Ранее мы уже рассказывали о дата-центре фотосервиса imgix, описывали детективную историю поиска проблем с SSD-дисками проекта Algolia, а сегодня представляем вашему вниманию обсуждение того, как команда стримингового сервиса SoundCloud перешла на использование микросервисов.

/ фото Jonathan Gross CC
В последнее время микросервисы стали настоящим хитом, но компания осуществила переезд не из технических соображений, а из соображений продуктивности. С одним из рабочих проектов, который представлял из себя монолитное приложение на Ruby on Rails, одностраничное JavaScript веб-приложение и клиента к публичному API, работали сразу две команды.
Они были изолированы друг от друга и даже работали в разных зданиях. Процесс разработки был основан на описании идей, мокапах, создании макетов, кода и выкладке проекта после недолгого тестирования. В итоге инженеры и дизайнеры жаловались на перегрузку, при этом продакт-менеджеры и партнеры жаловались, что ничего никогда не делается вовремя.
На данном этапе развития проекта было критически важно объявить о партнерстве с рядом заметных компаний, но для этого нужно было запустить закрытое бета-тестирование. Как раз в это время команда и решила разобраться в том, куда их завел процесс органического роста компании.
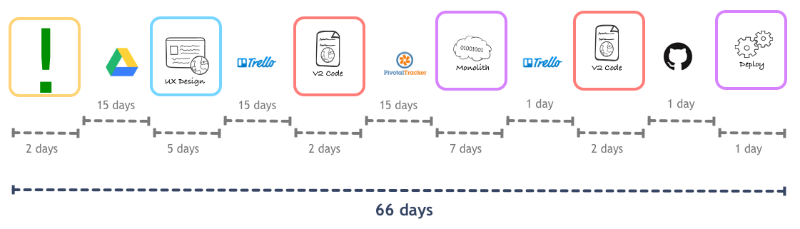
Для этого была использована карта потока ценности (Value Stream Map), которая помогла визуализировать реальное положение дел в рамках процесса разработки. Выяснилось, что было задействовано множество сторонних сервисов и итераций. Например, спецификация публиковалась в Drive, карточки – на доске в Trello, изменения кода – в Pivotal Tracker и так далее. В итоге общее время реализации увеличивалось еще и за счет того, что вторая команда обычно ждала, пока накопятся изменения в бранче, и уже потом «накатывала» их в продакшен.
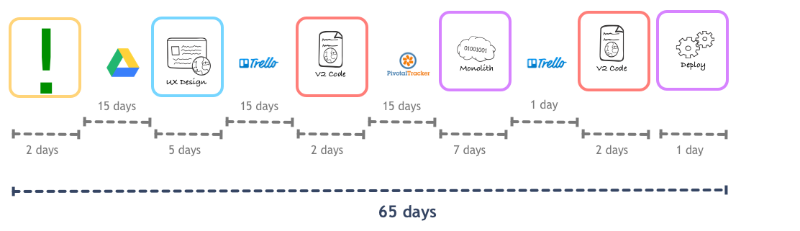
В общем, чтобы новая фича оказалась реализованной, требовалось не меньше двух месяцев. Для решения проблемы команда решила адаптировать технику поезда релизов (release train). Вместо того, чтобы ждать, пока накопится несколько новых фич, можно просто развертывать их по мере готовности каждый день. Во всей этой схеме главной бедой был пинг-понг между двумя командами фронтенд и бэкенд-разработки – 47 дней, потраченных на «инженерию», и 11 дней – на разработку. Остальное время вообще уходило впустую на бессмысленное ожидание.
Эксперимент с парной разработкой фичи силами бэкенд и фронтенд-разработчиков привел к тому, что каждый отдельный сотрудник стал тратить больше времени на работу по конкретной функции. При этом сохранялся процесс обязательного ревью кода (pull request), прежде чем код мог попасть в мастер-ветку нашего Rails-приложения.
Далее дизайнер, менеджер по продукту и фронтенд-разработчики стали работать вместе, и цикл разработки удалось еще немного сократить. Все это позволило команде осуществить первый релиз Next сильно раньше дедлайна.
