Честно говоря, Иван часто посмеивался над тщетными усилиями коллег из отдела мониторинга. Они прилагали огромные усилия для реализации метрик, которые им заказывало руководство компании. Они были настолько заняты, что больше никому ничего не хотели делать.
А руководству всё было мало – оно постоянно заказывало всё новые и новые метрики, очень быстро переставая пользоваться тем, что были сделаны ранее.
Последнее время все только и говорили про LeadTime – время поставки бизнесовых фич. Метрика показала сумасшедшее число – 200 дней на поставку одной задачи. Как же все охали, ахали и воздевали руки к небу!
Через некоторое время шум постепенно затих и от руководства поступил заказ на создание еще одной метрики.
Ивану было совершенно понятно, что и новая метрика точно также тихонько помрёт в тёмном уголке.
Действительно, размышлял Иван, знание числа совершенно никому ни о чём не говорит. 200 дней или 2 дня – нет никакой разницы, потому что по числу невозможно определить причину и понять, хорошо это или плохо.
Это типичная ловушка метрик: кажется, что новая метрика расскажет суть бытия и объяснит какой-то тайный секрет. Все так на это надеются, но ничего почему-то не происходит. Да потому что секрет надо искать вовсе не в метриках!
Для Ивана это был пройденный этап. Он понимал, что метрики – это просто обычная деревянная линейка для измерений, а все секреты надо искать в объекте влияния, т.е. в том, что эту метрику формирует.
Для интернет-магазина объектом влияния будут его клиенты, приносящие деньги, а для DevOps – команды, создающие и раскатывающие дистрибутивы с использованием конвейера.
Однажды, устроившись в холле в удобном кресле Иван решил как следует продумать как бы он хотел видеть метрики DevOps с учётом того, что объектом влияния являются команды.
Понятно, что всем хочется уменьшить время поставки. 200 дней – это, конечно, никуда не годится.
Но как, вот в чем вопрос?
В компании работают сотни команд, а в день через DevOps-конвейер проходят тысячи дистрибутивов. Реальное время поставки будет выглядеть как распределение. У каждой из команд будет своё собственное время и свои собственные особенности. Как среди этого месива можно найти хоть что-то?
Ответ возник сам собой – надо найти проблемные команды и разобраться, что у них происходит и почему так долго, а у «хороших» команд научиться как всё делать быстро. А для этого требуется измерить время, проведенное командами на каждом из стендов DevOps:
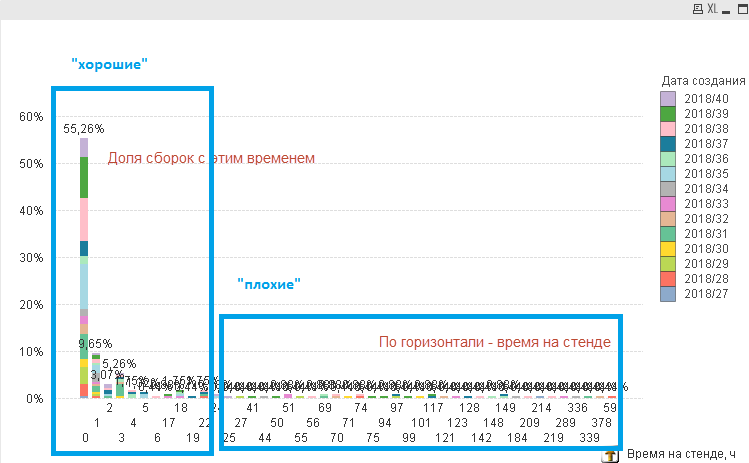
«Целью системы будет отбор команд по времени прохождения стендов, т.е. в итоге мы должны получить список команд с выбранным временем, а не цифру.
Если мы узнаем сколько времени суммарно потрачено на стенд и сколько времени потрачено на простои между стендами, то сможем найти команды, позвонить им и более подробно разобраться в причинах и устранить их», — подумал Иван.
