За последние 50 лет мы добились большого прогресса в разработке Интернета: от небольшой сети из нескольких компьютеров до всемирной структуры из миллиардов узлов. На этом пути мы узнали огромный объём информации о том, как создавать сети и соединяющие их маршрутизаторы. Совершённые нами ошибки стали важными уроками для тех из нас, кто готов был их усвоить.
В самом начале маршрутизаторы были обычными компьютерами с подключёнными к шине платами сетевого интерфейса (Network Interface Card, NIC).

Рисунок 1 — Подключенные к шине платы сетевого интерфейса.
До определённого момента такая система работала. В этой архитектуре пакеты поступали в NIC и передавались центральным процессором из NIC в память. ЦП принимал решение о переадресации и выводил пакет на внешний NIC. ЦП и память — это централизованные ресурсы, ограниченные в поддержке устройств. Шина тоже являлась дополнительным ограничением: ширина пропускания шины должна была поддерживать ширину пропускания всех NIC одновременно.
Если необходимо увеличивать масштаб сети, то очень быстро начинают возникать проблемы. Можно купить процессор побыстрее, но как увеличить мощность шины? Если удвоить скорость шины, то нужно удвоить скорость интерфейса шины в каждой плате NIC и ЦП. Это удорожает все платы, даже если мощность отдельного NIC не повысится.
Несмотря на полученный урок, удобным решением для увеличения масштабов было добавление ещё одной шины и процессора:
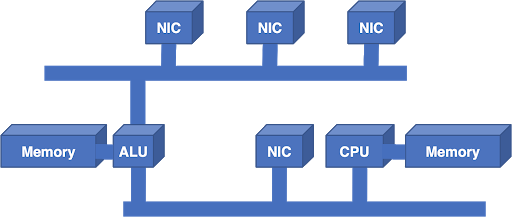
Рисунок 2 — Решением задачи масштабирования системы было добавление новой шины и процессора.
Дополнительное арифметико-логическое устройство (Arithmetic Logic Unit, АЛУ) было чипом цифровой обработки сигналов (Digital Signal Processing, DSP), выбранным благодаря его превосходному соотношению цены и производительности. Дополнительная шина увеличивала ширину пропускания, но масштабы архитектуры всё равно не росли. Другими словами, нельзя было добавить больше АЛУ и шин, чтобы увеличить производительность.
Так как АЛУ по-прежнему оставались существенным ограничением, следующим шагом стало добавление в архитектуру программируемой пользователем вентильной матрицы (Field Programmable Gate Array, FPGA) для снижения нагрузки по поиску Longest Prefix Match (LPM).
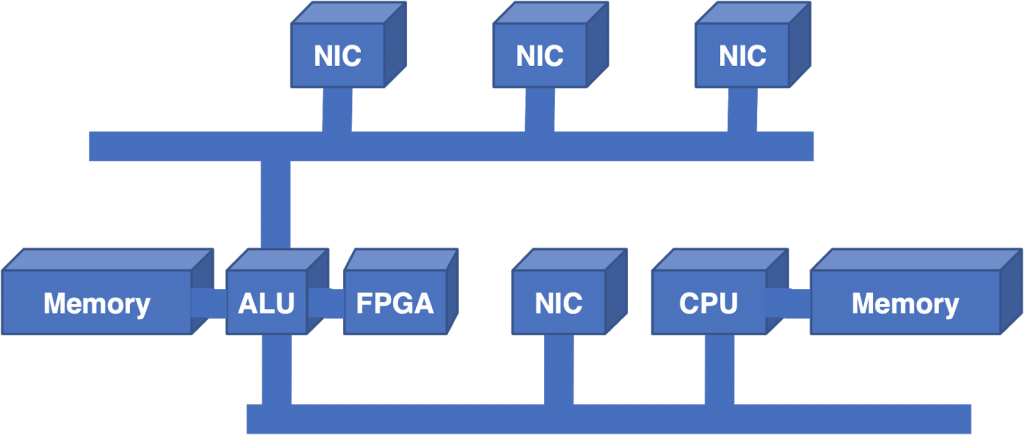
Рисунок 3 — Следующим этапом стало добавление Field Programmable Gate Array.
