Одна из крупных проблем обучения с подкреплением - это неэффективность по данным. Да, мы можем обучить нейросеть, которая будет играть в Пакмена лучше человека. Для этого ей потребуется сделать огромное, прямо-таки астрономическое число попыток. Для сравнения: мой кот тоже умеет разрабатывать сложные стратегии, и при этом ему не нужны тысячи повторений, чтобы обучиться чему-то элементарному.
В 2020 году Google выпустил статью “Dream to control: learning behaviours by latent imagination”. В статье описывался новейший алгоритм обучения в подкреплением - Dreamer. Алгоритм примечателен тем, что относительно быстро выучивает выигрышную стратегию - совершая относительно мало взаимодействий со средой.
После этого я очень захотел свой собственный Dreamer - желательно не как у гугла, а лучше. Кроме того, по математическому описанию код можно написать сильно по-разному - я хотел понять, какие есть подводные камни, поэтому в код гугла я практически не лез.
Дисклеймер:
Я не пытаюсь сделать ИИ похожим на человека и не утверждаю, что нейросети похожи на нервную систему каких-либо организмов. По моему опыту, машинное обучение обычно превосходит человека в тех задачах, где есть бигдата и легко проверяемая функция ошибки. Большинство известных мне исключений связаны с тем, что либо эволюция предобучила человека на огромном датасете, либо в детстве человек собрал огромную статистику. Как только задача требует непредвзятого универсального интеллекта - оказывается, что с хорошими шансами XGBoost работает точнее любого эксперта.
Что из себя представляет Dreamer?
Dreamer - это система обучения с подкреплением, которая использует обучение в воображении. Он состоит из трёх основных блоков:
Понижатель размерности. На входе у нас кадры из какого-нибудь Пакмена, а на выходе небольшие массивы float-ов, также называемые словом “эмбеддинг”. Так как любое изображение сильно избыточно, его можно сжать до нескольких чисел, описывающих содержание картинки. Эмбеддинг можно получить, например, автоэнкодером - это такая нейросеть, которая на выходе пытается воспроизвести вход. Но один из слоёв автоэнкодера содержит мало нейронов, то есть нейросеть вынуждена сжимать картинку в маленький информативный вектор, из которого можно потом получить такую же картинку. Например, если мы смотрим на катапульту и видим в ней систему из рычагов, масс, сил, упругостей и прочностей - то вот это “теормеховское” описание и будет эмбеддингом.
Модель мира. Это некая нейросеть, которая на вход принимает несколько прошлых эмбеддингов и действий нашего агента, а на выходе предсказывает будущий эмбеддинг. Или некую последовательность этих сжатых представлений.
Система обучения с подкреплением, которая будет учиться в виртуальной реальности, на модели мира (пункт 2), а управлять - в реальном мире.
То есть типичный запуск dreamer выглядит так: мы включаем пинг-понг от Атари, пять раундов агент жмёт случайные кнопки и собирает статистику. Затем обучает автоэнкодер, так что тот из цветной картинки 128 на 128 теперь умеет делать вектор в 30 элементов. Так как задачка всего одна - пинг-понг - кодировщику необязательно быть ёмким. Затем обучается модель мира - она учится по прошлым кадрам и действиям предсказывать будущие. Затем обучается система actor-critic - она понимает, какие действия в каких ситуациях приводят к повышению и понижению сигнала награды, на любом горизонте планирования.
Тут надо понимать, что каждая из описанных систем построена на нейросетях, то есть каждый раз, когда модель обучается, она просто делает несколько шагов градиентного спуска. Автоэнкодер чуть-чуть приближается от полностью рандомной нейронки к реально хорошему сжимателю, моделирующая сеть тоже чуть-чуть приближается к идеальной модели мира и так далее.
Сколько же длится обучение dreamer-а?
А это показано на синем графике.

Фактически, когда я запустил дример на игре Pong, он стал показывать какие-то результаты, отличающиеся от рандома, на 120-й партии.
Для меня это было шоком: самый sample-efficient ИИ вынужден проигрывать 120 партий, прежде чем научится действовать лучше рандома. Там всего две кнопки…
В общем, подумал я, dreamer успешно провалил тест на кота (мой кот научился бы быстрее), а значит, чтобы побить рекорд гугла, достаточно сделать что-то хоть немного лучше.
Архитектуры
Я перепробовал и обдумал много архитектур reinforcement learning. Мои требования были такие:
Система должна быть sample-efficient. Я знаю, как за бесконечное число экспериментов подобрать хорошую стратегию - эволюционный алгоритм это сделает отлично. Но надо пройти тест на кота - система должна уметь обучаться по считанным единицам подкреплений создавать некую неслучайную стратегию за единицы тысяч кадров.
Система должна уметь использовать чужой опыт. Если мы делаем reinforcement learning для, скажем, игры в Doom, то у нас должна быть возможность самим сыграть, передать запись игры боту и обучить его на ней. Не копировать стратегию человека - лишь сделать из неё выводы, лучше понять, какие ходы хороши, а какие плохи.
Система должна быть максимально универсальна. Как минимум она должна хорошо справляться со множеством задач, где на входе мы имеем цветной видеоряд, и действие происходит в чём-то, отдалённо похожем на наш мир.
Система должна работать максимально “из коробки” - никакого сложного тюнинга гиперпараметров
Ещё хорошо бы, чтобы ИИ вышел не очень требовательным к процессору, и чтобы достигал наиболее сильных стратегий… Но это по возможности.
Я хотел повторить Dreamer, но решил, что обучать автоэнкодер каждый раз под задачу - это необязательно. Можно один раз потратить несколько недель на сервере и получить некий усреднённо-универсальный кодировщик. Можно его даже для начала учить на задачах, которые похожи на те, где будем применять.
Мой энкодер
Для создания эмбеддингов широко применяются автоэнкодеры. На входе картинка, на выходе - она же. А в узком промежуточном слое - эмбеддинг.

