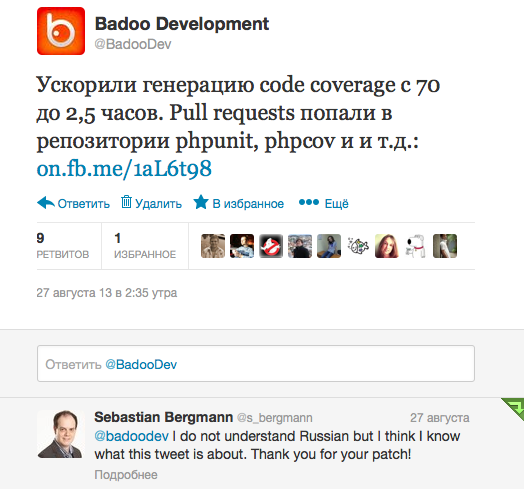
 Несколько месяцев назад мы ускорили генерацию code coverage с 70 до 2,5 часов. Реализовано это было как дополнительный формат в экспорте/импорте coverage. А недавно наши pull requests попали в официальные репозитории phpunit, phpcov и php-code-coverage.
Несколько месяцев назад мы ускорили генерацию code coverage с 70 до 2,5 часов. Реализовано это было как дополнительный формат в экспорте/импорте coverage. А недавно наши pull requests попали в официальные репозитории phpunit, phpcov и php-code-coverage.Мы не раз рассказывали на конференциях и в статьях о том, что мы «гоняем» десятки тысяч юнит-тестов за короткое время. Основной эффект достигается, как несложно догадаться, за счёт многопоточности. И всё бы хорошо, но одна из важных метрик тестирования ― это покрытие кода тестами.
Сегодня мы расскажем, как его считать в условиях многопоточности, агрегировать и делать это очень быстро. Без наших оптимизаций подсчёт покрытия занимал более 70 часов только для юнит-тестов. После оптимизации мы тратим всего 2,5 часа на то, чтобы посчитать покрытие по всем юнит-тестам и двум наборам интеграционных тестов общим числом более 30 тысяч.
Тесты мы в Badoo пишем на PHP, используем PHPUnit Framework от Себастьяна Бергмана (Sebastian Bergmann, phpunit.de).
Покрытие в этом фреймворке, как и во многих других, считается при помощи расширения Xdebug простыми вызовами:
xdebug_start_code_coverage();
//… тут выполняется код …
$codeCoverage = xdebug_get_code_coverage();
xdebug_stop_code_coverage();
На выходе получается вложенный массив, содержащий файлы, выполнявшиеся во время сбора покрытия, и номера строк в файлах со специальными флагами: был ли вызван код, не был или вообще не должен был вызваться. Подробно про работу Xdebug с покрытием можно почитать на сайте проекта.
У Себастьяна Бергмана имеется библиотека PHP_CodeCoverage, которая отвечает за сбор, обработку и вывод покрытия в разных форматах. Библиотека удобна, расширяема и нас вполне устраивает. У неё имеется консольный фронтенд phpcov.
Но и в сам вызов PHPUnit для удобства уже интегрирован подсчёт покрытия и вывод в разных форматах:
--coverage-clover <file> Generate code coverage report in Clover XML format.
--coverage-html <dir> Generate code coverage report in HTML format.
--coverage-php <file> Serialize PHP_CodeCoverage object to file.
--coverage-text=<file> Generate code coverage report in text format.
Опция --coverage-php ― это то, что нам нужно при многопоточном запуске: каждый поток подсчитывает покрытие и экспортирует в отдельный файл *.cov. Агрегацию и вывод в красивый html-отчёт можно сделать вызовом phpcov с флагом --merge.
--merge Merges PHP_CodeCoverage objects stored in .cov files.
Выходит всё складно, красиво и должно работать «из коробки». Но, видимо, далеко не все используют этот механизм, включая самого автора библиотеки, иначе быстро бы всплыла на поверхность «неоптимальность» механизма экспорта-импорта, используемая в PHP_CodeCoverage. Давайте разберём по порядку, в чём же дело.
За экспорт в формат *.cov отвечает специальный класс-репортер PHP_CodeCoverage_Report_PHP, интерфейс которого очень прост. Это метод process(), принимающий на вход объект класса PHP_CodeCoverage и сериализующий его функцией serialize().
Результат записывается в файл (если передан путь к файлу), либо возвращается как результат метода.
class PHP_CodeCoverage_Report_PHP
{
/**
* @param PHP_CodeCoverage $coverage
* @param string $target
* @return string
*/
public function process(PHP_CodeCoverage $coverage, $target = NULL)
{
$coverage = serialize($coverage);
if ($target !== NULL) {
return file_put_contents($target, $coverage);
} else {
return $coverage;
}
}
}
Импорт утилитой phpcov, наоборот, берёт все файлы в директории с расширением *.cov и для каждого делает unserialize() в объект. Объект затем передаётся в метод merge() объекта PHP_CodeCoverage, в который агрегируется покрытие.
protected function execute(InputInterface $input, OutputInterface $output)
{
$coverage = new PHP_CodeCoverage;
$finder = new FinderFacade(
array($input->getArgument('directory')), array(), array('*.cov')
);
foreach ($finder->findFiles() as $file) {
$coverage->merge(unserialize(file_get_contents($file)));
}
$this->handleReports($coverage, $input, $output);
}
Сам процесс слияния очень прост. Это слияние массивов array_merge() с небольшими нюансами вроде игнорирования того, что уже импортировалось, либо передано как параметр фильтра в вызов phpcov (--blacklist и --whitelist).
