
Данные. Они повсюду и их становится только больше. За последние 5-10 лет data science привлекла множество новичков, пытающихся ощутить вкус этого запретного плода.
Но как сегодня выглядит ситуация с наймом в data science?
Вот краткое изложение статьи в двух предложениях.
TLDR: в компаниях на 70% больше вакансий на должности дата-инженеров, чем на должности дата-саентистов. Так как мы обучаем новое поколение практиков в сфере обработки данных и машинного обучения, давайте сделаем больший упор на инженерные навыки.
Так как моя работа заключается в разработке обучающей платформы для профессионалов в области данных, я много думаю о том, как эволюционирует рынок вакансий, связанных с данными (машинное обучение и data science).
Общаясь с десятками перспективных новичков в сфере данных, в том числе и со студентами лучших вузов мира, я увидел серьёзное недопонимание того, какие навыки являются наиболее важными, помогают выделиться из толпы и подготовиться к карьере.
Дата-саентист может работать в любом сегменте следующих сфер: моделирование машинного обучения, визуализация, очистка и обработка данных (например, преобразование данных для SQL), проектирование и развёртывание на производстве.
С чего вообще начинать рекомендации курса обучения для новичков?
Данные говорят громче слов. Поэтому я решил провести анализ должностей в сфере данных, на которые есть вакансии у компаний, выходивших из Y-Combinator с 2012 года. Вопросы, которыми я руководствовался в своих исследованиях:
На какие должности в области данных компании нанимают чаще всего?
Насколько востребован традиционный дата-саентист, о котором нам сейчас так много говорят?
Релевантны ли по-прежнему те навыки, которые начали революцию данных?
Если вы хотите узнать подробности и изучить анализ, то продолжайте чтение.
Методология
Я решил провести анализ компаний из портфолио YC, которые, по их заявлению, выполняют какие-нибудь работы с данными.
Зачем фокусироваться на YC? Ну, во-первых, он ведёт каталог своих компаний, в котором легко выполнять поиск и скрейпинг.
Кроме того, как особо дальновидный инкубатор, в течение более чем десятка лет финансировавший компании по всему миру в разных отраслях, он, по моему мнению, образовал репрезентативную выборку рынка для проведения моего анализа. Тем не менее, относитесь ко всему написанному с долей скептицизма, потому что я не анализировал очень крупные технологические компании.
Скрейпингом я обработал URL главных страниц каждой компании YC с 2012 года, создав первоначальный пул из примерно 1400 компаний.
Зачем останавливаться на 2012 годе? В 2012 году AlexNet выиграла конкурс ImageNet, по сути, породив ту волну машинного обучения и моделирования данных, которую мы сейчас переживаем. Справедливо будет сказать, что это породило одно из первых поколений компаний, делающих основной упор на данные.
В этом первоначальном пуле я произвёл фильтрацию по ключевым словам, чтобы уменьшить количество релевантных компаний. В частности, я учитывал только компании, на веб-сайтах которых присутствовал хотя бы один из следующих терминов: AI, CV, NLP, natural language processing, computer vision, artificial intelligence, machine, ML, data. Также я не учитывал компании с поломанными ссылками на веб-сайты.
Появилась ли у меня куча ложноположительных данных? Конечно! Но на этом этапе я хотел обеспечить как можно более широкий охват, чтобы дальше можно было провести более тонкое исследование отдельных веб-сайтов вручную.
Уменьшив размер пула, я обошёл каждый сайт, нашёл раздел с вакансиями (обычно он называется Careers, Jobs или We’re Hiring), и зафиксировал каждую должность, в названии которой были указаны данные, машинное обучение, обработка естественных языков или компьютерное зрение. Это дало мне пул из примерно 70 компаний.
Примечание: вполне возможно, что я пропустил некоторые компании, потому что на отдельных веб-сайтах было очень мало информации, хотя компании могли и иметь вакансии. Кроме того, я встречал компании, у которых не было формальной страницы Careers, а только просьба связываться напрямую по электронной почте.
Я игнорировал оба типа компаний и не писал им, поэтому в моём анализе они не учитываются.
Ещё один аспект: основная часть этого исследования была проведена в последние недели 2020 года. Открытые вакансии могли измениться, потому что компании периодически обновляют страницы. Однако я не считаю, что это значительно повлияет на выводы.
В чём заключаются обязанности практиков по работе с данными?
Прежде чем приступать к результатам, стоит немного уточнить, какие обязанности имеют люди, работающие на каждой из должностей. Вот четыре должности, которые мы будем изучать, и краткое описание их обязанностей:
Дата-саентист: использует различные методики статистики и машинного обучения для обработки и анализа данных. Часто отвечает за создание моделей, проверяющих, что можно узнать из какого-то источника данных, хотя зачастую эти модели используются как прототипы, а не на производственном уровне.