Хоть это и помогло, но полностью проблему не решило. АЛУ по-прежнему было перегружено. LPM составляли большую часть нагрузки, однако централизованная архитектура всё равно плохо масштабировалась, даже если избавиться от части проблемы.
Несмотря на этот урок, следующий шаг был предпринят в другом направлении: к замене АЛУ и FPGA стандартным процессором. Проектировщики попытались обеспечить масштабирование, добавляя больше ЦП и шин. Это требовало больших усилий даже для небольшого увеличения мощности, и система всё равно страдала от ограничений ширины пропускания централизованной шины.
На этом этапе эволюции Интернета в дело вступили более серьёзные силы. Когда веб стал популярен у широкой публики, потенциал Интернета начал становиться всё очевиднее. Telcos приобрела региональные сети NSFnet и начала создавать коммерческие комплексы. Надёжными технологиями стали Application-Specific Integrated Circuits (ASIC), позволяющие реализовать бОльшую функциональность непосредственно в кремнии. Спрос на маршрутизаторы взлетел до небес, а потребность в значительных улучшениях масштабируемости наконец-то победила консерватизм инженеров. Для удовлетворения этого спроса возникло множество стартапов с широким диапазоном возможных решений.
Одной из альтернатив стал scheduled crossbar:
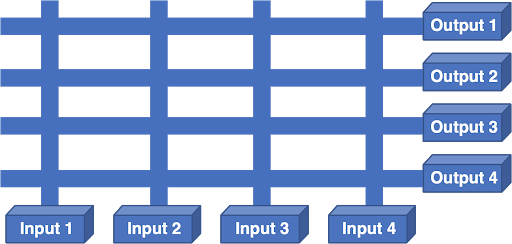
Рисунок 4 — Scheduled crossbar.
В этой архитектуре каждая NIC имела вход и выход. Процессор NIC принимал решение о переадресации, выбирал NIC выхода и отправлял запрос на планирование коммутатору (crossbar). Планировщик получал все запросы от плат NIC, вырабатывал оптимальное решение, программировал решение в коммутатор и направлял входы для передачи.
Проблема такой схемы заключалась в том, что каждый выход мог «слушать» одновременно один вход, а Интернет-трафик пульсирует. Если двум пакетам нужно попасть в одинаковый выход, одному из них приходилось ждать. Ожидание одного пакета приводило к тому, что другим пакетам на том же входе приходилось ждать, после чего система начинала страдать от Head Of Line Blocking (HOLB), что приводило к очень низкой производительности маршрутизатора.
Миграция на специализированные чипы также мотивировала проектировщиков мигрировать на внутренние структуры на основе ячеек, поскольку реализация коммутации небольших ячеек фиксированного размера гораздо проще, чем работа с пакетами переменной длины, иногда имеющими большой размер. Однако использование коммутационных ячеек также означало, что планировщик должен будет работать с более высокой частотой, что сильно усложняло планирование.
Ещё одним инновационным подходом стало выстраивание NIC в тор:

Рисунок 5 — NIC в форме тора.
В такой схеме каждая NIC имела связи с четырьмя соседями, а NIC входа должна была вычислять путь по структуре, чтобы достичь платы выходной линии. У такой системы имелись проблемы — ширина пропускания была неодинаковой. Ширина пропускания в направлении север-юг была выше, чем в направлении восток-запад. Если паттерн входящего трафика должен был двигаться в направлении восток-запад, возникали заторы.
