Comments 326
Больше похоже на самооблизывание, чем на статью. Я так и не узнал, зачем мне стоит писать меньше кода. Серьезно, тяжело разобрать свой код с хорошими комментариями? Чувак, ну, ты делаешь что-то не так. Н
Серьезно, тяжело разобрать свой код с хорошими комментариями?
Если ты прямо сейчас работаешь с этим проектом и видел этот код два дня назад — то ни хорошие ни плохие комментарии не нужны, за очень редким исключением.
А вот если к этому проекту (или к этой части в большом проекте) ты возвращаешься спустя 4 месяца — то даже свой собственный код воспринимается так же тяжело как и чужой.
Если в него вдумываться — можно понять, хотя бы немного отдаленно, что происходит внутри. Да, это сложно, но это не настолько большая проблема, что нужно сразу уменьшать размер кода.
Подавляющее большинство времени программист меняет существующий код, а не пишет новый. С чего это упрощение этого процесса не является важной проблемой?
А вот думают, читают и решают как раз очень много.
Во-первых, непосредственно при написании больше шансов допустить ошибку, во-вторых, при рефакторинге, большое количество кода редактировать куда тяжелее. Даже психологически: мысль «вот такенную телегу мне придётся сейчас разбирать» вполне может выбить из потока. Документирование каждой детали такого кода тоже не спасает, каждый раз при рефакторинге придётся поддерживать ещё и документацию, и в один момент произойдёт рассинхрон документации и реального кода.
Чем меньше кода и чем лаконичнее документация — тем лучше. Другое дело, что в реальной жизни всё равно придётся идти на компромиссы между количеством кода и например удобством тестирования и управлением зависимостями.
А всё потому, что на языке программирования и фреймворке мы пишем не «Hello world»-ы, а многокомпонентные приложения из тысяч строк кода, и взаимодействие кода с браузером клиента, удобство описания и взаимодействия компонентов, упаковка кода для клиента, отладка (на девелоперской, серверной и клиентской стороне!)… все эти вещи очень сильно влияют на разработку. А здесь даже до уровня «как написать if» не добрались, что уж говорить даже про модульные компоненты. Дело не в компромиссах из реальной жизни… А лишь в компромисах между «hello world» и реальным кодом.
Авторы, как вы собираетесь эти var a=… упаковывать и импортить вообще? Компоненты в React и Vue — именно этот вопрос решают. Их может быть несколько на один файл, им можно настроить области видимости. Первый попавшийся пример из интернета: github.com/HugoDF/vue-multiple-components-in-sfc/blob/master/02-global-component-string-template/src/App.vue, там объявлено два компонента: HelloWorld/'hello-world' и default/'app' (имя переменной компонента — по имени файла шаблона). Я в любой момент могу переименовать default в любое другое имя. У меня есть возможность инициализации этих переменных из различных источников и в разные моменты жизненного цикла компонента. А у вас псевдо-глобальные переменные почему-то этому решению соответствуют…
Дело в том, что Svelte — он не React и не Vue. Упаковывает и импортит компилятор. Вам об этом думать не надо. В этом и смысл — чтобы не писать кучу шаблонного кода(т.е. boilerplate), который обязательно должен быть в фреймворке с runtime. В учебнике чуть подробнее про импорты и вложенные компоненты(полистайте вперед немного, там последовательное объяснение и выполнение уроков)
кучу шаблонного кода(т.е. boilerplate), который обязательно должен быть в фреймворке с runtime
С чего бы?
С чего бы?
Потому что обычно фреймворк заранее не может знать какую его часть вы использовать НЕ будете. Svelte же предлагает иной подход.
Я имел ввиду не весь сам код фреймворка который загружается в память в не зависимости нужны ли его части или нет(отсутсвие оного, тоже несомненный плюс Svelte, безусловно).
Я хотел сказать, что runtime предполагает обязательные ритуальные действия, например как у помянул Rich в этой статье для Vue:
...
import Component from 'component';
export default {
...
components: {
Component
}
...
}Т.е. нельзя просто импортировать компонент и сразу вставить его в разметку. Нужно зарегистрировать его, чтобы он попал в рантайм. Т.е. лишние шаблонные действия.
Т.е. нельзя просто импортировать компонент и сразу вставить его в разметку.
Можно даже не импортировать, не устанавливать, а сразу использовать. Имея при этом рантайм. Пример я тут уже приводил.
Я хотел сказать, что runtime предполагает обязательные ритуальные действия
Эти действия выполняются не потому что что-то там в рантайме, они выполняются потому, что там точки настройки. Если вы будете автоматически генерировать вызов component и регистрацию компонента в модуле, то вы не сможете ни передать в компонент те или иные свойства, ни подменить реализации провайдеров.
Потому что обычно фреймворк заранее не может знать какую его часть вы использовать НЕ будете.
А тришейкинг куда делся?
обязательно
...
обычно
Вы уж определитесь там.)
А всё потому, что на языке программирования и фреймворке мы пишем не «Hello world»-ы, а многокомпонентные приложения из тысяч строк кода, и взаимодействие кода с браузером клиента, удобство описания и взаимодействия компонентов, упаковка кода для клиента, отладка (на девелоперской, серверной и клиентской стороне!)… все эти вещи очень сильно влияют на разработку. А здесь даже до уровня «как написать if» не добрались, что уж говорить даже про модульные компоненты. Дело не в компромиссах из реальной жизни… А лишь в компромисах между «hello world» и реальным кодом.
На своем опыте знаю, что если пишешь мало-мальски объемную статью, вкладываешь много сил, а ее потом почти никто не читает. Поэтому расчитывать на то, что в статьях на Хабре будут рассматриваться примеры приложений из реальной жизни, как минимум странно. Вы же сами их и не будете потом читать.
Авторы, как вы собираетесь эти var a=… упаковывать и импортить вообще? Компоненты в React и Vue — именно этот вопрос решают.
Все это в итоге работает точно также, только пишется проще, без лишнего бойлерплейта. Компоненты абсолютно изолированные. Есть разделение на внутренний стейт и интерфейс компонента (пропсы/методы). Причем сделано довольно элегантно на мой взгляд:
Пишем компонент:
<script>
let privateVar = 1,
publicProp = 2;
function privateFunc() { ... }
function publicMethod() { ... }
export { // публичный интерфейс
publicProp,
publicMethod
};
</script>
Используем через инстанс компонента или декларативно:
<Nested bind:this={comp} publicProp={3} />
<script>
import Nested from './Nested.svelte';
let comp; // или через инстанс
...
comp.publicProp = 4;
comp.publicMethod();
</script>
Их может быть несколько на один файл,
Это скорее минус чем плюс и нужно бить по рукам. Один компонент — один файл. Без исключений. Если нужно, например, представить несколько логически связанных компонентов как единый «пакет», то проще и нагляднее сделать так:
// multipleComponents/index.js
import HelloWorld from './HelloWorld.svelte';
import Default from './Default.svelte';
export default Default;
export HelloWorld;
Я в любой момент могу переименовать default в любое другое имя.
Если вы про устаревший механизм «регистрации» компонентов, то например в реакт его никогда не было. Да и нативные импорты позволяют вам переименовывать компоненты и так:
<Posts />
<Message />
<script>
import Posts from './Listview.svelte';
import { HelloWorld as Message } from './multipleComponents/';
</script>
У меня есть возможность инициализации этих переменных из различных источников и в разные моменты жизненного цикла компонента. А у вас псевдо-глобальные переменные почему-то этому решению соответствуют…
В Svelte все тоже самое, только лаконичнее. Более того, синтаксис Svelte 2 был очень похож на Vue. Если уж быть совсем точным, потому что синтаксис Vue был изначально скопирован с Ractive, автором которого является автор Svelte. Так что можно сказать, тот синтаксис, который вы так полюбили, придумал автор статьи ;-)
Это скорее минус чем плюс и нужно бить по рукам. Один компонент — один файл.
Так это как раз ведет к лишнему бойлерплейту. В том же реакте подход предполагает делать много-много мелких компонентов, которые имеют смысл только в одном месте и бойлерплейтом будет как раз разделять их по файлам.
Если нужно, например, представить несколько логически связанных компонентов как единый «пакет», то проще и нагляднее сделать так:
То есть в дополнение к бойлерплейту с разделением по файлам добавляется бойлерплейт в виде реимпортов?
Кстати, а как в svelte с ленивой подгрузкой компонентов дела обстоят?
Так это как раз ведет к лишнему бойлерплейту. В том же реакте подход предполагает делать много-много мелких компонентов, которые имеют смысл только в одном месте и бойлерплейтом будет как раз разделять их по файлам.
Тут я с вами не согласен. Есть полезный бойлерплейт, а есть бесполезный. Бесполезный это когда ты вынужден писать кучу лишних скобок или импортировать, а потом еще регистрировать комоненты и другие сущности, и т.п.
А тут на лицо полезный бойлерплейт. Во-первых, он делает структуру приложения понятно и прозрачной. Во-вторых, «много-много мелких компонентов» это условное понятие, потому что пока компонент мелкий, а знавтра новая задача и он уже большой. Один разработчик привык искать его в файле с другим компонентов, а другой был вынужден вынести его в отдельный файл. В-третьих, сейчас в этом месте нужен один подкомпонент, а завтра надо свитчить между 5-ю, тоже в этот же файл засунем все? В-четвртых, сегодня этот компонент нужен в одном месте, а завтра в 2-х. Получается постоянный refactoring-driven-development даже там, где он не нужен изначально.
Если уж есть какая-то начальная уверенность, что подкомпонент будет использоваться только совместно с родительским, то этот вопрос имхо лучше решить на уровне файловой системы:
/src/
/components/
/Grid/
index.js
Grid.svelte
/components/
UserCard.svelte
ProductCard.svelte
То есть в дополнение к бойлерплейту с разделением по файлам добавляется бойлерплейт в виде реимпортов?
Это совершенно не обязательно. Просто иногда это удобнее. Например вы примере выже, /src/components/Grid/index.js просто точка для импорта компонента Grid.svelte, чтобы удобнее было импортировать:
import Grid from '~/components/Grid/Grid.svelte';
vs
import Grid from '~/components/Grid/';
Кстати, а как в svelte с ленивой подгрузкой компонентов дела обстоят?
А как это вообще относится к фреймворку? Разве не любой фреймворк позволяется делать динамический импорт и значение промиса, который тот возвращает, вставлять в качестве компонента? Всю грязную работу все равно бандлер выполняет тут.
Есть полезный бойлерплейт, а есть бесполезный. Бесполезный это когда ты вынужден писать кучу лишних скобок или импортировать, а потом еще регистрировать комоненты и другие сущности, и т.п.
Импорт и регистрация — это как раз бойлерплейт полезный, т.к. он вам дает полезные возможности, который у вас без импорта и регистрации нет.
А тут на лицо полезный бойлерплейт. Во-первых, он делает структуру приложения понятно и прозрачной.
Это каким образом структура приложения становится более понятной и прозрачной от того что вас лишили возможности структурировать код?
«много-много мелких компонентов» это условное понятие, потому что пока компонент мелкий, а знавтра новая задача и он уже большой.
Ну вот когда будет большой (90% — что никогда), тогда и вынесете в отдельный файл. YAGNI же.
Один разработчик привык искать его в файле с другим компонентов, а другой был вынужден вынести его в отдельный файл
Шел 2019, казалось бы, а люди что-то там в файлах ищут.
Вы поймите, это проблема свелте, что у вас к файловой структуре привязана структура приложения. Нормальные фреймворки и средства разработки от этого уходят, не навязывая конкретное представления кодовой базы.
Один разработчик привык искать его в файле с другим компонентов, а другой был вынужден вынести его в отдельный файл. В-третьих, сейчас в этом месте нужен один подкомпонент, а завтра надо свитчить между 5-ю, тоже в этот же файл засунем все?
Какая разница вообще, в каком что файле? Обычно файлвоая структура разработчику неинтересна. Программист не работает с файлами, он работает с программными сущностями — модулями, классами, функциями.
Когда вы структуру вашего приложения привязываете к файловой структуре — в этом ничего хорошего нет, это все от бедного детства с деревянными игрушками.
то этот вопрос имхо лучше решить на уровне файловой системы:
Как раз нет, файловая система в идеале вообще не должна быть связана никак со структурой приложения. Так что не лучше. Просто на данный момент это один из самых распространенных способов решения проблемы.
А как это вообще относится к фреймворку?
Ну напрямую. Способ ленивого использования компонент всегда прибит к фреймворку. Как в свелте это делается? А динамические компоненты как создаются? Сам компонент в свелте как сущность — это вообще что?
Импорт и регистрация — это как раз бойлерплейт полезный, т.к. он вам дает полезные возможности, который у вас без импорта и регистрации нет.
Вот лично я с 2013 года импортирую и регистрирую компоненты. Сперва в рамках Ractive, потому Vue, потом Svelte 1-2. Расскажите пожалуйста о преимуществах импорта + регистрации, перед просто импортом. Интересно.
Это каким образом структура приложения становится более понятной и прозрачной от того что вас лишили возможности структурировать код?
Это передергивание. Понятной она становится потому, что я точно знаю, что каждый компонент логически отделен в отдельный файл. У меня не может возникнуть ситуации, когда какой-то джун вдруг решил сделать свалку компонентов внутри одного файла, а я должен следить и бить по рукам.
Ну вот когда будет большой (90% — что никогда), тогда и вынесете в отдельный файл. YAGNI же.
Еще раз, мне это нужно, чтобы проект имел четкую структуру — один компонент, один файл. Без вариантов и вариаций, которые в данном случае совершенно неуместны.
Шел 2019, казалось бы, а люди что-то там в файлах ищут.
А вы видимо не с файлами работаете? Поиск конечно хорошо, но если ты знаешь где находится компонент, значительно проще просто открыть сразу нужный файл.
Вы поймите, это проблема свелте, что у вас к файловой структуре привязана структура приложения. Нормальные фреймворки и средства разработки от этого уходят, не навязывая конкретное представления кодовой базы.
Нормальные это какие? На том же Vue, с которого началось обсуждение, и на котором мы писали с момента появления 2-ки и до сих пор, никто тоже так не делает. Идеоматический способ использовать все те же SFC. То что реакт можно превратить в помойку большая часть разработчиков реакт, с которыми я знаком, считают пагубным делом и имеют проблемы с этим на своих проектах. Не нужно придумывать из мухи слона. Для мелкого проекта, засунуть в один файл еще куда ни шло, но когда проект хоть чуть крупнее или средний — это большая ошибка.
Какая разница вообще, в каком что файле? Обычно файлвоая структура разработчику неинтересна. Программист не работает с файлами, он работает с программными сущностями — модулями, классами, функциями.
А импортируете эти сущности вы не из файлов случаем?
Когда вы структуру вашего приложения привязываете к файловой структуре — в этом ничего хорошего нет, это все от бедного детства с деревянными игрушками.
В общении с вами есть одна большая проблема — много воды и эпитетов, мало смыслов и дела. Разделение сущностей на отдельные файлы, а типов сущсностей на отдельные папки, я лично считаю единственным верным способом структуризации приложения. Вы видимо валите все в одни файл, аля PHP начала 2000-ых.
Как раз нет, файловая система в идеале вообще не должна быть связана никак со структурой приложения. Так что не лучше. Просто на данный момент это один из самых распространенных способов решения проблемы.
Совершенно не согласен. Ваше право так думать, но такие штуки как Next/Nuxt/Sapper даже конвенции роутинга возложили на файловую систему. И многих людям, включая меня, очень нравится.
Ну напрямую. Способ ленивого использования компонент всегда прибит к фреймворку.
Вы не очень видимо понимаете, что сама инициализация «ленивого» или «не ленивого» компонента, но просто динамического компонента, никак не отличаются. То есть если вы просто можете сменить компонент по условию где-то в точке монтирования, то этого достаточно для того, чтобы работала подгрузка компонентов по запросу. Поэтому, нет, сама по себе ленивая загрузка компонентов с фреймворком не связана. Либо надо формулировать не «ленивый», который подразумевает «по запросу», а «динамический», который подразумевает подстановку в рантайме.
Как в свелте это делается? А динамические компоненты как создаются?
Легче легкого:
<button on:click={load}>Load component</button>
<svelte:component this={comp} />
<script>
let comp = null;
function load() {
import('./Component.svelte')
.then(({ default }) => {
comp = default;
});
}
</script>
Или даже просто так при рендере парента и сразу со индикацией загрузки и выводом ошибок:
{#await import('./Component.svelte')}
<p>Loading...</p>
{:then comp}
<svelte:component this={comp.default} />
{:catch err}
<p>Component loading error: {err.message}</p>
{/await}
Сам компонент в свелте как сущность — это вообще что?
Просто класс. Поэтому в отличии от реакт, его можно использовать из внешнего, по отношению к Svelte, кода. Инстанциировать, дергать методы и т.п.
import Cart from '~/compoenents/Cart.svelte';
const cart = new Cart({
target: document.getElementById('cart'),
props: { ... }
});
// total sum of products in cart (computed value)
console.log(cart.total);
// <button id="addBtn" value="{productId}">Add to cart</button>
document.getElementById('addBtn').addEventListener(e => {
cart.add(+e.target.value);
});
Уточнение: в реакте компонент точно так же можно создать из внешнего кода и дергать его методы, просто потребуется 1 вызов ReactDOM.render
function Cart() {
....
}
ReactDOM.render(<Cart />, document.getElementById('cart');
Только вот что делать, если файл внешнего кода не проходит через сборщик (транспиллер), например? Как зашипить компонент React в качестве подключаемого на страницу через script-тег класса?
Вот так же:
var Cart = require('Cart'); // допустим, у нас requirejs
var cart = ReactDOM.render(React.createElement(Cart), document.getElementById('cart'));Разумеется, сам компонент через транспилер придётся перегнать.
Ну, в подобном коде предполагается, что компонент Cart подготовлен для взаимодействия с внешним кодом. Разумеется, такие компоненты никто не будет переводить на хуки.
Обычные компоненты (те, что взаимодействуют через свойства, а не через методы) тоже можно подключать, но придется вызывать ReactDOM.render для каждого изменения свойств.
Расскажите пожалуйста о преимуществах импорта + регистрации, перед просто импортом. Интересно.
Смысл регистрации состоит не в том, чтобы просто добавить лишнюю работу, а в том, что при регистрации можно настроить регистрируемый объект и характер его использования в конкретном модуле.
Это передергивание. Понятной она становится потому, что я точно знаю, что каждый компонент логически отделен в отдельный файл.
Но но когда надо не в отдельный, то это менее понятно, наоборот.
А импортируете эти сущности вы не из файлов случаем?
Нет, конечно. Импортирую я из модуля/неймспейса. А как эти модули/нейспейсы представлены на жестком диске или в памяти — от пользователя, вообще говоря, должно быть скрыто. Иначе абстракция течет.
Разделение сущностей на отдельные файлы, а типов сущсностей на отдельные папки, я лично считаю единственным верным способом структуризации приложения.
То, что вы описываете, не имеет отношения к структуризации приложения. Потому что приложение — это не файлы и папки. У вас просто чрезмерно низкоуровневое мышление.
Вы видимо валите все в одни файл, аля PHP начала 2000-ых.
Как раз раньше никто ничего в один файл не валил, потому что без иде потом в этом ворохе нельзя было бы работать, а иде нормальных не было.
Смысл регистрации состоит не в том, чтобы просто добавить лишнюю работу, а в том, что при регистрации можно настроить регистрируемый объект и характер его использования в конкретном модуле.
А как вы его в Vue можем прям уж «настроить»?
import Nested from './Nested.vue';
export default {
components: {
Nested
}
};
Так, что настраивать будем?
Но но когда надо не в отдельный, то это менее понятно, наоборот.
Просто никогда не надо.
Нет, конечно. Импортирую я из модуля/неймспейса. А как эти модули/нейспейсы представлены на жестком диске или в памяти — от пользователя, вообще говоря, должно быть скрыто. Иначе абстракция течет.
В JS нет модулей/неймспейсов. Вы может из ангулярщиков вообще? Раскусил вас))) Вас так послушать, раз такая штука есть только в ангуляр, то и использовать надо только его))))
То, что вы описываете, не имеет отношения к структуризации приложения. Потому что приложение — это не файлы и папки. У вас просто чрезмерно низкоуровневое мышление.
А у вас значит чрезмерно высокоуровневое. Есть в вашем фреймворке модули/неймспейсы (кстати модули из ангуляра вроде выпиливать собирались), навится — пользуйтесь. Вообще не понимаю, зачем представитель application framework тратит свое время на баталии в рамках ui frameworks. Вы бы вон пошли, недавно статья по Ember вышла. Это из той же ниши фреймворк, что и ангуляр.
Как раз раньше никто ничего в один файл не валил, потому что без иде потом в этом ворохе нельзя было бы работать, а иде нормальных не было.
Все валили. PHP вообще получил такое распространение по большей части потому, что умел нативно встраиваться в HTML и первое время это всех забавляло, что мешаем в один файл сразу. Только потом когда сайты подростать стали, подумали что не очень как-то.
он вам дает полезные возможности, который у вас без импорта и регистрации нет.
MAM архитектура даёт эти возможности без ручных импортов и регистраций. Так что бойлерплейт этот весьма бесполезный.
Нормальные фреймворки и средства разработки от этого уходят, не навязывая конкретное представления кодовой базы.
Обычно файлвоая структура разработчику неинтересна.
И это очень плохо, так как поощряет бардак в репозитории. Напротив, форсирование порядка, позволяет использовать это для уменьшения бойлерплейта. В частности — избавиться от импортов и регистраций.
Вы вот правда считаете, что возможность навести в репозитории беспорядок стоит написания кучи бойлерплейта?
MAM архитектура даёт эти возможности без ручных импортов и регистраций.
Не дает. Связь компонент-модуль — это многие-ко-многим. С-но, либо вы в модуле должны регистрировать все используемые им компоненты, либо в компоненте должны регистрировать все модули, в которых этот компонент используется (что шиза, конечно), либо иметь отдельный конфиг с описанием всех связей. Других вариантов описать отношение нет.
Вы вот вроде много слов написали, а смысл я так и не уловил. Вот где в $mol импорты/экспорты/регистрации/конфиги с отношениями?
Я откуда знаю? $mol же это ваш фреймворк.
Вот и скажите, как мне настроить в $mol использование компонента Х в модуле Y.
Я же написал, что подобная настройка там не требуется, а вы со мной спорите. Видимо вы знаете про "мой" фреймворк что-то, что не знаю я.
Я же написал, что подобная настройка там не требуется
Это вы как определили? Вот есть у меня модуль, мне надо в этом модуле в конкретном контексте подменить зависимости. Ну на тестовые, к примеру. Как решается эта задача в $mol? Или конфиг передать при инициализации. При этом модуль может использоваться в нескольких местах но с разными конфигами. Как это сделать?
В том же реакте подход предполагает делать много-много мелких компонентов, которые имеют смысл только в одном месте и бойлерплейтом будет как раз разделять их по файлам.
В том же реакте много-много мелких компонентов появляется, главным образом, в процессе оптимизации, ведь границы компонента являются барьером для рендера.
В svelte, судя по тому что я читал, просто нет необходимости разбивать большой компонент на кучу мелких ради того чтобы оно перестало лагать.
Я так и не узнал, зачем мне стоит писать меньше кода.
Верно, ведь больше кода = больше бананов!!!
Пока единственный здоровый плюс Svelte для меня — маленький бандл, это классно. Но такоже даёт elm, которому куча лет и тп.
Ну есть еще vue-native, flutter с dart..
Силами сообщества сейчас пилится Svelte-Native, но пока не для серьёзного применения.
Пример vue плохой- data может быть стрелочной функцией
function handleChangeA(event) { setA(+event.target.value); } function handleChangeB(event) { setB(+event.target.value); } <input type="number" value={a} onChange={handleChangeA}/> <input type="number" value={b} onChange={handleChangeB}/>
Не будет такого в реальном проекте.
Будет
import Input from '../common'; ... <Input type="number" value={a} onChange={setA}/> <Input type="number" value={b} onChange={setB}/>
А еще вместо компонента можно сделать переиспользуемый хук
function useNumberValue(initialValue) {
const [value, setValue] = useState(initialValue);
return [value, event => setValue(+event.target.value)];
}
export default () => {
const [a, handleChangeA] = useNumberValue(1);
const [b, handleChangeB] = useNumberValue(2);
return (
<div>
<input type="number" value={a} onChange={handleChangeA} />
<input type="number" value={b} onChange={handleChangeB} />
<p>
{a} + {b} = {a + b}
</p>
</div>
);
};но это уже кому как удобнее
Ваш useNumberValue — это очень странный хук, поскольку использовать его можно только совместно с тэгом input.
Но теперь, если потребуется перейти с инпута на что-то ещё — придется менять ещё и хук. И все ради того, чтобы не использовать простейший функциональный компонент...
Скорее наоборот, можно будет переключаться между разными UI-библиотеками (Material, Bootstrap и т.д.) не трогая код внутри хука.
