Практика Continuous Deployment подразумевает полную автоматизацию поставки изменений в продакшн при публикации их в основной ветке репозитория. Она приводит к высокой частоте релизов, что означает, что их необходимо делать бесшовно, иначе они будут снижать доступность сервиса.
Бесшовные релизы - задача нетривиальная и требует осторожного соблюдения определённого подхода. Благо, он уже обкатан на привычных всем REST-API, но для контекста мы это рассмотрим подробнее. Далее мы рассмотрим применение этого подхода к релизам схемы БД с сопутствующим инструментарием и то, как это сказывается на процессах в организации.
Оглашённое требование осторожности в сочетании с человеческим фактором неизбежно приводит к сбоям, а потому этот фактор необходимо минимизировать. Минимизируют его, как правило, лишь двумя способами: автоматизацией процессов и реорганизацией системы с целью часть процессов исключить вовсе. В данной статье мы коснёмся обоих способов с акцентом на первом.
Основные идеи в этой статье опираются на принципы первичности БД относительно приложений. Если вы с этой темой не знакомы, ожидайте в статье серьёзной смены привычной парадигмы.
В качестве БД в примерах мы подразумеваем PostgreSQL, однако основные идеи статьи универсальны.
Бесшовные релизы на примере REST API
Представим себе систему, состоящую из трёх сервисов. Два из них пользуются третьим. Это означает, что обратно-несовместимые изменения в API третьего сервиса могут привести к поломкам в остальных двух.
Эта система уже находится в продакшн, и у нас возникла необходимость сделать релиз, который требует изменения API третьего сервиса. Как это сделать, не cломав ничего, и без необходимости одновременно выкатывать обновления для всех трёх сервисов с простоем?
Подход
Устоявшийся подход для таких ситуаций - делать релиз сервиса с поддержкой как старого, так и нового API с последующим постепенным переводом потребителей на новое API.
То есть, помимо ресурса /v1 со старым API у нас возникает ресурс /v2 с новым. При этом, старое API адаптирует обновлённый сервис под прежний функционал. Сделать такой релиз без простоев не составляет проблем.
Очевидно, что поддерживать таким образом различные версии обременительно и является сковывающим фактором для развития сервиса. Поэтому после такого релиза стартует этап пере��ода всех потребителей сервиса на новое API. Выпускать потребителей без простоя тоже не составляет проблем.
В итоге мы добираемся до стадии, когда все потребители /v1 исчезли и у нас возникает возможность снять данное обременение с нашего сервиса, удалив весь код, обеспечивающий данную версию API. Делаем очередное развёртывание сервиса с поддержкой только /v2 всё так же без простоев.
Для чего я это рассказал? Дело в том, что ничего в данной тактике не привязывает нас к непосредственно REST. Она универсальна и применима ко всему, что имеет интерфейс для взаимодействия. Далее мы рассмотрим применение неё для выпуска обновлений схемы БД.
Применяем к БД
Представим себе, что в уже развёрнутой в продакшн БД нам нужно переименовать одну из таблиц. Как осуществить релиз так, чтобы запущенные приложения не поломались, и без простоев как БД так и приложений?
Для этого точно так же потребуется разделить данную трансформацию на несколько релизов. Как вариант, можно сделать так:
Добавить в схеме поддержку таблицы с новым названием, создав проекцию на старую таблицу:
begin;
create view new_table as select * from old_table;
commit;Перевести все приложения на использование только нового названия таблицы.
Удалить проекцию и переименовать старую таблицу в новую:
begin;
drop view new_table;
alter table old_table rename to new_table;
commit;Как видите, по сути, мы осуществили те же самые действия, как и в случае с REST. На первом шаге мы добавили поддержку нового функционала, сохранив обратную совместимость с прежним. Далее перевели всех пользователей на использование только нового функционала. И потом избавились от функционала старого.
