Цель/введение
Реактивные паттерны программирования становятся всё более востребованы при реализации высоконагруженных сервисов. Реактивные фреймворки предоставляют инструменты, позволяющие с минимальными затратами на кодирование использовать механизмы асинхронности и многопоточности.
В качестве примера, предлагаю рассмотреть реализацию сервис индексации данных в ElasticSearch. Данные хранятся в MongoDB, ключевые атрибуты которых синхронизируются с ElasticSearch (функционально похоже на Logstash). В проекте используется стек: Java/Spring Boot/Reactor/WebFlux/WebClient/RabbitMQ/MongoDB. На выбор RabbitMQ и MongoDB повлияло, в том числе, наличие реактивных драйверов.
Описание задачи
Сервис должен принимать поток данных из очереди, выбирать связанные данные из базы и передавать их ElasticSearch. Формат данных очереди: действие (index/delete); id документа; имя индекса; тип индекса (опционально).
Через web-интерфейс должен быть реализован функционал добавления, удаления и перестроения индекса.
Должна быть возможность формирования агрегированных полей, содержащих данные из нескольких исходных полей документов, и добавление данных в индекс из связанных коллекций.
Описание индексируемых данных должно быть в формате JSON.
DFD-диаграмма процесса индексации
Схема процесса индексации запросов, поступающих из очереди, выглядит следующим образом:

Алгоритм перестроения индекса выглядит практически также, за исключением того, что в нем отсутствует обработка запросов, отложенных из-за ошибок.
Описание функционала
Описание функционала коснется только работы реактивной части сервиса. Конфигурационные настройки, обработка формата описания индексируемых данных, формирование данных для запросов к ElasticSearch вынесены за рамки данной статьи, но вы можете посмотреть код на GitHub, по ссылке.
Теперь попробуем реализовать эту схему сквозным потоком Reactor, не используя подписки на отдельные элементы, в том числе отправку через WebClient HTTP-запросов и обработку полученных ответов. Отдадим, почти полностью, синхронизацию выполнения Reactor.
Код, запускающий процесс переиндексации выглядит следующим образом:
Task task = new Task(mongoElasticIndex); ParallelFlux dataEventsFlux = reactorRepositoryMongoDB .findAll(mongoElasticIndex.getCollection(), mongoElasticIndex.getProjection()) .parallel(appConfig.getIndexParallelism()) .runOn(Schedulers.boundedElastic()); Flux<Tuple2<String,Document>> processingData = processingData(dataEventsFlux, (p) -> "index", (p) -> (Document)p, (p) -> mongoElasticIndex, Flux.just(), task); task.setDispose(subscribe(processedData, task));
Получаем поток данных из коллекции, настраиваем параллелизм, формируем объект обработки потока и подписываемся на поток. Здесь класс Task – внутренний класс, назначение которого: собирать статистику и предоставлять информацию о выполняемых задачах индексации.
Метод processingData возвращает поток запросов и ответов, отправленных WebClient’ом:
private <T> Flux<Tuple2<String,Document>> processingData(ParallelFlux<T> events, Function<T, String> getAction, Function<T, Document> getDocument, Function<T, MongoElasticIndex> getMongoElasticIndex, Flux<String> mergeFlux, Task task) { return events // Добавление данных к исходному документу из присоединяемых коллекций .transform(joinData(getDocument, getMongoElasticIndex)) // Генерация данных для передачи в ElasticSearch .transform(document2ElasticJson(getAction, getDocument, getMongoElasticIndex)) .sequential() // Агрегирование данных для _bulk .transform(grouping(task)) // Добавление потока данных, на которые не получен ответ от ElasticSearch .mergeWith(mergeFlux) // Отправка запросов в ElasticSearch .transform(postBulk(task)) .subscribeOn(Schedulers.single()) .doOnNext(testAliveResponses(task)) .doOnSubscribe(p-> p.request(appConfig.getMaxSizeBuffer() * 2)) .doOnComplete(() -> { logger.info("Start: {} End: {} read {} write {}", formatDate(task.getStartDate()), formatDate(new Date()), task.getDocumentsRead(), task.getIndexesWrite(), getMaxProcessingRequest()); fileStorage.writeCollection2Files(waitingForResponse); removeTask(task); }); }
Методом transform Reactor соединяем отдельные обработчики потоков. Здесь есть одно существенное ограничение: входящий и исходящий потоки должны быть однотипными (Flux или ParallelFlux). Нельзя, например, с помощью transform встроить обработчик у которого вход Flux, а выход ParallelFlux.