Но потом я подумал: я же хочу, чтобы система работала с видеорядом. Было бы здорово, если бы мой энкодер мог выделять не просто зоны света и тени, а обнаруживал материальные объекты. Я делаю reinforcement learning, который буду тестировать в играх, а игры рассматриваю как метафору реальности. Так пусть у нас на входе “автоэнкодера” будет видеоряд, а на выходе - следующий кадр. Да, и всё это мы протащим через bottleneck.
Я хотел сделать систему, которая бы внутри эмбеддинга получила что-то вроде координат объектов, их скоростей, масс… Возможно, каких-то свойств прочности, взрывоопасности и так далее. Конечно, можно все эти свойства разметить вручную, но ручная разметка будет точно неполной. А можно разметить автоматически - и тогда она будет менее осмысленная, зато более исчерпывающей.
Итак, я арендовал сервер и приступил к экспериментам. Для начала я сделал огромный датасет из видео и нарезал его на входы и выходы. Входы - это цепочки по 6 кадров, на выходе - следующий кадр. Все кадры идут с некоторым периодом, то есть не прямо подряд.
На входе свёрточные слои, на выходе - деконволюционные, здесь всё стандартно. А что посередине? Я попробовал и LSTM, и GRU - они дали отвратный результат. Трансформер дал результат ещё хуже - наверное, его надо как-то хитро применять.
Лучше всего сработал, как ни странно, обычный полносвязный слой, соединяющий входной и выходной “каскады” нейросети.
Итак, картиночки. Первая картинка - это конец видеоряда. Последняя - это то, что нам надо предсказать. Посередине - это что предсказал автоэнкодер. У него эмбеддинг - всего 300 float-ов, то есть от никаких чудес я не ждал.
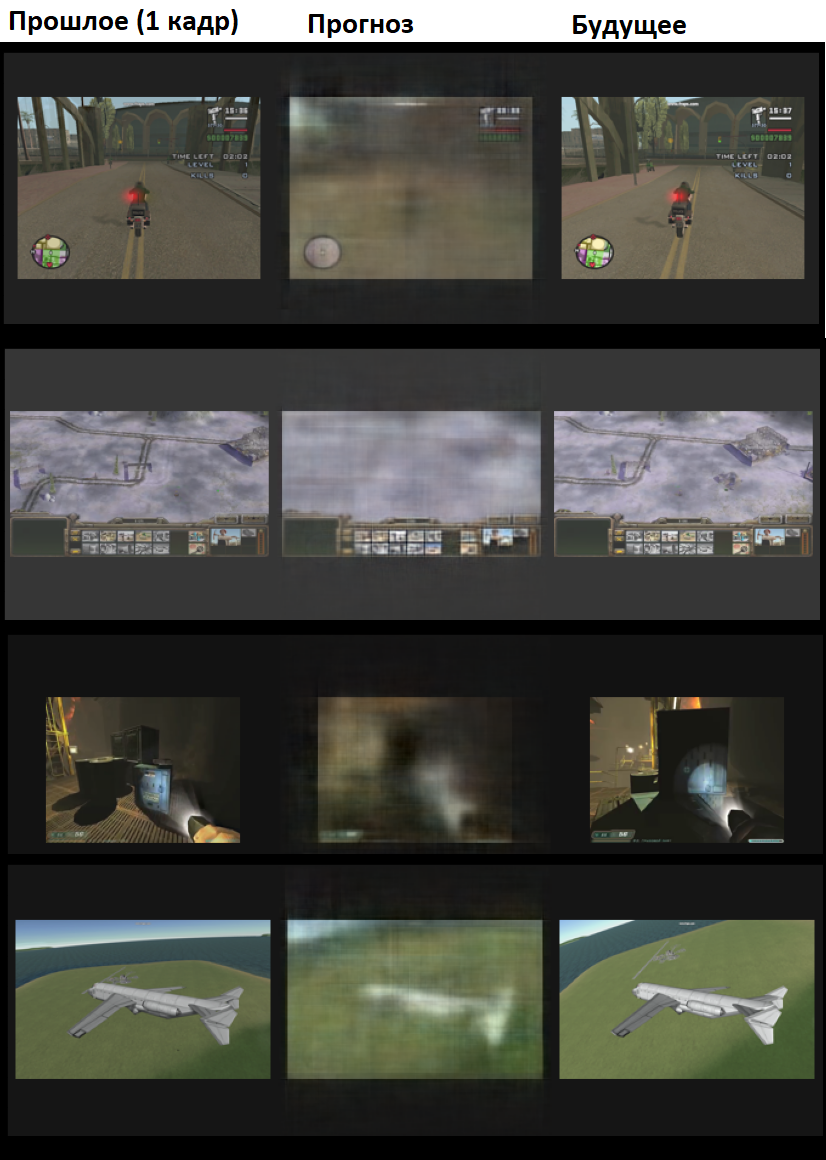