Для трансформации БД мы использовали миграции. Обновление продовой БД с помощью миграций можно автоматизировать, встроив в CI/CD-конвейер с помощью такого инструментария, как liquibase, flyway, sqitch. Это устоявшаяся практика и на эту тему вы найдёте множество статей, поэтому заострять на этом внимание не будем.
Самое сложное сокрыто во втором пункте. Для его реализации необходимо пройтись по всем запросам в приложениях и изменить названия. Если у нас лишь одно приложение и все запросы живут в изолированном слое и уже покрыты тестами, опирающимися на миграции, это может пройти гладко, но в остальных случаях нас ждут трудности и риски выхода в прод с поломанной интеграцией с БД.
Тестирование интеграции с БД
Итак, мы выявили необходимость плотно тестировать слой интеграции приложений с БД при обратно-несовместимых изменениях в её схеме.
Идеальный набор тестов позволит нам убедиться, что запросы:
исполняются без ошибок от БД
оперируют на ожидаемых приложением типах данных в параметрах и результатах
эффективно используют индексы
производят ожидаемые результаты по содержанию
приводят к ожидаемым изменениям в данных, если являются мутирующими
Звучит трудоёмко, поэтому, наверняка, на практике мы будем срезать углы. В общем-то и список этот отсортирован в соответствии с убывающей вероятностью реализации.
Критически важно - чтобы ошибок от БД не было и чтобы приложение не останавливалось из-за того, что, скажем, получает int4 там, где ожидает uuid. Отсутствие же ошибок для нас исключит самые вероятные причины для сбоев от опечаток до ссылок на несуществующие таблицы и колонки в запросах.
Отсутствие индекса часто можно пережить, так как, скорее всего, приложение, хоть и станет работать медленнее, но не остановится совсем, да и среагировать на это можно оперативно, если у вас настроен мониторинг.
Чтобы убедиться, что запросы ведут себя так, как мы ожидаем, нужны сложные тесты, требующие симуляции множества комплексных сценариев по принципу "если такая-то запись в БД имеет такое-то значение, то вызов данного запроса приведёт к таким-то последствиям". Они, несомненно, могут оказаться важны, но писать их кропотливо и они часто перекрываются функциональными тестами на уровне API приложения или компоненты.
Так вот, самые важные из перечисленных проверок возможно полностью автоматизировать без необходимости писать какие-либо тесты, и осуществлять эти проверки возможно за доли секунды.
Автоматизация проверок по подходу DB-first
Давайте задумаемся: какую минимальную информацию потребовалось бы передать коллеге, если бы мы хотели его попросить проверить SQL-запросы на корректность и совместимость со схемой БД? Ответ очевиден: нужны сами запросы и описание схемы БД. Раз этой информации достаточно для человека, то должно быть достаточно и для программы автоматизации данной задачи.
С помощью миграций возможно воссоздать БД с соответствующей структурой, а, имея под рукой все запросы, которые против неё планируется делать, возможно исполнить каждый и удостовериться в соответствии схеме, достать метаданные о параметрах и результатах и провести анализ с помощью запросов вроде EXPLAIN.
В итоге, полностью автоматически можно удостовериться, что запросы:
исполняются без ошибок от БД
оперируют на ожидаемых приложениями типах данных в параметрах и результатах
эффективно используют индексы
Отлично! Но теперь мы имеем дело с набором запросов, полностью отделённых от кода приложения. Встаёт вопрос: как это всё интегрировать и как выстраивать работу?
Генерация кода
Информации, получаемой из миграций и набора запросов, достаточно и для того, чтобы сгенерировать SDK, исполняющее данные запросы и транслирующее их в соответствующие типы параметров и результатов.
И вот лишь часть возможностей, которые с этим открываются:
SDK возможно генерировать для любого языка программирования, имеющего драйвер PostgreSQL. То есть, предоставляя файлы SQL, на выходе вы можете получить готовые интеграции для изобилия языков, которые могут применяться в вашей компании: от вездесущего Java до экзотичного Haskell.
