Comments 379
LINQ вошел в .NET как новый мощный язык манипуляции с данными. LINQ to SQL как часть его позволяет достаточно удобно общаться с СУБД с помощью например Entity Framework. Однако, достаточно часто применяя его, разработчики забывают смотреть на то, какой именно SQL-запрос будет генерировать LINQ.
Никак не отменяя сказанного в статье далее, хочу заметить одну вещь: за генерацию запросов к СУБД LINQ не отвечает. За это отвечает queryable provider, в вашем случае — Entity Framework. Смените провайдер — получите другие запросы, другие ошибки и другие оптимизации.
понятие правильности субъективно. но это еще не все, понятие правильности в контексте конкретной БД зависит только от конфигурации этой БД, а именно от сгенерированного этой самой БД плана выполнения запроса.
как думаете, существует ли query провайдер, умеющий собирать с БД несколько разных планов, для каждого конкретного linq-выражения, генерируя различные варианты sql запроса, а потом еще и определять правильность каждого?
Структуры планов будут одинаковыми в большинстве случаев, но выподнение каждого его элемента будет отличаться.
Каждый может ошибаться-все мы люди.
И потому внимание заострил на технических аспектах, а не на ошибки человека пусть даже из Microsoft
Да, за сам запрос утверждал, что inner и cross дадут одинаковые планы.
Кстати и логически и судя по плану, они действительно будут одинаковыми.
Единственное чего я не могу понять, у вас в создании таблиц нету индекса по ID2 в Ref соответственно не совсем понятно, что она во втором подзапросе делает (по вашему скрину не понятно), по идее она должна была по этому несуществующему индексу бежать (и сейчас там идет Index Scan вместо Index Seek, и вам просто повезло что так быстро нашлись в Ref нужные записи). А можете индекс по ID2 в Ref добавить и проверить первый запрос?
Technology Architect David Browne из Microsoft (как я понял, он как раз отвечает то ли за LINQ, то ли за сам MS SQL Server)
Если не секрет, из чего вы это поняли? Вот описание его позиции:
I'm a Technical Architect working at the Microsoft Technology Center in Dallas, helping customers design and implement solutions on the Microsoft platform
который утверждает, что запрос с CROSS JOIN должен выполняться как и запрос с UNION
Я вот не нашел в дискуссии такого утверждения.
Что, конечно, не отменяет того, что EF генерит неоптимальный запрос для данного конкретного случая. Вопрос в том, всегда ли альтернативный запрос оптимальнее.
Проблема-то не в запросах, а в планах, сами-то запросы эквивалентны.
Я вот не уверен, что оптимизация запросов должна быть задачей именно Linq провайдера, а не оптимизатора запросов СУБД.
От Linq провайдера же я ожидаю прозрачность: построение SQL запроса должно быть предсказуемым и не должно зависеть от каких-то хитрых эвристик.
Всегда нужно понимать что происходит за кадром хотя бы примерно.
Иначе с каждым новым уровнем абстракций Вы все ближе будете к бизнес-процессам или предметным процессам, но все меньше будете разработчиком и программистом.
Никакая мащина, никакой фреймворк, никакая суперумная сеть не сможет всегда делать хорошо на 100% свою работу без определенных оптимизаций на всех уровнях абстракций.
Ну да, нужно. Но если вы за понимание — почему вы выступаете против того, чтобы LINQ провайдеры занимались трансляцией и не лезли в оптимизацию?
Я расписал, что как лучше сделать запросы в LINQ некоторые приемы и все
Вот тут:
Это как раз большое заблуждение.
Если вы имели в виду что-то другое, то я не понимаю что именно.
Плюс что выше я написал:
«Всегда нужно понимать что происходит за кадром хотя бы примерно.
Иначе с каждым новым уровнем абстракций Вы все ближе будете к бизнес-процессам или предметным процессам, но все меньше будете разработчиком и программистом.
Никакая мащина, никакой фреймворк, никакая суперумная сеть не сможет всегда делать хорошо на 100% свою работу без определенных оптимизаций на всех уровнях абстракций»
Именно такого утверждения «почему вы выступаете против того, чтобы LINQ провайдеры занимались трансляцией и не лезли в оптимизацию?» я не делал.
Брр. Вот смотрите, я пишу что LINQ провайдеры должны заниматься трансляцией и не лезть в оптимизацию. Вы пишите что я заблуждаюсь — а потом сразу же отрицаете, что выступаете против того что LINQ провайдеры должны заниматься трансляцией и не лезть в оптимизацию.
Так все-таки, что должны делать LINQ провайдеры?
Всегда нужно понимать что происходит за кадром хотя бы примерно.
Ключевое слово тут примерно. Иначе так можно до
Иначе с каждым новым уровнем абстракций Вы все ближе будете к бизнес-процессам или предметным процессам, но все меньше будете разработчиком и программистом.
Ну тут сложный философский вопрос. Пилот современного Боинга — меньший пилот, чем пилот кукурузника?
Никакая мащина, никакой фреймворк, никакая суперумная сеть не сможет всегда делать хорошо на 100% свою работу без определенных оптимизаций на всех уровнях абстракций.
Это палка о двух концах. Premature оптимизацию тоже никто не отменял.
Иначе с каждым новым уровнем абстракций Вы все ближе будете к бизнес-процессам или предметным процессам,
… это и есть задача этих абстракций.
но все меньше будете разработчиком и программистом.
А вот это совершенно не обязательно.
Я, в принципе, согласен с тем, что построение должно быть предсказуемым, а оптимизацией должна заниматься СУБД. Но с другой стороны, провайдер — он для конкретной СУБД. Если для этой СУБД известно, что из двух семантически эквивалентных запросов один всегда выигрышнее по производительности, почему бы провайдеру не выбирать его? Опять же, я понимаю, что есть сложность разработки, время и вот это все. Но концептуально в этом есть свой пойнт.
А в данном споре было вообще просто cross и inner соединения.
А для них планы запросов полностью эквиваленты.
select top 1000 e1.Name, e2.Name
from Customer as e1
cross join Ref as e2
where e1.Ref_ID = e2.ID and e1.Ref_ID2 = e2.ID2vs
select top 1000 e1.Name, e2.Name
from Customer as e1
inner join Ref as e2 on e1.Ref_ID = e2.ID and e1.Ref_ID2 = e2.ID2Дает одинаковый план выполнения с clustered scan + clustered seek c seek predicate Seek Keys[1]: Prefix: [Test].[dbo].[Ref].ID = Scalar Operator([Test].[dbo].[Customer].[Ref_ID] as [e1].[Ref_ID]), над которыми nested loops join.
Нет, не будет. Там полностью идентичные поддеревья. В SSMS есть Showplan comparison, ровно для этого.
Собственно cross join это и есть inner join ON TRUE.
С тем архитектором техническим спор был с условием И между CROSS JOIN и INNER JOIN-также картинки там были приложены
Так, коллеги здесь в статье разбирается CROSS JOIN и INNER JOIN-UNION с условием ИЛИ-сравнить можете и сами.
Поучительно посмотреть на разницу между INNER JOIN по OR и UNION двух INNER JOIN. Ниже gandjustas уже объяснил, почему так получается.
У меня, кстати, есть весьма важный вопрос: а какой бизнес-задаче соответствует ваша модель данных, и почему она сделана именно такой, а не так, как принято в EF? В частности, почему вы делаете JOIN, а не переходы по навигационным свойствам?
В частности, изменится ли что-то, если Ref.ID и Ref.ID2 будут оба ссылаться на Customer.ID?
С тем архитектором техническим спор был с условием И между CROSS JOIN и INNER JOIN-также картинки там были приложены
В тех картинках хорошо видно, что у вас разные условия в CROSS JOIN и INNER JOIN (проще говоря, вы условие джойна в CROSS JOIN пропустили вообще). При одинаковом условии JOIN планы запросов одинаковые.
К этим тестам привел меня анализ запросов на MS SQL и код ревью LINQ-запросов.
В тестах максимально упростили ситуацию и фильтры.
Но если на атомарном уровне так, то можно легко догадаться что на проде будет.
Здесь же важно было заострить внимание как лучше переписать LINQ-запрос для генерации оптимального SQL-запроса.
там на картинке видно, что условие есть «where r.ID=1».
Ну так WHERE r.ID=1 — это ограничение по одной таблице из двух, а где c.[Ref_ID] = r.[ID]?
Но если на атомарном уровне так, то можно легко догадаться что на проде будет.
Нет, нельзя. Потому что другие отношения между данными приводят к другим запросам.
Я больше того скажу, планы запросов
select top 100 e1.Name, e2.Name
from Customer as e1
cross join Ref as e2
where e1.Ref_ID = e2.ID or e1.Ref_ID2 = e2.ID2и
select top 100 e1.Name, e2.Name
from Customer as e1
inner join Ref as e2 on e1.Ref_ID = e2.ID or e1.Ref_ID2 = e2.ID2(при добавленном индексе на Ref.ID2, покрывающем Name) тоже полностью эквивалентны. Собственно, у них и время выполнения одинаковое: 26 секунд.
SELECT *
FROM [dbo].[Customer] AS c
CROSS JOIN [dbo].[Ref] AS r
WHERE c.[Ref_ID] = r.[ID]
AND r.[ID]=1
и
SELECT *
FROM [dbo].[Customer] AS c
INNER JOIN [dbo].[Ref] AS r ON c.[Ref_ID] = r.[ID]
WHERE r.ID=1
Это те запросы, которые были здесь
И там же приложены картинки планов.
В этой же статье обсуждается условие ИЛИ и сравниваются CROSS JOIN с INNER JOIN-UNION, а не просто с INNER JOIN
Я вот не нашел в дискуссии такого утверждения.
There's no obvious reason why you shouldn't use the query that generates a CROSS JOIN
And the query may be very expensive, but changing it from a CROSS JOIN to some other kind of join isn't really going to help
Вопрос в том, всегда ли альтернативный запрос оптимальнее.
С такой статистикой таблиц и такими индексами всегда.
There's no obvious reason why you shouldn't use the query that generates a CROSS JOIN
And the query may be very expensive, but changing it from a CROSS JOIN to some other kind of join isn't really going to help
И ни слова про union. Разговор просто про замену CROSS JOIN на другой JOIN.
С такой статистикой таблиц и такими индексами всегда.
Это и есть не всегда.
А если индексы добавить?
При желании можно и на все.
При наличии индексов план изменится и итоговые различия могут оказаться несущественными.
Так вы код покажите. Вижу в плане с CrossJoin Index Scan внизу, который пробегает по таблице Ref столько раз, сколько в Cutomer.
У меня есть предположение, что если в Ref сделать индекс по ID2 include Name, то СУБД догадается что можно сделать два запроса и объединить результаты.
Еще бы неплохо проверить как Foreign key повлияет на запросы.
