Предлагаю ознакомиться с расшифровкой доклада начала 2020 года Андрея Бородина "Odyssey: архитектура, настройка, мониторинг"
Совсем недавно мы выпустили версию 1.0 нашего пулера соединений Odyssey. Он призван решить проблемы управления соединениям высоконагруженных инсталляций PostgreSQL. В этом докладе я хотел бы рассказать об архитектуре и эксплуатации Одиссея. Также будут затронуты проблемы, которые были решены в достаточно длинном переходе между 1.0rc и 1.0.

Всем привет! Я в Яндексе занимаюсь Postgres. И в последний год с лишним я занимаюсь управлением соединениями. Довольно критичная штука, потому что она стоит на пути каждого запроса. По-русски мы говорим «Одиссей».

Connection pooler. Я вообще не люблю англицизм. Мне кажется, что в техническом языке мы можем найти точные термины для каждого явления. Но для connection pooler подходящего слова нет. Можно называть менеджером. Но менеджер – это тоже не совсем то, что нужно. Если вы знаете, как правильно называть connection pooler в корректном техническом русском языке, обязательно мне об этом скажите. Connection pooler очень простая программа. Она занимается тем, что управляет клиентскими соединениями.

Немного про Postgres в Яндексе. Исторически известно, что на Postgres давно переехала Яндекс.Почта, в которой миллион с чем-то запросов в секунду выполняется Postrgres’ом. Там хранятся триллионы строк. И в Яндекс.Почту пишет сотни миллионов пользователей.
Но сейчас у нас есть Яндекс.Облако, в котором накопилось уже несколько петабайт в Postgres. И учитывая, что почта туда тоже заезжает, там количество запросов в секунду уже больше, чем 1 миллион запросов в секунду.
В Яндекс.Облако заезжают и другие сервисы Яндекса, которые хотят получить управляемый Postgres. И, конечно, они получают и Odyssey тоже.
Зачем нужно управлять соединениями с базой? Очевидно для того, чтобы соединений было меньше. Соединений с постмастером Postgres должно быть, как можно меньше, потому что одно соединение – это один бэкенд, один процесс форкнутый постмастера.
И на этом процессе висят различные кэши, которые желательно поддерживать и не плодить многократно.

Кроме этого, очень много алгоритмов работы с консистентными снапштотами в Postgres перебирают весь список бэкендов циклом. Эта типичная функция для получения снапшота. Для каждого соединения выполняется какой-то код. И при этом необходимо перебрать все соединения, которые есть в procArray.

- Самый простой и понятный способ для сервиса, который вы только что создали, это Application-side pooling.
- Более сложная вещь – это Proxy pooler.
- И когда-нибудь, я надеюсь, появится встроенный в базу данных pooler.
- И зачастую используются некоторые комбинации всего, что есть.

Application-side pooling – это простое и надежное решение, когда у вас есть приложение, которое работает с базой данных.
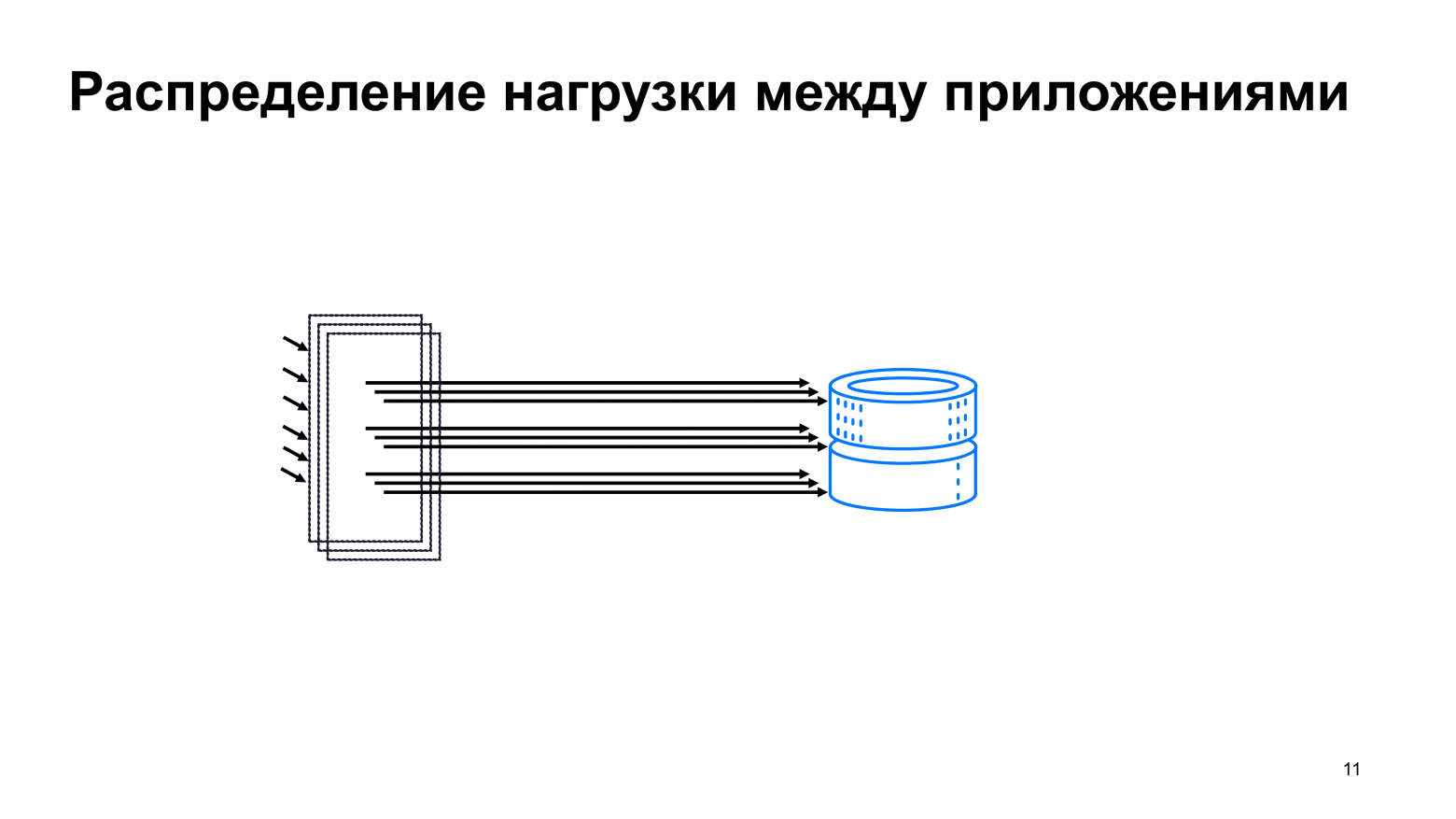
Но возникает рост количества соединений, если ваше приложение находится под балансировщиком нагрузки, и вы запускаете множество отдельных instances сервера приложений, каждый из которых поддерживает отдельный путь.

В определенный момент вы понимаете, что ваш сервис уже приносит очень много денег. И вы хотели бы, чтобы он был отказоустойчивым, и вы распределяете сервис по зонам доступности.
В каждой зоне доступности у вас есть балансировщик нагрузки, под которым находится некоторое количество бэкендов, в каждом из котором есть пул соединений.

И после этого ваша база данных выходит за пределы одного instance Postgres. Вы понимаете, что вам нужно шардирование. И теперь у вас есть зоны доступности, в которых есть балансировщик нагрузки. Это дом, который построил Джек или по-математически – это называется комбинаторный взрыв.
В определенный момент соединений с сервером для Application-side pooling становится слишком много. И с этим, что можно сделать?