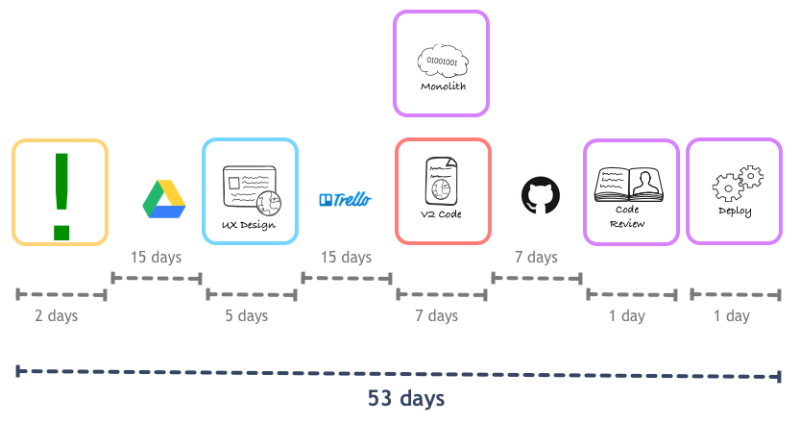
Создание пар из сотрудников разных специальностей, что привело к структуре «команд фич» (feature team), которая используется в SoundCloud и сегодня. Далее в процессе работы над монолитом на Ruby on Rails команда столкнулась с вопросами относительно практик ревью кода. Было решено применить аналогичный подход – требование просмотра кода вторым инженером, а при парном программировании такое ревью осуществлялось в режиме реального времени.
Эксперимент с несколькими парами выявил проблемы, которые заставили начинать все с начала. База кода монолита была столь обширна и охватывала столь различные аспекты, что никто не мог во всем этом ориентироваться. В компании даже родился мем «все всегда хорошо, пока не понадобится лезть в монолит».
В итоге пришло пересмотреть очень многое. Бэкенд-система была черным ящиком, который нужно было открыть. На выходе получился не монолит, а платформа с множеством компонентов. У каждого из них свои владельцы и свой независимый жизненный цикл. Кроме того, для разных модулей ожидание уровня сервиса также различалось.
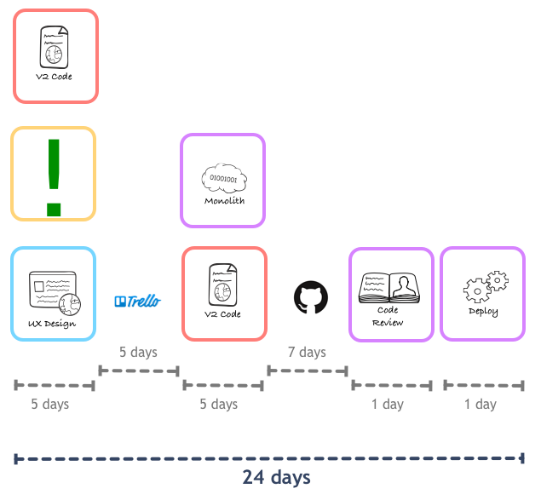
Таким образом, на уровне кода нужно было убедиться в том, что внесение изменений в конкретную функцию можно проводить в относительной изоляции, без необходимости трогать код других компонентов. А с точки зрения развертывания понадобилось убедиться в возможности изолированного развертывания фичи, что вело бы создании группы серверов ответственной только за одну фичу.
Решено было пойти другим путем и построить все, что нужно для проекта по монетизации, в качестве сервисов, изолированных от монолита. Проект включал масштабные обновления и полное переосмысление модели подписки, но удалось его закончить раньше сроков двумя командами по два инженера в каждой. Опыт был признан удачным, и этот подход применили для всех новых разработок.
Новый архитектурный фреймворк позволил сократить время на создание новых функций до, пусть не идеальных, но уже куда более приемлемых для компании величин, позволявших не отставать от конкурентов на сложном музыкальном рынке.
За главные объекты все еще отвечает одна команда, но теперь архитектура более стабильна, что снижает число «пожаров». В итоге даже эти сотрудники могут выделить время для перехода на микросервисы.
На сегодняшний день у SoundCloud все равно есть монолитный код, но его важность снижается с каждым днем. Он все еще критичен для многих функций, но теперь он даже не работает напрямую с интернетом (благодаря специальной системе). Возможно, полностью он не исчезнет никогда — многие функции столь малы и стабильны, что может быть дешевле оставить все как есть, но уже через год ничего реально важного там не останется.
P.S. Еще немного о том, как мы улучшаем работу провайдера виртуальной инфраструктуры 1cloud:
/ фото Jonathan Gross CC
В последнее время микросервисы стали настоящим хитом, но компания осуществила переезд не из технических соображений, а из соображений продуктивности. С одним из рабочих проектов, который представлял из себя монолитное приложение на Ruby on Rails, одностраничное JavaScript веб-приложение и клиента к публичному API, работали сразу две команды.
