Речевые технологии шагнули далеко вперед, спасибо машинному обучению и не только. Голосовые помощники больше не похожи на плохо смазанных роботов, у которых всегда одна интонация, да и та раздражает. Они научились (более или менее) нормально понимать запросы человека и гораздо адекватнее на них отвечать.
При этом нужно помнить, что речь — это тоже данные. И, как любые данные, речь тоже можно анализировать. А в ряде случаев — нужно. Меня зовут Алексей Новгородов, я ведущий разработчик дирекции по продуктам и технологиям больших данных. Сегодня я расскажу вам про один из наших продуктов — аудиоаналитику.
Команда и продукт
Главное в продукте или сервисе — это люди, поэтому с них и начну.
У нас есть два вида разработчиков:
Дата-сайентисты, которые придумывают гипотезы и решают профильные проблемы.
Классические разработчики, отвечающие за движение данных, их визуализацию и бизнес-составляющую, включая формирование всевозможных отчетов.
Кроме разработчиков есть продакт, а также ряд людей, не входящих в саму продуктовую команду, но все равно сильно помогающих нам: девопсы, аналитики, юристы и HR.
Аудиоаналитика для контакт-центров — это набор взаимосвязанных продуктов: Speech API, предоставляющий интерфейсы на низком уровне транскрибации, генерации голоса и тому подобного, и сам сервис аналитики для контакт-центров, который с помощью этого API генерирует аналитику для менеджеров по качеству контакт-центров.
Мы решили начать именно с контакт-центров потому, что они есть почти у любого бизнеса. Сейчас сложно представить себе компанию без контакт-центра, вне зависимости от ее деятельности. Ведь это место коммуникации с клиентом, привлечения, решения проблем и поздравлений с днем рождения, рассказы о каких-то новых акциях и многое, многое другое.
Но существует и обратная сторона вопроса, известная только самой компании. Такие контакт-центры — это большая проблема для бизнеса, потому что тут происходит коммуникация между живыми людьми и всё завязано на человеческий фактор. Оператор может встать не с той ноги, а то и в принципе не знать ответа. И это на самом деле проблема, которую надо устранять.
Для этого компании нанимают менеджеров по качеству. Но и это не панацея — обычно это тоже люди со всеми вытекающими слабостями, свойственными роду человеческому. Они не могут покрыть весь объем звонков, потому что работают по определенной выборке, и не каждая конфликтная ситуация может быть ими разрешена.
Но выход есть
Именно тут на помощь приходим мы и предоставляем интерфейс, который позволяет проанализировать весь набор звонков, в том числе исторических.
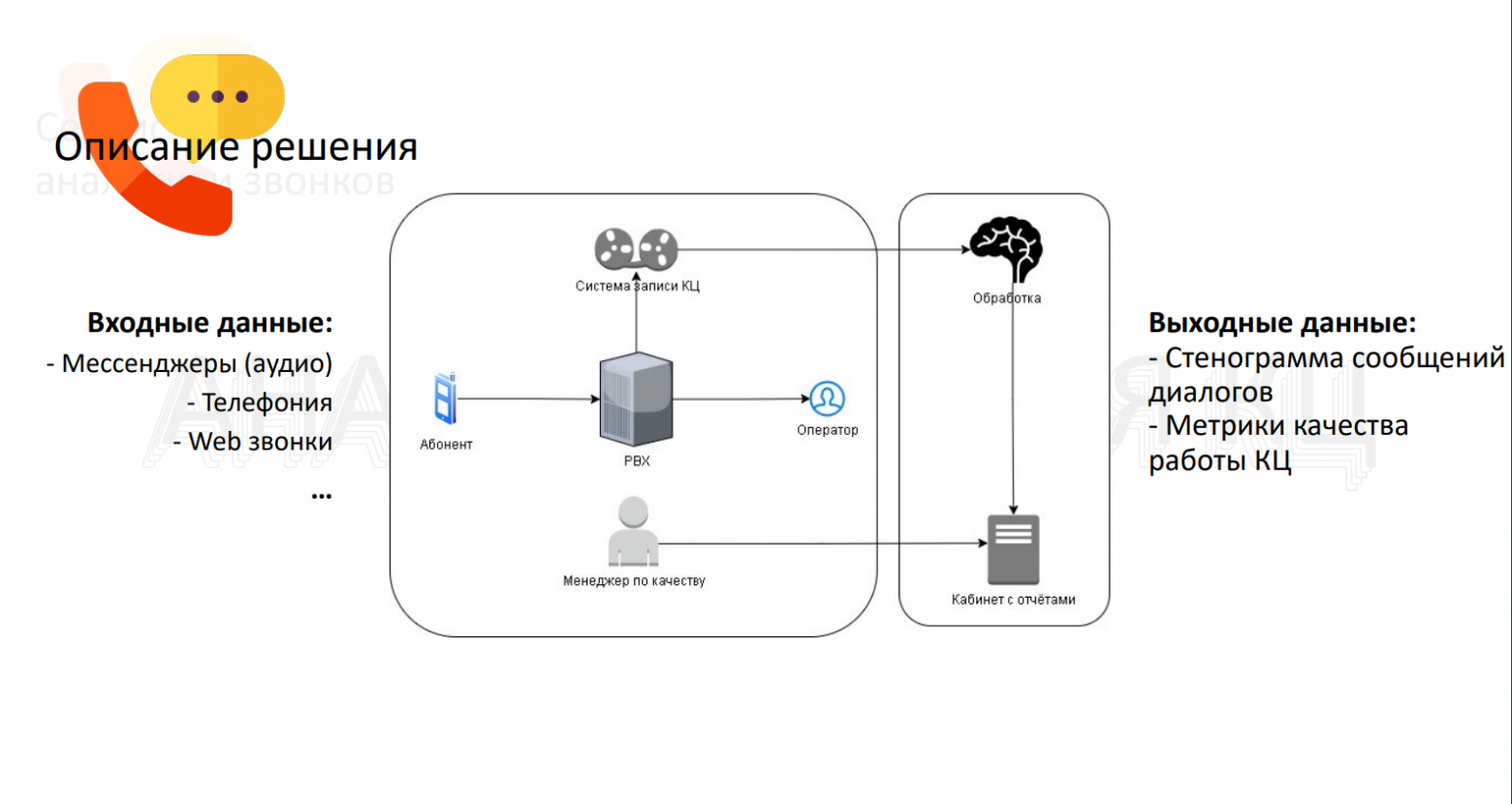
Вот максимально схематичное изображение контакт-центра. Отмечу, что это необязательно должен быть именно контакт-центр — наша система с одинаковым аппетитом ест аудио вообще из любого источника.
Так вот, в каждом контакт-центре есть система записи. С помощью кастомных сервисов, которые мы пишем под конкретную систему записи, звонки и метаданные из них попадают в наш конвейер обработки, далее все это складывается, анализируется, и на выходе получаются отчеты, которые менеджер по качеству может получить за любой период и в любой детализации.
Как мы к этому пришли

