Многие сомневаются, что облака обходятся дешевле собственного железа — такую точку зрения мы в ActiveCloud встречаем довольно часто. Одни пользуются облаками из-за гибкости, вторые хотят уйти от рутины, третьим нужна централизация, четвёртым — безопасность. Однако облака не только удобны, но и выгодны, и мы попробуем объяснить почему.
При оценке эффективности перехода в облака Заказчики зачастую склонны сравнивать стоимость владения облаками и железом в лоб. Например, если покупаем 5 серверов с 40 процессорными ядрами и 256 ГБ RAM, то и у облачного провайдера запрашиваем аналогичные ресурсы (40*5=200 vCPU + 256*5=1280 ГБ vRAM), а потом сравниваем затраты за 3 года или даже 5 лет.
К сожалению, в большинстве случаев такой подход не будет объективным, поскольку не учитывает ряд важных нюансов, напрямую влияющих на стоимость владения.
В облаке вопросы отказоустойчивости уже продуманы — хосты виртуализации кластеризованы, а в кластере зарезервированы ресурсы как минимум в размере одного хоста виртуализации, чтобы серверы клиентов в случае отказа хоста или его выключения на время регламентных работ могли быть перемещены на резервный хост. При этом дополнительной платы (сверх обозначенной стоимости ресурсов) за такой резерв сервис-провайдер не требует.
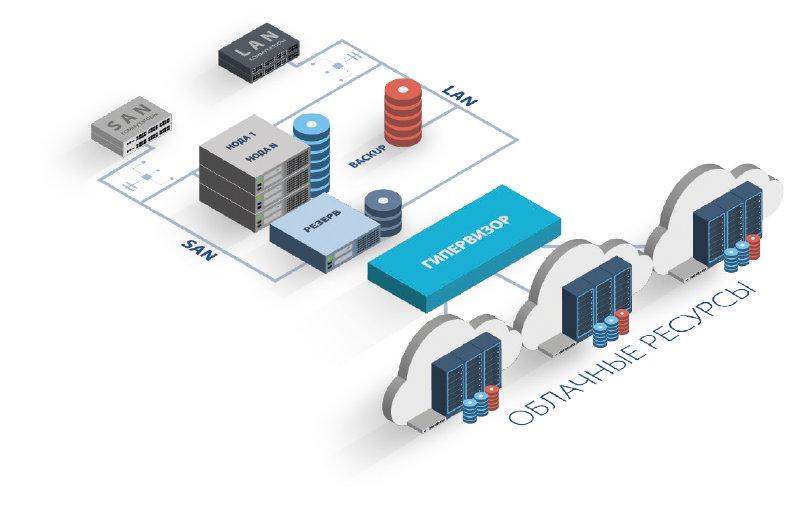
В случае своего железа потери на резервирование придётся вычесть из потенциально доступного на оборудовании пула ресурсов. В нашем примере с 5 серверами Заказчик при сохранении отказоустойчивости не сможет загрузить серверы по процессору и памяти более чем на 80%, иначе в случае отказа одного из хостов часть серверов физически не смогут быть перезапущены из-за нехватки ресурсов.
Конечно, можно рассчитывать, что в случае аварии вы сможете временно остановить ряд некритичных сервисов, но такой подход в реальных условиях как правило не работает.
То же самое справедливо и для облачного хранилища данных — в цену виртуального дискового пространства уже заложены устойчивые к множественным отказам типы рейдов и резервные диски горячей подмены, а в случае собственной СХД будут доступны для использования 45-65% от сырого дискового объема в зависимости от выбранного типа RAID-массива.
Практика показывает, что серверы архитектуры x86 не стоит постоянно нагружать более чем на 70-80% по процессору и 80-90% по памяти, иначе возможны просадки производительности, особенно заметные во время запуска обслуживающих задач (например, во время резервного копирования). При этом кратковременные всплески нагрузки железо, как правило, переживает нормально, а вот при долговременной работе в таком режиме деградация производительности размещённых на этом железе ИТ систем очень вероятна.
По этой причине многие сервисные провайдеры не только соблюдают правила допустимой предельной утилизации своего оборудования*, но и фиксируют такие обязательства в договоре с Заказчиком.
