LINQ вошел в .NET как новый мощный язык манипуляции с данными. LINQ to SQL как часть его позволяет достаточно удобно общаться с СУБД с помощью например Entity Framework. Однако, достаточно часто применяя его, разработчики забывают смотреть на то, какой именно SQL-запрос будет генерировать queryable provider, в вашем случае — Entity Framework.
Разберем два основных момента на примере.
Для этого в SQL Server создадим базу данных Test, а в ней создадим две таблицы с помощью следующего запроса:
Теперь заполним таблицу Ref с помощью запуска следующего скрипта:
Аналогично заполним таблицу Customer с помощью следующего скрипта:
Таким образом мы получили две таблицы, в одной из которых более 1 млн строк данных, а в другой-более 10 млн строк данных.
Теперь в Visual Studio необходимо создать тестовый проект Visual C# Console App (.NET Framework):

Далее, необходимо для взаимодействия с базой данных добавить библиотеку для Entity Framework.
Чтобы ее добавить, нажмем на проект правой кнопкой мыши и выберем в контекстном меню Manage NuGet Packages:

Затем в появившемся окне управления NuGet-пакетами в окне поиска введем слово «Entity Framework» и выберем пакет Entity Framework и установим его:

Далее в файле App.config после закрытия элемента configSections необходимо добавить следующий блок:
В connectionString нужно вписать строку подключения.
Теперь создадим в отдельных файлах 3 интерфейса:
И в отдельном файле создадим базовый класс BaseEntity для наших двух сущностей, в который войдут общие поля:
Далее в отдельных файлах создадим наши две сущности:
Теперь создадим в отдельном файле контекст UserContext:
Получили готовое решение для проведения тестов по оптимизации с LINQ to SQL через EF для MS SQL Server:

Теперь в файл Program.cs введем следующий код:
Далее запустим наш проект.
В конце работы на консоль будет выведено:
Т. е. в целом весьма неплохо LINQ-запрос сгенерировал SQL-запрос к СУБД MS SQL Server.
Теперь изменим условие И на ИЛИ в LINQ-запросе:
И вновь запустим наше приложение.
Выполнение вылетит с ошибкой, связанной с превышением времени выполнения команды в 30 сек:

Если посмотреть какой запрос при этом был сгенерирован LINQ:

, то можно убедиться в том, что выборка происходит через декартово произведение двух множеств (таблиц):
Давайте перепишем LINQ-запрос следующим образом:
Тогда получим следующий SQL-запрос:
Увы, но в LINQ-запросах условие соединения может быть только одно, потому здесь возможно сделать эквивалентный запрос через два запроса по каждому условию с последующим объединением их через Union для удаления дубликатов среди строк.
Да, запросы в общем случае получатся неэквивалентными с тем учетом, что могут быть возвращены полные дубликаты строк. Однако, в реальной жизни полные дублирующие строки не нужны и от них стараются избавляться.
Теперь сравним планы выполнения двух этих запросов:
Разберем два основных момента на примере.
Для этого в SQL Server создадим базу данных Test, а в ней создадим две таблицы с помощью следующего запроса:
Создание таблиц
USE [TEST] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Ref]( [ID] [int] NOT NULL, [ID2] [int] NOT NULL, [Name] [nvarchar](255) NOT NULL, [InsertUTCDate] [datetime] NOT NULL, CONSTRAINT [PK_Ref] PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[Ref] ADD CONSTRAINT [DF_Ref_InsertUTCDate] DEFAULT (getutcdate()) FOR [InsertUTCDate] GO USE [TEST] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Customer]( [ID] [int] NOT NULL, [Name] [nvarchar](255) NOT NULL, [Ref_ID] [int] NOT NULL, [InsertUTCDate] [datetime] NOT NULL, [Ref_ID2] [int] NOT NULL, CONSTRAINT [PK_Customer] PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[Customer] ADD CONSTRAINT [DF_Customer_Ref_ID] DEFAULT ((0)) FOR [Ref_ID] GO ALTER TABLE [dbo].[Customer] ADD CONSTRAINT [DF_Customer_InsertUTCDate] DEFAULT (getutcdate()) FOR [InsertUTCDate] GO
Теперь заполним таблицу Ref с помощью запуска следующего скрипта:
Заполнение таблицы Ref
USE [TEST] GO DECLARE @ind INT=1; WHILE(@ind<1200000) BEGIN INSERT INTO [dbo].[Ref] ([ID] ,[ID2] ,[Name]) SELECT @ind ,@ind ,CAST(@ind AS NVARCHAR(255)); SET @ind=@ind+1; END GO
Аналогично заполним таблицу Customer с помощью следующего скрипта:
Заполнение таблицы Customer
USE [TEST] GO DECLARE @ind INT=1; DECLARE @ind_ref INT=1; WHILE(@ind<=12000000) BEGIN IF(@ind%3=0) SET @ind_ref=1; ELSE IF (@ind%5=0) SET @ind_ref=2; ELSE IF (@ind%7=0) SET @ind_ref=3; ELSE IF (@ind%11=0) SET @ind_ref=4; ELSE IF (@ind%13=0) SET @ind_ref=5; ELSE IF (@ind%17=0) SET @ind_ref=6; ELSE IF (@ind%19=0) SET @ind_ref=7; ELSE IF (@ind%23=0) SET @ind_ref=8; ELSE IF (@ind%29=0) SET @ind_ref=9; ELSE IF (@ind%31=0) SET @ind_ref=10; ELSE IF (@ind%37=0) SET @ind_ref=11; ELSE SET @ind_ref=@ind%1190000; INSERT INTO [dbo].[Customer] ([ID] ,[Name] ,[Ref_ID] ,[Ref_ID2]) SELECT @ind, CAST(@ind AS NVARCHAR(255)), @ind_ref, @ind_ref; SET @ind=@ind+1; END GO
Таким образом мы получили две таблицы, в одной из которых более 1 млн строк данных, а в другой-более 10 млн строк данных.
Теперь в Visual Studio необходимо создать тестовый проект Visual C# Console App (.NET Framework):
Далее, необходимо для взаимодействия с базой данных добавить библиотеку для Entity Framework.
Чтобы ее добавить, нажмем на проект правой кнопкой мыши и выберем в контекстном меню Manage NuGet Packages:
Затем в появившемся окне управления NuGet-пакетами в окне поиска введем слово «Entity Framework» и выберем пакет Entity Framework и установим его:

Далее в файле App.config после закрытия элемента configSections необходимо добавить следующий блок:
<connectionStrings> <add name="DBConnection" connectionString="data source=ИМЯ_ЭКЗЕМПЛЯРА_MSSQL;Initial Catalog=TEST;Integrated Security=True;" providerName="System.Data.SqlClient" /> </connectionStrings>
В connectionString нужно вписать строку подключения.
Теперь создадим в отдельных файлах 3 интерфейса:
- Реализация интерфейса IBaseEntityID
namespace TestLINQ { public interface IBaseEntityID { int ID { get; set; } } }
- Реализация интерфейса IBaseEntityName
namespace TestLINQ { public interface IBaseEntityName { string Name { get; set; } } }
- Реализация интерфейса IBaseNameInsertUTCDate
namespace TestLINQ { public interface IBaseNameInsertUTCDate { DateTime InsertUTCDate { get; set; } } }
И в отдельном файле создадим базовый класс BaseEntity для наших двух сущностей, в который войдут общие поля:
Реализация базового класса BaseEntity
namespace TestLINQ { public class BaseEntity : IBaseEntityID, IBaseEntityName, IBaseNameInsertUTCDate { public int ID { get; set; } public string Name { get; set; } public DateTime InsertUTCDate { get; set; } } }
Далее в отдельных файлах создадим наши две сущности:
- Реализация класса Ref
using System.ComponentModel.DataAnnotations.Schema; namespace TestLINQ { [Table("Ref")] public class Ref : BaseEntity { public int ID2 { get; set; } } }
- Реализация класса Customer
using System.ComponentModel.DataAnnotations.Schema; namespace TestLINQ { [Table("Customer")] public class Customer: BaseEntity { public int Ref_ID { get; set; } public int Ref_ID2 { get; set; } } }
Теперь создадим в отдельном файле контекст UserContext:
Реализация класса UserContex
using System.Data.Entity; namespace TestLINQ { public class UserContext : DbContext { public UserContext() : base("DbConnection") { Database.SetInitializer<UserContext>(null); } public DbSet<Customer> Customer { get; set; } public DbSet<Ref> Ref { get; set; } } }
Получили готовое решение для проведения тестов по оптимизации с LINQ to SQL через EF для MS SQL Server:
Теперь в файл Program.cs введем следующий код:
Файл Program.cs
using System; using System.Collections.Generic; using System.Linq; namespace TestLINQ { class Program { static void Main(string[] args) { using (UserContext db = new UserContext()) { var dblog = new List<string>(); db.Database.Log = dblog.Add; var query = from e1 in db.Customer from e2 in db.Ref where (e1.Ref_ID == e2.ID) && (e1.Ref_ID2 == e2.ID2) select new { Data1 = e1.Name, Data2 = e2.Name }; var result = query.Take(1000).ToList(); Console.WriteLine(dblog[1]); Console.ReadKey(); } } } }
Далее запустим наш проект.
В конце работы на консоль будет выведено:
Сгенерированный SQL-запрос