Я отметил 5 пунктов:
модель;
входные данные;
выходные данные;
исправление ошибок;
контроль ресурсов.
Первая глобальная задача — получить из аудио качественный текст.
Наши data scientist’ы очень долго думали, проверяли кучу гипотез, читали статьи, научные исследования, начиная от акустико-фонетических подходов, таких как Vosk, Kaldi, и заканчивая хайповыми нейронками (DeepSpeech, Jasper и прочие). Но по качеству, скорости и стоимости транскрибирования, конечно, нейронки уделали всех.
Наша текущая нейронка чем-то похожа Jasper со своими инкодерами и декодерами, и целый транскрипт имеет ошибку по слову в 21%. Это достойный показатель по рынку, но мы продолжаем улучшение. За счёт проб других архитектур, более тонкой кастомизации, обучения под конкретные диалекты.
Итак, нейронку мы выбрали, теперь надо ее обучить. На первых порах мы брали открытые источники — CommonVoice, наборы от энтузиастов, аудиокниги. Сразу скажу, если думаете повторить наш путь — то будьте готовы к проведению колоссальной работы по очистке и верификации данных, качество там жуткое. Аудиокниги подошли бы, но, так как все это пишется в студиях, фона нет никакого, надо придумывать какие-то системы аугментации, шумы, все такое. Обучается хорошо, но при прогоне на зашумлённых записях сильно деградирует качество
Разбивка источников по качеству и доле в общей обучающей выборке (часы) у нас вышла такой.