На системе хранения данных утилизировать весь доступный объем, получившийся после сборки RAID-массивов, также не всегда получается, поскольку требуется резерв для работы различного функционала стораджа (например, аппаратных снапшотов или тиринга). Размер такого резерва может составлять 10% и более от доступного для адресации места.
При использовании СХД на механических дисках (HDD) размеченные луны не рекомендуется заполнять более чем на 70-80% при интенсивной дисковой нагрузке, чтобы избежать деградации производительности хранилища. SSD диски такой проблемы лишены, однако all-flash стораджи сегодня все еще достаточно дороги, и не для каждой компании их покупка рентабельна.
Не секрет, что при планировании потребляемых ресурсов всегда закладывается определенный резерв на случай роста. Размер этого резерва индивидуален, однако влияющие на него факторы более-менее известны.
Можно отталкиваться от статистики роста потребления в предыдущие годы — если эти данные есть, то закладываем аналогичную динамику и немного сверху на непредусмотренные срочные инициативы бизнес-подразделений. Если такой статистики нет, то придётся делать предположение самостоятельно на основании плана будущих проектов и стратегии компании по росту и географической экспансии. Такой прогноз вряд ли окажется точным, но это все же лучше, чем оказаться без мощностей, нужных бизнесу «здесь и сейчас»
В период высокой конкуренции практически на всех b2c рынках, бизнес вынужден делать ставку на скорость запуска и вывода на рынок новых продуктов и услуг, потому как зачастую первый на рынке снимает сливки, а второй получает убытки.
В таких условиях поддерживать нужный темп, опираясь на собственную инфраструктуру, могут себе позволить только крупные игроки, способные инвестировать в собственную экспертизу, или даже ИТ платформу, и перераспределить ресурсы между проектами в случае необходимости.
Для менее крупных и средних компаний намного быстрее будет масштабироваться по мере необходимости на облачных мощностях, поскольку свое железо быстро нарастить не получится. Даже если в компании внедрены стандарты на оборудование и налажен процесс расчета конфигурации в выбранном вендоре, пройдет не менее 2-3 месяцев, прежде чем железо будет рассчитано, поставлено, смонтировано и настроено для возможной эксплуатации. Если же процедура приобретения основных средств достаточна сложна, как часто бывает, и корпоративные регламенты требуют каждый раз проводить тендер с участием нескольких конкурирующих производителей, то процесс расширения ресурсного пула легко может растянуться на полгода и более.
Конечно, в случае с облаком планировать и закладывать в бюджет резерв тоже нужно, однако при неверном планировании компания не понесёт заметных убытков — облачные мощности всегда можно масштабировать по реальному потреблению, и нет нужды оплачивать лишнее, пока оно реально не потребуется.
Точное планированием ресурсов для ключевых учётных информационные систем может быть сложной задачей, поскольку каждое внедрение индивидуально и часто сопряжено с большим объёмом доработок под конкретные бизнес-процессы. В этом случае при сайзинге остается надеяться на рекомендации разработчиков системы, которые обязательно заложат возможные риски — ведь им не хочется оправдываться перед Заказчиком за медленную работу системы после внедрения. Получив рекомендации производителя, собственные ИТ специалисты также заложат риски, потому что не хотят выслушивать упреки от пользователей. В итоге получается, что производитель перестраховался при предоставлении рекомендаций раза в полтора, и ИТ отдел перестраховался при заказе оборудования раза в полтора, а в результате приобретенное дорогостоящее железо простаивает больше чем на половину, и лишнее обратно в магазин уже не отнесешь.
Облако не только спасает от подобных ситуаций, но также может сильно облегчить жизнь тем, кто арендует мощности на время внедрения, выполняя таким образом сайзинг на реально развернутой системе. В этом случае, правда, появляются некоторые риски совместимости — после переезда на свое железо производительность системы может внезапно снизиться без видимых причин. Но такой подход все же лучше, чем покупка оборудования вслепую.
