This is a series of articles dedicated to the optimal choice between different systems on a real project or an architectural interview.
In this series of articles, I will not talk about the deep beginnings of these technologies, I will not analyze every detail, but will focus on how to correctly submit these technologies to an interview and choose the correct and shortest path that would convince the interviewee that you have made the best decision in your particular situations.
This topic seemed relevant to me because such tasks can be encountered both at work and at an interview for System Design Interview and you will have to choose between these two types of DBMS. I plunged into this issue and will tell you what and how. What is better in each case, what are the advantages and disadvantages of these systems and which one to choose, I will show with several examples at the end of the article.
To understand the topic, you need to dive a little into the structure of these databases.
High-level differences between SQL and NoSQL
Storage:
SQL stores data in tables where each row represents an entity and each column represents information about that entity.
The most popular SQL databases are PostgreSQL (most likely you will choose it in an interview in 80% of cases, because it is one of the most common and easy to learn), Microsoft SQL, Oracle Database (both are ideal for large enterprise systems, like banks) and MySQL.
NoSQL has different data storage models such as key-value, graph, document, columnar etc.
The most popular NoSQL by type of storage that you are likely to choose in an interview and about which you should at least read a couple of articles:
Key-value: Redis and Amazon DynamoDB.
Document-oriented: MongoDB.
Graph: Neo4j, GraphDB
Columnar: Apache HBase, Apache Cassandra

Most likely, the interview will have such a task where you will need to choose the first 2 types (unless, of course, the preference is NoSQL), so you should study them in more detail and write some small project using, for example, Redis and MongoDB.
Different metrics for different non-relational databases
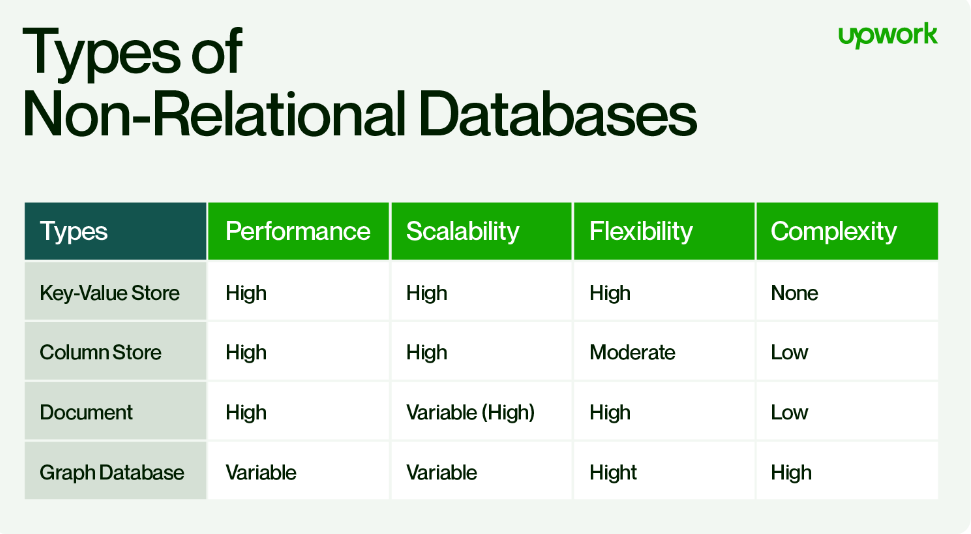
Scheme:
A schema in a SQL database refers to the organization or structure of data in the database. It defines the tables, fields, relationships, and constraints that make up the database, and serves as a blueprint for how data should be organized and stored. Schemas can be used to enforce data integrity and consistency, and they can also help with managing access to data by defining which users or roles have permission to perform certain actions.
In a NoSQL database, the concept of a schema is often less rigid and structured compared to a SQL database. NoSQL databases can be schemaless, meaning that the structure of the data being stored can change dynamically and doesn't need to be defined upfront.
However, some NoSQL databases do have a form of a schema, but it can be more flexible and dynamic than in SQL databases. For example, in a document-oriented NoSQL database like MongoDB, each document can have its own unique set of fields, and the data structure can change from document to document. In a key-value store like Redis, each key-value pair can have a different data type, so the structure of the data is implicit and doesn't need to be explicitly defined.
The specific scheme of a NoSQL database depends on the type of database and the design choices made by the developer or architect.