Чтобы убедиться, что система не просто замыливает последний кадр, а именно делает прогноз, взгляните на картинку с самолётом: там видно, как система предсказывает сдвиг линии горизонта.
Автоэнкодер хорошо замечает статические и контрастные детали - например, он быстро научился отрисовывать небо и графические интерфейсы.
Кроме того, я сделал ещё один кодировщик. На этот раз на входе был всё такой же видеоряд, но только из шутеров. А на выходе было сразу несколько вещей: предсказанный следующий кадр, сколько здоровья снимут главному герою в ближайшее время (и два разных горизонта прогноза), сколько он убьёт врагов и подберёт предметов. И размер эмбеддинга - 30 floatов.
Разумеется, картинка предсказалась хуже (первые 2 кадра - это вход, затем прогноз, затем фактическое будущее):



Впрочем в реальных испытаниях, в сцепке с Reinforcement learning, лучше сработал именно второй автоэнкодер.
Вообще, насколько важно, что "автоэнкодер" предсказывает картинку, если он её предсказывает настолько плохо? Сложно сказать, но наверное, это позволяет различать сцены, которые в равной мере перспективны с точки зрения наград, но выглядят по-разному, хотя бы имеют разную освещённость.
Среда и бейзлайны
В основном мои тесты происходили внутри vizdoom - это порт Doom, пригодный для запуска из Питон. На вход reinforcement learning получал картинку, на выходе у него набор действий, связанных с движением, стрельбой и открыванием дверей.
Сигнал наград завязан на убийство врагов (+1 за каждую смерть противника), попадания (+0.15 за попадание), подбор предметов (+0.1 за предмет) и изменение здоровья (+0.005 за каждую единицу здоровья, но это скорее сигнал наказания, так как здоровье чаще убывает).
Я использовал для сравнения два основных управляющих алгоритма .
Во-первых, это полный рандом. Полностью случайные действия.
Во-вторых, это sarsa. Одна нейросеть предсказывает, насколько перспективна позиция - оценивает суммарную награду за следующие несколько шагов по пришедшему эмбеддингу. Вторая оценивает ошибку первой, зная эмбеддинг и предпринятое действие. То есть, условно, первая нейронка говорит: обычно в такой ситуации мы убиваем в среднем 2 монстров. А вторая говорит: причём если мы станем стрелять, то это число вырастет на 1, а если идти влево, то упадёт на 2.
Кроме того, есть оценка новизны для каждой позиции. Эта оценка суммируется с сигналом награды, так что бот будет не только отрабатывать наилучшую известную стратегию, но пытаться открывать что-то новое.
Примерно так это выглядит на графике. Синее - это суммарная награда за последние несколько шагов. Она взята с экспонентциальным затуханием, чтобы более близкая награда воспринималась как более важная. Оранжевое - суммарная затухающая награда с учётом новизны позиции (мы дополнительно немного награждаем систему, если она проходит кадры, непохожие на те, что были в прошлом). Зелёное - оценка перспективности позиции, исключительно из знания самой позиции (state -> reward). Красное - коррекция этого прогноза нейросетью, которая знает и позицию (эмбеддинг), и действие (state+action -> reward).

