Приветствую, хабравчане! Сегодня речь пойдёт об одном, на мой взгляд, интересном варианте алгоритма для самообучающейся системы. Идея подобной статьи зрела давно, однако руки всё не доходили.
Рассматриваемую ниже модель можно спокойно отнести к областям эволюционного моделирования и роевого интеллекта, однако с заделом на дальнейшую интеграцию с существующими наработками в области нейросетей. Но, обо всём по порядку.
Мотивация
Началось всё с идеи, что восприятие мира нашим мозгом - образное. Каждому объекту реального мира, каждому явлению, с которым человек и его нервная система взаимодействуют, сознание ставит в соответствие некоторый ментальный образ, образ объекта из реального мира. Этот образ может быть как зрительным, так и звуковым или тактильным. Стоит полагать, что в образе и в переходе к нему и содержится смысловая часть нашего восприятия.

Взаимосвязи между объектами в реальном мире аналогичным образом переходят во взаимосвязи между образами этих объектов в голове. Но это уже тема для отдельной статьи.
С образами дерева, мяча, листа бумаги, кошки всё понятно. Но как быть с образами физических величин, спектр значений которых непрерывен? Суть проблемы поясню на примере. Допустим, человеку (будем звать его Василий) дают послушать звук частотой 500 Гц. Во время прослушивания в голове Василия появляется образ этого самого звука. Затем, Василию дают послушать другой звук, уже с частотой 600 Гц. И снова это приводит к появлению нового звуковой образа в голове нашего испытуемого. Теперь он способен отличать эти два звука между собой.
Но эксперимент продолжается. Василию дают слушать всё новые и новые звуки в промежутке от 500 до 600 Герц: 537, 571, 522.93, 586.128, 593.49245, ... Каждый новый звук, который запомнит испытуемый, будет порождать новый образ в голове последнего. До каких пор это будет продолжаться? Как утверждает математика – до бесконечности. Ведь между любыми двумя вещественными числами найдётся как минимум ещё одно вещественное число.
Выходит, если Василий запоминает, всё подряд, всё, с чем взаимодействует, то его память банально переполнится бесконечным числом образов объектов из окружающего мира. Значит, восприятие работает несколько иначе (да, да, для кого-то это было очевидно), преобразуя непрерывную реальность в конечный набор дискретных образов.
Это в свою очередь порождает ряд вопросов:
Не ясен механизм выбора, что запомнить, а что нет.
Какова предельная точность распознания объектов? Именно мозгом, не органами чувств.
Можно заметить, что человек хорошо запоминает только ту информацию с которой он постоянно имеет дело. Другими словами, повторение способствует лучшему запоминанию. Как реализовать и это в рамках теории образов?
Странная жизнь клеток
Прежде чем, перейти к ответам на поставленные вопросы, переместимся в воображаемый мир, где клетки живут ровно по тем правилам, которые мы придумаем.
Для начала определимся с пространством, в котором живут клетки. В игре "Жизнь", например, это дискретное пространство, состоящее из квадратных клеток. Мы же предоставим клеткам все радости жизни в непрерывном метрическом пространстве произвольной размерности.

Также разберёмся со способом питания клеток. В пространстве постоянно в разных местах появляются питательные точки, потребляя которые клетка увеличивает свою массу. Можно придумать множество всяких вариантов принципа, определяющего, какая клетка сможет подкрепиться питательной точкой и сможет ли. Остановимся на довольно странном для обычных клеток механизме, когда питание получает ближайшая к источнику клетка. Почему странном? Потому что, даже если ближайшая к питательной точке клетка находится на расстоянии в сотни километров, она всё равное его моментально получит.
Таким образом, клетки разбивают всё пространство на семейство областей с общими границами. Каждая такая область представляет собой множество точек, к которым одна из клеток будет ближайшей.
Деление. Здесь всё достаточно просто: клетка делится, если её масса становится критического значения M. Вопрос лишь в том, где будет располагаться дочерняя клетка. Самый простой вариант – где-то в случайном месте, неподалёку от родительской. Однако прибавим клеткам мобильности: пусть дочерняя клетка располагается на месте текущей питательной точки, которая и привела к делению материнской клетки.