Можно применять pooler, который находится между базой данных и вашим приложением. Сейчас выбор довольно обширный.
Есть Pgpool II. Это программа, которая умеет много всего. Она умеет распределять читающие и пишущие запросы. Она пытается понять суть ваших запросов. Но из-за того, что она делает много чего, в ней есть и проблема.
Есть Crunchy-Proxy. Это интересная попутка компании Crunchy Data создать свой Proxy pooler. Написан он на Go, но проект как-то сейчас не очень развивается.
Есть простой и понятный PgBouncer. Это pooler соединений, который предназначен для транзакционного pooling. И он старается больше ничего не делать. Это утилита, которая делает одну задачу, поэтому делает ее хорошо.
И в большинстве случаев для нашей нагрузки в каком-то виде подходит PgBouncer.

Но с ним есть некоторые проблемы.
В PgBouncer довольно сложная диагностика. PgBouncer не говорит, почему не смог открыть серверное соединение. У вас нет никакого кода ошибки. Если не подошел пароль, что-то не так с базой данных, то вы получаете всегда одну и ту же ошибку, которая вашему приложение не говорит, куда нужно деградировать: или нужно тротлить запросы, или нужно поджигать мониторинг и звать человека, который все починит. В общем, диагностика с PgBouncer довольно сложная.
Конечно, можно по косвенным признакам догадываться, что происходит, чтобы быстрее восстановить сервис, но Bouncer вам тут не помогает.
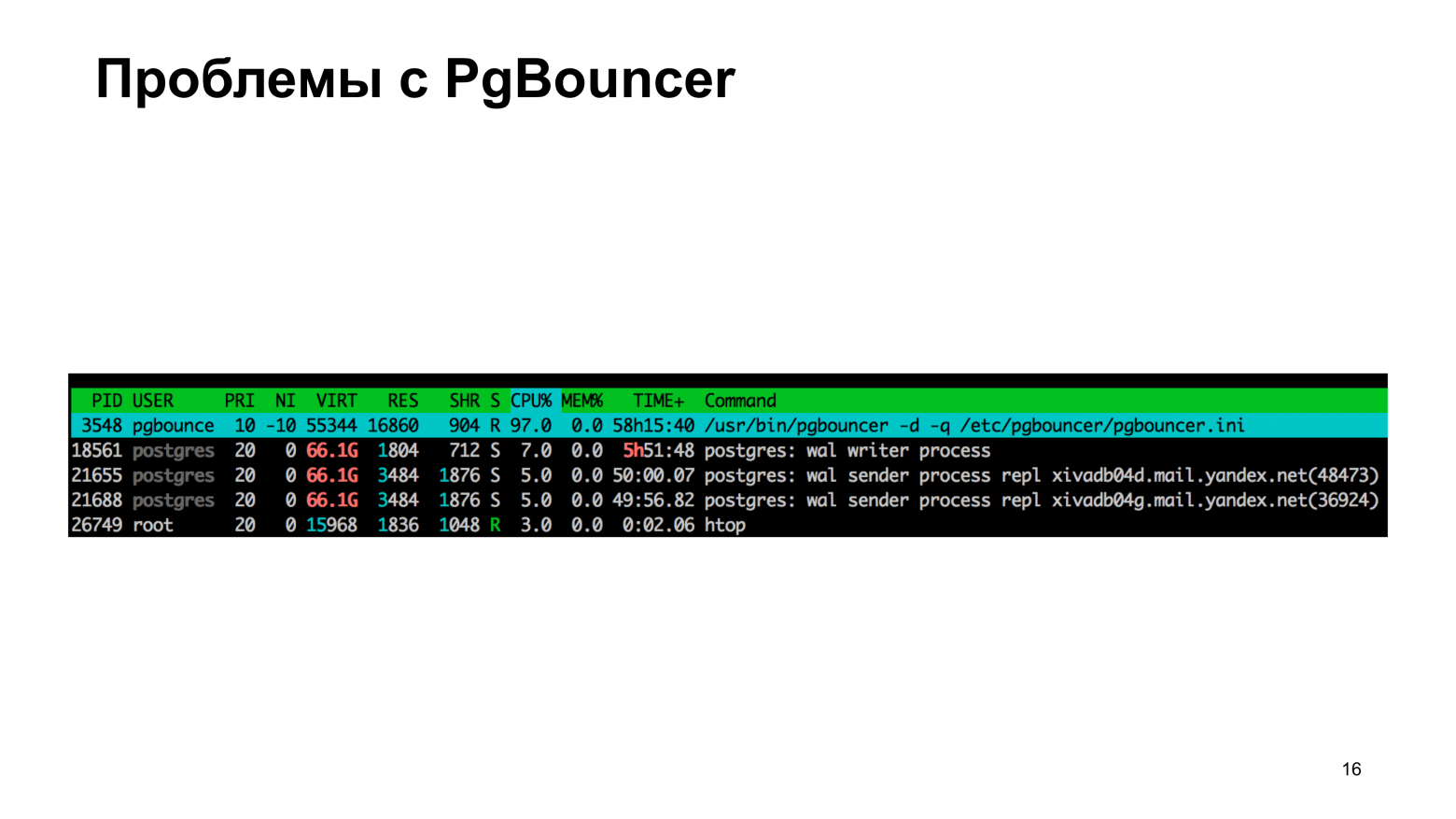
Другая проблема, которая более фундаментальная в том, что PgBouncer спроектирован однопоточным. Он сделан максимально простым и в этой простоте масштабируемость не присутствует как класс. Вот в CPU мы видим 97 % загрузки. База при этом не так, чтобы занята, но Bouncer не успевает передавать байтики туда и сюда.

