Comments 30
А потом из сисек получается тройка. Понятно.
Где-то я похожее читал... А, вспомнил: книга Дж.Хокинса "Об интеллекте". Там еще много чего другого, например, многослойные структуры кортикальных колонок. Рекомендую
Однако человек запомнив, например, цифру 3 на примере одного из ее изображений, способен распознавать тройки самых разных форм, размеров и ориентаций. Причем распознавать быстро и безошибочно
Что-то у меня есть какие-то сомнения в этом тезисе. Попробуйте научить ребёнка 3-4 лет опозновать цифру 3, ему не раз и не два надо будет показать и повторить, прежде чем он запомнит и начнёт их узнавать.
Этот механизм, по-видимому, работает в первые месяцы и годы жизни ребёнка, когда он только учится познавать мир (и учится, конечно, не на цифрах, а на окружающих предметах - лица родителей, кровать, игрушки и т.д.). Со временем в зрительной коре запечатлеваются не только пятна и контуры, но и более сложные образы, так что мозг приобретает способность узнавать предмет с одного взгляда, не нуждаясь в необходимости обводить его глазами по контуру.
Сложность в том, что в мозге нет свёрточных нейронных сетей, поэтому для развития навыка беглого взгляда мозг должен запомнить, как выглядит предмет, не только в центральном, но и в околоцентральных положениях в поле зрения.
Возможно у детей в таком возрасте дефицит внимания, им сложно сосредоточиться на чем то одном, поэтому при запоминании им приходится несколько раз показывать одну и ту же цифру, при распознавании мозг ребенка может все распознал правильно, но ребенок увидел конфету и уже переключился на неё.
Возможно у детей в таком возрасте дефицит внимания, им сложно сосредоточиться на чем то одном, поэтому при запоминании им приходится несколько раз показывать одну и ту же цифру, да и при распознавании мозг ребенка может все распознал правильно, но ребенок увидел конфету и уже переключился на неё.
Если для запоминания тройки нужно скользить по ней глазами, то как запоминаются более сложные узоры, геометрические фигуры, рисунки, картины?
Поэтому сомневаюсь, что описанный процесс работает.
Насколько я понял, в статье предлагается растровое изображение преобразовывать в векторное. При этом сама же нейросеть будет искать векторы в исходном растровом изображении, преобразовывать их в относительные перемещения, и распознавать ломаную из таких относительных перемещений. В принципе, вполне себе вариант. Такой подход будет мало чувствителен к повороту, однако будет чувствителен к масштабу. Но даже здесь можно нормализовать длины векторов. Проблема будет с большими сложными изображениями: пока нейросеть все векторы отсканирует - много времени пройдёт. Это - беда всех векторных представлений: они слишком много ресурсов требуют на сложных объектах.
Однако такой подход может быть вполне применим как раз для распознавания текста, как и предложено в статье.
Вообще-то, глядя на картинку в аннотации статьи, я ожидал, что статья будет о "координациях", которые биолог Конрад Лоренц определил как врождённые последовательности действий. Например, есть координация плавания у рыб, координация броска на добычу у хищников. Эта последовательность действий поддаётся регуляции: например, может начинаться не сначала, и заканчиваться преждевременно. Две координации, в зависимости от внешнего стимула, могут плавно переходить друг в друга: то есть при слабом стимуле животное двигается одним способом, при сильном - другим, а при промежуточном - комбинированным способом.
Я предполагал что такая система не будет чувствительной к повороту контура и его масштабу, потому что в ней нет как такового понятия геометрии контура – система лишь получает сигнал обратной связи от глаза как подтверждение того, что процесс в ней развивается правильно. Но сама геометрия сети, то есть направление распространения нервных импульсов в ней и геометрия контура могут отличаться. По поводу больших и сложных изображений, в этой модели небольшие сети параллельно распознают каждая свою, малую часть сложного объекта, которая в них записана и за счёт параллельности работы таких сетей компенсируется затрата времени при распознавании сложного изображения. Спасибо за ссылку на статью про "координации", почитаю. На картинке в аннотации я имел ввиду что любое действие животного это проигрывание того, что записано в таких микро сетях.