Я процитирую вас же:
К сожалению даже опытные и ведущие .NET-разработчики забывают о том, что необходимо понимать что делают за кадром те инструкции, которые они используют.
Но сейчас вы сами пытаетесь игнорировать что происходит "за кадром" в оптимизаторе запросов SQL Server.
По факту вы создали довольно плохую схему БД, которая неоптимальна для ваших запросов и пытаетесь на ней доказать какое-то утверждение.
Вам уже больше одного человека предлагают сделать схему оптимальнее и код написать более похожий на реальный.
Вы при этом настойчиво отбиваетесь, предлагая другим все сделать самостоятельно, хотя вы даже не потрудились выложить исходники в открытый доступ. Думаете кто-то реально будет ваш код из статьи копировать?
На продах обычно еще сложнее и хуже.
А что не так со схемой БД? Что не так с запросами?
Все коды выложены в статье.
Чтобы перепроверить, нужно создать все самому как тут написано и провести замеры, а также убедиться какие запросы создает EF к MS SQL Server.
На гит обычно выкладывают рабочие проекты, а не маленькую тестовую программу, которую легко можно описать в статье в том числе и весь ее код. Что и было сделано.
Также я в личке ответил Вам, что пришлю Вам в архиве весь проект и скрипт создания БД, если Вы укажите свой адрес. Но тоже есть и в публикации.
В схеме не хватает индексов, не хватает внешних ключей.
Код двух запросов у вас не эквивалентный, потому что UNION удаляет дубликаты, а кортеж Ref_ID, Costomer.Name,Ref.Name уникальность никак не гарантирует.
Планы запросов приведены без костов, а поэтому есть вероятность что в первом плане были physical reads, а во втором нет.
Код выложенный в статье невозможно скомпилировать и запустить. От этого теряется повторяемость эксперимента.
Планы запросов приведены без костов, а поэтому есть вероятность что в первом плане были physical reads, а во втором нет.
Ну по планам уже очевидно, что проблема не в этом. И не в индексах. Проблема в том, что ни SQL Server, ни LINQ не оптимизируют исходный запрос с OR. С другой стороны всегда можно сказать «не держите его так».
Как раз по планам и не очевидно. Потому что утверждать что план А лучше Б можно, смотря на косты (estimated cost).
Если при этом план с большим костом оказывается быстрее, то значит вы сами себя где-то обманули.
В этом примере обман заключается в том, что не имея статистики по распределению значений ключей соединения SQL Server считает количество совпадений в JOIN равными и небольшими. Можно в books online посмотреть сколько он там считает по дефолту. А реальная статистика показывает что 100 есть совпадения по первому условию.
И проблема вовсе не в EF.
Повторить мешает то, что надо собрать проект из разрозненных кусков.
github.com/jobgemws/TestLINQ
Для начала почитайте различия между Index и Clustered Index.
Второй план выполняется быстро не благодаря кластерному индексу (любой человек в теме посмеется над этим выражением), а благодаря перекосу в данных. Перекос заключается в том, что первая часть условия джоина, которая перед OR, покрывает 100% строк, поэтому по факту выполняется запрос
SELECT TOP (1000)
[Extent1].[Ref_ID] AS [Ref_ID],
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent1]
CROSS JOIN [dbo].[Ref] AS [Extent2]
WHERE [Extent1].[Ref_ID] = [Extent2].[ID] SQL Server естественно об этом не знает, поэтому для запроса с OR генерирует "универсальный" план. Который оказывается крайне ущербным для такой схемы.
Если сделать индексы и внешние ключи, то SQL Server построит статистику и вполне сможет построить план оптимальнее. А если убрать перекос в данных, то вполне возможно что оба запроса будут примерно одинаково работать.
Оптимизатор SQL Server довольно хорошо работает с OR в условиях, вплоть до того, что может сделать два параллельных запроса к индексам и объединить их результаты.
Повторите у себя все то, что я писал выше и с индексами и с FK и убедитесь сами.
По планам как раз видно, что индексы выручают сильно.
В чем ошибаюсь? Думаете я план читать не умею?
Может покажете estimated косты запросов?
Может сделаете индексы и проверите еще раз?
Вы про какие индексы? Которые не показываете? Или которых нет на тех скриншотах, которые вы привели?
github.com/jobgemws/TestLINQ
Там два подзапроса, каждый из которых выполняется независимо. И я всего лишь пересказал этот план простыми словами. Да там не хватает индекса по ID2, но автор говорил что построил его, и как я понял в плане второго подзапроса Cluster Index Scan, поменялось на Index Seek (уже не clustered но не суть), а первый не изменился никак.
Если сделать индексы и внешние ключи, то SQL Server построит статистику и вполне сможет построить план оптимальнее. А если убрать перекос в данных, то вполне возможно что оба запроса будут примерно одинаково работать.
Это каким образом? План с union'ами очевиден и понятен и всегда будет работать быстро. С cross join по вашему какой план она должна построить, даже при правильной статистике и индексах?
Какой перекос и какие 100% строк она покрывает?
Попробую объяснить по простому.
Вот SQL Server видит условие джоина:
([Extent1].[Ref_ID] = [Extent2].[ID]) OR ([Extent1].[Ref_ID2] = [Extent2].[ID2])Он не знает ничего про значения в Ref_ID, Ref_ID2 и ID2, поэтому считает условно вероятность выполнения обоих условий одинаковым.
План строит исходя из этого предположения.
По факту у нас для первых 1000 строк из Customer всегда находится строка в Ref, соответствующая условию [Extent1].[Ref_ID] = [Extent2].[ID]
Поэтому вручную переписанный запрос, поделенный на две части, выполняется полностью в первой части, до второй даже не доходит.
Подзапросы выполняются не независимо, а последовательно. Как будет выполняться вторая часть зависит от первой. Вы просто не умеете план читать.
Это каким образом? План с union'ами очевиден и понятен и всегда будет работать быстро.
Слишком сильное заявление.
С cross join по вашему какой план она должна построить, даже при правильной статистике и индексах?
Идеально это запрос к двум индексами и склейка результатов.
Да там не хватает индекса по ID2, но автор говорил что построил его, и как я понял в плане второго подзапроса Cluster Index Scan, поменялось на Index Seek (уже не clustered но не суть), а первый не изменился никак.
Сорри, но в вопросах быстродействия нельзя верить на слово.
По факту у нас для первых 1000 строк из Customer всегда находится строка в Ref, соответствующая условию [Extent1].[Ref_ID] = [Extent2].[ID]
Поэтому вручную переписанный запрос, поделенный на две части, выполняется полностью в первой части, до второй даже не доходит.
Да, согласен, 0 во втором подзапросе я не заметил. Только что это меняет? То есть это объясняет, почему отсутствие индекса по ID2 не повредило запросу, но не более.
Про перекос и 100% все равно не понял. То есть то что по каждому Ref_ID есть запись в Ref с ID это по вашему перекос? Вообще это как раз обычная ситуация, в обратную сторону был бы перекос.
Слишком сильное заявление.
Ок, при данной статистике и индексах.
Идеально это запрос к двум индексами и склейка результатов.
Это и есть второй запрос. Но как видим она это не делает. На postgres точно, жаль ms sql под рукой нет воспроизвести, это минут 10 работы.
Сорри, но в вопросах быстродействия нельзя верить на слово.
Ок, автор обновите план пожалуйста, а от не отстанут же :).
github.com/jobgemws/TestLINQ
Да, согласен, 0 во втором подзапросе я не заметил. Только что это меняет? То есть это объясняет, почему отсутствие индекса по ID2 не повредило запросу, но не более.
Отсутствие индекса и статистики повредило первому запросу, который без UNION. Это самое главное. Оптимизатор SQL Server достаточно умный, но он не всегда обладает данными.
Ок, при данной статистике и индексах.
Которых нет, ага.
Это и есть второй запрос. Но как видим она это не делает.
Это потому что нет статистики и индексов (как минимум), может еще и другие причины есть, но без индексов точно не сделает такой запрос.
На postgres точно, жаль ms sql под рукой нет воспроизвести, это минут 10 работы.
На postgres в разы более слабы оптимизтор. От не использует и 10% матана, который заложен в оптимизатор SQL Server.
Я еще не смотрел, посмотрю опишусь.
Дело не в CROSS JOIN. Собственно, ваш запрос полностью эквивалентен INNER JOIN с OR внутри. Это, к сожалению, не помогает SQL Server построить более эффективный (на этих данных) план выполнения.
Почему — вопрос интересный. Но это вопрос к MS SQL, а не к EF.
Более того, по этим выявленным результатам были переписаны некоторые LINQ-запросы (самые часто выполняемые), и взаимоблокировки полностью ушли с одного продовского сервера, скорость выполнения запросо также возросла.
INNER и CROSS+WHERE с одинаковым предикатом дают одинаковые планы, это гарантирует вам SQL SERVER
CROSS + WHERE A OR B в общем случае не дает такой же результат, как
INNER A UNION INNER B или INNER A UNION ALL INNER B. Первый может дать меньше строк, второй больше. Это не эквивалентные запросы в общем случае и точно LINQ не будет делать такое преобразование.
Но на практике полные дубли строк обычно не нужны.
В нашем случае были нужны недублирующие строки.
Честно говоря, не могу вспомнить где были нужны полные дубли для вывода.
Важно то, что вы пытаетесь сравнить неодинаковые запросы.
Это не совсем правильный (я бы даже сказал совсем неправильный) подход к оптимизации.
Во-первых оптимизация БД начинается с правильной схемы, а потом уже идут правильные запросы. Потому что при правильной схеме встроенный оптимизатор SQL Server прекрасно справляется с запросами, в которых нет очевидных ошибок.
Во-вторых оптимизация без понимания почему SQL Server сделал такой план, а не другой — это выглядит как попытка выкинуть число на игральных костях.
Я много занимался оптимизацией именно в "кровавом ынтерпрайзе". И в первую очередь смотрел на схему, индексы и ошибки в запросах, а потом уже пытался переписывать запросы, меняя их семантику.
Не все и нужно переписывать. Положительный результат достигается обычно локальными изменениями. Тут индекс сделали, там запрос поправили. Тут добавили сурогатный ключ, там таблицу добавили и прописали в 5 запросах джоины.
CROSS + WHERE A OR B в общем случае не дает такой же результат, как INNER A UNION INNER B
О! Я вот смотрю на запросы уже полдня, и мне кажется, что где-то должен быть подвох. Можете привести пример, в каком случае эти запросы не дадут одинаковый результат?
(за исключением порядка записей, с ним я уже сам повозился)
UPD: вы про случай, когда INNER (...OR...) даст дубликаты, а UNION их вырежет?