В принципе, это решаемая проблема. Раньше надо было накладывать небольшой патчик, который позволял PgBouncer разделять порт с другим PgBouncer. Теперь эта технология уже поддержана в PgBouncer, даже патч накладывать не надо. Нужно просто настроить reuseport. Но проблемы все равно возникают.
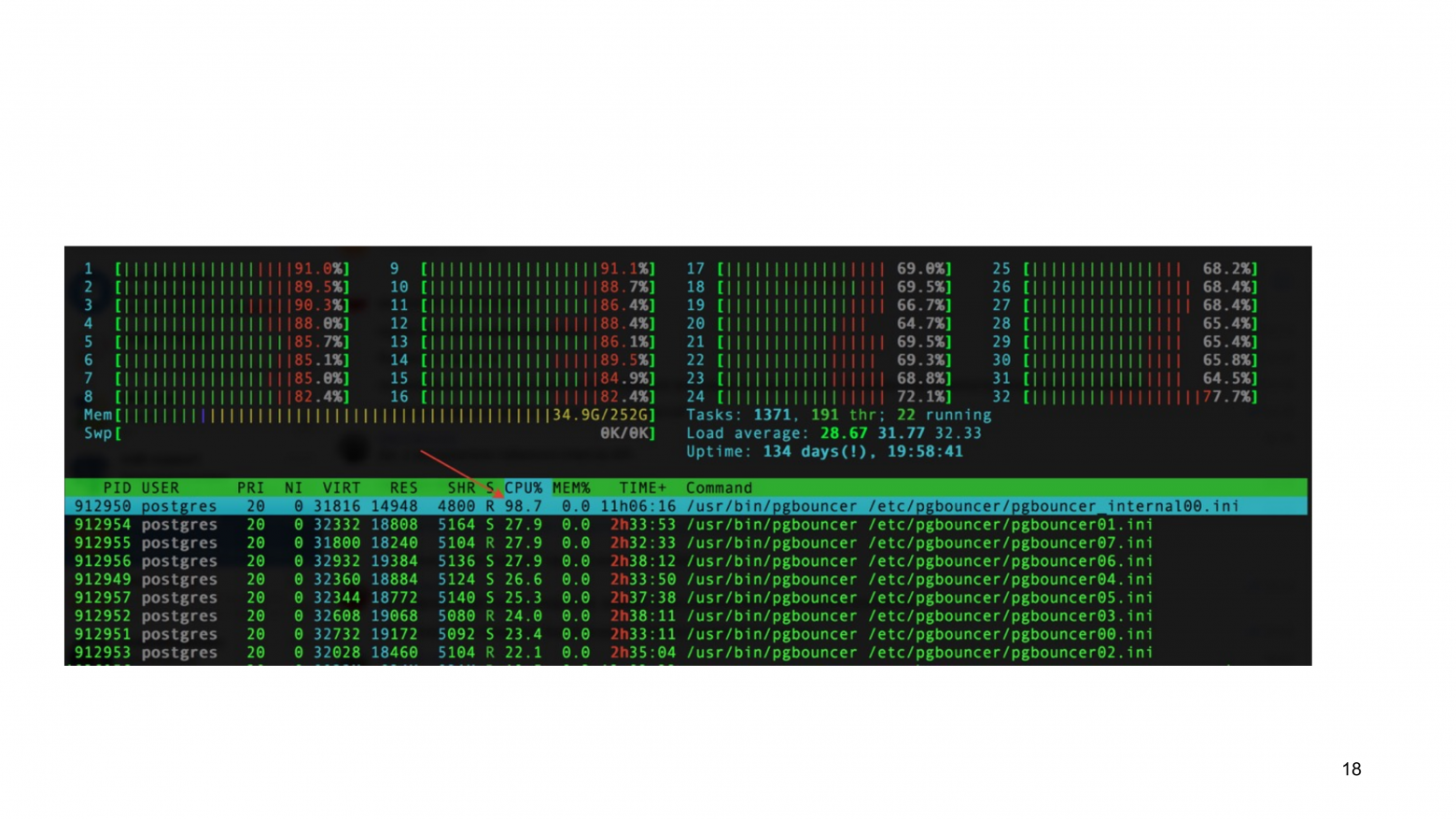
Вот вы видите пример с поднятым каскадом PgBouncer, где у нас есть внутренний Bouncer, который по-прежнему уперт в одно ядро.
Вы можете в каскаде обойтись без внутреннего PgBouncer, но тогда у вас будет connection pool внутри каждого процесса PgBouncer. И снова приходим к той же проблеме, что у нас много коннектов.
Если у вас есть какой-то PgBouncer, который терминирует множество коннектов перед базой данных, то c масштабированием в PgBouncer по-прежнему проблема.
Внешний слой PgBouncer обычно используется для приема волны TLS-соединений. TLS-соединения – это операция, которая требует участие центрального процессора значительно больше, чем типичное перекладывание байтов из сокета в сокет. Т. е. для центрального процессора потоки данных, измеренные в байтах в секунду, они не заметны. Но необходимость выполнять криптографию при TLS handshake существенна. Поэтому каскад PgBouncer, в принципе, справляется с проблемой производительности TLS соединений, но он сложнее в обслуживании. И не справляется с масштабирование, т. е. с передачей данных, с управлением соединений, что проблематично.

И, наконец, то, что послужило одним из основных триггеров для начала разработки Odyssey – это то, что PgBouncer имитирует поведение базы данных в части потерянного соединения.
Если у вас приложение по какой-то причине бросило соединение с базой данных, то PgBouncer продолжит выполнять тот запрос, который выполнялся. На эту проблему обращали внимание много раз. Написали pull request. Он принят не был. Его рассматривают до сих пор. И это еще одна проблема, что PgBouncer не очень хорошо саппортился.
И сразу после выхода Odyssey PgBouncer начали существенно лучше развивать. Это я забегаю вперед.

Из всех этих проблем мы пришли к необходимости разработки собственного connection pooler, который был назван Odyssey.
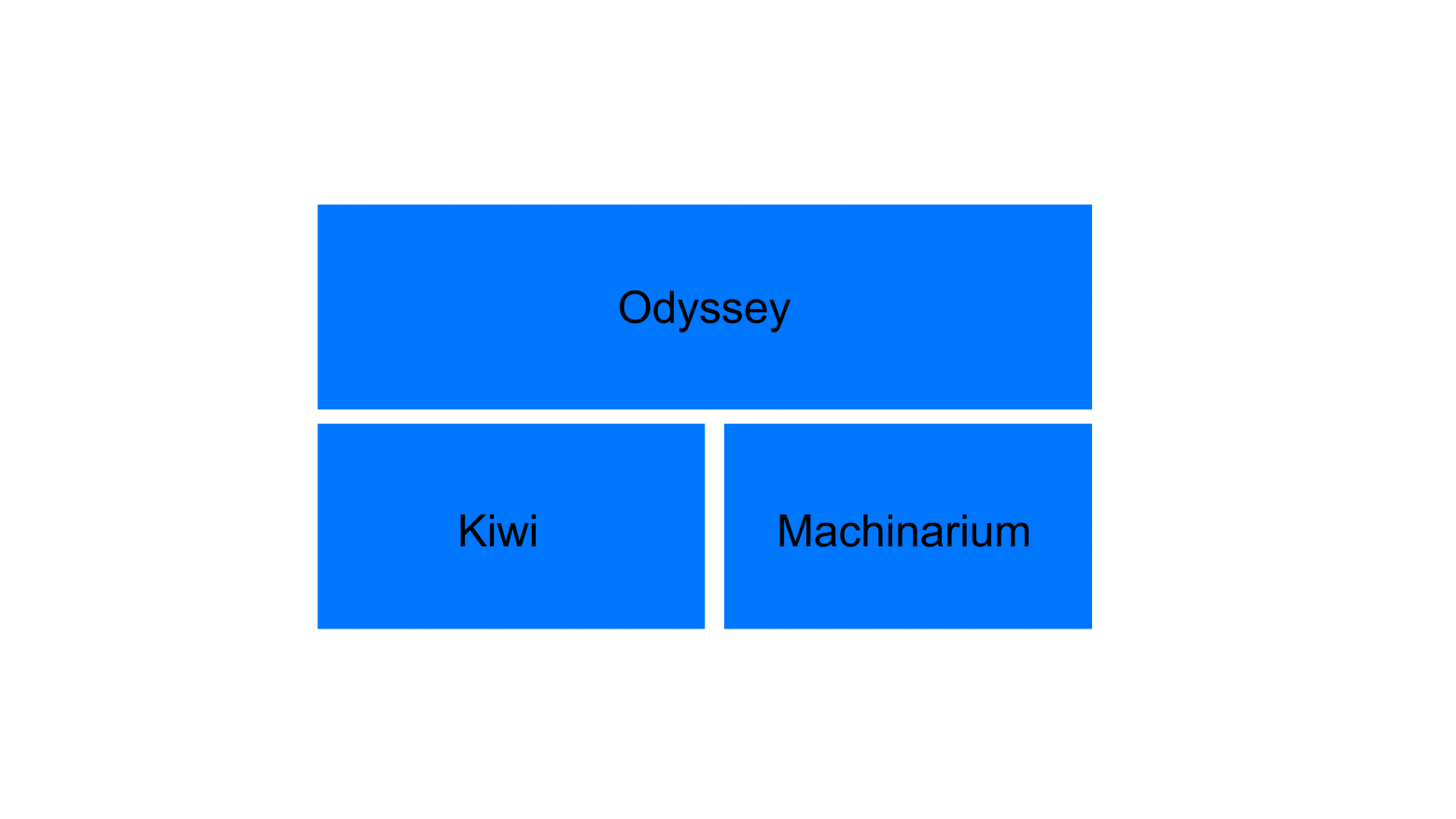
Odyssey основан на двух библиотеках. И поподробней сейчас поговорю про архитектуру Odyssey. Одна библиотека называется Kiwi, другая Machinarium.

