У меня есть цель — разобраться в том, что же происходило в 60-70-е годы в Xerox PARC и в окрестностях, как так вышло, что несколько коллективов инженеров, работая рука об руку, создали невероятные технологии, которые определили наше настоящее, а их идеи будут определять будущее. Почему этого не происходит сейчас? (а если происходит, то где?). Как собрать подобный коллектив? Где же мы повернули не туда? Какие идеи мы пропустили, а стоило бы к ним повнимательнее присмотреться?
Предлагаю вашему вниманию перевод начала большого текста Алана Кея (150 000 знаков), на который он неоднократно ссылается во всех своих выступлениях и ответах на Quora и HackerNews.
Кто готов помогать с переводом — пишите в личку.
Стимулов к появлению ООП было много, но два из них были особенно важны. Один крупномасштабный: придумать для сложных систем хороший подход, позволяющий скрывать их устройство. Другой поменьше: найти более удобный способ распределять вычислительные мощности, а то и вовсе избавиться от этой задачи. Как обычно бывает с новыми идеями, аспекты ООП формировались независимо друг от друга.
Любая новинка проходит несколько стадий принятия — как своими создателями, так и всеми остальными. Вот как это происходит у создателей. Сначала они замечают, что в разных проектах используется будто бы тот же подход. Позднее их предположения подтверждаются, но пока никто не осознает грандиозного значения новой модели. Затем происходит великий сдвиг парадигмы и модель становится новым способом мышления. И наконец она превращается в закостенелую религию, от которой сама и произошла. Все остальные принимают новинку по Шопенгауэру: сперва ее осуждают, называя безумной; через пару лет ее уже считают очевидной обыденностью; в конце концов те, кто ее отвергал, объявляют себя ее создателями.
То же было со мной. Будучи программистом ВВС США, я не раз замечал в программах намеки на ООП. Впервые на компьютере Burroughs 220 тренировочного авиационного командования (TAK) — в способе переноса файлов с одной инсталляции на другую. В те времена не было стандартных операционных систем и форматов файлов, поэтому какой-то программист (я до сих пор не знаю кто) нашел изящное решение: каждый файл он делил на три части. Сами данные лежали в третьей части — она могла быть любого размера и формата. Во второй части хранились процедуры B220, которые умели копировать данные, в том числе отдельные поля, и складывать их в третью часть. Ну а первая часть представляла собой массив относительных указателей на точки входа процедур второй части (исходные указатели хранились в стандартном порядке и имели ясное предназначение). Что и говорить, идея была отличная и использовалась во многих последующих системах. Она благополучно исчезла, когда пришел COBOL.
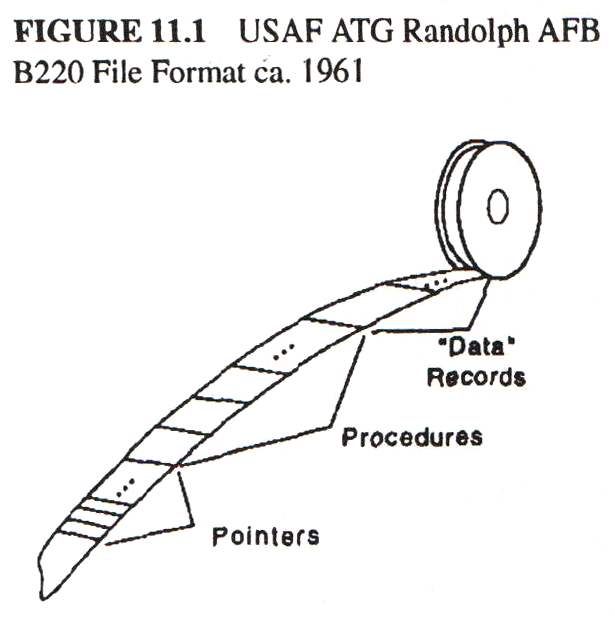
Моя вторая встреча с зачатками ООП состоялась, когда командование решило заменить 220-е машины на Burroughs 5000. Тогда я не имел достаточно опыта, чтобы оценить новые идеи в полной мере, но сразу обратил внимание на сегментированную систему хранения, на то, как эффективно компилировались языки высокого уровня и исполнялся байт-код, на автоматические механизмы вызова подпрограмм и переключения между процессами, на чистый код для совместного доступа, на механизмы защиты и т. д. Я заметил, что доступ к таблице программных ссылок походит на то, как в файловой системе B220 модулю давались интерфейсы процедур. Но все же моим главным уроком в тот раз были не идеи ООП, а трансляция и анализ языков высокого уровня.
После ВВС я, доучиваясь в университете, работал в Национальном центре атмосферных исследований и в основном занимался системами извлечения для больших массивов погодных данных. Я заинтересовался симуляцией — как одна машина может симулировать другую, — но времени хватило, только чтобы создать одномерный вариант поблочной пересылки битовых полей (bitblt) на CDC 6600, чтобы симулировать разные размеры слов. Остальное время уходило на учебу (а если честно, на студенческий театр). Когда я работал в Чиппева-Фолс и помогал отлаживать Burroughs 6600, то наткнулся на статью Гордона Мура, в которой он пророчил экспоненциальный рост плотности и снижение стоимости интегральных схем на много лет вперед. Предсказание потрясающее, но вряд ли я мог его постичь, стоя перед занимавшим целую комнату B6600 с его 10 МГц и фреоновым охлаждением.