Дата-инженер: разрабатывает надёжный и масштабируемый набор инструментов/платформ обработки данных. Должен хорошо быть знакомым с подготовкой информации для баз данных SQL/NoSQL и с созданием/поддержкой конвейеров ETL.
Инженер по машинному обучению (Machine Learning, ML): часто отвечает за обучение модели и за их ввод в производство. Должен знать какой-нибудь высокоуровневый фреймворк ML, а также хорошо освоить создание масштабируемых конвейеров для обучения и внедрения моделей.
Специалист по машинному обучению: работает над прогрессивными исследованиями. Обычно отвечает за исследование новых идей, которые можно публиковать на научных конференциях. Часто ему достаточно прототипировать новые модели, а потом передавать их инженерам по ML для внедрения в производство.
Сколько существует должностей по работе с данными?
Давайте попробуем составить график частоты каждой из должностей, на которые нанимают сотрудников компании. График выглядит так:
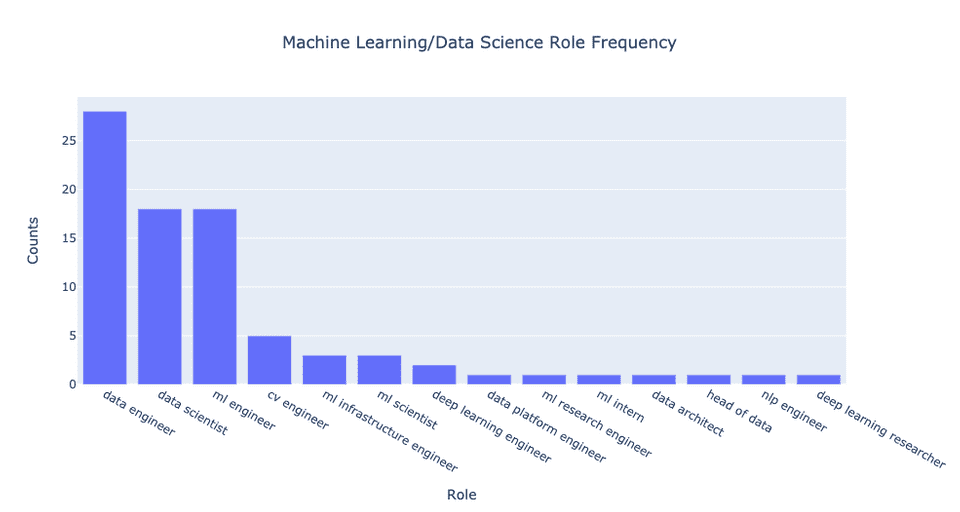
Сразу же становится заметным, что гораздо больше вакансий дата-инженеров (data engineer) по сравнению с традиционными дата-саентистами (data scientists). В данном случае компании нанимают приблизительно на 55% больше дата-инженеров, чем дата-саентистов, и примерно одинаковое количество инженеров по машинному обучению и дата-саентистов.
Но мы можем пойти глубже. Если посмотреть на названия различных должностей, то заметны повторения.
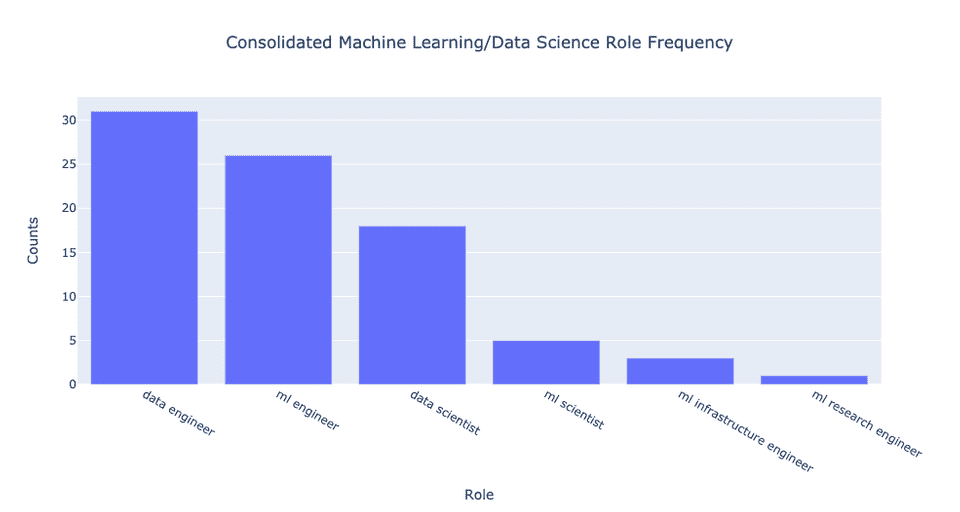
Давайте консолидируем должности, разбив их на приблизительные категории. Другими словами, я взял должности, описания которых приблизительно аналогичны, и объединил их под одним названием.