Таблицы
Customer
| ID | Name | ID_Ref | ID_Ref2 |
| 1 | XXX | 1 | 2 |
| 2 | XXX | 2 | 1 |
Ref
| ID | ID 2 | Name |
| 1 | 2 | XXX |
| 2 | 1 | XXX |Во всех запросах будет SELECT Customer.Name, Ref.Name
1) INNER + AND — вернет две строки (ХХХ, ХХХ)
2) INNER + OR — вернет две строки (ХХХ, ХХХ)
3) CROSS + WHERE сработает аналогично INNER
4) UNION — вернет одну строку (ХХХ, ХХХ)
4) UNION ALL — вернет четыре строки (ХХХ, ХХХ)
Спасибо.
To lair, вот запрос, который генерирует наша «функциональная СУБД»:
t0.key0 AS jkey1,
t1.key0 AS jprop0,
t0.key0 AS jprop1
FROM _auto_Main_Ref t0
JOIN _auto_Main_Customer t1 ON 1=1
WHERE t1.Main_refId2_Customer=t0.Main_id2_Ref
LIMIT 1000)
UNION
(SELECT t1.key0 AS jkey0,
t0.key0 AS jkey1,
t1.key0 AS jprop0,
t0.key0 AS jprop1
FROM _auto_Main_Ref t0
JOIN _auto_Main_Customer t1 ON 1=1
WHERE t1.Main_refId_Customer=t0.Main_id_Ref
LIMIT 1000)
LIMIT 1000
Он будет идентичен CROSS JOIN. И я загнал те же самые данные и проверил — даже на PostgreSQL там нормальный план и он выполняется меньше чем за секунду.
Тут проблема в том, что в 4) UNION возвращает наименования, а не ключи. Если бы возвращал уникальные ключи, то никаких проблем бы не было.
А если возвращать (только) ключи, то на MS SQL CROSS JOIN (не важно, с DISTINCT или без) выполняется меньше секунды, а UNION — порядка 30 секунд.
А с UNION можно план? Как вообще в нем MS SQL может там получить 30 секунд, если там по сути надо взять два простых запроса, выполнить взяв максимум первые 1000 записей, а затем просто связать (отрубив дубликаты, но на 1000 записей — это мизер).
А с UNION можно план?
Если я ничего не путаю, это недопустимое преобразование, потому что результат в общем случае изменится.
А в этом плане, как я понял, MSSQL берет ВСЕ записи в первом, ВСЕ записи во втором, объединяет, а затем берет первую 1000.
И этот факт не отменяет что на postres слабый оптимизатор. Информация по обоим есть в сети, изучайте.
В предыдущей статье все детально описано.
То есть запрос на Linq, 1C или голом SQL:
SELECT A.x FROM (SELECT invoiceid, SUM(quantity) AS x FROM invoiceDetail BY invoice) A JOIN selectedinvoices B ON a.invoiceid = b.invoiceid
Может смело положить всю базу (если у вас под сотню миллионов строк инвойсов). MS SQL вроде такой частный случай разрулит (правда в более сложных случаях те же яйца будут). И как вы настройками это решите?
На обеих СУБД такой запрос может вызвать проблемы.
По возможности лучше его переписать.
Иначе придется уже на уровне СУБД магией заниматься
Ну и не от вас же зависит, под какую СУБД разработчик проверял свой запрос.
По возможности лучше его переписать.
Кому? Вы будете дядю Васю, который на 1С сварганил такой запрос, искать? Который может уже давно в этой компании не работает. Или сами рискнете его поправить?
Я имел в виду, если есть возможность, то сразу писать нормально. В данном случае рассматривались LINQ-запросы и такую оптимизацию заложить можно.
А в целом Вы правы-проще поставить скуль и он в большинстве случаев сможет лучше пережевать тот говнокод, что ему будут подавать различные компоненты. А постгрес нужно очень тонко настроить, включая ОС, ФС и само железо, а сама поддержка обойдется дороже, чем на скуле
Настолько все плохо?
Я уж хотел ругать postgres за то, что они не убирает бесполезные джоины, типа такого:
select a.*
from A a
join B b on a.FK = b.PK
where b.primarykey = xНо без predicate pushdown это вообще жопаю. Причем простая оптимизация вроде...
Потому как справедливости ради и в MS SQL эти predicate pushdown'ы не фонтан. ЕМНИП, он даже с UNION'ами не справляются, не то что с проталкиванием нескольких предикатов. Я просто помню, что когда тестил адаптер под MS SQL и выключал predicate pushdown, который у нас приложение делает, MS SQL точно также во многих случаях начинал всю базу лопатить. Собственно по их патентам видно, что весь их predicate pushdown это набор каких-то эвристик для частных случаев.
Да и даже в этом обсуждении видно, что MS SQL DISTINCT TOP 1000 внутрь подзапросов не умеет проталкивать, чего от него еще ожидать.
Предикат сверху union не такой частый кейс.
Насчет эвристик не знаю, примитивная вещь. Даже на уровне linq легко сделать, а уж в оптимизаторе и подавно.
Судя по планам TOP 100 как раз прокидывает в самый низ. Заканчивая обход индекса при достижении нужного количество записей в резалтсете.
PS. АК прекрасный автомат, за много лет ничего лучше не придумали.
Предикат сверху union не такой частый кейс.
Насчет эвристик не знаю, примитивная вещь. Даже на уровне linq легко сделать, а уж в оптимизаторе и подавно.
На уровне linq очень многих вещей нельзя сделать, так как у него статистики нет в принципе. Он многие решения физически принимать не может.
В оптимизаторе можно много чего сделать, только почему то не делается :(
Судя по планам TOP 100 как раз прокидывает в самый низ. Заканчивая обход индекса при достижении нужного количество записей в резалтсете.
Как раз наоборот, он поэтому 27 секунд и выполняется, посмотрите обновленную статью и обновленный план (я сам удивился когда увидел)
ps: хотя план не обновили, только время выполнения, но он тут где-то сверху в комментах был.
Коллеги, напомню, чтобы так не мучаться с планами каждый раз, нужно создавать такие LINQ-запросы, которые создают предсказуемые для выполнения SQL-запросы. О чем и посвещена публикация для отдельного упрощенного примера.
А все, что не удалось в LINQ, то придется делать уже на уровне самой СУБД
нужно создавать такие LINQ-запросы, которые создают предсказуемые для выполнения SQL-запросы
То есть как минимум написать свой queryable provider, потому что вы не контролируете, как именно чужой провайдер преобразует LINQ-запрос в SQL.
можно и так, а можно так, чтобы не сильно зависеть от реализации оптимизатора в конкретном провайдере
Я не про оптимизатор говорю, а про транслятор. Вы не можете написать код так, чтобы не зависеть от реализации транслятора (ну или от спецификации, по которой он работает, если таковая вообще существует).
но можно к этому максимально приблизиться
… и как же?
писал выше и не только выше и многократно в комментариях, и в самой статье в частном порядке разобрано как
Неа. В статье разбрано только то, что на данной версии EF на конкретной конфигурации маппинга конкретный LINQ-запрос дает конкретный SQL-запрос, который вы считаете более выгодным. Нет никакого способа доказать, что EF будет всегда генерить такой SQL-запрос в ответ на такой LINQ-запрос. Нет никакого способа доказать, что этот SQL-запрос всегда выгоднее, чем другой.
Поэтому нет, вы не приблизились к написанию предсказуемых SQL-запросов, вы просто нашли точечное решение, которое сейчас у вас работает. Что, как я неоднократно говорил, само по себе полезно, но не факт, что подлежит обобщению.
linq это не отдельный язык запросов, это способ генерации SQL.
В оптимизаторе SQL Server много чего делается, даже чуть больше чем рядовой программист может представить, и делается на практике когда есть индексы и статистика. В их отсутствии оптимизатор не делает практически ничего.
Поэтому и 27 секунд, потому что оптимизатор не угадал с порядком джоинов, запрос обошел почти 100% записей чтобы получить нужную тысячу. Но остановился сразу при получении результатов.
вопрос не в том сколько, а в том как он обработает данные-вот в чем заключается главная задача оптимизатора. Статистика ведь может и устареть и не успеть обновиться-тоже из практики. А на индексы уповать для всех сложных запросов не стоит.
В оптимизации можно выделить следующие шаги:
1) оптимизация и кэширование на уровне всего приложения
2) оптимизация LINQ-запроса и SQL-запроса
3) и только здесь идет оптимизация на уровне СУБД
Я раньше тоже думал, что нужно все оптимизации на СУБД проводить-написал на эту тему десятки статей на разных ресурсах. Но со временем меня осенило-нужно просто писать на всех уровнях абстракций понятный для исполнения код, а не надеяться, что код с душком выполнит система оптимально. Надо мыслить шире и решать причины проблемы на том уровне абстракций, где она и закладывается.
Однако, упреждающую оптимизацию в фоне лучше проводить всегда и на всех уровнях абстракций, в том числе и на СУБД.
Статистика автоматом обновляется при изменении 10% таблицы. Так что в реальности она не может успеть устареть настолько сильно, чтобы стать неэффективной.
Есть особые случаи на очень больших таблицах, но на паре миллионов все будет работать хорошо.
Это опять аргумент в пользу бедных. Даже если индексы и статистика могут не сработать в 1% случаев это не повод их не использовать.
Поэтому и 27 секунд, потому что оптимизатор не угадал с порядком джоинов, запрос обошел почти 100% записей чтобы получить нужную тысячу. Но остановился сразу при получении результатов.
Какой порядок Join, вы о чем? Там всего 2 join'а. Как его можно не угадать.
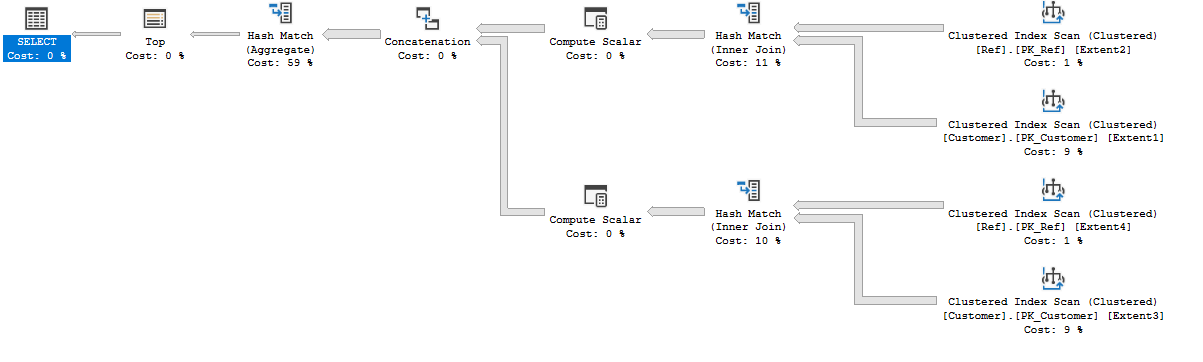
Вот план.
А вот картинка lair'а:
В обоих случаях видно что никакой TOP внутрь он не протолкнул, а значит ему пришлось на HashJoin вообще перейти. Тег Hash в обоих планах и на картинке это видно.
