
Всё началось с мема, который вы видите выше.
Сначала я посмеялся. А потом задумался: может ли быть так, что скриншот базы равноценен её снэпшоту?
Для этого у нас должно быть такое графическое представление базы, которое 1 к 1 отображает данные и структуру. Если сделать скриншот такого представления, из него можно восстановить базу.
Или... графическое представление и должно быть базой!
Тут, безусловно, можно схитрить и упростить себе жизнь:
Мы можем просто вывести sql скрипт в мелкопиксельном виде, а потом распознать текст со скриншота
Мы можем закодировать sql скрипт в бинарном виде и представить в виде изображения (4 байта на пиксель). Тогда скриншот тоже можно будет легко распарсить.
Но это всё ленивые и скучные способы. Куда интереснее было бы спроектировать базу так, чтобы мы действительно работали с ней как с изображением. Рисовали в пейнте и фотошопе, а не в этих скучных sql консолях и UI с таблицами.
По сути своей это вариант базы, с которой может работать художник (DBA-artist). Ну и конечно для неё нужен будет некий api, потому что использовать данные всё равно будет обычное приложение на обычном языке программирования, которому непонятны все эти художества, ему подавай json-ы.
Как вы понимаете, задача несёт исключительно исследовательский характер.
Начнём с формата данных.
Формат данных
Безумно велик соблазн использовать картинку просто как массив байт. Это и читать и писать удобнее. Для машины. Но цель - сделать не просто массив байт представленный в виде картинки, а осмысленное изображение, которое одновременно является источником данных.
Начнём с простого. Данные на картинке надо как-то находить. Вернее отличать данные от мета-информации и “отсутствия данных”. Давайте выберем некий маркерный цвет и попросим наших DBA-артистов рисовать квадраты этим цветом. Всё, что внутри - данные. Снаружи - не данные.
Цвет я выбрал таким, чтобы он хорош запоминался и при этом не было слишком “простым”, т.к. цвета вроде 0xFF0000, 0x00FF00 и иже с ними наверняка часто будут использоваться в данных.
Выбор пал на 0xBADBEE - нежно-голубой цвет, хорошо смотрящийся на белом фоне, и с мнемоническим названием. Ну и заодно саму базу я тоже так назвал.

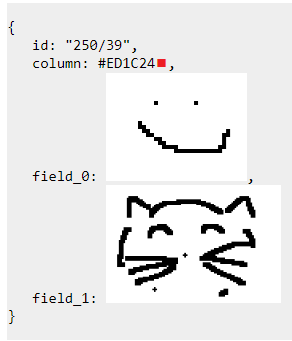
Перед вами простейшая БД с одной записью типа “картинка”. Если запустить сервер badbee, дать ему такую картинку, а потом воспользоваться встроенным клиентом, то он покажет нам вот такой стилизованный json:

И, кстати, можно сделать скриншот и вставить в свою базу.
Инструкция для тех, кто хочет попробовать
git clone https://github.com/AlexeyGrishin/badbee.gitустановите докер
docker build -t badbee .создайте
db/temp.pngdocker run -d --rm --name badbee -e DB_FILE=temp.png -p 3030:3030 -v "$pwd/db:/usr/badbee/db" badbeeоткройте http://localhost:3030 . Убедитесь что клиент открылся.
сделайте скриншот или просто скопируйте картинку выше и вставьте в
temp.pngнемножко подождите и F5
Если у вас возникли сложности с докером, то можно так:
git clone https://github.com/AlexeyGrishin/badbee.gitInstall rust & cargo from https://www.rust-lang.org/tools/install
Install wasm-pack from https://rustwasm.github.io/wasm-pack/installer/
cargo build.cd web-clientwasm-pack build --out-dir ../static --target webcd ..cargo run --package web-serverВероятно надо будет поставить visual studio build tools, но вам об этом скажут или на этапе инсталляции, или на этапе сборки
Первичные ключи
Необязательно, но желательно иметь для записей уникальные первичные ключи. Хотя бы для того, чтобы ссылаться на них из других мест. Я подумал и решил, что самым простым будет использовать координаты верхнего левого угла. Это будет точно уникальный id в рамках БД, его довольно легко получить в любом редакторе изображений. Да, если подвинуть запись, то её id изменится, хотя сама она не поменяется. Ну и ладно, просто будем иметь это ввиду.
Организация данных
Одиночные записи нужны редко. Чаще нам нужно несколько “колонок” для хранения разных сведений. И проще всего это организовать соединив несколько записей визуально.
У нас уже получается база, где хранятся владельцы и их питомцы, причём питомцев может быть разное количество.
Добавим ещё одного человека, у которого есть три рыбки, и одного грустного приятеля без питомцев.
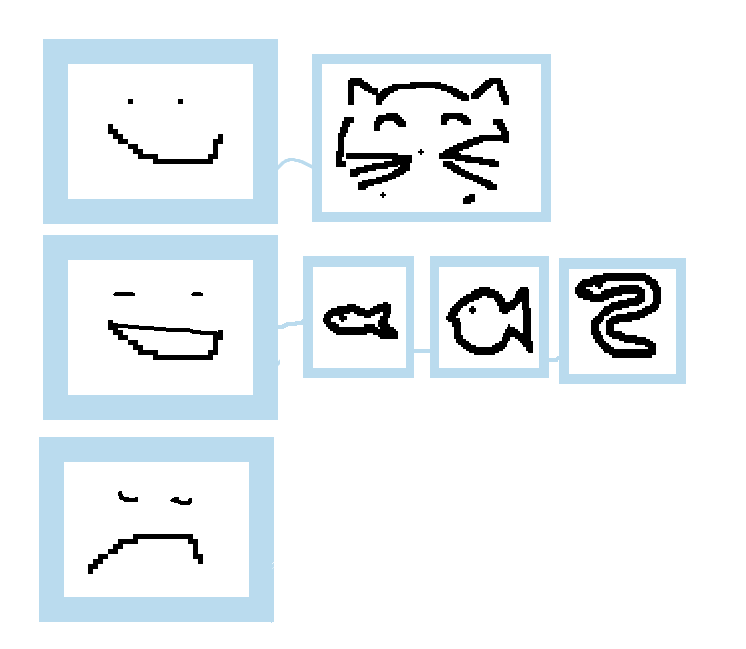
Если заполнить базу большим количеством записей, то в них становится сложно ориентироваться, выбирать что-то и искать. Я имею ввиду - программно. Глазами-то как раз всё легко.
Чтобы упростить себе жизнь и использовать преимущества пространственного расположения, я ввожу понятие “столбца” - тот самый загадочный “column” из примеров выше.
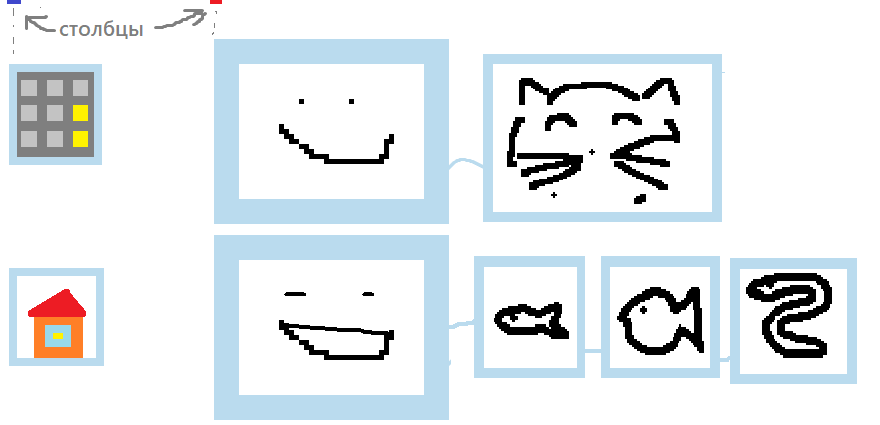
Кстати всё что нарисовано снаружи квадратов не учитывается - можно использовать как “комментарии”.
Все записи, которые вертикально располагаются под цветными пикселями сверху, считаются принадлежащими этому столбцу. Эта база организована так, что в “синем” столбце у нас записи домов, а в “красном” столбце - записи людей.