В метод subscribe сервиса инкапсулирована подписка на поток. Ниже приведена его реализация:
private Disposable subscribe(Flux<Tuple2<String,Document>> events, Task task) { return events .subscribe( p -> { if(isNull(task.getMongoElasticIndex())) { // Если задача не переиндексация waitingForResponse.remove(p.getT1()); } int count = Optional.ofNullable(p.getT2().get("items", List.class)) .map(List::size) .orElse(0); task.addIndexesWrite(count); }, e -> { if(task != rabbitMQTask)removeTask(task); fileStorage.writeCollection2Files(waitingForResponse); logger.error("Error: {}", e.getMessage()); } ); }
Далее коротко об отдельных функциях обработки потока.
Загрузка документов
Имеются два варианта загрузки:
Для всех документов основной коллекции индекса
ParallelFlux dataEventsFlux = reactorRepositoryMongoDB .findAll(mongoElasticIndex.getCollection(), mongoElasticIndex.getProjection()) .parallel(appConfig.getIndexParallelism()) .runOn(Schedulers.boundedElastic());
Метод findAll возвращает поток для всех документов коллекции. Parallel и runOn настраивают многопоточность для выборки и дальнейшей обработки.
Для единичного запроса, приходящему из очереди
ParallelFlux dataEventsFlux = reactiveQueue.inboundFlux() .parallel(appConfig.getIndexParallelism()) .runOn(Schedulers.boundedElastic()) .map(msg -> { IndexEvent indexEvent = reactiveQueue.msg2IndexEvent(msg); try { return CreateIndexItem(indexEvent); } catch (IllegalObjectIdException | IOException | ConvertDataException e) { logger.error("{} For message: {}", String.join(", ",throwable2ListMessage(e)), new String(msg.getBody(), StandardCharsets.UTF_8)); return new IndexItem(null, null, null); } }) .filter(e -> nonNull(e.getAction())) .flatMap(item -> Flux.zip("delete".equals(item.getAction()) // Для операции удаления создаётся Document, содержащий _id удаляемого документа ? Flux.just(new Document().append("_id", item.getIdDocument().get("_id"))) // Для операции обновления индекса Document загружается из базы данных : reactorRepositoryMongoDB.find( item.getMongoElasticIndex().getCollection(), item.getIdDocument(), item.getMongoElasticIndex().getProjection()), Flux.just(item) ) .map(d -> new EventDocument(d.getT2().getAction(), d.getT1(), d.getT2().getMongoElasticIndex())) );
Метод inboundFlux интерфейса reactiveQueue возвращает поток для очереди. Parallel и runOn идентичны предыдущему варианту. Далее событие преобразуется из JSON в объект IndexEvent, по содержимому которого документ извлекаются из базы, или создаётся объект для удаления документа из ElasticSearch.