По счастливой случайности осенью 1966 года я, ничего не подозревая, попал в аспирантуру Университета Юты. Ну то есть я не знал ни об Управлении перспективных исследовательских проектов (ARPA), ни об их проектах, ни о том, что главной целью команды было решить проблему скрытой линии в трехмерной графике. Я ничего этого не знал — пока в поисках работы не забрел в кабинет Дейва Эванса. У него на столе лежала огромная стопка коричневых папок. Он вручил мне одну из них со словами: «На, читай».
Такую папку получал каждый новичок. Назывались они все одинаково — «Sketchpad: графическая система коммуникации между человеком и компьютером». Система была удивительная и весьма отличалась от всего, что мне попадалось раньше. Вот ее три заслуги, которые проще всего осознать: 1) изобретение современной интерактивной компьютерной графики; 2) описание сущностей с помощью «эталонных чертежей», по которых затем можно производить конкретные экземпляры; 3) графические «рамки», применяя которые к эталонам, можно создавать наборы связанных сущностей и с их помощью управлять машиной. Структуры данных в этой системе понять было сложно. Единственное, что казалось немного знакомым, — это передача процедурам указателей для перехода по ним в подпрограммы (так называемая обратная индексация, как в файловой системе B220). Это первая оконная система с отсечением изображения и изменением масштаба. Ее виртуальный холст простирался на полкилометра по обеим осям!






Переваривая прочитанное, я сел за свой рабочий стол. На нем лежала куча пленок, распечатка программы и записка: «Это Алгол для 1108-го. Не работает. Почини». Новенькому аспиранту — новенькое задание, за которое никто не хотел браться.
Понять документацию было просто невозможно. Язык был вроде как Алгол для Case-Western Reserve 1107, но основательно переработанный и названный Симулой. Документация такая, будто кто-то написал ее на норвежском, а затем транслитерировал на английский (между прочим, так оно и было). Некоторые слова, например activity и process, использовались вообще в другом смысле.
Вместе с еще одним аспирантом мы раскатали 25-метровый рулон в коридоре и стали ползать по нему, изучая код и перекрикиваясь, когда находили что-то интересное. Самой странной частью кода был распределитель памяти, который, в отличие от Алгола, не использовал стек. Пару дней спустя мы поняли почему: в Симуле память отводилась под структуры, которые очень походили на экземпляры объектов Sketchpad, а еще там имелись своего рода описания, по которым и создавались независимые друг от друга объекты. То, что в Sketchpad было эталонами и экземплярами, в Симуле называлось activity и process. Более того, Симула оказалась процедурным языком для управления Sketchpad-подобными объектами, то есть опережала Sketchpad с его «рамками» в плане гибкости (но уступала ему в изящности).
Симула удивила и изменила меня навсегда. Она стала последней каплей: очередная встреча с идеями ООП позволила мне осознать их в общем смысле, я словно испытал катарсис. В математике я занимался абстрактными алгебрами, то есть небольшими наборами операций, универсально применимых к самым разным структурам. В биологии — клеточным метаболизмом и высокоуровневым морфогенезом, где простые механизмы управляют сложными процессами, а универсальные «кирпичики» организма могут превращаться в то, что нужно именно здесь и сейчас. Файловая система B220, сам B5000, графическая система Sketchpad и, наконец, Симула использовали ту же идею для разных целей. За несколько дней до этого главный конструктор B5000 и профессор в Университете Юты Боб Бартон на одном из выступлений сказал так: «Базовый принцип рекурсивного проектирования состоит в том, что сущности на любом уровне вложенности должны обладать равными возможностями». Тогда я впервые примерил эту идею к компьютеру и понял, что совершенно зря его делят на более слабые концепции — структуры данных и процедуры. Почему бы не делить его на маленькие компьютеры, как в системах с разделением времени? Только не на десять, а сразу на тысячи, каждый из которых симулировал бы полезную структуру.
Мне на ум пришли монады Лейбница, Платон с его «разделять всё на виды, на естественные составные части» и другие попытки обуздать сложность. Конечно, философия — это споры и мнения, а инженерное искусство — конкретные результаты. Где-то между ними — наука. Не будет преувеличением сказать, что Симула с тех пор стала для меня главным источником идей. Нет, я вовсе не хотел ее улучшать: меня влекли открывающиеся перспективы, совершенно новый подход к структуре вычислительных процессов. Правда, на осознание и эффективное внедрение новых идей ушел не один год.