Типы данных
Хранить и возвращать картинки - это, конечно, полезно. Но недостаточно. В базе нам нужно хранить и строки, и числа, и другую информацию, причём не просто в виде картинок, а в “машинно”-читаемом виде. Поборем желание сериализовывать данные в бинарной форме, и подойдём к решению иначе.
Самое простое - это булево значение. Если “пустота” (белый цвет) - это false. Если не пустота - значит true. В редакторе легко инструментом “заливка” переключать с одного на другое значение.
И тут возникает вопрос: как отличить, где мы имеем ввиду картинку, а где - булево значение? Нужна какая-то схема. И в идеале она должна быть тут же, в картинке.
Подумав над разными вариантами, я решил добавлять маленькие значки типов в уголки записей.

Цвет неважен, важно местоположение. Иконочка похожа на букву b - это и будет признак булева значения.

Теперь числа. Числами мы обычно что-то считаем. Если этого “чего-то” не очень много - то проще это что-то и нарисовать в нужном количестве. Например:
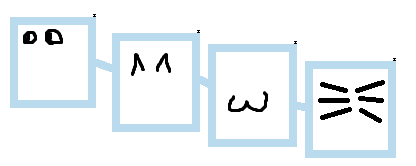
Состав кота: 2 глаза, 2 уха, 1 рот и 6 усов

Алгоритм парсинга простой:
Объявляем счётчик = 0
Ищется не “пустой” пиксель (цвет != белый). Если нашли:
Увеличиваем счётчик на 1
Выполняем “flood fill” в памяти, запоминая все не-пустые пиксели соединённые с этим
Повторяем с шага 2, отбрасывая пиксели, запомненные на шаге 2.2
У котика должно быть имя. Его должно быть можно прочитать и “машине”, и человеку в paint-е - таковы наши условия. Значит, нам нужно использовать текст, который легко парсится. Простой моноширинный шрифт подойдёт как нельзя лучше.

То, что он мелкий, имеет свои плюсы и минусы.
Плюсы:
Легко “писать” карандашом в пейнте, буквы простые
Легко парсить
Минусы:

В базе это выглядит вот так:

Ещё один интересный тип данных - это float. Как представить число с плавающей запятой? Например, от 0 до 1 - проценты, доля чего-то. Правильно, как визуальную долю!

Предположим, что это - уровень сытости котика.
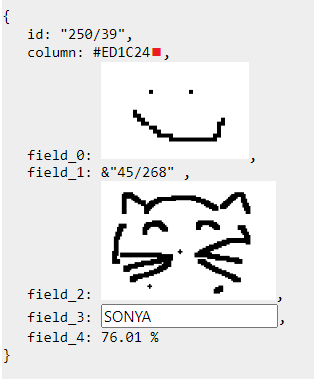
76% - неплохо.

