Продолжение. К предыдущим постам и карте цикла.
Все помнят Гагарина с его незабвенным: «Поехали!». Волнующий и ответственный момент. Ключ на старт, нажатие кнопки и понеслась! Работают скрипты, ползунки продвигаются одновременно на всех терминалах, таймер обратного отсчёта почти кричит, что скоро заветный финиш. А потом всё замирает и приятный зелёные свет заливает центр управления. Менеджеры обнимаются с программистами, тестировщики поливают всех шампанским, а вы, откинувшись на спинку кресла, закуриваете и смотрите за горизонт, где сейчас ваш новый продукт улучшает жизнь клиента и пользователей. Вселенная спасена.

В топку слюнявые фантазии и сладкие презентации про CI-CD-CD. В суровом и тёмном мире энтерпрайза система раскатывает вас. И происходит это медленно, нудно, под треск дедлайнов и шёпот адвокатов. Связанный по рукам и ногам корпоративной политикой и трендами политкорректности, ваш босс смотрит на тающий бюджет и пытается перегрызть вам вены мягкими беззубыми челюстями. Он бы с радостью познакомил вашу голову со своей коллекцией пресс-папье, но вы его честно предупреждали, что развёртка займёт год и ад из десятка версий в пилоте – это только начало. Вам, конечно, не терпится возразить, что так не должно быть и я сгущаю краски. Но раз уж у нас roll out, то давайте прокатимся!
Первое, что отличает информационные/автоматизационные системы крупных предприятий и организаций – железо. В большинстве случаев у вас идёт хотя бы частичная смена периферийных устройств. Компании и проекты у нас долгоиграющие. С прошлой версии, чего бы там до этого не стояло, многое устарело не только физически, но и морально. Принтеры на COM или LTP мне ещё встречались пару лет назад. Было смешно наблюдать, как молодёжь пытается настроить USB адаптер, чтоб провести симуляцию и не могут понять, что за 9600 бод от них требует это синее окошко. По мимо смены устройств, нужно еще и подключить своё новое добро к их старому ведру. Вот ваш проект был новый терминал для самообслуживания в почтовом отделении. Требования безопасности не дадут вам просто подключиться к внутренней сети и уж тем более залезть в неё извне через богомерзкий интернет. Скорее всего нужно будет кинуть кабель. Значит необходимо физически доставить новый терминал и физически его подключить. А как я уже не раз говорил – большой шанс, что первый шаг будет делать одна компания, а второй другая. То есть, чтоб установить вашу систему нужно:
чтобы вендор А (обычно производитель) доставил оборудование,
вендор Б (обслуживание) подключил,
заказчик или вендор В (внутренний IT департамент) дал доступ и отконфигурировал инфраструктуру.
И вот теперь вы можете удалённо подключиться и установить свой продукт. Иногда можно сделать предустановку софта договорившись с производителем/поставщиком. Но это не сильно сокращает время. Так как процесс всё равно требует выезда техника. А они ещё не умеют телепортироваться по скрипту в вашем пайплайне.
А было б круто, если бы телепорт работал. Ведь тех самых почтовых отделений много. Тысячи. И, как назло, в разных местах. И вот прям чтоб совсем выбесить – далеко друг от друга. Как будто специально! Жаль, что нельзя собрать все почтовые отделения на одном складе, наладить и развести по городам и сёлам. Хотя, вроде я читал тут, что так уже делают магазины самообслуживания – сразу цельными и в транспортном контейнере. Так что скорость первоначальной развёртки всегда упирается рогами в количество игроков, а копытами в географию. Это только при комунизьмах можно взять пол страны и «распределить» или «направить» на нужды. Компаний с армией работников и чёткой логистикой не много. Так вот и получается 20-50 отделений в неделю.
С нашей же слоновой башни такая скорость - очень даже ничего. Ведь в отличии от ограниченных пилотных запусков, тут начинается настоящий скейлинг. Взрывной и неконтролируемый, как бэклог новой версии продукта. На самом деле нет. Отличие разработки для предприятий в том, что всё завязано на железо и определенный штат работников. Даже если у вас не производственный цех со станками, а продуктовый магазин – пользователи вашей системы — это работники компании, которые работают со специализированными периферийными устройствами. Кассовым аппаратом с фискальным лотком, сканером инвентаря с принтером или контролером бензонасосов. Это только первого января можно утром выйти в знакомый ларёк, а там их окажется сразу три. Но они явно пытаются слиться снова в один, а посему их число постоянно меняется. В другие дни ни количество точек/филиалов/цехов, ни количество подключенных устройств не изменяется быстро и много без форс мажора. Сколько бы клиентов не стояло в очереди, их всё равно будет обслуживать единственный пользователь единственного терминала.