Дейв Эванс считал, что в аспирантуре многому не научишься и, как и многие «подрядчики» ARPA, хотел, чтобы мы занимались настоящими проектами и не тратили слишком много времени на теорию, а диссертации посвящали лишь новейшим разработкам. Обычно Дейв устраивал своих подопечных консультантами. Так в начале 1967 года он познакомил меня с дружелюбным Эдом Чидлом — настоящим гением аппаратного обеспечения. Эд тогда работал в местной аэрокосмической фирме над, как он выражался, «маленьким компьютером». Конечно, первый персональный компьютер, LINC, создал не он, а Уэс Кларк, зато Эд хотел сделать машину для некомпьютерщиков. Например, он хотел запрограммировать ее на языке высокого уровня, например на Бейсике. «Может, лучше на JOSS?» — предложил я. «Ну давай», — ответил он. Вот так и начался наш с ним приятный проект, который мы назвали FLEX. Чем глубже мы забирались в разработку, тем лучше осознавали, что хотим добиться динамической симуляции и расширяемости. JOSS (да и никакой другой известный мне язык) не особенно подходил ни для первого, ни для второго. Симула отпала сразу — наш компьютер был слишком мал для нее. Красота JOSS заключалась в невероятном уровне внимания к пользователям — в этом плане его не превзошел ни один язык. Но для серьезных вычислений JOSS был слишком медленным, а еще в нем не было настоящих процедур, областей действия переменных и т. п. Эйлер, язык созданный Никлаусом Виртом, походил на JOSS, но имел гораздо больший потенциал. Он представлял собой обобщение Алгола по идеям, впервые высказанным ван Вейнгаарденом: типы убраны, многие моменты унифицированы, процедуры стали объектами первого класса и т. д. Что-то вроде Лиспа, но без особых мудреностей.

По примеру Эйлера, мы решили упростить Симулу, применив к ней те же методы. Компилятор Эйлера был частью его формального описания и его легко можно было перевести в байт-код, подобный тому, что использовался в B5000. Это подкупало — значит, маленький компьютер Эда мог исполнять чужие байт-коды, пусть их и приходилось эмулировать с помощью длинного и медленного микрокода. Одна проблема: компилятор Эйлера был написан по неудобным правилам грамматики расширенного предшествования, отчего в синтаксисе приходилось идти на компромиссы. Например, запятая могла использоваться только в одной роли, потому что грамматика предшествования не позволяет иметь пространство состояний. Сначала я взял парсер Флойда — Эванса, работавший по принципу «снизу вверх» (и созданный на основе компилятора компиляторов Джерри Фельдмана), а позднее переключился на подход «сверху вниз». Для некоторых попыток я брал META II — язык для написания компиляторов Шорра. В конце концов транслятор закрепился в пространстве имен языка.
Мы думали, что наибольшее влияние на семантику FLEX должна оказать Симула, а не Алгол или Эйлер, но выходило иначе. А еще не было понятно, как же пользователи будут взаимодействовать с системой. Даже у первого компьютера Эда был экран (для графиков и т. п.), а LINC был оснащен «стеклянным телетайпом». Нам же по карману были лишь 16 тысяч 16-битных слов — о Sketchpad на такой машине можно было и не мечтать.
Итак, дело было в первой половине 1967-го. Мы всё думали над FLEX, а в Университет Юты приехал Даг Энгельбарт — визионер просто таки библейских масштабов. Он был одним из прародителей того, что мы с вами называем персональным компьютером. Он возил с собой 16-миллиметровый проектор с дистанционным управлением — СТАРТ/СТОП вместо курсора, ведь тогда курсоры были еще в новинку. Главной идеей, которую он продвигал в ARPA, была Онлайн-Система (NLS, oNLine Systems), призванная «усилить человеческий интеллект» с помощью интерактивного средства перемещения по «векторам мыслей в пространстве концепций». Даже по сегодняшним стандартам возможности его детища поражают воображение: гипертекст, графика, несколько рабочих панелей, эффективная навигация, удобный ввод команд, средства совместной работы и т. д. — целый мир понятий и абстракций. Благодаря Энгельбарту все, кто желал «усилить свой интеллект», сразу понимали, какими должны быть интерактивные компьютеры. Вот и я немедленно позаимствовал многие его идея для FLEX.

Симбиоз человека и компьютера, стоявший в центре всех проектов ARPA, и маленький компьютер Эда вновь напомнили мне о законе Мура, но на этот до меня наконец дошло его значение. Я осознал, что машина, занимавшая раньше целую комнату (тот же TX-2 или даже B6600 на 10 МГц), теперь умещается на столе. Эта мысль меня напугала: стало ясно, что современный подход к компьютерам долго не протянет, и само слово «компьютер» приобретало новый смысл. Наверное, так же себя чувствовали люди, только что прочитавшие трактат Коперника и взглянувшие на новые Небеса с новой Земли.
Вместо пары тысяч учебных мейнфреймов, разбросанных по всей планете (даже сейчас, в 1992 году, в мире насчитывается всего около 4000 мейнфреймов IBM) и нескольких тысяч пользователей, обученных определенным приложениям, в мире будут миллионы персональных машин и пользователей вне досягаемости университетов и организаций. Откуда возьмутся приложения? Как люди будут учиться этому? Как разработчики ПО узнают, что нужно конкретному пользователю? Здесь прямо напрашивалась расширяемая система — такая, чтобы люди сами подгоняли ее под свои нужды (и даже могли дорабатывать). Благодаря успеху систем с разделением времени многие в ARPA это уже понимали. Грандиозная метафора о симбиозе человека и машины затмевала любые проекты и не давала им превратиться в религии, удерживая внимание на абстрактном Святом Граале — «усилении человеческого интеллекта».