А что, если отмечать не одну долю, а несколько, разными цветами? Этакий говорящий сам за себя pie chart?
Например, мы хотим хранить распорядок дня котика. Каждый цвет кодирует некую деятельность (а легенда сверху помогает не запутаться).
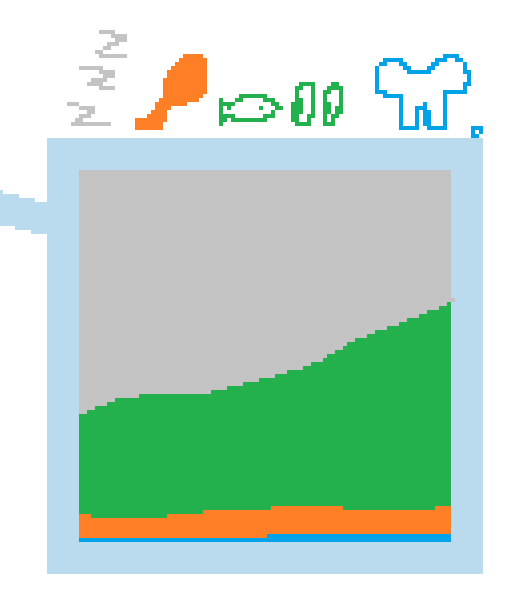
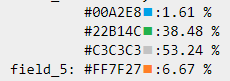
Что ж, наш котик не так уж и много тыгыдыкает, как слон, а смотрит рыбов гораздо чаще, чем ест. В нашей базе уже можно хранить много полезного!
Ссылки
В примерах выше у нас были 2 домика и 3 человека. Хочется расселить человеков по домам, при этом оставив записи домов и людей раздельными, не объединяя их в огромную колбасу.
На помощь приходят ссылки. Выглядят они как пустые записи с типом “ссылка”. И в отличие от других маркеров типов, цвет тут имеет значение.

Ссылки, как мы видим, просто нарисованы от “внешнего ключа” к “первичному” (а точнее - к записи). Алгоритм следования по ссылкам (тот же flood fill, на самом деле) толерантен к небольшим разрывам, поэтому линии можно смело пересекать, если они разных цветов.

Если человек переедет из одного дома в другой, надо будет просто стереть одну линию и нарисовать другую.

Детали реализации
Каких-то алгоритмических откровений тут нет. Как примерно читается “база” я упоминал выше. Сначала, при запуске приложения, происходит чтение “схемы”, т.к. в памяти строится модель - где какие записи, какого типа, как связаны между собой. Чаще всего используется flood fill, который позволяет найти связи между записями.
Сами данные считываются при чтении уже конкретных записей. В теории это позволяет менять данные снаружи не меняя схему и видеть актуальные данные, но пока только в теории.
Для реализации сервера и простенького клиента я взял rust. Тупо потому что давно хотел что-нибудь на нём попробовать сделать. Скорее всего какие-то вещи я сделал неправильно, буду рад услышать продуктивную критику.
Что такое продуктивная критика
Я придерживаюсь убеждения, что фразы вроде “полная хрень”, “тут неправильно всё”, “зачем так делать” и иже с ним не являются критикой. Они являются способом публичного самоутверждения. Критика - это указание на ошибки таким образом, чтобы критикуемый получил достаточно информации о сути проблемы и возможных способах исправления, или хотя бы направление для самостоятельного исследования. Если сообщение не помогает критикуемому стать лучше - это не критика.
С кодом можно ознакомиться тут: https://github.com/AlexeyGrishin/badbee
Серверная часть