У энтерпрайз архитектуры, зачастую, основное требование – бесперебойность работы. Непрерывность бизнеса. Соответственно ваши лучшие друзья: сегрегация и федерация. Separa et impera. Система должна создавать впечатление глобальности (единой системы), при этом внутри это набор независимых систем интегрированный какой-нибудь шиной. Та самая омниканальность из предпродажных презентаций. Как бы менеджерам ни хотелось сократить количество систем в разработке и обслуживании – не стоит сливать всё в одну кучу, даже если это сделать легко и интуитивно правильно. Интуиция начальства - вообще плохой помощник. Если у вас есть супермаркет, то многие будут ратовать за то, что одна система и база данных будут управлять и складом, и заказами, и продажами на кассе, и продажами через сайт и аппликацию. Это понятно, что один бэк (обычно никому в голову не придёт сделать один фронт для разных задач), кажется, означает намного меньше расходов на разработку и поддержку. Чтоб избавить власть-имущих от мук выбора, вы начинаете капать на мозг тяжелыми и горячими доводами. Количество банковских терминалов известно и почти статично, а количество пользователей мобильного приложения нет. При этом критичность отказа одного терминала в банке намного выше проблемы одного клиента с мобилы. Значит проектирование инфраструктуры будет иметь разные фокусы. В одном варианте у нас нет динамического масштабирования, но необходима отказоустоичивость через избыточность оборудования, а во втором мы хотим платить за вычислительные мощности по мере необходимости и не зарываться в согласованность данных. Ну и, конечно, с точки зрения безопасности, мы хотим разделить внутреннюю сеть и интернет. И вообще, скомпрометированный банкомат – удар по бренду и будет иметь финансовые последствия. Так что никак нельзя «всё в одну кучу». На начальных этапах проектирования с этим обычно спорить не будут. Деньги ещё виртуальные. А вот когда у вас напряг на пилотных версиях и срывы сроков, то отдел разработки волевым решением какого-нибудь мелкого менеджера возьмёт и захимерит обращение напрямую в БД одного сервиса из другого. Ну, потому что гейт/шина/меш/брокер ещё не готова или какой-то сценарий с дэдлоками требует ещё пару недель на доработку, а сдавать вчера. Обоснование для «быстрого» решения всегда найдут и вас в известность не поставят. Потому, что если вы уж дочитали до этой точки, то точно будете против плохой тактики в стратегических решениях. А раз вы против, то значит: «Вы токсичный и общаться с вами не приятно!».
Отступление в тему:
Иногда подход «всё в одну кучу» имеет логичное обоснование. Особенность географически распределенного бизнеса (например сеть кафе) в том, что в каждой точке есть определенный набор устройств. Чем более развита страна, в которой процветает наша гипотетическая сеть кафе, тем больше шанса нарваться на старое железо. Страны, которые вошли в цифровую эру раньше, закупили и установили всё оборудование десяток лет назад. И наоборот, страны, где большинство процессов были устаревшими и не автоматизированы, навёрстывают подстегивая прогресс деньгами. Так что найти в западной Европе кассовые аппараты на базе Pentium/Celeron4 с парой гигов RAM и принтером COM порте так же легко, как в бывшем союзе узнать, что всё на i5 в 64 бита и стабильной беспроводной связи с периферийными устройствами. Так вот слабое железо не даст развернуться «хорошей» архитектуре. Хорошей в кавычках, потому что если архитектура идёт в разрез с требованиями и реальностью, то она идёт лесом. В кафе есть обычно 2 слабых компа для кассы, 1 такой же хилый для кухни. Там, где есть хорошая WAN сеть – этого хватает. Облачко возьмёт расчёт на себя, оставив в кафе только презентацию и периферию. А вот там, где соединение не надёжно и возможны длительные оффлайны, клиент вряд ли согласиться с концепцией «нет сети – нет продаж». Покупатель пришёл, товар есть, команда на месте. Клиенту нужно делать деньги, а не архитектуру. Так что будьте добры обеспечить работоспособность локально. В варианте, когда ресурсы ограничены и нельзя рассчитывать на удалённые машины, то цельные клиент-сервер решения с хорошим разделением кода внутри – наш вариант. А вот микро-чего-нибудь – совсем нет. Хорошо, что мы продумали и учли всё это заранее.