Совершенно иным подходом было создание полной сети связей NIC-NIC и распределение ячеек по всем NIC:
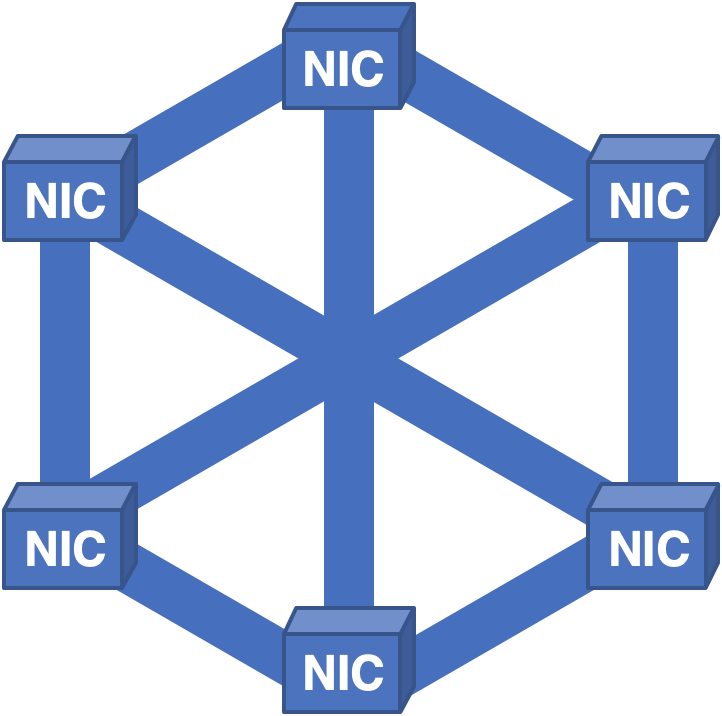
Рисунок 6 — Полносвязная структура с распределением ячеек на все NIC.
Несмотря на усвоение предыдущих уроков, были выявлены новые проблемы. В такой архитектуре всё работало достаточно хорошо, пока не требовалось извлечь плату для ремонта. Поскольку каждая NIC содержала ячейки для всех пакетов в системе, при извлечении платы ни один из пакетов нельзя было воссоздать, что приводило к кратковременным, но болезненным простоям.
Мы даже взяли эту архитектуру и перевернули её с ног на голову:

Рисунок 7 — Здесь все пакеты попадают в центральную память, а затем на выходную NIC.
Такая система работала довольно неплохо, но проблемой стало масштабирование памяти. Можно просто добавить несколько контроллеров и банков памяти, но в какой-то момент общая ширина пропускания оказывается слишком сложной для физического проектирования. Столкнувшись с практическими физическими ограничениями, мы вынуждены были думать в других направлениях.
Источником вдохновения для нас стала телефонная сеть. Давным-давно Чарльз Клоз догадался, что масштабируемые коммутаторы можно изготавливать, создавая сети из более мелких коммутаторов. Как оказалось, все нужные нам чудесные свойства присутствуют в сети Клоза:

Рисунок 8 — Сеть Клоза.
Свойства сети Клоза:
Мы всегда реализуем входы и выходы вместе, поэтому обычно сгибаем это изображение по пунктирной линии. При этом получается свёрнутая сеть Клоза, и именно её мы используем сегодня в многокорпусных маршрутизаторах: в некоторых корпусах установлены NIC и слой коммутаторов, в других — дополнительные слои коммутаторов.

Рисунок 9 — Свёрнутая сеть Клоза.
К сожалению, даже эта архитектура имеет свои проблемы. Формат ячеек, используемых между коммутаторами, проприетарен и принадлежит производителю чипов, из-за чего возникает зависимость от чипсетов. Зависимость от поставщика чипов ненамного лучше зависимости от одного поставщика маршрутизаторов, проблемы те же: привязка ценообразования и доступности устройств к одному источнику. Апгрейды оборудования вызывают сложности, поскольку новый коммутатор ячеек должен одновременно поддерживать устаревшие соединения и формат ячеек для сохранения взаимодействия, а также все скорости канала и форматы ячеек нового оборудования.