Добавление данных к исходному документу из присоединяемых коллекций
private <T> Function<ParallelFlux<T>, ParallelFlux<T>> joinData(Function<T, Document> getDocument, Function<T, MongoElasticIndex> getMongoElasticIndex) { return (ParallelFlux<T> items) -> items.flatMap(p -> { if(getDocument.apply(p).size() == 1) { return Flux.just(p); } return Flux.fromIterable(getMongoElasticIndex.apply((T) p).getJoinConditions(getDocument.apply(p))) .flatMap(it -> Flux.zip(Flux.just(it.getCollection().getJoinedFieldName()), reactorRepositoryMongoDB.find(getMongoElasticIndex.apply((T) p).getCollection(), it.getCondition(), it.getCollection().getProjection()))) .reduce(p, (acc, t) -> { getDocument.apply(acc).put(t.getT1(), t.getT2()); return acc; }); } ); }
Метод joinData возвращает функциональный объект, добавляющий данные к исходному документу из документов присоединяемых коллекций. Использование flatMap и Flux.zip позволяет асинхронно запускать и обрабатывать потоки, в том числе и потоки, создаваемые запросами к базе данных mongodb. Все вопросы, связанные с синхронизацией, берет на себя Reactor.
Генерация JSON для ElasticSearch
private <T> Function<ParallelFlux<T>, ParallelFlux<String>> document2ElasticJson( Function<T, String> getAction, Function<T, Document> getDocument, Function<T, MongoElasticIndex> getMongoElasticIndex) { return (ParallelFlux<T> items) -> items.map(item -> { String elasticSend; try { Document document = getDocument.apply(item); MongoElasticIndex mongoElasticIndex = getMongoElasticIndex.apply(item); elasticSend = "delete".equals(getAction.apply(item)) ? mongoElasticIndex.deleteBuild(document) : mongoElasticIndex.indexBuild(document); } catch (ConvertDataException e) { throw new RuntimeException(e); } catch (JsonProcessingException e) { throw new UncheckedIOException(e); } return elasticSend; }); }
Из полученного документа формируется JSON-объект модификации индекса в ElasticSearch. Контролируемые исключения приходится конвертировать в неконтролируемые.
Агрегирование данных для _bulk-запроса
Function<Flux<String>, Flux<String>> grouping(Task task) { return (Flux<String> source) -> source .bufferTimeout(appConfig.getMaxSizeBuffer(), Duration.ofMillis(appConfig.getMaxDurationBuffer())) .doOnNext(p -> task.addDocumentsRead(p.size())) .map(p -> String.join("\n", p) ); }
Использование _bulk-запроса к ElasticSearch позволяет существенно снизить трафик и повысить производительность индексации. Объединение отправляемых данных несложно сделать при помощи bufferTimeout. Значениями максимального размера буфера и времени ожидания можно найти компромисс между оперативностью обновления данных в ElasticSearch, размером запроса и производительностью.
Отправка запросов ElasticSearch
public Function<Flux<String>, Flux<Tuple2<String, Document>>> postBulk(Task task) { return (Flux<String> source) -> source .flatMap(buffer -> { if(isNull(task.getMongoElasticIndex())) { // Если задача не переиндексация waitingForResponse.add(buffer); } return Flux.zip(Flux.just(buffer), webClientElastic.post() .uri("/_bulk") .body(BodyInserters.fromValue(buffer)) .retrieve() .onStatus(httpStatus -> httpStatus.equals(HttpStatus.TOO_MANY_REQUESTS), response -> Mono.error(new HttpServiceException("System is overloaded", response.rawStatusCode()))) .onStatus(httpStatus -> httpStatus.is4xxClientError() && !httpStatus.equals(HttpStatus.TOO_MANY_REQUESTS), response -> Mono.error(new RuntimeException("API not found"))) .onStatus(HttpStatus::is5xxServerError, response -> Mono.error(new HttpServiceException("Server is not responding", response.rawStatusCode()))) .bodyToFlux(Document.class) .retryWhen(Retry.backoff(appConfig.getWebClientRetryMaxAttempts(), Duration.ofSeconds(appConfig.getWebClientRetryMinBackoff())) .filter(throwable -> throwable instanceof HttpServiceException) .onRetryExhaustedThrow((retryBackoffSpec, retrySignal) -> { throw new HttpServiceException("External Service failed to process after max retries", HttpStatus.SERVICE_UNAVAILABLE.value()); })) ); }); }
Создаётся поток, отправляющий через WebClient запросы к ElasticSearch. Поток, формируемый методом post WebClient’а, Flux.zip объединяет с запросом, это позволяет при обработке ответа связать полученный ответ с отправленным запросом. С помощью retryWhen, Retry.backoff настроена обработка некоторых ошибок.