Библиотека Kiwi занимается обработкой протокола Postgres. Стандартный протокол Postgres по обмену сообщениями Proto3. Для каждого из сообщений в Kiwi написана функциональность, которая позволяет по простому его отформатировать и отправить единообразно, как если бы вы являлись клиентом или сервером. Если переиспользовать код из libpq или бэкенда Postgres, то он всегда понимает, где он находится. В случае connection pooler он одновременно является и фронтендом и бэкендом Postgres’ного протокола.

Machinarium – более сложная библиотека, которая предназначена для организации многопоточных вычислений и для обработки сообщений о событиях.
В Machinarium есть машины. Машина – это, по сути, thread прибитый к определенному процессорному ядру. И на нем могут регистрироваться корутины. Корутина – это программа, которая получает время центрального процессора от шедулера операционной системы. И продолжает выполнение до тех пор, пока у нее не наступает момент, когда она должна ассинхронно ждать.
Например, здесь у нас показано три потока. Нижний поток создает Machinarium. Средний поток – это то, что выполняется внутри этой машины, это корутина, которая создает другую корутину. И верхняя корутина вызывает sleep. Это самое простое асинхронное ожидание, когда csw_worker говорит Mashinarium’у, что он хочет отдать текущее время центрального процессора какой-то другой корутине и вернутся в данном случае через 0 миллисекунд.
Точно также корутина может попросить Machinarium подождать событие на сокете какое-то определенное время и вернуться либо через это время, либо при появлении данных на сокете.
По сути, это аналог библиотеки, на которой основан PgBouncer. В PgBouncer это libevent, а в Machinarium – это масштабируемая версия libevent, предназначенная для connection pooling, либо для работы по перекладыванию данных.

Архитектура у Odyssey выглядит следующим образом. У нас есть main-машина, т. е. main-поток, в котором есть одна корутина, которая обслуживает сокет. Просматривает наличие соединения в бэклоге. Если видит входящее TCP-соединение, то создает в одном из воркеров новую машину, которой передается соединение. При этом не происходит каких-то форков, просто передается одно сообщение в канале о том, что нужно запустить новую корутину, которая будет заниматься обслуживанием работы одного соединения.
За счет корутинового подхода, когда мы передаем управление не через router, а через вызов функции wait_read или sleep, то работа одной машины по обслуживанию одного клиентского соединения описывается не машиной состояний, а последовательным вызовом. Дождаться прихода стартап-пакета. После этого дождаться выполнения аутентификации. После этого дождаться первого байта, первого запроса. После этого попросить серверное соединение. После этого передать серверному соединению и т. д. Это последовательная программа, которая значительно легче в восприятии, чем машина состояний, когда вы, по сути, пишите условия. Например, если я на прошлом выходе был в состоянии ожидания аутентификации, то я проверяю завершение аутентификации. Или если я был в состоянии открытия сервера, то я проверяю доступен ли мне сервер.
Кроме основного потока также есть потоки, отвечающие за поддержание в консистентном состоянии пул серверных и клиентских соединений, и отвечающих за состояние так называемой консоли, или то, что в PgBouncer называется базой данных PgBouncer. Т. е. служебная база данных, в которой вы можете выполнить show stats, show clients, show pulls и другие команды.