Queries:
For queries to SQL databases, respectively, the SQL language is used with various modifications from database developers, for convenient binding of programming languages with SQL databases, ORM is used, in the case of Java, this is Hibernate, Spring Data
There is no specific language for queries in the NoSQL database, it all depends on the type of database type that was described earlier, using specialized APIs, declarative structured and Query-by-Example queries
Examples of queries in SQL and NoSQL database MongoDB:

In this query, we are looking for contacts who either have at least one work phone number or were hired after a certain date. Again, we see that the MongoDB equivalent is quite simple.
Note the use of dollar signs in operator names (`$or`, `$gt`) as syntactic sugar. Also note that in both examples it's important to use an actual date in our comparison, not a string.
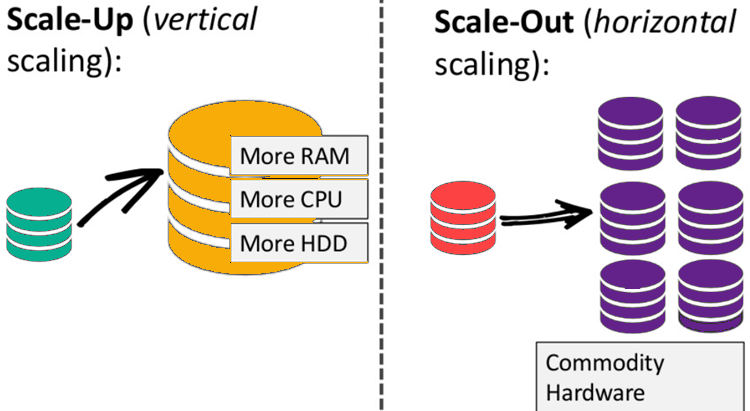
Scalability:
In most cases, SQL databases are vertical and this can be expensive on the budget. You can scale such databases horizontally, but this requires some skill, knowledge and specifics of the database you work with, otherwise there is a risk of losing data. On this occasion, you can read in detail about sharding, partitioning and replication.
But with NoSQL databases horizontal scaling works better. NoSQL databases scale horizontally, which means we can easily add additional servers to our NoSQL database infrastructure to handle large traffic.
Many NoSQL technologies also distribute data automatically between servers. Why is NoSQL easier to scale? Because there is no JOIN operation. Therefore, JOIN operations scale poorly, and this is the fundamental problem with the relational approach. However, this (in most cases) also lacks ACID properties, which can lead to data loss, inconsistencies, and other disadvantages of non-ACID systems.
Reliability:
Most relational databases use ACID properties. This means that when it comes to data integrity and transaction reliability, databases are the best choice.
On the other hand, non-relational databases sacrifice ACID for the sake of fast scaling and high performance, so such databases should be used in places where data safety and transactionality should not be 99.9%.
Let's summarize what and when to use.
SQL if you need:
- Structured data with strict schema
- Relational data
- The need for complex joins (use of subqueries, join)
- Transactions
- Search by index
NoSQL if you need:
- Dynamic or flexible scheme
- Non relational data
- No complex data connections needed
- High-intensity work with data
- High throughput for IOPS (standard IOPS)
4 examples of what is optimal to choose under different conditions in the problem
Example 1: Library Management System
Imagine you're building a library management system where you need to keep track of books, authors, and library members, as well as checkouts, returns, and fines. In this case, it would be more appropriate to use a SQL database because:
Data Structure:
The data can be easily structured into tables for books, authors, library members, checkouts, returns, and fines, with relationships between them.
The books, authors, and library members can be represented in tables with columns for the relevant information. For example, the books table could have columns for the book's title, ISBN, author, and publication date.
Relationships between the tables can be established through foreign keys. For example, the books table could have a foreign key to the authors table, which would link each book to its author.
The checkouts, returns, and fines can also be represented in tables with columns for the relevant information. For example, the checkouts table could have columns for the library member, the book, and the checkout date.
Data Consistency and Accuracy:
Data consistency and accuracy are important, as the library needs to keep track of accurate information about its books, authors, and members, as well as the checkouts, returns, and fines. SQL databases provide ACID transactions to ensure that all updates to the database are either completed successfully or rolled back.
ACID transactions ensure that all updates to the database are either completed successfully or rolled back in the case of a failure. This means that the library management system can handle multiple requests to checkout the same book at the same time without any data loss or corruption.