Любое железо, будь то сетевое оборудование, серверы или хранилища, нужно обслуживать. То же самое можно сказать в отношении систем виртуализации, мониторинга, безопасности, бекапирования и других сервисов, обеспечивающих стабильную и безопасную работу ключевых бизнес-систем компании. Персонал, способный поддерживать все это в рабочем состоянии и починить в случае аварии, стоит достаточно дорого. Зачастую — неоправданно дорого для не самого крупного бизнеса.
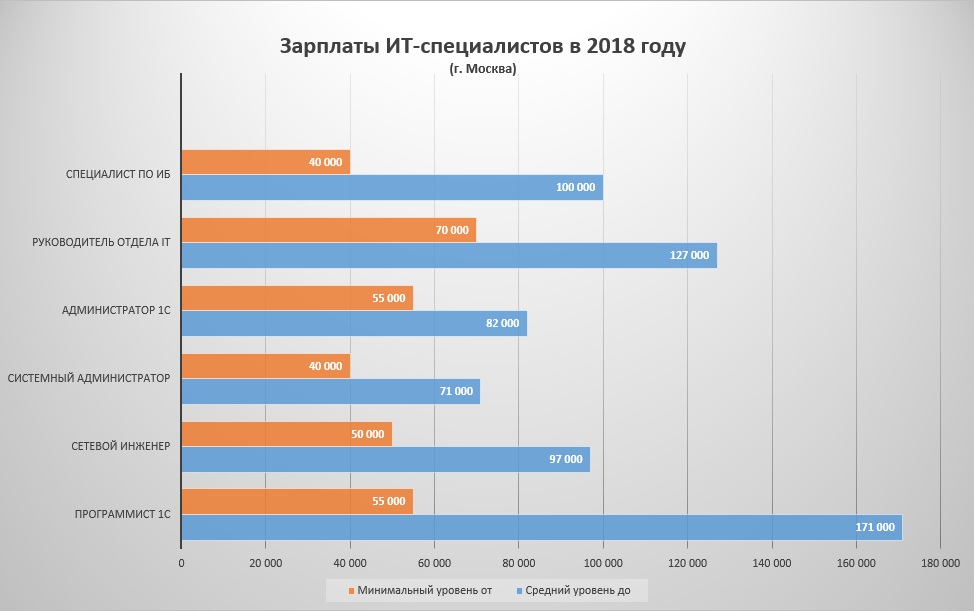
На основе статистических данных, в том числе HH.RU(https://stats.hh.ru).
При этом совокупная сложность используемого стека инфраструктурных технологий становится выше с каждым годом, и вместе с ней постоянно растут требования к квалификации обслуживающих специалистов.
Удерживать таких людей в штате даже при наличии пухлого бюджета становится все сложнее, поскольку стоящих специалистов помимо зарплаты необходимо также обеспечивать потоком задач с нарастающей сложностью и ответственностью. Конкурировать за них с профильными ИТ компаниями как правило попросту невыгодно.
Размещая инфраструктуру в облаке, Заказчик тем самым фактически получает доступ к разносторонней команде квалифицированных архитекторов и инженеров, опыт и компетенции которых постоянно растут. Чем плотнее компания взаимодействует с сервис-провайдером в своих проектах, тем в большей степени может рассматривать его не только как поставщика облачных услуг, но и как постоянно доступного ИТ партнера, готового делиться с клиентом опытом и комплексно решать его задачи.
Здесь важно отметить, что аренда мощностей и сервисов в облаке, конечно же, не освободит компанию от необходимости инвестировать в свою службу ИТ, однако позволит пересмотреть штат, выбирая специалистов с более узкими, профильными для ваших бизнес-систем компетенциями, перекладывая ответственность за инфраструктурные и пограничные сервисы на плечи провайдера.
Каким бы именитым не был производитель, от производственного брака и ошибок в работе софта все равно не застрахован никто. Особенно бывает обидно, когда из-за этого не просто некорректно работает часть функционала, а невозможна эксплуатация приобретенных ИТ активов в целом, и оперативно решить вопрос с производителем не получается, даже если приобретена дорогая next business day поддержка.
Происходит такое по разным причинам: иногда у вендора ещё не выстроены процессы, и поддержка оказывается в ограниченном режиме, иногда нужных деталей нет в ЗИП, иногда требуются кастомные прошивки, на написание которых уходит не одна неделя, а то и не один месяц, — однако результат всегда один — потраченное время, нервы, сорванные сроки проекта и вызов на ковер к бизнесу. Думаю, многие согласятся, что переложить подобные риски на плечи провайдера намного приятнее.