В целом считаю данный тред скорее публицистическим, ибо оба подхода имеют право на жизнь. Миру мир!
А вот то что фреймворк сам делает преобразование типа – это очень х… во. Нельзя менять общепризнаное API
То есть вы знаете конкретный кейс, когда значение поля для ввода с type=number должно использоваться как строка? Хм… честно говоря я не знаю. В итоге получается, что вам приходится создавать целый компонент, чтобы просто исправить неочевидное поведение браузерной реализации импута, а зачем? Если уж не хотите пользоваться благами автоматизации и хочется писать все руками, то Svelte не запрещает вам использовать подход реакта:
<input type="number" value={a} on:input={handleChangeA}>
<input type="number" value={b} on:input={handleChangeB}>
Пшык и проблемы нет? Был бы смысл в этом только…
Почему пользователи фреймворка должны учить кастомное поведение, если разработчики фреймоворка не удосужились выучить дефолтное?
Потому что это удобно, это изначально ожидаемое поведение для type=number и это скорее бага в спецификации. Кроме того, использование 2way биндингов не только опциональное, но и отключаемое на уровне компилятора.
Ну и как бы 2way биндинги не обязаны вообще следовать стандартам, потому что в стандартах их нет. Они нужны исключительно для удобства использования, а не просто для прокидывания значений как есть. Если вам нужно raw-значение, используйте ивенты как я описал выше и пишите собственное приведение типов для каждого места использования. Право ваше.
То есть вы знаете конкретный кейс, когда значение поля для ввода с type=number должно использоваться как строка?
Когда оно не целое.
При чем тут сложение? Вы спрашивали конкретный кейс, я вам назвал конкретный кейс. Складывать ничего не надо.
Попробуйте написать "0.5" в своем примере.
Еще у вас пишутся нули слева и сбрасывается позиция при автоматическом удалении нулей с конца.
Забаговано, короче, приемку ваш инпут не прошел.
И проблема в том, что нормальный инпут из него даже не сделать, не меня логики, которая там в потрохах защита.
Валидация с запятыми тоже, кстати, криво работает.
Попробуйте написать «0.5» в своем примере.
А вы попробуйте написать 0,5 то есть так как работает input type=number. Мне вот вообще само поле не дает написать точку. Все остальное работает как и предполагается: svelte.dev/repl/bb67cff2eaf0486498bb1510bc7b5fa4?version=3.3.0
Забаговано, короче, приемку ваш инпут не прошел.
И проблема в том, что нормальный инпут из него даже не сделать, не меня логики, которая там в потрохах защита.
Валидация с запятыми тоже, кстати, криво работает.
Здрасти, мы с вами не пишем компонент input number для всех случаев жизни, а просто получаем значение из html input в виде числа для сложения. И я не знаю кейсов, когда число нам нужно ввиде строки.
А вы попробуйте написать 0,5
Мне не надо 0,5, мне надо 0.5, потому что так хочет пользователь. И выводит же 0.5 с точкой. А вводится с запятой? Это что за шизофрения с разным форматом ввода/вывода?
работает input type=number
В нативном контроле можно и точку и запятую вводить. Это косяк того, как у вас обрабатываются биндинги.
Мне вот вообще само поле не дает написать точку.
Вот именно! А как сделать, чтобы давало?
Все остальное работает как и предполагается:
Нет, не работает. Стартовые нули должны удаляться (не удаляются) позиция курсора при удалении нулей на конце сбрасываться не должна (она сбрасывается), валидация запятой должна быть консистентна (она неконсистентна).
Здрасти, мы с вами не пишем компонент input number для всех случаев жизни, а просто получаем значение из html input в виде числа для сложения.
Я же вам сказал, в чем проблема. Проблема в том, что из вашего инпута нельзя сделать нормальный, человеческий инпут. Из инпута, который отдает строку — можно, а из вашего — нельзя. В этом и состоит кейс, когда "значение поля для ввода с type=number должно использоваться как строка".
Мне не надо 0,5, мне надо 0.5, потому что так хочет пользователь. И выводит же 0.5 с точкой. А вводится с запятой? Это что за шизофрения с разным форматом ввода/вывода?
Это веб-стандарты, детка) HTML вводит 0,1, а js выводит 0.1 )))) Причем тут Svelte?
В нативном контроле можно и точку и запятую вводить. Это косяк того, как у вас обрабатываются биндинги.
Скорее это уже исправление косяка нативного контрола, потому как после того, как вы введете 0.1, а потом начнете использовать нативные стрелочки, ваше значение наменится на значение с запятой. Лучше уж чтобы все было единообразно.
Вот именно! А как сделать, чтобы давало?
То что не дает, пожалуй, может оказаться просто багой. Надо будет код глянуть.
Нет, не работает. Стартовые нули должны удаляться (не удаляются) позиция курсора при удалении нулей на конце сбрасываться не должна (она сбрасывается), валидация запятой должна быть консистентна (она неконсистентна).
Типа, вы считаете правильным, что для input number можно написать число 007 и браузерный инпут спокойно примет это значение в качестве числа? Мне кажется это не нормально. Если считаете иначе, можете не юзать биндинги. Мое мнение тут не изменилось — биндинги чинят некоторые огрези реализации нативных контролов, чтобы разработчику было удобнее.
Я же вам сказал, в чем проблема. Проблема в том, что из вашего инпута нельзя сделать нормальный, человеческий инпут. Из инпута, который отдает строку — можно, а из вашего — нельзя. В этом и состоит кейс, когда «значение поля для ввода с type=number должно использоваться как строка».
У нас с вами видимо разные представления о правильном инпуте. Для меня числовой инпут дающий вводить не число — это не совсем правильный инпут))
Причем тут Svelte?
Svelte при том, что этот инпут — не нативный, а обертка над ним. Он не ведет себя как нативный, он ведет себя так, как написали разработчики svelte.
Это веб-стандарты, детка)
Но вы же понимаете, что пользователю до фени веб-стандарты?
Я еще раз уточню, в чем проблема — она не в том что поведение конкретно такое, кривое или нет, не важно. Оно в том, что его поменять нельзя. Именно из-за того, что у вас число вместо строки.
То есть ответ на ваш вопрос "зачем надо число возвращать в виде строки" — чтобы можно было свободно его обработать, как захочется.
Скорее это уже исправление косяка нативного контрола, потому как после того, как вы введете 0.1, а потом начнете использовать нативные стрелочки, ваше значение наменится на значение с запятой
Оно на целое число меняется, там ни запятых, ни точек. И это не важно, поймите, как вам (или мне, или разработчику свелте) кажется лучше.
У нас с вами видимо разные представления о правильном инпуте.
Представление о правильно инпуте, оно очень простое и одно единственное: то, что пользователь хочет видеть в качестве правильного инпута, то и есть правильный инпут.
Svelte при том, что этот инпут — не нативный, а обертка над ним. Он не ведет себя как нативный, он ведет себя так, как написали разработчики svelte.
Это реализация биндинга такая. Может она бажит, что не исключено. В любом случае, если что-то не устраивает в нем, всегда можно использовать `on:input`.
Я еще раз уточню, в чем проблема — она не в том что поведение конкретно такое, кривое или нет, не важно. Оно в том, что его поменять нельзя. Именно из-за того, что у вас число вместо строки.
Можно не использовать биндинг и написать любое свое поведение. Svelte не исключает подход реакта, но дополнят его автоматическим биндингом.
То есть ответ на ваш вопрос «зачем надо число возвращать в виде строки» — чтобы можно было свободно его обработать, как захочется.
Вопрос был зачем это делать, если реализация биндинга подразумевает его конвертацию. Нужна строка пожалуйста:
<input type="number" value={a} on:input={e => a = +e.target.value}>
Оно на целое число меняется, там ни запятых, ни точек. И это не важно, поймите, как вам (или мне, или разработчику свелте) кажется лучше.
А вы сами попробуйте:
<input type="number" step="0.1" bind:value={a}>
Представление о правильно инпуте, оно очень простое и одно единственное: то, что пользователь хочет видеть в качестве правильного инпута, то и есть правильный инпут.
А что пользователь хочет видеть решаете вы или кто?
Это реализация биндинга такая.
Да. Но проблема в том, что какую вы реализацию не сделаете — все равно в определенных случаях понадобится другое поведение, не то, которое вшито разработчиком. А исправить его нельзя, т.к. компонент возвращает число, а не строку.
Можно не использовать биндинг и написать любое свое поведение.
То есть свой инпут писать? Отличное предложение.
А вы сами попробуйте:
А, ну если степ выставить то да.
А что пользователь хочет видеть решаете вы или кто?
Решает, очевидно, сам пользователь.
Да. Но проблема в том, что какую вы реализацию не сделаете — все равно в определенных случаях понадобится другое поведение, не то, которое вшито разработчиком. А исправить его нельзя, т.к. компонент возвращает число, а не строку.
Так почему нельзя то? Не нравится как реализован автоматический 2way биндинг? Нужна строка или какие-то дополнителные манипуляции? Не используйте! Svelte лишь предоставляет дополнительный, встроенный и простой механизм, а уж сделать в лоб, как в реакт, всегда можно:
<input type="number" value={a} on:input={handleChangeA}>
То есть свой инпут писать? Отличное предложение.
Почему свой то? Просто написать как в реакт. И то короче будет. Пример я уже дваджы привел.
Решает, очевидно, сам пользователь.
Тогда давайте не будем дуржно сидеть тут и решать за него. Суть ведь вопроса очень простая:
React:
1) Если ли возможность отловить изменением поля и созранить значение в стейт вручную? ДА
2) Есть ли механизм 2way биндинга с автоматическим приведением типа в зависимости от типа поля? НЕТ
Svelte:
1) Если ли возможность отловить изменением поля и созранить значение в стейт вручную? ДА
2) Есть ли механизм 2way биндинга с автоматическим приведением типа в зависимости от типа поля? ДА
То есть Svelte просто дает вам больше возможностей, ничего при этом не отнимая. Надо пользуйтесь, в этой задаче автор решил что этого будет достаточно. Надо что-то другое — используйте другой подход. Проблемы же нет!
Не используйте!
Не использовать что, svelte? :)
Почему свой то? Просто написать как в реакт.
Так нельзя как в реакт, у вас биндинг кривой. С этим биндингом не получится.
1) Если ли возможность отловить изменением поля и созранить значение в стейт вручную? ДА
Так нет. Надо писать руками свой биндинг. Или, погодите, вот это вот: on:input={handleChangeA}, это биндинг свелте, а не нативный?
Ну тогда это вообще нк, в одностороннем биндинге у вас компонент отдает строку, а в двухстороннем тот же компонент отдает число :tt:
В какой вселенной это считается нормальным?
Не использовать что, svelte? :)
Конкретно вам именно это и рекомендую! Мучайтесь дальше))
Так нельзя как в реакт, у вас биндинг кривой. С этим биндингом не получится.
Это в реакт нельзя, потому что там просто нет такого биндинга. Читайте код)) Говорят можно, а вы как Фома.
Так нет. Надо писать руками свой биндинг. Или, погодите, вот это вот: on:input={handleChangeA}, это биндинг свелте, а не нативный?
Ну тогда это вообще нк, в одностороннем биндинге у вас компонент отдает строку, а в двухстороннем тот же компонент отдает число :tt:
В какой вселенной это считается нормальным?
Это нормально, потому что это вообще не биндинг, если не видите. Это event handler, ровно такой же как в реакт. А если быть точным, это директива браузерного события input на элементе и работает так, как вы ожидаете от браузера.
В Svelte 1а и 2х биндинги работают так:
<!-- 1way - only write -->
<input value={a}>
<!-- 2way - write&read -->
<input bind:value={a}>
<!-- event directive with 1way - React-like -->
<input value={a} on:input={handler}>
3-й раз написал одно и тоже. Надеюсь в этот раз до вас наконец-то дойдет.
Это в реакт нельзя, потому что там просто нет такого биндинга. Читайте код))
В каком смысле нет? Я пишу onChange={handleChange} — вот это биндинг, который мне реакт предоставляет.
Это нормально, потому что это вообще не биндинг, если не видите. Это event handler, ровно такой же как в реакт.
Так еще раз — в реакт есть готовый биндинг, а в свелте можна_сделать при помощи нативных средств, так? Ну то что можно выкинуть любой фреймворк и руками написать что угодно — не секрет.
вы знаете конкретный кейс, когда значение поля для ввода с type=number должно использоваться как строка?
Чтобы написать "e" - не является валидным значением, а не "undefined" - не является валидным значением.
Затем, что пользователь может скопировать значение из другого места, где в выделение может попасть лишнее или используется немного иной формат. И нужно дать пользователю возможность отредактировать вставленное значение.
А зачем это писать, если можно просто не давать вводить не валидные значения?
Ну вот пустая строка — это невалидное значение и ее можно написать. Если бы вы сразу инициализировали компонент какой-то непустой строкой ('0' например) и не давали возможности стереть все до пустой — другой разговор. Это правда, тоже весьма неудобное поведение.
Сначала, версия Svelte:
Обожаю такие вот наколеночные примеры, бесконечно далёкие от реального использования. А потом начинается:
- Надо управлять входными данными.
- Надо получать результаты.
- Надо стилизовать каждый дом-элемент.
- Надо иметь возможность кастомизировать стили.
- Надо прикручивать e2e тесты.
- Надо собирать аналитику по использованию.
В результате код обрастает тем самым шумом, с которым боролись:
<script>
import Number from './Number.svelte';
export let name = ''
export let prefix = ''
export let a = 1;
export let b = 2;
export let style;
let id = prefix + '.' + name
export let res;
$: res = a + b;
</script>
<Number prefix={id} name="a" bind:value={a} style={style.a} />
+
<Number prefix={id} name="b" bind:value={b} style={style.b} />
=
<span id={ id + '.' + 'res' } class="res" style={style.res}>{res}</span>И это ещё без асинхронного вычисления значения и без обработки ошибок, без которого Svelte показывает просто белый экран.
Ну и для сравнения, вот как выглядит почти полное отсутствие шума на самом деле:
$my_form $mol_view
sub /
<= First $mol_number
value?v <=> first?v 1
\+
<= Second $mol_number
value?v <=> second?v 1
\=
<= Result $mol_view
sub /
<= result \namespace $.$$ {
export class $my_form extends $.$my_form {
result() {
return this.first() + this.second()
}
}
}Возможно лаконичность синтаксиса замотивирует вас почитать документацию: https://github.com/eigenmethod/mol/tree/master/view#viewtree
Проще всего понять суть, сравнивая исходный и сгенерированный код в песочнице.
И куда подевались prefix, id и style, которые вы добавили в код на svelte, но их не видно в tree?
Для полноты сравнения нужно было наверное показать еще имплементацию First, Second и Result.
но их не видно в tree?
О том и речь, что во view.tree это всё не надо делать вручную. Автоматика-с.
нужно было наверное показать еще имплементацию First, Second и Result.
Вообще-то они показаны. Я привёл полностью работоспособный код компонента. Вы можете скопипастить его в my/form/form.view.tree и my/form/form.view.ts и далее использовать.
В конечном html у нас два тэга input для ввода и один span для вывода. В исходном коде они никак не фигурируют.
Или хотите сказать, что "<=>" обозначает input, а "<=" – span?
В конечном html
Конечный — всё-таки DOM. HTML — это просто один из способов его сериализации.
Или хотите сказать, что "<=>" обозначает input, а "<=" – span?
Нет, это двусторонний и односторонний биндинги свойств.
<= First $mol_number
value?v <=> first?v 1Создать компонент $mol_number и назвать его First, привязать его значение value к нашему значению first, и вывести его.
О том и речь, что во view.tree это всё не надо делать вручную. Автоматика-с.
При всем уважении, автоматика — это когда не нужно view-компоненты создавать самому, а если для каждого куска на экране все так же нужно создавать и заполнять вручную файл, то его синтаксис по сути ни на что не влияет.
Ну и для сравнения, вот как выглядит почти полное отсутствие шума на самом деле:
$my_form $mol_view sub / <= First $mol_number value?v <=> first?v 1 \+ <= Second $mol_number value?v <=> second?v 1 \= <= Result $mol_view sub / <= result
Для стороннего наблюдателя, который не восхищен безусловно своим дитятком, так выглядит сплошной белый шум.
$my_form $mol_view sub / <= First $mol_number value?v <=> first?v 1 \+ <= Second $mol_number value?v <=> second?v 1 \= <= Result $mol_view sub / <= result \
Это что-то на Хаскелле?
Опять же, вы тут используете несколько готовых компонентов $mol ($my_form, $mol_view, $mol_number), не представляете детали их реализации, а потом говорите «смотрите!!! а на Svelte реализация этого с нуля будет уже не в 3 строчки, а в 10 строк». Хм, ну ладно. Не уверен, что это звучит очень круто и убедительно… Скорее уж наоборот)
Понять бы еще зачем вы все это понаписали.
Я же написал 6 пунктов для которых всё это нужно.
Что такое prefix? Зачем он одинаковый для обоих инпутов?
Чтобы у каждого дом элемента был уникальный семантический идентификатор, к которому можно привязать тесты и аналитику.
Пример на $mol вообще не содержит этих вещей.
Потому, что фреймворк делает это всё самостоятельно, а не требует писать бойлерплейт.
Возможно они сокрыты внутри реализации $mol_number
Они сокрыты в $mol_view, от которого наследуются вообще все компоненты. Это тот самый рантайм, с которым "борется" Svelte.
Неявно можно и в Svelte
Попробуйте реализовать.
Опять же, вы тут используете несколько готовых компонентов $mol ($my_form, $mol_view, $mol_number), не представляете детали их реализации
$my_form — компонент, который тут собственно и создаётся.
$mol_number — стандартный компонент. Реализацию Number для Svelte я тоже не привёл, так что всё честно.
$mol_view — тот самый рантайм, которого в Svelte нет, и который прячет от программиста львиную долю бойлерплейта.
Я же написал 6 пунктов для которых всё это нужно.
Это очень абстракные 6 пунктов, но я попробую их прокомментировать:
Надо управлять входными данными.
Происходит фактически также как во всех популярных UI фреймворках, типа React и Vue. Кроме «props down, events up», можно еще «2way binding» на пропсы компонентов при желании. Пропсы и публичные методы очень четко отделены от приватного стейта и функций. Реактивные декларации помогают делать любой пре-форматинг входящих значений. Для расшаривания стейта между компонентами есть очень реактивные сторы на обсерверабл с очень удобным «сахаром» компилятора, который возволяет работать с ними в синхронной манере.
Все это подходы по управлению входными данными понятные большинству разработчиков. $mol/treeview предлагают то, что мало кто понимает и даже хочет понимать, ибо не нравится оно просто.
Надо получать результаты.
«Забрать» значения из компонента можно через события или двойное связывание.
Надо стилизовать каждый дом-элемент.
Надо иметь возможность кастомизировать стили.
Из коробки работают как изолированные стили, так и глобальные. Можно прокидывать стили через пропсы. Любой доступныей функционал CSS и даже CSS-in-JS. Кроме того, можно при большом желании точечно перегружать стили подкомпонентов из родительского, без прокидывания через пропсы, но лучше это использовать только для leaf-компонентов.
Надо прикручивать e2e тесты.
Прикручивайте, причем тут фреймворк? В стандартной поставке Sapper, например, идет Cypress.
Надо собирать аналитику по использованию.
Тоже самое. Прикручивается за 2 минуты с помощью пары хелперов.
Чтобы у каждого дом элемента был уникальный семантический идентификатор, к которому можно привязать тесты и аналитику.
Зачем тогда его прокидывать каждому компоненту вручную? Я бы сделал общий экшн и просто подписывал его туда куда надо:
<div use:uid>
...
</div>
<script>
import uid from '~/actions/uid.js';
</script>
Добавляем экшн тем элементам тех компонентов, которые должны генерить этот «уникальный семантический идентификатор» и все.
Потому, что фреймворк делает это всё самостоятельно, а не требует писать бойлерплейт.
То что в $mol это уже идет из коробки, не является плюсом для меня. К тому же я не знаю как это реализовано, может мне это не подходит. А если мне вообще это не нужно? Как это выпилить их вашей коробки?
Они сокрыты в $mol_view, от которого наследуются вообще все компоненты. Это тот самый рантайм, с которым «борется» Svelte.
Вот именно, он нам не нужен. Подобный рантайм, с которым Svelte борется, мешает делать компоненты по настоящему независимыми. Раз все компоненты наследуются от $mol_view, а он в себе содержит много встроенных возможностей, как мне их оттуда выпилить, если мне они не нужны или если мне нужна какая-то собственная реализация?
$my_form — компонент, который тут собственно и создаётся.
Сорян, там у вас черт ногу сломит. Имел ввиду конечно же $.$my_form от которого он наследуется. Думаю имеет смысл привести реализацию этого компонента. То что он «стандартный» не считается.
Попробуйте реализовать.
Реализацию Number для Svelte я тоже не привёл, так что всё честно.
Так давайте исправим это:
Input.svelte
<div use:uid={{id}} class:floating>
<input
use:imask={mask}
{value}
{id}
{...attrs}
on:accept={e => value = e.target.value}
on:focus={e => active = true}
on:blur={e => active = false}
>
{#if label}
<label class:active for={id}>{label}</label>
{/if}
</div>
<script>
import imask from 'svelte-imask';
import uid from '~/actions/uid';
let active = false,
floating = true,
label = '',
value,
mask,
attrs,
id;
$: {
let { id, mask, label, floating, value ...rest } = $$props;
attrs = rest;
}
export {
floating,
label,
value,
mask,
id
};
</script>
<style>
div { ... }
input { ... }
label { ... }
label.active { ... }
.floating label { ... }
</style>
Это компонент поля, который поддерживает все возможности html input, кроме того поддерживает маскинг но основе imask (все его опции), можно устанавливать лейбл, как обычный, так и floating (аля Material Design). Пользуемся как вы написали, только без prefix.
Теперь давайте посмотрим на реализацию такого же компонента, только на $mol. Только полную, со стилями, с поддержикой всех типов инпутов, с интеграцией с 3rd-party решением (imask) и т.д.
$mol_view — тот самый рантайм, которого в Svelte нет, и который прячет от программиста львиную долю бойлерплейта.
Который никому как раз и не нужен, потому что всем нужны независимые микро-компоненты, которые можно собирать в разной композиции.
я попробую их прокомментировать
К чему весь этот маркетинг с очень частым употреблением слова "очень"? Я же привёл пример кода, который получится, после реализации этой функциональности. Можете сократить — дерзайте. Не в ущерб функциональности только.
ибо не нравится оно просто
Устроили тут детский сад.
Прикручивайте, причем тут фреймворк?
А вы попишите e2e тесты, чтобы прочувствовать всю боль их поддержки, когда после очередного коммита, тесты отваливаются, потому что не находят нужного элемента или находят сразу несколько и берут первый попавшийся, или просто находят не тот элемент, но который по счастливой случайности сматчился на ваш селектор. Собственно, на главной же странице cypress можно видеть селектор по значению атрибута src у картинки. Изменили ссылку — сломались все тесты, в которых эта картинка участвовала. Вывели ещё куда-то эту картинку — получайте зелёные тесты для сломанной функциональности. В какой-то момент автотестировщикам задалбывает тратить большую часть своего рабочего времени на починку тестов. Они приходят к программистам и просят их ставить элементам уникальные идентификаторы. И тут начинается веселье с префиксами, когда один компонент есть на странице в нескольких экземплярах. В какой-то момент устаёшь писать бойлерплейт и начинаешь задумываться, что неплохо было бы автоматизировать генерацию идентификаторов. Но уже поздно, ибо на старте проекта выбрали инструмент, в котором это не автоматизировать, так как посчитали тогда, что "вам это не нужно".
Прикручивается за 2 минуты с помощью пары хелперов.
За 2 минуты аналитика прикручивается при автогенерации уникальных человекопонятных идентификаторов. А без них вам придётся во все вьюшки руками добавлять идентификаторы, имея всё те же проблемы, что и с тестами. С той лишь разницей, что в случае ошибки, у вас будет мусор в статистике, который вы не сможете исправить задним числом. И как с любой ручной работой ошибок будет много. И очень весело узнавать, что статистика за последние пол года накрылась медным тазом, когда ошибки всё же обнаруживаются.
Я бы сделал общий экшн
Далее следует код, который не понятно что и не понятно как делает. И после этого вы ещё предъявляете какие-то претензии к $mol, где кроме классов и реактивных свойств нет абсолютно ничего, ибо этих двух идиом достаточно для описания интерфейсов любой сложности.
Добавляем экшн тем элементам тех компонентов, которые должны генерить этот «уникальный семантический идентификатор» и все.
На основе чего он будет их генерить? Откуда он возьмёт информацию о семантике?
А если мне вообще это не нужно?
- На самом деле нужно.
- Оно в любом случае не мешает.
если мне нужна какая-то собственная реализация?
Берёте и пилите свою реализацию, к $mol_view вас никто гвоздями не прибивает. В отличие от того же Svelte, где прикладной программист вообще не контролирует, как будет рендериться компонент, какой использовать шаблонизатор и тп.