Complex Queries:
SQL databases provide a rich query language, allowing the library management system to generate reports and analyze data. For example, the library management system can generate a report of all checkouts for a particular author in the past year using a query like:
SELECT books.title, checkouts.checkout_date FROM books JOIN checkouts ON books.book_id = checkouts.book_id WHERE books.author = "Jane Austen" AND checkouts.checkout_date >= DATE_SUB(NOW(), INTERVAL 1 YEAR)
Data Integrity:
Data integrity is crucial, and the system must enforce rules to ensure that each checkout is recorded against the correct book, and each fine is recorded against the correct library member. SQL databases have constraints and triggers that can enforce these rules.
Constraints and triggers can be used to enforce rules and ensure that data is entered correctly. For example, a constraint can be used to ensure that a library member cannot checkout more than 5 books at a time. A trigger can be used to automatically update the fines table whenever a checkout is returned late.
Moderate Volume of Writes and Reads:
The library management system must handle a moderate volume of writes and reads, and SQL databases are well-suited for handling this type of workload.
SQL databases are well-suited for handling a moderate volume of writes and reads. The library management system can handle multiple requests to check out and return books, as well as generating reports, without any performance issues.
In conclusion, in this scenario, a SQL database like MySQL or PostgreSQL would provide a robust, scalable, and flexible solution for the library management system.
Example 2: Social Media Application
Imagine you're building a social media application where users can post updates, comment on posts, and like posts. In this case, it would be more appropriate to use a NoSQL, let's expand on the example to see how a NoSQL database would work:
Data Structure:
The data for each user, post, comment, and like can be stored as separate documents. For example, the post document could contain the post text, the user who posted it, and the date and time it was posted. The comment document could contain the comment text, the user who made the comment, and the date and time it was made. The like document could contain the user who liked the post and the date and time they liked it.
The relationships between the posts, comments, and likes can be stored as references or embedded within the documents. For example, the post document could contain an array of references to the comments and likes associated with that post.
Data Consistency and Accuracy:
The NoSQL database can handle eventual consistency, meaning that the data may take some time to be updated across all nodes in the cluster. This is acceptable in a social media application, where real-time data consistency is not critical.
Complex Queries:
NoSQL databases may not have as rich a query language as SQL databases, but they are designed for fast data retrieval. For example, the social media application can retrieve all posts for a particular user with a query like:
db.posts.find({user: "Jane Doe"})
NoSQL databases can also use MapReduce for complex data analysis and processing.
Data Integrity:
NoSQL databases may not have the same level of data integrity enforcement as SQL databases, but they can still enforce data constraints through code and application logic. For example, the social media application can enforce a rule that a user cannot like their own post by checking the user ID in the like document before allowing it to be saved.
High Volume of Writes and Reads:
NoSQL databases are optimized for handling a high volume of writes and reads, making them a good choice for social media applications. The social media application can handle multiple updates, comments, and likes in real-time without any performance issues.
Scalability:
NoSQL databases are designed for horizontal scaling, allowing the application to add more nodes as needed to handle the increasing load. The social media application can handle an increasing number of users and posts without any performance degradation.
In conclusion, in this scenario, a NoSQL database like MongoDB, Cassandra, Redis, or Aerospike would provide a scalable, fast, and flexible solution for the social media application.
Example 3: Log Management System
Imagine you're building a log management system where you need to collect and process large volumes of log data from various sources. In this case, it would be more appropriate to use a NoSQL database because:
The data is unstructured and may change frequently, as new log sources are added or log data formats change. NoSQL databases have a flexible schema that can easily accommodate these changes.
The system needs to handle a large volume of writes, as log data is generated continuously. NoSQL databases are designed to handle high write loads.
The system must be scalable to accommodate growing log data volumes, and NoSQL databases can easily scale horizontally by adding more nodes to the cluster.
A log management system might use a NoSQL database like Apache Cassandra or Apache HBase, which are both designed for handling high write loads and have a flexible schema to accommodate changing log data formats.
Example 4: Banking System
Imagine you're building a banking system where you need to keep track of customer accounts, transactions, and loans. In this case, it would be more appropriate to use a SQL database because:
The data is easily structured into tables for customers, accounts, transactions, and loans, with relationships between them.
The data consistency and accuracy is important, as financial transactions must be recorded correctly. SQL databases provide ACID transactions to ensure that all updates to the database are either completed successfully or rolled back.
The system needs to support complex queries to generate reports or analyze data. For example, you may want to generate a report of all transactions for a particular customer in the past year.
Data integrity is crucial, and the system must enforce rules to ensure that each transaction is recorded against the correct customer account.
In this scenario, a SQL database like Oracle or PostgreSQL would be a good choice, as they are widely used and well-established for managing structured data with complex relationships.
In the next article I will tell you how to choose between different message brokers.