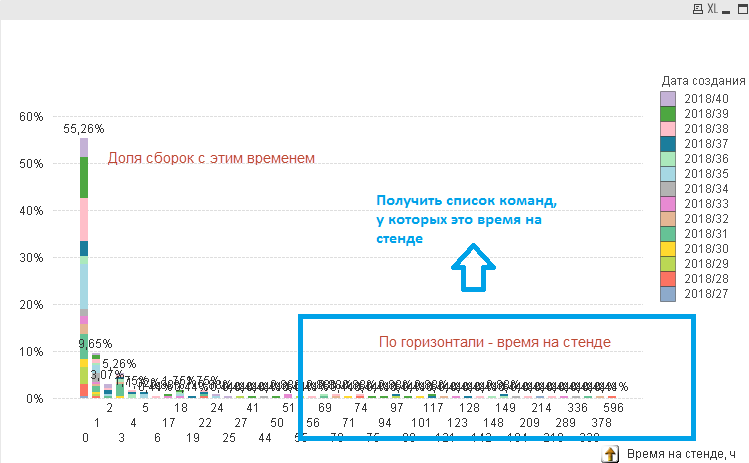
Для подсчета необходимо было углубиться в процесс DevOps и его сущности.
В компании используется ограниченное количество систем, и информацию можно получить только из них и больше ниоткуда.
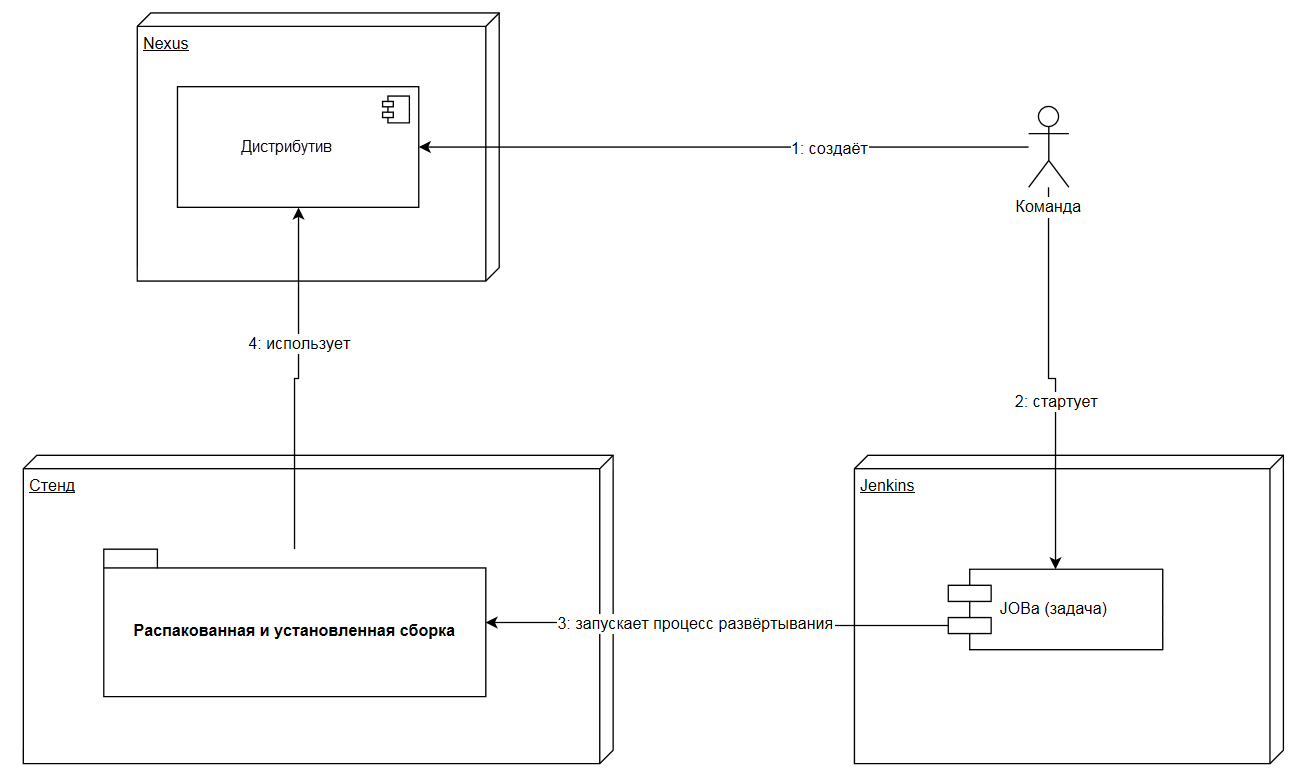
Все задачи в компании регистрировались в Jira. Когда задача бралась в работу, для неё создавался бранч, а после реализации делался коммит в BitBucket и Pull Request. При принятии PR (Pull Request) автоматически создавался дистрибутив и сохранялся в хранилище Nexus.