А кто-то пробовал современные мультимодальные LLM протестировать на способность опознавать не виданные ранее образы, просто увидев пример один раз ?
Автор упускает из виду тот факт, что мозг человека постоянно обучается с самого рождения. Мы постоянно получаем огромное количество визуальной информации, которая обрабатывается и систематизируется мозгом. Этот непрерывный процесс обучения формирует основу для распознавания новых образов в дальнейшем. Даже если мы видим цифру 3 впервые, наш мозг уже имеет огромный багаж знаний о линиях, изгибах, формах и других базовых элементах, из которых состоят изображения.
Процесс "запоминания" образа, описанный в статье, кажется чрезмерно упрощённым. Автор предполагает, что глаз двигается вдоль контура, и это движение напрямую кодируется в нейронной сети. Но как быть с более сложными образами, которые не сводятся к простому контуру? Как быть с объектами, которые мы видим под разными углами? Мозг не просто запоминает контур, он формирует многомерное представление объекта, учитывая его форму, цвет, текстуру, контекст и множество других факторов.
Что касается вопроса о мультимодальных LLM. Возможно, такие тесты уже проводились, и было бы интересно узнать их результаты. Однако, я сомневаюсь, что современные LLM смогут полностью повторить способности человеческого мозга в этой области. Потому что с рождения человека его мозг находится в непрерывном процессе обучения, получая информацию из всех доступных источников: зрение, слух, осязание, вкус, обоняние. Этот колоссальный по своим объёмам поток данных формирует основу для невероятно сложной и гибкой системы распознавания образов. LLM, даже самые продвинутые, пока что оперируют с наборами данных, которые являются лишь бледной тенью того, что переживает человек на протяжении своей жизни.
Поэтому для будущих мультимодальных систем надо будет собирать намного больше данных, и, что более важно, эти данные должны быть непрерывными, многоаспектными и контекстуально богатыми. Носимые устройства, такие как очки дополненной реальности, могут стать ключом к решению этой проблемы.
Мне кажется что запоминание и распознавание сложных объектов как процесс состоит из более простых элементов. В статье описаны как раз эти простые элементы – запоминание и распознавание контуров объектов. Возможно что я ошибаюсь, но мне кажется, что в мозге нет сложной обработки данных в нашем обычном понимании, нет сложной координации процессов (ведь тогда для каждого сложного процесса в мозге понадобится физически создавать свой отдельный координатор – а сложных процессов, неограниченное количество). К тому же при сложной обработке одна нейронная сеть должна передавать в другие нейронные сети структурированную информацию, а нейронных сетях-получателях эта информация должна обрабатываться и передаваться дальше. Все это требует синхронизации, дополнительных “проводов” и затрат энергии в мозге. В предложенной модели мозг это более простая и однородная конструкция – маленькие нейронные сети работают параллельно и независимо, сложный распознаваемых образ это их общая одновременная активность. Про мультимодальные LLM, спасибо, почитаю.
Какого размера должны быть тройка или как близко к лицу, что приходится двигать глазом?
Скорее уж глаз остановится в двух точках - центр полуокружностей тройки, а водить глазами по всей форме человеку надо только при записи этой цифры вручную.
Возможно, что человек не может отследить сознательно, как движется глаз, когда он смотрит на образ цифры, но у каждого процесса есть своя динамика. Нам кажется что мы посмотрели на образ и сразу его распознали, но на самом деле это ведь некий процесс, который как-то начинается, происходит, развивается. В этой модели предполагается, что небольшая нейронная сеть управляет глазом так, что он движется по контуру, ведь контур цифры 3 может быть самой разной формы, перевернутым, растянутым, с помехами и т.д. Но тем не менее мозг способен к обобщению, способен распознать внешне разные контуры как цифру 3.