Облачные провайдеры обслуживают большое количество Заказчиков, и недоступность облака по любым причинам сильно бьет по деловой репутации поставщика услуг, даже если отказ произошел не по его вине. Клиентам все равно, какого размера дерево упало на датацентр, и какого цвета был экскаватор, повредивший оптику. Поэтому вопрос выбора и оснащения площадки как правило не стоит — арендуем Tier3 ЦОД и подключаем несколько Интернет-каналов с защитой от DDoS.
Чтобы обеспечить похожий уровень надежности и безопасности в локальной серверной, придется инвестировать в нее порядка 100 000 $ на стойку, но и в этом случае по ряду параметров коммерческий дата-центр будет выигрывать.
Даже если не ставить перед собой задачу построить серверную по мировым стандартам, а лишь обеспечить приемлемые условия эксплуатации для своего оборудования, то капитальные затраты все равно будут заметными — придется выделить помещение, проложить СКС, подключить пару внешних каналов связи, подвести качественные линии электропитания, способные выдержать десяток-другой киловатт, правильно организовать охлаждение и вентиляцию, позаботиться о ИБП, а в идеале задублировать основные инженерные системы и поставить промышленную систему пожаротушения и СКУД.
И конечно же все вышеперечисленное придется обслуживать, что вряд ли обойдётся дешевле четверти миллиона в год на каждую полную стойку.
Можно облегчить себе жизнь и разместить свое оборудование в коммерческом ЦОД. Однако преимущества аутсорсинга непрофильных ИТ операций достаточно быстро становятся очевидны, и от аренды стоек Заказчики переходят к гибриду своего железа и постепенно его заменяющих облачных сервисов.
Если при сравнении учесть описанные выше нюансы, то в большинстве случаев окажется, что облака позволяют бизнесу снизить издержки, даже если при выборе провайдера сделать акцент на качестве услуг и количестве доступных сервисов.
Быстро рассчитать стоимость ресурсов облака поможет калькулятор на сайте ActiveCloud — есть возможность сразу учесть в расчете резервное копирование, техническую поддержку, лицензии на операционную систему и другие опции. Если у вас есть потребность сравнить стоимость владения облачной и собственной инфраструктурой в деталях – напишите на dmitriy.yashin@activecloud.ru.
При оценке эффективности перехода в облака Заказчики зачастую склонны сравнивать стоимость владения облаками и железом в лоб. Например, если покупаем 5 серверов с 40 процессорными ядрами и 256 ГБ RAM, то и у облачного провайдера запрашиваем аналогичные ресурсы (40*5=200 vCPU + 256*5=1280 ГБ vRAM), а потом сравниваем затраты за 3 года или даже 5 лет.
К сожалению, в большинстве случаев такой подход не будет объективным, поскольку не учитывает ряд важных нюансов, напрямую влияющих на стоимость владения.
1. Не учитываются ресурсы, требуемые для обеспечения отказоустойчивости
В облаке вопросы отказоустойчивости уже продуманы — хосты виртуализации кластеризованы, а в кластере зарезервированы ресурсы как минимум в размере одного хоста виртуализации, чтобы серверы клиентов в случае отказа хоста или его выключения на время регламентных работ могли быть перемещены на резервный хост. При этом дополнительной платы (сверх обозначенной стоимости ресурсов) за такой резерв сервис-провайдер не требует.
В случае своего железа потери на резервирование придётся вычесть из потенциально доступного на оборудовании пула ресурсов. В нашем примере с 5 серверами Заказчик при сохранении отказоустойчивости не сможет загрузить серверы по процессору и памяти более чем на 80%, иначе в случае отказа одного из хостов часть серверов физически не смогут быть перезапущены из-за нехватки ресурсов.
Конечно, можно рассчитывать, что в случае аварии вы сможете временно остановить ряд некритичных сервисов, но такой подход в реальных условиях как правило не работает.