Они были изолированы друг от друга и даже работали в разных зданиях. Процесс разработки был основан на описании идей, мокапах, создании макетов, кода и выкладке проекта после недолгого тестирования. В итоге инженеры и дизайнеры жаловались на перегрузку, при этом продакт-менеджеры и партнеры жаловались, что ничего никогда не делается вовремя.
На данном этапе развития проекта было критически важно объявить о партнерстве с рядом заметных компаний, но для этого нужно было запустить закрытое бета-тестирование. Как раз в это время команда и решила разобраться в том, куда их завел процесс органического роста компании.
Для этого была использована карта потока ценности (Value Stream Map), которая помогла визуализировать реальное положение дел в рамках процесса разработки. Выяснилось, что было задействовано множество сторонних сервисов и итераций. Например, спецификация публиковалась в Drive, карточки – на доске в Trello, изменения кода – в Pivotal Tracker и так далее. В итоге общее время реализации увеличивалось еще и за счет того, что вторая команда обычно ждала, пока накопятся изменения в бранче, и уже потом «накатывала» их в продакшен.
В общем, чтобы новая фича оказалась реализованной, требовалось не меньше двух месяцев. Для решения проблемы команда решила адаптировать технику поезда релизов (release train). Вместо того, чтобы ждать, пока накопится несколько новых фич, можно просто развертывать их по мере готовности каждый день. Во всей этой схеме главной бедой был пинг-понг между двумя командами фронтенд и бэкенд-разработки – 47 дней, потраченных на «инженерию», и 11 дней – на разработку. Остальное время вообще уходило впустую на бессмысленное ожидание.
Эксперимент с парной разработкой фичи силами бэкенд и фронтенд-разработчиков привел к тому, что каждый отдельный сотрудник стал тратить больше времени на работу по конкретной функции. При этом сохранялся процесс обязательного ревью кода (pull request), прежде чем код мог попасть в мастер-ветку нашего Rails-приложения.
Далее дизайнер, менеджер по продукту и фронтенд-разработчики стали работать вместе, и цикл разработки удалось еще немного сократить. Все это позволило команде осуществить первый релиз Next сильно раньше дедлайна.
Создание пар из сотрудников разных специальностей, что привело к структуре «команд фич» (feature team), которая используется в SoundCloud и сегодня. Далее в процессе работы над монолитом на Ruby on Rails команда столкнулась с вопросами относительно практик ревью кода. Было решено применить аналогичный подход – требование просмотра кода вторым инженером, а при парном программировании такое ревью осуществлялось в режиме реального времени.
Эксперимент с несколькими парами выявил проблемы, которые заставили начинать все с начала. База кода монолита была столь обширна и охватывала столь различные аспекты, что никто не мог во всем этом ориентироваться. В компании даже родился мем «все всегда хорошо, пока не понадобится лезть в монолит».
В итоге пришло пересмотреть очень многое. Бэкенд-система была черным ящиком, который нужно было открыть. На выходе получился не монолит, а платформа с множеством компонентов. У каждого из них свои владельцы и свой независимый жизненный цикл. Кроме того, для разных модулей ожидание уровня сервиса также различалось.
Таким образом, на уровне кода нужно было убедиться в том, что внесение изменений в конкретную функцию можно проводить в относительной изоляции, без необходимости трогать код других компонентов. А с точки зрения развертывания понадобилось убедиться в возможности изолированного развертывания фичи, что вело бы создании группы серверов ответственной только за одну фичу.
Решено было пойти другим путем и построить все, что нужно для проекта по монетизации, в качестве сервисов, изолированных от монолита. Проект включал масштабные обновления и полное переосмысление модели подписки, но удалось его закончить раньше сроков двумя командами по два инженера в каждой. Опыт был признан удачным, и этот подход применили для всех новых разработок.
Новый архитектурный фреймворк позволил сократить время на создание новых функций до, пусть не идеальных, но уже куда более приемлемых для компании величин, позволявших не отставать от конкурентов на сложном музыкальном рынке.
За главные объекты все еще отвечает одна команда, но теперь архитектура более стабильна, что снижает число «пожаров». В итоге даже эти сотрудники могут выделить время для перехода на микросервисы.
На сегодняшний день у SoundCloud все равно есть монолитный код, но его важность снижается с каждым днем. Он все еще критичен для многих функций, но теперь он даже не работает напрямую с интернетом (благодаря специальной системе). Возможно, полностью он не исчезнет никогда — многие функции столь малы и стабильны, что может быть дешевле оставить все как есть, но уже через год ничего реально важного там не останется.
P.S. Еще немного о том, как мы улучшаем работу провайдера виртуальной инфраструктуры 1cloud:

{kind=link}
{kind=link}
{kind=link}
{kind=link}