Каждая ячейка должна иметь адресацию, указывающую выходную NIC, к которому она должна передавать информацию. Такая адресация конечна, что создаёт предел масштабируемости. Контроль и управление в многокорпусных маршрутизаторах пока совершенно проприетарны, вызывая ещё одну проблему единственного поставщика в программном стеке.
К счастью, мы можем решить эти проблемы, изменив философию создания архитектур. В течение последних пятидесяти лет мы стремились масштабировать маршрутизаторы. Из опыта построения больших облаков мы научились тому, что чаще более успешна философия горизонтального масштабирования.
В архитектуре с горизонтальным масштабированием вместо создания огромного, чрезвычайно быстрого единственного сервера используется стратегия «разделяй и властвуй». Стойка из мелких серверов может выполнять ту же работу, будучи при этом более надёжной, гибкой и экономной.
К маршрутизаторам такой подход тоже применим. Можно ли взять несколько мелких маршрутизаторов и выстроить их в топологию Клоза, чтобы получить аналогичные преимущества архитектуры, но избежав при этом связанных с ячейками проблем? Как оказалось, это не особо сложно:

Рисунок 10 — Замена коммутаторов ячеек на пакетные коммутаторы, сохраняющая топологию Клоза для упрощения масштабирования.
Заменив коммутаторы ячеек на пакетные коммутаторы и сохранив топологию Клоза, мы обеспечиваем простоту масштабирования.
Масштабирование возможно в двух измерениях: или добавление новых входных маршрутизаторов и пакетных коммутаторов параллельно с существующими слоями, или добавление дополнительных слоёв коммутаторов. Поскольку отдельные маршрутизаторы сегодня достаточно стандартизированы, мы избегаем зависимости от одного поставщика. Все каналы реализуют стандартный Ethernet, поэтому проблемы с совместимостью отсутствуют.
Апгрейды выполняются легко и напрямую: если в коммутаторе нужно больше каналов, то можно просто заменить его на коммутатор побольше. Если нужно проапгрейдить отдельный канал и оба конца канала имеют такую возможность, то достаточно просто апгрейдить оптику. Отличающиеся скорости передачи разнородных каналов внутри структуры не являются проблемой, поскольку каждый маршрутизатор работает как устройство сопоставления скорости.
Такая архитектура уже популярна в мире дата-центров и в зависимости от количества слоёв коммутаторов имеет название архитектуры leaf-spine или super-spine. Она доказала свою высокую надёжность, стабильность и гибкость.
С точки зрения плоскости передачи, очевидно, что это реальная альтернатива архитектуре. Остаются проблемы с плоскостью контроля и плоскостью управления. Для горизонтального масштабирования плоскости контроля требуется улучшение масштаба наших управляющих протоколов на один порядок величин. Мы пытаемся реализовать его, совершенствуя механизмы абстрагирования созданием прокси-представления архитектуры, описывающей всю топологию как единый узел.
Аналогично, мы работаем над развитием абстракций плоскости управления, которые позволят нам контролировать всю структуру Клоза как единый маршрутизатор. Эта работа производится как открытый стандарт, поэтому ни одна из задействованных технологий не является проприетарной.
На протяжении пятидесяти лет архитектуры маршрутизаторов эволюционировали скачкообразно, было совершено множество ошибок в процессе поиска компромиссов между разными технологиями. Очевидно, что наша эволюция ещё не завершена. В каждой итерации мы решали проблемы предыдущего поколения и обнаруживали новые сложности.
Будем надеяться, что благодаря внимательному изучению нашего прошлого и современного опыта мы сможем двигаться вперёд, к более гибкой и надёжной архитектуре, и создавать будущие усовершенствования без полной замены оборудования.
В самом начале маршрутизаторы были обычными компьютерами с подключёнными к шине платами сетевого интерфейса (Network Interface Card, NIC).
