание того, почему маска дизеринга в таком виде настолько эффективна, если не оптимальна. Результаты этой матрицы дизеринга показаны ниже на примере классического тестового изображения «Lena» 256×256, а также шахматного тестового паттерна. Также показаны результаты использования стандартных масок дизеринга Байера, а также один пример с синим шумом. Два наиболее распространённых метода синего шума — это Void-and-Cluster и Poisson disc sampling. Для краткости я показал только результаты метода Void and cluster. [Питерс]. Interleaved gradient noise работает лучше, чем Байер и синий шум, но не так хорошо, как
-дизеринг. Можно увидеть, что дизеринг Байера демонстрирует заметный диссонанс белого в светло-серых областях. Дизеринг -последовательностью и синим шумом в общем виде сравнимы, хотя можно разобрать незначительные отличия. Стоит заметить некоторые аспекты R-дизеринга:- Он не изотропный! Спектры Фурье демонстрируют только отдельные и дискретные точки. Это классический признак квазипериодических тайлингов и дифракционных спектров квазикристаллов. В частности, спектры Фурье для -маски соответствуют тому факту, что триангуляция Делоне для канонической R-последовательности состоит из квазипериодического тайлинга трёх параллелограммов.
- R-дизеринг при комбинировании с треугольной волной обеспечивает невероятно равномерную маску!
- Несмотря на отличающийся внешний вид двух R-масок дизеринга, в окончательных результатах дизеринга разницы почти нет.
- Глядя на губы и плечи Лены, можно сказать, что R-дизеринг обеспечивает более чёткие результаты, чем маска синего шума.
- Яркость
 внутренне является вещественным числом, а потому маски естественным образом масштабируются до произвольных битовых глубин.
внутренне является вещественным числом, а потому маски естественным образом масштабируются до произвольных битовых глубин.
Рисунок 11. Слева направо: (i) Исходное изображение (ii) R-последовательность, скомбинированная с функцией треугольной волны; (iii) R-последовательность отдельно; (iv) маска дизеринга синего шума и (v) стандартный Байер. Маски дизеринга R-последовательности вполне конкурентны против других современных масок. Заметьте, что R2 показывает лучшее качество на лице и плечах Лены. Кроме того, в отличие от масок синего шума, R-маска дизеринга так проста, что не требует предварительных вычислений.
Более высокие размерности
Аналогично предыдущему разделу, но для пяти (5) измерений, график ниже показывает (глобальное) минимальное расстояние между любыми двумя точками для
-последовательности, (2,3,5,7,11)-последовательности Холтона и случайной последовательности. На этот раз нормализованная величина минимального расстояния нормализована на коэффициент . Можно увидеть, что вследствие «проклятия размерностей» случайное распределение лучше, чем все последовательности с низким расхождением — за исключением -последовательности. В -последовательности даже при точках минимальное расстояние между двумя точками всё ещё постоянно находится рядом с и всегда выше .Последовательность.
Рисунок 12. Это показывает, что R-последовательность (синяя) постоянно лучше Холтона (оранжевая); Соболя (зелёная); Нидеррайтера (красная); и случайной (фиолетовая). Учтите, что чем больше, тем лучше, потому что это соответствует бОльшему расстоянию упаковки.
Численное интегрирование
На следующем графике показаны типичные кривые погрешностей
для аппроксимации определённого интеграла, связанного с гауссовой функцией половинной ширины , , при этом: (i) (синяя); (ii) последовательность Холтона (оранжевая); (iii) случайная (зелёная); (iv) Соболь (красная). График показывает, что для точек разница между случайным сэмплированием и последовательностью Холтона теперь меньше. Однако, как было показано на одномерном случае, -последовательность и Соболь постоянно лучше последовательности Холтона. Это также даёт нам понять, что последовательность Соболя незначительно лучше -последовательности.Рисунок 13. Квазислучайные методы Монте-Карло для 8-мерного интегрирования. Чем меньше значения, тем лучше. Новая R-последовательность и последовательность Соболя показывают себя значительно лучше, чем последовательность Холтона.