Рисунок 1 КАЧЕСТВЕННО некорректный - аксоны НЕ ветвятся. Не знаю, откуда взят рисунок, но этот источник явно не шарит в биологии человека даже на базовом уровне.
По сути "метод", описанный в статье - это обобщённое описание принципа работы сверточной нейросети. То есть от чего пытались уйти:
Здесь что то не так. Рассмотрим другой подход.
К тому и вернулись...
Пример с цифрой, возможно, можно описать с помощью механизма саккад, но только такие узкие частные случаи и получится. Образы объекта в реальности далеко не всегда имеют четкие контуры, распознаются по контурам и т.д. В общем здесь просто описан ЧАСТНЫЙ случай ЧАСТНОГО случая, не более.
Саккад за "единицу времени" происходит на много порядков меньше, чем потребовалось бы, чтобы таким способом описать всё, что человек видит даже на одной статической "картинке".
Резюмируя: статья во многом некорректная и неверная, однако, сам посыл хороший и правильный - действительно, мозг в реальности очень быстро "учится" распознавать и отличать одни объекты от других в самых разных видах, ситуациях, освещении и т.д. Значит, принципы "распознавания" кардинально и качественно иные, нежели описанные в статье и существующие методы в области ИИ.
Гипотеза: возможно, стоит попробовать применить подход, схожий с тем, что применяется в генеративных визуальных моделях - диффузионный метод, в котором картинка создаётся не попиксельно, а совокупностью образов?
То есть, возможно, мозг "видит" перед собой сразу что-то вроде "нагромождения" множества образов (вот тут для их "разделения", вполне может быть, что во внутренних системах мозга где-то и применяется какое-то подобие алгоритмов поиска контуров объектов, однако, явно количества саккад не достаточно для такого объема, возможно, при этом идёт огромное количество параллельных процессов?), которые он "узнаёт" перед собой и далее фиксирует в своих нейросетях?..
Картинка с соединенными нейронами, конечно, условная. В статье описан, с моей точки зрения, не частный случай, а то как может работать такая система на нижнем уровне, на уровне запоминания и распознавания контуров. Нечеткий контур это все же контур и, возможно, такая система сможет его распознать, используя свою инерцию и обобщая детали. Спасибо про замечание о саккадах. Я предполагал направлением движения глаза управляет нейронная сеть и саккады это лишь дополнительный механизм на одном из этапов запоминания. Про множество образов и параллельные процессы – да, я имел в виду, что, возможно, такие небольшие сети работают параллельно и на нижнем уровне распознают записанные в них контуры, то есть основное управление глазом идет от микро сети, а не от саккад. Саккады лишь вносят небольшой элемент случайности при поиске в сети, когда она запоминает контур. Про диффузионный метод, спасибо, почитаю.
Мда, глупая человечешка пытается понять, как работает компьютер, разобрав его на винтики и выковыривая микросхемы и конденсаторы из материнской платы:
-не понимаю, где тут буквы и картинки, откуда звук, ведь нету рта...
Скорее всего мозг сперва учится узнавать и запоминать точки, линии, светло или темно. Потом прямые, кривые, закорючки, кружочки, цвета и т.д. Т.е. сперва простейшие элементы, потом сложнее. Далее, уже эти закорючки соединять в более сложные сочетания. Цифра 3 запоминается не сама по себе, а как сочетание неких простейших элементов. От слоя нейронных сетей к слою повышается абстракция. И уже потом, мы можем найти цифру 3 в расположениях домов, деревьев, звёзд и т.д.
Во многих системах при обучении распознаванию образов загружается большое количество различных изображений этого образа. Однако человек запомнив, например, цифру 3 на примере одного из ее изображений, способен распознавать тройки самых разных форм, размеров и ориентаций. Причем распознавать быстро и безошибочно. Как такое возможно?