Рисунок 1 — Подключенные к шине платы сетевого интерфейса.
До определённого момента такая система работала. В этой архитектуре пакеты поступали в NIC и передавались центральным процессором из NIC в память. ЦП принимал решение о переадресации и выводил пакет на внешний NIC. ЦП и память — это централизованные ресурсы, ограниченные в поддержке устройств. Шина тоже являлась дополнительным ограничением: ширина пропускания шины должна была поддерживать ширину пропускания всех NIC одновременно.
Если необходимо увеличивать масштаб сети, то очень быстро начинают возникать проблемы. Можно купить процессор побыстрее, но как увеличить мощность шины? Если удвоить скорость шины, то нужно удвоить скорость интерфейса шины в каждой плате NIC и ЦП. Это удорожает все платы, даже если мощность отдельного NIC не повысится.
Урок первый: стоимость маршрутизатора должны линейно расти с его возможностями
Несмотря на полученный урок, удобным решением для увеличения масштабов было добавление ещё одной шины и процессора:
Рисунок 2 — Решением задачи масштабирования системы было добавление новой шины и процессора.
Дополнительное арифметико-логическое устройство (Arithmetic Logic Unit, АЛУ) было чипом цифровой обработки сигналов (Digital Signal Processing, DSP), выбранным благодаря его превосходному соотношению цены и производительности. Дополнительная шина увеличивала ширину пропускания, но масштабы архитектуры всё равно не росли. Другими словами, нельзя было добавить больше АЛУ и шин, чтобы увеличить производительность.
Так как АЛУ по-прежнему оставались существенным ограничением, следующим шагом стало добавление в архитектуру программируемой пользователем вентильной матрицы (Field Programmable Gate Array, FPGA) для снижения нагрузки по поиску Longest Prefix Match (LPM).
Рисунок 3 — Следующим этапом стало добавление Field Programmable Gate Array.
Хоть это и помогло, но полностью проблему не решило. АЛУ по-прежнему было перегружено. LPM составляли большую часть нагрузки, однако централизованная архитектура всё равно плохо масштабировалась, даже если избавиться от части проблемы.
Урок второй: LPM можно реализовать в кремнии и они не являются преградой для производительности
Несмотря на этот урок, следующий шаг был предпринят в другом направлении: к замене АЛУ и FPGA стандартным процессором. Проектировщики попытались обеспечить масштабирование, добавляя больше ЦП и шин. Это требовало больших усилий даже для небольшого увеличения мощности, и система всё равно страдала от ограничений ширины пропускания централизованной шины.
На этом этапе эволюции Интернета в дело вступили более серьёзные силы. Когда веб стал популярен у широкой публики, потенциал Интернета начал становиться всё очевиднее. Telcos приобрела региональные сети NSFnet и начала создавать коммерческие комплексы. Надёжными технологиями стали Application-Specific Integrated Circuits (ASIC), позволяющие реализовать бОльшую функциональность непосредственно в кремнии. Спрос на маршрутизаторы взлетел до небес, а потребность в значительных улучшениях масштабируемости наконец-то победила консерватизм инженеров. Для удовлетворения этого спроса возникло множество стартапов с широким диапазоном возможных решений.
Одной из альтернатив стал scheduled crossbar:
Рисунок 4 — Scheduled crossbar.
В этой архитектуре каждая NIC имела вход и выход. Процессор NIC принимал решение о переадресации, выбирал NIC выхода и отправлял запрос на планирование коммутатору (crossbar). Планировщик получал все запросы от плат NIC, вырабатывал оптимальное решение, программировал решение в коммутатор и направлял входы для передачи.
Проблема такой схемы заключалась в том, что каждый выход мог «слушать» одновременно один вход, а Интернет-трафик пульсирует. Если двум пакетам нужно попасть в одинаковый выход, одному из них приходилось ждать. Ожидание одного пакета приводило к тому, что другим пакетам на том же входе приходилось ждать, после чего система начинала страдать от Head Of Line Blocking (HOLB), что приводило к очень низкой производительности маршрутизатора.