И вы серьезно думаете что и автор и lair не догадались статистику обновить?
Как top протолкнуть в UNION? При текущей схеме и запросах?
SELECT
[Limit1].[C1] AS [C1],
[Limit1].[C2] AS [C2],
[Limit1].[C3] AS [C3]
FROM ( SELECT DISTINCT TOP (1000)
[UnionAll1].[C1] AS [C1],
[UnionAll1].[Name] AS [C2],
[UnionAll1].[Name1] AS [C3]
FROM (SELECT DISTINCT TOP (1000)
1 AS [C1],
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent1]
INNER JOIN [dbo].[Ref] AS [Extent2] ON [Extent1].[Ref_ID] = [Extent2].[ID]
UNION
SELECT DISTINCT TOP (1000)
1 AS [C1],
[Extent3].[Name] AS [Name],
[Extent4].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent3]
INNER JOIN [dbo].[Ref] AS [Extent4] ON [Extent3].[Ref_ID2] = [Extent4].[ID2]) AS [UnionAll1]
) AS [Limit1]тем более что ORDER нигде не указан, а значит может быть любым.
Вы понимаете что при таком переписывании запрос внешний селект может дать от 1 до 1000 записей?
На самом деле, не может: внутренний селект уже вернул уникальные записи. Другое дело, что там теперь есть лишний DISTINCT, но его же и убрать можно.
да, действительно. Но результат двух запросов все равно неэквивалентный. Поэтому сам SQL Server не будет делать такое преобразование.
Мне, на самом деле, очень любопытно, как разработчики оптимизатора определяют границы эквивалентности.
(я просто помню, как мы сами при разработке некоей оптимизации сначала написали тесты на полную эквивалентность, потом когда они в некоторых случаях попадали, внимательно посмотрели, вспомнили, какие гарантии мы даем наружу, и часть проверок эквивалентности убрали, потому что иначе было слишком неэффективно)
Они описаны в реляционной алгебре насколько я понимаю.
Ну, это тоже было бы формулировкой: "мы считаем эквивалентными те запросы, которые эквивалентны в терминах реляционной алгебры (для незнакомых см. туда-то)", но я подозреваю, что даже такого заявления они себе не могут позволить сделать публично.
Это немного другой вопрос. Те семантические преобразования, которые есть сейчас, описаны в BOL. Легко убедиться что они не поменяют семантику запроса.
Некоторые преобразования вытекают из реляционной алгебры, некоторые из здравого смысла. Например ditinct фактически не присутствует в плане если в проекции есть ключи.
Но результат двух запросов все равно неэквивалентный.
Это с чего вдруг? Если вы не указали ORDER SQL сервер не гарантирует порядок. Соответственно они эквивалентны. То есть да могут вернуть разные значения, но в документации по любому SQL серверу написано, что один и тот же запрос может через секунду вернуть другие значения (просто из-за каких-то внутренних операций со страницами).
Собственно если бы даже был ORDER, то его тоже можно было бы протолкнуть внутрь подзапросов и получить эквивалентные запросы.
(del, уже спросили)
А если убрать перекос в данных, то вполне возможно что оба запроса будут примерно одинаково работать.
Извините, но это как? Говорить клиенту, что простите, у вас данные «перекошенные». Выровняйте их, пожалуйста.
В первую очередь надо сообщить СУБД об этом. Путем создания индекса и\или статистики.
Во вторую очередь переписать запросы так, чтобы внутренние соображения SQL Server насчет кардинальности джоинов соответствовали представлениям писателя запросов.
А для тестового примера можно и данные перегенерировать.
представлениям писателя запросов.
Кстати, а откуда писатель запросов вообще должен статистику знать, чтобы «правильно писать запросы»? Ее вроде как только SQL сервер знает.
Человек всегда знает о данных больше чем машина. Потому что для машины это всего лишь числа, а для вас они имеют смысл или просто вы знаете алгоритм по которому эти числа генерируются.
SQL Server при этом сам ничего не знает. Знает он только если создать нужые объекты — индексы, статистику, внешние ключи. Иначе оптимизатор полагается на константы и простые эверистики, которые предполагают равномерное распределение данных и равноценность предикатов.
Суть работы DBA по созданию и оптимизации схемы данных — передать как можно больше этих знаний тупой железке, чтобы она сама могла генерировать оптимальные планы запросов.
А для тестового примера можно и данные перегенерировать.
Во-первых еще не доказано что запрос с UNION лучше (имеет меньше cost). Это он в данной схеме с таким набором данных отработал лучше, по случайному совпадению.
Во-вторых чем проще LINQ переводится в SQL, тем проще его писать.
Продублирую из соседней ветки:
CROSS + WHERE A OR B в общем случае не дает такой же результат, как
INNER A UNION INNER B или INNER A UNION ALL INNER B. Первый может дать меньше строк, второй больше. Это не эквивалентные запросы в общем случае и точно LINQ не будет делать такое преобразование.
А иначе как в приложении вы будете обрабатывать записи с одинаковыми ключами?
На фразе "с одинаковыми ключами" мой внутренний реляционный движок приуныл...
Во-первых, пользователь растеряется куда вводить когда дубли, а во вторых куда сохранять. Хотя второе еще можно решить.
Просто приведите пример в жизни, когда нужны дубликаты строк?
Так дело не в том, что дубликаты строк нужны, а в том, что надо строить такие запросы, которые их не будут давать.
И только не надо там про индексы и FK-не всегда это возможно сделать для всех запросов думаю понятно почему.
Ну как бы вам сказать.
Берем ваш первый запрос:
from e1 in db.Customer
from e2 in db.Ref
where (e1.Ref_ID == e2.ID) || (e1.Ref_ID2 == e2.ID2)
select new { Data1 = e1.Name, Data2 = e2.Name }Он, как вы и говорили, за 30 секунд не выполняется (почти 7 минут на моей машине). Окей.
Берем ваш второй запрос:
(from e1 in db.Customer
join e2 in db.Ref
on e1.Ref_ID equals e2.ID
select new { Data1 = e1.Name, Data2 = e2.Name })
.Union(
from e1 in db.Customer
join e2 in db.Ref
on e1.Ref_ID2 equals e2.ID2
select new { Data1 = e1.Name, Data2 = e2.Name })Он тоже за 30 секунд не выполняется (почти четыре минуты на моей машине). Окей.
А теперь — маленький трюк. Просто превратим сделаем ваш первый запрос полностью эквивалентным второму по возвращаемому набору данных. Видите разницу в запросах?
(
from e1 in db.Customer
from e2 in db.Ref
where (e1.Ref_ID == e2.ID) || (e1.Ref_ID2 == e2.ID2)
select new { Data1 = e1.Name, Data2 = e2.Name }
).Distinct();Вот во что он разворачивается в MS SQL:
SELECT
[Limit1].[C1] AS [C1],
[Limit1].[Name] AS [Name],
[Limit1].[Name1] AS [Name1]
FROM ( SELECT DISTINCT TOP (1000)
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1],
1 AS [C1]
FROM [dbo].[Customer] AS [Extent1]
CROSS JOIN [dbo].[Ref] AS [Extent2]
WHERE [Extent1].[Ref_ID] = [Extent2].[ID] OR [Extent1].[Ref_ID2] = [Extent2].[ID2]
) AS [Limit1]200 миллисекунд.
Планы можно посмотреть?
Estimated и Actual если не сложно
Execution plan XML от actual execution (я не выводил estimated) подойдет?
да
А планы других запросов?
Там вроде три XML, от трех запросов.
Сорри, слепой.
Планы с distinct и без оного эквивалентны. Cost у них одинаковый.
Но в первом случае внешний цикл был по Customer, а внутренний по Ref. Чтобы его "оптимизировать" SQL Server прогнал всю таблицу ref через промежуточную таблицу, что вызвало огромное количество операций увеличения tempdb (проверьте, он огромный).
Во втором запросе (с distinct) внешний цикл был по Ref, а внутренний по Customer и "внезапно" потребовалось обойти всего 4 записи из Ref и чуть меньше 200 000 из Customer.
Такие ошибки в оценке селективности свидетельствуют о нехватке индексов и внешних ключей.
Запрос с Union честно все перебирает, сортирует и убират дубли и выбирает первую 1000. Из-за ошибки в оценке селективности выделенного зранее обхъема памяти не хватило для сохранения и сортировки результатов и SQL Serverиспользовал tempdb, что и дало время около 3 минут.
Короче можно сделать вывод, что вывод автора статьи не стоит ничего. Небольшое изменение начальных условий кардинально меняет план запроса и время выполнения. Оптимизацией это назвать у меня язык не поворачивается.
Вот и мне казалось, что когда подобные мелкие изменения сильно влияют на производительность, да еще и контринтуитивно, распространять их влияние на все другие кейсы — преждевременно.
Спасибо за анализ.
Данный кейс нам помог-потому и поделился.
Весь линк я не рассматривал.
И да, нужно все перепроверять на конкретных примерах и условиях. Впрочем как и любую другую информацию.
Лучше изначально заложить простоту в понимание запроса
… и поэтому вы написали более сложный запрос вместо более простого.
Данный кейс нам помог-потому и поделился.
Есть маленький нюанс: вы заменили запрос на неэквивалентный (и раньше, если я правильно помню, об этом в тексте не было ни слова; я, например, не заметил и поверил вам). У людей могут быть совершенно другие задачи.
Я привел стабильный пример и достаточно шустрый, т к там два простых запроса и DISTINCT делает тоже что и UNION
Про дубликаты я дополнил везде-и в реалиях никто дубликаты не выводит.
Тогда почему в вашем изначальном запросе они не отсекались?
Я привел стабильный пример и достаточно шустрый
Ну да, если проигнорировать чужие измерения...
НЕ стал описывать, т к привел скрипты наполнения данными-в таком случае дублей не будет даже если вы все данные перемножите между собой.
Более того я тоже задумался а возможны ли в принципе дубли если в условиях равенство.
Перемножьте A на B там уже не будет дублей, а сверху фильтр и все-дублей не было изначально, не будет и потом
Потому что в случае с такими условиями их никогда не будет
Эм. Ничто в вашей схеме данных этого не гарантирует. Что мешает нескольким Customer иметь одинаковые RefID? Одинаковые RefID2? Нескольким Ref иметь одинаковые ID2?
А вы эти "где-то существующие дополнительные ограничения" не приводите, и предлагаете что нам, что серверу самостоятельно об этом догадываться. Нехорошо.
Нет конечно полностью без индексов никак-бывают сложные ситуации, но это должно быть исключение, а не правило. Надо лечить источник проблем, а симптомы лишь тогда, когда на данный момент источник полечить не удается. Решение когда DBA делает ревью кода, который создает SQL-запросы позволило сократить проблемы в разы
в целом скорее всего Вы правы, но старался по максимуму упростить задачу
Нельзя это делать, теряя важные стартовые условия. Вы — потеряли.