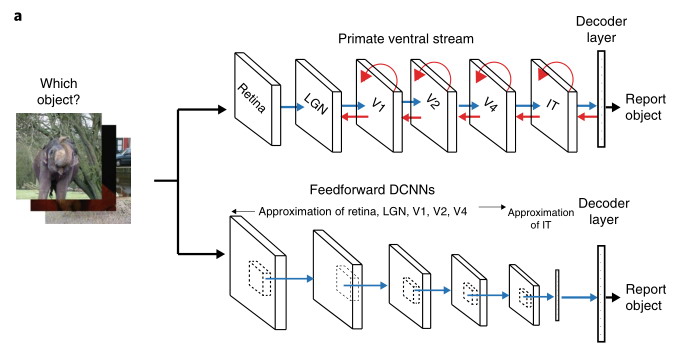
А это, кстати, не так уж трудно понять исходя из МО. ИНС неплохо моделируют процессы в мозге, в частности, сверточные сети вентральный тракт зрительной системы приматов, т.к. прототипами ИНС были именно биологические нейроны и сети мозга. Достаточно понять, что происходит при обучении CNN. Для этого нужно посмотреть на зависимость показателей эффективности обучения от показателей их объема. Обычно вычисляется процент успеха тренинга от числа итераций обучения с заданным числом выборок (batch). В этом исследовании приводятся такие графики для разных батчей и обучающих наборов. Видно, что показатель успеха вначале довольно быстро нарастает, кумулятивно, особенно для больших значений батчей, но в дальнейшем рост резко замедляется. С чем связано такое поведение? Видимо с интеграцией в слоях сети общих признаков обучающих выборок (изображений), которые облегчают дальнейшее обучение, но все меньше содержат новизну. В нижележащих слоях накапливаются общие геометрические примитивы - различные линии, края, и тд, выше углы, контуры, еще выше общие части объектов. То же самое происходит в зрительном тракте человека только намного более эффективно, т.к. многие подобные признаки у человека носят априорный характер, они имеются уже у новорожденных. Зрительную систему не нужно тренировать специально, чтобы они появились, например, для выделения краев, линий, углов, и даже более сложных признаков, например, контуров лица. Эти факты установленные в различных психофизиологических исследованиях. Младенцы и детеныши животных реагируют на них сразу же после появления на свет. Если бы это было не так, и они уже не были готовы реагировать на различные критические ситуации, привлекая родителей, то могли быстро погибнуть. К таким общим комплексным признакам относится, в частности, нативная приближенная оценка численности объектов, см. обсуждение этого вопроса в этой ветке коментов.
{kind=link}
{kind=link}
{kind=link}
Мозг с рождения имеет сложную структуру частично уже настроенную на восприятие, которая развивается с возрастом по мере приобретения опыта. Это не обучение с "чистого листа", как иногда полагают разработчики ИИ, исходя из опыта собственной работы по программированию ИНС, затем проецируя его на структуру и функции мозга. Нечто похожее предлагается в статье. Это может больше подходить для разработки проекта бионического зрения, но не объяснения процессов в мозге человека. По нейрофизиологии зрительной системы почитайте книгу одного из классиков исследований в этой области Д. Хьюбела: Глаз, мозг, зрение.
{kind=link}
Да, в статье как раз попытка разобраться, как можно избежать использования большого количества изображений объектов при обучении. Если зрительная система способна распознавать какие то объекты с рождения, то распознавание ведь это все равно физический процесс в мозге. Допустим, при рождении в мозге уже есть микро сеть, которая распознает вертикальную линию. Но вертикальные линии могут быть под разными углами и так далее. То есть распознавание разных вариантов ориентации таких линий может идти по алгоритму, описанному в статье, просто исходная микро сеть появилась не в результате обучения данного организма, а уже есть с рождения. Новые же микро сети появятся при обучении распознаванию других объектов в процессе жизни организма.
Про сложность мозга, пока мне кажется, что мозг на нижнем, физическом уровне работает однообразно и параллельно. Вряд ли в мозге для распознавания разных объектов создаются отдельные, специализированные структуры.