Сейчас мы используем Odyssey в production для многих тысяч instances Postgres. Но в процессе внедрения мы прошлись по очень большому количеству граблей. Вся эта история показала, что в код PgBouncer, хоть он сейчас не очень активно развивается, вложено огромное количество внимания. И разработчики PgBouncer на самом деле сталкивались с огромным количеством проблем.
Первые проблемы, которые уже относительно далеко от текущего момента. Мы внедрили Odyssey на первых production-системах и все нормально работало, пока у нас друзья из Postgres Professional не собрались бенчмаркить Odyssey. И они нам сообщили, что у нас в production работает система, в которой есть утечки памяти. Это было прямо удивительно. Официального релиза тогда не было, но нам сообщили, мы починили.
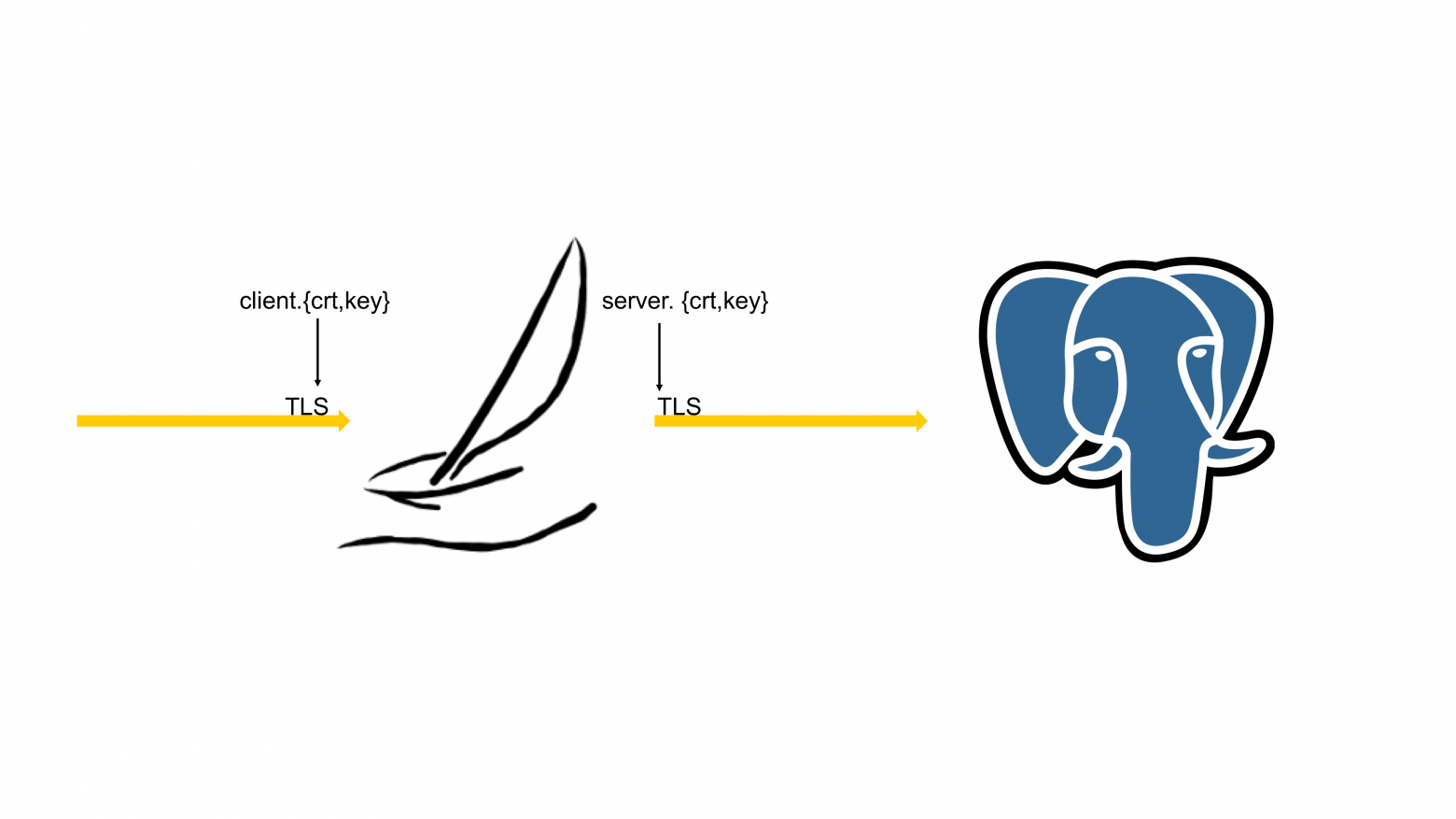
Дальше было интереснее. Как на входе в Odyssey, так и на выходе из Odyssey есть TLS-шифрование. И этому TLS-шифрованию нужны сертификаты. И эти сертификаты могут меняться.
И Odyssey для того, чтобы сертификат можно было заменить, перечитывал этот сертификат. Замечательный масштабированный connection pooler обращается к файловой системе, которая внезапно становится не масштабируемой, потому что при достаточно большой волне входящих TLS-соединений, все, что делает connection pooler, это перечитывает и перечитывает, и перечитывает множество TLS-сертификатов.
Эта проблема выразилась в довольно сложной отладке, потому что возникла неожиданно, когда перезагрузили вообще все.
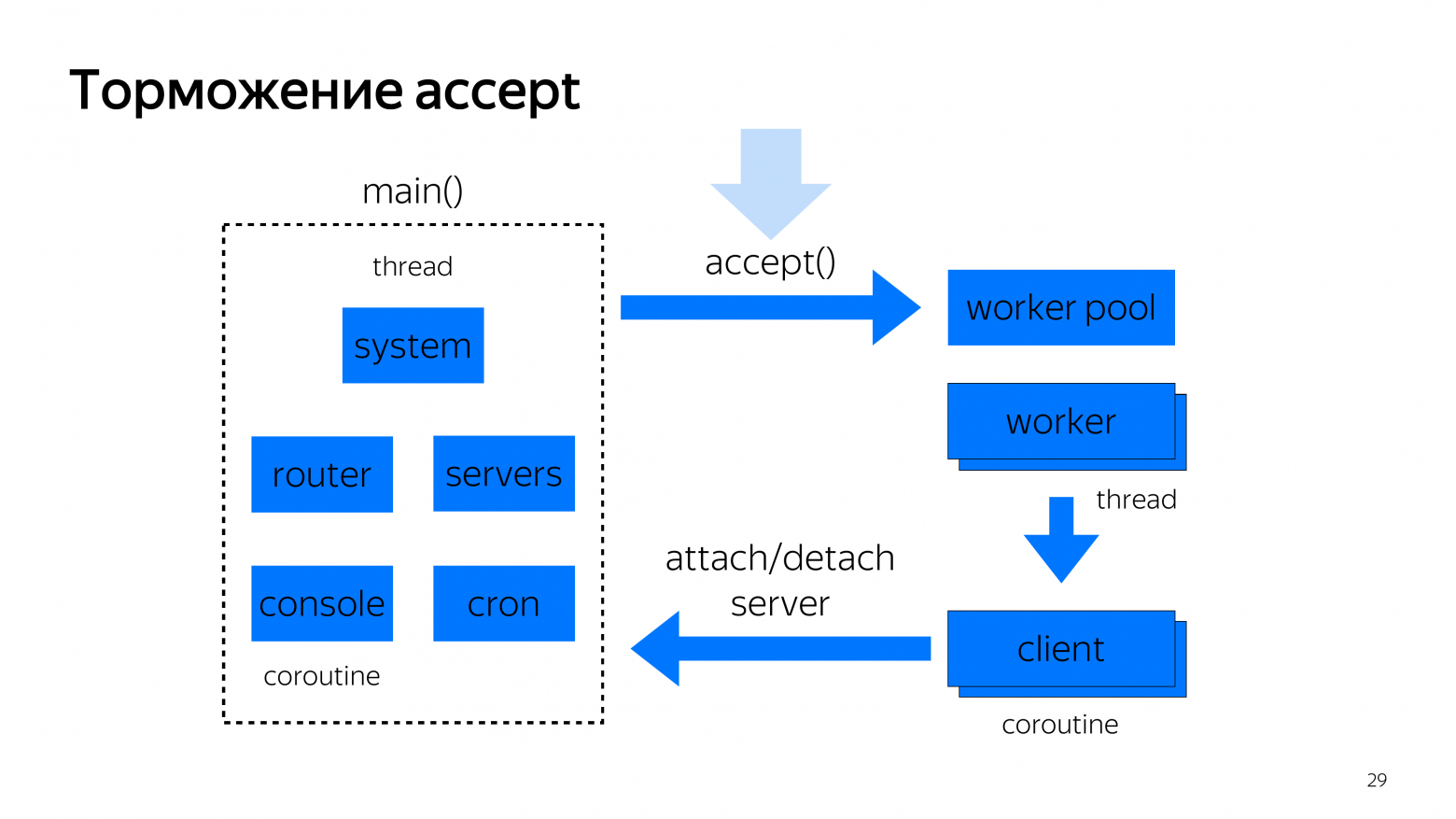
Эту проблему починили, но возникла другая проблема с тем, что, если приходят одновременно 20 000-30 000 входящих TLS-соединений, многопоточный pooler сразу все TLS-соединения заэксептит. И после этого начнет TLS handshake с каждым из них. Если у вас стоит тайм-аут на TLS handshake, например, 3 секунды и вы одновременно проводите 30 000 операций TLS handshake, то с достаточно высокой вероятностью успехом не завершится ни один из них.
Поэтому нам пришлось делать торможение accept и делать инверсию приоритетов, т. е. когда мы понимаем, что сейчас можно хэндшейкить еще кого-то, то мы берем последнего, кто пришел, потому что у него наименьшая вероятность в будущем сломаться на середине handshake по тайм-ауту.

Другая проблема, которую мы обнаружили относительно недавно, заключается в том, что недавно в Postgres было добавлено шифрование, которое называется GSSAPI.
Суть в том, что теперь Postgres ожидает либо присоединение, либо нормальный стартап-пакет, либо пакет с просьбой установки TLS-соединения, либо пакет с просьбой GSSAPI.
И PSQL первым отправит пакет на запрос с GSSAPI. Ни PgBouncer, ни Odyssey на момент выпуска 12 Postgres не поддерживали этот пакет. И говорили, что мы не знаем, что ты просишь и на всякий случай разрываем соединение. Эту проблему мы сейчас починили.