Как выяснилось, sarsa решает большинство тестовых задач ощутимо лучше полного рандома. Спотыкается лишь на тех, где награды наиболее редки. И, что важно, sarsa выходит на хорошие результаты за 5-10 эпизодов. То есть 5-10 партий рандомит - и дальше начинает почти стабильно выигрывать.
Может, отказаться от dreamer и делать ИИ на базе sarsa? Он же реально быстро учится.
Дело в том, что у sarsa есть теоретические ограничения эффективности. Мы предсказываем награду на следующих шагах, исходя из истории. То есть исходя из неявного предположения, что мы будет действовать примерно так же, как в прошлом. Таким подходом очень тяжело сформировать сложный навык. Например, наш reinforcement learning может пробежать через лужу кислоты за большой аптечкой. Лужа снимет 5 хп, аптечка даст 25 - всё нормально. Но sarsa не знает, как он себя поведёт после того, как наступит в кислоту. Может, он встанет на месте. Может, отступит. А может, пройдёт к аптечке. В результате ожидаемые потери от кислоты очень сильно зависят от того, как раньше sarsa вёл себя, попав в кислоту.
Поэтому делаем dreamer.
Dreamer, попытка номер один
Я сделал нейросеть, которая по нескольким эмбеддингам и действию предсказывает следующий кадр - она работала на LSTM. Это должна была быть “модель мира” для dreamer.
Первым делом стало понятно, что учится она очень долго. А обучившись, всё равно выдаёт ошибку в 25-30%. Я попробовал другие архитектуры нейросетей - например, вместо LSTM-слоя пробовал полносвязный слой или даже трансформер. Ничего подобного, качество низкое. Когда обучаешься на таких “снах”, получается совершенно нежизнеспособная стратегия.
Тогда я попробовал сделать ход конём: в мире машинного обучения существует невероятно точная, универсальная и быстрая модель. Да, у неё есть некоторые недостатки, но на своём поле эта модель побеждает любые нейросети. Я говорю о бустинге решающих деревьев. LightGBM, XGBoost, Catboost - вот простые способы создать систему сверхчеловеческой точности.
Я сделал массив бустингов. Каждый из них принимал на вход данные последних нескольких эмбеддингов, а так же последнее действие агента, а на выходе предсказывал одну компоненту эмбеддинга. Чтобы всё это не переобучилось, а разделил выборку на train и validation, и строил новые деревья, пока validation не начнёт проседать.
7-10% ошибки. Победа! Но нам же надо не на один шаг прогнозировать, а на… Сколько будет 10 секунд в кадрах? 250-300 шагов - это минимум. Уже на втором шаге модель на вход получает данные, которые в прошлый раз выдала на выходе. С погрешностью, разумеется. Насколько же быстро прогноз “шёл в разнос”?
На 2-м шаге ошибка с 7-10% взлетала до 40-100%. Эффект бабочки на максималках.
Разумеется, меня это не устроило, и я решил аугментировать данные. Сделать несколько копий входных данных с шумами, чтобы сделать прогнозную систему более устойчивой.
Это не помогло: бабочка продолжала издевательски махать своими крыльями, вызывающие ураганы на другом краю Земли.
Я осознал, что в большинстве статей по системам с рекуррентным планированием эффекту бабочки не уделено почти никакого внимания. Да, говорят, что если предсказывать мир покадрово, то прогноз деградирует, и кадру к 50-му вырождается. Но не предлагают какую-то хорошую теорию, которая бы объясняла, что может усилить или ослабить эту нестабильность, и как с ней вообще работать.
Вместо этого рассказывают, как тяжело перебирать большое число планов внутри модели. Но это как раз не выглядело для меня проблемой - если существуют model-free системы вроде той же sarsa, значит, можно запустить их в виртуальной реальности, порождённой нейросетью, и не придётся тестировать огромное число траекторий.
Model-based и попытка номер 2
Где-то примерно на этом месте я стал задаваться вопросом: почему я делаю, как в статье гугла, но у меня не получается? Именно в этот момент я скачал и запустил оригинальный dreamer, и именно тогда я понял, что творение гугла настолько неэффективно по данным.
Я добыл на гитхабе коды множества model-based reinforcement learning. Это системы, которые могли предсказывать кадры, которые выдаст среда, если в неё зарядить какие-то определённые действия.
Оказалось, что все системы, которые я увидел, обладают одним важным общим свойством. Они делают прогноз одномоментно на много кадров вперёд. Нейросеть за один прогон порождает не один кадр, а сразу цепочку. Да, и это была не LSTM, а гибрид конволюционной и полносвязной сети - как мои “автоэнкодеры”.
Немного творческой доработки - и у меня есть модель, умеющая по цепочке эмбеддингов, старых действий и запланированных новых делать прогноз на много кадров вперёд за один проход.

По-моему, модель выглядит убого и плохо. Ни тебе LSTM, ни трансформера, план на будущее заряжается просто “вповалку”.
Но, важный момент. Эта модель реально работает. На уровнях из Doom она давала ошибку в 10-20% на горизонте в 50-110 кадров, и эта ошибка не росла с огромной скоростью. А если на спрогнозированных кадрах построить ещё 50-110 следующих, то ошибка не взлетит экспонентциально. Таким подходом можно прогнозировать кадров на 300 вперёд (блоками по 50-100 кадров), и не получать существенного эффекта бабочки.
Например, посредственно обученная модель выдаёт прогноз вот с такой погрешностью:

Это 3 шага прогноза по 90 кадров каждый. Я брал средний модуль ошибки (mae) и делил на средний разброс эмбеддингов (их std).
А ошибка в 10-20% - это много или мало? Если мы с такой точностью оцениваем награду, это очень хороший результат. Но мы-то оцениваем эмбеддинг, а награду рассчитываем уже по нему, другой нейросетью (которая в свою очередь обучается на реальных исторических сигналах награды).
Итак, я сделал простой model-based reinforcement learning. Берём текущую ситуацию, предлагаем несколько сотен планов, прогнозируем траекторию (последовательность эмбеддингов) для каждого плана. Каждый эмбеддинг оцениваем на предмет ожидаемой награды, выбираем траекторию с максимальной наградой, выполняем то действие, с которого траектория начинается. И при любой возможности дообучаем модель мира (states+actions->next states) и модель награды (state->reward).
Этот model-based отработал. Он был медлительным и показал результаты хуже, чем у sarsa, но лучше, чем у рандома. Тем не менее, на задачах с особенно разреженными наградами он отработал относительно хорошо - лучше, чем sarsa.
Тогда я сделал некое подобие dreamer: модель мира генерирует множество траекторий, и на них обучается actor-critic алгоритм. И уже actor-critic принимает решения.
Вот только у actor-critic есть нехорошее свойство… Когда он оценивает “потенциал” позиции, то есть награду, которой можно из этой позиции достичь, он использует рекурсивную q-функцию. Что это значит? Он разбивает всю историю на пары позиций: прошлая позиция и будущая. А дальше считает для каждой позиции потенциал.
Допустим, так. У нас в кадре 50 было 2 единицы награды, а в кадре 51 было -1 награды. Считаем, что награды, которые ближе к нам во времени, важнее тех, что дальше. Для простоты считаем, что в 2 раза за каждую единицу времени.
Итого, говорим, что потенциал (q-функция) 50-ой позиции равен 2+0.5*(-1) = 1.5. Но это потенциал точки с горизонтом планирования 2. А если нам нужно больше? Надо вместо награды во “второй” точке подставить q-функцию, и снова посчитать ту же формулу. А откуда мы узнаем q-функцию для, в нашем случае, 51-ой точки? Наверное, рассчитаем, исходя из 52-й точки. Ладно, а если это невозможно, так как 51-я точка - последняя? А мы хотим горизонт в 200 шагов?
Тогда надо построить модель, которая по эмбеддингу предсказывает q-функцию в точке. А затем неизвестные значения q заполнить моделью.
Хотим дальность прогнозирования в 200 шагов? Нам надо 200 раз обучить модель и 200 раз сгенерировать прогноз.
Во-первых, это ужасно долго. Во-вторых, у нас даже награды предсказаны машинным обучением - с ненулевой погрешностью. А мы от них считаем какую-то функцию и делаем её таргетом другой нейросети. Затем берём выходы уже получившейся нейросети, складываем с наградами и снова делаем таргетом для нейронки. 200 раз подряд. Интуитивно кажется, что машинное обучение поверх машинного обучения - это не очень хорошо, а если ещё и делать так рекурсивно, то ошибка будет расти лавинообразно.
Итак, на практике мой dreamer с actor-critic внутри отработал неплохо. Хуже, чем sarsa, а главное, намного медленнее. Но лучше, чем полный рандом. Может, ML поверх ML - это не так уж и плохо?
В любом случае, проблема медлительности никуда не исчезла. Поэтому я решил рассчитать q-функцию так, как это делается в sarsa. Сгенерить множество случайных планов, по ним построить траектории, по ним рассчитать дисконтированную (то есть с экспоненциальным затуханием) награду.
Сделал. Назвал эту конструкцию dreamer-sarsa. Работала система и правда быстрее, чем dreamer с actor-critic, но эффективность значительно упала. Почему?
Не могу сказать, почему вышло хуже, чем в прошлом dreamer, но скажу, почему получилось хуже, чем в sarsa.
Когда мы оцениваем потенциал точки по фактически пройденным траекториям, мы очень зависим от того, как мы действовали на тех траекториях. Если в одну и ту же среду поместить случайную стратегию и, например, sarsa, то sarsa через некоторое время обучится какой-то хорошей стратегии и получит траектории с более высокой наградой, чем у случайного алгоритма. Примерно так:

На картинке видно, что даже хороший алгоритм не сразу находит действенную стратегию, либо использует разведку, либо ещё по каким-то причинам действует неоптимально. В любом случае, средняя награда по траекториям (а значит, и q-функции у стартовой точки) будет совершенно разным в зависимости от того, какая стратегия порождала эти траектории.
Дальше были следующие соображения. Существует уравнение Беллмана - оно позволяет рассчитать q-функцию так, будто мы используем наилучшую возможную стратегию. Даже без знания этой стратегии и наилучшей траектории. Это хорошо, но уравнение Беллмана рассчитывается рекурсивно, по формуле, похожей на формулу q-функции в actor-critic. Это значит, что во-первых, долго, во-вторых, ML поверх ML с соответствующим накоплением ошибок.
Можно было бы создавать планы действий, похожие на те, что были раньше - например, генерировать их специальной нейросетью. Можно попробовать взять нейросеть, которая устойчиво предсказывает на 100 шагов вперёд, и брать прогноз только 1-го шага. И таким образом можно не просто генерировать траектории, а сделать полноценную интерактивную виртуальную реальность, где будет обучаться какой-нибудь алгоритм, у которого совершенно ужасный sample-efficiency, но который находит хорошие стратегии.
В любом случае, в первую очередь нужно проверить, правда ли проблема именно в том, что траектории порождены плохой стратегией. Поэтому я сделал надстройку над своим dreamer-sarsa: теперь он берёт множество начальных точек и для каждой создаёт множество траекторий. А потом оставляет несколько наилучших. Например, берёт 500 эпизодов прошлого, для каждого эпизода создаёт 300 планов длиной 800 шагов. Исполняет, оценивает планы. Оставляет 3 наилучших (с максимальной суммой наград). Получается 500х3=1500 траекторий по 800 шагов длиной. Запускаю и… dreamer-sarsa-filter отрабатывает лучше, чем просто dreamer-sarsa! И почти настолько же быстро.
Испытания
Приведу таблицу со сравнительной оценкой полученных reinforcement learning. В таблице видно, что тестировал я не всё - к сожалению, мои RL чересчур медлительны. Испытывал я их преимущественно на историях в 15-30 эпизодов, то есть гугловый dreamer за это время показывает результат как у полного рандома.
Испытание | random | sarsa | model-based | dreamer | dreamer-sarsa | dreamer-sarsa-filtered |
basic map 6 (впереди тёмный коридор, по бокам столбики) | 2.0296 | 3.05 | 2.235 | 2.6 | ? | 2.46 |
defend center (персонаж в центре хорошо освещённого зала, вокруг монстры) | 0.975 | 2.306 | 1.32 | ? | 1.17 | 1.38 |
doom 2 map 5 (персонаж в комнатке, впереди выход в коридор к монстрам) | 0.981 | 0.64 | 0.93 | 1.27 | 1.17 | 1.21 |
Приведу так же видеозаписи с испытаний этих RL. Я брал типичные эпизоды обученного RL - не слишком удачные, и не слишком провальные. Сразу оговорюсь: хотя исполнение стратегий неустойчиво (sarsa может в одном эпизоде получить 3 очка, а в следующем 1), сам процесс обучения устойчив, то есть при множестве пусков один и тот же алгоритм RL за 30 эпизодов сойдётся примерно к одному и тому же среднему значению награды.
Так как мне не удалось вставить сюда красивую таблицу с гифками, реализую её в виде ссылки
Во-первых, видно, что в большинстве случаев RL вообще никуда не попадают. Как они набивают очки?.. На самом деле, они получают очки в случае, если монстр погибает по любой причине. Поэтому очень популярны стратегии, при которых RL стрельбой привлекает внимание монстров, а потом движется так, чтобы они сами друг друга поубивали случайными попаданиями.
Во-вторых, как можно увидеть по этим записям, стратегии sarsa ощутимо выбиваются. Sarsa намного более склонны… Поступать нестандартно, что ли?
Почему так получается? Вероятно, всё дело в эвристике любопытства. Значит, надо добавить эту эвристику в dreamer - и посмотреть, что получится.
Эвристика любопытства называется RND - random network distillation. Суть её в том, что мы создаём случайно инициализированную нейросеть, которая принимает на вход эмбеддинги и выдаёт некие вектора. И делаем вторую нейросеть, которая предсказывает выходы той, случайной. Если предсказываем хорошо - значит, ситуация знакомая. Если высокая ошибка - значит, ситуация новая, и надо увеличить награду на эту “степень новизны”.
Испытание:
random | sarsa | model-based | dreamer | dreamer-sarsa | dreamer-sarsa-filtered | dreamer-rnd | |
basic map 6 | 2.0296 | 3.05 | 2.235 | 2.6 | ? | 2.46 | 2.7 |
defend center | 0.975 | 2.306 | 1.32 | ? | 1.17 | 1.38 | 1.06 |
doom 2 map 5 | 0.981 | 0.64 | 0.93 | 1.27 | 1.17 | 1.21 | 1.23 |
doom 2 map 11 (впереди бассейн кислоты) | 0.15 | -0.05 | ? | ? | ? | ? | 0.21 |
Как видим, dreamer-rnd работает довольно устойчиво, и почти догоняет тот dreamer, что использует actor-critic. sarsa работает не очень устойчиво - не со всеми окружениями справляется. И все эти RL вообще даже близко не подходят к человеку.
Каков же потенциал развития?
Где-то примерно на этом этапе я догадался посмотреть, на каком числе последовательностей обучается модель мира. Оказалось, что всё грустно - каждый её период обучения затрагивает десятки последовательностей - это очень мало, странно, что мы вообще хоть чему-то обучились. А всё потому, что когда я разбивал на весь таймлайн на батчи, я делал их непересекающимися. А длина единичного прогноза у меня ~100 эмбеддингов.
Хорошо, расположим батчи внахлёст.