Потенциально, работать с таким SDK должно быть значительно проще, чем с любым фреймворком, так как оно по определению заточено под домен вашей БД и не имеет задачи подходить к другим, а значит домен уже и сложности меньше.
По той же причине оно может принципиально сократить возможности стрелять себе в ногу для пользователей, оставляя возможными только сценарии использования, соответствующие домену.
Проблема Object-relational Impedance Mismatch самоустраняется, так как запросы один в один проецируются в методы или процедуры целевого языка, – ведь что такое запрос, если не параметризуемая процедура, возвращающая результаты?
Сгенерированный SDK мы подключаем как библиотеку в свой проект и впредь общаемся с БД из приложения через него. Изменения запросов осуществляем в коде запросов и перегенерируем SDK. Когда добавляем миграцию - тоже перегенерируем SDK. Никогда SDK сами не редактируем.
Таким образом, мы получаем чёткую границу между кодом БД и кодом приложения. SQL-запросы живут вместе с миграциями схемы, а не размешаны в коде приложения. Приложение же опирается на артефакты кодогенератора, который работает, опираясь на код SQL.
В итоге мы получаем следующий процесс поставки изменений.
Процесс поставки изменений по ролям
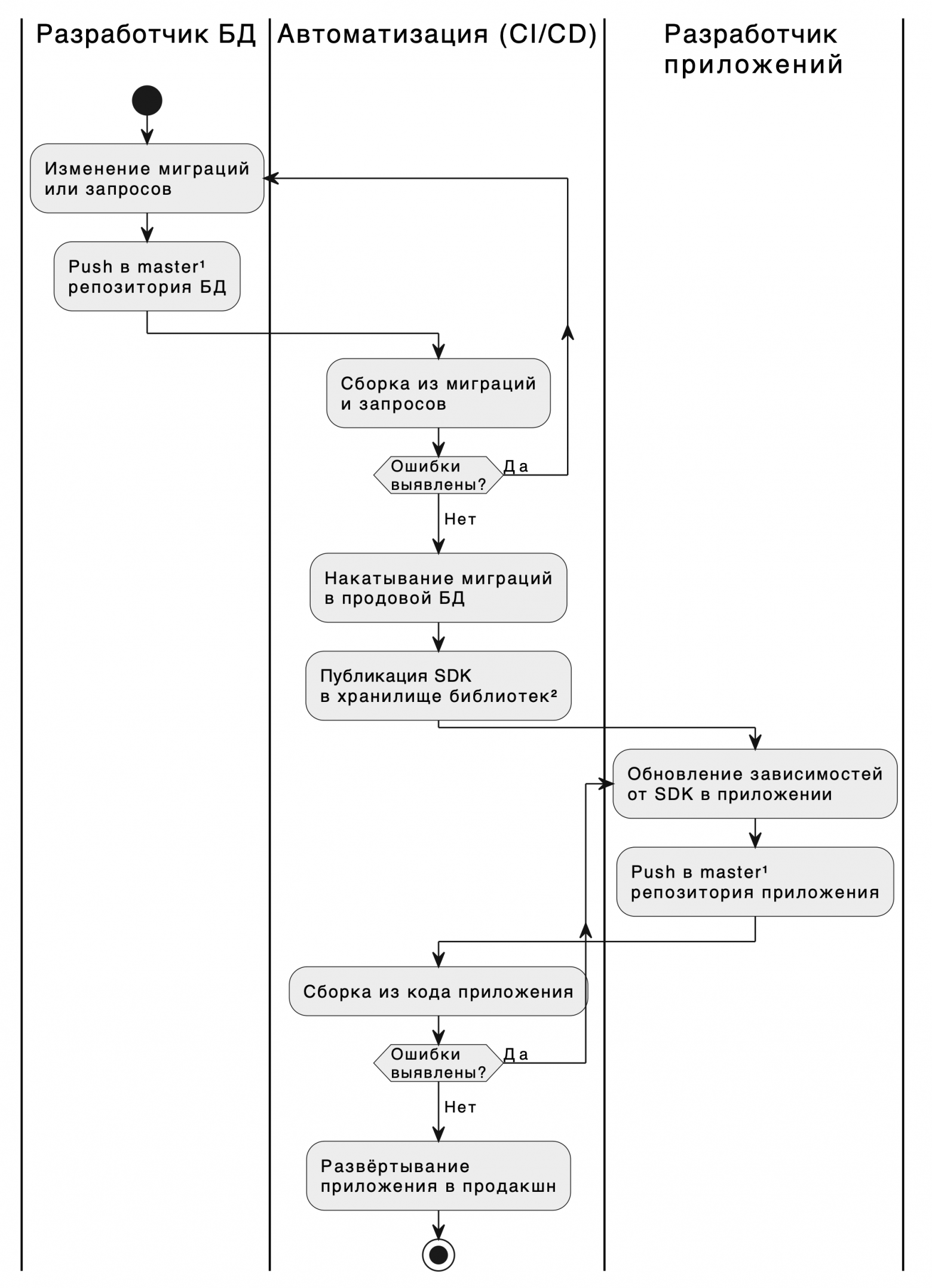
¹ Push в master - это процедура PR/MR со своими проверками на ревью и в CI, в случае успеха которых происходит влитие изменений в master. Это может быть и прямой push в эту ветку. Всё зависит от политик в организации.
² Хранилище библиотек - это Artifactory, Maven, NuGet, Hackage, S3, Git-репозиторий или что угодно, специфичное для вашего языка и организации.
На диаграмме выше видно чёткое выделение зоны ответственности за БД на процессном уровне. Также мы уже успели отметить, что на уровне кода это разделение тоже очевидно.
Конечно, обе роли разработчиков могут заполняться одними и теми же людьми. Однако, теперь у нас возникает возможность передать разработку БД в зону ответственности специалистов, которые разбираются в её тонкостях, а не поверхностно, как большинство разработчиков приложений. За счёт одного этого действия мы одновременно ускорим разработку и сократим частоту инцидентов, связанных с некорректным использованием БД. При этом, от специалистов БД не будет требоваться знание чего-либо о языке программирования, для которого будет генерироваться SDK.