Далее дистрибутив раскатывался на нескольких стендах с помощью Jenkins для проверки правильности накатки, автоматического и ручного тестирования:
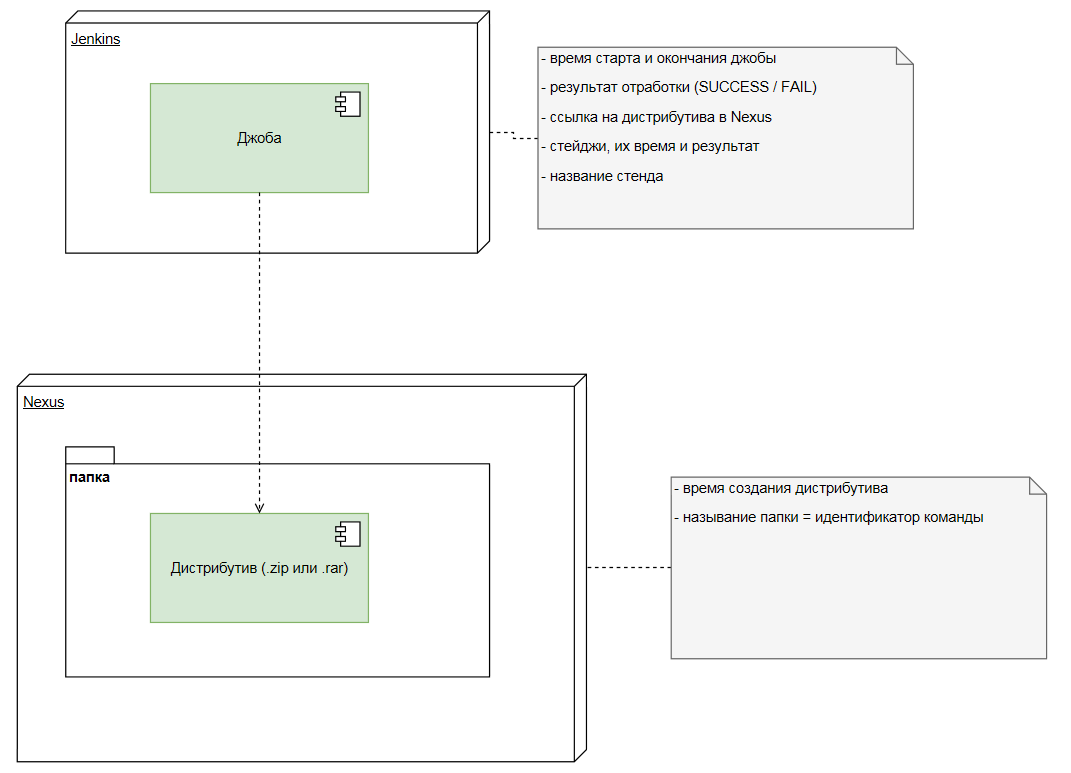
Иван расписал из каких систем какую информацию можно взять, чтобы просчитать время на стендах:
На основе имеющейся в распоряжении информации прорисовывалась такая схема:

Зная сколько времени создаётся дистрибутивов и сколько времени затрачивается на каждый из них, можно легко посчитать общие затраты на прохождение всего конвейера DevOps (полный цикл).
Вот какие DevOps-метрики получились у Ивана в итоге:
С одной стороны, метрики очень хорошо характеризовали конвейер DevOps с точки зрения времени, с другой — считались очень просто.
Довольный хорошо проделанной работой Иван составил презентацию и пошел представлять её руководству.
Обратно он выходил хмурый и с опущенными руками.
— Это фиаско, братан — улыбнулся ироничный коллега…
Продолжение читайте в статье «Как быстрые результаты Ивану помогли».
А руководству всё было мало – оно постоянно заказывало всё новые и новые метрики, очень быстро переставая пользоваться тем, что были сделаны ранее.
Последнее время все только и говорили про LeadTime – время поставки бизнесовых фич. Метрика показала сумасшедшее число – 200 дней на поставку одной задачи. Как же все охали, ахали и воздевали руки к небу!
Через некоторое время шум постепенно затих и от руководства поступил заказ на создание еще одной метрики.
