
Процесс создания сервиса не ограничивается разработкой и тестированием. Помимо этого есть ещё и эксплуатация сервиса в продакшн-инфраструктуре.
Так, для реализации проекта требуются специалисты с разными компетенциями — разработчики и инфраструктурные инженеры. Первые знают, как писать код, вторые — как работает софт и в какой конфигурации он будет более эффективен.
В статье речь пойдет о том, как мы в 2ГИС выстраивали процессы работы в команде Infrastructure & Operations (9 человек) и взаимодействие с командами разработки (5 команд). На первый взгляд, всё просто и логично.
Но это не так. Если взять этих людей и сказать «Вы, разработчики, только пишете код, а вы, администраторы, будьте добры, отвечайте за стабильную работу этого кода в продакшне», мы получим ряд проблем:
- Разработчики часто вносят изменения. Изменения часто являются источником сбоев. Администраторы не любят сбои, соответственно, не любят изменения.
- Различия в терминологии и опыте сильно мешают в коммуникациях.
- Перекладывание ответственности в случае инцидентов совсем не редкость.

О наших баранах
Если три упомянутых выше проблемы вас не впечатлили, посмотрите на список моментов, с которыми столкнулась наша команда:
- С коммуникациями всё сложно. Обращаться за помощью было не принято и инструменты выбирались без консультаций, исходя не из задачи, а из удобства. Получалось, что люди приходили уже с готовым решением, часто нагугленным, а не с проблемой.
- Частично ручное конфигурирование сервисов. С разрастанием количества сервисов объём ручной работы увеличивался. Люди были перегружены, нервозность в коллективе нарастала.
- Уникальность сервисов. Каждый проект был уникален как снежинка, соответственно, время разбора инцидентов было очень большим — сначала нужно разобраться в работе сервиса, потом понять, в чём проблема, а потом уже чинить. К тому же, часто разработчики не интересовались, существует ли уже в компании какой нибудь кластер PostgreSQL или Rabbit и деплоили свой.
- Не были сформулированы и зафиксированы правила работы системных администраторов и таск-трекинг. Фидбек от разработчиков — «Фиг знает, чем они там занимаются».
- Не были формализованы каналы коммуникаций. В итоге — что-то пишется на почту, что-то в скайп, что-то в Slack, о чём-то договариваются по телефону.

В совокупности все эти факторы приводили к увеличению времени разработки продуктов и нервозности в коллективе.
Что делать?
Принцип
Мы решили действовать в следующем ключе: по максимуму избавить разработчиков от инфраструктурных вопросов, чтобы они сосредоточились только на планировании и написании бизнес-логики.
Решение находилось в нескольких областях — в технической и в области организации процессов. В технической — потому что имеющиеся решения не предоставляли необходимого функционала. В процессной — так как чёткий процесс только предстояло создать.
Технические решения
Итак, из технических решений в плане инфраструктуры у нас был OpenStack. Что он позволяет делать? Создавать всю необходимую инфраструктуру для проекта — виртуальную машину, DNS, IP и т.д. Но при этом всё-таки остаётся необходимость написания деплоя продуктов, организации мониторинга, логирования, обеспечения отказоустойчивости. Всё это остаётся в зоне ответственности команды разработки и отъедает у неё время.
Платформа
Мы решили провести эксперимент — кардинально сменить дистрибуцию приложений. Несколько небольших проектов, которые предстояло выпустить в ближайшее время, решили выпускать в Docker.
Мы хотели, чтобы наши разработчики не приобретали дополнительную головную боль, а получали решение своих проблем. Принудительное изучение новых технологий не входило в планы. Кроме того, в проведение эксперимента не хотелось инвестировать огромное количество времени.
Выбор пал на платформу для запуска web-приложений Deis. Как они сами о себе говорят — MicroPaaS или небольшой клон Heroku. Micro — потому что позволяет запускать только stateless-сервисы. Сейчас Deis больше не поддерживается, но нам он сослужил хорошую службу в плане адаптации людей к новым технологиям. Подробнее об этой платформе и её технических аспектах мои коллеги делали уже доклады здесь и здесь. Я лишь остановлюсь на том, что в итоге получили наши разработчики.
Deis даёт 3 способа запустить приложение:
- Можно собрать Docker Image самому и отдать его Deis.
- Можно просто написать Dockerfile.
- Самый простой вариант — команда ‘git push deis master’. Он сам по Heroku buildpack собирает Docker Image.