SELECT TOP (1000) [Extent1].[Ref_ID] AS [Ref_ID], [Extent1].[Name] AS [Name], [Extent2].[Name] AS [Name1] FROM [dbo].[Customer] AS [Extent1] INNER JOIN [dbo].[Ref] AS [Extent2] ON ([Extent1].[Ref_ID] = [Extent2].[ID]) AND ([Extent1].[Ref_ID2] = [Extent2].[ID2])
Т. е. в целом весьма неплохо LINQ-запрос сгенерировал SQL-запрос к СУБД MS SQL Server.
Теперь изменим условие И на ИЛИ в LINQ-запросе:
LINQ-запрос
var query = from e1 in db.Customer from e2 in db.Ref where (e1.Ref_ID == e2.ID) || (e1.Ref_ID2 == e2.ID2) select new { Data1 = e1.Name, Data2 = e2.Name };
И вновь запустим наше приложение.
Выполнение вылетит с ошибкой, связанной с превышением времени выполнения команды в 30 сек:
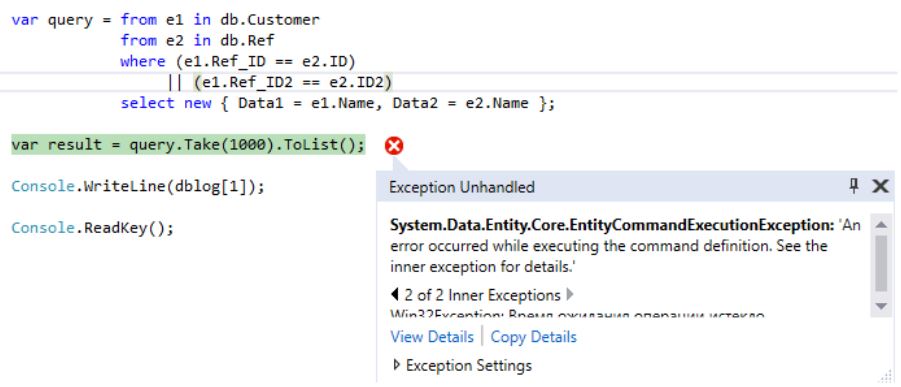
Если посмотреть какой запрос при этом был сгенерирован LINQ:
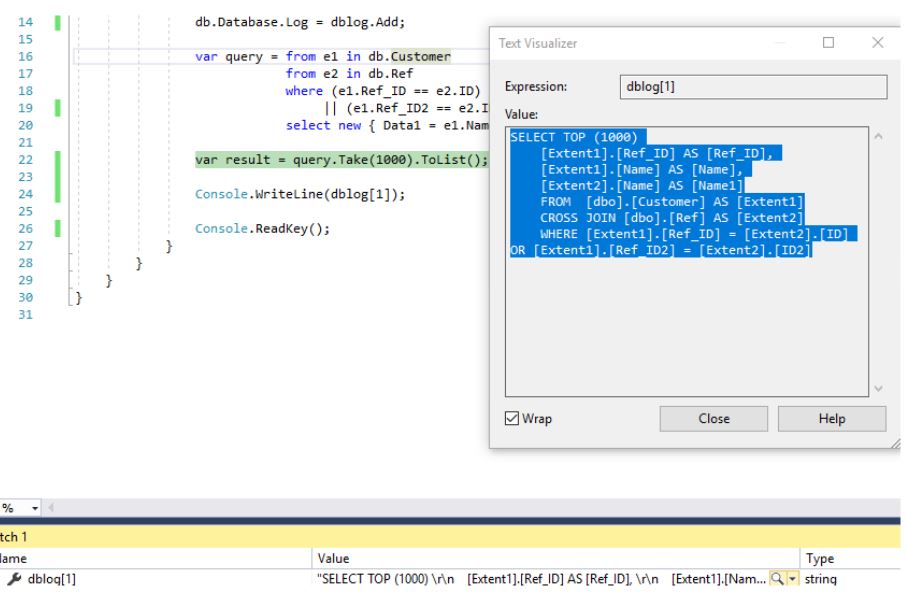
, то можно убедиться в том, что выборка происходит через декартово произведение двух множеств (таблиц):
Сгенерированный SQL-запрос
SELECT TOP (1000) [Extent1].[Ref_ID] AS [Ref_ID], [Extent1].[Name] AS [Name], [Extent2].[Name] AS [Name1] FROM [dbo].[Customer] AS [Extent1] CROSS JOIN [dbo].[Ref] AS [Extent2] WHERE [Extent1].[Ref_ID] = [Extent2].[ID] OR [Extent1].[Ref_ID2] = [Extent2].[ID2]
Давайте перепишем LINQ-запрос следующим образом:
Оптимизированный LINQ-запрос
var query = (from e1 in db.Customer join e2 in db.Ref on e1.Ref_ID equals e2.ID select new { Data1 = e1.Name, Data2 = e2.Name }).Union( from e1 in db.Customer join e2 in db.Ref on e1.Ref_ID2 equals e2.ID2 select new { Data1 = e1.Name, Data2 = e2.Name });
Тогда получим следующий SQL-запрос:
SQL-запрос
SELECT [Limit1].[C1] AS [C1], [Limit1].[C2] AS [C2], [Limit1].[C3] AS [C3] FROM ( SELECT DISTINCT TOP (1000) [UnionAll1].[C1] AS [C1], [UnionAll1].[Name] AS [C2], [UnionAll1].[Name1] AS [C3] FROM (SELECT 1 AS [C1], [Extent1].[Name] AS [Name], [Extent2].[Name] AS [Name1] FROM [dbo].[Customer] AS [Extent1] INNER JOIN [dbo].[Ref] AS [Extent2] ON [Extent1].[Ref_ID] = [Extent2].[ID] UNION ALL SELECT 1 AS [C1], [Extent3].[Name] AS [Name], [Extent4].[Name] AS [Name1] FROM [dbo].[Customer] AS [Extent3] INNER JOIN [dbo].[Ref] AS [Extent4] ON [Extent3].[Ref_ID2] = [Extent4].[ID2]) AS [UnionAll1] ) AS [Limit1]
Увы, но в LINQ-запросах условие соединения может быть только одно, потому здесь возможно сделать эквивалентный запрос через два запроса по каждому условию с последующим объединением их через Union для удаления дубликатов среди строк.
Да, запросы в общем случае получатся неэквивалентными с тем учетом, что могут быть возвращены полные дубликаты строк. Однако, в реальной жизни полные дублирующие строки не нужны и от них стараются избавляться.
Теперь сравним планы выполнения двух этих запросов:
- для CROSS JOIN в среднем время выполнения 195 сек:

- для INNER JOIN-UNION в среднем время выполнения менее 24 сек:

.
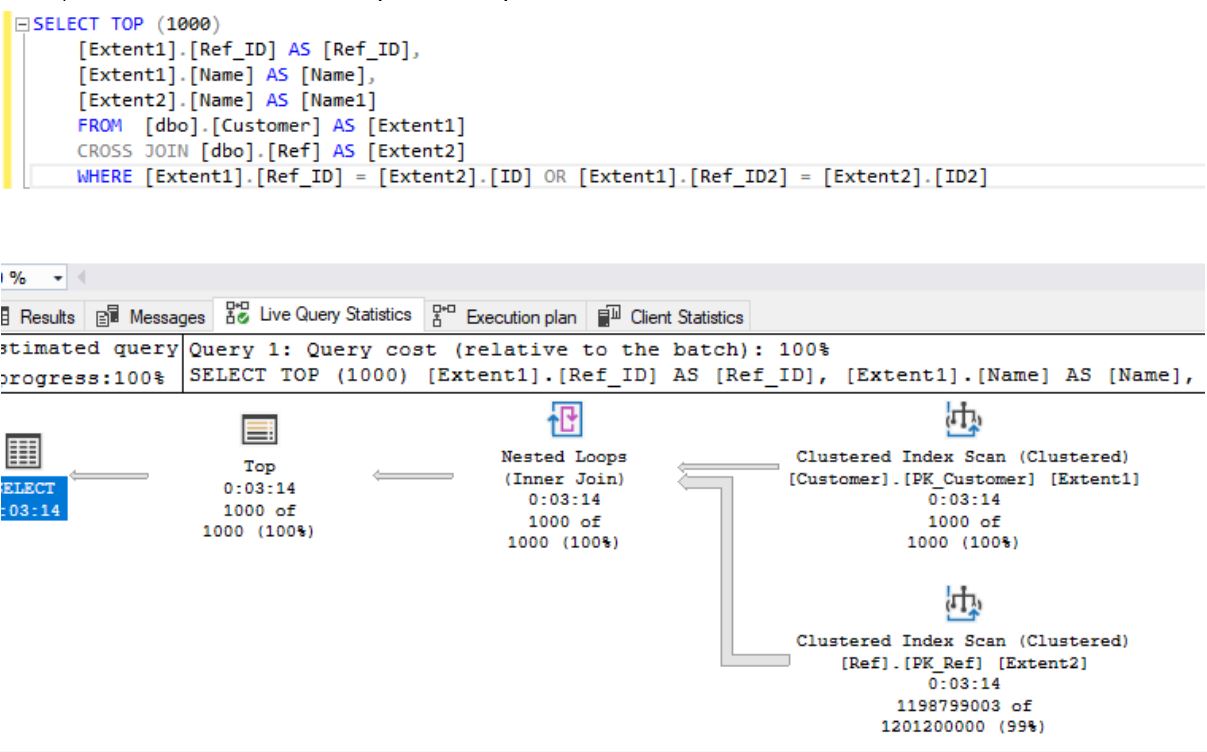
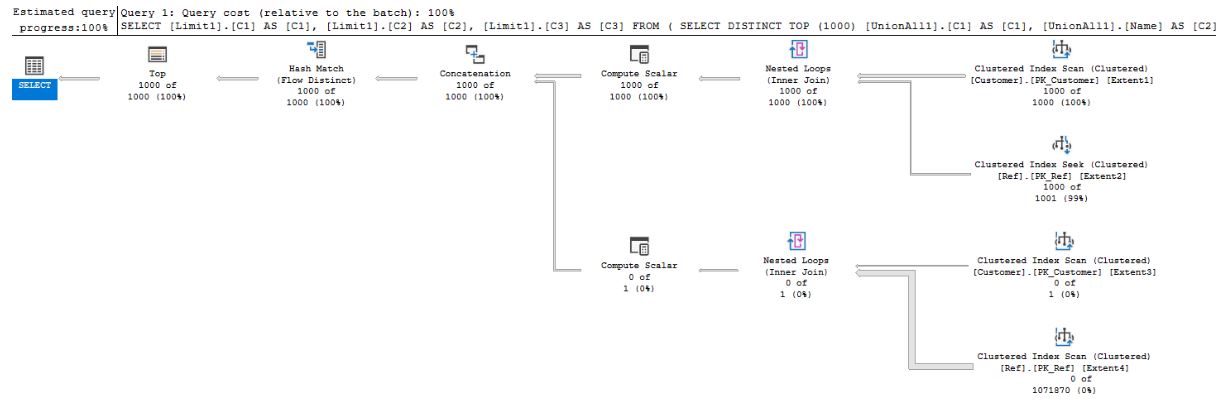
Также в этом репозитории в папке Plans находятся планы выполнения запросов с условиями ИЛИ.