Имел ввиду конечно же $.$my_form от которого он наследуется. Думаю имеет смысл привести реализацию этого компонента. То что он «стандартный» не считается.
$my_form $mol_view
sub /
<= First $mol_number
value?v <=> first?v 1
\+
<= Second $mol_number
value?v <=> second?v 1
\=
<= Result $mol_view
sub /
<= result \Так давайте исправим это
Реализация этого компонента не имеет значения, не подменяйте предмет обсуждения.
всем нужны независимые микро-компоненты, которые можно собирать в разной композиции
TodoMVC на Svelte — 8кб, на $mol — 15. Не большая разница. При этом для последнего вообще не ставилось задачи минимизировать размер бандла, ибо бандлы и так небольшими получаются.
К чему весь этот маркетинг с очень частым употреблением слова «очень»? Я же привёл пример кода, который получится, после реализации этой функциональности. Можете сократить — дерзайте. Не в ущерб функциональности только.
Вы привели пример кода для реализации этой функциональности с нуля и сравнили с реализацией на готовых компонентах. Если строить разговор так, тогда реализация будет такой:
<Number bind:value={a} />
+
<Number bind:value={b} />
=
<span use:uid>{result}</span>
<script>
import uid from '~/actions/uid';
import Number from '~/components/Number.svelte';
export let first = 1,
second = 1,
result;
$: result = a + b;
</script>
Коротко, но главное хотя бы понятно, что вообще происходит, а не просто набор букаф.
Устроили тут детский сад.
Говорит человек, который пытается присунуть свой «грязный» $mol во все статьи до которых он только дотягивается.
Они приходят к программистам и просят их ставить элементам уникальные идентификаторы. И тут начинается веселье с префиксами, когда один компонент есть на странице в нескольких экземплярах. В какой-то момент устаёшь писать бойлерплейт и начинаешь задумываться, что неплохо было бы автоматизировать генерацию идентификаторов. Но уже поздно, ибо на старте проекта выбрали инструмент, в котором это не автоматизировать, так как посчитали тогда, что «вам это не нужно».
За 2 минуты аналитика прикручивается при автогенерации уникальных человекопонятных идентификаторов.
Все это верно, но причем тут UI фреймворк, если это можно организовать сверху? Вы любитель коробочных решений, это уже все поняли. Право ваше конечно, но может хватит трясти перед всеми своим $mol'ом, как эксгибиционист?
Далее следует код, который не понятно что и не понятно как делает. И после этого вы ещё предъявляете какие-то претензии к $mol, где кроме классов и реактивных свойств нет абсолютно ничего, ибо этих двух идиом достаточно для описания интерфейсов любой сложности.
Так я как раз и поступил как вы. Использовал некое готовое решение, которое написали для задачи и показал как его можно применить к конкретному элементу. У вас внутри $mol же наверное тоже какой-то код написан. Будем считать, что внутри экшена написан такой же код.
На основе чего он будет их генерить? Откуда он возьмёт информацию о семантике?
Откройте уже для себя такие штуки как finder и аналоги. И живите как нормальные люди.
На самом деле нужно.
Оно в любом случае не мешает.
Не нужно. Лишнее всегда мешает, а я вижу в $mol много всего лишнего сейчас. Как исправите, приходите опять, посмотрим, подумаем. Пока нам это не нужно, спасибо, коммивояжер вы наш))) «Не хотите ли попробовать немного $mol?» )))))
Берёте и пилите свою реализацию, к $mol_view вас никто гвоздями не прибивает.
Как это не прибивает? Говорили же сами, что все компоненты от него наследуются, так? Фичи эти реализованы внутри него видимо и выпилить их нельзя, так? Получается вы советуете мне дублировать функционал и весь дубляж еще и в бандл тянуть? Спасибо, не надо.
В отличие от того же Svelte, где прикладной программист вообще не контролирует, как будет рендериться компонент, какой использовать шаблонизатор и тп.
В $mol я не просто не контролирую что-то, я даже не понимаю как этот самый treeview связан с шаблоном и html вообще. Понятия не имею как понять, что вот эта хень:
<= Result $mol_view
sub /
<= result \
будет эквивалентна:
=
<span id={ id + '.' + 'res' } class="res" style={style.res}>{res}</span>
Вижу span, но где span у вас, я не понимаю. Но честно признаться и не сильно интересно. Писать такое, я бы и не хотел.
Кроме того, в Svelte я точно знаю как будет рендериться компонент, потому что могу за пару минут прочитать ВЕСЬ его код. А чтобы понять что там твориться в $mol, с его вечно фантанирующими эксепшенами, мне еще нужно будет продебажить, что тоже не очень просто, как я понял. Как кстати дебажить TreeView? Есть там сорсмапы или еще что-то?
Этот класс определён во view.tree
Честно признаюсь, я ничего не понимаю в вашем коде. Вообще. Как и все тут, но мне кажется что вот это должно означать, что некий класс $my_form наследутеся от другого класса $.$my_form.
export class $my_form extends $.$my_form
Если он это наследуется от TreeView, то все еще хуже чем я думал.
Реализация этого компонента не имеет значения, не подменяйте предмет обсуждения.
Мне сложно подменить предмет обсуждения, потому что его нет. Вы прибежали, навязали свою задачу, которая видимо хорошо ложиться на то, что у вас реализовано внутри готовых $mol компонентов. Показали какой-то никому не понятный код, который не понятно что делает и как работает. Дальше показали код на Svelte, так как вы его понимаете и сделали какой-то вывод. При этом никто не увидел реализацию того, о чем вы говорите, потому что оно где-то там внутри, как суслик, которого никто не видит, а он есть. Да и код, который вы представили для Svelte, учитывая что это код с нуля, выглядит весьма не плохо, если чуть причесать.
Делаем вывод, раз на Svelte это так просто реализуется, $mol и его $mol_view нахер не нужен. Если хотите продолжать диалог именно в практической плоскости, сперва давайте реализацию аналога Input.svelte из предыдущего комментария. Будем тогда припарировать $mol на тех задачах, которые близки мне.
TodoMVC на Svelte — 8кб, на $mol — 15. Не большая разница. При этом для последнего вообще не ставилось задачи минимизировать размер бандла, ибо бандлы и так небольшими получаются.
Во-первых, не 8Кб, а 3.5Кб, если вы конечно про gzip (а зачем какой-то иной размер обсуждать?). Ждем тогда еще когда вы наконец-то закончите с этим. За год видимо не смогли осилить.
Будем считать, что внутри экшена написан такой же код.
Так напишите этот код. Спойлер — ничего путного не получится. И приведённый в пример finder — та ещё хрень, генерирующая хрупкие селекторы.
Говорили же сами, что все компоненты от него наследуются, так?
Все стандартные компоненты. Вы можете от них наследоваться, а можете не наследоваться. Полиморфизм, все дела.
Получается вы советуете мне дублировать функционал
$mol — микромодульный конструктор, ничего дублировать не надо.
я даже не понимаю как этот самый treeview связан с шаблоном и html вообще.
С опытом, я надеюсь, вы отучитесь думать в терминах HTML и начнёте думать в терминах компонент и их композиции.
Как кстати дебажить TreeView? Есть там сорсмапы или еще что-то?
Из него генерирует тайпскриптовый класс. Читать и дебажить его вы можете как угодно.
Честно признаюсь, я ничего не понимаю в вашем коде. Вообще.
Возможно потому, что:
честно признаться и не сильно интересно.
Кому было интересно — разобрались и прониклись идеями.
Если он это наследуется от TreeView, то все еще хуже чем я думал.
Обычное такое опциональное переопределение.
Так напишите этот код. Спойлер — ничего путного не получится.
Типа вы смогли написать, а никто больше не сможет? ))) Знал что ваша самооценка на высоте, но так чтобы пробивать небесный свод…
И приведённый в пример finder — та ещё хрень, генерирующая хрупкие селекторы.
Думаю вы его не пробовали. Пока с ним проблем не было особых, но если вы знаете кейс, тогда был бы разговор.
Все стандартные компоненты. Вы можете от них наследоваться, а можете не наследоваться. Полиморфизм, все дела.
То есть единственный варинант выпилить всю ту хрень, которую вы напилили в $mol_view — это отказаться от всех готовых компонентов существующих под $mol? Да уж, все дела.
$mol — микромодульный конструктор, ничего дублировать не надо.
Как это, беру компонент $mol_number, который наследуется от $mol_view, пишу генерацию уникальный селекторов сверху как мне надо и получаю дублирование данного функционала в бандле. Разве нет так? Никакая микромодульность тут не поможет.
С опытом, я надеюсь, вы отучитесь думать в терминах HTML и начнёте думать в терминах компонент и их композиции.
Судя по степени интереса к $mol, популярности ваших статей и комментариев, делаю вывод, что вы у нас тут один такой весь опытный, просто капец)))
Лично мне html и композиция компонентов на его основе, при всех минусах, нравится значительно больше чем ваш treeview. Можете хоть треснуть)
Из него генерирует тайпскриптовый класс. Читать и дебажить его вы можете как угодно.
То есть я пишу вот эту хрень, а дебажить буду то, чего я в глаза не видел, то есть какой-то TS класс, который за меня сгенерировали? Получается я должен еще разбираться, как именно мой TreeView превращается в TS? Гадость какая.
В Svelte я почему-то дебажу именно тот код, который я пишу.
Возможно потому, что
И это тоже, но в основном потому что это хреновый синтаксис, хреновая идея и хреновая реализация с откровенно плохим DX. А изучать хочется только то, что изначально хотя бы не вызывает рвотных рефлексов.
Кому было интересно — разобрались и прониклись идеями.
А что кто-то еще на этом пишет? Сколько там, человек 10 небось уже есть? Ну ваще прогресс конечно, аж 13 контрибуторов, 2 из которых это вы (накрутка?) и уже 211 звездочек. Ну и популярностью ваших статей/выступлений/комментариев. Мир так устроен, что в любой социальной среде, всегда есть группа маргиналов, склонных к мазахизму.
Так как код вы так и не показали, считаю что беседа потеряла конструктивную направленность и не смеет практического смысла.
p/s 212 звездочек, чтобы вам не обидно было. Успехов!
Советую вам подумать над своим поведением, и завязывать уже с общением в стиле школоло. Если вы, конечно, хотите подниматься по карьерной лестнице. Удачи. Она вам понадобится.
Btw, не знаю как там ваша «лестница», моя уже по большей части пройдена. Поэтому и трачу время, чтобы подтаскивать других.
Несмотря на это, специалист вы хороший, не пропадёте. А вот $mol, к сожалению для вас, совершенно точно не взлетит! Если же я ошибаюсь и в будущем он наберёт популярность, хотя бы на уровне Svelte, то я первым твитну о нем и признаю свои ошибки. Обещаю вам.
Это все преимущества? Не увидел ни одной весомой причины, почему я должен с Vue перейти на это
Кроме этого, мы должны помнить, что необходимо принудительно привести строковое значение в числовое с помощью оператора +, иначе 2 + 2 будет равно 22 вместо 4.
Кажется, явное всегда лучше. Тот факт, что в Svelte есть неявное приведение string к number в случае input type number нужно держать в голове. То есть, разбирая код на Svelte нужно потратить гораздо больше усилий мозга, нежели чем в явных решениях других ребят, что вы привели в статье. Это я про фразу
Поэтому, когда вы читаете такой код, вам придётся приложить гораздо больше усилий, чтобы понять замысел автора.
И в целом, читая доку по Svelte, лично у меня часто возникала мысль, блин, еще и это придется помнить. То есть кода пишем мало, да. Зато в голове теперь весь «рантайм» Svelte загрузить придется. Не спорю, с тем же React придется сделать тоже самое, но там этого «рантайма» куда меньше.
Тот факт, что в Svelte есть неявное приведение string к number в случае input type number нужно держать в голове. То есть, разбирая код на Svelte нужно потратить гораздо больше усилий мозга
Справедливости ради, это то, что называется expected result, а значит, если все (или правильнее сказать, если движок JS в браузере) будут возвращать данные в том же типе, что и указан в инпуте — все быстро привыкнут к "правильному, ожидаемому" поведению и проблем не будет.
С другой стороны да, везде используя явное приведение типов освобождает от необходимости заботиться о том, в каком реально типе данные были получены (в определённых пределах), но всё-таки, это скорее костыль, чем решение.
И немного про сам Svelte, но это уже ответ не вам, а скорее к автору статьи
Кстати, про input type=«number». Если запустить пример из статьи и стереть значение из input'а, мы получим замечательный результат: undefined + 2 = NaN.
Если запустить пример из статьи и стереть значение из input'а, мы получим замечательный результат: undefined + 2 = NaN.
Вызываем в тред PaulMaly, он расскажет, как правильно.

Короткий ответ — das ist javascript)))
И все же интересно было бы узнать, какого поведения по-умолчанию вы ожидаете? приведение undefined к 0? Если такое и надо делать, то для какой-то конкретной задачи, то есть в userland, а не на уровне фреймворка:
$: sum = (a || 0) + (b || 0);
Если такое и надо делать, то для какой-то конкретной задачи, то есть в userland, а не на уровне фреймворка
Я бы с вами согласился, но это противоречит аргументации в статье, где автор пеняет на реакт именно из-за необходимости ручной конвертации строк в числа
В Svelte это не может считаться ошибкой, потому то undefined выставляется совершенно осознано. Вот реализация хелпера приведения биндинга к числу:
export function toNumber(value) {
return value === '' ? undefined : +value;
}
Почему-то мне кажется что у автора были причины сделать так. И тут встает вопрос, раз этот код имеет смысл и сделано так специально, возможно чтобы избежать каких-то более серьезных проблем, получается что в реакт примере мы должны делать что-то подобное:
import toNumber from 'lodash.tonumber';
...
function handleChangeA(event) {
setA(toNumber(event.target.value));
}
function handleChangeB(event) {
setB(toNumber(event.target.value));
}
...
То есть писать еще больше кода, который Svelte пишет за нас. И кстати, почему-то lodash тоже undefined к нулю не приводит, с чего бы это?
если бы был какой-то идеоматический способ конвертировать undefined в number
Правильный вопрос: с какого фига там вообще взялся undefined?
Лучше NaN. Либо число, либо не число. Ну или ошибка.
<p>{a || 0}</p>
<p>{b || 0}</p>
<script>
$: sum = (a || 0) + (b || 0);
</script>
vs
<p>{isNaN(a) ? 0 : a}</p>
<p>{isNaN(b) ? 0 : b}</p>
<script>
$: sum = (isNaN(a) ? 0 : a) + (isNaN(b) ? 0 : b);
</script>
Мне почему-то первый вариант нравится больше. Кроме того в нем меньше возможности налажать, потому что девелопер забудет сделать проверку именно на isNaN.
Я вам по секрету скажу: NaN — тоже ложно значение в условиях.
1) Если переменная не содержит значения, то это не NaN, а undefined
2) С NaN в любом случае больше проблем чем с undefined
В итоге, если выбирать между приведением пустой строки к NaN или 0, я бы лучше выбрал 0, то не NaN. Уверен undefined тоже неспроста используют в Svelte.
То есть вы считаете что в JS «отсутствует значение» — это NaN?
NaN — это не отсутствие значения, NaN — это Not a Number. '' — определенно Not a Number.
А мне вот кажется, что это называется undefined.
Ну вы еще заставьте пользователя таблицу приведения типов из js выучить.
есть же чисто прикладной аспект — проверять на undefined значительно проще и удобнее
Это программисту проще и удобнее. А что проще программисту — не важно, это никого не волнует. Пользователь явно не хочет разбираться, что такое undefined и чем оно отличается от null.
Вы же свой undefined пользователю суете.
В итоге, если выбирать между приведением пустой строки к NaN или 0
Если ваша ф-я приводит строку к числу, то результат работы такой ф-и не может быть undefined. Это шизофрения. Пустая строка — это не 0 и не undefined, это определенно NaN. Так же как и строка вида 'gfgfdgdf'. Кейс со строкой '' ничем не отличается от кейса со строкой 'gdfgdfgdf'.
NaN — это не отсутствие значения, NaN — это Not a Number. '' — определенно Not a Number.
Но когда юзер полностью отчищает поле для ввода, это не Not a Number, это отсутствие значение.
Ну вы еще заставьте пользователя таблицу приведения типов из js выучить.
Причем тут юзер? Это задача разработчика запроцессить данный кейс и с undefined это будет сделать проще, чем с NaN.
Это программисту проще и удобнее. А что проще программисту — не важно, это никого не волнует. Пользователь явно не хочет разбираться, что такое undefined и чем оно отличается от null.
Проще и очевиднее программисту, значит меньше ошибок и больше крайних случаев, таких как отчищение поля, который он может валидно запроцессить. А значит юзеру как раз и не надо будет думать про типы. Почему-то когда какой-то очередно JS связанный с числами, ломается в интернетах, я лично как юзер чаще вижу на экране непонятный NaN, чем undefined. Возможно потому, что одни разрабы думают как вы, тот работать с NaN не умеют, а другие разрабы думают как я, и вполне себе успешно хендлят undefined.
Но когда юзер полностью отчищает поле для ввода, это не Not a Number, это отсутствие значение.
Нет, значение не отсутствует. Это пустая строка.
Причем тут юзер? Это задача разработчика запроцессить данный кейс и с undefined это будет сделать проще, чем с NaN.
Чем проще? И выводите свой undefined вы именно юзеру. У вас там undefined + 5 = NaN.
Проще и очевиднее программисту, значит меньше ошибок и больше крайних случаев
Наоборот — крайних случаев меньше, либо у вас корректное число, либо NaN. Всего два случая. Вы же зачем-то при парсинге предлагаете добавить третий кейс — undefined. Какой в нем смысл, чем '' отличается в этом случае от 'gfdgfd' и зачем вообще нужны такие усложнения — не ясно.
Нет, значение не отсутствует. Это пустая строка.
Пустая строка для поля ввода числа?))) Нет уж, для меня, как для разработчика, понятнее undefined, чем пустая строка при вводе чила.
Чем проще? И выводите свой undefined вы именно юзеру. У вас там undefined + 5 = NaN.
Проще чем, что разоаботчику работать с undefined проще чем с NaN, а значит вероястность того, что вы вообще это увидите ниже. В случае с NaN ничем не лучше вообще, ибо NaN + 5 будет все тот же NaN. И в чем профит?
Наоборот — крайних случаев меньше, либо у вас корректное число, либо NaN. Всего два случая.
Да, у меня либо корректное число, либо нет значения, то есть undefined. NaN — это значение, но значение которое мне не нужно, то есть не валидное значение и с ним работать никак не могу. undefined — это отсутствие значения, такое бывает. В js мы всегда предполагаем, что переменная либо не имеет значения, то есть undefined, либо имеет валидное значение, в данном случае number. Вы же предлагаете добавить кейс с обработкой еще и невалидного значения.
Ок, рассмотрим пример, безотносительно Svelte:
let number; // undefined
function setNumber(n) {
number = n;
}
setNumber(1); // 1 - valid
setNumber(); // undefined
setNumber(NaN); // NaN - invalid
Какой из кейсов лишний? По мне так очевидно, потому что на undefined мы в любом случае должны закладывать обработку, а вот еще и на NaN — это лишняя работа.
Пустая строка для поля ввода числа?
Да, пустая строка, значение ''.
Проще чем, что разоаботчику работать с undefined проще чем с NaN,
Чем проще?
бо NaN + 5 будет все тот же NaN. И в чем профит?
а undefined + 5 будет NaN. Проще тем, что сущностей две а не три. Зачем лишняя?
Да, у меня либо корректное число, либо нет значения, то есть undefined.
Так у вас есть значение. У вас есть строка '', вы ее парсите и числа не получается. Точно так же вы парсите, например, 'gfgdf' и у вас тоже числа не получается. В чем разница между этими двумя кейзами? Почему при ошибке парсинга одной строки — NaN, а при ошибке парсинга второй — undefined? Почему по сути эквивалентные кейзы у вас ведут себя по-разному? Обратите внимание, что, например, parseInt именно так и работает — либо NaN либо нормальное число. И никаких undefined или наллов или еще чего.
Вы же предлагаете добавить кейс с обработкой еще и невалидного значения.
Так невалидное значение в вашем случае это NaN. А отсутствия значения быть не может, оно всегда есть.
Какой из кейсов лишний? По мне так очевидно, потому что на undefined мы в любом случае должны закладывать обработку
Не должны, т.к. undefined быть в строке не может, этот кейс лишний. В строке всегда строка. Если она пустая — это будет ''. Не undefined.
А вот NaN у вас в любом случае будет, если вы попытаетесь распарсить 'gfgdf'. По-этому NaN исключить нельзя.
Да, пустая строка, значение ''.
Для меня это звучит скорее как баг в элементе input type=number.))
Чем проще?
Нет кейсов когда нужно использовать isNaN, проще сравнить 2 undefined чем 2 NaN. И все другие геморы связанные с NaN.
а undefined + 5 будет NaN. Проще тем, что сущностей две а не три. Зачем лишняя?
Мне кажется или в ответ на мой ответ на ваш ответ, вы написали тот же ответ? Чтож продолжу эту славную традицию:
let number; // undefined
function setNumber(n) {
number = n;
}
setNumber(1); // 1 - valid
setNumber(); // undefined
setNumber(NaN); // NaN - invalid <- это 3-й кейс
Так у вас есть значение. У вас есть строка '', вы ее парсите и числа не получается. Точно так же вы парсите, например, 'gfgdf' и у вас тоже числа не получается. В чем разница между этими двумя кейзами?
Никакой, оба их них дадут мне undefined в биндиге Svelte? Это же не number.
Почему при ошибке парсинга одной строки — NaN, а при ошибке парсинга второй — undefined? Почему по сути эквивалентные кейзы у вас ведут себя по-разному?
А с чего вы это взяли?
Обратите внимание, что, например, parseInt именно так и работает — либо NaN либо нормальное число. И никаких undefined или наллов или еще чего.
Если бы web api были удобной и продуманной штукой, мы бы с вами не сидели так плотно на фреймворках, либах и других lodash'ах.
Так невалидное значение в вашем случае это NaN. А отсутствия значения быть не может, оно всегда есть.
Так если стерли все = значения нет же. А вы говорите всегда. Мне кажется нормальным просто не давать ввести в поле для ввода числа текст. Например, когда я на сайте ввижу поле для ввода телефона, и мне не дают туда ввести `hello world`, меня это почему-то ни разу не смущало.
Не должны, т.к. undefined быть в строке не может, этот кейс лишний. В строке всегда строка. Если она пустая — это будет ''. Не undefined.
Биндинг пытается сделать из якобы input type=number, который при этом свободно принимает строки, настоящий number, который строки вообще не принимает. Тем самым юзер сразу понимает, что вводит чухню. undeined — это кейс от которого никак не избавиться, потому что js так работает и у нас переменная, у нас аргументы функций и все такое. А вот дополнительно вводить NaN в эту задачу смысла нет. Выше я привел все примеры. Захотите — изучите.
А вот NaN у вас в любом случае будет, если вы попытаетесь распарсить 'gfgdf'. По-этому NaN исключить нельзя.
Вы бы сперва хоть проверили как это работает, прежде чем писать то: svelte.dev/repl/2b7f5eeb4eea44978693b0c3c421b8bd?version=3.3.0
Вот попробуйте туда ввести 'gfgdf'. Удачи!
Для меня это звучит скорее как баг в элементе input type=number.))
Баш — это когда что-то работает с нарушением спецификации. Инпут работает в согласии со спецификацией.
Мне кажется или в ответ на мой ответ на ваш ответ, вы написали тот же ответ?
Вы не можете несколько строк прочитать? Еще раз — у вас гарантированно есть NaN, т.к. undefined + 5 = NaN. Вы не можете от него отказаться, т.к. он по факту у вас есть, вы вынуждены его обрабатывать. С-но выбор между NaN + 5 = NaN и undefined + 5 = NaN. В первом случае две сущности, во втором — три. Что вам тут непонятно?
Так если стерли все = значения нет же.
Как нет, если оно есть. Это пустая строка. Напишите в консоли undefined === '', вам вернет false. undefined (отсутствие значения) и '' (пустая строка) — это разные вещи. Что вам непонятно-то тут?
Например, когда я на сайте ввижу поле для ввода телефона
Не дать ввести что-либо кроме телефона легко, а вот не дать ввести что-либо кроме чисел — очень нетривиальная задача. Вы просто явно с такими задачами не встречались.
это кейс от которого никак не избавиться, потому что js так работает
js как раз так не работает. В форме у вас пустая строка — не undefined. Когда вы эту строку засовываете в parseInt(), то получается NaN (и никогда не получается undefined). Если засунуть эту строку в Number — получится 0 (или NaN в случае 'gdfgdf' — но, снова, никаких undefined).
Никогда и ни при каких обстоятельствах в js в данном контексте не бывает undefined.
Никакой, оба их них дадут мне undefined в биндиге Svelte?