DBA конечно делает, но потом решает и добивается ревью LINQ запросов и обучает разрабов как не надо писать и все счастливы
Дадада. "Все счастливы". Если то, что приведено выше, пример такого счастья, то без меня, пожалуйста.
Решение когда DBA делает ревью кода, который создает SQL-запросы
Я надеюсь, у этого DBA есть хотя бы лет пять опыта в работе с соответствующей технологией?
Если еще интересует-по C# более 10-ти лет, на скуле-чуть меньше. Опыт нелинейный, т к работаю еще на одну компанию аутсорс постоянно и еще на некоторых временных работах.
Года ничего не значят-можно и все 8 не туда потерять
Так, Ваш запрос в итоге дольше выполняется-там с картинками привел-замазывал внизу название сервера и логин криво, т к уже сонный
Поделилмя детально что было, как сделали и что получили.
Спасибо
Да, можно крутить оптимизацию СУБД. Но если можно сразу построить оптимальный запрос по синтаксису, который с большей вероятностью поймет оптимизатор, тогда почему бы этим не воспользоваться? Зачем писать в LINQ from-from, когда нужен inner join? Пока вы поймете какой индекс нужен, этот запрос не один раз опрокинет прод.
Я с этими линками собаку сьел. И мне тоже пели, что планы хорошие и быстро. А в проде потом факап, который в частности и мне приходилось и не только индексами разгребать.
Пишите максимально понятно и не надейтесь на оптимизатор.
Лучше сразу посмотреть какой запрос создается и улучшить LINQ-запрос так, чтобы SQL-запрос всегда или максимально всегда выполнялся предсказуемым способом
Имхо, inner join будет лучше cross join хотя бы потому, что из реляционной алгебры известно, что внутреннее соединение быстрее декартового произведения.
Вы забыли один нюанс: INNER JOIN и CROSS JOIN — это всего лишь синтаксис конкретного языка. Транслируются они во внутреннее соединение или в декартово произведение — личное дело СУБД.
Во всех случаях решать не мне, а оптимизатору.
То что он может cross join обработать как inner join, это потому что оптимизатор улучшили. Но это не значит, что можно извините «говнокоду» позволять существовать
То что он может cross join обработать как inner join, это потому что оптимизатор улучшили.
Да нет, потому что в SQL больше одного варианта для джойнов. Собственно, есть описанный в документации вариант:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v
WHERE pv.BusinessEntityID=v.BusinessEntityIDДля которого явно сказано, что он эквивалентен INNER JOIN.
Но это не значит, что можно извините «говнокоду» позволять существовать
А где вы говнокод-то нашли?
когда вместо INNER генерится в запрос CROSS
А почему, собственно, вместо?
У вас в LINQ что написано? Правильно:
from e1 in db.Customer
from e2 in db.Ref
where (e1.Ref_ID == e2.ID) || (e1.Ref_ID2 == e2.ID2)Там есть join? Правильно, нет. А что там написано? Правильно, типичное соединение "старого" (как документация на T-SQL пишет, "pre-SQL-92") типа, когда две таблицы указываются во FROM, а условие — в WHERE. И это с чистой совестью пишется в CROSS JOIN, потому что это полный честный эквивалент.
Что конкретно не всегда хорошо? То, что LINQ-провайдер транслирует ваше намерение в T-SQL максимально близко?
Почему должен-то? Вы не написали join, вы написали другую конструкцию.
Переписали — получили UNION. Все логично, вроде.
Нет, серьезно. Пока что EF весьма достоверно транслирует ваши намерения в T-SQL, ну а тот уже работает в меру знаний оптимизатора. И что не так?
Кому писать? Разработчику? Жертвуя читаемостью? Ну да, это типичная оптимизация "по месту", с этим никто не спорит.
Я думал, вы про провайдер говорите, что он вам не тот код генерит, который вы хотите.
Я устал честно-не могу достучаться до Вас
Достучаться до lair? Серьезно? Вам ему что 2+2 = 4 будет тяжело доказать, он всегда вам сможет возразить, что может это в троичной системе исчисления. И даже то, что 4 в ней вообще не существует его не сильно смутит.
Неужели так сложно понять, что надо писать так, чтобы оптимизатор выполнял предсказуемо.
Тогда лучше писать сразу на SQL, чтобы уж точно никакой дополнительный транслятор не включался.
Более того иногда даже длл пишут на C++ и там делают обработку-например связанные с обработкой очень большого количества целей-водных, наземных, где данные генерятся со скоростью свыше 4 млрд строк в час. Там никакой C# с СУБД не выдержат. И вот тут то только разработчик и программист справятся-вспоминаем об абстракциях, что я говорил выше)
А так SQL-язык выглядит более изящно и красиво, чем LINQ to SQL если уж так со всех сторон посмотреть.
Неа. Например, с повторным использованием в SQL как-то не очень.
Бен Уотсон «Высокопроизводительный код на платформе .NET» и там подробно описано, что в большинстве случаев для внеших систем такие как СУБД лучше писать LINQ-запрос в одном месте во избежании генерации неоптимальных SQL-запросов.
Вы можете сколь угодно разбивать LINQ-конструкции, но только те, что в вашем окружении. Например, для LINQ to Objects. Но для LINQ to SQL это в будущем порождает плохие запросы, которые невсегда сможет пережевать оптимально оптимизатор СУБД
Производительность обычно противоречит изяществу и красоте. Это неудивительно, да.
Это, однако, не повод заниматься копипастой кода, потому что стоимость поддержки тоже имеет значение (и иногда весьма большое).
Никто не приводит конкретных цифр.
… в том числе и вы.
а то, что называют непонятным работало с 70-х годов и ранее (ракеты летали, в космос людей запускали, техника работала лучше, приложения были стабильнее в работе). А сейчас?
Все-я спать и Вам спокойной ночи-в конце концов в жизни много других важных дел, чем читать все комментарии. Все равно останется каждый при своем-так стоит ли продолжать, тратя свое драгоценное время.
А сейчас?
А сейчас мы можем себе позволить выпустить приложение на рынок быстрее, чем раньше. Да, ценой худшей производительности на единицу железа.
я и говорю-больше конфигураторов и меньше разработчиков и программистов.
К слову-это и есть говнокодить
и куча мучений пользователей
Ну да, было бы лучше, если бы у них никакого приложения не было, пусть руками делают.
я и говорю-больше конфигураторов и меньше разработчиков и программистов
Я понимаю, что вам очень хочется поделить людей на программистов и не-программистов по какому-нибудь удобному вам критерию.
Есть такие их мало. Раньше было больше.
Мне не хочется делить, но люди сами делают свой выбор-либо ближе к предметке, либо к программированию
Да уж лучше стабильное решение, чем с сюрпризами.
Нет, вы не поняли. Нет такого выбора. Есть выбор "с сюрпризами, но сейчас" или "стабильное, но через два года".
Мне не хочется делить, но люди сами делают свой выбор-либо ближе к предметке, либо к программированию
Неа. Люди делают выбор уровня абстракции (да и то, они между ними перемещаются зачастую), а вот вы почему-то считаете, что чем ниже по абстракции, тем ближе к программированию.
Вас в книгу одного из создателей .NET:
Бен Уотсон «Высокопроизводительный код на платформе .NET»
А, простите, в каком месте Ben Watson создатель .NET? Насколько я могу видеть, он в Bing работал.
там подробно описано, что в большинстве случаев для внеших систем такие как СУБД лучше писать LINQ-запрос в одном месте во избежании генерации неоптимальных SQL-запросов.
А вы можете привести цитату? Ну или хотя бы назвать точную главу (и в каком это издании, первом или втором)? А то я что-то не могу там такого найти, только рассуждения про общее использование LINQ.
И в .NET
Можно источник?
недалеко от места, где описывается когда лучше использовать for, а когда foreach
"for vs foreach" — это раздел в пятой главе (General coding and class design). В этой главе LINQ не упоминается. Следующая глава, шестая — это Using .NET Framework, там действительно есть раздел про LINQ, и там нет сделанного вами утверждения. Можете все-таки точно указать главу и привести цитату?
Насколько я могу видеть, он в Bing работал.
Вот его резюме. Ни слова про "создание .NET" или хотя бы работу в команде .NET.
нередко решения в одном фреймворке копируются в решения других фрейморков, также в резюме не указывается все, но по его работам видно, что он не только разбирается в вопросах производительности .NET, но и также влиял на ее изменения в последующих выпусках.
Ну и включите критическое мышление-даже если это все убрать, то так хорошо разбираться в производительности .NET в определенных вопросах может лишь тот специалист, который не просто контактировал с разработкой этой платформы, но и как минимум своими рекомендациями влиял на ее изменений в этих некоторых вопросах.
Но опять же, мы ушли далеко от темы публикации-прошу вернуться, а не уходить не туда. Иначе получим вновь холивар к тому же весьма бессмысленный
так хорошо разбираться в производительности .NET в определенных вопросах может лишь тот специалист, который не просто контактировал с разработкой этой платформы, но и как минимум своими рекомендациями влиял на ее изменений в этих некоторых вопросах.
Нет, это совершенно не обязательно. Не обязательно на что-то влиять, чтобы в этом разбираться.
Но опять же, мы ушли далеко от темы публикации-прошу вернуться, а не уходить не туда.
Мы ушли от темы публикации, потому что вы решили использовать для подтверждения своего тезиса некое неочевидное утверждение. Вы готовы признать, что это утверждение было не по теме публикации?
Конечно не по теме, как и Ваши методы увода автора статьи далеко от сути публикации
О, прекрасно. Это высказывание не по теме, соседнее с ним, которое вы точно так же оставили без подтверждения, видимо, тоже. Получается, что ваше утверждение "Вы можете сколь угодно разбивать LINQ-конструкции, но только те, что в вашем окружении. Например, для LINQ to Objects. Но для LINQ to SQL это в будущем порождает плохие запросы" осталось без подтверждения — а это, в свою очередь, было единственным аргументом против переиспользования выражений в LINQ.
Ну так что, можно повторно использовать LINQ-выражения или нельзя?
однозначного ответа нет-я описал выше
Это почему же нельзя?
Вот и мне интересно. Но jobgemws очень уверенно пишет нам:
в большинстве случаев для внеших систем такие как СУБД лучше писать LINQ-запрос в одном месте во избежании генерации неоптимальных SQL-запросов [...] для LINQ to SQL это в будущем порождает плохие запросы, которые невсегда сможет пережевать оптимально оптимизатор СУБД
Нужно использовать разумно. Этот мой комментарий есть частный случай этому
Ну так любой инструмент надо использовать разумно, кто бы с этим спорил.
Это как-то отменяет тот факт, что разумно используемый LINQ превосходит разумно используемый SQL по возможностям повторного использования?
И это неправда.
Именно за счет композируемости Linq помогает генерировать оптимальные запросы. А если пытаться весь запрос выписать в одном месте, то у вас получится плохая пародия на SQL.