И, пока идёт тестирование, проведём ещё одну проверку. Нам же хотелось бы узнать, какие траектории генерирует дример? Траектории, правда, из эмбеддингов, так что посмотреть мы их не сможем. А так как у меня не совсем автоэнкодер, то декодирующая часть не выдаст вменяемую картинку на выходе. Но можно для каждого эмбеддинга подыскать наиболее похожий из недавней истории. И затем найти кадр, который по времени совпадал с этим эмбеддингом. Таким образом мы всё-таки найдём что-то похожее на сгенерированную траекторию.
Сделаю, чтобы траектория воспроизводилась замедленно - так будет меньше мельтешения.
Итак, с новой схемой обучения модель учится значительно быстрее. Рост обучающей выборки скомпенсировался уменьшением числа эпох, и в сумме и скорость обучения (и в секундах, и особенно в эпизодах) выросла, и точность.
А сгенерированные эпизоды выглядят примерно так.
Как видим, не все траектории одинаково полезны. Ну и технология визуализации не совсем удачная.
Тем не менее, новая версия dreamer смогла добиться чуть лучших результатов, чем предыдущая, по крайней мере, на этой карте. 2.88 очков против 2.7 у наилучшего из прошлых дримеров и против 3.05 у sarsa.
Проверим теперь, работают ли мои RL-системы на других окружениях, не на Doom. Как мы помним, энкодер обучен на шутерах, так что в 2-мерных играх Atari вполне может и не разобраться. С другой стороны, большинство видеоигр так или иначе моделируют наш 3-мерный мир дискретных объектов и ньютоновской механики, так что возможно, энкодер от шутеров вполне применим для игры Pong. Ну и с третьей стороны, алгоритмам RL в некотором смысле безразлично, как именно им подают данные. Лишь бы разные ситуации выглядели для него по-разному, а ситуации, выглядящие похоже, развивались похожим образом.
Итак, dreamer последней модели выдал -20.19 очков, а рандом -20.09. RL не обучился. Но есть интересное наблюдение. Модель научилась очень точно предсказывать и награды, и эмбеддинги.
Прогноз наград (синее факт, оранжевое прогноз):

Ошибка прогноза эмбеддинга, измерено в стандартных отклонениях:

Ошибка всего в 5%, почти нет эффекта бабочки. В чём может быть проблема?
Я вижу такие варианты:
Модель прогноза траекторий почему-то предсказывает траектории верно, если они фактически были и неверно, если их никогда не было. Такое могло бы быть в случае переобучения. Но обучение модели построено так, что примерно каждый двадцатый батч попадает в обучающую выборку, а затем от этой выборки отрезается ещё и валидационная для раннего останова. Причём собственно на fit поступает не более 100 батчей, а всего их может быть больше 500 - все остальные идут на валидацию.
Переобучение системы, предсказывающей награды. У неё есть регуляризация и аугментация данных, но нет разделения выборки на train, test и validation.
Мы как-то неправильно строим стратегию по известной модели мира.
Вариант 2, похоже, проверить нетрудно. Посмотрим, насколько точно модель предсказывает новые сигналы подкрепления, и насколько точно она их предсказывает после того, как дообучилась на них.

На картинке один и тот же эпизод до того, как система на нём дообучилась (test) и после. Итак, модель наград у нас не переобучена.
Посмотрим, какие награды эта модель видит на различных траекториях. Сгенерируем траектории и найдём точки с максимальной, минимальной и медианной наградами.
Минимум: -20.324026, медиана:0.93079257, максимум: 10.992256.
Это выглядит очень неправдоподобно. Награда в конкретной точке может быть от -1 до 1, в большинстве случаев должен быть 0. Ладно, у нас происходит отбор траекторий, медиана должна быть больше нуля. Но чтобы настолько? Построим гистограмму наград в точках построенных траекторий:

-20 и 10 - это, конечно, редкие выбросы. Но всё равно, “колокол” наград очень широкий. Не должна нейросеть выдавать такие числа. Такое распределение означает, что нейросеть всё-таки переобучена: для неё реальные и сгенерированные данные выглядят по-разному, и на сгенерированных нейросеть ведёт себя неадекватно.
Первое, что приходит в голову, когда смотришь на такую проблему - это изменение активационной функции. Пусть будет не relu на выходе, а сигмоида или арктангенс - у них есть вполне ограниченное множество значений. Вторая идея - аугментировать обучающую выборку для той сети, что предсказывает награды. Продублировать несколько раз и зашумить.
Попробуем второй вариант, с аугментацией. Только тогда надо уменьшить регуляризацию, а то вообще ничему не обучимся.
Итак, да. Идея оказалась удачной. Распределение наград на сгенерированных траекториях:

Прогноз наград на тестовой выборке (довольно неплохо, учитывая, какую аугментацию мы провели):

И график набранных очков по раундам:

Средний балл -19.87 против -20.09 у рандома, всего на 14 раундах. Впрочем, это может быть случайность, надо перепроверить.