То же самое справедливо и для облачного хранилища данных — в цену виртуального дискового пространства уже заложены устойчивые к множественным отказам типы рейдов и резервные диски горячей подмены, а в случае собственной СХД будут доступны для использования 45-65% от сырого дискового объема в зависимости от выбранного типа RAID-массива.
2. Не учитывается предел загрузки серверов и систем хранения данных
Практика показывает, что серверы архитектуры x86 не стоит постоянно нагружать более чем на 70-80% по процессору и 80-90% по памяти, иначе возможны просадки производительности, особенно заметные во время запуска обслуживающих задач (например, во время резервного копирования). При этом кратковременные всплески нагрузки железо, как правило, переживает нормально, а вот при долговременной работе в таком режиме деградация производительности размещённых на этом железе ИТ систем очень вероятна.
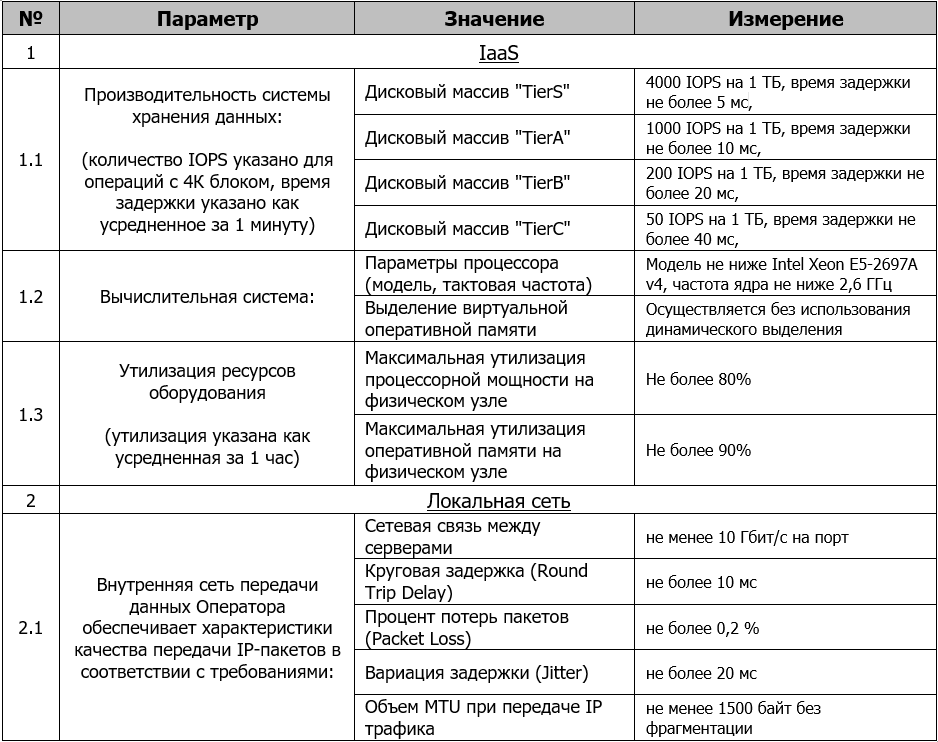
По этой причине многие сервисные провайдеры не только соблюдают правила допустимой предельной утилизации своего оборудования*, но и фиксируют такие обязательства в договоре с Заказчиком.
Выдержка из договора SLA для нашего облака VMware
На системе хранения данных утилизировать весь доступный объем, получившийся после сборки RAID-массивов, также не всегда получается, поскольку требуется резерв для работы различного функционала стораджа (например, аппаратных снапшотов или тиринга). Размер такого резерва может составлять 10% и более от доступного для адресации места.
При использовании СХД на механических дисках (HDD) размеченные луны не рекомендуется заполнять более чем на 70-80% при интенсивной дисковой нагрузке, чтобы избежать деградации производительности хранилища. SSD диски такой проблемы лишены, однако all-flash стораджи сегодня все еще достаточно дороги, и не для каждой компании их покупка рентабельна.
3. Не учитываются издержки, связанные с ограниченным масштабированием
Не секрет, что при планировании потребляемых ресурсов всегда закладывается определенный резерв на случай роста. Размер этого резерва индивидуален, однако влияющие на него факторы более-менее известны.