Тут я выделил 2 основных части. Библиотека с “ядром” базы, у которой есть апи для чтения/записи. И веб-сервер, который превращает http запросы в запросы к базе и затем превращает ответ в json.
Для веб-сервера взял warp(https://github.com/seanmonstar/warp/). Несмотря на то, что его сильно нахваливают, честно говоря мне не удалось его “грокнуть”. Я послушно копировал примеры, адаптировал их под себя, но как устроена эта система фильтров, к чему именно применится тот или иной фильтр - понять было сложновато. Если брать express.js и его middleware, то там это было как-то проще для понимания. Но то node.js и динамическая типизация, думаю в warp многое наворочено в угоду производительности.
Для работ с базами я попробовал реализовать простую модель акторов. Каждая база (да, сервер может обрабатывать несколько картинок-баз) - это актор, который запускается в отдельном “лёгком потоке” (скорее корутине, или как это называется правильно у tokio). Веб-сервер посылает команды актору базы и ждёт ответа, не мешая запросам к другим базам.
Актор выглядит примерно так:
while let Some(message) = rx.recv().await { if let DBMessage::Shutdown = message { break; } db.handle(message).await } async fn handle(&mut self, message: DBMessage) -> () { match message { DBMessage::Shutdown => {...}, DBMessage::SetModel { model, image } => {...} DBMessage::CloneRecord { x, y, tx } => {...} DBMessage::GetRecords { query, tx } => {...} ... DBMessage::Sync => {...} } }
Вообще сначала я попытался делать “по-старинке”, через mutex-ы. Но бесконечные заворачивания всего подряд в Arc<Mutex<Box<...>>> меня немного утомили. С акторами код стал почище и попонятнее, но возникла проблема, которую я не очень пока понимаю как правильно решать (как неправильно - придумать могу много способов).
Актор в такой схеме получается “однопоточным”. Пока он обрабатывает одну команду (например GetRecords) он не может обрабатывать другие. Если кто-то запросил 10000 записей, а ещё кто-то 1, то этот второй будет ждать пока соберутся 10000 записей для первого. А если понадобится выполнить сохранение изменений на диск или загрузку изменений с диска...
Но, допустим, мы хотим распаралелить только чтение. Самое простое, что приходит в голову - делегируем операцию чтения какому-то “пулу” потоков, каждый из которых может читать из одного и того же участка памяти, где хранятся данные базы... Стоп, но тогда их снова надо в мютексы заворачивать, а как раз хотелось от этого уйти... В общем, интересно как это делают в мире акторов, и не только в rust.