Обработка ответов ElasticSearch
private Disposable subscribe(Flux<Tuple2<String,Document>> events, Task task) { return events .subscribe( p -> { if(isNull(task.getMongoElasticIndex())) { // Если задача не переиндексация waitingForResponse.remove(p.getT1()); } int count = Optional.ofNullable(p.getT2().get("items", List.class)) .map(List::size) .orElse(0); task.addIndexesWrite(count); }, e -> { if(task != rabbitMQTask)removeTask(task); fileStorage.writeCollection2Files(waitingForResponse); logger.error("Error: {}", e.getMessage()); } ); }
Обработка ответов ElasticSearch минимальна. Если ответ получен на контролируемый запрос (не запрос на переиндексацию), то запрос удаляется из множества запросов, для которых контролируется получение ответа. Ответы на переиндексацию не контролируются. В полученном ответе атрибут items должен быть списком, содержащим информацию об обработанных документах. На количество элементов в списке увеличивается счетчик обработанных документов.
Настройка WebClient
Основная часть настройки делается в конфигурационном классе, бин возвращает объект WebClient.Builder:
@Bean @Qualifier("elastic") public WebClient.Builder webClientWithTimeout() { final TcpClient tcpClient = TcpClient .create() .option(ChannelOption.CONNECT_TIMEOUT_MILLIS, timeout) .doOnConnected(connection -> { connection.addHandlerLast(new ReadTimeoutHandler(timeout, TimeUnit.MILLISECONDS)); connection.addHandlerLast(new WriteTimeoutHandler(timeout, TimeUnit.MILLISECONDS)); }); return WebClient.builder() .baseUrl(baseUrl +":" + port.toString()) .filter(basicAuthentication(user, password)) .defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE); }
В конструкторе сервиса добавляются фильтры, вызываемые при отправке запроса и получении ответа:
this.webClientElastic = webClientElastic .filter(onRequest()) .filter(onResponse()) .build();
Методы, возвращающие фильтры:
private ExchangeFilterFunction onRequest() { return ExchangeFilterFunction.ofRequestProcessor(clientRequest -> { addSendRequest(); int sleepCycleCount = 0; while (getProcessingRequest() > getMaxProcessingRequest()) { try { logger.info("Sleep: {} ProcessingRequest reached {} (MaxProcessingRequest {})", getSleepOverRequest(), getProcessingRequest() - 1, getMaxProcessingRequest()); sleep(getSleepOverRequest()); if (sleepCycleCount++ > appConfig.getSleepCycleCountMax()) { break; } } catch (InterruptedException e) { e.printStackTrace(); } } logger.info("Request: {} {}", clientRequest.method(), clientRequest.url()); return Mono.just(clientRequest); }); } private ExchangeFilterFunction onResponse() { return ExchangeFilterFunction.ofResponseProcessor(clientResponse -> { addReceiveResponse(); logger.info("Response Status {}", clientResponse.statusCode()); return Mono.just(clientResponse); }); }
Фильтры выводят информацию об отправке запросов, получении ответов и модифицируют счетчики отправленных запросов и полученных ответов. Перед отправкой запроса, если превышено количество не полученных ответов, процесс “засыпает” на некоторое время.