Что на счёт старения? Все клетки вне зависимости от положения и питания постоянно теряют небольшую долю своей массы. Это значение подобрано так, чтобы размер колонии оставался стабильным и число клеток было не сильно больше или меньше некоторого фиксированного числа (N). Как только масса клетки становится отрицательной, клетка удаляется с поля со статусом «мёртвая».
Все наши правила можно записать в виде следующих формул:



где ? – функция Хевисайда, ?(x,y) – расстояние между точками x и y, μ – величина порции питания клетки, M - масса, достаточная для репродукции (репродуктивная масса), n - число клеток в колониии, N - ограничение сверху на численность колонии.
Вот как всё это выглядит в движении:

Анализ поведения колонии в целом
Что в итоге мы имеем? Колония клеток растёт и развивается таким образом, что клетки выживают только в тех зонах, где питания достаточно для поддержания их жизнедеятельности. Действительно, если новая клетка «случайным» образом образовалась в месте, где питательные точки появляются редко, то, очевидно, в среднем она будет терять массу быстрее, чем набирать. Ведь все питательные точки будут с большей вероятностью оказываться рядом с другими клетками и подпитывать их.
Как ни удивительно, масса между клетками в колонии распределена квазилинейно (коэффициент наклона графика ⍺ ≈ M/N). То есть на каждый интервал значений массы приходится одно и то же число клеток:



При этом, как и ожидалось, число клеток в колонии сначала растёт, а затем флуктуирует возле фиксированного значения N:

Данные, как элементы метрического пространства
Допустим, в нашем распоряжении имеется произвольный датасет в виде пар входных и выходных данных. Это может быть некоторая математическая функция f(x), словарь с одного языка на другой, набор картинок с пометками, кто на них изображен.
Так или иначе, элементы входных данных образуют пространство, на котором можно ввести метрику – функцию расстояния между объектами.
// (код на Rust) trait Distance { fn distance(&self, other: &Self) -> f64; }
Если тип данных является числом, то расстояние легко найти как модуль разности

если вектором чисел, то

Ну, а если входные данные – это картинка, то можно использовать попиксельное сравнение. В случае чёрно-белой картинки, формулу можно записать так:

Для слов можно использовать как «посимвольную», так и тривиальную метрику. Но, строго говоря, лучше использовать именно тривиальную метрику (что и реализовано в коде ниже):

Это оправдано тем, что по смыслу, слова «вода» и «мода» отличаются не меньше, чем «вода» и «водой». Тривиальная метрика и в том и в другом случае даст расстояние ρ=1, в то время как, согласно посимвольной метрике, слова «вода» и «мода» отличаются меньше (ρ=1), чем «вода» и «водой» (ρ=2), хотя последняя пара слов представляет собой одно и тоже слово, просто в разных падежах.
// для чисел impl Distance for f64 { fn distance(&self, other: &Self) -> f64 { return (self - other).abs(); } } // для векторов и массивов impl Distance for Vec<f64> { fn distance(&self, other: &Self) -> f64 { let mut s = 0.0; let n = self.len(); for i in 0..n { let x = self[i] - other[i]; s += x*x; } s.sqrt() } } struct BWImage { matrix : Vec<Vec<u8>>, } // для чёрно-белых картинок impl Distance for BWImage { fn distance(&self, other: &Self) -> f64 { let mut s = 0.0; let n = self.len(); let m = self[0].len(); for i in 0..n { for j in 0..m { let x = self.matrix[i][j] - other.matrix[i][j]; s += x*x; } } s.sqrt() } } // for strings impl Distance for String { fn distance(&self, other: &Self) -> f64 { return (self == other) as i32 as f64; } }
Клетки в поисках паттернов
Попробуем применить описанную выше клеточную модель к анализу данных. Как это сделать? Как уже говорилось, датасет есть набор пар входных данных и выходных. То есть преобразование из одного пространства (метрического) в другое. Клетки в рамках нашей модели тоже «живут» в метрическом пространстве. Следовательно, каждый элемент входных данных можно использовать как питающую клетки точку.
Выходные же данные можно рассматривать как метки на клетках. Метку i-й клетки обозначим  .Таким образом каждая клетка в колонии становится своего рода связующим звеном между соответствующим входом и выходом. При этом метки от питательных точек передаются дочерним клеткам во время деления.
.Таким образом каждая клетка в колонии становится своего рода связующим звеном между соответствующим входом и выходом. При этом метки от питательных точек передаются дочерним клеткам во время деления.