Работать с rust мне скорее понравилось, чем нет. Borrow checker иногда хочет странного, но зато если скомпилировалось и запустилось - то скорее всего работает. Бинарник получился размером в 4 мегабайта, а при запуске с мелкой картинкой занимает 5 мегабайт RAM (5 мегабайт! Не гигабайт!). Я уже отвык от таких чисел в кровавом энтерпрайзе.
Несколько моментов, которые мне особенно запомнились при работе, может быть кому-то из новичков будет интересно.
Обработка ошибок
На начальном этапе разработки я пренебрёг обработкой ошибок. В языках с exception-ами такой подход прокатывал - можно было потом try/catch-ей насовать. В расте это уже не прокатывает. Понатыкав везве вызовов unwrap() я потом частенько с болью смотрел на то, как сервер падает (причём совсем) то там то тут из-за каких-то мелких ошибок, выходов за границы и прочих ожидаемых ошибок. А когда я решил исправить ситуацию и заодно возвращать какие-то осмысленные ошибки в своём api, то мне пришлось по всей цепочке вызовов заворачивать все ответы в Result, трансформировать виды ошибок, активно использовать оператор ? и всё прочее. Оно того стоило, на мой взгляд, но в следующий раз я потрачу лишние пару секунд и сразу предусмотрю и Result, и прокидывание ошибок вместо unwrap().
Явные и неявные преобразования
Очень мощным мне показался механизм трейтов From/Into. Как чаще всего выглядит какая-нибудь функция в api в java:
public Something createSomething(String value) { ... }
Возможно, автор библиотеки заморочился и добавил несколько перегрузок функции с другими аргументами, чтобы было удобно пользоваться. А возможно нет. Тогда придётся все свои нестандартные типы данных превращать в строки явно при использовании библиотеки.
В rust же можно записать вот так:
fn create_something<T>(value: T) -> Something where T: Into<String> { ... }
Что означает “можно передать сюда что угодно, что можно конвертировать в String”. И достаточно для вашего типа реализовать trait From - и можно передавать ваши типы в библиотечную функцию. Причём тут <T> - это не типа дженерика в java, а скорее темплейт в C++. То есть для вашего типа создастся своя версия create_something, где будет вызвано преобразование в String (и, скорее всего, как-нибудь хитро заинлайнено и оптимизировано - я бы ожидал).
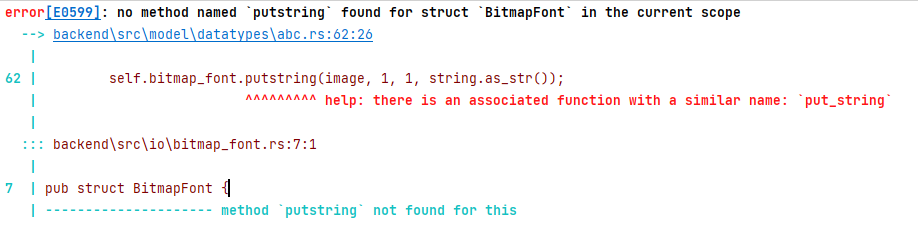
Компилятор
Сообщения об ошибках в rust - это произведение искусства. В кои-то веки компилятор не орёт на тебя как полоумный, а реально пытается помочь и подсказать. Посмотрите, ну разве не прелесть?
Клиентская часть
Т.к. для демонстрации работы api мне нужен был простенький клиент, то я решил и его тоже сделать на rust, благо rust можно превращать в web assembly.
На пробу взял фреймворк sauron (https://github.com/ivanceras/sauron). Как вы можете догадаться, взял чисто из-за названия, потому что иных критериев выбора у меня не было.
Работой с ним я более-менее доволен. Чем-то напомнил мне elm. Ну и react немного тоже. Довольно круто то, что jsx-подобный синтаксис реализован с помощью rust-овских макросов. Причём макросы в rust - это не то же самое, что макросы в C/C++. Там это просто замена строк, здесь же выполняется полноценный синтаксический разбор, компилятор не даст опечататься и предупредит о выстрелах в ногу.
Пример кода:
fn boolean_view(value: serde_json::Value, rec_id: &str, field_idx: usize) -> Node<Msg> { let rec_id = rec_id.to_string(); let value = value.as_bool().unwrap(); node! [ <span> <input type = { "checkbox" } checked = { value } on_checked=move |e| { Msg::PatchRequested { id: rec_id.clone(), fi: field_idx, new_value: json!{ e } } } /> </span> ] }
Что мне не понравилось. Из примеров и документации неясно как выполнять декомпозицию. В примере выше можно видеть, что для рендера мне надо возвращать Node<Msg>, где Node - это собственно элемент virtual dom, а Msg - enum с сообщениями, и вот он уникален для моего приложения. Как выносить отдельные виджеты в библиотеки, как реюзать их, чтобы они отправляли разные сообщения - неясно. Я не говорю, что такой возможности нет вообще, но я не увидел как это сделать.
Так же не все события можно использовать в макросах, что вынуждает переключаться на составление node вручную (например - image onload). Это в целом не так страшно выглядит, но мне не нравится когда в проекте используются разные техники для одного и того же.
Событие on_mount было бы полезным, но оно вызывается до того как созданный dom element вставлен в документ и до того как созданы дочерние элементы. То есть какие-то операции можно проводить только над самим элементом, а связать его с другими элементами в dom - уже не получится.
В общем, как следует помучавшись, я смог таки сделать даже простенькую рисовалку, чтобы иметь возможность менять значения полей типа image.