Спасибо за Ваши замечания и ссылки на литературу, обязательно почитаю.
Да, в статье как раз попытка разобраться, как можно избежать использования большого количества изображений объектов при обучении.
В том и дело, что приведенная схема не совсем соответствует организации и функциям мозга. Фактически для каждого объекта и его составных частей должна формироваться своя подсеть в общей сети мозга. Но мозг так не устроен. У него генетически предопределенная иерархическая структура и деление на отделы, включая визуальной системы, которая оптимизирует и сам процесс обучения и его результаты в соответствии с эволюционно выработанной биологической целесообразностью. В вашей схеме, как понял, обучение каждый раз будет происходить заново для каждого объекта и нарастать линейно потребляя большое количество памяти, а это ограниченный ресурс.
Допустим, при рождении в мозге уже есть микро сеть, которая распознает вертикальную линию. Но вертикальные линии могут быть под разными углами и так далее.
Поизучайте как устроены устроены простые, сложные и сверхсложные рецептивные поля, миниколонки коры, и тд, в книге ссылку на которую давал. Выделение признаков начинается уже в сетчатке глаз.
Про сложность мозга, пока мне кажется, что мозг на нижнем, физическом уровне работает однообразно и параллельно. Вряд ли в мозге для распознавания разных объектов создаются отдельные, специализированные структуры.
Что подразумевается под физическим уровнем? Клеточный? Все весьма разнообразно. Одних только нейронов многие десятки видов, зависит как классифицировать, и открывают новые. С точки зрения инженерного подхода кажется запутанным и чрезмерно избыточным. Однако стандартная упрощенная модель формального нейрона, как взвешенного по входам сумматора с функцией активации, не всегда адекватно описывает функционал биологических нейронов и сетей. Например, функционал распространенного пиромидального нейрона лучше описывается целой 5-8 слойной сетью из формальных нейронов. Это, кстати, может объяснить почему глубокие сверточные сети из многих десятков слоев и даже сотен, как у Гугленета, распознают эффективнее, нежели с несколькими слоями, см. этот комент.
Вообще написанное сильно напоминает, что предлагает Д. Хокинс. Не читали его работы (1, 2)? Однако он оговаривает свой инженерный подход к пониманию обучения, поведения и интеллекта, и использует миниколонки для проектирования ИИ в его понимании. Т.е. не делает акцент на объяснение функций мозга, а у вас в заключении
Можно ли применить микроплееры не только для распознавания образов, но и для объяснения работы мозга в целом?
Возможно да.
На Хабре такое может пройти и вызывать одобрение - накинул карму за интерес к теме, но специалисты вряд ли оценят)
Там не совсем линейное потребление памяти – если для простого объекта, скажем контура, элемента сложного объекта или похожего на него объекта в мозге уже есть микро сеть для него, то она и запустится, заново обучать другую микро сеть не нужно. Обучать новую микро сеть нужно только если человек видит какой то новый элемент объекта, для которого в мозге ещё нет микро сети. К тому же нейронов в мозге человека миллиарды, возможно хватит для параллельной работы таких маленьких сетей. Да, конечно, у меня к этой проблеме еще и инженерно-алгоритмический подход. Мозг человека и осьминога отличаются, но оба могут решают задачи распознавания. Возможно, здесь важна не только анатомия мозга, но и алгоритмы его работы.
Применение данного подхода к работе самого мозга я сейчас прорабатываю, для меня это очень интересная тема. Возможно подготовлю отдельную статью. Текущую статью я посылал и делал презентацию на European Conference on Computer Vision (ECCV-25) in London, UK, которая проходила в январе, потом опубликовал здесь, на Хабре.
Еще раз большое Вам спасибо за комментарии и ссылки на литературу.
Еще вспомнил в стране подобными исследованиями с инженерным подходом занимался Соколов Е. Н., см. там список литературы. Очень интересно писал по этим темам, там есть статья про саккады.
Удачи в поисках!
Распознавание образов в мозге с помощью микроплееров