Можно отталкиваться от статистики роста потребления в предыдущие годы — если эти данные есть, то закладываем аналогичную динамику и немного сверху на непредусмотренные срочные инициативы бизнес-подразделений. Если такой статистики нет, то придётся делать предположение самостоятельно на основании плана будущих проектов и стратегии компании по росту и географической экспансии. Такой прогноз вряд ли окажется точным, но это все же лучше, чем оказаться без мощностей, нужных бизнесу «здесь и сейчас»
В период высокой конкуренции практически на всех b2c рынках, бизнес вынужден делать ставку на скорость запуска и вывода на рынок новых продуктов и услуг, потому как зачастую первый на рынке снимает сливки, а второй получает убытки.
В таких условиях поддерживать нужный темп, опираясь на собственную инфраструктуру, могут себе позволить только крупные игроки, способные инвестировать в собственную экспертизу, или даже ИТ платформу, и перераспределить ресурсы между проектами в случае необходимости.
Для менее крупных и средних компаний намного быстрее будет масштабироваться по мере необходимости на облачных мощностях, поскольку свое железо быстро нарастить не получится. Даже если в компании внедрены стандарты на оборудование и налажен процесс расчета конфигурации в выбранном вендоре, пройдет не менее 2-3 месяцев, прежде чем железо будет рассчитано, поставлено, смонтировано и настроено для возможной эксплуатации. Если же процедура приобретения основных средств достаточна сложна, как часто бывает, и корпоративные регламенты требуют каждый раз проводить тендер с участием нескольких конкурирующих производителей, то процесс расширения ресурсного пула легко может растянуться на полгода и более.
Конечно, в случае с облаком планировать и закладывать в бюджет резерв тоже нужно, однако при неверном планировании компания не понесёт заметных убытков — облачные мощности всегда можно масштабировать по реальному потреблению, и нет нужды оплачивать лишнее, пока оно реально не потребуется.
4. Не учитываются издержки на неточный сайзинг ключевых бизнес-систем
Точное планированием ресурсов для ключевых учётных информационные систем может быть сложной задачей, поскольку каждое внедрение индивидуально и часто сопряжено с большим объёмом доработок под конкретные бизнес-процессы. В этом случае при сайзинге остается надеяться на рекомендации разработчиков системы, которые обязательно заложат возможные риски — ведь им не хочется оправдываться перед Заказчиком за медленную работу системы после внедрения. Получив рекомендации производителя, собственные ИТ специалисты также заложат риски, потому что не хотят выслушивать упреки от пользователей. В итоге получается, что производитель перестраховался при предоставлении рекомендаций раза в полтора, и ИТ отдел перестраховался при заказе оборудования раза в полтора, а в результате приобретенное дорогостоящее железо простаивает больше чем на половину, и лишнее обратно в магазин уже не отнесешь.
Облако не только спасает от подобных ситуаций, но также может сильно облегчить жизнь тем, кто арендует мощности на время внедрения, выполняя таким образом сайзинг на реально развернутой системе. В этом случае, правда, появляются некоторые риски совместимости — после переезда на свое железо производительность системы может внезапно снизиться без видимых причин. Но такой подход все же лучше, чем покупка оборудования вслепую.
5. Не принимается в расчет стоимость обслуживания своей инфраструктуры
Любое железо, будь то сетевое оборудование, серверы или хранилища, нужно обслуживать. То же самое можно сказать в отношении систем виртуализации, мониторинга, безопасности, бекапирования и других сервисов, обеспечивающих стабильную и безопасную работу ключевых бизнес-систем компании. Персонал, способный поддерживать все это в рабочем состоянии и починить в случае аварии, стоит достаточно дорого. Зачастую — неоправданно дорого для не самого крупного бизнеса.
На основе статистических данных, в том числе HH.RU(https://stats.hh.ru).
При этом совокупная сложность используемого стека инфраструктурных технологий становится выше с каждым годом, и вместе с ней постоянно растут требования к квалификации обслуживающих специалистов.
Удерживать таких людей в штате даже при наличии пухлого бюджета становится все сложнее, поскольку стоящих специалистов помимо зарплаты необходимо также обеспечивать потоком задач с нарастающей сложностью и ответственностью. Конкурировать за них с профильными ИТ компаниями как правило попросту невыгодно.