Обратимся к примеру. Имеется автомобиль, управлять которым мы хотим научить клеточную колонию. Для этого автомобиль (под управлением водителя) должен несколько раз проехать по нужному маршруту, собирая данные. Получится некоторое семейство траекторий. На «вход» модели будем подавать координаты автомобиля (получаем с помощью GPS), а на «выход» - необходимое действие: ехать прямо/повернуть направо/повернуть налево.
; тёмно-зелёный цвет – клетки обучившейся колонии (реализуют осреднённую траекторию); оранжевый цвет – метки на клетках (действия по управлению автомобилем из датасета)")
При приближении автомобиля первому повороту, соответствующая его расположению питательная точка окажется в зоне клетки с меткой «повернуть направо». Система «распознает» ситуацию на дороге, как требующую поворота вправо и повернёт. Затем, посылаемый GPS сигнал будет порождать питательные точки снова в окрестности клеток с меткой «ехать прямо», вплоть до следующего поворота.
); зелёные точки - клетки колонии во время обучения")
Рассмотрим ещё один пример. Задача состоит в дискретной имитации непрерывной математической функции  – колебания маятника с частотой 1 рад/с и амплитудой 4. В качестве «входа» – время t за вычетом целого числа периодов. В качестве «выхода» – координата маятника x(t). На гифке видно, как происходит добавление и удаление новых клеток колонии. Ниже представлен график результатов.
– колебания маятника с частотой 1 рад/с и амплитудой 4. В качестве «входа» – время t за вычетом целого числа периодов. В качестве «выхода» – координата маятника x(t). На гифке видно, как происходит добавление и удаление новых клеток колонии. Ниже представлен график результатов.
Оранжевая кривая – график зависимости положения самого маятника от времени. При имитации поведения маятника, сначала время t локализуется на интервале  (вычитаем число целых периодов). Затем для каждого значения ? (питательной точки) определяется ближайшая к нему клетка под номером k и её метка
(вычитаем число целых периодов). Затем для каждого значения ? (питательной точки) определяется ближайшая к нему клетка под номером k и её метка  . Синий график есть зависимость значения метки, получаемой таким образом для каждого значения t. Формулой это можно записать так:
. Синий график есть зависимость значения метки, получаемой таким образом для каждого значения t. Формулой это можно записать так:

В данном случае имитация (аппроксимация) функции происходила 15ю клетками, 15ю зонами.

А вот какой почти гладкий результат даёт колония в 100 клеток (что логично, разбиение периода на большее число отрезков).

Связь с ментальными образами
Применим нашу модель к анализу и классификации картинок. Для простоты в качестве датасета используем примитивные чёрно-белые картинки, с двумя значениями яркости (0 и 255). Размер 17x46. Картинки получаются путём наложения шума на две исходные картинки кошки и собаки.