То, что делает именно этот этап критичным – это ознаменование конца разработки. Цена, о которой ваша компания договорилась с заказчиком, обычно, покрывает бюджет лишь частично. Настоящий Эль Дорадо – это постоянные платежи за обслуживание. Так что для вашей компании необходимо перейти в BAU и желательно сразу из POC. Клиент же, напротив, понимает, что чем дольше он работает с вашей системой в режиме RO(rollout), тем меньше расходов. Разработка то уже оплачена, а вот обслуживание встанет еще одной статьей расходов на долгие годы. Так что без политики тут не обойдётся. Тем более, что сам процесс обогащения функционала и бэклога не прекращается при начале периода установки и миграции. В ваш роллаут будут подмешивать пилотки новых требований клиента. Ведь он уже начал работать с продуктом, а значит появились не только достоверные отзывы, но и хотелки. Да, CR, оплачивается отдельно и как бы является следующим шагом. Но предыдущий то, еще не окончен. А когда обе ноги в воздухе, то в любом случае придётся падать. Гравитация, как известно, к кардиологу не ходит. Конечно, все надеются, что приземлитесь на ноги и где-нибудь дальше от точки старта. Но, если вас зовут не Надежда, то я бы не обольщался позитивным исходом от параллельный бэклогов и новых прототипов в проде. Всё это сильно осложняет эволюцию инфраструктуры и добавляет костылей. Все мы это уже проходили. Задача архитектора узнавать грабли по виду, а не по воздействию.

И так, вы уже наверно, догадались, что у вас будет много бранчей. Так как график количества версий, которые всё еще не установили на весь парк машин, со временем начинает напоминать e^x.
Что с этого, нам, архитекторАм? Слои и модули должны быть хорошо разделены и легко дополнять или сменять друг друга. Еще один уровень абстракции. Пытались ввести его после окончания разработки? Мои истории не всегда дадут вам рецепт. Я подкидываю то, к чему готовиться. Как решить – сильно зависит от вашего проекта. В истории с разными типами банковских отделений сильно помог принцип матрёшки:
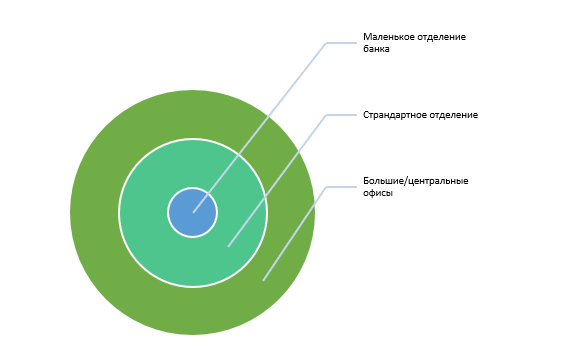
Проект с функционалом обычного отделения включал в себя проект маленького офиса. Всем известный паттерн компоновки на масштабе продукта. API стоится по паттерну команд, но при внешнем разделении, внутри оффлайновой части, зачастую, много нерушимых связей. Так что просто собрать из набора команд другой тип сервера не получается. В любом случае на начальных этапах начальство вряд ли сможет оценить лишние затраты на разработку и частичное излишества. Допустим модель данных маленького проекта может включать поля из самого большо, даже если они и не используются. Добавить новые модели легче, чем изменять существующие. Вот тут и возникнут внутренние конфликты. Продуктовая часть для всех трёх типов идет независимо и не всегда при разработке нижнего уровня можно узнать, что понадобиться верхнему. А значит в нижний будут вносить изменения ретроактивно, добавляя лишние циклы тестирования и рефакторинга. Зато при безболезненной компоновке легко наладить CI-CD пайплайн, в котором единый репозиторий выдает три артефакта. В проде у вас много версий, а в коде лишь треть из них.
Пример из жизни:
Да, в заказах от энтерпрайза много оффлайна, но чтоб вы не думали, что с облаками проще… Одна западноевропейская компания решила дать SaaS аналитику своим партнерам и дилерам. Архитектура простая, так как клиент очень хотел в классику: шина с их проприетарными кусками олдскульной аналитики и с десяток микросервисов. Исторически сложилось, что у богатых европейских стран много влияния в Африке. А отношения с дилерами регулирует контракт и местное законодательство. Так как речь шла о расчёте рисков исходя из медицинских и экономических данных клиента, то строгость отношения к этим параметрам в Европе зашкаливала. Напрашивалось простое решение – дать в развивающимся странам тот же уровень защиты и функциональности. Но вот в этих странах совсем не хотели лишних дисклеймеров и ограничений по использованию личных данных клиента. У местных дилеров другая бизнес-модель. Получалось что нужно иметь два разных облачных решения, так как сервис контракты и оркестрация были разные. Из одного продукта пришлось делать 3.5 системы: общая часть (80% всей системы), для Европы, для Африки и анонимайзер данных, для синхронизации между геолокациями. Приходится так же матрёшкаться и делать 2 системы в 2-х разных облаках. Ведь тут еще сюрприз – не каждое облако имеет аккредитацию нужного уровня кошерности в отдельно взятой стране.