Одной из интересных особенностей NLS был параметризированный интерфейс: пользователи сами могли задавать его в виде «грамматики взаимодействия» в своем компиляторе компиляторов TreeMeta. Примерно так же описал это Уильям Ньюман в своем «Обработчике реакций»: с помощью планшета и стилуса конечный пользователь или разработчик описывал интерфейс в традиционной грамматике регулярных выражений, где в каждом состояниями были процедуры, выполнявшие какие-либо действия (в NLS встраивание было возможно благодаря бесконтекстным правилам). Идея была заманчивая по многим причинам, особенной в варианте Ньюмана, но я видел в ней зияющий недостаток: грамматики вынуждали пользователя выходить в состояние системы, если он хотел запустить что-нибудь новое. Все эти иерархические меню или экраны, по которым нужно было сначала вернуться на верхний уровень, чтобы попасть куда-то еще. Здесь пригодилась бы возможность переходить из одного состояния в любое другое, что плохо укладывалось в теорию формальных грамматик. В общем, напрашивался более «плоский» интерфейс, но как сделать его достаточно функциональным и интересным?
Напомню, что FLEX был слишком мал для того, чтобы стать мини-NLS. Нам пришлось выкручиваться, чтобы внедрить в него хотя бы часть передовых идей, а в некоторых случаях и развить их. Я решил, что универсальное окно в огромный виртуальный мир в духе Sketchpad лучше, чем тесные горизонтальные панели. Мы с Эдом придумали алгоритм отсечения изображения, очень похожий на тот, что создал Сазерленд в Гарварде: он со своими студентами разработал такой алгоритм одновременно с нами в рамках проекта по созданию шлема «виртуальной реальности».
На FLEX ссылки на сущности были обобщением дескрипторов B5000. Вместо разных форматов ссылок на числа, массивы и процедуры, дескрипторы FLEX содержали два указателя: один — на «эталон» объекта, а другой — на его конкретные экземпляры (мы потом поняли, что первый указатель лучше класть в экземпляры, чтобы сэкономить место). К работе с обобщенными задачами мы подошли иначе. В B5000 были l-значения и r-значения — в некоторых случаях этого было достаточно, но для более сложных объектов нужны было что-то другое. Вот пример. Пусть a — разреженный массив, элементы которого по умолчанию имеют значение 0. Тогда a[55] := 0 все равно приведет к созданию элемента, потому что «:=» — оператор, а a[55] дереференцируется в l-значение, прежде чем кто-либо успеет понять, что r-значение — это значение по умолчанию. При этом неважно, чем на самом деле является a: массивом или процедурой над массивом. Здесь нужно что-то вроде a(55, ':=', 0). При таком подходе программа сначала проверит все нужные операнды и только потом, если нужно, создаст элемент. Другими словами, «:=» тут уже не оператор, а вполне себе указатель на метод сложного объекта. На то, чтобы понять это, мне потребовалось неприлично много времени. Наверное, потому что пришлось перевернуть традиционное представление об операторах, функциях и т. п. Только после этого я осознал, что поведение должно быть частью объекта. Проще говоря, объект — это набор пар «ключ-значение», где в роли значений выступают определенные действия. У Рудольфа Карнапа есть книга по логике, которая помогла мне понять, что традиционные способы расширения программ и «содержательные» дефиниции обладают одинаковыми возможностями, но последние интуитивно понятнее и удобнее.

Как и в Симуле, для приостановки и возобновления работы объектов использовалась сопрограммная управляющая конструкция. Постоянные объекты (файлы, документы) были для машины приостановленными процессами и сортировались в соответствии с их статичными областями переменных. Пользователь мог видеть эти области на экране и выбирать нужную. Сопрограммы использовались и для организации циклов. Оператор while проверял генераторы, которые возвращали false, когда не могли предоставить новое значение. Для связи нескольких генераторов применялись булевы значения. Например, for-циклы писались так:
while i <= 1 to 30 by 2 ^ j <= 2 to k by 3 do j<-j * i;
Конструкция… to… by… здесь что-то вроде сопрограммы. Многие из этих идей впоследствие появились и в Smalltalk, но в более сильной форме.
Еще одна интересная управляющая конструкция FLEX — when. Она работала на «мягких прерываниях» от событий.

Продолжение следует...
За перевод спасибо Алексею Никитину.
(Кто считает, что эта статья важная и хочет помочь с переводом — пишите в личку или alexey.stacenko@gmail.com)
Переводы Алана Кея:
Ричард Хэмминг

Предлагаю вашему вниманию перевод начала большого текста Алана Кея (150 000 знаков), на который он неоднократно ссылается во всех своих выступлениях и ответах на Quora и HackerNews.
Кто готов помогать с переводом — пишите в личку.
I. 1960–66 — Становление ООП и другие новые идеи 60-х
Стимулов к появлению ООП было много, но два из них были особенно важны. Один крупномасштабный: придумать для сложных систем хороший подход, позволяющий скрывать их устройство. Другой поменьше: найти более удобный способ распределять вычислительные мощности, а то и вовсе избавиться от этой задачи. Как обычно бывает с новыми идеями, аспекты ООП формировались независимо друг от друга.
Любая новинка проходит несколько стадий принятия — как своими создателями, так и всеми остальными. Вот как это происходит у создателей. Сначала они замечают, что в разных проектах используется будто бы тот же подход. Позднее их предположения подтверждаются, но пока никто не осознает грандиозного значения новой модели. Затем происходит великий сдвиг парадигмы и модель становится новым способом мышления. И наконец она превращается в закостенелую религию, от которой сама и произошла. Все остальные принимают новинку по Шопенгауэру: сперва ее осуждают, называя безумной; через пару лет ее уже считают очевидной обыденностью; в конце концов те, кто ее отвергал, объявляют себя ее создателями.