Потом мы купили нескольких коммерческих датасетов. Тут тоже свои проблемы: качество в целом лучше, но все равно так себе, хотя продают за очень большие деньги. В общем, нам тоже не подошло. Тут мы, естественно, дошли до того, что нам нужно самим собирать все эти данные, и так родилась Таскания – платформа для формирования обучающих выборок.
Перед тем как загрузить данные в Тасканию, надо решить две проблемы, так как источником данных выступали наши контакт-центры.
Первая проблема – в аудиозвонках очень много лишней информации: компании, тарифы, цены, телефоны, паспортные данные, ФИО и тому подобное. Хоть системы обучения и не выходят за пределы закрытого контура, данная информация слишком катализированная и нужна для обучения. Спасибо DS-ам, они предложили нам системы деперсонализации, которые по некоторым шаблонам и специально обученным сетям могут вырезать из аудио эту всю лишнюю информацию и на их место вставить пустые данные. То есть после прогона через деперсонализаторы аудио можно направить нам, не боясь, что какая-то информация выйдет за пределы контакт-центра.
Вторая проблема – часть системы записи (там, где решили сэкономить место) пишет всё в одноканальном режиме, то есть в один канал записывается и оператор, и абонент. И опять DS’ы предоставили комбайн под названием “диаризация”, на основе АЧХ она позволяет нам из одного моноканала получить несколько аудиофайлов, в каждом аудиофайле будет только один говорящий, тем самым мы можем из монофайла сделать полифайл.
А что с Тасканией?
Таскания – это платформа, которая позволяет создавать датасеты, причем не только аудио, но еще видео, текст, что угодно.
Плюсы: это развернуто у нас в контуре, можно создавать несколько проектов, в каждом проекте куча заданий, кросс-валидация, отдельно задание на проверку заданий и система поощрений, что, наверное, очень приятно для исполнителя.
В поисках исполнителей мы кинули клич по организации, на него откликнулось очень много людей, которые и выполняли задания. Так и собрали (и продолжаем собирать) наши датасеты.
У нас была еще одна проблема, с которой следовало разобраться: проблема сервиса контакт-центров – надо как-то доставлять данные от клиента к нашим нейронкам. Мы перепробовали кучу разных вариантов, включая старые добрые Sftp/ Webdav. Затем нашли инструмент под названием Minio, облачное хранилище с адекватным API, стандартным s3like-интерфейсом и кучей дополнительных плюшек, системой мониторинга и логирования. Minio позволил нам получать от сервисов, которые мы написали для выгрузки, аудиофайлы в нашем контуре.

Ещё проблема — каждая система записи выгружает и пишет в своем качестве, в каждом формате свои метаданные. Так что без конвертера никуда, мы решили воспользоваться открытыми конвертерами. В итоге в начале нашего конвейера все аудиофайлы приводятся к одному формату.

Я на схемке написал G711, это не совсем точно, я больше подчеркнул, что мы выбрали наихудшее (= наименьшего качества) аудио, которое понимает нейронка и может понять человек, чтобы максимально охватить контакт-центры. То есть если они пишут 16 000 сэмплов, мы всегда это можем обрезать до 8 000. Кстати, сейчас мы прорабатываем механизм, при котором у нас появилась некая линейка нейронов по 8К, 16К, 32К, 44К. И аудио даунгрейдится до ближайшей, что позволяет ещё больше повысить качество.
А если они меньше 8000, увы, мы уже не сможем понять, что там сказано. Плюс опять же та же диаризация в конвейере, чтобы мы могли разделить аудиофайл на файл с агентом и файл с абонентом.
Кроме этого, мы добавили языковую модель, потому что наша нейронка выдает наружу всё так, как слышит, то есть если сказать “молоко”, она и напишет “малако”. Такой себе внеплановый фонетический разбор слова, который никто не заказывал.
Чтобы менеджеру по качеству было не так больно всё это читать, добавили пунктуацию и нормализацию фраз. Теперь у нас появилась возможность расставить все фразы с таймингом. На выходе — большой диалог, как в Телеграме, с которым комфортно работать.

Отдельно отмечу NVIDIA Triton – хороший инструмент, помогает как вертикально, так и горизонтально скалировать ресурсы GPU. Он нам очень сильно помог, потому что одни наши нейронки сильно нагружают GPU, а другие – лишь отчасти. Так как каждый сервис забирал на себя по одной GPU, мы очень нерационально расходовали ресурсы.

После перехода на Triton мы можем в рамках одного сервиса запускать кучу моделей разных форматов: и Tensor, и ONNX, и PyTorch. При этом можно держать несколько инстансов и горизонтально расставлять эти серверы там, где надо.
В общем, вот как и вот на чём работает наша аудиоаналитика, если что-то стоит раскрыть подробнее — пишите в комментариях, учту и отвечу.