Окей, модель отлично справляется с поставленной задачей (хоть и довольно простой). Но что представляют собой координаты клеток колонии после обучения? Если подумать, то все клетки расположены на месте каких-то питательных точек, то есть соответствуют некоторым конкретным картинкам из датасета. Эти картинки, в силу свойств алгоритма, представляют нечто среднее для своей группы (картинок, помеченных одной и той же меткой).
Если выражаться более точно, клетки колонии стремятся занять положение питательных точек, которые ближе всего к геометрическому центру каждой отдельной группы точек (кластера картинок), определяемого по формуле:

Таким образом, каждая клетка в ходе обучения пытается стать представителем группы питательных точек, представителем кластера данных. Такой представитель содержит в себе наиболее общие черты всех элементов кластера, выступает в роли эталона, сравнение с которым позволяет классифицировать объекты, определять принадлежность объекта к тому или иному кластеру данных.
В тоже время, это уже вопрос не просто классификации. Это вопрос восприятия. Обученная модель, если мы «покажем» ей картинку, прежде чем ответить, что изображено на последней, сначала перейдёт к картинке, соответствующей ближайшей по метрике клетке. Это то, как модель «видит» то, что мы ей подаём на вход, как воспринимает информацию.
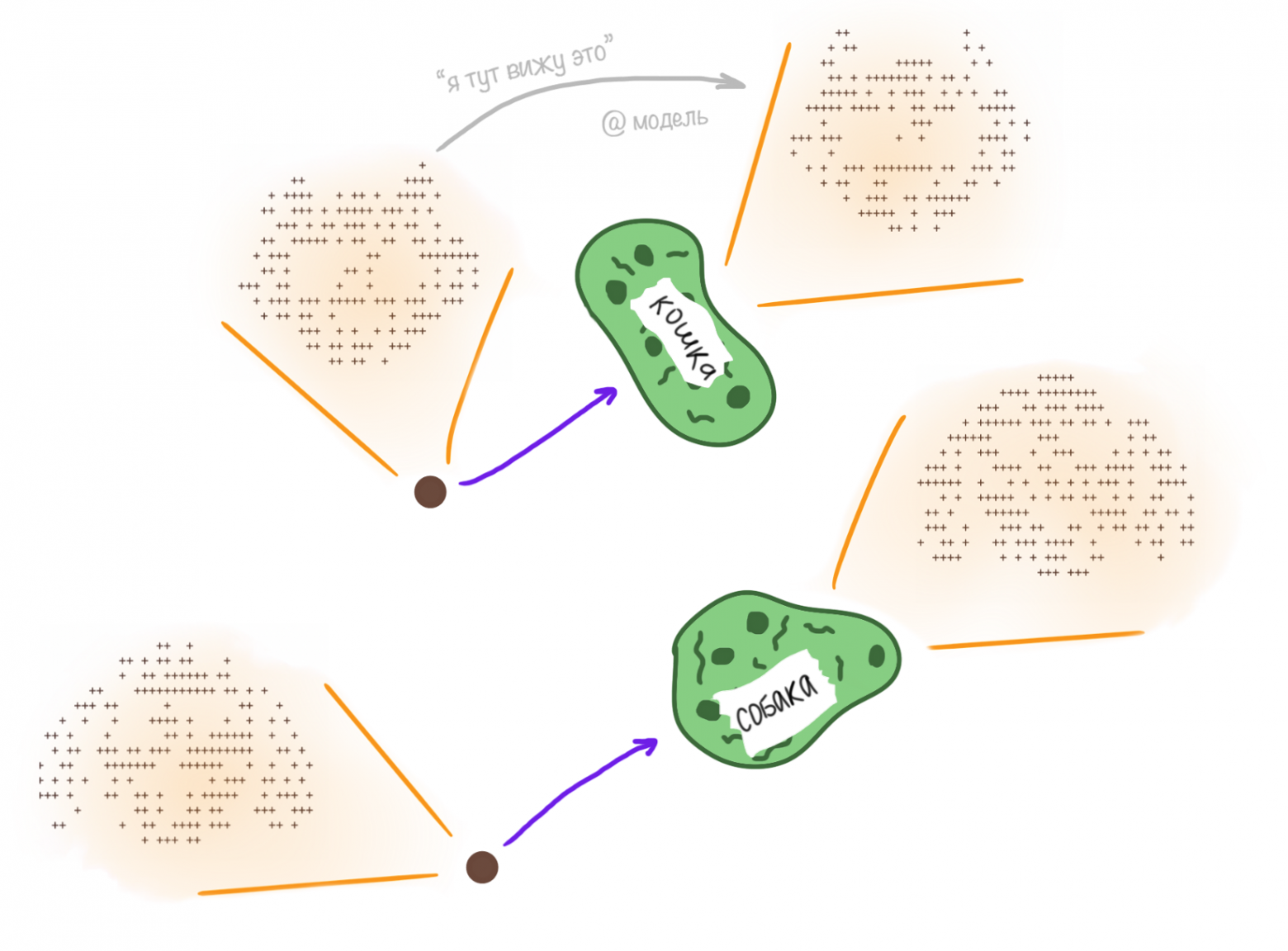
По сути, сам ответ на вопрос «на картинке изображена собака или кошка?» имеет смысл только для нас, для людей. Для модели же именно смысловая нагрузка заключена в переходе от подаваемой картинки к той, что содержится у неё в памяти в виде одной из выживших в ходе обучения клеток. Метка на клетке – это просто удобство; способ, с помощью которого уже мы, люди, интерпретируем результаты обработки данных моделью.
Ментальный образ – это тоже объект в памяти мозга, который наше сознание ставит в соответствие воспринимаемому объекту. Например, когда мы видим какую-то конкретную кошку, в голове это провоцирует отклик в виде образа некоторой абстрактной кошки. Образ и реально наблюдаемый объект не обязаны совпадать в деталях, но их общие характерные черты позволяют нам провести сравнение и осуществить переход.
В виду сказанного, клетки внутри модели выполняют роль ментальных образов. Такая аналогия позволяет нам дать ответы на поставленные выше вопросы, по новому взглянуть на механизм обучения и запоминания.
Мозг как дискретный аппроксиматор
Пришло время дать название нашей модели. В силу того, что конечный набор дискретных клеток во время обучения аппроксимирует в том числе непрерывное распределение входных данных (см. график), хорошим названием видится «дискретный аппроксиматор».
. Красным - расположение клеток колонии. Пространство одномерное.")
И так, пусть мозг при запоминании и распознавании действует как дискретный аппроксиматор. В случае взаимодействия с новым для человека объектом, его мозг не стремится сразу запомнить этот объект. Более того, сначала человек может воспринимать объект искаженно. И лишь спустя некоторое время, в течение которого он взаимодействовал с этим объектом, в сознании человека появится новый образ. Например, если вы никогда не видели волка (даже на картинке), никогда про него не слышали, то, скорее всего, при первой встрече подумаете, что это большая собака.
Это происходит потому, что соответствующая волку питательная точка в ментальном пространстве, сначала запитывает клетку-образ собаки (так как она – ближайшая по всем характеристикам). Если взаимодействие с волком произойдет единожды, то новый образ не появится или по крайней мере не закрепится в сознании. Однако при постоянном контакте с волком, клетка-образ собаки наберет массу, поделится и дочерняя клетка станет уже образом волка.