То же было со мной. Будучи программистом ВВС США, я не раз замечал в программах намеки на ООП. Впервые на компьютере Burroughs 220 тренировочного авиационного командования (TAK) — в способе переноса файлов с одной инсталляции на другую. В те времена не было стандартных операционных систем и форматов файлов, поэтому какой-то программист (я до сих пор не знаю кто) нашел изящное решение: каждый файл он делил на три части. Сами данные лежали в третьей части — она могла быть любого размера и формата. Во второй части хранились процедуры B220, которые умели копировать данные, в том числе отдельные поля, и складывать их в третью часть. Ну а первая часть представляла собой массив относительных указателей на точки входа процедур второй части (исходные указатели хранились в стандартном порядке и имели ясное предназначение). Что и говорить, идея была отличная и использовалась во многих последующих системах. Она благополучно исчезла, когда пришел COBOL.
Моя вторая встреча с зачатками ООП состоялась, когда командование решило заменить 220-е машины на Burroughs 5000. Тогда я не имел достаточно опыта, чтобы оценить новые идеи в полной мере, но сразу обратил внимание на сегментированную систему хранения, на то, как эффективно компилировались языки высокого уровня и исполнялся байт-код, на автоматические механизмы вызова подпрограмм и переключения между процессами, на чистый код для совместного доступа, на механизмы защиты и т. д. Я заметил, что доступ к таблице программных ссылок походит на то, как в файловой системе B220 модулю давались интерфейсы процедур. Но все же моим главным уроком в тот раз были не идеи ООП, а трансляция и анализ языков высокого уровня.
После ВВС я, доучиваясь в университете, работал в Национальном центре атмосферных исследований и в основном занимался системами извлечения для больших массивов погодных данных. Я заинтересовался симуляцией — как одна машина может симулировать другую, — но времени хватило, только чтобы создать одномерный вариант поблочной пересылки битовых полей (bitblt) на CDC 6600, чтобы симулировать разные размеры слов. Остальное время уходило на учебу (а если честно, на студенческий театр). Когда я работал в Чиппева-Фолс и помогал отлаживать Burroughs 6600, то наткнулся на статью Гордона Мура, в которой он пророчил экспоненциальный рост плотности и снижение стоимости интегральных схем на много лет вперед. Предсказание потрясающее, но вряд ли я мог его постичь, стоя перед занимавшим целую комнату B6600 с его 10 МГц и фреоновым охлаждением.
Графическая система Sketchpad и Симула
По счастливой случайности осенью 1966 года я, ничего не подозревая, попал в аспирантуру Университета Юты. Ну то есть я не знал ни об Управлении перспективных исследовательских проектов (ARPA), ни об их проектах, ни о том, что главной целью команды было решить проблему скрытой линии в трехмерной графике. Я ничего этого не знал — пока в поисках работы не забрел в кабинет Дейва Эванса. У него на столе лежала огромная стопка коричневых папок. Он вручил мне одну из них со словами: «На, читай».
Такую папку получал каждый новичок. Назывались они все одинаково — «Sketchpad: графическая система коммуникации между человеком и компьютером». Система была удивительная и весьма отличалась от всего, что мне попадалось раньше. Вот ее три заслуги, которые проще всего осознать: 1) изобретение современной интерактивной компьютерной графики; 2) описание сущностей с помощью «эталонных чертежей», по которых затем можно производить конкретные экземпляры; 3) графические «рамки», применяя которые к эталонам, можно создавать наборы связанных сущностей и с их помощью управлять машиной. Структуры данных в этой системе понять было сложно. Единственное, что казалось немного знакомым, — это передача процедурам указателей для перехода по ним в подпрограммы (так называемая обратная индексация, как в файловой системе B220). Это первая оконная система с отсечением изображения и изменением масштаба. Ее виртуальный холст простирался на полкилометра по обеим осям!
Переваривая прочитанное, я сел за свой рабочий стол. На нем лежала куча пленок, распечатка программы и записка: «Это Алгол для 1108-го. Не работает. Почини». Новенькому аспиранту — новенькое задание, за которое никто не хотел браться.
Понять документацию было просто невозможно. Язык был вроде как Алгол для Case-Western Reserve 1107, но основательно переработанный и названный Симулой. Документация такая, будто кто-то написал ее на норвежском, а затем транслитерировал на английский (между прочим, так оно и было). Некоторые слова, например activity и process, использовались вообще в другом смысле.
Вместе с еще одним аспирантом мы раскатали 25-метровый рулон в коридоре и стали ползать по нему, изучая код и перекрикиваясь, когда находили что-то интересное. Самой странной частью кода был распределитель памяти, который, в отличие от Алгола, не использовал стек. Пару дней спустя мы поняли почему: в Симуле память отводилась под структуры, которые очень походили на экземпляры объектов Sketchpad, а еще там имелись своего рода описания, по которым и создавались независимые друг от друга объекты. То, что в Sketchpad было эталонами и экземплярами, в Симуле называлось activity и process. Более того, Симула оказалась процедурным языком для управления Sketchpad-подобными объектами, то есть опережала Sketchpad с его «рамками» в плане гибкости (но уступала ему в изящности).