Море версии не только результат новых требований или реализации следующей фазы разработки (ведь большой продукт всегда дробят), но и объективно необъективного поведения высших приматов. Много версий, много мерджей, много конфликтов, много костылей и заглушек. Следовательно, и много багов. Обычно мелких (если у вас хорошо поставлена автоматизация). Каждый большой патч (а это еще одна версия в роллаут) будет закрывать десяток серьёзных ошибок и открывать столько же мелких. Это будет напрягать клиента. Ко всему этому добавятся конфликты, связанные с переобучением, новыми рельсами и желанием оставаться в лыжах вне зависимости от сезона и места. Человек работал себе десяток лет, починял примус, а теперь вы забрали примус и требуете нажимать кнопки на фонарике! Чем больше опыта у работников на старой системе, тем больше просядет их производительность в первое время. Там они знали и умели всё. А тут другое и по-другому. И теперь в книге жалоб и предложений будут длинные и сочные предложения о вас и вашей системе, с упоминанием мест, которые вы обязательно должны посетить. Второй и менее очевидный повод для жалоб – потеря контроля (необходимость следовать процедурам и их прозрачность). Современные системы пытаются подмять под себя все процессы и сделать и открытыми для менеджмента. Встроенные аудит-функции, статистики, прогнозы и всё такое вкупе с повышенной безопасностью. Теперь ни отлучиться с рабочего места без записи в логе, ни списать мелочь со счёта, ни подправить документы задним числом. Всё цифровое, подписанное и улетает сразу в главный офис.
Много шума из ничего способствую стрессу и тревоги у вашего клиента. Чем больше будет расти в нём чувство тревоги, что после очередной версии обнаружится что то серьёзное, а не очередная мелочь, которую можно легко обойти, тем дольше жирнее будет локальный поц и дольше времени на обкат. И очень быстро возникают остановки по требованию (фризы). У вас сеть магазинов и скоро чёрная пятница? Стоп машина! Где-нибудь в октябре. Чтоб точно отловить и уничтожить всё, что может помешать мега-распродаже в конце ноября. Или откатиться назад к стабильной версии. Ну а там еще и рождественские праздники. Так что давайте продолжим в первых числах января… И тут вы вспоминаете, что в первых числах января доступность и работоспособность вашей команды резко падает. И теперь уже вы объявляете свой фризтайм. Будьте готовы к тому, что треть года роллаут будет стоять на месте.
Так что поездка будет длинной. Клиент всегда норовит держать ваш руль одной рукой, а уж педаль тормоза у него всегда под полным контролем. Как же доехать до конца роллаута быстрее? Сломать спидометр! Если показатели скорости не высокие, то и тормоз жать не нужно, правда? Так что в каждый патч и релиз тихо вкладываются изменения инфраструктуры, для предотвращения больших расхождений между версиями. Ну вот в той же матрёшке, нашли баг в самой большой, а функционал частично идёт из самой маленькой. В маленькой же проблемы нет, поэтому клиент не будет вкладывать ресурсы в раскат и этой версии в проде. Так что либо у вас возникают 2 разных бранча маленькой версии, либо вы вкладываете изменение в следующий релиз мини отделений без уведомления клиента. А иногда и ваших менеджеров (если изменяемая область будет и так покрыта тестирование ради какого-то другого фикса). Менеджеры как-то не любят изменения. Бизнес строится на минимизации рисков. Любое изменение – риск. Поэтому 2 версии для менеджера нижнего и среднего звена – лучшее решение. Деньги не им считать, а если работы больше и им увеличат команду, то они только выиграют.
Надеюсь, мне удалось убедить вас в том, что развёртка системы может занять много времени. Очень много. Я помню проект, где с пилотки до перевода в штатный режим прошло 3 года. А всего то 4 вида типовых наборов в 1500 локаций. И раз процесс долгоиграющий, то возникают вещи, которые, почему то, остаются недоделанными и неожиданными. Допустим закрытие офисов/точек работы или слияния/поглощения компаний. Ну и конечно, смена стандартов, регуляций и оборудования.
Наверное, опыт и реализм – то, отличает архитектора от остальной команды. Ну и ещё ум и сообразительность. Правда если они действительно есть, то самое время подыскать другой проект и/или компанию. Всё самое сложное и интересное уже произошло и дальше из вашей уже не такой стройной, но устойчивой и понятной архитектуры будут несколько лет делать костыльно-каловую конструкцию. Освободите место тем, кто ещё слаб знаниями, но горяч душой. Следующий этап – кузнеца кадров.