То есть вы вообще в своих биндингах сломали js-ную логику парсинга чисел.
Баш — это когда что-то работает с нарушением спецификации. Инпут работает в согласии со спецификацией.
К сожалению, веб спеки не отличаются продуманностью. Надо по спеке — юзаем ивент хендлер как в реакт, надо удобно — 2way биндинг. Выбор есть и это хорошо.
Вы не можете несколько строк прочитать? Еще раз — у вас гарантированно есть NaN, т.к. undefined + 5 = NaN. Вы не можете от него отказаться, т.к. он по факту у вас есть, вы вынуждены его обрабатывать. С-но выбор между NaN + 5 = NaN и undefined + 5 = NaN. В первом случае две сущности, во втором — три. Что вам тут непонятно?
Это вам тут не понятно, у меня есть 2 переменные, которые я могу чекать и еще как-то процессить и есть выражение, к которому вы аппелируете. Напомню как вам код:
<!-- undefined + 5 = NaN -->
{a} + {b} = {a + b}
Так вот ваш NaN, от которого я яковы не могу отказаться, это результат выражения, а не переменной. Его нет в стейте напрямую и ни одна из переменных не может принять это значение в том случае о котором пишу я. Это результат inline операции над необработанными значениями переменных. Если я их обработаю должным образом, данная операция НИКОГДА не примет значение NaN, то есть он будет исключен из уравнения. А вот undefined вы исключить никак не можете, потому что просто создавая переменную без начального значения или вызваете функцию без аргумента, сразу получаете undefined в списке возможных значений. Так работает JS, увы. И раз NaN я могу исключить, кроме того я ним тяжелее работать, а undefined я исключить не могу никак. Уж лучше я буду работать с двумя вариантами: валидное значение (число) и отсутствие значения (undefined).
Как нет, если оно есть. Это пустая строка. Напишите в консоли undefined === '', вам вернет false. undefined (отсутствие значения) и '' (пустая строка) — это разные вещи. Что вам непонятно-то тут?
Пустая строка это не значение для типа number. Его нужно к чему-то привести. Вариантов 2, либо к 0, но почему? Либо принять что в качестве числа, пустая строка это отсутствие значения. Мне импонирует второе.
Не дать ввести что-либо кроме телефона легко, а вот не дать ввести что-либо кроме чисел — очень нетривиальная задача. Вы просто явно с такими задачами не встречались.
Тут просто задача напрямую так не ставится. Код приведение значения я приводил выше. Он крайне просто и логичен. Не знаю о чем вы тут спорите.
js как раз так не работает. В форме у вас пустая строка — не undefined. Когда вы эту строку засовываете в parseInt(), то получается NaN (и никогда не получается undefined). Если засунуть эту строку в Number — получится 0 (или NaN в случае 'gdfgdf' — но, снова, никаких undefined).
Никогда и ни при каких обстоятельствах в js в данном контексте не бывает undefined.
Я писал о другом. undefined — всегда есть в списке вероятных значений для переменной или аргументы функции. От него никак не избавиться.
То есть вы вообще в своих биндингах сломали js-ную логику парсинга чисел.
Точно! Взяли и придумали удобную)
К сожалению, веб спеки не отличаются продуманностью.
А к багам это какое отношение имеет?
Это вам тут не понятно, у меня есть 2 переменные, которые я могу чекать и еще как-то процессить и есть выражение, к которому вы аппелируете.
Вы опять не прочитали, что я пишу. Еще раз, у вас уже есть NaN. Потому что undefined + 5 = NaN. С-но вы не выбираете "число + NaN" вс "число + undefined", вы выбираете "число + NaN" вс "число + NaN + undefined". И вы почему-то топите за первый вариант. Почему? Я это пытаюсь у вас выяснить.
Так вот ваш NaN, от которого я яковы не могу отказаться, это результат выражения, а не переменной.
И это не отменяет того факта, что вы должны его обработать.
Если я их обработаю должным образом, данная операция НИКОГДА не примет значение NaN
Как не примет, если у вас она по факту в вашем примере NaN принимает. Кроме NaN еще, кстати, надо infinity обрабатывать.
А вот undefined вы исключить никак не можете
undefined я могу исключить просто потому, что в js из inputa этот undefined никогда не придет.
И раз NaN я могу исключить
Не можете, не сломав инпут.
Пустая строка это не значение для типа number. Его нужно к чему-то привести.
Любая строка — не значение для типа number.Чтобы строка стала числом — ее надо распарсить. ВАjs, Если вы парсите строку, которая является корректным числом, вы получаете это число. Если вы парсите строку, которая не является корреткным числом — вы получаете NaN. но не при каких обстоятельствах вы не получаете при парсинге строки undefined.
Тут просто задача напрямую так не ставится. Код приведение значения я приводил выше. Он крайне просто и логичен.
А непустую некорректную строку вы к чему и как приводите? И почему алгоритм вашего приведения нарушает спеку js? Зачем?
Я писал о другом. undefined — всегда есть в списке вероятных значений для переменной или аргументы функции.
js — динамический язык, по-этому в списке вероятных значений для переменной или аргументов ф-и есть все вообще.
Если, однако, мы говорим о инпуте — то мы знаем, что там будет всегда строка. Если мы говорим о результате парсинга этой строки — мы знаем, что там число или NaN. И еще мы знаем, что undefined там не бывает.
Лучше бы было то, что ввёл пользователь, без потери информации.
Вводим "2e" — инпут очищается. Как пользователю ввести число "2e10"?
Вводим "2." — инпут очищается. Как пользователю ввести число "2.1"?
Вводим "e2" — текст остаётся в инпуте. Очень похоже на число, да.
Вводим "--1" — текст остаётся в инпуте. Очень похоже на число, да.
Вводим «e2», добавляем в начале 1 — мгновенно получаем 100.
Вводим «e100», добавляем в начале 0 — мгновенно получаем 0 (дробная часть — не, не слышали).
Вводим «e100», добавляем в начале 1 — о, ура, получили «1e+100»!
Вводим ".e10", добавляем 1 после точки — получаем 1000000000. Дробная часть из нескольких цифр? Не, не слышали.
Забавно, как у нас с вами разнятся ожидания. Хотя это вопрос стандартизации.
Вот от date я бы на 97% ожидал именно тип даты. А вот с номером телефона и в каком формате если строка — тут вопрос. Скорее это таки long без форматирования, который можно представлять в любом формате в строке. Или массив цифр, чтоб ни у кого не было соблазна оперировать номером телефона как числом.
Вот от date я бы на 97% ожидал именно тип даты.
Здесь возникает вопрос с часовыми поясами. new Date('2019-05-12') вернет вам полночь в вашей таймзоне, а в других поясах это будет другое число.
Хранить всегда в UTC? Или, по крайней мере, записывать. А при чтении из date вы сможете получить как локализованное значение, так и UTC, так и с любым другим сдвигом.
Получится какой-то такой код
const value = '2019-05-12';
// Date.UTC принимает только числа, поэтому парсим строку руками
const [year, month, day] = date.split('-');
const date = new Date(Date.UTC(Number(year), Number(month) - 1, Number(day)));
console.log(date.getUTCDate()); // будет всегда 12 в любой таймзоне, как нам и хотелосьКак-то это не вяжется с исходным пожеланием статьи о том, чтобы писать меньше кода.
Как мне кажется, это хорошо что и нативный input, и svelte для дат возвращают ее строковое представление, чтобы разработчик сам его обрабатывал как надо.
И еще пример из реакт:
this.setState({ foo: 1 }); // {foo} НЕ используется в шаблоне JSX
Вам ведь надо «помнить» что вызов setState() вызовет rerender + reconcile даже если {foo} не используется в шаблоне вообще!!!??? В Svelte вы полностью избавлены от таких проблем)
В Svelte вы полностью избавлены от таких проблем)
Наоборот же — в svelte надо помнить, что если foo в шаблоне нет, то рендер не будет вызван :)
Логика реакта с безусловным рендером в этом плане явно проще.
Наоборот же — в svelte надо помнить, что если foo в шаблоне нет, то рендер не будет вызван :)
Извините, а зачем нам рендер, если foo нет связан с DOM? Или в этом просто какой-то сокральный смысл есть?
Логика реакта с безусловным рендером в этом плане явно проще.
Она не проще, а просто тупее. Нам же памяти не жалко, пусть гоняет туда-сюда vdom, даже если это не имеет смысла.
Извините, а зачем нам рендер, если foo нет связан с DOM?
А откуда я знаю, что он не связан? О том же и речь — в svelte мне надо помнить, что с чем связано.
Она не проще, а просто тупее.
KISS :)
Нам же памяти не жалко, пусть гоняет туда-сюда vdom, даже если это не имеет смысла.
Ну вообще-то да.
А откуда я знаю, что он не связан? О том же и речь — в svelte мне надо помнить, что с чем связано.
Простите, но у вас задача-то какая? Вызвать рендер или показать значение?
А откуда я знаю, что он не связан? О том же и речь — в svelte мне надо помнить, что с чем связано.
Вопрос же в том, зачем вам об этом вообще думаю? Лично мне достаточно знать 2 вещи:
1) я хочу чтобы мой стейт всегда был синхронизирован в DOM
2) я знаю что Svelte делает это максимально эффективно.
Исходя из этого, если внутренняя логика компонента требует изменения foo, то я его буду менять в любом случае, связана эта переменная с DOM или нет. Если она связана, то согласно п.1, я в любом случае хочу, чтобы изменения были применены к DOM. Если же не связана, то очевидно, я не хочу никаким образом нагружать свое приложение лишними вычислениями. Именно так будет работать Svelte. В реакте же мы нагружаем приложение вычислениями в любом случае и как мы тут выяснили ниже, только постоянный рефакторинг компонентов позвонил сделать этот процесс хоть сколь-либо контролируемым.
KISS :)
В данном случае это Keep It So Stupid
Ну вообще-то да.
Именно поэтому реакт не подходит для многих проектов, особено для low-power устройств. И речь даже не о экзотических штуках, типа POS терминалах, на которых Svelte показал себя прекрасно, но я просто на мобильных и ТВ. Мы его лично пробовали на ТВ, это марк же.
Если же не связана, то очевидно, я не хочу никаким образом нагружать свое приложение лишними вычислениями.
Так не факт, что они лишние.
Именно поэтому реакт не подходит для многих проектов, особено для low-power устройств. И речь даже не о экзотических штуках, типа POS терминалах, на которых Svelte показал себя прекрасно, но я просто на мобильных и ТВ.
Вопрос, зачем вообще использовать spa для low-power устройств, остается открытым.
Так не факт, что они лишние.
Если foo не связан в DOM, то rerender + reconcile при его изменении — это безусловно лишние операции.
Вопрос, зачем вообще использовать spa для low-power устройств, остается открытым.
А React подходит только для SPA? Еще говорят Svelte имеет какие-то ограничения по области использования ;-) К вашему сведению, все приложения для TV это как правило SPA, потому что далеко не все платформы поддерживают запуск приложения с удаленного сервера, обычно файлы крутятся на локальном или даже по протоколу file://.
Если foo не связан в DOM, то rerender + reconcile при его изменении — это безусловно лишние операции.
А вдруг рендер где-то что-то поменяет и в итоге изменятся данные, которые выводятся?
А React подходит только для SPA? Еще говорят Svelte имеет какие-то ограничения по области использования ;-)
Что реакт, что свелте, что все остальное — это спа-фрейморвки. Если вам не нужно спа, то у них нет преимуществ никаких по сравнению с vanillajs.
обычно файлы крутятся на локальном
Ну так и крутите на локальном, spa зачем? Можно спокойно написать логику на беке. Да и вообще было бы интересно увидеть конкретный кейс, где реакт тормозил, а вот свелте решил проблему. Ну и еще желательно пример какого-нибудь приложения на свелте хотя бы среднего (100kloc+) размера приложения, чтобы понимать, как это скалируется все.
А вдруг рендер где-то что-то поменяет и в итоге изменятся данные, которые выводятся?
Такого быть не должно.
Что реакт, что свелте, что все остальное — это спа-фрейморвки. Если вам не нужно спа, то у них нет преимуществ никаких по сравнению с vanillajs.
Обоснуйте. Не вижу никакой проблемы во вставке компонента реакт или свелте на любую страницу (кроме веса реакта).
А вдруг рендер где-то что-то поменяет и в итоге изменятся данные, которые выводятся?
А вдруг, где-то, что-то, как-то))) Очень конструктивненько))) Я вам уже писал об этом, моя мысль не изменилась — реактголовногомозга. И я вас понимаю, потому что если долго работать с такой парадигмой, по-другому мыслить уже не получается.
Говорите рендер что-то где-то поменяет? Хм, попробую себе представить:
<p>{bar()}</p>
<input bind:value={foo} type="number">
<script>
let foo = 0;
function bar() {
return foo + 1;
}
</script>
Так что ли? Только в Svelte такие вещи делаются не так))) Можно через чистую функцию (если нравятся функции), а можно через вычисляемое выражение:
<p>{bar(foo)}</p>
<p>{baz}</p>
<input bind:value={foo} type="number">
<script>
let foo = 0;
function bar(foo) {
return foo + 1;
}
$: baz = foo + 1;
</script>
Результат будет одинаковый, за исключением того, что функция будет вычисляться по принципу pull, а реактивная декларация по принципу push. Там уж решайте от задачи. В данном кейсе я бы выбрал второй подход. Он эффективнее тут и значительно лаконичнее.
Что реакт, что свелте, что все остальное — это спа-фрейморвки. Если вам не нужно спа, то у них нет преимуществ никаких по сравнению с vanillajs.
Это не так))) У реакт да, никаких преимуществ, но Svelte есть преимущество перед vanillajs, потому что по-сути Svelte — это способ писать vanillajs без необходимости писать vanillajs. Svelte подходит не только для любых видов SPA, но и для микро-фронтендов, для работы поверх классического бекенда в качестве интерактивных виджетов страницы (взамен jquery или ванильных реализаций). С ним можно даже рефакторить приложения на других фреймворках, например переписывать какие-то отдельные компоненты, чтобы они работали лучше.
Ну так и крутите на локальном, spa зачем? Можно спокойно написать логику на беке.
А кто сказал что есть доступ к локальному серверу? Там же просто раздача статики. Что вы ерунду то пишете, не в курсе, так просто промолчали бы.
Да и вообще было бы интересно увидеть конкретный кейс, где реакт тормозил, а вот свелте решил проблему.
В видео к предыдущей статье был кейс с POS терминалами. Реакт тоже тестировался.
Ну и еще желательно пример какого-нибудь приложения на свелте хотя бы среднего (100kloc+) размера приложения, чтобы понимать, как это скалируется все.
А есть такие приложения в open-source для реакта? Пришлите ссылку, гляну, может напишу аналог. Правда придется при этом по фунционалу раздуть процентов на 50%. Ну чтобы сравняться по кол-ву строк кода с приложение на реакт.
Вообще вопрос странный, учитывая что из коробки Svelte значительно мощнее реакта, то непонятно, почему вы вообще ставите вопрос о том, что он может хуже скалироваться?
Я вам уже писал об этом, моя мысль не изменилась — реактголовногомозга.
Вообще-то я реакт не люблю и считаю худшим, что есть в современном фронтенде (как и в принципе околофейсбучные технологии, ребята из фейсбука для меня как царь Мидас, но только наоборот).
Если серьезно, по всей ветке — в линтере есть правило, которое дает ворнинг по неиспользуемым в шаблонах переменные стейта :)
Вообще-то я реакт не люблю и считаю худшим, что есть в современном фронтенде (как и в принципе околофейсбучные технологии, ребята из фейсбука для меня как царь Мидас, но только наоборот).
Удивили, признаюсь)) Тогда вообще не ясно чего вы так за него топите и что по-вашему «хорошо». Или вы эдакий вечно ворчливый дедька с клюшкой? Все вам не нравится, все говно.
Если серьезно, по всей ветке — в линтере есть правило, которое дает ворнинг по неиспользуемым в шаблонах переменные стейта :)
Во-первых, если для решения проблемы нужен линтер, то значит эта проблема есть. Во-вторых, линтер за вас не перепишет код, который уже завязан на foo и его setState. Хорошо бы, чтобы шаблон просто не ререндерился, если связанные с ним части стейта не поменялись. Я даже не понимаю с чем тут можно спорить. Ну хорошо ведь, а?
Тогда вообще не ясно чего вы так за него топите и что по-вашему «хорошо».
Я не топлю, я просто сравниваю два разных подхода. Если вдруг что-то выглядит где-то как "топление" — ну ок, это просто так выглядит :)
Во-первых, если для решения проблемы нужен линтер, то значит эта проблема есть.
Да, это проблема из разряда "неиспользуемая переменная/ф-я". Ну, чтобы в коде мусора не было и не вспоминать через год, а что это там за yoba в стейте и не используется ли она как-то там где-то там :)
Ну хорошо ведь, а?
С точки зрения логики приложения без разницы.
Пока мы не "ломаем" рендер (кейз с изменением чего-то там в рендере). Если ломаем (зачем-то, мало ли) — то рендерить всегда будет полезнее :)
Я не топлю, я просто сравниваю два разных подхода. Если вдруг что-то выглядит где-то как «топление» — ну ок, это просто так выглядит :)
Да я понял, вы из Ангулярщиков. Кстати, ниче против ангуляра не имею, очень достойная вещь для энтерпрайзов. Наверное сам бы взял для очень крупного проекта. Благо очень крупными мы и не занимаемся, терпеть не могу такие проекты.
Да, это проблема из разряда «неиспользуемая переменная/ф-я». Ну, чтобы в коде мусора не было и не вспоминать через год, а что это там за yoba в стейте и не используется ли она как-то там где-то там :)
Не-не, это другое. Мы рассматриваем кейс, когда часть стейта перестала использоваться в шаблоне, а не вообще в компоненте. В том то и дело, что в компоненте на основе foo еще много чего может вычисляться и setState там тоже делается не просто так. А вот в шаблоне не используется(((
С точки зрения логики приложения без разницы.
Пока мы не «ломаем» рендер (кейз с изменением чего-то там в рендере). Если ломаем (зачем-то, мало ли) — то рендерить всегда будет полезнее :)
Я говорю про общую эффективность операций, а не про логику и уже тем более, не про DX. В комментариях есть разработчики которым вообще плевать на то сколько раз в секунду из компоненты полностью перерендериваются, сколько памяти жрут и т.д.
Да я понял, вы из Ангулярщиков.
Здесь, скорее, стоит речь вести о задачах. Я из тех, кто больше по тем задачам, для которых подходит ангуляр — так правильнее всего :)
Если мне надо будет накидать гостевуху, я точно не буду писать ее на ангуляре. Может, возьму тот же свелте, из интереса просто :)
Вы вот, как сами сказали, по другим задачам.
В комментариях есть разработчики которым вообще плевать на то сколько раз в секунду из компоненты полностью перерендериваются, сколько памяти жрут и т.д.
Ну вот опять же это вопрос задачи. Приложение должно быть достаточно производительным. Просто если вы пишите под низкопроизводителные устройства, то у вас граница, где "достаточно" переходит в "п*здец как тормозит" проходит очень близко, с-но, вам всегда и приходится о производительности думать. Если же эта граница далеко — то, с-но, думать об этом смысла нет, пока она не приблизится :)
Вам ведь надо «помнить» что вызов setState() вызовет rerender + reconcile даже если {foo} не используется в шаблоне вообще!!!???
А зачем нужно свойство, от которого не зависит визуализация?
Под рантаймом я как раз и подразумеваю неявные штуки, которые фреймворк/либа делает за меня. Вам про числа уже много написали, что ожидается порой совсем другое. А если вы все же настаиваете на своем, то почему у инпута типа date нет приведения к дате? Или есть?)
Более того, синтаксис — учи еще один язык. Чего стоят только вот такие штуки:
{#await promise then value}
<p>The value is {value}</p>
{/await}
В общем, без полбутылки не разберешься. Писать вот так сразу на нем куда сложнее, чем на vue или react. Там реально есть интуитивные штуки.
Вот как раз это помнить не стоит сразу. Об этом нужно вспомнить, когда это станет проблемой. Оптимизацией нужно заниматься тогда, когда это нужно, как бы это не звучало)
Вы видимо пишете код исключительно для топовых моделей устройств с хуилионом памяти. В нашем же случае проблемы с реакт встают практически моментально. У вас они тоже есть скорее всего, просто вы их пока не замечаете.
Под рантаймом я как раз и подразумеваю неявные штуки, которые фреймворк/либа делает за меня.
Любая абстракция в рантайме — это не явная штука которую фреймворк делат за вас. Вот вы уверены что совершенно точно знаете как ведет себя «машинка» реакта конкретно для вашего компонента? А для Svelte я знаю совершенно точно, потому что я могу просто открыть итоговый код компонента и прочитать его полностью за 1-2 минуты, ибо там нет вообще никакой подкапотной магии. Я могу БЕЗ ДЕБАГГЕРА совершенно точно сказать какая операция моего компонента какие именно действия будет производить, а вы в реакт так можете? Нет. Это то что я называю «рантаймом».
Вам про числа уже много написали, что ожидается порой совсем другое.
Ожидаете другое? Не юзайте встроенный 2way биндинг, юзайте такой же ивент хендлер как в реакт, получайте строку и делайте с ней что надо. Одно другому не мешает. Только в Svelte и том же Vue и Angular у нас такая возможность есть, а в реакт ее просто нет.
А если вы все же настаиваете на своем, то почему у инпута типа date нет приведения к дате? Или есть?)
А с какие пор у нас Дата — это примитивный тип? Поэтому и не приводится. Для Boolean кстати тоже приведение идет, например если это чекбокс:
<script>
let checked = true;
</script>
<input type="checkbox" bind:checked={checked}>
<p>{typeof checked}</p> <!-- boolean -->
Более того, синтаксис — учи еще один язык.
Синтаксис любых DSL для HTML надо учить. Тот же Angular и Vue. Синтаксис HTMLx, который использует Svelte не сложнее чем у них уж точно. А ежели вы топите за JSX, то хочу вас расстроить, там тоже много чего надо учить, даже если вы знаете JS. А уж HTML лучше вообще не знать, а то использовать JSX будет болью.
Чего стоят только вот такие штуки:
Вы их и учить то не можете, потому что нигде таких штук больше нет. А {#await} кстати очуменно удобная штуковина.
В общем, без полбутылки не разберешься. Писать вот так сразу на нем куда сложнее, чем на vue или react. Там реально есть интуитивные штуки.
А давайте сравним, чего воздух то сотрясать без толка?
<>
<h1 style="color:red">Hello {name}!</h1>
<input value={name} onChange={e => setName(e.target.value)}>
<hr>
{(() => {
if (count < 10) {
return <button onClick={e => setCount(count + 1)}>
Clicks {count}
</button>;
} else {
return <>
<p>Clicks limit overcome</p>
<button onClick={e => setCount(0)}>Drop</button>
</>;
}
})()}
</>
<template>
<div>
<h1 style="color:red">Hello {{ name }}!</h1>
<input v-model="name">
<hr>
<button v-if="count < 10" @click="count++">
Clicks {{ count }}
</button>
<div v-else>
<p>Clicks limit overcome</p>
<button @click="count=0">Drop</button>
</div>
</div>
</template>
<h1 style="color:red">Hello {{ name }}!</h1>
<input [(value)]="name">
<hr>
<button *ngIf="count < 10; else elseBlock" (click)="count = count + 1">
Clicks {{ count }}
</button>
<ng-template #elseBlock>
<p>Clicks limit overcome</p>
<button (click)="count=0">Drop</button>
</ng-template>
<h1 style="color:red">Hello {name}!</h1>
<input bind:value={name}>
<hr>
{#if count < 10}
<button on:click={e => count++}>
Clicks {count}
</button>
{:else}
<p>Clicks limit overcome</p>
<button on:click={e => count=0}>Drop</button>
{/if}
Все примеры идентичны и в любом из этих примеров есть что «поучить», несмотря на то, что мы даже до работы с массивами не добрались. Если вы конечно работаете с каким-то из этих DSL много лет, наверное вам он кажется более понятным, чем остальне. НО, только один из этих примеров не работает… Именно он, тот самый интуйтивный. ;-)
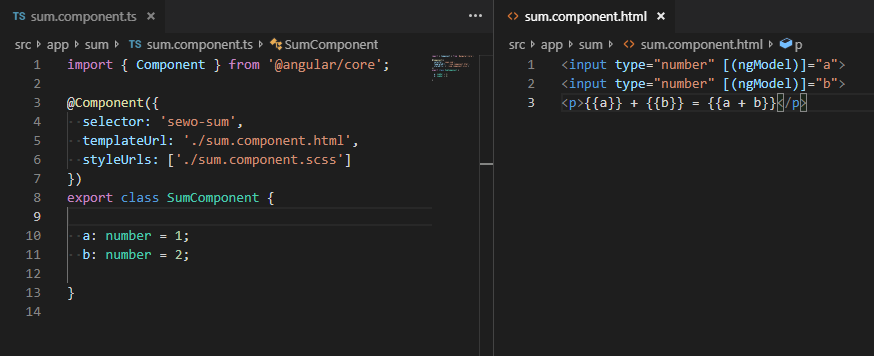
Количество именно написанного кода соизмеримо со Svelte — две переменные и три HTML-элемента. Остальное автоматически генерирует CLI и на эту обвязку при работе вообще не обращаешь внимания. При этом, за один раз ты смотришь либо код компонента, либо представление. Что ещё больше сокращает количество информации, которую надо охватить за раз.