Ссылка на соответствующий код, если интересно: https://github.com/AlexeyGrishin/badbee/blob/demo/web-client/src/field_view.rs#L53
После компиляции набор ресурсов занимает примерно 400 килобайт.

Не с чем сравнить, чтобы понять, много это или мало для такого приложения. Но как будто многовато, тем более это уже бинарник, а не текстовый листинг. Возможно, выбранный фреймворк слишком прожорливый.
Большой файл с данными
Выше я писал, что при запуске с небольшой картинкой приложение занимает в памяти 5 мегабайт. Хорошо, а что если картинка - большая?
Для проверки я сделал картинку 10000х40000 пикселей, 32 цвета, PNG. Занимает она на диске 287 мегабайт, и внутри содержится более 9000 записей (в каждой записи - 8 полей).
Добавлять её в статью или на github я, конечно, не буду.

Запускаю сервер с одной только этой картинкой в докере (называется она husky_bigger.png)
docker run -d --rm --name badbee -e DB_FILE=husky_bigger.png -p 3030:3030 -v "$pwd/db:/usr/badbee/db" badbee
Через некоторое время открываю клиент:
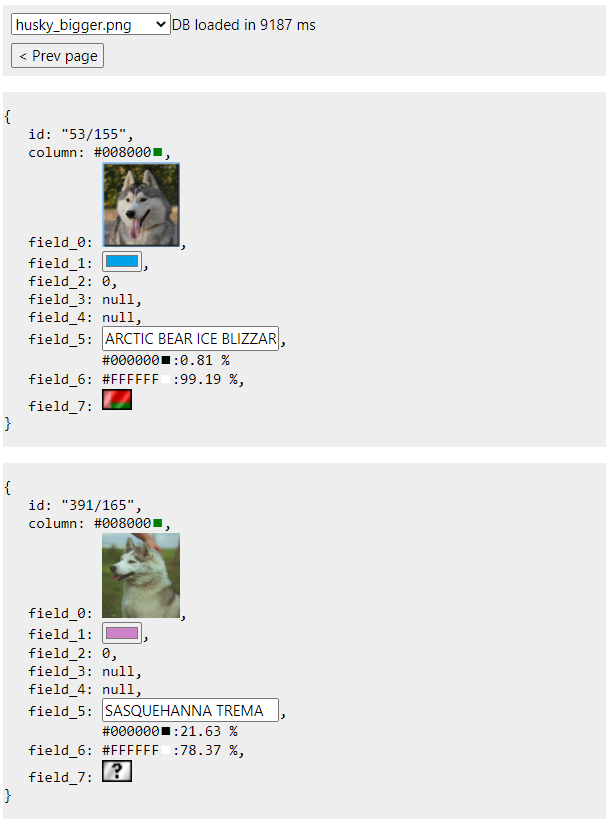
Нормально, загрузилось. 10 секунд потребовалось чтобы распарсить модель.
А что по памяти?

Уже не так круто. Но ничего особо неожиданного в этом нет. PNG - сжатый формат. Чтобы работать с отдельными точками, надо сначала распаковать всё в более плоскую модель. 10000 пикселей на 40000 пикселей на 4 байта на пиксель - получаем те самые 1.5 гигабайта.
Выглядит уже не так масштабируемо, как хотелось бы. А что если файл будет в 10 раз больше? Плюс понятно, что нам не нужно постоянно держать всё в памяти. В разное время будут требоваться разные записи, и хорошо было бы держать в памяти только какие-то кусочки, а остальное пусть подргужается с диска, когда нужно.
Но тут нас ждёт проблема. PNG использует сжатие Deflate - по сути тот же zip. И (поправьте меня, если я ошибаюсь) нет способа в общем виде достать что-то из середины zip архива не распаковав то что было в начале. Мы не можем из png на диске выбрать часть картинки из середины.
И тогда на помощь приходит...
BMP!
Этот формат хранит изображение без сжатия, а данные отдельных пикселей располагаются предсказуемым образом и построчно (правда почему-то снизу вверх, т.е. в начале файла идёт последняя строка пикселей, потом предпоследняя, и в конце - первая).