Симула удивила и изменила меня навсегда. Она стала последней каплей: очередная встреча с идеями ООП позволила мне осознать их в общем смысле, я словно испытал катарсис. В математике я занимался абстрактными алгебрами, то есть небольшими наборами операций, универсально применимых к самым разным структурам. В биологии — клеточным метаболизмом и высокоуровневым морфогенезом, где простые механизмы управляют сложными процессами, а универсальные «кирпичики» организма могут превращаться в то, что нужно именно здесь и сейчас. Файловая система B220, сам B5000, графическая система Sketchpad и, наконец, Симула использовали ту же идею для разных целей. За несколько дней до этого главный конструктор B5000 и профессор в Университете Юты Боб Бартон на одном из выступлений сказал так: «Базовый принцип рекурсивного проектирования состоит в том, что сущности на любом уровне вложенности должны обладать равными возможностями». Тогда я впервые примерил эту идею к компьютеру и понял, что совершенно зря его делят на более слабые концепции — структуры данных и процедуры. Почему бы не делить его на маленькие компьютеры, как в системах с разделением времени? Только не на десять, а сразу на тысячи, каждый из которых симулировал бы полезную структуру.
Мне на ум пришли монады Лейбница, Платон с его «разделять всё на виды, на естественные составные части» и другие попытки обуздать сложность. Конечно, философия — это споры и мнения, а инженерное искусство — конкретные результаты. Где-то между ними — наука. Не будет преувеличением сказать, что Симула с тех пор стала для меня главным источником идей. Нет, я вовсе не хотел ее улучшать: меня влекли открывающиеся перспективы, совершенно новый подход к структуре вычислительных процессов. Правда, на осознание и эффективное внедрение новых идей ушел не один год.
II. 1967–69 — FLEX: первый ПК на основе ООП
Дейв Эванс считал, что в аспирантуре многому не научишься и, как и многие «подрядчики» ARPA, хотел, чтобы мы занимались настоящими проектами и не тратили слишком много времени на теорию, а диссертации посвящали лишь новейшим разработкам. Обычно Дейв устраивал своих подопечных консультантами. Так в начале 1967 года он познакомил меня с дружелюбным Эдом Чидлом — настоящим гением аппаратного обеспечения. Эд тогда работал в местной аэрокосмической фирме над, как он выражался, «маленьким компьютером». Конечно, первый персональный компьютер, LINC, создал не он, а Уэс Кларк, зато Эд хотел сделать машину для некомпьютерщиков. Например, он хотел запрограммировать ее на языке высокого уровня, например на Бейсике. «Может, лучше на JOSS?» — предложил я. «Ну давай», — ответил он. Вот так и начался наш с ним приятный проект, который мы назвали FLEX. Чем глубже мы забирались в разработку, тем лучше осознавали, что хотим добиться динамической симуляции и расширяемости. JOSS (да и никакой другой известный мне язык) не особенно подходил ни для первого, ни для второго. Симула отпала сразу — наш компьютер был слишком мал для нее. Красота JOSS заключалась в невероятном уровне внимания к пользователям — в этом плане его не превзошел ни один язык. Но для серьезных вычислений JOSS был слишком медленным, а еще в нем не было настоящих процедур, областей действия переменных и т. п. Эйлер, язык созданный Никлаусом Виртом, походил на JOSS, но имел гораздо больший потенциал. Он представлял собой обобщение Алгола по идеям, впервые высказанным ван Вейнгаарденом: типы убраны, многие моменты унифицированы, процедуры стали объектами первого класса и т. д. Что-то вроде Лиспа, но без особых мудреностей.
По примеру Эйлера, мы решили упростить Симулу, применив к ней те же методы. Компилятор Эйлера был частью его формального описания и его легко можно было перевести в байт-код, подобный тому, что использовался в B5000. Это подкупало — значит, маленький компьютер Эда мог исполнять чужие байт-коды, пусть их и приходилось эмулировать с помощью длинного и медленного микрокода. Одна проблема: компилятор Эйлера был написан по неудобным правилам грамматики расширенного предшествования, отчего в синтаксисе приходилось идти на компромиссы. Например, запятая могла использоваться только в одной роли, потому что грамматика предшествования не позволяет иметь пространство состояний. Сначала я взял парсер Флойда — Эванса, работавший по принципу «снизу вверх» (и созданный на основе компилятора компиляторов Джерри Фельдмана), а позднее переключился на подход «сверху вниз». Для некоторых попыток я брал META II — язык для написания компиляторов Шорра. В конце концов транслятор закрепился в пространстве имен языка.
Мы думали, что наибольшее влияние на семантику FLEX должна оказать Симула, а не Алгол или Эйлер, но выходило иначе. А еще не было понятно, как же пользователи будут взаимодействовать с системой. Даже у первого компьютера Эда был экран (для графиков и т. п.), а LINC был оснащен «стеклянным телетайпом». Нам же по карману были лишь 16 тысяч 16-битных слов — о Sketchpad на такой машине можно было и не мечтать.
Даг Энгельбарт и его NLS
Итак, дело было в первой половине 1967-го. Мы всё думали над FLEX, а в Университет Юты приехал Даг Энгельбарт — визионер просто таки библейских масштабов. Он был одним из прародителей того, что мы с вами называем персональным компьютером. Он возил с собой 16-миллиметровый проектор с дистанционным управлением — СТАРТ/СТОП вместо курсора, ведь тогда курсоры были еще в новинку. Главной идеей, которую он продвигал в ARPA, была Онлайн-Система (NLS, oNLine Systems), призванная «усилить человеческий интеллект» с помощью интерактивного средства перемещения по «векторам мыслей в пространстве концепций». Даже по сегодняшним стандартам возможности его детища поражают воображение: гипертекст, графика, несколько рабочих панелей, эффективная навигация, удобный ввод команд, средства совместной работы и т. д. — целый мир понятий и абстракций. Благодаря Энгельбарту все, кто желал «усилить свой интеллект», сразу понимали, какими должны быть интерактивные компьютеры. Вот и я немедленно позаимствовал многие его идея для FLEX.