Настройка среды выполнения
Для того чтобы запустить этот сервис нам нужны: rabbitmq, mongodb и elasticsearch. Всё это проще установить в Docker. Ещё в самом начале проекта установил Docker Desktop и настроил контейнеры для запуска нужных cервисов. Как это делается можно посмотреть, например, в этой статье. По аналогии установил rabbitmq, mongodb. Добавил конфигурационные файлы и внес изменения в файл docker-compose.yml. Получившиеся настройки Docker можно найти в папке проекта docker-elk. Ниже скриншот запущенного контейнера:
Запуск сервиса
Для тестирования загрузил в базу mongodb 1000 документов. Из Postman и отправляю запрос:
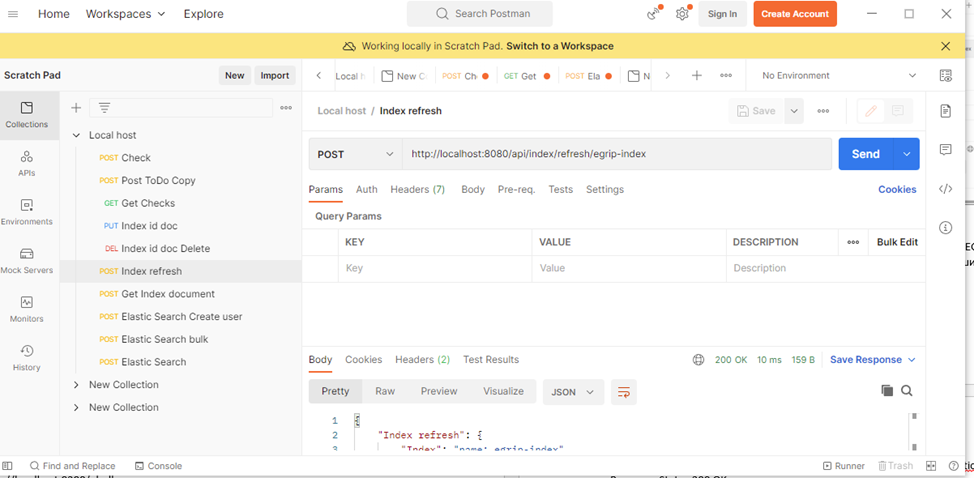
В полученном логе видно, что обработка выполняется в разных потоках:
2022-11-02 15:23:17.396 INFO 8336 --- [ Thread-6] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:17.418 INFO 8336 --- [ Thread-42] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:17.447 INFO 8336 --- [ Thread-5] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:17.462 INFO 8336 --- [ Thread-7] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:17.475 INFO 8336 --- [ctor-http-nio-1] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:17.477 INFO 8336 --- [ Thread-33] org.mongodb.driver.connection : Opened connection [connectionId{localValue:855, serverValue:83}] to localhost:27017 2022-11-02 15:23:17.484 INFO 8336 --- [ctor-http-nio-2] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:17.485 INFO 8336 --- [ Thread-5] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:17.489 INFO 8336 --- [ctor-http-nio-3] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:17.493 INFO 8336 --- [ Thread-4] org.mongodb.driver.connection : Opened connection [connectionId{localValue:856, serverValue:84}] to localhost:27017 2022-11-02 15:23:17.566 INFO 8336 --- [ Thread-6] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:17.588 INFO 8336 --- [ Thread-7] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:17.622 INFO 8336 --- [ Thread-4] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:17.651 INFO 8336 --- [ctor-http-nio-4] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:17.651 INFO 8336 --- [ctor-http-nio-1] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:17.658 INFO 8336 --- [ctor-http-nio-2] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:17.658 INFO 8336 --- [ctor-http-nio-3] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:17.673 INFO 8336 --- [ Thread-52] org.mongodb.driver.connection : Opened connection [connectionId{localValue:940, serverValue:85}] to localhost:27017 2022-11-02 15:23:17.676 INFO 8336 --- [ Thread-7] org.mongodb.driver.connection : Opened connection [connectionId{localValue:941, serverValue:86}] to localhost:27017 2022-11-02 15:23:17.715 INFO 8336 --- [ctor-http-nio-4] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:17.738 INFO 8336 --- [ Thread-5] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:17.748 INFO 8336 --- [ Thread-34] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:17.772 INFO 8336 --- [ Thread-7] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:17.790 INFO 8336 --- [ Thread-34] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:17.811 INFO 8336 --- [ctor-http-nio-1] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:17.818 INFO 8336 --- [ctor-http-nio-2] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:17.849 INFO 8336 --- [ Thread-36] org.mongodb.driver.connection : Opened connection [connectionId{localValue:993, serverValue:87}] to localhost:27017 2022-11-02 15:23:17.851 INFO 8336 --- [ Thread-36] org.mongodb.driver.connection : Opened connection [connectionId{localValue:994, serverValue:88}] to