Pooler должен понимать, что у него запросили GSSAPI, корректно ответить, что он его не поддерживает. И только после этого клиент попросит TLS-соединение.
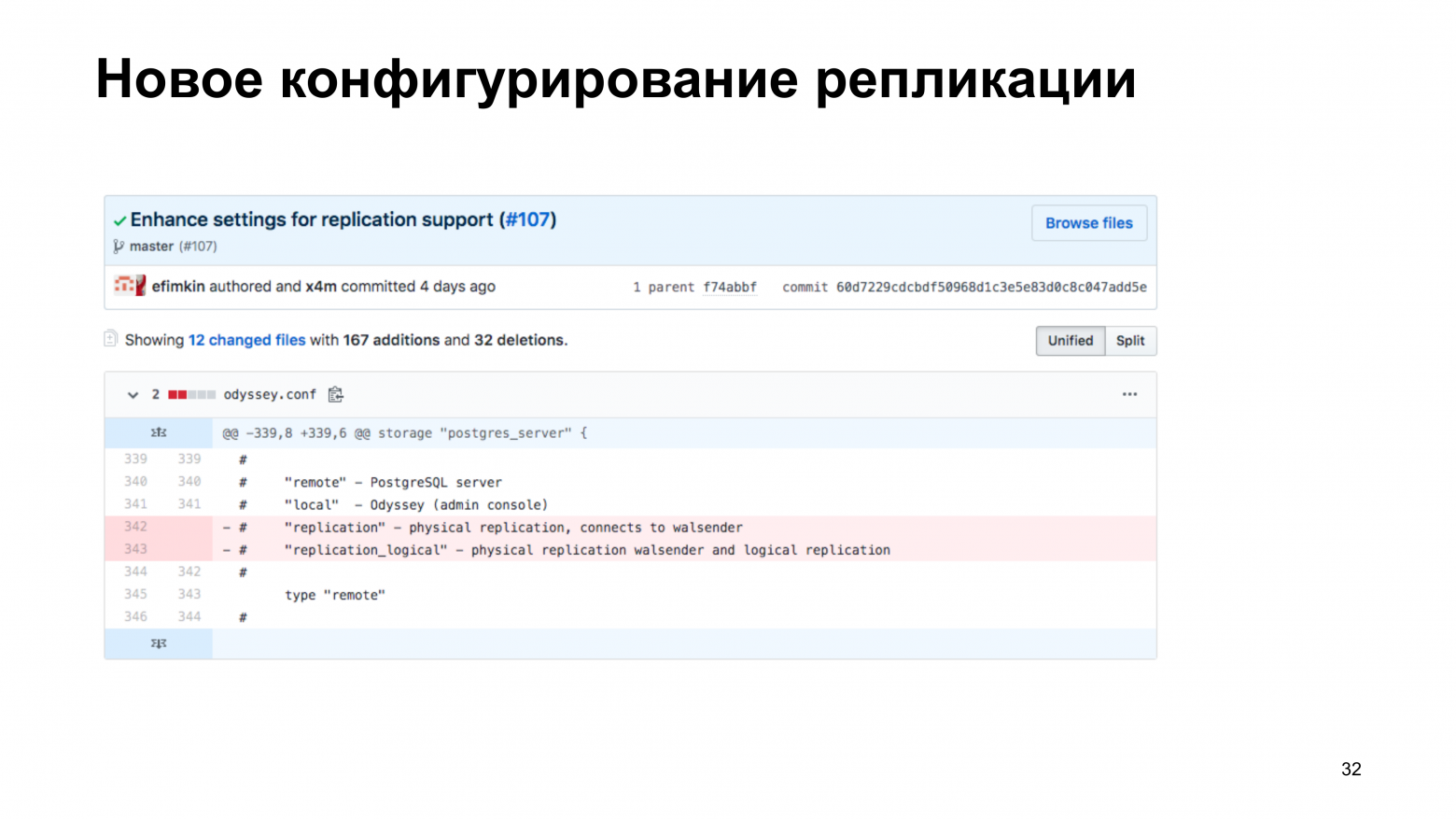 Через Odyssey возможно прохождение логической или физической репликации. Для этого у нас были в версии 1.0 созданы специальные storages, в которых мы говорим, что этот storage предназначен для логической или физической репликации. Но с настройкой возникли проблемы. И Евгений предложил использование более эффективного способа настройки, когда у нас никакой настройки про репликации нет. Но если приходит клиент и просит подключить его не к бэкенду, а к walsender, то мы идем в базу данных и спрашиваем: «Ему можно?». И база данных говорит: «Нет, ему нельзя делать basebackup» или «Да, хорошо, открываем для него walsender с логической репликацией из определенной базы данных».
Через Odyssey возможно прохождение логической или физической репликации. Для этого у нас были в версии 1.0 созданы специальные storages, в которых мы говорим, что этот storage предназначен для логической или физической репликации. Но с настройкой возникли проблемы. И Евгений предложил использование более эффективного способа настройки, когда у нас никакой настройки про репликации нет. Но если приходит клиент и просит подключить его не к бэкенду, а к walsender, то мы идем в базу данных и спрашиваем: «Ему можно?». И база данных говорит: «Нет, ему нельзя делать basebackup» или «Да, хорошо, открываем для него walsender с логической репликацией из определенной базы данных».
Кстати, это break inEnhaced. В версии 1.1, которая должна скоро выйти, эти два способа конфигурирования будут устранены, потому что, по сути, они будут не нужны. Т. е. вам достаточно удалить строчки в конфиге, которые создавали. И после этого все будет работать так же, как раньше.

Управление количеством серверов – это основная задача connection pooler. Connection pooler должен делать как можно меньше серверных соединений. Но в конфиге у нас есть лимит. Пользователь pooler’а говорит, что для определенной базы данных и комбинации ее с пользователем открывай максимум 1 000 соединений.
И Odyssey имел достаточное логическое поведение, что, если к нам приходят 1 000 входящих клиентских соединений, то мы одновременно открываем 1 000 серверных соединений, потому что все нужны. По факту, это не очень хорошая идея. И в коде PgBouncer мы потом нашли довольно длинный комментарий на тему того, что открытие серверного соединения значительно дороже, чем выполнение большинства OLTP-запросов. Поэтому даже если pooler сконфигурирован в режиме большого количества соединений в пуле, то не нужно открывать их все сразу.
И эту проблему мы нашли на сервисах, у которых периодическая нагрузка с небольшими пиками, которые могли в итоге триггерить необходимость открытия большого количества серверных соединений. Сейчас у нас есть настройка, которая говорит, что мы открываем одновременно не больше, например, 4-х соединений. Это все равно быстрее, чем это делает PgBouncer, но тем не менее мы не откроем все до лимита.

Вообще, управление количеством сервером – это задача для ML. Сейчас на достаточно рваной нагрузке от сервиса и PgBouncer, и Odyssey – это обычные графики. Их вверх подбрасывают, вниз они падают. Это неправильно.
Хороший pooler должен предсказать, сколько ему соединений понадобится. У него должна быть какая-то стратегия. И он должен этой стратегии придерживаться. Но мы пока не придумали хороший ML-способ, который бы предсказывал будущее. И как только научимся, сразу сделаем.

Управление клиентскими соединениями тоже оказалось в некотором смысле проблемой, потому что мы изначально выкатывались на высоконагруженных базах данных, в которых есть десятки тысяч входящих клиентских соединений. И в них, после того, как мы прошлись по предыдущим граблям, все стало хорошо.
После того, как мы начали выкатываться на маленькие базы, на половинку процессорного ядра, мы столкнулись с другой проблемой. Бывают сервисы, которые приходят в connection pooler, говорят половину пакета и молчат. У них недостаточно времени для того, чтобы Python сказал что-то еще. И это было совершенно неожиданным, потому что может оказаться, что они все такие. Нам нужно зависших клиентов просто выкидывать.
Мы пошли в код PgBouncer и нашли там длинный комментарий о том, что медленные клиенты – это такая же проблема, как и слишком быстрые клиенты. И что если клиент находится в состоянии аутентификации или установки TLS handshake, но ничего не говорит 15 секунд, то PgBouncer его выкидывает. Мы теперь делаем так же. Кстати, этого не было в версии 1.0. Это, видимо, будет в одном из следующих релизов.

Настройка client_max_routing отвечает за количество одновременно устанавливаемых TLS handshakes. И нужна для того, чтобы инвертировать приоритеты при входящей волне TLS-соединений.

Мы старались сделать все, как можно проще, но получилось вот так.

Odyssey может слушать одновременно несколько портов, при этом с разными настройками, с разными TLS-соединениями. И за это отвечает блок конфигурации listen.
Лучшая конфигурация (документация) по Odyssey – это не раздел документации, а конфиг. Если прочитать конфиг от начала и до конца, то становится понятно, как это работает.
Listen говорит о том, какой порт на каком интерфейсе открыть и как именно его слушать.

Раздел конфигурации Storage – это описание способа соединений с физически существующей базой данных. Там описывается, что это либо remote, либо local. Local – это административная консоль, т. е. то, что называлось PgBouncer в PgBouncer.