Симбиоз человека и компьютера, стоявший в центре всех проектов ARPA, и маленький компьютер Эда вновь напомнили мне о законе Мура, но на этот до меня наконец дошло его значение. Я осознал, что машина, занимавшая раньше целую комнату (тот же TX-2 или даже B6600 на 10 МГц), теперь умещается на столе. Эта мысль меня напугала: стало ясно, что современный подход к компьютерам долго не протянет, и само слово «компьютер» приобретало новый смысл. Наверное, так же себя чувствовали люди, только что прочитавшие трактат Коперника и взглянувшие на новые Небеса с новой Земли.
Вместо пары тысяч учебных мейнфреймов, разбросанных по всей планете (даже сейчас, в 1992 году, в мире насчитывается всего около 4000 мейнфреймов IBM) и нескольких тысяч пользователей, обученных определенным приложениям, в мире будут миллионы персональных машин и пользователей вне досягаемости университетов и организаций. Откуда возьмутся приложения? Как люди будут учиться этому? Как разработчики ПО узнают, что нужно конкретному пользователю? Здесь прямо напрашивалась расширяемая система — такая, чтобы люди сами подгоняли ее под свои нужды (и даже могли дорабатывать). Благодаря успеху систем с разделением времени многие в ARPA это уже понимали. Грандиозная метафора о симбиозе человека и машины затмевала любые проекты и не давала им превратиться в религии, удерживая внимание на абстрактном Святом Граале — «усилении человеческого интеллекта».
Одной из интересных особенностей NLS был параметризированный интерфейс: пользователи сами могли задавать его в виде «грамматики взаимодействия» в своем компиляторе компиляторов TreeMeta. Примерно так же описал это Уильям Ньюман в своем «Обработчике реакций»: с помощью планшета и стилуса конечный пользователь или разработчик описывал интерфейс в традиционной грамматике регулярных выражений, где в каждом состояниями были процедуры, выполнявшие какие-либо действия (в NLS встраивание было возможно благодаря бесконтекстным правилам). Идея была заманчивая по многим причинам, особенной в варианте Ньюмана, но я видел в ней зияющий недостаток: грамматики вынуждали пользователя выходить в состояние системы, если он хотел запустить что-нибудь новое. Все эти иерархические меню или экраны, по которым нужно было сначала вернуться на верхний уровень, чтобы попасть куда-то еще. Здесь пригодилась бы возможность переходить из одного состояния в любое другое, что плохо укладывалось в теорию формальных грамматик. В общем, напрашивался более «плоский» интерфейс, но как сделать его достаточно функциональным и интересным?
Напомню, что FLEX был слишком мал для того, чтобы стать мини-NLS. Нам пришлось выкручиваться, чтобы внедрить в него хотя бы часть передовых идей, а в некоторых случаях и развить их. Я решил, что универсальное окно в огромный виртуальный мир в духе Sketchpad лучше, чем тесные горизонтальные панели. Мы с Эдом придумали алгоритм отсечения изображения, очень похожий на тот, что создал Сазерленд в Гарварде: он со своими студентами разработал такой алгоритм одновременно с нами в рамках проекта по созданию шлема «виртуальной реальности».
На FLEX ссылки на сущности были обобщением дескрипторов B5000. Вместо разных форматов ссылок на числа, массивы и процедуры, дескрипторы FLEX содержали два указателя: один — на «эталон» объекта, а другой — на его конкретные экземпляры (мы потом поняли, что первый указатель лучше класть в экземпляры, чтобы сэкономить место). К работе с обобщенными задачами мы подошли иначе. В B5000 были l-значения и r-значения — в некоторых случаях этого было достаточно, но для более сложных объектов нужны было что-то другое. Вот пример. Пусть a — разреженный массив, элементы которого по умолчанию имеют значение 0. Тогда a[55] := 0 все равно приведет к созданию элемента, потому что «:=» — оператор, а a[55] дереференцируется в l-значение, прежде чем кто-либо успеет понять, что r-значение — это значение по умолчанию. При этом неважно, чем на самом деле является a: массивом или процедурой над массивом. Здесь нужно что-то вроде a(55, ':=', 0). При таком подходе программа сначала проверит все нужные операнды и только потом, если нужно, создаст элемент. Другими словами, «:=» тут уже не оператор, а вполне себе указатель на метод сложного объекта. На то, чтобы понять это, мне потребовалось неприлично много времени. Наверное, потому что пришлось перевернуть традиционное представление об операторах, функциях и т. п. Только после этого я осознал, что поведение должно быть частью объекта. Проще говоря, объект — это набор пар «ключ-значение», где в роли значений выступают определенные действия. У Рудольфа Карнапа есть книга по логике, которая помогла мне понять, что традиционные способы расширения программ и «содержательные» дефиниции обладают одинаковыми возможностями, но последние интуитивно понятнее и удобнее.