Для Linq to objects да, но для взаимодействия с внешней системой такой как СУБД Linq to SQL невсегда и в общем плане скорее нет, чем да. На этом уже не одну собаку сьел
И да на linq to objects, можно написать что угодно, но это не забирает у людей права пользоваться опытом/здравым смыслом ;)
последний запрос выполняется более 2 минут на моем сервере-значительно дольше как первого, так и второго варианта:

Откуда TOP (1000) в запросе?
В моем плане, в отличие от вашего, есть параллелизм.

Плюс у нас редакция Standard с большим количетвом активных заппосов, что априори не дает возможность делать запросы на стороне СУБД многопоточными
Для чистоты эксперимента параллелизм выключают.
Эгм. А почему, собственно? Нигде в вашем посте об этом ни слова. Почему вдруг внезапно запросы должны быть оптимальными для выключенного, а не включенного, паралеллизма?
Суть статьи была показать какие запросы генерируются.
Вы пытаетесь решить следствие проблемы силами СУБД и железа. Но важно решить саму причину, т к новые ядра равно как и RAM-диск быстро Вам никто не предоставит. И если есть возможность написать лучше запрос, то почему бы это не сделать. В многопоточной же среде Вы забываете того факта, что один поток может быть отдан другому процессу и тогда весь запрос будет еще дольше выполняться в случае незватки на всех свобоных потоков
Суть статьи была показать какие запросы генерируются.
И, как мы выяснили, в первую очередь генерируются неэквивалентные запросы.
Вы пытаетесь решить следствие проблемы силами СУБД и железа.
Ну да, силами СУБД. Она для этого предназначена. Нет, не силами железа.
Но важно решить саму причину
Добавление Distinct "решает причину" в вашем синтетическом случае. Не важно, есть ограничение по DOP или нет.
Ну хотя бы потому что вы жрете дополнительное возможно чужое процессорное время. Не говоря уже о том, что весь такой план это большая лотерея повезет / не повезет. А план с union куда более предсказуем и логичен. Во всяком случае если оценивать его с алгоритмической точки зрения.
Ну хотя бы потому что вы жрете дополнительное возможно чужое процессорное время.
Или использую простаивающее. Серверу явно лучше знать, сколько у него свободных тредов.
Нет, не должен был. Без UNION все равно быстрее.
Если ваша "оптимизация" на некоторых машинах работает хуже, возможно, что-то с ней не так.
Я имею в виду ваше изменение в LINQ-коде.
Я тоже привел планы.
github.com/jobgemws/TestLINQ/tree/master/Plans
плюс были проведены многократно на разных средах
Ну вот выставил я DOP=1. Запрос с UNION теперь выполняется 38 секунд. Запрос с DISTINCT... CROSS JOIN — все равно меньше секунды.
Нет, я допускаю, что я чего-то крупно в этом запросе не вижу, и он не эквивалентен семантически. Но… сколько не смотрю — не вижу.
Я его уже приводил.
(
from e1 in db.Customer
from e2 in db.Ref
where (e1.Ref_ID == e2.ID) || (e1.Ref_ID2 == e2.ID2)
select new { Data1 = e1.Name, Data2 = e2.Name }
).Distinct()13 мс против 24 с для вашего решения с Union.
Позже проверю и отпишусь.
Спасибо)
Идея статьи и была в том числе собрать лучшие решения. Но не методом оптимизации СУБД и железа, а на уровне LINQ
Как раз с логической точки зрения ровно наоборот.
Был запрос:
from e1 in db.Customer
from e2 in db.Ref
where (e1.Ref_ID == e2.ID) || (e1.Ref_ID2 == e2.ID2)
select new { Data1 = e1.Name, Data2 = e2.Name }Нам предлагают заменить его на (более сложный для понимания) запрос:
(
from e1 in db.Customer
join e2 in db.Ref
on e1.Ref_ID equals e2.ID
select new { Data1 = e1.Name, Data2 = e2.Name}
).Union(
from e1 in db.Customer
join e2 in db.Ref
on e1.Ref_ID2 equals e2.ID2
select new { Data1 = e1.Name, Data2 = e2.Name }
)Эти запросы неэквиваленты. Есть два способа привести их в эквивалентность: либо выбросить дупликаты из первого, либо добавить дубликаты во второй. К счастью, автор поста явно пишет: "полные дублирующие строки не нужны", поэтому можно не думать, какой из вариантов нам предпочесть. Просто добавляем Distinct в конец запроса, и получаем ожидаемое (а не случайное) поведение, и отсутствие WTF, почему два запроса возвращают разные наборы данных.
(
from e1 in db.Customer
from e2 in db.Ref
where (e1.Ref_ID == e2.ID) || (e1.Ref_ID2 == e2.ID2)
select new { Data1 = e1.Name, Data2 = e2.Name }
).Distinct()
генерируется следующий SQL код:
SELECT
[Limit1].[C1] AS [C1],
[Limit1].[Name] AS [Name],
[Limit1].[Name1] AS [Name1]
FROM ( SELECT DISTINCT TOP (1000)
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1],
1 AS [C1]
FROM [dbo].[Customer] AS [Extent1]
CROSS JOIN [dbo].[Ref] AS [Extent2]
WHERE [Extent1].[Ref_ID] = [Extent2].[ID] OR [Extent1].[Ref_ID2] = [Extent2].[ID2]
) AS [Limit1]
выполнялся более 30 сек, отвалился по таймауту
тогда как запрос вида:
var query = (from e1 in db.Customer
join e2 in db.Ref
on e1.Ref_ID equals e2.ID
select new { Data1 = e1.Name, Data2 = e2.Name }).Union(from e1 in db.Customer
join e2 in db.Ref
on e1.Ref_ID2 equals e2.ID2
select new { Data1 = e1.Name, Data2 = e2.Name });
создал SQL код вида:
SELECT
[Limit1].[C1] AS [C1],
[Limit1].[C2] AS [C2],
[Limit1].[C3] AS [C3]
FROM ( SELECT DISTINCT TOP (1000)
[UnionAll1].[C1] AS [C1],
[UnionAll1].[Name] AS [C2],
[UnionAll1].[Name1] AS [C3]
FROM (SELECT
1 AS [C1],
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent1]
INNER JOIN [dbo].[Ref] AS [Extent2] ON [Extent1].[Ref_ID] = [Extent2].[ID]
UNION ALL
SELECT
1 AS [C1],
[Extent3].[Name] AS [Name],
[Extent4].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent3]
INNER JOIN [dbo].[Ref] AS [Extent4] ON [Extent3].[Ref_ID2] = [Extent4].[ID2]) AS [UnionAll1]
) AS [Limit1]
и выполнился за 24 сек.
Первый выполнил в SSMS-2,5 мин
Вот для первого:
и

для второго запроса:

и

и

Как уже говорилось (и я даже планы привел), есть варианты, когда работает не так, как у вас. Что означает, что ваша "оптимизация" нестабильна.
Ну, у меня работает плохо, о чем и речь.
github.com/jobgemws/TestLINQ/tree/master/Plans
выполнился за 24 сек.
Это тот же запрос, который в посте выполнялся "менее 1 сек"? На той же машине, или на другой?
Первый выполнил в SSMS-2,5 мин
Разница в шесть раз; а в посте — в 195. Любопытно.
Да, на обычной машине 24 сек-самый плохой результат-вписал в статью и поправил не в 195 раз, а в разы. При этом худший вариант для первого не правил, а так было бы почти 4 минуты и более
И вас не смущает такой разброс измерений?
Ну то есть не смущает. Ну ок, что тут еще скажешь.
Суть даже не в планах, а в синтаксисе. Приведенный запрос в статье генерирует более стабильный код для выполнения, чем CROSS JOIN-эт ужас просто полагаться на оптимизатор
Аналогично и Вас могу спросить-не смущает по прикрепленным моим планам, что Ваш запрос приведенному в статье?
Меня смущает, что я не понимаю, что именно вы спрашиваете.
Приведенный запрос в статье генерирует более стабильный код для выполнения
Любопытные у вас критерии стабильности.
Я, впрочем, уже сказал: если у вас это узкое место, и вам помогло — окей, хорошо быть вами, вы нашли свое решение. Но это оптимизация по месту, она ухудшила читаемость кода, и не факт, что она поможет хотя бы кому-то, чья ситуация не точно совпадает с вашей.
Но делать красивее код, принося в жертву производительность-там чуть-чуть и там чуть-чуть. Далеко ваше приложение не вырастет без тормозов. Если используете ORM так потрудитесь чтобы SQL-код создавался таким, каким написал бы его DBA.
А спрашивал я Вас не столько Ваш вопрос ко мне сколько считаете ли Вы нормальным довериться ORM на столько, что не проверяете какой SQL-код он создает? Не консультируетесь у DBA как лучше поправить его в SQL, чтобы затем поправить в LINQ? И по остальным фреймворкам-просто доверяете и все? На производительность тесты не проводите?
Я уже писал-чем выше абстракция, с которой человек манипулирует, тем он дальше от разработчика и программиста. Если Вы не понимаете почему нужно стремиться создавать оптимальный код еще до того как кто-то его обработает, то увы я не убедил Вас, о чем сожалею.
Но спасибо за вклад и поправку на счет условия И в LINQ-запросах. Хотя я И пишу последним приведенным примером-тоже понятный код-ничуть не длиннее, но точно гарантируется именно внутреннее соединение, а не что там взбредет ORM от версии к версии и от поставщика.
Мне страшно, что будет с миром, т к все больше конфигураторов, которые решают предметные задачи, настраивающие доступные решения, но не понимающие как это там все работает (на сколько оптимально и корректно), и все меньше разработчиков и программистов, которые могут сделать толковые решения на разных уровнях абстракций.
Если используете ORM так потрудитесь чтобы SQL-код создавался таким, каким написал бы его DBA.
Ну то есть — выкиньте ORM и пишите код руками, потому что иначе не выйдет.
считаете ли Вы нормальным довериться ORM на столько, что не проверяете какой SQL-код он создает?
Проверяю, если запрос сложный. На простых не проверяю.
Не консультируетесь у DBA как лучше поправить его в SQL, чтобы затем поправить в LINQ?
Если работает с нужной мне производительностью — не консультируюсь.
Тут ведь понимаете, какое дело. Вот есть приложение, в нем таких однотипных запросов ну, скажем, штук сто. Приложение развернуто у полутора тысяч клиентов, у каждого из которых своя собственная БД со своим распределением данных. Вот, скажем, DBA говорит: в этом месте на этой БД тормозит, переписывай код. Как узнать, не ухудшит ли переписанный код ситуацию у остальных клиентов? Как узнать, надо ли переписывать код в остальных местах приложения? А расходы на это переписывание и поддержку точно оправдаются?