Это означает, что можно разрезать изображение на горизонтальные полоски, и подгружать в памяти их с диска по мере надобности (и выгружать тоже).
Если для работы с png я использовал библиотеку rust image (https://github.com/image-rs/image), то для работы с bmp навелосипедил своего кода (https://github.com/AlexeyGrishin/badbee/blob/demo/backend/src/io/bmp_on_disk.rs)
Для начала просто превратим наш png в bmp и посмотрим что изменится.
Во-первых изменился размер файла. Он стал 1.2Гб. Почему не 1.5? Потому что в bmp нет альфа-канала, и на каждый пиксель приходится максимум 24 бита (3 байта), а не 32.
Теперь запустим приложение с этим файлом.
docker run -d --rm --name badbee -e DB_FILE=husky_bigger.bmp -e BMP_KEEP_IN_MEM_INV=1 -p 3030:3030 -v "$pwd/db:/usr/badbee/db" badbee
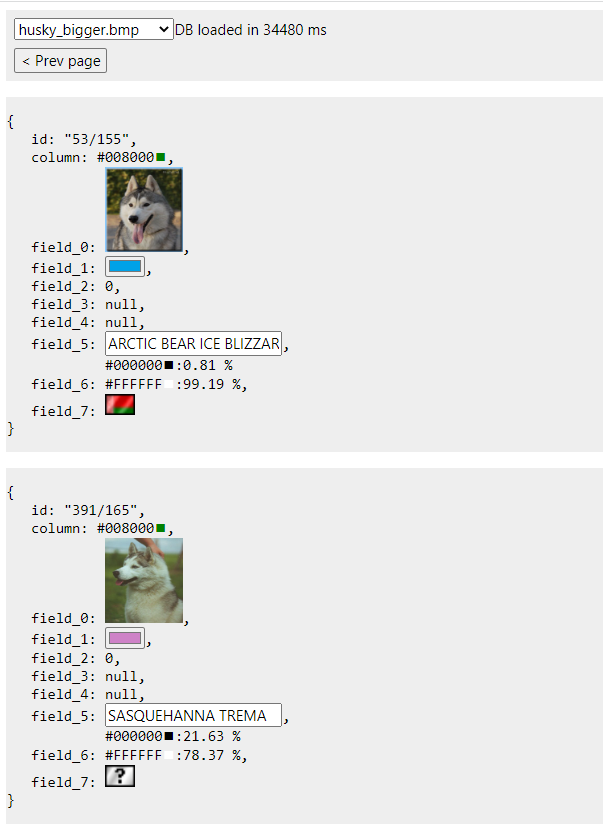
Всё то же самое, но грузилось подольше. Возможно потому, что файл грузится не сразу целиком, а полосками по 1024 пикселя. Возможно потому, что я выдал не настолько быстрый код, как авторы библиотеки image.
Что по расходу памяти?

Ожидаемо.
Теперь перезапустим, изменив параметр BMP_KEEP_IN_MEM_INV. Его смысл - указать приложению, что в памяти надо держать не более 1/BMP_KEEP_IN_MEM_INV от объёма файла. Предыдущий раз мы запускали со значением 1, теперь возьмём значение 6
docker run -d --rm --name badbee -e DB_FILE=husky_bigger.bmp -e BMP_KEEP_IN_MEM_INV=6 -p 3030:3030 -v "$pwd/db:/usr/badbee/db" badbee
Загрузка прошла примерно за то же время:

А памяти стало занимать меньше:
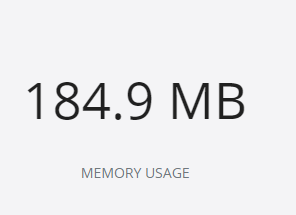
Если листать в клиенте туда сюда, то в логах контейнера можно увидеть, как он выгружает/загружает кусочки изображения.

Заключение
Тут я даже не знаю что писать. Замеры перформанса? Планы на развитие? Сферы применения? Мы точно говорим о базе данных, хранимых в png?
Впрочем, формат можно использовать для хранения конфигов. В геймдизайне, например. Зачем тюнить параметры юнитов в скучном json, когда можно делать это прямо в текстурах в фотошопе?
А вот как может выглядеть docker-compose.png

Это и конфиг, и схема в одном флаконе. Можно сфотографировать на телефон и дома поднять сервер по фотографии.

Ещё одно возможное применение - это обучение основам БД. Всё-таки при работе с базами данных приходится изучать и принципы, и инструменты. А тут можно наглядно показывать принципы в любом графическом редакторе, объяснять понятия записей, схемы данных, ключей и связей.
На этом всё. Не забывайте делать бэкапы. И скриншоты тоже. На всякий случай.