И последнее, что надо настроить – это связки database и user, в которых мы описываем, какого размера должен быть пул. Описываем, через какое время нужно отключать клиента, если ему не удалось найти сервер. И нужно ли пробрасывать ошибки.
Кстати, одна из настроек Postgres – это client_fwd_error. Если вы ставите «no», то мы имитируем поведение Bouncer. Т. е. если по какой-то причине мы не можем установить соединение с сервером, мы бросим ту же самую ошибку, которую бросает Bouncer. Если тут будет по дефолту написано «yes», то мы перебросим вам ту ошибку, которую вам пытался сказать Postgres.
Pool_cancel и pool_rollback – это настройки, которые говорят о том, что если у нас порвалось клиентское соединение, то должны ли мы откатить транзакцию, которая находилась в прогрессе или должны ли мы отправить cancel выполняющемуся запросу.
Application_name_add_host – это аналогичная настройка Bouncer, которая говорит о том, что нам нужно добавить ip-адрес клиентского соединения к application_name серверного соединения.
И последняя настройка, которую мы недавно добавили, это quantiles времен транзакций и quantiles времен запросов для улучшения мониторинга.

Зачем нужны квантили? Bouncer возвращает вам среднее время транзакции и среднее время запроса. Но среднее время не дает вам никакого понимания о том, что на самом деле происходит. Если у вас есть 10 % очень медленных запросов, а все остальные запросы мгновенные, то в среднем вы увидите, что база как-то работает. А на самом деле 10 % пользователей уже страдают.
В этом плане среднее время ответа – это время, которое не характеризует ничего. При этом 0,99 квантиль говорит о том, что 99 % ответов укладываются в данном случае в 1,273 миллисекунды. И он уже достаточно хорошо показывает, что ваша база совсем сложилась или просто немножко там стало похуже из-за того, что там есть какие-то проблемы с интерфейсом или какие-то проблемы с дисковой подсистемой, или какие-то начались cron-процессы. И наличие квантилей запросов помогают лучше диагностировать и лучше мониторить вашу систему. Единственное, что квантили лучше выводить на графике, потому что мгновенные значения квантилей – это тоже не очень хорошо помогает в диагностике.
Мониторинг достаточно стандартный у Odyssey. Мы его унаследовали в основном от PgBouncer.
Utilization – это процессорное время выполнения воркеров Odyssey. Если у вас выделено 4 воркера, то это означает, что Odyssey может работать на 4-х процессорах. И если вы видите утилизацию в 400 %, то, скорее всего, вам нужно больше воркеров.
Saturation и Errors в нашем случае – это одно и то же, потому что и то и другое сводится к анализу логов Odyssey, в которых нужно подсчитывать количество соединений, которым не удалось получить серверное соединение. Количество ошибок будет вам говорить о перегрузке времени центрального процессора. И какие-то другие ошибки, которые не вписываются в стандартный паттерн.

В Odyssey на данный момент нет технологий, которые называются online restart. В PgBouncer есть возможность установить новую версию и сказать PgBouncer – запусти новый процесс и забери старые дескрипторы у старого процессора PgBouncer. Но для нас эта возможность создавала больше проблем, потому что неожиданно она переставала работать, поэтому в Odyssey она не реализована.
Даже reload Odyssey вызывает некоторые проблемы, потому что вы потенциально изменили настройки серверных соединений, после этого Odyssey начинает все старые соединения сбрасывать, а новые заново набирать. По сути, reload немного эффективнее, чем просто restart сервиса, но это тоже отражается на графиках производительности.
И еще важная вещь про мониторинг Odyssey состоит в том, что необходимо проверять доступность всех портов, потому что вы прослушиваете два интерфейса – IPv4 и IPv6 и по какой-то причине после замены PgBouncer на Odyssey у вас PgBouncer не закрыл вовремя порт, то Odyssey запускается на интерфейсе IPv6. Радуется, что ему дали открыть порт, пытается запуститься на интерфейсе IPv4 и видит, что порт занят. И он решает, что его работа тут сделана, он будет жить на другом порту. После чего все клиенты, которые пришли к вам по IPv4 видят, что база данных лежит, ничего не работает.

Odyssey мы стараемся развивать как Open Source продукт. К нам приходят люди и предлагают свои фичи. И для нас это очень важно. Особенно после того, как в PgBouncer поддержали source-port, они теперь тоже масштабируемые, то нам нужны какие-то штуки, чтобы выделяться на их фоне. И если у вас есть пожелание что-то новое дописать, сообщайте мне об этом.
В частности, внешние контрибьюторы принесли к нам SCRAM аутентификацию.
И сейчас еще в процессе merge поддержка pause и resume. Эта возможность нужна, когда вы делаете апгрейд базы. Вы ставите на паузу всех клиентов. Они думают, что база данных тормозит. В это время вы базу данных выдираете из-под pooler. Делаете апгрейд, засовываете обратно. И оказался, что у вас уже 11 или 12, или 13 Postgres.