Урок третий: внутренняя структура маршрутизатора не должна блокировать сигналы даже в условиях нагрузки
Миграция на специализированные чипы также мотивировала проектировщиков мигрировать на внутренние структуры на основе ячеек, поскольку реализация коммутации небольших ячеек фиксированного размера гораздо проще, чем работа с пакетами переменной длины, иногда имеющими большой размер. Однако использование коммутационных ячеек также означало, что планировщик должен будет работать с более высокой частотой, что сильно усложняло планирование.
Ещё одним инновационным подходом стало выстраивание NIC в тор:
Рисунок 5 — NIC в форме тора.
В такой схеме каждая NIC имела связи с четырьмя соседями, а NIC входа должна была вычислять путь по структуре, чтобы достичь платы выходной линии. У такой системы имелись проблемы — ширина пропускания была неодинаковой. Ширина пропускания в направлении север-юг была выше, чем в направлении восток-запад. Если паттерн входящего трафика должен был двигаться в направлении восток-запад, возникали заторы.
Урок четвёртый: внутренняя структура маршрутизатора должна иметь равномерное распределение ширины пропускания, потому что мы не можем предсказать распределение трафика.
Совершенно иным подходом было создание полной сети связей NIC-NIC и распределение ячеек по всем NIC:
Рисунок 6 — Полносвязная структура с распределением ячеек на все NIC.
Несмотря на усвоение предыдущих уроков, были выявлены новые проблемы. В такой архитектуре всё работало достаточно хорошо, пока не требовалось извлечь плату для ремонта. Поскольку каждая NIC содержала ячейки для всех пакетов в системе, при извлечении платы ни один из пакетов нельзя было воссоздать, что приводило к кратковременным, но болезненным простоям.
Урок пятый: маршрутизаторы не должны иметь единой точки отказа
Мы даже взяли эту архитектуру и перевернули её с ног на голову:
Рисунок 7 — Здесь все пакеты попадают в центральную память, а затем на выходную NIC.
Такая система работала довольно неплохо, но проблемой стало масштабирование памяти. Можно просто добавить несколько контроллеров и банков памяти, но в какой-то момент общая ширина пропускания оказывается слишком сложной для физического проектирования. Столкнувшись с практическими физическими ограничениями, мы вынуждены были думать в других направлениях.
Источником вдохновения для нас стала телефонная сеть. Давным-давно Чарльз Клоз догадался, что масштабируемые коммутаторы можно изготавливать, создавая сети из более мелких коммутаторов. Как оказалось, все нужные нам чудесные свойства присутствуют в сети Клоза:
Рисунок 8 — Сеть Клоза.
Свойства сети Клоза:
- Мощность растёт с увеличением масштаба.
- Не имеет единой точки отказа.
- Поддерживает достаточную избыточность для устойчивости при сбоях.
- Справляется с перегрузками, распределяя нагрузку по всей структуре.
Мы всегда реализуем входы и выходы вместе, поэтому обычно сгибаем это изображение по пунктирной линии. При этом получается свёрнутая сеть Клоза, и именно её мы используем сегодня в многокорпусных маршрутизаторах: в некоторых корпусах установлены NIC и слой коммутаторов, в других — дополнительные слои коммутаторов.
Рисунок 9 — Свёрнутая сеть Клоза.
К сожалению, даже эта архитектура имеет свои проблемы. Формат ячеек, используемых между коммутаторами, проприетарен и принадлежит производителю чипов, из-за чего возникает зависимость от чипсетов. Зависимость от поставщика чипов ненамного лучше зависимости от одного поставщика маршрутизаторов, проблемы те же: привязка ценообразования и доступности устройств к одному источнику. Апгрейды оборудования вызывают сложности, поскольку новый коммутатор ячеек должен одновременно поддерживать устаревшие соединения и формат ячеек для сохранения взаимодействия, а также все скорости канала и форматы ячеек нового оборудования.