Сейчас уже вышла вторая версия Deis Workflow, которая работает на Kubernetes. Так что мы успешно проапгрейдились и сохранили user experience и дали нашим более технологически сложным проектам Kubernetes.
Что мы получили с переходом на контейнерную инфраструктуру?
- Более эффективную утилизацию железа.
- Унифицированный подход к разработке сервисов. Теперь большинство сервисов выглядит одинаково и разобраться в том, что происходит, стало гораздо проще.
- Для одной платформы теперь легко сделать стандарты журналирования и мониторинга.
Backing services
Хорошо, у нас готово решение для приложений, но помимо самого кода есть ещё и базы данных. У многих проектов есть уникальные инстансы баз данных с разной степенью отказоустойчивости различных версий, которые требуют времени на поддержку. Здесь мы понимали, что счастье абсолютно для всех мы сделать не сможем. Увы. Мы взяли однотипные проекты — их было большинство — которым не требуется запись в несколько дата-центров. Для них подняли один большой кластер Postgres на железе и постепенно перевезли туда указанные проекты.
Теперь разработчики могут просто деплоить код в платформу, реквестить базу у админов и всё. Однако, «могут» — это не значит, что будут делать обязательно.
Распространение технологий

Следует сказать несколько слов про то, что, на самом деле, при появлении новой технологии в компании не обязательно сразу все кидаются её использовать.
Во-первых, польза не всегда очевидна, во-вторых, у всех очень много дел, в-третьих, и так всё работает.
Для того, чтобы технологией начали реально пользоваться, мы, например, сделали следующее:
- Написали документацию — FAQ, Quick start.
- Провели серию внутренних TechTalks, на которых рассказывали, какие именно проблемы разработки мы решаем.
- В отдельных случаях садились непосредственно в команду и разбирали возникающие вопросы и проблемы.
IaC, CI и вот это всё
Внедрение новых инструментов не было бы возможным, если бы мы не воспользовались подходом IaC + CI. В своей работе мы придерживаемся следующих правил:
- Вся инфраструктура должна быть в Git.
- Обязательно должен быть CI.
- Непосредственно на сервера ходим только в крайних случаях, всё остальное через CI.
- Каждое изменение должно пройти ревью как минимум двух коллег.
Процессные решения
Входное и выходное ревью

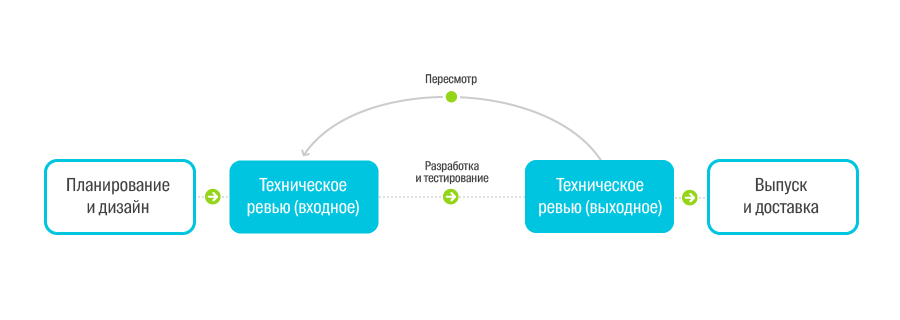
Для контроля попадания проектов в нашу новую инфраструктуру мы придумали следующий процесс — техническое ревью проектов.
Он состоит их двух шагов.
Входное ревью — на стадии проектирования, то есть как только команда придумала, как её сервис будет выглядеть.
- Цель: провалидировать архитектуру, выбранные технологии, обсудить требуемые ресурсы.
- Комитет: продакт-менеджер, инфраструктурный инженер, QA, эксперты по областям и прочие заинтересованные люди.
- На выходе: список задач, которые нужно исправить до выходного ревью.
Выходное ревью — за несколько дней до предполагаемой даты релиза
- Цель: проверить готовность продукта к релизу.
- Комитет: Те же + техподдержка.
- На выходе: дата релиза и список совместных действий.
Прижилось не сразу, так как процесс был воспринят как сдача экзамена или защита проекта — сразу же возник вопрос «А почему я, собственно, это должен делать?»
Мы ответили, что это не сдача экзамена какому-то конкретному отделу, а консультации со специалистами на тему того, как сделать продукт лучше и стабильнее.
Это + ещё несколько удачных кейсов спасения проекта от оверинжиниринга + найденные неучтеные проблемы помогло техническому ревью всё-таки взлететь.