Вопросы
Привет! Игнатов Алексей из Озона. У меня вопрос. Когда появится хэбашичка для Odyssey? Т. е. hba аутентификация так же, как в Postgres pg_hba.conf и т. д.? Я на GitHub задавал вопрос этот, но там не поняли, что я имел в виду.
Видимо, я не понял.
Сейчас нельзя ограничить клиента по ip, по hostname и т. д., т. е. коннектиться можно отовсюду, как я понял.
Вы можете по iptables его ограничить.
Нет, iptables – это круто, но не очень. Потому что раз у нас Odyssey – аналог Bouncer, то, мне кажется, pg_hba аутентификация тут ложится очень ровненько.
Давайте еще это обсудим. Откроем Issue на GitHub.
Уже есть, я могу указать.
Да-да. Надо посмотреть и обсудить, как это сделать.
Отлично, спасибо!
Спасибо за доклад! В качестве идеи еще могу предложить добавить metrics endpoint, чтобы можно было с помощью Prometheus снимать статистику.
Да, приходили люди из Prometheus. Они предложили слинковаться с их библиотекой, что меня немного испугало. Тут два варианта: либо я реализую их библиотеку сам, что меня тоже пугает. Но, конечно, поддержка систем мониторинга важна. И парсить логи – это не то, что хотелось бы делать. Тут вопрос к Алексею. Нужно ли делать только Prometheus или есть еще какие-то системы, которые нужно поддержать? Давайте сразу всех посмотрим.
Я думаю, что Prometheus в какой-то степени уже стандарт в плане мониторинга, хотя многие, наверное, не согласятся. Но сам endpoints metrics довольно удобен, его можно использовать не только Prometheus’ом. Поэтому, я думаю, что это просто интерфейс для предоставления метрик наружу.
Какие системы мониторинга его еще понимают?
Zabbix умеет с этим работать. Как минимум, это очень удобный интерфейс, чтобы не парсить логи, как например, это нужно с Bouncer и не нужно открывать админскую консоль, чтобы посмотреть метрики. Можно сходить в endpoint и посмотреть.
Т. е. там нужно внутри Odyssey еще http-сервер?
Веб-сервер, да. Но это просто план, чтобы выделяться от Bouncer.
Это хороший план. Это звучит как план.
А блокчейн?
Блокчейн – это интересно, но не сейчас. Спасибо за вопрос.
У меня вопрос. Если какие-то планы по добавлению аудита в Prometheus, чтобы все запросы, которые проходят, можно было аудировать, заранее пресекать?
Была идея – добавить расширяемость в Odyssey для того, чтобы можно было написать какой-то модуль, который будет загружен, в котором будут хуки, которые могут подцепиться. Но если мы сейчас добавим расширяемость, то будет вопрос о том, чем расширять. Будет ли кто-то писать хуки для аудита? Я даже не знаю, что там может быть.
В этом вопросе про аудит есть две части. Поддержать возможность теоретически – да, обязательно надо сделать. Поддержать возможность по факту, т. е. я просто не специалист в аудите запросов. И если кому-то интересно потом написать модуль, который будет анализировать запросы, то давайте это делать. Мы обсудим, как это может выглядеть и какие кухи нужны, и сделаем. Спасибо за вопрос, интересная идея.
Андрей, ты говоришь, что не любишь англицизмы и тебе не нравится «connection pooler». И у меня есть довольно-таки неплохая альтернатива. Когда я учился в своем учебном заведении на микросхемотехнике, у нас была такая штука как мультиплексор. Можно говорить мультиплексор соединений.
Это был бы корректный термин, если у нас было одно серверное соединение.
По сути, мы мультиплексируем много клиентских соединений в какое небольшое количество серверных соединений.
Если бы у нас клиент был строго прибит к одному серверному соединению, это был бы мультиплексор. Дело в том, что, если мы перегрузим чужой термин, который значит немного больше, чем мы от него хотим, это будет хуже, чем использование иностранного слова. Давайте проголосуем, кому нравится больше pooler, кому мультиплексор. Мы в сообществе в состоянии решать, какая будет терминология в русском языке. Кто за мультиплексор? 2 человека. Кто за pooler? Ок, pooler победил.
Это просто была идея.
Идеи нужно обязательно перебирать.
Спасибо за доклад! У меня дополнение. Может быть, все-таки не Prometheus, потому что это будет вендерлог. И хоть я его люблю, но у клиентов бывают разные желания, может быть просто какой-то универсальный, которым можно дергать и собирать эти данные метрики, а уже сообщество само допишет библиотеки для Prometheus, для Cloudwatch, и для всего, что только возможно?
А нам что нужно сделать для этого в Odyssey?
Вы можете сделать call к Odyssey. Он вам вернет те метрики, которые вас интересуют. Это, наверное, это больше, чем хочется. Это, наверное, в долгосрочной перспективе хорошо.
Сейчас можно приконнектиться к консоли и выполнить команду show stats. Это не то же самое?
Это все-таки надо приконнектиться к консоли, а хочется попроще.
Наверное, надо писать exporter в Prometheus.
А exporter куда?
Exporter, который входит в консоль и метрику выводит.
Т. е. у нас есть другой процесс, который по Postgres протоколу приходит в Odyssey и спрашивает: «Как дела?». Odyssey говорит, как у него дела. А exporter при этом слушает какой-то порт и по http может ответить. Это интересная идея, потому что не будет зависимости внутри бинарника Odyssey. У нас с зависимостями Postgres на CentOS есть некая проблема со сборкой. И хотелось бы меньше зависимостей, чтобы было меньше проблем. Exporter – это хорошая идея. Спасибо. Мы, кстати, можем его писать не на C, а на чем-то попроще, например, на Go. Спасибо за идею. Какие еще вопросы есть?
Спасибо за доклад! Какие требования к компилятору? Какие лицензии?
Лицензии? Я не знаю, т. е. она open source. Есть исходный код, можете его забирать. Если продадите кому-то, то я порадуюсь за вас. Лучше всего этот вопрос задать на GitHub. Там есть значок справа с весами. Я думаю, что это про лицензию.
Хорошо, какой компилятор нужен?
GCC или Clang.
Это понятно. А стандарт?
Стандарт C99.
Андрей, чем-то из опытной эксплуатации можете поделиться? Сколько коннектов сейчас держатся? Какие в основном ошибки, если есть?
Мы ограничиваем соединение 20 000 клиентскими соединений. Если приходит одновременно даже 10 000 соединений все равно – это время недоступности. Т. е. какие-то соединения успевают пройти в базу, но при этом им центрального процессора не очень хватает, чтобы реально выполнять запросы в течение довольно длительного промежутка времени, который измеряется секундами, а иногда и больше, если что-то идет не так.
Какие еще числа? Если больше 500 MB оперативной памяти используется, то это что-то подозрительное, что-то идет не так. Для программы, которая байтики перекладывает, это слишком много.
Для 10 000 соединений, сколько ставите?
Мы обычно ставим половину от того, что доступно на контейнере виртуальной машины, т. е. выставляем половину из доступных центральных процессоров. 10 000 соединений работает хоть на одном процессоре, просто вопрос – за сколько они похэндшейкаются? Т. е. TLS handshake – это до 100 миллисекунд на средненьком ядре. Если 100 миллисекунд верхняя оценка и взять один коннект, то 10 соединений в секунду заходит. Очень мало довольно. Если у вас будет 10 процессорных ядер, то 100 соединений в секунду. Уже жить можно, уже кто-то запросы сможет выполнить. 100 миллисекунд – это пессимистичная оценка. По факту соединения могут быть быстрее и 10 миллисекунд. Но все равно TLS handshake – это единица до десятки миллисекунд затрат центрального процессора.
В Odyssey.conf есть max clients. Это к чему относится? Это всего количество клиентских соединений, которые можно сделать к instance Odyssey или это соединения per_worker? И есть ли вообще возможность ограничить количество соединений на конкретного клиента? Т. е. у нас есть user1 в базе и я ему хочу разрешить, например, 50 коннектов к Odyssey, а есть user2 и я ему хочу разрешить, например, 100. Есть ли такая возможность?
Да, такая возможность есть. Но начнем издалека. Когда мы обрабатываем клиентское соединение до того, как мы сделали TLS handshake, мы не знаем, кто к нам пришел. Т. е. пользователь скажет свой логин и пароль тогда, когда уже зашифруется. А установление TLS соединения для нас уже какой-то ресурс, который мы не хотим просто так потратить, если мы находимся под перегрузкой. Поэтому max clients – это ограничение на все количество соединений. И мы не знаем, кто там конкретно.
В max clients устанавливается 20 000 и это 20 000 входящих TCP соединений. Если к нам пришел 20 001-ый коннект, мы ему говорим: «Пока» и не начинаем с ним TLS handshake. Вот pool size. И если поставить pool size «1», то это будет означать, что после того, как пользователь пришел вторым соединением, а первое еще находится в транзакции, то он будет ждать какое-то время. И если он не дождется окончания транзакции у первого серверного соединения, то ему покажут код ошибки 5300: too many clients for this pool, т. е. sorry, приходи потом.
Т. е. в итоге это сервер wait настройка или можно все-таки для каждого клиента распределить свой pool size?
Database. И внутри database есть user. Для каждого user можно определить pool size. Вы можете это сделать на стороне Postgres. Postgres вам ответит так же: «too many clients». И Odyssey пробросит ту же самую ошибку. И это поведение эквивалентное, но оно включает в себя round trip до postmaster. Postmaster увидит, что форкаться не надо и сразу ответит. Это лишние расходы, которые можно не делать, если установить у себя pool size. У себя мы устанавливаем pool size.
Привет! Я смотрю на авторизацию у тебя. В Bouncer у нас отдельный файлик: пользователь и MD5 hash. А тут у вас получается, что в конфиге нужно прописывать роли и MD5 hash?
Да.
Т. е. они не вынесены отдельно для удобства администрирования?
Вы можете включать конфиги в конфиге, т. е. в конфиге можно указать директиву include и прочитать другой конфиг.
Где точно такая же должна портяночка, да?
Да, будет точно такая же структура. Вы можете Storage настроить в одном, listen в том же, а настройки баз данных вынести. Но конфиги стоит улучшать. Недавно пришел человек на GitHub и говорит: «Давайте сделаем исследование пользователей, т. е. какие-то общие настройки выделим в одного пользователя и еще три от него наследуются, и дополнят его настройки своими». Я думаю, что это надо реализовать. В том числе можно улучшить и включение других конфигов, чтобы можно было вынести чувствительную информацию в какое-то безопасное место. Например, на флешку, которую админ выдергивает и убегает с этой информации. Это я так фантазирую.