Использовался следующий набор отношений эквивалентности:
NLP engineer (инженер по обработке естественных языков) ≈ CV engineer (инженер по компьютерному зрению) ≈ ML engineer (инженер по машинному обучению) ≈ Deep Learning engineer (инженер по глубокому обучению) (хотя сферы могут быть разными, обязанности приблизительно одинаковы)
ML scientist (специалист по машинному обучению) ≈ Deep Learning researcher (исследователь глубокого обучения) ≈ ML intern (стажёр в области машинного обучения) (похоже, стажировка связана с исследованиями)
Data engineer (дата-инженер) ≈ Data architect (дата-архитектор) ≈ Head of data (руководитель отдела обработки данных) ≈ Data platform engineer (инженер платформы обработки данных)
Если вам не нравится работать с сырыми значениями, то вот процентное соотношение, чтобы упростить понимание:

Вероятно, можно было объединить ML research engineer или с ML scientist, или с ML engineer, но учитывая, что это довольно гибридная должность, я оставил всё как есть.
В целом, консолидация сделала различия ещё более явными! Существует примерно на 70% больше открытых вакансий дата-инженера, чем дата-саентиста. Кроме того, примерно на 40% больше открытых вакансий инженера по машинному обучению, чем дата-саентиста. Также есть всего примерно 30% вакансий специалиста по машинному обучению от количества вакансий дата-саентиста.
Выводы
Спрос на дата-инженеров значительно выше, чем на другие связанные с данными профессии. В каком-то смысле, это отражает эволюцию отрасли в целом.
Когда 5-8 лет назад популярность получило машинное обучение, компании решили, что им нужны люди, способные создавать классификаторы данных. Но потом фреймворки наподобие Tensorflow и PyTorch сильно выросли в качестве, упростив вход в область глубокого и машинного обучения.
Это сделало набор навыков для моделирования данных общедоступным.
Сегодня узким местом стала помощь компаниям во внедрении результатов машинного обучения и моделирования в производство из-за проблем с данными.
Как аннотировать данные? Как обрабатывать и очищать данные? Как перемещать их из А в Б? Как делать это ежедневно и как можно быстрее?
Всё это сводится к необходимости хороших инженерных навыков.
Это может казаться скучным и несексуальным, но, возможно, сегодня нам нужно олдскульное проектирование ПО с уклоном в данные.
Благодаря крутым демо и ажиотажу в медиа мы годами были очарованы идеей о профессионалах обработки данных, вдыхающих жизнь в сырые данные. Вспомните, когда в последний раз вы видели статью на TechCrunch о конвейере ETL?
Во всяком случае, мне кажется, что мы делаем недостаточный упор на крепкие инженерные навыки в подготовке к работе в data science и в обучающих программах. Кроме обучения пользованию linear_regression.fit() стоит учиться и написанию юнит-тестов!
Значит ли это, что вам не надо изучать data science? Нет.
Это значит, что конкуренция будет жёстче. Для избытка новичков на рынке, обученных data science, будет меньше вакансий.
Всегда будет существовать спрос на людей, способных эффективно анализировать данные и извлекать из них важную информацию. Но они должны быть хороши.
Скачивания предварительно обученной модели с веб-сайта Tensorflow на основе набора данных Iris, вероятно, больше недостаточно, чтобы получить работу в data science.
Однако очевидно, что при наличии множества вакансий инженеров по машинному обучениюкомпании часто хотят получить гибридного специалиста по данным — того, кто способен создавать и внедрять модели. Или, если говорить кратко, того, кто может пользоваться Tensorflow, но также способен собрать его из исходников.
Можно сделать и ещё один вывод: вакансий в исследованиях машинного обучения не так уж много.
Исследования машинного обучения получают свою долю хайпа, потому что именно в нём происходит прогресс, все эти AlphaGo, GPT-3 и прочее.
Однако для многих компаний, особенно находящихся на ранних этапах развития, больше необязательно находиться на рубеже прогресса. Часто для них ценнее получить модель, выполняющую задачи на 90%, но способную масштабироваться до тысячи и более пользователей.
Я не хочу сказать, что исследования машинного обучения не важны. Разумеется, это совершенно не так.
Но вы, вероятно, найдёте больше подобных вакансий в исследовательских лабораториях, способных делать большие капиталовложения в течение долгих периодов времени, а не в стартапе на первом этапе финансирования, пытающемся продемонстрировать инвесторам свою пригодность для рынка продуктов.
Я считаю, что важно калибровать ожидания новичков в сфере обработки данных. Мы должны признать, что сегодня data science стала другой. Надеюсь, этот пост позволил пролить свет на современное состояние отрасли. Только узнав, где мы находимся, мы поймём, куда стоит двигаться.