Также обращаю внимание, что SDK может генерироваться для множества языков программирования приложений одновременно, что даёт возможность оптимизировать работу сразу для нескольких отделов, если они пользуются одной БД.
Предметно
До этого момента рассуждение в статье шло в гипотетическом пространстве "а что если бы мы работали по такому-то подходу и обладали необходимым инструментарием". Дело в том, что я представляю компанию dbfirst.ru, в которой такой инструментарий и разрабатывается. Теперь давайте рассмотрим предметное решение обсуждаемой проблемы с его помощью.
Примеры использования dbFirst для проверок в CI
В этой секции мы создадим проект и рассмотрим применение компилятора dbfirst для выявления ошибок в различных ситуациях и то, как эти проверки позволили бы нам построить надёжный CI/CD-пайплайн.
Создание проекта
Создадим новый репозиторий, в нём создадим конфигурационный файл проекта по пути ./project.dbfirst-v1.yaml со следующим содержанием:
# Неймспейс для ваших проектов
space: my-space
# Название данного проекта
name: music-catalogue
# Версия данного проекта
version: 1.0.0Также по пути ./migrations/1.sql создадим первую миграцию:
create table "artists" (
"id" int4 not null generated always as identity primary key,
"name" text not null,
"genre" text null
);И пару запросов:
./queries/insert-artist.sql:
insert into artists (name, genre)
values ($name, $genre)
returning id./queries/select-artist-by-id.sql:
select name, genre
from artist
where id = $idПрогоним компилятор dbfirst и посмотрим на результат:
> dbfirst
relation "artist" does not exist
Context:
queries/select-artist-by-idКомпилятор обнаружил ошибку в одном из запросов. Исправим запрос ./queries/select-artist-by-id.sql:
select name, genre
from artists
where id = $idПрогоним компилятор заново и посмотрим на результат:
> dbfirst
OkТаким образом мы увидели первую ценность: компилятор помогает избежать ошибок в процессе написания запросов.