-20.20 очков. Меньше, чем у рандома? Неужели в Pong рандом набирает и правда -20.09 очков, при том, что если в среднем один раз за два эпизода закидывать мяч на сторону противника, то будет -20.50 очков? Проверить на большом числе случайных партий!
Проверка показывает, что у рандома график выглядит следующим образом:

И средний score равен -20.34. Хорошо, это уже более правдоподобно. Видим, что RL опять же набирает больше очков, чем рандом, но лишь самую малость.
Длительные испытания
Проверим, как наш dreamer будет справляться, если запустить его не на 15-50 эпизодах, а на тысячах. Но чтобы это обучение можно было провести в разумные сроки, надо модифицировать dreamer:
Уменьшить число эпох обучения всех нейросетей
Уменьшить число воображаемых траекторий
Ввести способ принятия решений из actor-critic - он (вроде как) даёт лучшие результаты, а q-функцию можно рассчитывать на 1-2 шага за эпизод, а не на 25-100 шагов, как было раньше.
Назовём эту систему dreamer-light. В любом случае, узким местом останется энкодер - он тратит ~0.1 секунды на один кадр.
Итак, испытание законичлось провалом. На карте “basic map 6” dreamer light настрелял 1.73 очка в среднем по 826 эпизодам - а рандом набивает чуть больше 2 очков. Но посмотрим на детали этого провала. Мы невероятно точно предсказывали траектории - самые серьёзные ошибки выглядели так:

То есть первый участок траектории предсказан околоидеально, на втором отдельные выбросы. Так как схема actor-critic не требует длинных траекторий, которые рискуют эффектом бабочки, мы и не генерировали больше кадров, чем нейросеть может выдать за один прогон. И таких выбросов не было.
А вот награды мы предсказывали плохо:

И это проблема не на уровне нейросети. Большинство крупных положительных наград - это ситуации, когда один монстр убивал другого, иногда ещё и вне поля зрения RL-агента. А большинство отрицательных наград - это попадание в RL-агента из пулемёта или дробовика. То есть это во-первых, вероятностный процесс из-за разлёта пуль, во-вторых, подлетающая пуля не видна, и не всегда понятно, что в нашего персонажа уже стреляют. И, наконец, RL-агент может не смотреть туда, где находится противник, и не знать, что по нему уже ведут огонь.
Если бы я видел только этот график и эти рассуждения, то сказал бы, что любые разновидности dreamer вообще не смогут справиться с Doom (а с Pong сможет без проблем). Тем не менее, у нас dreamer-ы с другими настройками вполне успешно справлялись. Кроме того, если предсказывать не точечную награду, а дисконтированную (сумму наград за следующие насколько кадров, с экспоненциальным затуханием), то получится отличная точность:

И эта отличная точность может быть связана с тем, что мы делали энкодер так, чтобы он хорошо предсказывал будущие дисконтированные награды.
Проверим, как dreamer light справится с Pong.
Никак он не справился. Отличная точность прогноза наград, отличная точность прогноза эмбеддингов - и при этом дример умудрился играть намного хуже рандома.

Выводы.
Пока проводил все эти эксперименты и пытался воспроизвести dreamer, пришёл к следующим соображениям:
Знание математической концепции какого-либо ИИ - это совершенно недостаточно. Есть множество деталей, которые не выглядят концептуально важными, но от которых зависит успех. Например, для построения будущей траектории можно использовать рекуррентный прогноз, а можно однократно выдавать батч в 100 кадров - и результат будет радикально разный. Или можно брать существующую траекторию и рассчитывать наилучшие ходы методом actor-critic, а можно методом sarsa, и результат будет совершенно разный. Концепции интеллекта из психологии или нейрофизиологии в этом плане ещё хуже: они ещё менее конкретны и в них ещё меньше понятно, где реально необходимые детали, а где “костыли”, связанные с тем, что интеллект приходилось собирать из мяса.
Возможность визуализации кадров очень важна. Я сделал энкодер, который делает такой эмбеддинг, из которого нельзя котором развернуть картинку - и это была сомнительная идея.
Создать модель мира, которая по действиям предсказывает следующие эмбеддинги - это нетрудно (задумайтесь, что было бы, если бы в своей жизни могли видеть будущее с 5% погрешностью на приличное расстояние вперёд). Даже в Doom это получилось довольно легко и точно. Даже с учётом откровенно дурацкой архитектуры сети.
Не всегда можно выстроить соответствие между наблюдаемым кадром/кадрами и наградой.
Есть какие-то проблемы с actor-critic - по крайней мере в моей реализации. Потому что ситуация, когда у нас есть отличная (с 5% погрешностью) модель мира, отличная модель наград и при этом не выстраивается стратегия - такая ситуация выглядит очень неправильной.
У нас есть RL, который довольно надёжно и быстро находит стратегию, которая лучше рандома.
У оргинального Dreamer намного быстрее отрабатывает энкодер. Вероятно, причина в том, что он более легковесный в силу более узкой специализации под задачу.