Ивану было совершенно понятно, что и новая метрика точно также тихонько помрёт в тёмном уголке.
Действительно, размышлял Иван, знание числа совершенно никому ни о чём не говорит. 200 дней или 2 дня – нет никакой разницы, потому что по числу невозможно определить причину и понять, хорошо это или плохо.
Это типичная ловушка метрик: кажется, что новая метрика расскажет суть бытия и объяснит какой-то тайный секрет. Все так на это надеются, но ничего почему-то не происходит. Да потому что секрет надо искать вовсе не в метриках!
Для Ивана это был пройденный этап. Он понимал, что метрики – это просто обычная деревянная линейка для измерений, а все секреты надо искать в объекте влияния, т.е. в том, что эту метрику формирует.
Для интернет-магазина объектом влияния будут его клиенты, приносящие деньги, а для DevOps – команды, создающие и раскатывающие дистрибутивы с использованием конвейера.
Однажды, устроившись в холле в удобном кресле Иван решил как следует продумать как бы он хотел видеть метрики DevOps с учётом того, что объектом влияния являются команды.
Цель метрик DevOps
Понятно, что всем хочется уменьшить время поставки. 200 дней – это, конечно, никуда не годится.
Но как, вот в чем вопрос?
В компании работают сотни команд, а в день через DevOps-конвейер проходят тысячи дистрибутивов. Реальное время поставки будет выглядеть как распределение. У каждой из команд будет своё собственное время и свои собственные особенности. Как среди этого месива можно найти хоть что-то?
Ответ возник сам собой – надо найти проблемные команды и разобраться, что у них происходит и почему так долго, а у «хороших» команд научиться как всё делать быстро. А для этого требуется измерить время, проведенное командами на каждом из стендов DevOps:
«Целью системы будет отбор команд по времени прохождения стендов, т.е. в итоге мы должны получить список команд с выбранным временем, а не цифру.
Если мы узнаем сколько времени суммарно потрачено на стенд и сколько времени потрачено на простои между стендами, то сможем найти команды, позвонить им и более подробно разобраться в причинах и устранить их», — подумал Иван.
Как посчитать время поставки для DevOps
Для подсчета необходимо было углубиться в процесс DevOps и его сущности.
В компании используется ограниченное количество систем, и информацию можно получить только из них и больше ниоткуда.
Все задачи в компании регистрировались в Jira. Когда задача бралась в работу, для неё создавался бранч, а после реализации делался коммит в BitBucket и Pull Request. При принятии PR (Pull Request) автоматически создавался дистрибутив и сохранялся в хранилище Nexus.
Далее дистрибутив раскатывался на нескольких стендах с помощью Jenkins для проверки правильности накатки, автоматического и ручного тестирования:
Иван расписал из каких систем какую информацию можно взять, чтобы просчитать время на стендах:
- Из Nexus – Время создания дистрибутива и название папки, в которой содержался код команды
- Из Jenkins – Время старта, длительность и результат отработки каждой джобы, название стенда (в параметрах джобы), стейджи (шаги джоба), ссылка на дистрибутив в Nexus.
- Jira и BitBucket Иван решил в конвейер не включать, т.к. они больше относились к этапу разработки, а не к прокатке готового дистрибутива по стендам.
На основе имеющейся в распоряжении информации прорисовывалась такая схема:
Зная сколько времени создаётся дистрибутивов и сколько времени затрачивается на каждый из них, можно легко посчитать общие затраты на прохождение всего конвейера DevOps (полный цикл).
Вот какие DevOps-метрики получились у Ивана в итоге:
- Количество созданных дистрибутивов
- Доля дистрибутивов, «зашедших» на стенд и «прошедших» стенд
- Время, проведенное на стенде (цикл стенда)
- Полный цикл (суммарное время по всем стендам)
- Длительность джобов
- Простой между стендами
- Простой между запусками джобов на одном стенде
С одной стороны, метрики очень хорошо характеризовали конвейер DevOps с точки зрения времени, с другой — считались очень просто.
Довольный хорошо проделанной работой Иван составил презентацию и пошел представлять её руководству.
Обратно он выходил хмурый и с опущенными руками.
— Это фиаско, братан — улыбнулся ироничный коллега…
Продолжение читайте в статье «Как быстрые результаты Ивану помогли».