Каждая ячейка должна иметь адресацию, указывающую выходную NIC, к которому она должна передавать информацию. Такая адресация конечна, что создаёт предел масштабируемости. Контроль и управление в многокорпусных маршрутизаторах пока совершенно проприетарны, вызывая ещё одну проблему единственного поставщика в программном стеке.
К счастью, мы можем решить эти проблемы, изменив философию создания архитектур. В течение последних пятидесяти лет мы стремились масштабировать маршрутизаторы. Из опыта построения больших облаков мы научились тому, что чаще более успешна философия горизонтального масштабирования.
В архитектуре с горизонтальным масштабированием вместо создания огромного, чрезвычайно быстрого единственного сервера используется стратегия «разделяй и властвуй». Стойка из мелких серверов может выполнять ту же работу, будучи при этом более надёжной, гибкой и экономной.
К маршрутизаторам такой подход тоже применим. Можно ли взять несколько мелких маршрутизаторов и выстроить их в топологию Клоза, чтобы получить аналогичные преимущества архитектуры, но избежав при этом связанных с ячейками проблем? Как оказалось, это не особо сложно:
Рисунок 10 — Замена коммутаторов ячеек на пакетные коммутаторы, сохраняющая топологию Клоза для упрощения масштабирования.
Заменив коммутаторы ячеек на пакетные коммутаторы и сохранив топологию Клоза, мы обеспечиваем простоту масштабирования.
Масштабирование возможно в двух измерениях: или добавление новых входных маршрутизаторов и пакетных коммутаторов параллельно с существующими слоями, или добавление дополнительных слоёв коммутаторов. Поскольку отдельные маршрутизаторы сегодня достаточно стандартизированы, мы избегаем зависимости от одного поставщика. Все каналы реализуют стандартный Ethernet, поэтому проблемы с совместимостью отсутствуют.
Апгрейды выполняются легко и напрямую: если в коммутаторе нужно больше каналов, то можно просто заменить его на коммутатор побольше. Если нужно проапгрейдить отдельный канал и оба конца канала имеют такую возможность, то достаточно просто апгрейдить оптику. Отличающиеся скорости передачи разнородных каналов внутри структуры не являются проблемой, поскольку каждый маршрутизатор работает как устройство сопоставления скорости.
Такая архитектура уже популярна в мире дата-центров и в зависимости от количества слоёв коммутаторов имеет название архитектуры leaf-spine или super-spine. Она доказала свою высокую надёжность, стабильность и гибкость.
С точки зрения плоскости передачи, очевидно, что это реальная альтернатива архитектуре. Остаются проблемы с плоскостью контроля и плоскостью управления. Для горизонтального масштабирования плоскости контроля требуется улучшение масштаба наших управляющих протоколов на один порядок величин. Мы пытаемся реализовать его, совершенствуя механизмы абстрагирования созданием прокси-представления архитектуры, описывающей всю топологию как единый узел.
Аналогично, мы работаем над развитием абстракций плоскости управления, которые позволят нам контролировать всю структуру Клоза как единый маршрутизатор. Эта работа производится как открытый стандарт, поэтому ни одна из задействованных технологий не является проприетарной.
На протяжении пятидесяти лет архитектуры маршрутизаторов эволюционировали скачкообразно, было совершено множество ошибок в процессе поиска компромиссов между разными технологиями. Очевидно, что наша эволюция ещё не завершена. В каждой итерации мы решали проблемы предыдущего поколения и обнаруживали новые сложности.
Будем надеяться, что благодаря внимательному изучению нашего прошлого и современного опыта мы сможем двигаться вперёд, к более гибкой и надёжной архитектуре, и создавать будущие усовершенствования без полной замены оборудования.