Размещая инфраструктуру в облаке, Заказчик тем самым фактически получает доступ к разносторонней команде квалифицированных архитекторов и инженеров, опыт и компетенции которых постоянно растут. Чем плотнее компания взаимодействует с сервис-провайдером в своих проектах, тем в большей степени может рассматривать его не только как поставщика облачных услуг, но и как постоянно доступного ИТ партнера, готового делиться с клиентом опытом и комплексно решать его задачи.
Здесь важно отметить, что аренда мощностей и сервисов в облаке, конечно же, не освободит компанию от необходимости инвестировать в свою службу ИТ, однако позволит пересмотреть штат, выбирая специалистов с более узкими, профильными для ваших бизнес-систем компетенциями, перекладывая ответственность за инфраструктурные и пограничные сервисы на плечи провайдера.
6. Не всегда учитывается стоимость вендорской поддержки используемого ПО и оборудования
Каким бы именитым не был производитель, от производственного брака и ошибок в работе софта все равно не застрахован никто. Особенно бывает обидно, когда из-за этого не просто некорректно работает часть функционала, а невозможна эксплуатация приобретенных ИТ активов в целом, и оперативно решить вопрос с производителем не получается, даже если приобретена дорогая next business day поддержка.
Происходит такое по разным причинам: иногда у вендора ещё не выстроены процессы, и поддержка оказывается в ограниченном режиме, иногда нужных деталей нет в ЗИП, иногда требуются кастомные прошивки, на написание которых уходит не одна неделя, а то и не один месяц, — однако результат всегда один — потраченное время, нервы, сорванные сроки проекта и вызов на ковер к бизнесу. Думаю, многие согласятся, что переложить подобные риски на плечи провайдера намного приятнее.
7. Не учитывается стоимость постройки и содержания своей серверной
Облачные провайдеры обслуживают большое количество Заказчиков, и недоступность облака по любым причинам сильно бьет по деловой репутации поставщика услуг, даже если отказ произошел не по его вине. Клиентам все равно, какого размера дерево упало на датацентр, и какого цвета был экскаватор, повредивший оптику. Поэтому вопрос выбора и оснащения площадки как правило не стоит — арендуем Tier3 ЦОД и подключаем несколько Интернет-каналов с защитой от DDoS.
Чтобы обеспечить похожий уровень надежности и безопасности в локальной серверной, придется инвестировать в нее порядка 100 000 $ на стойку, но и в этом случае по ряду параметров коммерческий дата-центр будет выигрывать.
Даже если не ставить перед собой задачу построить серверную по мировым стандартам, а лишь обеспечить приемлемые условия эксплуатации для своего оборудования, то капитальные затраты все равно будут заметными — придется выделить помещение, проложить СКС, подключить пару внешних каналов связи, подвести качественные линии электропитания, способные выдержать десяток-другой киловатт, правильно организовать охлаждение и вентиляцию, позаботиться о ИБП, а в идеале задублировать основные инженерные системы и поставить промышленную систему пожаротушения и СКУД.
И конечно же все вышеперечисленное придется обслуживать, что вряд ли обойдётся дешевле четверти миллиона в год на каждую полную стойку.
Можно облегчить себе жизнь и разместить свое оборудование в коммерческом ЦОД. Однако преимущества аутсорсинга непрофильных ИТ операций достаточно быстро становятся очевидны, и от аренды стоек Заказчики переходят к гибриду своего железа и постепенно его заменяющих облачных сервисов.
Если при сравнении учесть описанные выше нюансы, то в большинстве случаев окажется, что облака позволяют бизнесу снизить издержки, даже если при выборе провайдера сделать акцент на качестве услуг и количестве доступных сервисов.
Быстро рассчитать стоимость ресурсов облака поможет калькулятор на сайте ActiveCloud — есть возможность сразу учесть в расчете резервное копирование, техническую поддержку, лицензии на операционную систему и другие опции. Если у вас есть потребность сравнить стоимость владения облачной и собственной инфраструктурой в деталях – напишите на dmitriy.yashin@activecloud.ru.