То же самое с изучением иностранных языков. Нужно регулярное повторение, чтобы запомнить новые слова. Сначала новое слово запитывает образы старых, созвучных слов. Поэтому за раз новое слово не выучить, оно быстро забудется. Но регулярное повторение провоцирует клетки-образы достичь критической массы и поделиться, создавая вакантный образ для нового слова.
В то же время, клетки подвержены старению. Старые воспоминания стираются: образ без подкрепления (через взаимодействие с соответствующим реальным объектом) теряет постепенно массу, а затем, по достижении нулевого значения последней, умирает. Хоть способность человека забывать информацию часто рассматривается как нечто негативное, это очень важный механизм приспособления к новым условиям, избавления от неактуальных или добавленных по ошибке образов.
Наконец, можно утверждать, что точность распознавания объектов не имеет ограничений разве только в виде конечного объёма памяти мозга. В рамках предоставленного количества образов можно реализовать любую мелкость разбиения области. Можно 10 клеток расставить на отрезке в 10 см, а можно их же расставить на отрезке в 0,1 см.
При первом знакомстве с новой местностью вы вряд ли позже сможете в точности воспроизвести расположение всех объектов на карте. Однако чем больше вы будете посещать это место, тем лучше вы будете помнить, что где находится, и через время сможете ориентироваться, что называется, «на автомате». Это конкретный пример того, как мозг постепенно увеличивает точность своей внутренней модели реальности.
Ограничение здесь, повторюсь, только в числе образов, которые память мозга может в себя вместить. Но прежде, чем память закончится, мозг очистит её от старых образов – воспоминания о местности, где вы провели детство, будут становиться постепенно всё более размытыми, по мере того, как вы будете всё лучше ориентироваться в новом городе.
Нейроны места
А что на подобные рассуждения может ответить биология? Есть ли биохимические процессы в мозге, которые бы отвечали за формирование новых образов? Не буду томить – такое явление существует и называется оно нейрогенезом.
Нейрогенез – это процесс зарождения и роста новых нейронов. Долгое время ученые полагали, что «нервные клетки не восстанавливаются», что нейрогенез происходит только в раннем возрасте, на этапе активного роста мозга и организма в целом. Так вот это заблуждение. Последние исследования [1] говорят в пользу того, что и у взрослых представителей человеческого вида по крайней мере в гиппокампе протекают процессы образования новых нейронов.
Ежедневно в гиппокампе добавляется около 700 новых нейронов [2]. При этом около 50 % новорождённых клеток погибает по механизмам запрограммированной клеточной гибели, но если молодые нейроны образуют синаптические контакты или получают необходимую трофическую поддержку, то они могут выживать в течение долгого времени [3].
Наконец, как выясняется [4, 5], попытки искусственно затормозить процессы нейрогенеза у крыс приводят к ухудшению распознавания ими схожих объектов, эмоций и мест.
Лично я вижу здесь определённое сходство между тем как работает «дискретный аппроксиматор» и тем как проявляется нейрогенез. Идём дальше.
В 2014-м году нобелевку по физиологии и медицине присудили американскому ученому Джону О’Кифу и и норвежским исследователям Мей-Бритт Мозер и Эдварду Мозер за открытие нейронов места.
Нейроны места – это «особый» тип нейронов, которые активируются, когда животное или человек находятся в определённом месте. То есть каждый нейрон отвечает за определённую область в пространстве (отсюда и название), становится носителем её ментального образа. Расположены нейроны места в гиппокампе.