/**
* Merges the data from another instance of PHP_CodeCoverage.
*
* @param PHP_CodeCoverage $that
*/
public function merge(PHP_CodeCoverage $that)
{
foreach ($that->data as $file => $lines) {
if (!isset($this->data[$file])) {
if (!$this->filter->isFiltered($file)) {
$this->data[$file] = $lines;
}
continue;
}
foreach ($lines as $line => $data) {
if ($data !== NULL) {
if (!isset($this->data[$file][$line])) {
$this->data[$file][$line] = $data;
} else {
$this->data[$file][$line] = array_unique(
array_merge($this->data[$file][$line], $data)
);
}
}
}
}
$this->tests = array_merge($this->tests, $that->getTests());
}
Именно использование подхода сериализации и десериализации и стало той самой проблемой, которая не давала нам быстро генерировать покрытие. Не раз сообщество обсуждало производительность функций serialize и unserialize в PHP:
http://stackoverflow.com/questions/1256949/serialize-a-large-array-in-php;
http://habrahabr.ru/post/104069 и т.д.
Для нашего небольшого проекта, PHP-репозиторий которого содержит больше 35 тысяч файлов, файлы с покрытием весят немало, по несколько сот мегабайт. Общий файл, «смерженный» из разных потоков, весит почти 2 гигабайта. На таких объёмах данных unserialize показывал себя во всей красе ― мы ждали генерации покрытия по несколько суток.
Поэтому мы и решили попробовать самый очевидный способ оптимизации ― var_export и последующий include файлов.
Для этого в репозиторий php-code-coverage был добавлен новый класс-репортер, который делает экспорт в новом формате через var_export:
class PHP_CodeCoverage_Report_PHPSmart
{
/**
* @param PHP_CodeCoverage $coverage
* @param string $target
* @return string
*/
public function process(PHP_CodeCoverage $coverage, $target = NULL)
{
$output = '<?php $filter = new PHP_CodeCoverage_Filter();'
. '$filter->setBlacklistedFiles(' . var_export($coverage->filter()->getBlacklistedFiles(), 1) . ');'
. '$filter->setWhitelistedFiles(' . var_export($coverage->filter()->getWhitelistedFiles(), 1) . ');'
. '$object = new PHP_CodeCoverage(new PHP_CodeCoverage_Driver_Xdebug(), $filter); $object->setData('
. var_export($coverage->getData(), 1) . '); $object->setTests('
. var_export($coverage->getTests(), 1) . '); return $object;';
if ($target !== NULL) {
return file_put_contents($target, $output);
} else {
return $output;
}
}
}
Формат файла мы скромно назвали PHPSmart. Расширение у файлов такого формата ― *.smart.
Для того чтобы объект класса PHP_CodeCoverage позволял себя экспортировать и импортировать в новый формат, были добавлены сеттеры и геттеры его свойств.
Немного правок в репозиториях phpunit и phpcov, чтобы они научились работать с таким объектом, и наше покрытие стало собираться всего за два с половиной часа.
Вот так выглядит импорт:
foreach ($finder->findFiles() as $file) {
$extension = pathinfo($file, PATHINFO_EXTENSION);
switch ($extension) {
case 'smart':
$object = include($file);
$coverage->merge($object);
unset($object);
break;
default:
$coverage->merge(unserialize(file_get_contents($file)));
}
}
Наши правки вы можете найти на GitHub и попробовать такой подход на своем проекте.
github.com/uyga/php-code-coverage
github.com/uyga/phpcov
github.com/uyga/phpunit
Себастьяну Бергману мы отправили пулл-реквесты наших правок, надеясь вскоре увидеть их в официальных репозиториях создателя.
github.com/sebastianbergmann/phpunit/pull/988
github.com/sebastianbergmann/phpcov/pull/7
github.com/sebastianbergmann/php-code-coverage/pull/185
Но он их закрыл, сказав, что хочет не дополнительный формат, а наш вместо своего:

Что мы с радостью и сделали. И теперь наши изменения вошли в официальные репозитории создателя, заменив использовавшийся до этого формат в файлах *.cov.
github.com/sebastianbergmann/php-code-coverage/pull/186
github.com/sebastianbergmann/phpcov/pull/8
github.com/sebastianbergmann/phpunit/pull/989
Вот такая небольшая оптимизация помогла нам ускорить сбор покрытия почти в 30(!) раз. Она позволила нам гонять не только юнит-тесты для подсчёта покрытия, но и добавить два набора интеграционных тестов. На время импорта-экспорта и мержа результатов это существенно не повлияло.
P.S.:
Илья Агеев,
QA Lead