Генерация кода
Дополним конфигурационный файл ./project.dbfirst-v1.yaml до следующего состояния:
space: my-space
name: music-catalogue
version: 1.0.0
# Какие SDK генерировать
artifacts:
- java-jdbc-v1
- haskell-hasql-v1И прогоним компилятор заново:
> dbfirst
OkВзглянем в возникшую папку artifacts и обнаружим в ней готовые SDK для Java и Haskell.
Для примера, вот так будет выглядеть один из сгенерированных методов в SDK для Java:
public InsertArtistResultRow insertArtist(Optional<String> genreParam, String nameParam) throws SQLException {
insertArtistStatement.setString(1, nameParam);
if (genreParam.isPresent()) {
String genreParamPresent = genreParam.get();
insertArtistStatement.setString(2, genreParamPresent);
} else {
insertArtistStatement.setNull(2, Types.VARCHAR);
}
insertArtistStatement.execute();
try (ResultSet resultSet = insertArtistStatement.getGeneratedKeys()) {
if (resultSet.next()) {
int idCol = resultSet.getInt(1);
return new InsertArtistResultRow(idCol);
} else {
throw new SQLException("Not a single row produced");
}
}
}Так для Haskell:
insertArtist :: Statement Model.InsertArtistParams Model.InsertArtistResultRow
insertArtist =
Statement sql encoder decoder True
where
sql =
"insert into artists (name, genre)\n\
\values ($1, $2)\n\
\returning id"
encoder =
(Model.insertArtistParamsName >$< (Encoders.param (Encoders.nonNullable Encoders.text))) <> (Model.insertArtistParamsGenre >$< (Encoders.param (Encoders.nullable Encoders.text)))
decoder =
Decoders.singleRow $
Model.InsertArtistResultRow <$> (Decoders.column (Decoders.nonNullable Decoders.int4))Проверка, что изменения миграций не ломают существующих клиентов
Представим, что мы назвали таблицу artists по ошибке, и теперь хотим переименовать её в artist, но БД уже в продакшн, и нам нужен бесшовный релиз. Та самая ситуация, которую мы уже описывали выше.
Представим, что произойдёт, если мы станем решать эту проблему в лоб, просто переименовав таблицу. Добавим следующую миграцию в файле ./migrations/2.sql:
alter table artists rename to artist;Запустим компилятор:
> dbfirst
relation "artists" does not exist
Context:
queries/insert-artistИными словами, компилятор нам сообщает, что мы нарушили контракт, ожидаемый запросами, и, как следствие, прежде сгенерированными SDK. Соответственно, помимо помощи при разработке, это нам открывает возможность удостоверяться при Continuous Deployment, что мы не поломаем клиентов, перед накатыванием миграции в прод.
Исправим миграцию ./migrations/2.sql на:
create view artist as select * from artists;И прогоним компилятор:
> dbfirst
OkПредставим, что на этом месте наш CD накатил миграцию.
Далее обновим клиентов. Для этого изменим запросы:
./queries/insert-artist.sql:
insert into artist (name, genre)
values ($name, $genre)
returning id./queries/select-artist-by-id.sql:
select name, genre
from artist
where id = $idИ прогоним компилятор:
> dbfirst
OkНа данном месте CD опубликовал наши SDK, и мы получили возможность уйти обновлять приложения-клиенты. По завершении этой процедуры подчищаем в БД:
./migrations/3.sql:
begin;
drop view artist;
alter table artists rename to artist;
commit;Слушаем компилятор:
> dbfirst
OkИ тут происходит очередное автоматическое накатывание схемы.
Проверка типов
Если вы обратили внимание, в сгенерированном коде типы данных параметров и результатов были выведены автоматически. На вход мы лишь предоставили миграции и нетипизированные запросы. С одной стороны, это удобно. С другой, это означает, что компилятор нам не сможет помочь определить изменение типов в схеме. Рассмотрим эту проблему предметно и найдём решение ей.