Со временем система сама себя откалибровала и процесс начал занимать меньше времени. Дополнительной полезностью стала осведомленность о релизах продуктов. Мы всегда знаем, что и когда будет релизиться, а также архитектуру и слабые места всех проектов.
Планирование
Опять же, чтобы знать, что происходит и что будет происходить, мы ввели процесс планирования, которого раньше в команде системных администраторов не было. Сделали таким же, как и для остальных команд разработки. Таск-трекинг в Jira, месячные итерации, процентов 30-40 времени закладываем на непредвиденные таски. Так же мы участвуем во всех больших планированиях, где решается, над чем будет вестись работа в ближайшие полгода.
On-call rules
И ещё одним источником нервотрепки был полный хаос в работе с инцидентами. Когда какой-нибудь сервис переставал работать, непонятно было, кто кому должен звонить и что вообще с этим делать. Так мы ввели достаточно простые штуки:
Дежурства
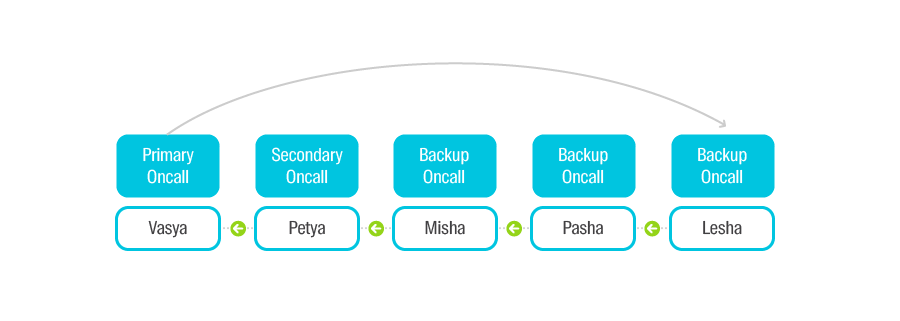
По принципу очереди. Есть Primary On-call, есть Secondary On-call, есть все остальные. Каждую неделю происходит смена — Primary перемещается в конец очереди, Secondary становится Primary. Задача дежурного — в максимально короткие сроки восстановить работоспособность сервиса. Если же админ понимает, что проблема вне зоны его компетенции, он сообщает об этом разработчикам сервиса.
Postmortem meeting или разбор полётов
В рабочее время дежурный назначает митинг со всеми причастными сторонами. Обязательно участие представителей пострадавшего сервиса, ответственных за железо, техподдержки.
На этом митинге документируются следующие аспекты:
- Хронология событий. Когда была обнаружена проблема и когда исправлена.
- Импакт. Какое влияние оказал инцидент на пользователей.
- В чём была исходная причина.
- Какие действия должны быть предприняты каждой из сторон, чтобы инцидент больше не повторился.
Полученный список тасок выполняется в приоритете. Кажется, нудятина и бюрократия. Однако, это очень полезная штука. Серьёзно помогает в аргументации и проталкивании задач из техдолга.
Коммуникации
Беспорядочные коммуникации мешают понять, что происходит, и за всем уследить.
Исходные данные у нас были такие:
- Существующие каналы: Slack, почта, телефон, Mattermost.
- Входящая в команду информация: проблемы, вопросы, фича-реквесты.
- Исходящая информация: работы на сервисах.
Сейчас процессы выстроены следующим образом:
Быстрые вопросы и сообщение о проблемах — в открытый канал в Slack, чтобы могли все видеть.
Если это реальная проблема, то вслед за сообщением обязательно заводится тикет в Jira. Фича-реквесты однозначно сразу идут в Jira.
Для информирования команд о работах в инфраструктуре был написан свой сервис Status Board. В нём человек заводит ивент на сервис, в котором содержится информация: когда будут производиться работы, сколько сервис будет недоступен и т.д., а Status Board рассылает необходимые нотификации.
Выводы
Эксплуатация — неотъемлемая составляющая жизни сервиса. И начинать думать о том, как он будет работать в продакшне, нужно с самого начала работы над ним. Стабильность сервиса обеспечивают как инфраструктурные инженеры, так и разработчики, поэтому они должны уметь общаться — сидеть вместе, вместе разбирать проблемы, иметь прозрачные друг для друга процессы, разделять ответственность за инциденты, планировать работы. Не забудьте уделить время и создать удобный инструментарий для совместной работы. Напишите FAQ, проведите TechTalk, но убедитесь, что недопонимания не осталось.
Подружить команду администраторов с командами разработчиков непросто, но однозначно игра стоит свеч.
Видеоверсию статьи можно посмотреть на techno.2gis.ru