Как и в Симуле, для приостановки и возобновления работы объектов использовалась сопрограммная управляющая конструкция. Постоянные объекты (файлы, документы) были для машины приостановленными процессами и сортировались в соответствии с их статичными областями переменных. Пользователь мог видеть эти области на экране и выбирать нужную. Сопрограммы использовались и для организации циклов. Оператор while проверял генераторы, которые возвращали false, когда не могли предоставить новое значение. Для связи нескольких генераторов применялись булевы значения. Например, for-циклы писались так:
while i <= 1 to 30 by 2 ^ j <= 2 to k by 3 do j<-j * i;
Конструкция… to… by… здесь что-то вроде сопрограммы. Многие из этих идей впоследствие появились и в Smalltalk, но в более сильной форме.
Еще одна интересная управляющая конструкция FLEX — when. Она работала на «мягких прерываниях» от событий.
Продолжение следует...
За перевод спасибо Алексею Никитину.
(Кто считает, что эта статья важная и хочет помочь с переводом — пишите в личку или alexey.stacenko@gmail.com)
Ещё
Переводы Алана Кея:
- С днём рождения, Алан Кейǃ (или как получить +80 к IQ)
- Алан Кей: Будущее «чтения» зависит от будущего «обучения сложным для понимания вещей»
- Алан Кей: «Компьютеры — это инструменты, музыка которых — идеи»
- Алан Кей: Что сделало Xerox PARC особенными и кто еще сегодня похож на них
- Алан Кей: крутым концепциям тоже нужна любовь
- Алан Кей: Как обстоят дела у всего человечества, вид «из космоса»
- Алан Кей и Марвин Мински: Computer Science уже имеет «грамматику». Нужна «литература»
- Алан Кей (и коллективный интеллект Хабра): какие книги формируют мышление тру инженера
- Алан Кей: как бы я преподавал Computer Science 101
- Алан Кей: Будущее нельзя построить постепенно
- Персона. Алан Кэй — пророк, автор концепции GUI и языка Smalltalk
- Алан Кей: Будущее «чтения» зависит от будущего «обучения сложным для понимания вещей»
- Алан Кэй, создатель ООП, про разработку, Лисп и ООП
- С днём рождения, Алан Кейǃ (или как получить +80 к IQ)
- Алан Кей в мире компьютеров
Ричард Хэмминг
Книга Ричарда Хэмминга The Art of Doing Science and Engineering: Learning to Learn
Предисловие
- Intro to The Art of Doing Science and Engineering: Learning to Learn (March 28, 1995) Перевод: Глава 1
- «Foundations of the Digital (Discrete) Revolution» (March 30, 1995) Глава 2. Основы цифровой (дискретной) революции
- «History of Computers — Hardware» (March 31, 1995) Глава 3. История компьютеров — железо
- «History of Computers — Software» (April 4, 1995) Глава 4. История компьютеров — Софт
- «History of Computers — Applications» (April 6, 1995) Глава 5. История компьютеров — практическое применение
- «Artificial Intelligence — Part I» (April 7, 1995) Глава 6. Искусственный интеллект — 1
- «Artificial Intelligence — Part II» (April 11, 1995) Глава 7. Искусственный интеллект — II
- «Artificial Intelligence III» (April 13, 1995) Глава 8. Искуственный интеллект-III
- «n-Dimensional Space» (April 14, 1995) Глава 9. N-мерное пространство
- «Coding Theory — The Representation of Information, Part I» (April 18, 1995) Глава 10. Теория кодирования — I
- «Coding Theory — The Representation of Information, Part II» (April 20, 1995) Глава 11. Теория кодирования — II
- «Error-Correcting Codes» (April 21, 1995) Глава 12. Коды с коррекцией ошибок
- «Information Theory» (April 25, 1995) Готово, осталось опубликовать
- «Digital Filters, Part I» (April 27, 1995) Глава 14. Цифровые фильтры — 1
- «Digital Filters, Part II» (April 28, 1995) Глава 15. Цифровые фильтры — 2
- «Digital Filters, Part III» (May 2, 1995) Глава 16. Цифровые фильтры — 3
- «Digital Filters, Part IV» (May 4, 1995) Глава 17. Цифровые фильтры — IV
- «Simulation, Part I» (May 5, 1995) Глава 18. Моделирование — I
- «Simulation, Part II» (May 9, 1995) Глава 19. Моделирование — II
- «Simulation, Part III» (May 11, 1995) Глава 20. Моделирование — III
- «Fiber Optics» (May 12, 1995) Глава 21. Волоконная оптика
- «Computer Aided Instruction» (May 16, 1995) Глава 22. Обучение с помощью компьютера (CAI)
- «Mathematics» (May 18, 1995) Глава 23. Математика
- «Quantum Mechanics» (May 19, 1995) Глава 24. Квантовая механика
- «Creativity» (May 23, 1995). Перевод: Глава 25. Креативность
- «Experts» (May 25, 1995) Глава 26. Эксперты
- «Unreliable Data» (May 26, 1995) Глава 27. Недостоверные данные
- «Systems Engineering» (May 30, 1995) Глава 28. Системная Инженерия
- «You Get What You Measure» (June 1, 1995) Глава 29. Вы получаете то, что вы измеряете
- «How Do We Know What We Know» (June 2, 1995) переводим по 10 минутным кусочкам
- Hamming, «You and Your Research» (June 6, 1995). Перевод: Вы и ваша работа