localhost:27017 2022-11-02 15:23:17.895 INFO 8336 --- [ctor-http-nio-3] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:17.898 INFO 8336 --- [ctor-http-nio-4] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:17.911 INFO 8336 --- [ Thread-6] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:17.926 INFO 8336 --- [ Thread-36] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:17.944 INFO 8336 --- [ Thread-36] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:17.966 INFO 8336 --- [ Thread-36] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:17.993 INFO 8336 --- [ Thread-36] org.mongodb.driver.connection : Opened connection [connectionId{localValue:1078, serverValue:90}] to localhost:27017 2022-11-02 15:23:18.002 INFO 8336 --- [ Thread-48] org.mongodb.driver.connection : Opened connection [connectionId{localValue:1079, serverValue:89}] to localhost:27017 2022-11-02 15:23:18.041 INFO 8336 --- [ Thread-34] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:18.044 INFO 8336 --- [ctor-http-nio-4] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:18.044 INFO 8336 --- [ctor-http-nio-2] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:18.044 INFO 8336 --- [ctor-http-nio-3] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:18.044 INFO 8336 --- [ctor-http-nio-1] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:18.059 INFO 8336 --- [ Thread-31] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:18.076 INFO 8336 --- [ Thread-7] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:18.083 INFO 8336 --- [ctor-http-nio-1] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:18.096 INFO 8336 --- [ctor-http-nio-2] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:18.135 INFO 8336 --- [ Thread-34] org.mongodb.driver.connection : Opened connection [connectionId{localValue:1156, serverValue:92}] to localhost:27017 2022-11-02 15:23:18.138 INFO 8336 --- [ Thread-39] org.mongodb.driver.connection : Opened connection [connectionId{localValue:1155, serverValue:91}] to localhost:27017 2022-11-02 15:23:18.140 INFO 8336 --- [ Thread-39] ru.mvz.elasticsearch.service.Indexer : Request: POST http://localhost:9200/_bulk 2022-11-02 15:23:18.180 INFO 8336 --- [ctor-http-nio-3] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:18.180 INFO 8336 --- [ctor-http-nio-4] ru.mvz.elasticsearch.service.Indexer : Response Status 200 OK 2022-11-02 15:23:18.181 INFO 8336 --- [ctor-http-nio-4] ru.mvz.elasticsearch.service.Indexer : Start: 2022-11-02 15:23:17.250 End: 2022-11-02 15:23:18.181 read 1000 write 1000
Теперь проверим, что загрузилось.
Запрос к ElasticSearch показывает наличие индекса с 1000 документами:

И попробуем найти что-то в ElasticSearch:

Получен ответ ElasticSearch с найденным документом!
Заключение
В этом материале мне хотелось привести пример сервиса, реализованного с использованием Spring Boot, WebFlux, WebClient, Reactor - надеюсь, что у меня это получилось.
Несколько выводов:
Реактивные фреймворки, в том числе и Reactor, делает за нас существенную часть работы по реализации асинхронных многопоточных алгоритмов, позволяя сосредоточиться на предметной области.
С их помощью можно, достаточно просто, создавать высоконагруженные сервисы.
Для получения максимального эффекта от перехода на реактивные паттерны программирование нужно чтобы вся цепочка вычислений была реактивной, начиная с драйверов доступа к базам данных, очередям, файлам и т.д.
Ещё раз, репозиторий с кодом и настройками находится здесь
Несколько ссылок на используемые материалы:
Шпаргалка по Spring Boot WebClient
Reactive Programming: Reactor и Spring WebFlux — часть 2
Реактивное программирование со Spring, часть 2 Project Reactor