Для бекендщиков ровно наоборот
Есть куча других фреймворков которые не требуют эти знания, но которые дают тоже самое но с болъшей скоростью, меньшим размером и т.д.
Какие?
Зачем изучать? Все эти концепции любому программисту должны быть и так известны, ничего нового там не придумали.
<DateRange bind:start={startDate} bind:end={endDate} />
<p>Selected dates: {startDate} - {endDate}</p>
<script>
import DateRange from './DateRange.svelte';
let startDate = Date.now(),
endDate;
</script>
Кроме того ваш довод про «остальное автоматически генерирует CLI» не очень состоятелен, так как его можно применить и к Vue, потому что там без сниппетов в IDE тоже мало кто пишет. Другое дело читать все эти лишние конструкции все равно придется потом вам или другим. И кода это в любом случае больше.
CLI есть всегда (ну почти) и в любой IDE (или без неё), а наличие сниппетов зависит от IDE.
Де-факто, Angular CLI является частью фреймворка и потому
ng g c sumUI framework vs Application framework — это как?
Я ещё понимаю, когда UI library vs App framework в контексте React vs Angular. А вот UI vs App — непонятно.
Всё-таки сниппеты IDE и команды CLI — немного две большие разницы.
Конечно, ведь сниппеты к IDE пишутся дома на коленке, а CLI — это сложная вещь. Кстати, у Vue тоже вполне себе не плохой CLI. Только CLI не поможет вам читать код, который оно нагенерит.
UI framework vs Application framework — это как?
Я ещё понимаю, когда UI library vs App framework в контексте React vs Angular. А вот UI vs App — непонятно.
А мне кажется это более точные определения, потому что ну вот какая из Vue или React «библиотека»? У них нет никакой прикладной ценности.
Lodash — это библиотека, а основная ценность Vue/React/Svelte — это структурирование кода в виде компонентов с изолированным стейтом, то есть это фреймворки, структуры. Далее, вопрос, а что мы можем структурировать с помощью React/Vue/Svelte? Полностью веб-приложение можем? Очевидно без роутинга, фетчинга и другие таких вещей нет, но можем построить UI.
В этом смысле Vue/React/Svelte — это UI frameworks. Angular — application framework, потому что на его основе мы можем построить не только UI, но и все приложение.
Очевидно без роутинга, фетчинга и другие таких вещей нет
Вот делаю я простую браузерную игрушку типа "Жизнь" — зачем мне там роутинги, фетчинги и тп?
Angular — application framework, потому что на его основе мы можем построить не только UI, но и все приложение.
Вот делаю я читалку PDF. Как это сделать без привлечения сторонних библиотек?
Вот делаю я простую браузерную игрушку типа «Жизнь» — зачем мне там роутинги, фетчинги и тп?
А это уже целое приложение? ))) Выглядит как демка просто.
Вот делаю я читалку PDF. Как это сделать без привлечения сторонних библиотек?
Ну так берите PDF фреймворк и вперед))
Вот делаю я читалку PDF. Как это сделать без привлечения сторонних библиотек?
А откуда взялось уточнение "без привлечения сторонних библиотек"? От application framework не требуется заменять все возможные библиотеки.
У вас ведь тоже компилятор вызывается из консоли и генерит итоговый код :)
Вообще, никто не мешает для ангуляра написать схему, которая будет подхватывать файлы, написанные по типу svelte и автоматом генерить по ним ангуляровские файлы из примера выше. И регистрировать их в ближайшем локальном модуле автоматом.
Но в плане реализации, совершенно другой подход.
На самом деле, нет, ангуляр точно так же компилирует шаблоны. С ivy и тришейкинг хотят добавить, чтобы было "исчезающе" :)
А в реакте компилировать ничего не надо вовсе, т.к. там шаблон по сути обычный js.
На самом деле, нет, ангуляр точно так же компилирует шаблоны.
На самом деле да. Потому что несмотря на AoT агнуляра делается оно только для шаблонов, а в Svelte не только для них. Примерно то, что сейча сделает ангуляр, предшественник Svelte, фреймворк Ractive делал уже в 2013 году.
С ivy и тришейкинг хотят добавить, чтобы было «исчезающе» :)
Когда добавят, тогда и посмотрим. Хотя в целом в верном направлении думают. Пока же все равно все компоненты зависят от ангуляр core.
А в реакте компилировать ничего не надо вовсе, т.к. там шаблон по сути обычный js.
Вы видимо так и не вкурили в чем самая ценность компиляции. Попробую донести еще раз:
Принцип работы React, у которого шаблонизатор просто JS и которому не нужна компиляци:
State Changed -> Rerender -> Reconcile -> Update DOM
Принцип работы Svelte, который ниче особенного и вообще все это уже было:
State Changed -> Update DOM
Разницу улавливаете? Стало понятнее куда делись 2 тяжеленные операции из рантайма и зачем нам компиляци?
На самом деле да. Потому что несмотря на AoT агнуляра делается оно только для шаблонов, а в Svelte не только для них.
Ну это на самом деле проблема svelte, что приходится делать компиляцию и самого кода компонента. По факту, это ничего полезного не дает.
Примерно то, что сейча сделает ангуляр, предшественник Svelte, фреймворк Ractive делал уже в 2013 году.
Только в ractive нету и 10% функционала ангуляра. А так-то да :)
Хотя в целом в верном направлении думают. Пока же все равно все компоненты зависят от ангуляр core.
В точности как и у вас они зависят от svelte/core. Просто вы этот svelte/core при компиляции кладете к каждому компоненту.
Принцип работы React, у которого шаблонизатор просто JS и которому не нужна компиляци:
Два промежуточных шага нужны исключительно для оптимизации, так что их можно отбросить, они не влияют на семантику.
Стало понятнее куда делись 2 тяжеленные операции из рантайма и зачем нам компиляци?
Они убрались не из-за компиляции, а из-за того, что у вас cd вместо vdom'a. В ангуляре этих шагов тоже нет. И ни в каком другом фреймворке с cd нет.
По факту, единственная польза от компиляции в рамках js — это то, что вы можете не тащить с собой компилятор в итоговый бандл. И это все. Больше она никаких плюсов не может давать by design, так устроен сам js.
Ну это на самом деле проблема svelte, что приходится делать компиляцию и самого кода компонента. По факту, это ничего полезного не дает.
Это не проблема Svelte, а решение проблем других фреймворков. Если вы этого так и не поняли, учитывая километры переписки комментариях к другим статьям, когда вам несколько человек уже объясняли одно и тоже, я тут бессилен.
Только в ractive нету и 10% функционала ангуляра. А так-то да :)
А давайте например? Ну чтобы прям 90% только набрать)
В точности как и у вас они зависят от svelte/core. Просто вы этот svelte/core при компиляции кладете к каждому компоненту.
Это не так, видимо вы так и не посмотрели на исходные коды. Весь Svelte — это чуточка хелперов, которые подключаются только по надобности и шейкаются и очень специализированный код компонента по работе с DOM. Все, там больше ничего нет. Более того, в зависимости от того, как вы собирете свои компоненты, в какой композиции, в какие бандлы, какими настройками зависит итоговый код бандлов. Вы можете хоть каждый компонент сделать отдельный бандлом, тогда местами код будет дублироваться да, а можете собрать все в один, тогда не будет. И все это возможно лишь изменением настроек бандлера, а не компонентов. Но главное остается неизменным — любой бандл абсолютно stand-alone и содержит только тот код, который нужен для его работы.
Два промежуточных шага нужны исключительно для оптимизации, так что их можно отбросить, они не влияют на семантику.
Как отбросить, если тогда реакт не сможет сделать точечное изменение в реальный DOM, так как не поймет что поменялось и какое изменение нужно. Вы что такое говорите)))
Они убрались не из-за компиляции, а из-за того, что у вас cd вместо vdom'a. В ангуляре этих шагов тоже нет. И ни в каком другом фреймворке с cd нет.
Опять 25)) Для vdom — это и есть cd. Если в случае со Svelte под cd вы подразумеваете строгие стравнения парочки значений, после которых идет точечный вызов DOM API для заранее закэшированных элементов, то ладно, можете называть как хотите. Только на надо это сравнивать с ангуляр, потому что он делает значительно больше вычислений в рантайме. Нет? Приведите пример cd на ангуляр, а я приведу для Svelte и сравним, идет?
По факту, единственная польза от компиляции в рамках js — это то, что вы можете не тащить с собой компилятор в итоговый бандл. И это все. Больше она никаких плюсов не может давать by design, так устроен сам js.
Нихрена себе «единственный плюс», это львиная доля вычислений в рантайме. Жирный такой плюс. Когда вы можете написать так:
<button on:click={e => count++}>Count {count}</button>
А ВЕСЬ cd и render в рантайме будет заключаться в:
if (changed.count) {
if (t1.data !== ctx.count) t1.data = ctx.count;
}
Где закешированная t1 это текстовая нода внутри button (даже document.querySelector не делается!!!)
Давайте представим сколько операция будет выполнено в ангуляр/реакт чтобы сделать тоже самое, а?
Это не проблема Svelte, а решение проблем других фреймворков.
Каких именно проблем?
А давайте например? Ну чтобы прям 90% только набрать)
ractive — это, опять же, как и svelte чистый рендерер. Там в общем-то ничего нет.
Это не так, видимо вы так и не посмотрели на исходные коды. Весь Svelte — это чуточка хелперов
Окей, окей, не весь кор кладете к каждому компоненту, а то что нужно. Или все собирается в отдельный бандл. Какая разница-то?
Как отбросить, если тогда реакт не сможет сделать точечное изменение в реальный DOM, так как не поймет что поменялось и какое изменение нужно.
Без этих шагов он просто перерендерит весь дом, вот и все.
Опять 25)) Для vdom — это и есть cd.
В реакте нет cd и vdom нужен только для оптимизации. Семантически реакт просто перерендеривает дом.
Если в случае со Svelte под cd вы подразумеваете строгие сравнения парочки значений
Ну в одной компоненте их конечно парочка, но на практике их тысячи.
Приведите пример cd на ангуляр, а я приведу для Svelte и сравним, идет?
Сравним как именно?
А ВЕСЬ cd и render в рантайме будет заключаться в:
Так можно и в рантайме все скомпилировать и будет точно так же.
Давайте представим сколько операция будет выполнено в ангуляр/реакт чтобы сделать тоже самое, а?
Ну столько же и будет. Точно так же, что реакт, что ангуляр сравнят старое и новое значение и обновят соответствующую дом-ноду (сам процесс апдейта, конечно, немного по-разному будет проходит, но это несущественно).
А по-вашему что там происходить будет?
В реакте нет cd и vdom нужен только для оптимизации.
В том реакте, который я знаю, vdom — это основа всего. Он лежит в основе архитектуры, синтаксиса и семантики. Нельзя так просто взять и отказаться от "просто оптимизации" в реакте.
Семантически реакт просто перерендеривает дом.
И именно в этом проблема. Выбрано изначально неоптимальное решение, которое дальше пытаются оптимизировать.
В том реакте, который я знаю, vdom — это основа всего. Он лежит в основе архитектуры, синтаксиса и семантики.
Нет, не лежит. Вы можете убрать из реакта вдом и для программиста не изменится вообще ничего.
Выбрано изначально неоптимальное решение, которое дальше пытаются оптимизировать.
Не бывает оптимальных или неоптимальных решений. Бывают достаточно и недостаточно оптимальные.
Вы можете убрать из реакта вдом и для программиста не изменится вообще ничего.
И как в таком случае будет выглядеть метод render?
Не бывает оптимальных или неоптимальных решений. Бывают достаточно и недостаточно оптимальные.
Бывают решения, которые менее оптимальны чем другие.
И как в таком случае будет выглядеть метод render?
В смысле? Точно так же и будет. Возвращает кусок дома, описанный на jsx. Ну или прямыми вызовами.
Бывают решения, которые менее оптимальны чем другие.
Ну да, недостаточно оптимальные решения (оптимальность = 0) менее оптимальны, чем достаточно оптимальные (оптимальность = 1). Но все недостаточно оптимальные эквивалентны друг другу, как и достаточно оптимальные.
В смысле? Точно так же и будет. Возвращает кусок дома, описанный на jsx. Ну или прямыми вызовами.
Кусок DOM, конечно же, можно вернуть — но для полноценной работы с DOM нужно ещё и уметь его обновлять не перезатирая. Если сделать метод render возвращающим DOM — то такая архитектура никогда не позволит достигнуть состояния "достаточно оптимально".
Это реализуется проще — каждому узлу выставляется идентификатор, и если по нему находится узел в доме, то берётся он, а если нет — создаётся новый. И это будет даже эффективней, чем Реакт, который полностью перерендеривает поддерево, при переносе его в дугого родителя.
И при этом, конечно же, никакого инструментария для автоматического проставления этих идентификаторов?
А самое веселое при таком подходе начинается если идентификаторы ошибочно повторяются.
Элементам так или иначе придётся давать имена вручную. Ибо семантику никакая автоматика не сгенерирует.
Идентификатор складывается из идентификатора компонента и имени элемента в нём. Так что глобальный конфликт не возможен. А локальный можно пресекать обёрткой вокруг render функции хранящей использованные в ней имена.
Кусок DOM, конечно же, можно вернуть — но для полноценной работы с DOM нужно ещё и уметь его обновлять не перезатирая.
В данный момент реакт обновляет дом, перезатирая.
то такая архитектура никогда не позволит достигнуть состояния "достаточно оптимально".
В реакте же позволяет, с некоторыми оптимизациями.
В данный момент реакт обновляет дом, перезатирая.
В данный момент реакт не трогает DOM если нечего менять.
В реакте же позволяет, с некоторыми оптимизациями.
Так потому и позволяет, что виртуальный DOM используется.
В данный момент реакт не трогает DOM если нечего менять.
А если менять надо — то перезатирает.
Так потому и позволяет, что виртуальный DOM используется.
Но это просто оптимизация, она никак не влияет на архитектуру и поведение приложения. Вы можете убрать вдом и приложение будет работать с тем же результатом, просто выдавать его будет несколько медленнее.
Но это просто оптимизация, она никак не влияет на архитектуру и поведение приложения.
Архитектура Реакта возможна в существующем виде только из-за этой "просто оптимизации".
Вы можете убрать вдом и приложение будет работать с тем же результатом, просто выдавать его будет несколько медленнее.
Нет, будет теряться состояние элементов при каждом чихе.
Архитектура Реакта возможна в существующем виде только из-за этой "просто оптимизации".
И без возможна. Просто убираете оптимизацию и получаете реакт без нее.
Нет, будет теряться состояние элементов при каждом чихе.
Реакт при ререндере элемента стейт не теряет, только когда компонент заново создается.
Ну и вас никто не заставляет делать ререндер поддерева, если не изменились пропсы, для этого не нужно никакого вдома, достаточно просто сохранять предыдущие пропсы и сравнивать при новом вызове рендера.
Реакт при ререндере элемента стейт не теряет, только когда компонент заново создается.
Так потому и не теряет, что не пересоздает его. Будет пересоздавать — будет терять.
Ну и вас никто не заставляет делать ререндер поддерева, если не изменились пропсы, для этого не нужно никакого вдома, достаточно просто сохранять предыдущие пропсы и сравнивать при новом вызове рендера.
Ререндера можно избежать только для компонента целиком, но не для его части.
Так потому и не теряет, что не пересоздает его. Будет пересоздавать — будет терять.
А кто предлагал пересоздавать компонент? Мы вроде обсуждали ререндер дома в ф-и render. Очевидно, вроде, что ререндер дом-дерева компонента и пересоздание самого компонента — вещи существенно разные, нет?
Ререндера можно избежать только для компонента целиком, но не для его части.
Под "поддеревом" и подразумевался компонент. С точки зрения дома, компоненту соответствует некоторое поддерево в этом доме.
А кто предлагал пересоздавать компонент? Мы вроде обсуждали ререндер дома в ф-и render. Очевидно, вроде, что ререндер дом-дерева компонента и пересоздание самого компонента — вещи существенно разные, нет?
Вы предлагали пересоздавать элемент. У которого тоже, внезапно, бывает внутреннее состояние.
Под "поддеревом" и подразумевался компонент. С точки зрения дома, компоненту соответствует некоторое поддерево в этом доме.
Я понял что вы подразумевали. А теперь прочитайте и вы то что я пишу.
PS Чтобы было понятнее о чем я пишу: посмотрите вот этот код (https://codesandbox.io/s/1o9vm152nj) и скажите, как вы планируете сделать что-то аналогичное без виртуального DOM:
class App extends React.Component {
componentDidMount() {
setInterval(() => this.forceUpdate(), 1000);
}
render() {
return (
<React.Fragment>
<div>Current time: {new Date().toLocaleString()}</div>
<input />
</React.Fragment>
);
}
}Текущая версия не сбрасывает введенный пользователем текст внутри input каждую секунду.
PS Чтобы было понятнее о чем я пишу: посмотрите вот этот код (https://codesandbox.io/s/1o9vm152nj) и скажите, как вы планируете сделать что-то аналогичное без виртуального DOM:
Есть компонент input, у него есть внутреннее состояние, при ререндеринге компонент не пересоздается, с-но состояние не меняется.
input — не компонент, input — это элемент DOM. Он должен пересоздаваться при каждом рендере просто чтобы реакт остался реактом, а нее превратился во что-то непохожее.
input — не компонент, input — это элемент DOM.
Вам же никто не мешает враппер использовать.
Он должен пересоздаваться при каждом рендере просто чтобы реакт остался реактом
Но реакт же его не пересоздает. И остается реактом.
Вам же никто не мешает враппер использовать.
Варианта два.
- в методе render создается элемент DOM;
- в методе render создается враппер/ссылка/что-то ещё, которая дальше станет элементом DOM.
В первом случае вы не сможете сохранить одновременно поведение реакта и его внешний вид.
Во втором случае вы переизобретаете виртуальный DOM.
Но реакт же его не пересоздает. И остается реактом.
Но реакт использует виртуальный DOM.
Возвращает кусок дома, описанный на jsx. Ну или прямыми вызовами.
Это уже будет не Реакт. От слова "Вообще".
Каких именно проблем?
Проблем лишних вычислений в рантайме. В случае с реакт, компиляция Svelte заменяет vdom, а это довольно большя рантайм абстракция.
ractive — это, опять же, как и svelte чистый рендерер. Там в общем-то ничего нет.
Это как-то не очень конкретно. Вы говорили про 90%, то есть Ractive имеет всего 10% ангуляра, как я понял, так? В связи с тем, мне бы хотелось немного конкретики. Ну например, какие 90% задач я не могу решать на Ractive, но могу на Ангуляр.
Окей, окей, не весь кор кладете к каждому компоненту, а то что нужно. Или все собирается в отдельный бандл.
То что вы называете «core» вообще не кладется каждому компоненту. Ему кладется только код, специфический для него, тот который был написал разработчиком или сгенерирован во время компиляции. Общие хелперы в компоненты не суются.
Какая разница-то?
Разница в размере) В десятки раз)
Без этих шагов он просто перерендерит весь дом, вот и все.
Вот именно. А в моей фразе было ключевое условие точечное изменение в реальный DOM . Только не спрашивайте зачем))
В реакте нет cd и vdom нужен только для оптимизации. Семантически реакт просто перерендеривает дом.
vdom — это и есть cd для реакта. тыщу раз уже обсуждали.
Ну в одной компоненте их конечно парочка, но на практике их тысячи.
Кого тысячи? Компонентов? Условий? Пусть даже у нас сотни компонентов и тысячи таких вот простых и строгих условий и что? Или вы подразумеваете что все изменения стейта связаны сразу со всеми этими компонентами? Ерунда это)) А проверка даже сотни строгих условия за одно изменение стейта, большая часть которых просто не сработает, это весьма дешевая операция.
Сравним как именно?
Да легко. Напишем какой-то простенький компонент. Я на Svelte, вы на Angular. Я вам опишу точные шаги, которые происходят от момент изменения стейта, до апдейта DOM. Вы тоже самое распишете. И сравним)
Так можно и в рантайме все скомпилировать и будет точно так же.
Можно? Так покажите как! Какой код при этом будет сгенерирован. Какие именно операции будут выполняться для конкретно задачи и все такое.
Ну столько же и будет. Точно так же, что реакт, что ангуляр сравнят старое и новое значение и обновят соответствующую дом-ноду (сам процесс апдейта, конечно, немного по-разному будет проходит, но это несущественно).
А по-вашему что там происходить будет?
Меньше слов больше дела! Далеко ходить за примером не будем:
<h1>Hello {name}!</h1>
<input bind:value={name}>
<button on:click={e => count++}>
Clicks {count}
</button>
<script>
let name = 'world',
count = 0;
</script>
REPL
p/s на ангуляр наверное как-то так будет:
import { Component } from "@angular/core";
@Component({
selector: "app-root",
template: `
<h1>Hello {{ name }}!</h1>
<input [(value)]="name">
<button (click)="increment()">
Clicks {{ count }}
</button>
`
})
export class AppComponent {
name = "world";
count = 0;
increment() {
this.count++;
}
}
Поправьте, если что-то не верно написал.
Проблем лишних вычислений в рантайме. В случае с реакт, компиляция Svelte заменяет vdom, а это довольно большя рантайм абстракция.
Она не заменяет вдом, у свелте совершенно иная логика апдейта.
В связи с тем, мне бы хотелось немного конкретики.
Ну вы серьезно? Можно же просто взять спеку ангуляра и идти по порядку, все вычеркивая. Ractive — это, по сути, аналог angular/core. Вот практически всего, что за пределами angular/core (и часть самого angular/core в виде модульной системы и DI) там нету (за исключением, быть может, отдельных редких элементов).
Ну например, какие 90% задач я не могу решать на Ractive, но могу на Ангуляр.
Все задачи так-то можно решить на ассемблере.
vdom — это и есть cd для реакта. тыщу раз уже обсуждали.
Это механически cd, с точки зрения реализации, но не с точки зрения семантики. Когда говорят о cd то подразумевают обычно, что это cd делается с той целью, чтобы найти, что изменить (для тех самых точечных апдейтов) — так это в свелте, так это в ангуляре и еще много где. Без cd эти фреймворки просто не работают — ничего обновлять без него не будет.
В случае реакта ситуация принципиально иная — реакт будет работать и без cd, просто медленнее. cd там нужен не для того, чтобы найти, что изменять, а для того, чтобы найти, что не изменять, скажем так :)
p/s на ангуляр наверное как-то так будет:
Ну типа того, хотя синтаксис template statement допускает присваивания, так что можно 1в1 как в svelte:
import { Component } from "@angular/core";
@Component({
selector: "app-root",
template: `
<h1>Hello {{ name }}!</h1>
<input [(value)]="name">
<button (click)="count = count + 1">
Clicks {{ count }}
</button>
`
})
export class AppComponent {
name = "world";
count = 0;
}Она не заменяет вдом, у свелте совершенно иная логика апдейта.
vdom нужен вовсе не для апдейта. сами апдейты идут всегда через dom api. vdom нужен чтобы понять какая часть dom требует апдейта на то или иное изменение стейта. в этом смысле компиляция решает те же задачи, что и rerender+reconcile.
Ну вы серьезно?
Конечно. Это же вы откуда-то взяли цифру 90% и утвердлаете ее. Я лишь люблю точность.
Можно же просто взять спеку ангуляра и идти по порядку, все вычеркивая. Ractive — это, по сути, аналог angular/core. Вот практически всего, что за пределами angular/core (и часть самого angular/core в виде модульной системы и DI) там нету (за исключением, быть может, отдельных редких элементов).
DI много где нет, также как и модулей/неймспейсов и что? Вопрос ведь нужны ли они, если задачи можно решить и без них.
Все задачи так-то можно решить на ассемблере.
Только в сравнении Ractive vs Angular, ассемблер скорее второй. Вы вкурсе что ни в моем, ни в вашем примере 2way биндинг не работает? И нужно еще постараться, чтобы его завести. Пару-тройку модулей подключить, несколько деклараций, чтобы завести гребанный биндинг. Хотите покажу это же пример на Ractive:
const App = Ractive.extend({
template: `
<h1>Hello {{ name }}!</h1>
<input value="{{ name }}">
<button on-click="@.add('count')">
Clicks {{ count }}
</button>
`,
data() {
return {
name: 'world',
count: 0
};
}
});
Вот и все. Пример будет сразу просто работать. Без необходимости танцев и бубнов. Рабочий пример.