А если быть совсем точным, все еще занятнее: люди, которые пишут используемую мной ORM — они за соседним столом сидят. И я могу, наверное, пойти и сказать им: чуваки, сделайте так, чтобы выражения вот такого типа разворачивались вот в такой код на SQL. Но, снова, есть вопрос: а как гарантировать, что не станет хуже?
точно гарантируется именно внутреннее соединение, а не что там взбредет ORM от версии к версии и от поставщика.
Не, не гарантируется. Гарантируется только тот SQL, который вы руками напишете.
Но все же INNER JOIN будет не хуже CROSS JOIN, а вот обратное может при определенных ситуациях сыграть не лучшую шутку. Так почему сразу не писать так, чтобы вероятность этой шутки была минимальной? Только это хотел сказать. На этом все. Спасибо
Но все же INNER JOIN будет не хуже CROSS JOIN, а вот обратное может при определенных ситуациях сыграть не лучшую шутку.
Ни в одном обсуждавшемся здесь примере такого не произошло.
Так почему сразу не писать так, чтобы вероятность этой шутки была минимальной?
Потому что это не то, что вы делаете в своих примерах. Вы в своих примерах заменяете INNER JOIN ON (A OR B) на INNER JOIN ON A UNION INNER JOIN ON B.
… или вы подумали, что суть в чем-то одном, а в вашей статье получилось совсем другое.
habr.com/ru/post/275251
Вот только обоих приведенных вами вариантов здесь нет. А есть CROSS JOIN ... WHERE a OR b, который всегда был эквивалентен по плану INNER JOIN ... ON a OR b, против INNER JOIN ON a UNION INNER JOIN ON b.
Производительность обычно противоречит изяществу и красоте. Это неудивительно, да.
Это, однако, не повод заниматься копипастой кода, потому что стоимость поддержки тоже имеет значение (и иногда весьма большое).
Ну, собственно, да, изолированная проверка.
SELECT TOP (1000) c.[Name], r.[Name]
FROM Customer AS c CROSS JOIN Ref AS r
WHERE c.[Ref_ID] = r.[ID] OR c.[Ref_ID2] = r.[ID2]Больше семи минут (ждать надоело).
SELECT DISTINCT TOP (1000) c.[Name], r.[Name]
FROM Customer AS c CROSS JOIN Ref AS r
WHERE c.[Ref_ID] = r.[ID] OR c.[Ref_ID2] = r.[ID2](добавлено только DISTINCT)
Меньше секунды.
Наличие дубликатов ключей (хотя ключ по определению не должен иметь дубликатов) говорит об очень плохой схеме.
Если дубликаты "внезапно" появляются в результатах запроса, то это говорит о недостаточной нормализации.
Денормализация для скорости это от неумения делать индексы.
Увы, за 10+ лет в "кровавом ынтерпрайзе" другого не встречал.
Это я не говорю о всяких DWH, там может быть оправдано. Но туда рядовые программисты с LINQ не полезут.
Не будем разводить холивар, а просто проведите тесты и отпишитесь когда какой вариант лучше получился у Вас-это и интересно и более объективно, чем меряться как количеством опыта, так и его качеством.
Но в общем случае с Вами очень интересно дискутировать, находить лучшее решение-спасибо)
Это никак не противоречит сказонному мной. То что индексы не могут помочь в 100% случаев не значит, что денормализация нужна, а тем более нужна в вашем проекте.
Так вы решаете симптомы, а не проблему.
Проблема заключается как раз в том, что вы не оптимизировали схему под ваши запросы. Далее вместо вписывания грамотных индексов начинается денормализация, появляются дубли, странные distinct и сомнительные решения типа "давайте поменяем запрос на неэквивалентный, авось юзеры не заметят"
Повторюсь, что это упрощенный пример и акцент был на LINQ-запросах, чтобы создавать предсказуемый для выполнения SQL-запрос в большинстве случаев. Я за комплексный подход, а не решать все на стороне СУБД. Да и наследованную схему на проде менять сложнее, чем переписать LINQ-запрос и выложить на прод.
Повторюсь, что это упрощенный пример
… из которого вы в процессе упрощения потеряли важную информацию, которая могла бы помочь выбрать правильное решение.
Да и наследованную схему на проде менять сложнее, чем переписать LINQ-запрос и выложить на прод.
Вот ровно это и называется лечением симптомов.
Я даже не буду говорить, что это неправильно: я регулярно оказывался в ситуации, когда починить проблему архитектурно правильнее в одном месте, но решают починить заплаткой в другом, потому что это быстрее, или проще, или выгоднее с точки зрения обратной совместимости, или еще что-то. С точки зрения бизнеса, короче говоря, это оправданное решение. Просто в таких случаях неплохо бы себя не обманывать и не говорить "мы починили причину" — нет, мы починили некое проявление, но мы знаем, что причина в другом месте.
Странно это слышать от человека, который недавно утверждал, что лучше писать понятнее, но с потерей производительности.
Но от части с Вами соглашусь.
Однако, напомню, что мы живем не в идеальном вакуумном академическом мире. И Вас занесло далеко от сути публикации
Странно это слышать от человека, который недавно утверждал, что лучше писать понятнее, но с потерей производительности.
Ничего странного, эти два подхода никак друг другу не противоречат.
Однако, напомню, что мы живем не в идеальном вакуумном академическом мире.
И что?
И Вас занесло далеко от сути публикации
Вы уж определитесь, что является "сутью публикации", м?
Если использовать EfCore какие запросы получатся? По моим наблюдением генератор sql у него получше.
На практике бывают кейсы, когда для связи таблиц нельзя использовать внешние ключи. Например, записи с общим индентификатором создаются в двух таблицах, но при этом какое-то время не гарантируется одновременное присутствие связанных записей в БД.
Это возможно, если данные приходят из внешних систем и зависимая запись может появиться раньше чем та, на которую она ссылается. Я не говорю, что это архитектурно правильно, но реально встречал такой кейс в энтерпрайзе.
первый раз чтобы сджойнить что-то типа
from t1
left join t2 on t1.a=t2.b and t1.b=t2.b and t2.a='asd'
left join t3 on t2.c!=t3.c and t2d=t3.d and t3.e='abc'
я долго мучил инетрнет и эксперементировал
получалась любая другая фигня но не такой запрос
и в присоединяемых таблицах есть условия не только по соответствию полей
быстро найти пример не получилось
Понял Вас.
А какой при этом SQL-запрос получился?
Не лучше ли неравенство убрать из условия соединения, т к она может дать плохой эффект
link запрос выглядел довольно сложно
что то типа;
from aa in a
join bb in b on new {A = aa.a, B = aa.b, C=true} equals new {A = bb.a, B = bb.b, C=bb.c==«asd»} into group aabbgr
from aabbsubgr in aabbgr.DefaultOrEmpty()
и вторая таблица такимже макаром
Однако, важно помнить одну вещь. Так как большинство СУБД действуют как настоящие коммунисты: строго следуем плану и без разницы, что уже понятно, что что-то пошло не так (ну кроме Oracle, который вроде как умеет что-то перепланировать, но я честно не в курсе что именно). Поэтому, главный кошмар SQL разработчика в том, что если по какой-то причине (недостатку статистики, «перекосу» данных или звезды не так сошлись) выбрался кривой план, то СУБД начнет его выполнять со сложностью, на порядки превышающей оптимальную. А если он еще начнет параллелиться, то будет совсем плохо, так как сожрет много ресурсов сервера. С точки зрения пользователя, зачастую не столь важно выполнится запрос за 1с (с CROSS JOIN) или за 2с (с UNION). Но если он будет выполняться 1000 секунд, то тут же посыплются тикеты вида «у меня все тормозит» или «все повисло».
Преимущество UNION в таком случае, что он выполняется всегда достаточно прямолинейно (так как требуется просто объединить таблицы, удалив дубликаты, что при хорошей хэш-функции делается за относительно линейное время). С логической же точки зрения, UNION помогает «разбивать» сложность. Как, например, в этом примере вместо одного выражения с двумя условиями, будет два более простых запроса с одним условием, которые затем уже будут сливаться. Чем проще каждый конкретный запрос, тем меньше вероятность у СУБД ошибиться и «свалиться» в кривой алгоритм.
По этой причине, схемы с UNION часто более безопасны, чем CROSS JOIN, если запрос выполняется относительно нечасто. Если же требуется оптимизация, то там уже нужно смотреть планы, данные, и выбирать лучший.
нужно заменить UNION ALL
Тоже результаты не совпадут с исходным запросом или надо будет запрос переписать, чтобы семантику сохранить.
Однако, если бы там был задан порядок, то UNION бы также разбивал сложность, при условии, что СУБД догадывалась бы отсечь 1000 первых записей в первом подзапросе и 1000 первых во втором, а потом объединять их. Если бы не догадывалась, то тогда надо было в явную указывать TOP 1000 в каждом из подзапросов.
Добавлю, что дубликаты строк на практике не нужны. По крайней мере в большинстве случаев
Если возвращать уникальные ключи. Но в исходном запросе их нет, и совершенно не факт, что добавить их на уровне провайдера — легко.
Общее правило при работе с EF — не уверен в качестве сгенерированного кода — перепроверяй его в LinqPad (https://www.linqpad.net/) и доводи до вменяемого состояния.
Не согласен с примитивностью статьи в виду того факта, что в ней детально все расписано.
То, что в ней другая ORM применяется не делает ее примитивной
EF = Entity Framework.
Статья примитивненькая, т.к. все описанное в ней достаточно очевидно, если уже доводилось решать проблемы с оптимизацией работы EF и там встречаются и более интересные случаи (типа разворачивания Navigation Property в OUTER JOIN вместо INNER JOIN и обход этого явным сравнением значения с null и т.д.).
В работе случалось и не такие запросы оптимизировать, поэтому и привел как рекомендацию утилиту LinqPad, которая позволяет анализировать запросы, в которые EF транслирует выражения.
Ну и если объективно, актуальность этой статьи под вопросом, т.к. сейчас все переходят на .NET Core и больший интерес представляет EF Core 2.2, т.к. поддержку .NET Standard в EF обещают только в 6.3 (и то с ограничениями) и ничего нового в эту ORM вероятнее всего уже добавляться не будет.
Нет, в EFCore совершенно другой linq-провайдер. Построенный на базе relinq.
EF старой версии достался древний и довольно кривой провайдер.
"It is worth noting that LINQ in .NET Core has made a number of efficiency improvements"
Ben Watson, Leticia Watson. Writing High-Performance .NET Code, 2nd Edition, April 2018. Глава "Using the .NET Framework", подраздел "LINQ".
Статья была про правильную генерацию SQL-кода, который предсказуемо выполнится
Т е взяли тот же оптимизатор и местами сделали лучше.
Нет, там такого не написано.
Статья была про правильную генерацию SQL-кода, который предсказуемо выполнится
А этим — напомню свой первый комментарий — занимается не LINQ, а провайдер. Entity Framework в вашем случае. Сколько раз Entity Framework упоминается в книге, на которую вы ссылаетесь?