Добавим очередную намеренно инвазивную миграцию, меняющую тип колонки genre с text на int8:
./migrations/4.sql:
begin;
alter table artist
drop column genre;
alter table artist
add column genre int8;
commit;Прогоняем компилятор и видим:
> dbfirst
OkНо для нас это совсем не ОК. Если мы выкатим такую миграцию в прод, все запущенные клиенты начнут выдавать ошибки при попытке исполнить запрос insert-artist, так как в колонку genre они будут подставлять текстовое значение, когда БД будет ожидать int8. Аналогичные проблемы нас ждут и с результатом запроса select-artist-by-id.
Как заставить компилятор определять и такие ошибки?
Явные сигнатуры
Способ, который работает уже сейчас - самим жёстко фиксировать типы данных параметров и результатов в запросах.
Например, если бы наш запрос ./queries/insert-artist.sql выглядел следующим образом:
insert into artist (name, genre)
values ($name :: text, $genre :: text)
returning id :: int8то компилятор выдал бы нам следующую ошибку:
column "genre" is of type integer but expression is of type text
Context:
queries/insert-artistОднако, из-за наличия неявных конвертаций в Postgres строгость таких проверок не абсолютная. Например, если бы мы написали id :: int2 вместо id :: int8, компилятор бы не заметил в этом проблем. Стоит заметить, правда, что и приложение бы не выдавало ошибок в рантайме, так что поставленная задача решается. Однако, это стоит учитывать, так как подобные конвертации могут привести к обрезанию значений.
Ещё один нюанс: компилятор не может принудить указывать сигнатуры, а потому указываем мы их или нет, остаётся на откуп дисциплине.
Генерация контракта
Мы рассматриваем возможность разработки функционала генерации файлов контракта, в котором бы хранилась информация о сигнатурах запросов с учётом nullability и, возможно, дополнительная мета-информация о проекте. Подразумевается, что это позволило бы проводить строгие проверки проекта на соответствие ожидаемому контракту, который, в частности, можно было бы использовать в CI/CD.
Если у вас есть мнение или идеи на этот счёт, прошу высказаться в комментариях.
Проверка производительности
Этот функционал пока находится в планах. Задумывается прогонять на все запросы с выборками explain и выявлять seq-scan. Также, на будущее мы прорабатываем возможность заполнения таблиц генерируемыми данными для более сложного анализа производительности.
Если у вас есть идеи на этот счёт, тоже призываю вас к обсуждению в комментариях.
Проверка совместимости на старте и readiness-пробы
Этот функционал тоже находится в планах. Задумывается встраивать в SDK процедуру, которая будет осуществлять проверку БД на совместимость, а именно, на соответствие ожиданиям всех запросов в SDK.
Такую проверку можно будет осуществлять на стадии инициализации приложения и блокировать направление на него трафика, если проверка не проходит, например, встроив её в readiness-пробу для Kubernetes, если вы пользуетесь им, или для его аналога. Если не пользуетесь, то такая проверка, как минимум, позволит вам быть оповещённым о грядущих проблемах на самых ранних стадиях.
Также эту проверку можно осуществлять и когда приложение уже принимает трафик, чтобы защититься от неожиданных изменений схемы в процессе работы приложения.
Пожалуйста, тоже оцените важность такой доработки в комментариях.
Развитый процесс поставки изменений
В завершение, взглянем на то, до чего можно было бы развить наш конвейер CI/CD с использованием инструментария dbFirst. Это пример, задача которого подсветить огромные возможности и гибкость в автоматизации процессов и повышения надёжности вашей системы.