Это механически cd, с точки зрения реализации, но не с точки зрения семантики. Когда говорят о cd то подразумевают обычно, что это cd делается с той целью, чтобы найти, что изменить (для тех самых точечных апдейтов) — так это в свелте, так это в ангуляре и еще много где. Без cd эти фреймворки просто не работают — ничего обновлять без него не будет.
Опять вы за свое — много воды, мало смыслов.
В случае реакта ситуация принципиально иная — реакт будет работать и без cd, просто медленнее. cd там нужен не для того, чтобы найти, что изменять, а для того, чтобы найти, что не изменять, скажем так :)
В Svelte говорите ничего не будет обновляться если убрать cd? Как это?:
// было
if (changed.count) {
if (t1.data !== ctx.count) t1.data = ctx.count;
}
// стало
t1.data = ctx.count;
Убираем все проверки, получаем тот же поведение что и у Реакт без vdom, то есть ререндер всего на каждый пчих.
Ну типа того, хотя синтаксис template statement допускает присваивания, так что можно 1в1 как в svelte:
Не знал, интересно, хотя конечно не 1в1 как в Svelte:
// так
<button (click)="count+=1">
Clicks {{ count }}
</button>
// или так
<button (click)="count++">
Clicks {{ count }}
</button>
В обоих случаях получаем Template parse errors. Так что не льстите ангуляру слишком сильно ;-)
Так почему же 2way биндинг не работает в примере? И когда вы расскажете какие именно операции производит ангуляр при работе с этим примером?
Как мы сделаем то же самое в React? Скорее всего, это будет выглядеть примерно так:
Автор, а функции отдельно вы написали специально для того, чтоб символов побольше напечатать? Люблю такие бессмысленные и беспощадные специальные олимпиады.
Попробуйте убрать эти ваши обработчики в стрелочные функции прямо по месту применения, ваш вырожденный пример от этого никак не ухудшится.
Вот стрелочные функции "по месту применения" в Реакте лучше никогда не писать, поскольку они ломают все оптимизации. Там, по-хорошему, надо useCallback со стрелочной функцией использовать, чтобы обработчик события при каждом рендере не переподписывался:
const handleChangeA = useCallback(event => setA(+event.target.value));Не сильно меньше кода получилось.
Во-вторых,
лучше никогда не писать, поскольку они ломают все оптимизации
не обязательно. Зависит от того, что, где, и в каком контексте вы написали. «Ломают все оптимизации» — это очень громкое и очень неправильное обобщение.
Вам по этому поводу уже выше всё хорошо расписали — это далеко не самый приятный подход.
Хм, если бы мне что-то хорошо расписали, я бы заметил… Можете уточнить что именно?
Неочевидное плохо практически всегда, разве что иногда можно с ним мириться, если неочевидное даёт другие существенные плюсы
Если бы я еще понимал о чем вы тут говорите. Я вам вроде бы про использование хендлеров по месту vs их определению в коде, писал. Где же тут неочевидное поведение?
Я вам вроде бы про использование хендлеров по месту vs их определению в коде, писал.
Да?
но и потому что там идет приведение строки к числу. В разметке JSX это будет смотреться просто ужасающе.
Я в вашем посте читаю «там надо приводить и в шаблон это впихивать неочень, а вот у нас не надо приводить, всё сделано без вас».
Да?
Да.
Я в вашем посте читаю «там надо приводить и в шаблон это впихивать неочень, а вот у нас не надо приводить, всё сделано без вас».
Извините, но я никак не могу повлиять на те смыслы, которые вы сами вкладываете в читаемое. Вы написали:
Автор, а функции отдельно вы написали специально для того, чтоб символов побольше напечатать?
Я вам ответил, что так написано не только потому, что:
это более читаемо, но и потому что там идет приведение строки к числу.
Вы написали:
Попробуйте убрать эти ваши обработчики в стрелочные функции прямо по месту применения, ваш вырожденный пример от этого никак не ухудшится.
Я вам ответил, что пример это явно ухудшит, так как:
В разметке JSX это будет смотреться просто ужасающе. Никто в своем уме так не пишет.
Кроме того, даже если вы напишете вызову по месту, это никак не скажется положительно на примере реакта:
import React, { useState } from 'react';
export default () => {
const [a, setA] = useState(1);
const [b, setB] = useState(2);
return (
<>
<input type="number" value={a} onChange={e => setA(+e.target.value)}/>
<input type="number" value={b} onChange={e => setB(+e.target.value)}/>
<p>{a} + {b} = {a + b}</p>
</>
);
};
Обратите внимание, я даже фрагмент использую, чтобы уменьшить код. Стало сильно лучше? Не особо)))
Даже если на Svelte вообще не использовать биндинг, все равно короче выйдет:
<script>
let a = 1,
b = 2;
</script>
<input type="number" value={a} on:input={e => a = +e.target.value}>
<input type="number" value={b} on:input={e => b = +e.target.value}>
<p>{a} + {b} = {a + b}</p>
Не говоря уже о самом принципе работы, когда на любое изменение любого поля в Реакт будет заново вызваны все useState, далее будет полный rerender + reconcile всего компонента, просто чтобы поменять пару нод. Чтож поделать, у реакта просто дизайн такой. Нравится так писать? Никто вас не заставляет писать по-другому, но и врать себе не надо. Это действительно совершенно разный DX.
Обратите внимание, я даже фрагмент использую, чтобы уменьшить код. Стало сильно лучше? Не особо)))
Стало ложным следующее утверждение из статьи:
Иначе говоря, требуется 442 символа в React и 263 символа в Vue, чтобы достичь чего-то, что в Svelte занимает 145 символов. Версия React буквально в три раза больше!
Опачки, уже не в три раза и даже не в два, а на полтора десятка букв длиннее Vue.
Мой начальный комментарий — именно о том, что если уж вы пытаетесь натянуть вырожденный пример на достоинство фреймворка, то делать это нужно честно. На мой опыт чтения «хайповых» статей (на хабре и за пределами) — так не делает почти никто. Статья про хайп технологии Х? Будем сравнивать вылизанный код Х с кривоватым кодом Y, и сделаем вид, что всё нормально. Тут — то же самое. Если уж сравниваете количество значащих букв (хотя метрика на редкость, простите мой французский, дебильная) — то делайте это честно.
Нравится так писать?
Я так не пишу. И вообще никогда в жизни не полезу защищать реактовский стейт, он очень примитивный. Но, к счастью, можно пользоваться реально хорошими частями реакта (шаблонами и рендером) и не пользоваться стейтом. Никто не заставляет.
Никто вас не заставляет писать по-другому, но и врать себе не надо.
Врать в статьях тоже не надо. Но вот поди ж ты.
Стало ложным следующее утверждение из статьи:
Почему ложным? Автор статьи привел идеоматические примеры для React/Vue/Svelte и посчитал букавы. Вы же начали разговор со своих предпочтений. Считаете что на React или Vue примеры могут быть короче и написаны специально, чтобы сделать длинее? Я так не считаю. Кроме того на Svelte длинее просто не получается, если только биндинги не использовать, но какие для этого причины? В примере на Vue тоже используется биндинг, а в React его просто нет.
Мой начальный комментарий — именно о том, что если уж вы пытаетесь натянуть вырожденный пример на достоинство фреймворка, то делать это нужно честно.
Пример не мой, но мне кажется что читать надо построчно.
1) Где короче всего завести переменную в стейте с возможностью изменения? Варианты ответов:
a)
let a = 0;
b)
import { useState } from 'react';
...
const [a, setA] = useState(0);
c)
export default {
data() {
return {
a: 1
};
}
};
2) Как короче считать переменную в виде числа из поля для ввода и записать в переменную? Варинты ответов:
a)
<input type="number" bind:value={a}>
b)
<input type="number" value={a} onChange={e => setA(+e.target.value)}/>
c)
<input type="number" v-model.number="a">
3) Обязательный корневой элемент шаблона увеличивает кол-во необходимых букаф? Варинты ответов:
a) Да
b) Нет
И так далее. Мне кажется ответы очевидны. Об чем тогда спор?
На мой опыт чтения «хайповых» статей (на хабре и за пределами) — так не делает почти никто.
Готов принять ваше пари. Пишите код на React/Vue так как вы считаете нужным, а я напишу аналог на Svelte и посчитаем. Ок?
Но, к счастью, можно пользоваться реально хорошими частями реакта (шаблонами и рендером) и не пользоваться стейтом.
Гхарк… извините, пил кофе, поперхнулся и залил им весь стол. Чего там у Реакт хорошо? Шаблоны? Это JSX который? Жвачкой прилепили DSL на основе императивного языка программирования поверх декларативного XML-like языка? Это еще ладно, можно привычнуть. Опять же там Typescript сразу из коробки. Ок. Но рендер? Вы это вообще серьезно? Он же тупо вызывает заново функцию на КАЖДЫЙ пчих, вообще на каждый и заново делает rerender + reconcile всего компонента вообще на любое изменение! Я вообще не представляю о чем думали люди, которые это писали. Основная версия все еще то, что они были из мира PHP, где на любой запрос создается новый тред и все такое.
Чтобы уважаемые реактоводы на меня не обиделись, опишу что действительно хорошо у Реакта:
1) Facebook + community + tooling
2) Действительно много готовых компонентов и не только компонентов
3) Действительно много работы с хорошими зп
4) React Native
Готов принять ваше пари. Пишите код на React/Vue так как вы считаете нужным, а я напишу аналог на Svelte и посчитаем. Ок?
Так вы ж уже написали выше. И я даже посчитал. Длиннее вышло? Ну да. Но, в общем, не в разы.
Шаблоны? Это JSX который? Жвачкой прилепили DSL на основе императивного языка программирования поверх декларативного XML-like языка?
Вы где-то в мире фронтэнда видели шаблоны лучше? Я — нет. Как не пытайся совмещать декларативщину с императивщиной, а какие-то минусы будут всегда. Намазывать неродную декларативщину поверх html чтоб что-то там сделать, как делает тот же ангуляр (да и вообще это очень древний подход, куда древнее нынешнего хипстерского фронтэнда) — тоже мягко говоря такое себе, в декларативщину не всё удобно влезает, и монструозные конструкции всё равно появляются. А уж как приятно что-то динамическое там генерить (нет), ммм!
Он же тупо вызывает заново функцию на КАЖДЫЙ пчих, вообще на каждый и заново делает rerender + reconcile всего компонента вообще на любое изменение!
… и именно потому, что он очень тупой и простой — это позволяет надстраивать его сторонним стейт менеджментом с интересным и фичеобильным изкоробочным поведением. И не надо вылавливать проблемы того, что сторонний стейт менеджмент что-то там наоптимизирует, а потом еще и рендер что-нибудь наоптимизирует и в итоге код превратится в тыкву.
«Просто и тупо» — это не всегда плохо, а только иногда.
Так вы ж уже написали выше. И я даже посчитал. Длиннее вышло? Ну да. Но, в общем, не в разы.
То есть вы даже попробовать не хотите? Не в разы, но код копиться. Плюс я описал далеко не все моменты, скобки, и тп. Именно тот бойлерплейт, который так противно писать, а главное не понятно зачем, если можно не писать? Поэтому считаю цифры из статьи вполне себе обоснованными. Думаете иначе, с вас пример и будем считать вместе.
Вы где-то в мире фронтэнда видели шаблоны лучше? Я — нет. Как не пытайся совмещать декларативщину с императивщиной, а какие-то минусы будут всегда.
Любой настоящий DSL, а знаете почему? Потому что там ключевая фраза «domain specific», то есть можно спроектировать код конкретную доменную область, в данном случае под HTML. Является ли Javascript «domain specific» для HTML? Очевидно нет, это как бы язык общего назначения. Как он вообще может быть лучше чем DSL? Никак.
тоже мягко говоря такое себе, в декларативщину не всё удобно влезает, и монструозные конструкции всё равно появляются
Сравним парочку конструкций?
<div>
{conditionA ? (
<Foo />
) : conditionB ? (
<Bar />
) : (
<Baz />
)}
</div>
}
vs
<div>
{#if conditionA}
<Foo />
{:else if conditionB}
<Bar />
{:else}
<Baz />
{/if}
</div>
Первый пример просто верх простоты, изящества и удобства, а уж какая читаемость. Огонь! Или вот еще:
<ul>
{numbers.map((value) =>
<ListItem key={value.toString()} value={value} />
)}
</ul>
vs
<ul>
{#each numbers as value (value)}
<ListItem {value} />
{/each}
</ul>
Кроме того, что DSL проще читается в потоке HTML, есть и еще один не очевидный плюс — нет никаких вариаций написания этих конструкций. Могут меняться параметры и переменные, но сами конструкции всегда пишутся одинаково. Это в свою очередь позволяет проще «извлекать» их из общего «шума» HTML и ведет к лучшему пониманию теми, кто читает код. JSX же можно написать как хочешь, скобки, пробелы, переносы, все как в голову взбредет. И тут на сцену выходят всякие обязательные линтеры и т.п. Линтеры это конечно хорошо, но это все же показатель несовершенства того, к чему они применяются.
… и именно потому, что он очень тупой и простой — это позволяет надстраивать его сторонним стейт менеджментом с интересным и фичеобильным изкоробочным поведением. И не надо вылавливать проблемы того, что сторонний стейт менеджмент что-то там наоптимизирует, а потом еще и рендер что-нибудь наоптимизирует и в итоге код превратится в тыкву.
«Просто и тупо» — это не всегда плохо, а только иногда.
Это он то простой? По вашему это просто когда на то, чтобы поменять одну букавку в DOM нужно сперва построить копию DOM в памяти, потом пройтись по всем нодам и их аттрибутам и сравнить? Это просто? Нет, во-первых, это не просто, во-вторых, глупо и не опимально. И ребята из реакта знают об этом, именно поэтому и придумали всякие там shoudComponentUpdate/PureComponent/useMemo/useCallback. Они вам как бы говорят, ребята ну тут написали крайне хреновую и тяжелую абстракцию, а вы давайте там уж сами как-то разгребайте если у вас она будет плохо работать.
А вот что делает Svelte, если значение a изменилось:
if (changed.a) input0.value = ctx.a;
if (changed.a) {
set_data(t2, ctx.a);
}
if ((changed.a || changed.b) && t6_value !== (t6_value = ctx.a + ctx.b)) {
set_data(t6, t6_value);
}
Где set_data это обертка над `el.data = text`, а всякие там input0 и t2 — закэшированные ссылки на нужные DOM ноды. И это весь rerender + reconcile который нужен.
Кстати, по поводу сторонних стейт менеджеров. Смотрите фокус:
<script>
import { interval } from 'rxjs';
let count = interval(400);
</script>
<h1>The count is {$count}</h1>
Или вот еще, только на Effector:
<script>
import { createStore, createEvent } from 'effector';
let inc = createEvent('counter ++');
let counter = createStore(0).on(inc, n => n + 1);
</script>
<h1>Count: {$counter}</h1>
<button on:click={inc}>Increment</button>
Именно тот бойлерплейт, который так противно писать, а главное не понятно зачем, если можно не писать? Поэтому считаю цифры из статьи вполне себе обоснованными.
Ну то есть вы сами накатали укороченный реактовый пример, который хоть и не best practices, но в рамках статейного сравнения вполне себе нормальный, и который разбивает утверждение про «реакт длиннее в разы» — и далее всё тот же вы говорите, что в статье всё норм.
Такое себе.
Сравним парочку конструкций?
Они не имеют принципиальных различий. Ну, разве что писать многуровневый тернарник — это в принципе не стоит. Но —
<div>
{() => {
if (conditionA)
return <Foo />;
else if (conditionB)
return <Bar />;
else
return <Baz />;
}()}
</div>уж точно не страшнее варианта svelte. Шелухи вокруг на некоторое количество букв больше, но читается прекрасно. Ну и это plain JS, а не третий набор конструкций для заучивания (впрочем, в JSX html — это не совсем html, так что JSX тут не вырывается вперед один фиг).
А второй пример с map и так читается нормально, там переделывать за вами ничего не надо. Вопрос привычки.
Кроме того, что DSL проще читается в потоке HTML
Подождите-подождите, вы всерьез считаете, что в svelte вы пишете чистый HTML с вкраплениями конструкций её DSL? Но это очевидно не так — HTML в svelte — это тоже «не совсем HTML», и вы точно так же останетесь с формально валидным, но не работающим HTML, если попробуете предварительно заменить все DSL-вставки на их вычисленный результат. Все эти bind: on:, и так далее в любом случае без svelte становятся тыквой, как без реакта становится тыквой className. Принципиальных различий с JSХ тут нет.
И ребята из реакта знают об этом, именно поэтому и придумали всякие там shoudComponentUpdate/PureComponent/useMemo/useCallback.
Это не рендер, это state management. Всё, что вы тут написали. Как я уже сказал, state management в реакте настолько примитивный, что постоянно надо закатывать солнце руками — отсюда и этот список. Рендеру же и не надо быть сложным.
Кстати, по поводу сторонних стейт менеджеров. Смотрите фокус
Это не фокус. RP в разных парадигмах очень легко переходит друг в друга (паттерн-то один и тот же), а так же в не-RP код и обратно. Это не достоинство svelte, это просто признак нормального RP.
Ну то есть вы сами накатали укороченный реактовый пример, который хоть и не best practices, но в рамках статейного сравнения вполне себе нормальный, и который разбивает утверждение про «реакт длиннее в разы» — и далее всё тот же вы говорите, что в статье всё норм.
Такое себе.
Во-первых, это не идеоматический пример Реакт, против идеоматического на Svelte, то есть мы уже с вами подкручиваем Реакт, только бы он хоть чуточку догонял. Во-вторых, пример на Svelte реально короче. В-третьих, перечитайте еще раз что действительно написано в статье:
Такая сильная разница скорее исключение — из моего опыта, компонент React обычно примерно на 40% больше, чем его эквивалент на Svelte.
Итак, этот компонент на React примерно на 40% больше чем на Svelte? Думаю похоже на правду.
Я ж вроде про конкретные примеры спросил.
Легко: github.com/htmlx-org/HTMLx
«Любой настоящий DSL» конечно будет лучше. В рамках своего D, вот в чем загвоздка. А вне рамок — вообще не в тему.
А зачем нам шаблонизатор HTML вне рамок HTML? Вы меня прям смутили)))
Они не имеют принципиальных различий. Ну, разве что писать многуровневый тернарник — это в принципе не стоит. Но —
Они имеют очень даже принципиальные различия. И вы своим примером лишь доказали сразу 2 вещи: 1) излишняя свобода в написании управляющих конструкция поверх html — это плохо; 2) JSX — это ни разу не JS, лишь его подмножество. Если бы это было не так, вам не пришлось бы изгоняться с дополнительной анонимной функцией, чтобы написать обычный if-else.
А второй пример с map и так читается нормально, там переделывать за вами ничего не надо. Вопрос привычки.
А я может хочу for или while использовать. Тоже в анонимную функцию оборачивать? )))
Подождите-подождите, вы всерьез считаете, что в svelte вы пишете чистый HTML с вкраплениями конструкций её DSL? Но это очевидно не так — HTML в svelte — это тоже «не совсем HTML», и вы точно так же останетесь с формально валидным, но не работающим HTML, если попробуете предварительно заменить все DSL-вставки на их вычисленный результат. Принципиальных различий с JSХ тут нет.
Во-первых, он валидный, а значит никаких сюрпризов для тех, кто уже знает HTML. Во-вторых, этот HTML без проблем отрисует даже браузер, просто все DSL конструкции он примет на TextNode. JSX же даже синтаксически не является ни валидным HTML, ни валидным JS. Эдакий чудоудюрыбакит. Начинаешь писать JS, опс, оказывается не всякую конструкцию из JS можно использовать. Начинаешь писать HTML, опять нет.
Это не рендер, это state management. Всё, что вы тут написали. Как я уже сказал, state management в реакте настолько примитивный, что постоянно надо закатывать солнце руками — отсюда и этот список. Рендеру же и не надо быть сложным.
Не понимаю как вы разделяете рендер и стейт менеджмент при state-driven подходе. И все же это рендер тупой и тормозной, потому что он даже понятия не имеет какие данные стейта используются для рендера, а какие нет. И еще раз прочитайте вот эту часть, тут чисто про рендер:
Это он то простой? По вашему это просто когда на то, чтобы поменять одну букавку в DOM нужно сперва построить копию DOM в памяти, потом пройтись по всем нодам и их аттрибутам и сравнить? Это просто? Нет, во-первых, это не просто, во-вторых, глупо и не опимально.
Это не фокус. RP в разных парадигмах очень легко переходит друг в друга (паттерн-то один и тот же), а так же в не-RP код и обратно. Это не достоинство svelte, это просто признак нормального RP.
Раз это не фокус, а давайте вы тоже самое на React напишете и мы с вами сравним код, а?
Итак, этот компонент на React примерно на 40% больше чем на Svelte? Думаю похоже на правду.
А я с этим и не спорил. Я спорил с «в разы». «Такая сильная разница» в статье взялась не потому, что иногда реакт в разы длиннее, а потому, что автор статьи пример на реакте написал избыточно длинно, только и всего.
И вы своим примером лишь доказали сразу 2 вещи: 1) излишняя свобода в написании управляющих конструкция поверх html — это плохо; 2) JSX — это ни разу не JS, лишь его подмножество. Если бы это было не так, вам не пришлось бы изгоняться с дополнительной анонимной функцией, чтобы написать обычный if-else.
1 — да нет, нормально.
2 — а где-то утверждалось обратное? Вы спорите со своими собственными фантазиями о JSX?
А я может хочу for или while использовать. Тоже в анонимную функцию оборачивать? )))
Конечно. И ничего страшного в этом нет. У вас глаз за лишнюю пару скобок цепляется настолько сильно, что прям жизни нет?
Во-первых, он валидный, а значит никаких сюрпризов для тех, кто уже знает HTML.
И хоть сколько-нибудь значимым достоинством это не является. «Знающий HTML» напишет onclick=, а потом будет удивляться, что у него там прекрасностей svelte не добавляется.
Во-вторых, этот HTML без проблем отрисует даже браузер, просто все DSL конструкции он примет на TextNode.
И ценности в этом нет никакой, потому что на выходе будет всего лишь честно отрисованная в браузере тыква.
Начинаешь писать JS, опс, оказывается не всякую конструкцию из JS можно использовать. Начинаешь писать HTML, опять нет.
Всякую, но не напрямую. С HTML — то же самое, что и в svelte. Хочешь реакта? Будь добр писать именно так, как ожидает от тебя реакт, а иначе весь реакт пройдет мимо. Что class нельзя написать — и вовсе забавный факт несовпадения окружения, то же самое, что и то, что вы стили в JS пишете кэмелкейсом, а не через -.
Раз это не фокус, а давайте вы тоже самое на React напишете
В реакте нет RP из коробки, что я вам напишу? Там весь код будет про то, как подружить RP с setState/useState. Ничего интересного. Какой-нибудь MobX со своим изкоробочным решением для реакта сделает это за вас.
Не понимаю как вы разделяете рендер и стейт менеджмент при state-driven подходе.
Очень просто: надо ли мне что-то из вашего списка, если я не использую setState/useState (в угоду каким-то сторонним решениям, которые сделают это за меня максимально корректным и минимальным образом)? Нет, не надо. Будут ли у меня отрисованы компоненты? Да, будут.
И еще раз прочитайте вот эту часть, тут чисто про рендер:
«Эта часть» меня вообще никак не волнует, пока мой код проходит по памяти и скорости (а у меня есть очень-очень большой и сложный код на реакте+mobx, который всё отлично проходит). Как известно из других статей о svelte — быстродействием против хорошо написанного реакта она не поражает. Память мерить куда сложнее, но, опять же, пример не лабораторного, а реального сложного кода мне говорит о том, что весь этот «страшно неэффективный» процесс рендера реакта не так уж память и жрет, чтоб это было заметно на практике даже в сложных по памяти условиях.
А я с этим и не спорил. Я спорил с «в разы».
Автор потом отдельно отметил, что это скорее исключение, а обычно это порядка +40%. Не нужно быть таким чувствительным.
«Такая сильная разница» в статье взялась не потому, что иногда реакт в разы длиннее, а потому, что автор статьи пример на реакте написал избыточно длинно, только и всего.
Не избыточно, а идеоматически. В этом смысле все примеры написаны одинаково так, как их советуют писать в учебниках/доках/докладах. Svelte отличается лишь тем, что длинее писать смысла нет.)))
1 — да нет, нормально.
2 — а где-то утверждалось обратное? Вы спорите со своими собственными фантазиями о JSX?
1) это плохо, почему я описал. почему это нормально по-вашему, я так и не понял. Мой поинт очень прост — читать DSL в потоке HTML вообще задача не плостая, не надо ее усложнять вариативностью данных конструкций.
2) Все пишут что JSX — «это просто JS», но это заблуждение. Это subset на основе JS синтаксиса, тот же DSL только не очень то подходящий доменному языку.
И хоть сколько-нибудь значимым достоинством это не является. «Знающий HTML» напишет onclick=, а потом будет удивляться, что у него там прекрасностей svelte не добавляется.