За рекомендацию спасибо)
Прошу как будет у Вас время вкратце описать описанные мною результаты на данной ORM. Думаю читателям будет интересно
Перепишите оригинальный запрос на
var query = from e1 in db.Customer
from e2 in db.Ref.Where(e2 => (e1.Ref_ID == e2.ID) || (e1.Ref_ID2 == e2.ID2))
select new { Data1 = e1.Name, Data2 = e2.Name };И получите INNER JOIN, а не CROSS JOIN
Но это не изменяет того факта, что этот запрос не эффективен для этого набора данных, скорее всего без UNION тут не обойтись.
Опять же SQL отвратителен и тянет лишнее.
SELECT TOP (1000)
[Extent1].[Ref_ID] AS [Ref_ID],
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent1]
INNER JOIN [dbo].[Ref] AS [Extent2] ON [Extent1].[Ref_ID] = [Extent2].[ID] OR [Extent1].[Ref_ID2] = [Extent2].[ID2]Вам привет от LINQ провайдера linq2db
SELECT TOP (1000)
[e1].[Name],
[e2].[Name]
FROM
[Customer] [e1]
INNER JOIN [Ref] [e2] ON ([e1].[Ref_ID] = [e2].[ID] OR [e1].[Ref_ID2] = [e2].[ID2])
----
SELECT TOP (1000)
[t1].[Data1],
[t1].[Data2]
FROM
(
SELECT
[e1_1].[Name] as [Data1],
[e2_1].[Name] as [Data2]
FROM
[Customer] [e1_1]
INNER JOIN [Ref] [e2_1] ON [e1_1].[Ref_ID] = [e2_1].[ID]
UNION
SELECT
[e1_2].[Name] as [Data1],
[e2_2].[Name] as [Data2]
FROM
[Customer] [e1_2]
INNER JOIN [Ref] [e2_2] ON [e1_2].[Ref_ID2] = [e2_2].[ID2]
) [t1]
Вы правы. Но также дополню, что лучше писать в LINQ явно join, а не from-from, если требуется по факту внутреннее или внешнее соединение, а не декартово произведение. Т е заранее писать код так, чтобы он предсказуемо выполнялся в большинстве случаев
Про RIGHT, FULL JOIN, я вообще молчу — их в EF просто нет.
FULL JOIN — вызов DefaultIfEmpty на join.
LEFT и RIGHT — проверкой одной из сторон на null
но FULL JOIN как и CROSS JOIN по возможности лучше не создавать в SQL-запросах
У FULL JOIN, вообще-то, есть конкретный смысл, который иногда нужен.
есть, но по возможности его лучше избегать как и CROSS JOIN
Гм. Вот есть две сущности, А и Б, связанные неким отношением. Нужно вывести в одном отчете сущности все сущности А и все сущности Б, а для тех из них, которые связаны, вывести связь. Как это сделать через FULL OUTER JOIN — понятно. Как это сделать, избегая FULL OUTER JOIN, и почему это решение будет лучше?
ну как показала практика from-from может дать CROSS JOIN, что уже не гуд. Лучше чтобы явно INNER JOIN, если подразумевается именно INNER JOIN.
Рассмотрел случай from-from, когда можно INNER JOIN, т к по ревью кода-это самое частое явление
CROSS JOIN, что уже не гуд. Лучше чтобы явно INNER JOIN
У вас есть пример, когда замена CROSS JOIN на INNER JOIN с сохранением всех условий меняла план выполнения на MS SQL?
Если Вы считаете, что вместо INNER JOIN лучше писать CROSS JOIN, но на выходе будет одно и тоже по строкам, то я Вас не переубежу-простите
Нет, я задал конкретный вопрос: есть ли примеры, когда замена одного на другое при сохранении всех условий меняла план выполнения?
Я ничего не говорил о том, что лучше, я задал вполне конкретный вопрос.
То есть он сам меняет запрос на неэквивалентный?
Не очень понял под какой "конкретный случай". Запросы неэквивалентны, гарантировать что пара Ref.Name и Customer.Name будет уникальна нельзя никак. Если реально linq2db делает такое преобразование, то это повод на всегда от него отказаться. Слишком много на себя берет.
По сути такую "оптимизацию" должен делать внутри себя сам SQL Server.
Может у вас есть кейсы когда linq2db слишком много взял? Я внимательно выслушаю.
Сорри, неверно понял ваше сообщение.
в жизни эквивалентны, т к дубликаты строк никому не нужны. В академическом смысле конечно неэквивалентны. Также в статье указано, что в общем понимании неэквивалентны, но с оговоркой на то, что полные дубли обычно не нужны. Потому с этим можно сказать что оптимизированная выборка даст нужный результат. Предполагается что первая выборка не дает дубликатов-это входные данные.
никто ничего не должен, должен разработчик писать предсказуемый для выполнения код. Иначе остается верить оптимизаторам стороннего софта, что в будущем для созданного приложения может сыграть не самую хорошую шутку. Ну или придерживаться знаменитой фразы:"база виновата-надо ее оптимизировать, а мы ничего поделать не можем-такой LINQ и такой ORM". В умелых руках все будет оптимально
никто ничего не должен, должен разработчик писать предсказуемый для выполнения код.
Это внутренне противоречивое утверждение. Код может быть предсказуем для выполнения только в том случае, если выполняющая его среда дает гарантии (то есть, должна) по его выполнению.
В умелых руках все будет оптимально
Тут всегда важно помнить: оптимально по какому критерию?
ничего сложного-просто посмотреть какой SQL-запрос будет создаваться.
Зная, что нужно на выходе, выбрать оптимальный вариант
повторюсь-на практике полные дубли строк не нужны, так что этот провайдер явно лучше справился с данным LINQ-запросом. Но статья была о том, чтобы создавать такие LINQ-запросы, чтобы создавались SQL-запросы предсказуемые для выполнения
Если писать join, где нужен join, а не from-from, то переучиваться не придется, т к таким образом задается предсказуемый для выполнения код
2 экрана)
но в хранимке данный отчет был бы шустрее и проще
любые трансляторы и оптимизаторы-это минные поля, потому нужно писать максимально предсказуемый код. А уже после этого проводить оптимизацию ниже
Обычно используют гибриднве решения-что-то через орм-простые вещи, а что-то через хранимки. Те на два экрана это было в компании, где создавали софт под заказ даже для крупных юридических клиентов. Но сама компания была небольшой. Перейдя к заказчику со временем софт плохо масштабировался и многие части софта были переписаны в том числе и на хранимки для удовлетворения быстродействия.
Более того, сейчас есть куча тулзов, позволяющих быстро дебажить и находить определения обьектов в хранимках.
Системы реального времени обычно пишутся таеже либо полностью на хранимках, либо гибридно-что-то через орм совсем простое, а что-то через хранимки.
Также компании, которые дорожат стабильностью и быстротой систем обычно сами их и пилят, т к все эти аутсорсы наклепают быстро через ORM, получат денег и все-им лишь бы быстрее сделать. Потому и идет тенденция, что компании создают свои ИТ-департаменты для непрерывного проуесса поддержки инфраструктуры ИТ клмпании и разрвботки софта. Некоторые инфраструктуру частично или полностью отдают в ДЦ, но очень серьезнве компании имеют свои ДЦ.
Но вообще я бы представил, что будет если смоделировать систему реального воемени на орм и если она чуть притормозит, а из-за этого пострадают люди, то потом выслушал бы и про то, что индексы выручат все и про статистику, и про ормы… надо здесь и сейчас, предугадывать проблеиу, а не решать ее когда она настала. Дальновидность и неубиваемость, а также долгосрочность кода-это главное отличие разработчика и программиста от полбзователя кода и конфигуратора
Есть кейсы, когда SQL оптимизатору сносит крышу и ничего вменяемого он соорудить не может, вот и идут в ход временные таблицы.
Как там в EF со временными таблицами? Сори гипотетический вопрос.
Редкий но распространенный кейс, отфильтровать данные по 10000 записей. В IN это не влазит, что будем делать? Какую сторед процедуру будем писать?
Дискуссия в целом оставила неприятное впечатление, но это лично мое мнение.
EF сделал все правильно, CROSS JOIN с условием (что тоже самое что и INNER JOIN ON, от перемещения условия в ON суть не меняется, на плане видно) максимально точно соответствует тому, что написано в LINQ, дальше ожидается что БД сделает все, что посчитает нужным.
В случае с AND условием сервер использует Index Seek по таблице Ref, что логично, так как одна из колонок — PK, а в случае с OR — переключается на Index Scan, то есть прямой перебор. Seek гораздо быстрее, чем прямой перебор, вот и результат.
Поставьте себя на место БД, вам надо найти совпадения в двух таблицах (пусть даже первую 1000), хотя бы по одной колонке из двух, как можно это ускорить (и не замедлить), в каком порядке перебирать?
Предлагается делать union, который возвращает назад Index Seek, но нет гарантии, что с другим распределением данных или значением TOP все еще будет лучше, а еще к такому запросу уже не просто будет что-либо добавить.
Можно поменять ведущую таблицу джоина через FORCE ORDER, можно переписать запрос так, чтобы вместо одного cross джоина было два left с доп условием и индексом, но опять же придется изучить вопрос оптимальности в случаях если данные распределены по-другому или top имеет другое значение.
Лучше наверное попытаться отрезать часть запроса по другим критериям либо не использовать такой джоин вообще, т.е. просто вытащить тысячу по первому условию, если не набралось — выполнить второй запрос, можно перести в процедуру.
Вы правы, неприятное.
Здесь рассматривался частный случай.
Однако, общий посыл был в том, чтобы создавать код, который будет выполняться предсказуемо. В частности создавать LINQ-запрос, который будет через провайдер создавать SQL-запрос, который предсказуемо будет выполняться. Т е если нужен INNER, то писать INNER, а не CROSS и никакой другой, надеясь, что оптимизатор исправит ошибку разработчика
И да вы правы, то что сейчас предлагает LINQ, немножко путает. Я краем глаза видел что у Microsoft есть планы по его расширению, но когда это будет — мне не известно.
Offtop
Я тоже как то задумался над этой неоднозначностью и пришла идея просто добавить еще парочку функций и унифицировать синтаксис. Предупреждаю, что сие работает только для linq2db
from t in mainTable
from st in subTable.InerJoin(st => st.Id == t.Id)
from lt in subTable.LeftJoin(lt => lt.Id == t.Id)
from rt in subTable.RightJoin(rt => rt.Id == t.Id)
from ft in subTable.FullJoin(ft => ft.Id == t.Id)
select new
{
t,
st,
lt,
rt,
ft
}Как оказалось, это намного удобней и пересталять джоины местами, и менять LEFT на INNER и наоборот намного проще.
Некоторые аспекты оптимизации LINQ-запросов в C#.NET для MS SQL Server