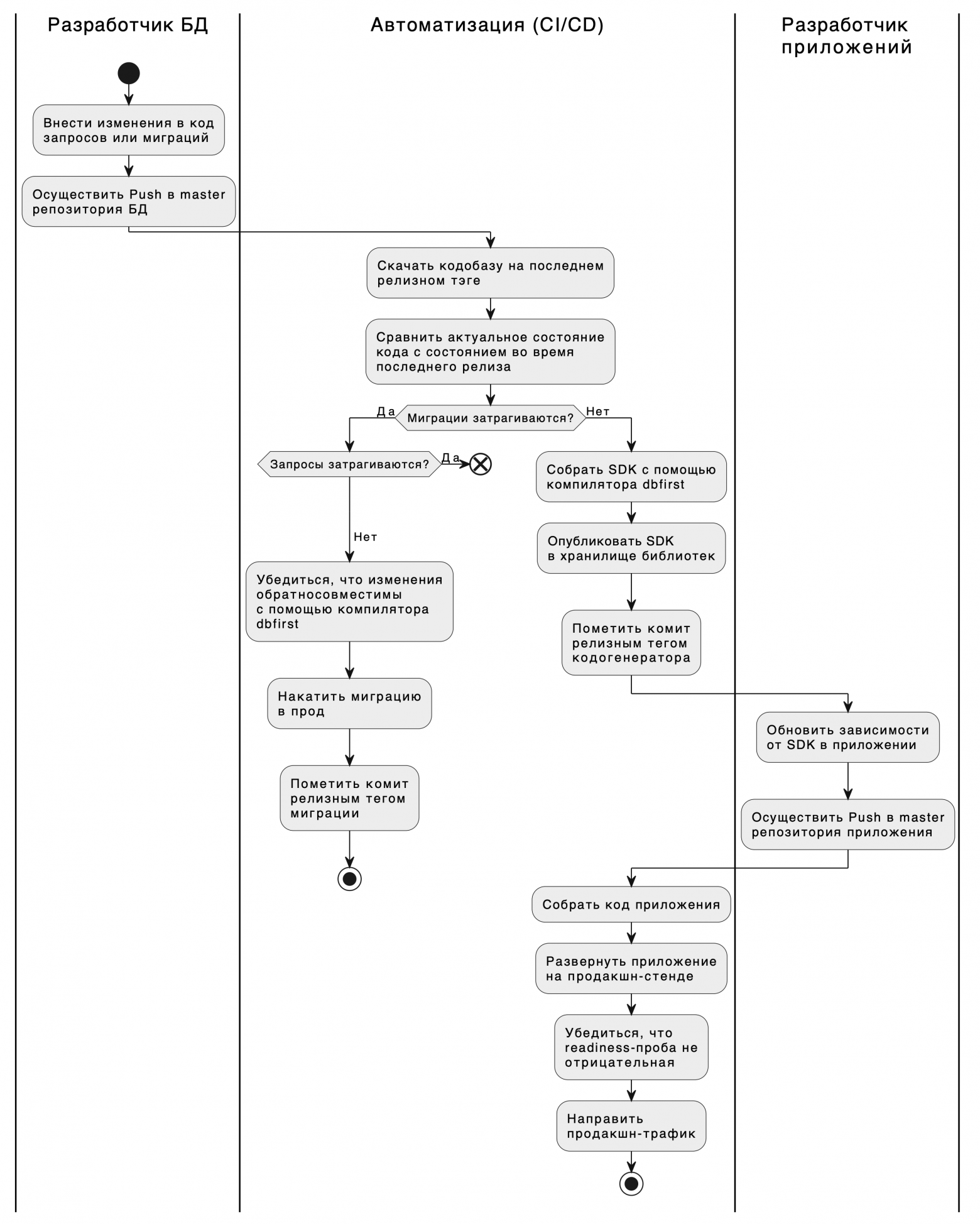
О dbfirst
Описанным инструментарием вы можете начать пользоваться уже сейчас. Для этого заходите на dbfirst.ru.
Также мы оказываем консалтинг-услуги по разработке слоя интеграции с БД и внедрению подхода DB-First в компании. Если в вашей компании несколько сервисов взаимодействует с одной БД, мы можем кардинально ускорить вашу разработку.
Для прямой связи со мной пишите в Telegram: @wormholio.