Так пусть напишет))) И значете что произойдет? Все будет работать так, как он привык в HTML: svelte.dev/repl/472f3af895ae4accb75dace2b872099e?version=3.3.0
Конечно же разработчик не настолько глуп, чтобы ожидать что стейт Svelte будет доступен в стандартном обработчике HTML, но все остальное может работать там как обычно и без ошибок. Так что да, Svelte — это валидный HTML/CSS/JS. Магия))
И ценности в этом нет никакой, потому что на выходе будет всего лишь честно отрисованная в браузере тыква.
О, ценность огромная. Например, у нас программисты и верстальщики — это разные люди. Представяете насколько проще верстальщику заверстать компонент на HTML/CSS как он привык, без необхомости заучивать подводные камни JSX? Вместо шаблонизатора он испльзует статические тексты, поэтому даже сборку ему настраивать ненадо. А когда он его заверстал, он просто передает файлик разработчику, и тот лишь дописывает его. Не портирует из HTML/CSS в JSX/CSS-in-JS, а просто дописывает. Это нереально удобно и реально экономит время и силы.
Всякую, но не напрямую. С HTML — то же самое, что и в svelte. Хочешь реакта? Будь добр писать именно так, как ожидает от тебя реакт, а иначе весь реакт пройдет мимо.
Пример и все описанное выше надеюсь все же убедит вас, что Svelte — это валидный HTML/CSS/JS без нюансов.
Что class нельзя написать — и вовсе забавный факт несовпадения окружения, то же самое, что и то, что вы стили в JS пишете кэмелкейсом, а не через -
Да уж чего там class. Там и style нельзя писать. И с svg проблемы и еще кучу всего. Давайте просто пойдем от противного:
React:
1) Валидный JS всегда валидный JSX, так? НЕТ
2) Валидный HTML всегда валидный JSX, так? НЕТ
Svelte:
1) Валидный JS всегда валидный Svelte, так? ДА
2) Валидный HTML всегда валидный Svelte, так? ДА
Что и требовалось доказать.
В реакте нет RP из коробки, что я вам напишу? Там весь код будет про то, как подружить RP с setState/useState. Ничего интересного. Какой-нибудь MobX со своим изкоробочным решением для реакта сделает это за вас.
Вы говорили же про использования внешних решений. Я вам привел 2 очень простых примера интеграции Rxjs и Effector в Svelte. Можете просто переписать их на React, чтобы мы ощутили разницу того, как же круто и офигенно реакт позволяет интегрировать сторонние стейт менеджеры по сравнению с убогим Svelte?
Очень просто: надо ли мне что-то из вашего списка, если я не использую setState/useState (в угоду каким-то сторонним решениям, которые сделают это за меня максимально корректным и минимальным образом)? Нет, не надо. Будут ли у меня отрисованы компоненты? Да, будут.
На самом деле проблема знаете в чем. В реакт cd основана на постоянном rerender + reconcile и с внутренним стейтом это работотает ни разу не эффективно. Чтобы это заработало хотя бы адекватно, вы вынуждены прикручивать еще один cd, только снаружи реакта, чтобы тот сам следил какие пропсы надо изменять, а какие ненадо и не пушил реакт на постоянную перерисовку по пустякам. Это конечно наверное очень инновационно держать в рантайме аж 2 cd механизма, но лично мне кажется что это ибыточно, и реакт и принцип работы его vdom тут как раз слабое звено.
«Эта часть» меня вообще никак не волнует, пока мой код проходит по памяти и скорости (а у меня есть очень-очень большой и сложный код на реакте+mobx, который всё отлично проходит)
Ответ на предыдущий комментарий относится и сюда. Нравится крутить реактивностью отдельно — пожалуйста. Мне не понятно почему не использовать уже готовые решения.
Как известно из других статей о svelte — быстродействием против хорошо написанного реакта она не поражает. Память мерить куда сложнее, но, опять же, пример не лабораторного, а реального сложного кода мне говорит о том, что весь этот «страшно неэффективный» процесс рендера реакта не так уж память и жрет, чтоб это было заметно на практике даже в сложных по памяти условиях.
Ну давайте посмотрим. React + Mobx говорите?

Так то вообще огонь конечно. Всего то в 1,5-2,5 раза хуже по всем показателям. Так что все ок, не волнуйтесь, используйте дальше и пусть ваши юзеры будут счастливы ;-)
Ой, реакт фейлит на перестановку строк в таблице способом «в лоб». Это очень нужная операция в боевом коде и я прям очень страдаю от того, что она медленная (нет).
А в остальном разница минимальна. Это именно то, что я имел в виду под «быстродействием против хорошо написанного реакта она не поражает». Потому что реально не поражает.
Ой, реакт заметно хуже стартует. Я пишу для людей, у которых данные грузятся секунду-две в идеальном случае, и они дополнительные 200ms для старта реакта вообще не ощущают даже без этих ваших SSR.
Ой, реакт памяти жрет как минимум в два раза больше, на vdom и вот это всё. Я немедленно расплакался от того, что у меня dom страницы с реактом весит не мегабайт, а два.
Вы сейчас перешли ту самую границу, которая отделяет нормальных людей от людей типа vintage
Во-первых, это грубо. И я тут вынужден заступиться за vintage, который конечно, вероятно, излишне «влюблен» в свое творение, но противопоставлять его «нормальным людям» это уж слишком. Кроме того, как специалист, я уверен, что он в некоторых вещах разбирается лучше нашего с вами. Во-вторых, даже если вы имели ввиду, что я также как и он, излишне ратую за свой любимый фреймворк, то давайте разберемся чуть детальнее:
1) Я пытаюсь вам логически объяснить что rerender-reconcile всего и на каждый пчих — это как минимум не очень эффективно. Вы говорите что это ОК.
2) Я пытаюсь на примерах показать, что на React писать дольше и сложнее многие вещи. Вы говорите что это ОК.
3) Обсуждаем стейт, вы говорите что надо еще сверху крутануть дополнительный стейт-менеджер со своим cd, я говорю нафиг тогда реакт с его cd? Вы говорите что это ОК.
4) Сами же начинаете аппелировать к скорости и другим метрикам, я вам присылаю скриншоты, с официальных источников. Вы не разобравшись все равно говорите что это ОК.
Так кто из нас излишне «влюблен» в свой фреймворк и не хочет посмотреть проблемам в лицо?
Скажите, на что вы рассчитываете, когда постите картинки откуда-то из ангажированных источников без детализации? Вы всерьез думаете, что я не схожу к автору js-framework-benchmark и не посмотрю результаты, которые постит он сам?
А вы всерьез думаете что это картики не из официальной репы js-framework-benchmark? Если вы чуть внимательнее посмотрите на мой и свой скриншот, то возможно разберетесь в чем дело.
Обвинять людей в «подделке» и «подставновках» не попытавшись разобраться — это низко. Фу быть таким.
Ой, реакт фейлит на перестановку строк в таблице способом «в лоб». Это очень нужная операция в боевом коде и я прям очень страдаю от того, что она медленная (нет).
Ну раз уж вы так хотите разобраться детальнее… Я кстати не собирался, потому что считаю все эти бенчмарки несущественными. Напоминаю, это вы решили пойти в эту сторону. Еще раз полный и корректный скриншот для React и Svelte:
Выделим самые яркие моменты. В среднем в 1.5 раза медленнее, 2.5 раза медленнее select rows и почти в 8 раз медленнее swap rows, но вы правы это мелочь. Поэтому берем именно slowdown geometric mean, то есть примерно в 1.5 раза медленнее Svelte. Вы писали:
Как известно из других статей о svelte — быстродействием против хорошо написанного реакта она не поражает.
Ну наверное да, ускорение в 1.5 раза вашим проектам не нужно. Особенно радует фраза «против хорошо написанного реакта». Тем самым вы как бы признаете, что «помнить» как именно работает реакт все же приходится больше.
Ой, реакт заметно хуже стартует. Я пишу для людей, у которых данные грузятся секунду-две в идеальном случае, и они дополнительные 200ms для старта реакта вообще не ощущают даже без этих ваших SSR.
Svelte — это ванилла JS, поэтому стартует он ровно также, а если уж доверять этим сравнениям то даже быстрее)))
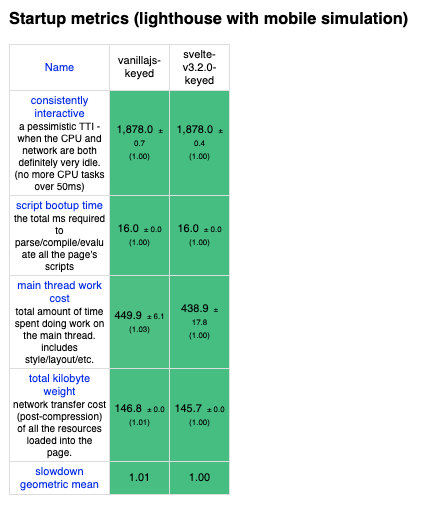
Вам это не нужно? Нет проблем) Но это то, что «можно померить» и реакт тут аж в 2 раза медленнее:
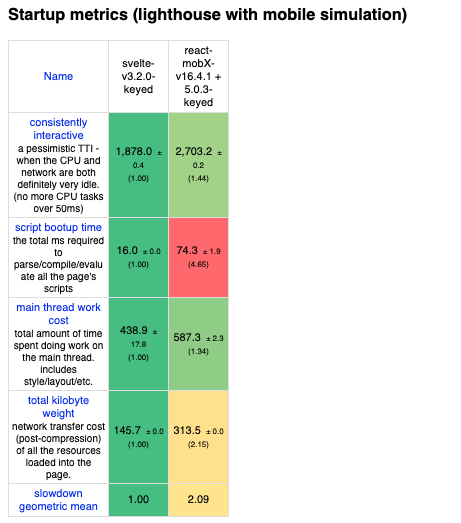
Может у вас там кейсы конечно такие, но «наши там SSR» созданы для того, чтобы улучшить FMP и SEO. Возможно вы рассчитываете, что гугл умный, гугл умеет js. А вы в курсе, что гугл умеет js ровно настолько, насколько ваш js быстро стартует? Ну и пофиг, вы же админки одни пишете.
Ой, реакт памяти жрет как минимум в два раза больше, на vdom и вот это всё. Я немедленно расплакался от того, что у меня dom страницы с реактом весит не мегабайт, а два.
Точно, всего то надо на каждый пчих построить 2 версии одного итого же vdom дерева и потом последовательнос сравнить все ноды и их аттрибуты. И все это в памяти. Вы свои сайты небось на Macbook Pro тестируете только?
Ладно, это все лирика, смотрим цифры:
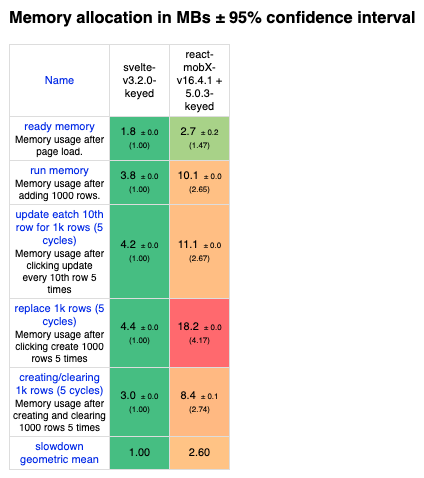
OMG, в 2.5 раза! Действительно, какая это все же «эффективная и дешевая» операция получается. Смотрите, а вот Vue всего в 1.5 раза, а почему? У него же тоже vdom и все такое. Может потому что у него настоящая реактивность под катотом? И не та, что сбоку на жвачке, как Mobx, с двойным cd, а настоящая:

Да и по другим показателям он в среднем в 1.3-1.5 раза лишь отстает. Видимо не сам концепт vdom плох, а прежде всего его реализация в react?
Знаю вам на все это пофиг. Реакт лучший и хоть тресни))
Память мерить куда сложнее, но, опять же, пример не лабораторного, а реального сложного кода мне говорит о том, что весь этот «страшно неэффективный» процесс рендера реакта не так уж память и жрет, чтоб это было заметно на практике даже в сложных по памяти условиях.
Это верно, все зависит от задач. Наши задачи говорят что Реакт работает так себе, ваши говорят что он прекрасен. Однако если так логически рассудить, если принять общее кол-во устройств в мире за 100%, то очевидно что топовых устройств с «пофиг на память» и «пусть зрузится как хочет» в разы меньше, чем устройств средней комплектации и дешевых моделей. Те же ТВ, думаете мы бы не хотели писать только под premium модели за 150К? С ними реально проблем меньше. Но, мир так устроен, что в домах подавляющего большинства юзеров стоят модели за 30-40К, телефона за 5-10К и так далее. Сколькие из них ваши юзеры? Неизвестно, но очевидно многие. Должны ли инструменты разработчика «насиловать» их дешевые устройства, только потому что вас это все «вообще никак не волнует»? Не думаю.
Противопоставляя «нормальных людей» и «ненормальных людей» — я имел в виду прежде всего то, что вы уже который пост очень слабо интересуетесь словами собеседника, вместо этого волнуясь только бы о том как победить. Мне очень не нравится, когда вместо беседы двух людей на меня клеят ярлычок «react» и занимаются исключительно вопросами разгрома.
vintage очень часто переходит именно на такой способ написания комментариев, поэтому и был приведен в пример.
Если сказать более конкретно, то последней каплей тут стало то, что на мою фразу о производительности вы притащили картинки сравнения всего — от производительности до startup time и до потребления памяти. Нравится вам громить реакт — да ради бога, но я вам позировать в роли соломенного чучела тут не собираюсь.
я имел в виду прежде всего то, что вы уже который пост очень слабо интересуетесь словами собеседника, вместо этого волнуясь только бы о том как победить.
В отличии от вас, я не игнорирую ваши реплики и скрупулезно отвечаю на все из них. Отсюда делаю вывод, что меня слова собеседника как раз интересуют. Кроме того, я даже не знал, что мы тут с вами воюем, чтобы ставить целью победу.
Если сказать более конкретно, то последней каплей тут стало то, что на мою фразу о производительности вы притащили картинки сравнения всего — от производительности до startup time и до потребления памяти.
Именно, это ваша фраза была про производительность и бенчмарки. Я лишь привел не пустые слова, мол «реакт такой же быстрый», а конкретные цифры — реакт медленнее в 1.5 раза. По мне так, это много. Напоминаю, что тот же Vue отстает не так сильно.
Мне очень не нравится, когда вместо беседы двух людей на меня клеят ярлычок «react» и занимаются исключительно вопросами разгрома.
Нравится вам громить реакт — да ради бога, но я вам позировать в роли соломенного чучела тут не собираюсь.
Отлично) Может быть вам напомнить, что это вы начали тред в желании «победить» и «разгромить» автора тем, что он видите ли написал не так как вам кажется:
Автор, а функции отдельно вы написали специально для того, чтоб символов побольше напечатать? Люблю такие бессмысленные и беспощадные специальные олимпиады.
Сперва обвинили автора в спекуляциях, а к концу треда начали обвинять и меня в спекуляциях, хотя сами просто смотрели не в последнюю версию ставнения. Приплели сюда зачем-то vintage при том, что он вообще в треде не участвовал. А я при этом хочу вас победить и разгромить? Не пишите чушь и вам не будут апеллировать.
В отличии от вас, я не игнорирую ваши реплики и скрупулезно отвечаю на все из них.
Нет. Вы скурпулезно берете каждую мою реплику и пишете в ответ всё что угодно. «Ответом» это не всегда может считаться, потому что не всегда даже как-то относится к реплике. Именно об этом я и говорю — вы не разговариваете с собеседником, вы громите реакт. Собеседник тут — лишь удобный фасад, создающий видимость диалога.
Я лишь привел не пустые слова, мол «реакт такой же быстрый», а конкретные цифры — реакт медленнее в 1.5 раза.
Вы привели пустую цифру «реакт медленнее в 1.5 раза» в среднем по набору тестов, который вы даже не изволили показать. Но и даже этого вам показалось мало, и вы еще потащили всё остальное, о чем вообще речи не шло. См. пункт выше.
Сперва обвинили автора в cпекуляциях
… потом пришли вы, и даже сами поучаствовали в обосновании того, что у автора спекуляции в конкретных утверждениях. Которые там действительно есть. В конкретных утверждениях. Не во всей статье.
Затем вам не понравилось то, что кто-то обижает ваш фреймворк, и началось долгое общение ни о чем. Чего стоят только несколько комментов, посвященных тому, что я утверждаю, что реакт не в несколько раз больше svelte, а вы возражаете, что реакт всё равно больше svelte. Вам самому-то не смешно?
Нет. Вы скурпулезно берете каждую мою реплику и пишете в ответ всё что угодно. «Ответом» это не всегда может считаться, потому что не всегда даже как-то относится к реплике.
А, давайте, чтобы вы не выглядели как пустозвон, вы в ответе на это сообщение процетируете парочку подобных реплик и их ответов? За одно и расскажете, почему вы считаете, что мой ответ безотносителен к реплике. А то мало ли, может вы опять что-то спутали или не так поняли…
Вы привели пустую цифру «реакт медленнее в 1.5 раза» в среднем по набору тестов, который вы даже не изволили показать.
Изначально не стал их приводить, потому что: 1) не хотел заострять особое внимание; 2) все тесты занимают больше места в комментарии, а я см. п. 1. Да и зачем они все, если сам бенчмарк предлагает результирующее значение slowdown geometric mean? Мне кажется оно обобщает все результаты и созданно именно с целью быстрого сравнения. Завести эту тему и углубиться в нее решили именно вы, а теперь ноете, что я уж тогда и в другие, не менее важные, метрики решил углубиться. Раз вы завели тему про производительность, для вас она важна, а я в таком случае завел тему и про другие метрики, так как считаю их не менее важными.
… потом пришли вы, и даже сами поучаствовали в обосновании того, что у автора спекуляции в конкретных утверждениях. Которые там действительно есть. В конкретных утверждениях. Не во всей статье.
Это не так, потому что я вам четко указал свою точку зрения, на ваши необоснованные претензии, а именно:
Не избыточно, а идеоматически. В этом смысле все примеры написаны одинаково так, как их советуют писать в учебниках/доках/докладах. Svelte отличается лишь тем, что длинее писать смысла нет.)))
Примеры на Svelte написаны именно таким образом, потому что именно так советует писать документация, а не чтобы написать по-меньше. Примеры на React и Vue написаны точно с таким же прицелом — так пишут все, кто пишет код, при этом не пытается искусственно, за счет читаемости, уменьшить кол-во символов. Поэтому я считаю, что все примеры абсолютно адекватно написаны и посчитаны совершенно корректно. А вы лишь пытались, как вы это называете, искусственно «победить» и «разгромить» автора.
Затем вам не понравилось то, что кто-то обижает ваш фреймворк, и началось долгое общение ни о чем. Чего стоят только несколько комментов, посвященных тому, что я утверждаю, что реакт не в несколько раз больше svelte, а вы возражаете, что реакт всё равно больше svelte. Вам самому-то не смешно?
Вы просто статью не читали, дочитали до результатов конкретного примера, обозлились на них и давай в комменты настрачивать. А я вас на эту тему поправил, привел итоговый вывод автора:
Такая сильная разница скорее исключение — из моего опыта, компонент React обычно примерно на 40% больше, чем его эквивалент на Svelte.
Это и есть финальный вывод сравнения кол-ва кода между React и Svelte. С чем вы тут спорите?
vintage очень часто переходит именно на такой способ написания комментариев, поэтому и был приведен в пример.
Можете дать ссылки на примеры таких комментариев, чтобы я почитал и подумал над своим поведением?
The count is {$count}
А почему ошибку тут не выводит, как и в примере ниже?
Сравним парочку конструкций?
Давайте сравним:
content() {
if( conditionA ) return this.Foo()
if( conditionB ) return this.Bar()
return this.Baz()
}number_views() {
return this.numbers().map( value => this.Number_view( value ) )
}В первом примере вы div отделили от логики выбора. В Реакте я тоже так как бы могу, но в итоге получившийся код перестаёт даже отдаленно напоминать итоговый DOM.
Во втором примере всё ещё хуже. Мало того, что код не имеет ничего общего с DOM, так ещё и выглядит куда менее аккуратно чем JSX — а ведь это ещё постараться надо было...
Блин, да даже на jquery у меня понятнее получалось!
В Реакте я тоже так как бы могу, но в итоге получившийся код перестаёт даже отдаленно напоминать итоговый DOM.
Есть у Реакта такой недостаток, да.
Мало того, что код не имеет ничего общего с DOM
Логика в принципе не может иметь ничего общего с DOM, так как DOM — это структура данных, а логика — нет.
выглядит куда менее аккуратно чем JSX
Что такое "аккуратно"?
(да и вообще это очень древний подход, куда древнее нынешнего хипстерского фронтэнда)
Вообще-то, нет. Генерить результат "напрямую", как в реакте — на десятки лет более старый подход, чем темплейты :)
С-но, темплейты и были придуманы как решение проблем, вызванных использованием подхода реакта. Не наоборот :)
это позволяет надстраивать его сторонним стейт менеджментом с интересным и фичеобильным изкоробочным поведением.
Попытки прикрутить $mol_atom2 к Реакту показали, что в процессе этого прикручивания теряются почти все фичи $mol_atom2, а сам Реакт со своим реконцилятором становится при этом пятой ногой. Так что Реакт проще выпилить, чем сделать из него что-то нормальное.
это позволяет надстраивать его сторонним стейт менеджментом с интересным и фичеобильным изкоробочным поведением.
Вот только сама необходимость такого стороннего стейт менеджера и является недостатком.
За весь свой программистский опыт я не видел убедительных случаев, где полный «кухонный комбайн» был бы лучше грамотного сочетания отдельных хороших систем.
Любой десктопный уи-фреймворк или бекенд-фреймворк?
С-но, единственная отрасль где вообще обсуждается вопрос "комбайн вс некомбайн" — это фронтенд. Во всех остальных случаях такого вопроса даже не открывалось, т.к. все достаточно очевидно: комбайн всегда лучше по понятным причинам (нет, не из-за того, что не надо думать над компоновкой, а из-за того, что части системы заведомо нормально работают друг с другом), и если можно использовать комбайн — используют комбайн.
Любой десктопный уи-фреймворк или бекенд-фреймворк?
По части бекенд-фреймворка я с вами спорить не буду, ибо не настолько владею темой, а вот по части десктопных уи-фреймворков — это как раз тот случай, когда и комбайн отстоен, и альтернатив никаких, потому что комбайны, как правило, такие, что не предусматривают подмену каких-либо частей. Писать уи на swing — чистое мучение, например. Просто потому, что swing — то еще говно. В котором «части системы заведомо нормально работают друг с другом», вот только лучше он от этого не становится.
С-но, единственная отрасль где вообще обсуждается вопрос «комбайн вс некомбайн» — это фронтенд.
Нет, вы не в том ключе пишете — единственный период времени, где вообще появились вопросы «комбайн вс некомбайн» — это сейчас. Потому что опенсорс, множество решений, и так далее. И уже не надо писать многомегабайтное «цельное» решение, а можно написать только некоторую часть, особенно если вы хороший интерфейс можете выставить вокруг неё.
Раньше такого вопроса даже не открывалось, потому что решений было мало, а доступ к ним был хуже, и надо было обязательно фигачить нечто комбайновое, чтоб оно вообще кого-то интересовало или чтоб его можно было продать.
Во всех остальных случаях такого вопроса даже не открывалось, т.к. все достаточно очевидно: комбайн всегда лучше по понятным причинам
Ну да, ангуляр всегда лучше «по понятным причинам» (с). А пацаны-то и не знали.
когда и комбайн отстоен, и альтернатив никаких
А почему альтернатив никаких, вы не думали?
единственный период времени, где вообще появились вопросы «комбайн вс некомбайн» — это сейчас
Это "сейчас фронтенд". Потому что вне фронтенда этот вопрос и сейчас не стоит. И стоять не будет.
И уже не надо писать многомегабайтное «цельное» решение
Ну видите в чем дело, очень мало в каком контексте "многомегабайтность" решения в принципе может вызывать какие-то проблемы.
Ну да, ангуляр всегда лучше «по понятным причинам» (с).
Ну именно так. Если вам нужно сложное приложение, а не очередной твиттер, и у вас нету проблем с "многомегабайтностью" (а их обычно в таком случае нет), то альтернатив ангуляру в 2019 в общем-то и не придумали.
В других случаях будут другие варианты. В каких-то — и тот же сабжевый свелте, например.
А почему альтернатив никаких, вы не думали?
Потому что писать код — сложно, а публичный интересный другим людям код — еще сложнее.
Это «сейчас фронтенд». Потому что вне фронтенда этот вопрос и сейчас не стоит. И стоять не будет.
Посмотрим.
Ну именно так. Если вам нужно сложное приложение, а не очередной твиттер, и у вас нету проблем с «многомегабайтностью» (а их обычно в таком случае нет), то альтернатив ангуляру в 2019 в общем-то и не придумали.