Вот как выглядят результаты эксперимента над крысой, которая бегала по специальной дорожке, по которой рассыпан корм[6]. Точками нанесены положения животного, когда активировался один из нейронов. Цвет точки соответствует нейрону, который активировался, когда крыса находилась в этой точке.
Легко видеть, что каждой области (группе точек одного цвета) соответствует свой нейрон. И не смотря на то, что пространство непрерывно, мозгу крысы удалось разбить его на 8 зон.
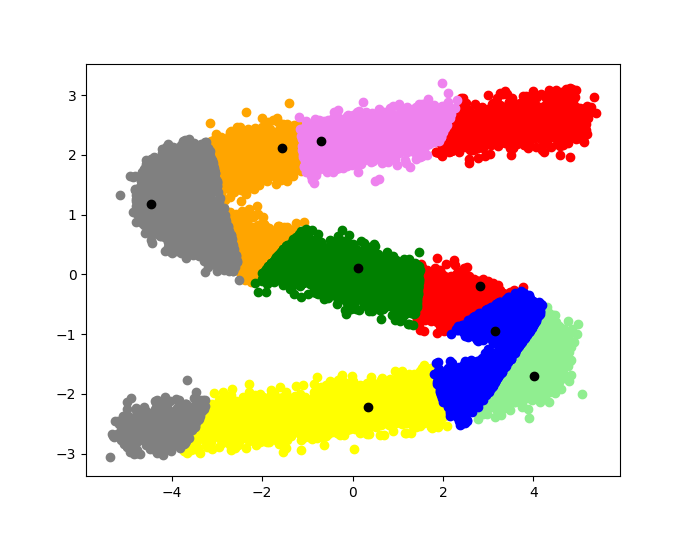
А вот уже результаты симуляции подобного эксперимента с помощью дискретного аппроксиматора. Черными точками отмечены клетки-образы соответствующих мест, цветными точками – положения симуляции крысы. Каждому цвету соответствует область, ближайшая к одной из клеток.
Вот ещё пример. Здесь крыса бегала уже по замкнутой треугольной дорожке.
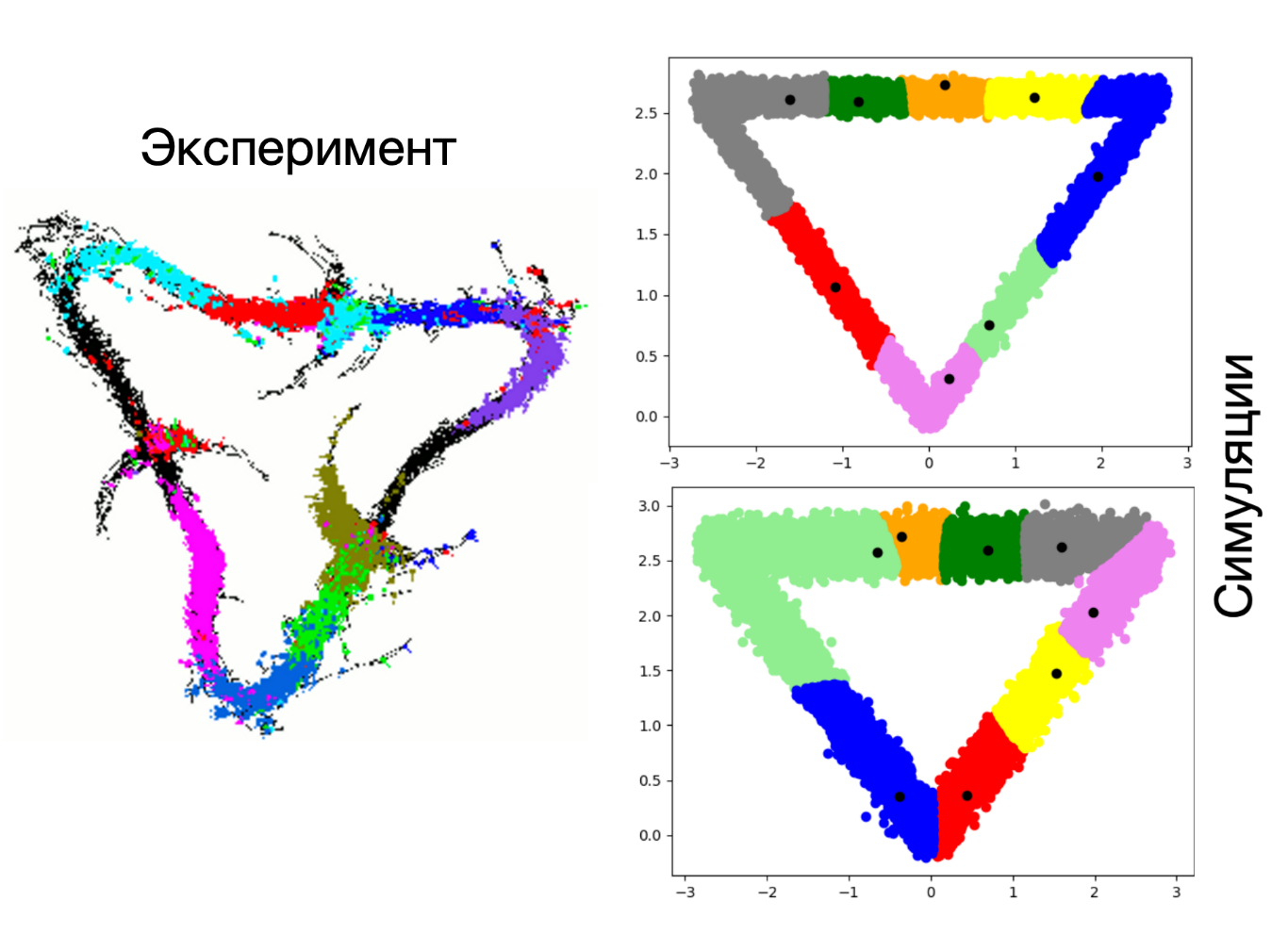
Довольно показательной является история «пациента H.M.» . Генри Густав Молисон в детстве получил черепно-мозговую травму и впоследствии страдал от приступов эпилепсии. Нейрохирург Уильям Сковилл в качестве решения проблемы предложил удалить некоторые раздела мозга, включая гиппокамп. После операции приступы эпилепсии действительно прошли, но важно не это. Молисон потерял возможность запоминать новые события в его жизни. Такие люди живут в настоящем, не помня, что было 5 минут назад.
Тщательные наблюдения за пациентом, позволили ученым прийти к выводу, что гиппокамп - та самая область мозга с активно протекающими процессами нейрогенеза - принимает активное участие в работе кратковременной памяти.
Согласно современным представлениям, вновь поступающая в мозг информация после первичной обработки сначала сохраняется в гиппокампе. Если переживание достаточно сильное или мы периодически вспоминаем его в первые несколько дней, гиппокамп пересылает его обратно в кору головного мозга на «постоянное» хранение.
Кавычки поставлены по той простой причине, что воспоминания даже в долговременной памяти подвержены стиранию, перезаписи при повторном обращении к ним. Это явление называется реконсолидацией.
Логично предположить, что нейрогенез происходит и в других областях мозга, но менее активно, что приводит к большей стабильности и сохранности воспоминаний и выученных навыков. Другими словами активный нейрогенез соответствует кратковременной памяти, а пассивный - долгосрочной.
Другие примеры
Рассмотрим ещё примеры того, чему можно научить дискретный аппроксиматор. Ниже можно видеть результат аппроксимации сложной траектории, в виде двух фигур, которые в полярных координатах описываются уравнением:

, ?=Ωt")
Наконец, самый, на мой взгляд, эффектный пример, когда аппроксиматор учится играть в мяч. Правила довольно простые: необходимо пододвигая платформу снизу ловить мячик, который каждый раз начинает падать в случайном месте.
Во время обучения на вход модели (то есть в качестве координат питательных точек) подаём тройку (x,y,z), где x,y – координаты мячика, z – положение платформы (по горизонтали). А на выход (в качестве метки) подаём действие: подвинуть платформу на позицию вправо, влево или оставить на месте.

Заключение
Статья подходит к концу. К каким выводам можно прийти? Прежде всего, представленная клеточная модель действительно способна справляться с задачами машинного обучения, такими как распознавание картинок, аппроксимация математических функций, автоматическое управление.
Конечно, имеются и проблемы, связанные, например, со сходимостью алгоритма. Однако есть и преимущества, по отношению к тем же нейросетям. Модель не является «черным ящиком», каждая клетка-образ (в отличие от нейронов скрытого слоя) является носителем отдельной смысловой единицы (образа). В силу этого построенная на описанных выше принципах более сложная и полная модель будет более пригодной для масштабирования интерпретации внутренних процессов. Можно будет напрямую комбинировать различные обученные раздельно модели в одну, а также извлекать напрямую выявленные моделью закономерности в данных.
Другой момент, который хотелось бы отметить, это наличие в мозге человека и животных процессов, которые схожи с процессами в модели в плане как механизма протекания, так и назначения. Клетки внутри модели живут и делятся, имитируя процессы нейрогенеза. Нейрогенез принимает активное участие в распознавании и запоминании. Модель также хорошо справляется с этими задачами.
Спасибо всем, кто дочитал до этого места. Отдельное спасибо тем, кто читал вдумчиво, не пропуская абзацы. Надеюсь, статья была интересной и полезной. Жду ваши отзывы и идеи в комментариях.