Мне остаётся только повторить «а пацаны-то и не знают». Ну вот реально, мир пишет примерно на чём угодно, Китай — больше на Vue, остальные — больше на реакте, сложность приложения тут вообще никаким боком, потому что пишут что угодно, и тут выходит на сцену Druu, и говорит человечьим голосом: ребята! Вы ничего не понимаете! Альтернатив ангуляру нет! Не беспокоиться может только твиттер!
Если реальность не соответствует вашим воззрениям — тем хуже для реальности, так что ли?
Кстати, если уж вы мне предложили подумать, то и я вам предложу: ангуляр — поделие по большей части гугла. Одни из самых сложных публично доступных приложений в интернете — у гугла. А теперь подумайте, почему они не написаны на ангуляре.
больше на реакте, сложность приложения тут вообще никаким боком
Как раз сложность приложение (и вообще его характер) имеет первостепенное значения при выборе технологий для реализации. А вот Китай у вас или не Китай — как раз не важно совершенно.
Если реальность не соответствует вашим воззрениям — тем хуже для реальности, так что ли?
А она соответствует, вполне. Кровавый интерпрайз пишется на ангуляре, твитторы и прочие несложные вещи — на реакте или том же вуе, ну и всякие свелте и им подобные вещи (либо ванилла жс) там, где тянуть что-то тяжелое нельзя.
публично доступных приложений в интернете — у гугла
Это какое?
А теперь подумайте, почему они не написаны на ангуляре.
А почему не на реакте/вуе или свелте? :))
Потому что легаси и переписывать дорого. А так у них были продукты на том же первом ангуляре. Сейчас есть и на втором, основная часть для внутреннего использования, скорее всего.
Как раз сложность приложение (и вообще его характер) имеет первостепенное значения при выборе технологий для реализации. А вот Китай у вас или не Китай — как раз не важно совершенно.
С точки зрения джуна/мидла — ага.
С точки зрения человека более опытного — огромное значение имеют ответы на вопросы «где мы будем брать людей, знакомых с технологией, и во сколько денег они нам обойдутся», а так же «где мы будем искать пути решения проблем, с которыми мы столкнёмся». Для первого вопроса «Китай или не Китай» внезапно оказывается очень важным. Для второго — в меньшей степени, но тоже важным.
А она соответствует, вполне. Кровавый интерпрайз пишется на ангуляре
Кровавый энтерпрайз пишется на чем попало. У нас, например, половина нового (3 и менее года от начала запиливания proof of concept) энтерпрайза на ангуляре, половина — на реакте. Те, что на ангуляре — очень радуются, потому что у них, например, есть и то, что на angularJS, и они вместо развития сидят и думают, как они это всё переписывать будут. Те, у кого актуальный ангуляр — тоже сидят и думают, как бы им переделать их имеющиеся оптимизации рендера, потому что нынче ivy делает как раз примерно то самое, что у них понаворочено, только лучше. В общем, благодать.
Потому что легаси и переписывать дорого
Угу. И для кровавого энтерпрайза это как раз обычная причина №1 для того, что что-то написано на технологии Х. Не потому, что «лучше», не потому, что «хуже», а потому, что в своё время начали писать именно на Х, а переписывать дорого.
Для первого вопроса «Китай или не Китай» внезапно оказывается очень важным. Для второго — в меньшей степени, но тоже важным.
Внезапно, нет, ни для первого вопроса, ни для второго. Китай — это не село, так что у вас не возникнет проблем с тем, чтобы найти в Китае разработчиков на ангуляр, реакт, да хоть на EmberJs.
Кровавый энтерпрайз пишется на чем попало.
Все пишется "на чем попало", я говорю лишь о бОльшей части.
Угу.
Так и зачем вы спрашивали, если и так прекрасно знаете ответ?
как бы им переделать их имеющиеся оптимизации рендера
Это какие оптимизации рендера?
и они вместо развития сидят и думают, как они это всё переписывать будут
Зачем? angularJs — это другой фреймворк, просто с походим названием. И он до сих пор поддерживается, к слову.
Внезапно, нет, ни для первого вопроса, ни для второго. Китай — это не село, так что у вас не возникнет проблем с тем, чтобы найти в Китае разработчиков на ангуляр, реакт, да хоть на EmberJs.
Разные разработчики встречаются с разной частотой и за разные деньги. Хоть и не деревня. Дело вовсе не в «не найдем», а в «сколько в итоге заплатим». Так-то и индусов можно нанять. И менеджера к ним, который бы заставлял их работать. И менеджера с другой стороны, который бы того менеджера заставлял работать. И так далее. Всё решаемо, вопрос всегда в цене.
Зачем? angularJs — это другой фреймворк, просто с походим названием. И он до сих пор поддерживается, к слову.
Затем, что «Китай или не Китай» имеет значение. В среднем никто не хочет сидеть и тянуть лямку AngularJS. То есть надо либо платить больше, либо искать согласных (и это всё равно в итоге «платить больше»), либо переписывать (что тоже выливается в повышенные расходы, к слову). Такой вот lose-lose-lose.
Это какие оптимизации рендера?
Это переходы с keyed-подхода (элементы в DOM однозначно привязываются ключами к кускам данных) на nonkeyed (элементы в DOM и куски данных могут пересопоставляться) полуавтоматическим способом. C ivy заниматься этим по большей части уже не надо, исключая граничные случаи а-ля «меняем местами строки в огромной таблице»; их код мог бы радикально упроститься при сохранении имеющейся скорости (проверялось), вот только беда — понаписано уже очень много, и рефакторинг там будет мягко говоря не прост.
Дело вовсе не в «не найдем», а в «сколько в итоге заплатим».
А у вас есть какая-то статистика по сравнения отношений средних зп разработчиков вуе/ангуляра в Китае и, например, в США?
Затем, что «Китай или не Китай» имеет значение. В среднем никто не хочет сидеть и тянуть лямку AngularJS.
Так не "в Китае не хочет", а "никто не хочет". Везде :)
Это переходы с keyed-подхода (элементы в DOM однозначно привязываются ключами к кускам данных) на nonkeyed (элементы в DOM и куски данных могут пересопоставляться) полуавтоматическим способом. C ivy заниматься этим по большей части уже не надо
Ангуляр и сейчас ноды не пересоздает, когда не надо, без всяких ключей.
и комбайн отстоен, и альтернатив никаких
А какие альтернативы вы пробовали?
Вот только фокус в том, что комбинация внешнего стейт-менеджера с реактом "грамотным сочетанием" не является.
К примеру, в текущей архитектуре react невозможно избавиться от повторного рендера сразу после монтирования компонента, и этому, так или иначе, подвержены все стейт-менеджеры.
К примеру, в текущей архитектуре react невозможно избавиться от повторного рендера сразу после монтирования компонента
Я вам больше скажу — этого и без стейт менеджеров нельзя добиться, если только у вас компонент не без состояния или не выводит своё состояние синхронно из пропсов.
Это личное дело реакта, что ему надо будет два рендера во всех других случаях.
Ну да, это именно проблема реакта.
Реакт в принципе с нуля всё два раза рендерит. Скорее всего потому, что первый раз в vdom, а второй уже реально. Там и экземпляры компонентов разные, для vdom и не для vdom. Потом, при дальнейших апдейтах, как я понимаю, измененные куски отправляются в vdom напрямую, потому что дальше никаких лишних дёрганий render() нет.
ЗЫ: Или даже нет… проверять это в онлайн-песочнице было плохой идеей. Надо б экспериментировать в чистом браузере. Вообще конечно забавно, что мне пришлось три раза перезагрузить страницу на codesandbox, чтоб у меня ts взлетел должным образом в песочнице.
Фаза "рендерит реально" называется reconcile.
Когда я говорил "рендерит два раза" — я имел в виду именно два вызова render, с фазой reconcile после каждого (но вторая фаза почти всегда холостая).
Когда я говорил «рендерит два раза» — я имел в виду именно два вызова render
Я именно это и полез проверять. На изменения в самом dom я и до этого смотрел, и там ничего интересного. И лишнего.
Но надо чистую песочницу сбацать, проверять это на разных онлайн-песочницах — та еще затея, у них вечно чего-нибудь отпадает, то с TS, то с реактом, то еще с чем-нибудь.
А вы не забыли в методе componentDidMount вызвать setState или forceUpdate?
К примеру, в текущей архитектуре react невозможно избавиться от повторного рендера сразу после монтирования компонента, и этому, так или иначе, подвержены все стейт-менеджеры.
Зачем я буду руками дёргать стейт, если у меня менеджер?
Ну и к слову, всё-таки привёл минимальный пример в рабочее состояние, несмотря на ненужную возню с песочницей: codesandbox.io/embed/n9k74ly1v0
Вы видите там лишние рендеры? Я — нет.
Чтобы проэмулировать то, что должен делать стейт-менеджер. Разумеется, при использовании реального стейт-менеджера этого не требуется.
Любой стейт-менеджер вынужден выбирать между повторным рендером и утечками памяти в Concurrent Mode.
В mobx-react на данный момент заткнули проблему через очистку незакоммиченных реакций по тайм-ауту (магический тайм-аут взят с потолка). Выглядит полным костылем.
Вот ещё интересная ссылка: https://github.com/facebook/react/issues/15317
Где короче всего завести переменную в стейте с возможностью изменения?
a?v 0Это на view.tree.
Как короче считать переменную в виде числа из поля для ввода и записать в переменную?
$mol_number value?v <=> a?vЭто тоже на view.tree. При этом эти два код можно и объединить:
$mol_number value?v <=> a?v 0Обязательный корневой элемент шаблона увеличивает кол-во необходимых букаф?
Как правило общий корневой дом элемент вокруг компонента необходим в целях визуализации. Так что это довольно сомнительное преимущество.
Это на view.tree.
Кошмар какой)
let a = 0;
vs
a?v 0
Хм, дайте-ка подумать… Это действительно сложный выбор, как же лучше завести переменную — с помощью javascript или используя `2 буквы разлененные вопросиком и нолик через пробел`? Даже не знаю…
$mol_number value?v <=> a?v
Кстати, $mol_number — это же компонент, а не html input. А как в treeview использовать html input? Он же умеет html правда? Не умеет? То есть для каждого html тега мне надо будет написать свой компонент, просто чтобы использовать его? Круто! И так инновационно!
Это тоже на view.tree. При этом эти два код можно и объединить:
Вообще огонь! А главное выглядит очень стильно. Не то что этот устаревший html и js. Фу на них!
Как правило общий корневой дом элемент вокруг компонента необходим в целях визуализации. Так что это довольно сомнительное преимущество.
Если вам это нужно, вы всегдя можете сделать один корневой элемент, а если не нужно, можете не делать один. Имхо это в любом случае гибче.
То есть для каждого html тега мне надо будет написать свой компонент, просто чтобы использовать его?
- Не обязательно, можно переопределить свойство dom_name.
- В большинстве случаев не нужен какой-то конкретный хтмл-элемент и вполне подходит дефолтный (по имени компонента).
- А даже когда нужен — всё-равно приходится писать вокруг него обёртку на любом фреймворке. Как минимум, чтобы не писать стили каждый раз заново.
Если вам это нужно, вы всегдя можете сделать один корневой элемент,
Это нужно почти всегда. Редкое исключение — призрачные обёртки. Но тут просто корнем выступает единственный вложенный компонент.
Не обязательно, можно переопределить свойство dom_name.
А точнее? Не хочу специальный компонент для тега input
В большинстве случаев не нужен какой-то конкретный хтмл-элемент и вполне подходит дефолтный (по имени компонента).
Какого компонента? Мне нужен просто тег input со всеми его аттрибутами.
А даже когда нужен — всё-равно приходится писать вокруг него обёртку на любом фреймворке. Как минимум, чтобы не писать стили каждый раз заново.
Стили могут быть и глобальные. Оборачивать каждый HTML тег в компонент, даже если поведение тега никак не меняется — это дурь какая-то.
Это нужно почти всегда. Редкое исключение — призрачные обёртки. Но тут просто корнем выступает единственный вложенный компонент.
Вот вы так думаете, возможно даже на вашей практике так, а я думаю по-другому и моя практика иная. Поэтому не столь категоричный подход Svelte мне и нравится.
А точнее?
$mol_view dom_name \inputНе хочу специальный компонент для тега input
Хотите копипастить одни и те же стили и поведение для каждого инпута?
Какого компонента?
Того, который использовался. В примере выше имя тега по умолчанию будет mol_view.
Мне нужен просто тег input со всеми его аттрибутами.
Вам нужна просто более быстрая лошадь.
Стили могут быть и глобальные.
И могут сломать сторонние виджеты. И будут грузиться, даже если на странице нет ни одного инпута.
Оборачивать каждый HTML тег в компонент, даже если поведение тега никак не меняется
В том-то и дело, что почти всегда меняется.
Никак не взаимодействую со всем этим js-кодингом, поэтому почти вся статья прошла мимо меня. Но вот пример в начале зацепил.
Также я не утверждаю, что уменьшение строк кода — это самоцель, так как это может способствовать превращению нормального читаемого кода, вроде этого…
for (let i = 0; i <= 100; i += 1) { if (i % 2 === 0) { console.log(`${i} — чётное`); } }
… во что-то неудобоваримое:
for (let i = 0; i <= 100; i += 1) if (i % 2 === 0) console.log(${i} — чётное);
Для таких конструкций (по 1 строчке во вложенном блоке) всегда использую второй вариант. Он просто лучше читается и не выглядит простынёй кода, замусоренной пробелами. И при "приёме чужого кода в разработку" одним из первых дел конвертирую эти неудобные простыни в нормальный компактный код.
Но фигурные скобки, переводы строк и отступы вокруг одного statement, прекрасно влезающего в строку, на мой взгляд лишние. И даже иногда вокруг двух (ну тут без фигурных скобок уже не обойтись естественно а вот остальное можно убрать), если второе — передача управления (return, continue, break, goto).
Такой код обычно представляет из себя одну логическую единицу действия, внутрь которой надо смотреть только когда отлаживается конкретно она, и написание её в одну строчку как раз очень хорошо её зрительно «инкапсулирует» при случайном просмотре, но всё же даёт возможность быстро (без кликов и движений мышки) заглянуть внутрь при наличии осознанного на то желания. Если там внутри какой-то сложный алгоритм, то естественно он будет не в одну строчку. А если надо всё-таки в одну — то будет выделен в отдельную функцию.
А вообще я удивлён такой резкой реакцией, раньше такое только на околополитические темы случалось.
Array.from(Array(100).keys())
.filter(i => i % 2 === 0)
.forEach(i => console.log(`${i} — чётное`));
const isEven = i => i % 2 === 0;
const range = num => [ ...Array(num).keys() ];
const log = item => console.log(item);И тогда мы получаем следующее:
range(100)
.filter(isEven)
.map(it => `${i} — чётное`)
.forEach(log);Впрочем, если учесть что едва ли не 9 из 10 разработчиков пишут в таком стиле, неудивительно что всё требует жутко много памяти и работает очень медленно… зато удобно для глаз автора кода (наверное).
Т.е. я не говорю за «все ПО на планете», но вполне бывают ситуации, когда 100500 мелких оптимизаций в ядре дают прирост производительности суммарно в сотню-другую процентов.
Разумеется, если такой фрагмент выполняется один раз или очень редко, это не очень существенно, но речь о том что те кто думает что «так понятнее» делают это везде (и другим советуют), в итоге в более-менее сложном приложении (или при ощутимо большем числе элементов) это накапливается и можем легко получить вместо 0.05 секунды аж целую одну, а это уже существенная задержка.
На самом деле, даже если опустить вопрос эфективности, в данном случае больше удивляет сам ход мыслей разработчика — а именно создание массива для обработки простой последовательности чисел — вас это не смущает?
К тому же, как уже выше заметили, таки остался вопрос о том чем это реально лучше чем цикл по «понятности» — на мой взгляд, цикл как раз более понятен и логичен.
Разумеется, если такой фрагмент выполняется один раз или очень редко
Да пусть он хоть на каждый рендер выполняется. Вы разницы все равно не заметите. Даже если таких фрагментов будет сотня.
На самом деле, даже если опустить вопрос эфективности, в данном случае больше удивляет сам ход мыслей разработчика — а именно создание массива для обработки простой последовательности чисел
А с точки зрения хода мыслей разработчика массива тут не создается.
Разработчик говорит: "из последовательности чисел 1..100 отфильтруй четные и выведи на экран" (и это, согласитесь, проще чем "установи значение переменной в 0, увеличивай на единицу, пока оно не станет больше 100, для каждого значения, если оно четное — выведи его на экран"), а то, что движок не умеет в оптимизацию и создает массив в принципе тут (не говоря уже о промежуточных) — проблема движка.
Вы разницы все равно не заметите. Даже если таких фрагментов будет сотня.
Если фрагмент настолько прост — может быть. А если он сложнее и их десятки тысяч? Что-то я сомневаюсь что тот кто привык писать всё «в лоб» хоть на секунду задумается о разнице.
То что движок не умеет оптимизацию — это конечно проблема движка, но пока это так (а ситуация вряд ли изменится в обозримом будущем) — разработчик должен об этом думать. Если он об этом не думает, то получаются раздутые тормозные приложения.
А оптимизмции по скорости или размеру нужно делать только тогда, когда профилировщик указывает на это место в коде, как на “бутылочное горлышко"
Если фрагмент настолько прост — может быть. А если он сложнее и их десятки тысяч?
Тогда можно поправить тысячу из этих десятков и проблема решена.
разработчик должен об этом думать
Не должен, это преждевременная оптимизация. Когда ваше приложение перестанет удовлетворять требованиям по скорости/памяти — тогда и надо думать.
В рамках идеи "давайте писать меньше кода" люди ещё написали кода и назвали это Svelte. Прям как алкоголик, который решил допить бутылку водки, чтобы водки стало меньше и чтобы меньше её пить.
Я просто хочу убедить вас, что лучше отдавать предпочтение языкам и шаблонам, которые позволяют нам писать меньше кода естественным образом.
После этой фразы я ожидал поворот статьи в сторону Haskell, или хотя бы PureScript :-)
Может быть автор должен уважать своих читателей? Дальше читать не захотелось…
Опять маслобойка? Автор упускает важную деталь — для Angular / React / Vue уже есть отличная поддержка со стороны IDE, а без нее экономия на символах ничего не стоит. Для Svelte, насколько я знаю, она очень глубоко в альфе (хотя если это не так, поправьте меня пожалуйста).
У svelte, кстати, я идеологических проблем вижу буквально пару (в отличие от еще более странных поделий, за которые тут на хабре порой топят) — и на самом деле если б мне надо было писать проект в определенных рамках — я бы её как минимум внёс в шорт-лист. Но, конечно, не факт, что svelte стала бы окончательным выбором. Одна проблема всеобщая — это очень унылая поддержка со стороны IDE, что для проекта размером больше наколенного будет серьезным недостатком; вторая — системная, критичная для достаточно больших проектов, тот фактик, что код svelte полностью разматывается в стандартный js без фреймворка — даёт постоянный неустранимый оверхед в виде многократного повторения ошметков фреймворка повсеместно в каждом месте скомпилированного кода.
Беда только в том, что вот такие вот статейки — они о серьезных идеологических проблемах не говорят, да и вообще не в кассу и для серьезного обсуждения технологий их просто бессмысленно читать, в них нет ни одного достойного прочтения предложения. Но тем не менее на хабре это уважаемые плюсовые статьи, вот что радости не приносит.
Вообще это грустно, что я не припоминаю ни одной статьи про svelte, где бы честно говорилось о минусах. О плюсах — были, о высосанных из пальца плюсах — были в три раза чаще первых, а вот о минусах говорят только в комментах, а авторы статей хорошо если одно предложение напишут.
Одна проблема всеобщая — это очень унылая поддержка со стороны IDE, что для проекта размером больше наколенного будет серьезным недостатком;
Ответил тут.
вторая — системная, критичная для достаточно больших проектов, тот фактик, что код svelte полностью разматывается в стандартный js без фреймворка — даёт постоянный неустранимый оверхед в виде многократного повторения ошметков фреймворка повсеместно в каждом месте скомпилированного кода.
Это не совсем так. Более того, это скорее преимущество. Во-первых, нет никаких повторяющихся «ошметков» фреймворка. Весь код, который можно расшарить, расшаривается в пределах бандла для всех компонентов. Во-вторых, в бандл в принципе подключается только то, что используется. В-третьих, да есть точка, в которой размер бандла на Svelte будет больше, чем React + компоненты, но она практически недостижима для одной страницы. Я вам даже скажу примерно сколько — около 600 компонентов. Пруф от чувака, который вообще никак не ангажирован со Svelte.
Если же вы ее достигли и еще не сделали code-splitting для динамической подгрузки компонентов по запросу, то у вас какие-то проблемы. А с code-splitting Svelte работает в разы лучше, чем любой монолит, из-за своих «идеологических проблем». Или как я это называю «верных архитектурных решений».
Вообще это грустно, что я не припоминаю ни одной статьи про svelte, где бы честно говорилось о минусах. О плюсах — были, о высосанных из пальца плюсах — были в три раза чаще первых, а вот о минусах говорят только в комментах, а авторы статей хорошо если одно предложение напишут.
Готов еще раз с вами обсудить минусы Svelte. Рассказывайте!
p/s надеюсь вы не на полном серьезе апеллируете во всех своих комментариях к автору статьи? Ибо это перевод.
Готов еще раз с вами обсудить минусы Svelte. Рассказывайте!
Так вроде ж обсудили уже. Если с разматыванием кода проблем нет, то остаётся только вопрос плагинов к IDE (которые конечно «можно написать», но, как говорится, когда напишут, тогда и будем посмотреть). В остальном у меня нет никаких претензий общего плана, а о частностях можно будет говорить, когда до них дойдет. Более того, сам подход мне очень нравится, да и читал я «скомпилированный» код svelte — и там тоже всё довольно здорово.
Пока у меня, к сожалению, новых проектов нет, где можно было бы взять svelte, но если будут (и будут плагины IDE) — другое дело. Ну или если в реакте, который меня пока устраивает, начнётся какая-нибудь ангуляр-подобная движуха по переделыванию фреймворка вне зависимости от того, нужно ли это кому-то вне фейсбука или нет. Если фейсбук в один прекрасный день объявит, что ООП в реакте больше не будет и пишите на хуках, потому что <список высосанных из пальцах аргументов почему ФП лучше ООП (нет)> — так я мгновенно переобуюсь куда-нибудь еще, например на svelte.
p/s надеюсь вы не на полном серьезе апеллируете во всех своих комментариях к автору статьи? Ибо это перевод.
Я человек простой — не вижу плашки «перевод» — считаю это оригиналом. Но да, теперь вот прочитал внимательно.
Я человек простой — не вижу плашки «перевод» — считаю это оригиналом. Но да, теперь вот прочитал внимательно
Я засылал в Песочницу и там то ли не было выбора "Статья/Перевод/Новость", то ли я был крайне невнимателен (публиковал во время 13 часовой поездки сидячим поездом Псков-Петрозаводск). В любом случае, сейчас уже не исправить.
Автор упускает важную деталь — для Angular / React / Vue уже есть отличная поддержка со стороны IDE, а без нее экономия на символах ничего не стоит. Для Svelte, насколько я знаю, она очень глубоко в альфе (хотя если это не так, поправьте меня пожалуйста).
И что? Им и годков по больше. Плагины для IDE это то, что можно написать. А вот дизайн самого фреймворка, особенно который оброс легаси, просто так не переделаешь.
Вы недооцениваете сложность реализации нормальной поддержки со стороны IDE, особенно учитывая количество возможных сочетаний технологий (JS / TS / Coffeescript, CSS / LESS / SASS / PostCSS / ...). Небольшая экономия символов не оправдывает необходимости все это переделывать.
Разница между изначальной и нормальной поддержкой в IDE, на мой взгляд, огромна. И какая разница, что было N лет назад, когда Angular / React / Vue только зарождались? Сейчас-то у них эта поддержка есть, поэтому фреймворк без нее можно позиционировать разве что как игрушку или эксперимент, но не как production-ready решение.
Требования к production-ready решениям в 2015 и 2019 годах значительно различаются.
Если в общих чертах — то да, именно так. С нишей веб-фреймворков наконец-то стало происходить то, что уже давно происходит с языками программирования, графическими движками и операционными системами: она заполнилась качественными, взрослыми проектами, которые суммарно подняли планку требований. Конкурировать с ними силами одного или нескольких энтузиастов больше невозможно. Поэтому из практичных вариантов остается два — делать игрушечные research-проекты в поисках чего-то действительно революционного, или присоединиться к разработке одного из уже существующих проектов, благо они все тоже open source, и сделать его еще лучше.
for (let i = 0; i <= 100; i += 1) {
if (i % 2 === 0) {
console.log(`${i} — чётное`);
}
}разве не так?
for (let i = 0; i <= 100; i += 2)
console.log(`${i} — чётное`);
пишите меньше кода…
Пишите меньше кода