 Думаем, читателям нашего блога не нужно рассказывать подробно, что такое словарь ABBYY Lingvo. C этого продукта началась компания ABBYY 27 лет назад. Сначала словарь можно было использовать только на компьютерах, потом появились мобильные приложения и онлайн-сервисы. Недавно мы открыли доступ к словарям Lingvo для сторонних разработчиков на сайте https://developers.lingvolive.com – пока в бесплатном бета режиме.
Думаем, читателям нашего блога не нужно рассказывать подробно, что такое словарь ABBYY Lingvo. C этого продукта началась компания ABBYY 27 лет назад. Сначала словарь можно было использовать только на компьютерах, потом появились мобильные приложения и онлайн-сервисы. Недавно мы открыли доступ к словарям Lingvo для сторонних разработчиков на сайте https://developers.lingvolive.com – пока в бесплатном бета режиме.Под катом мы подробнее расскажем о том, как мы работали над этим сервисом и как его можно использовать.
Облачный Lingvo API можно использовать во многих сценариях. Например, включить функциональность перевода слов в приложение, в котором она не является основой: в мобильное приложение для путешественников, в игру, в электронную книгу или программу для чтения на смартфонах. Можно, например, добавить перевод к веб-приложению для изучения иностранных языков.
Сервис даёт возможность интегрировать в продукты полный или краткий перевод слов, толкование слов, исправление ошибок и подсказки верного написания, полнотекстовый поиск по статьям доступных словарей, отображение статьи из определенного словаря, формы слова и произношения. Разработчики получают доступ к 140 словарям различной тематики для 15 языков, для всех языков работает морфология. Русский и украинский языки выступают в парах с европейскими (английский, немецкий, французский, испанский, итальянский португальский, латынь, польский, греческий, датский), а также с китайским, казахским и татарским. Доступны словари общей лексики, толковые, а также тематические по направлениям: бухгалтерский учет и аудит, юриспруденция, программирование и менеджмент.
Перевод происходит полностью на стороне сервиса, от программ-пользователей требуется только возможность отправлять HTTP-запросы.
Lingvo API открыт для интеграции в программы для мобильных (iOS, Android), десктопных (Windows, Linux, Mac и т.д.) и веб-приложений бесплатно при ограничении на перевод в 50 000 знаков/сутки. В дальнейшем сервис будет платным с оплатой по мере использования, модель лицензирования пока в работе и прямо сейчас мы не сможем более подробно рассказать о том, какая она будет.
API сервиса
Чтобы начать использовать Lingvo API нужно зарегистрироваться на https://developers.lingvolive.com, используя адрес электронной почты, аккаунт в Facebook, VKontakte, Google, либо войти на сайт с помощью аккаунта Lingvo Live. Затем нужно добавить свое приложение на вкладке «Мои приложения». В бета режиме можно бесплатно зарегистрировать три приложения с лимитом в 50 000 знаков/сутки.
Новому приложению автоматически выдаётся стандартный набор словарей и ключ для доступа к API. С этим ключом приложение должно авторизоваться, получить токен для доступа, который нужно прикладывать в заголовок запросов к API. Как это сделать, описано в справке .
Клиентские приложения взаимодействуют с сервисом при помощи HTTP-запросов, они могут быть нескольких видов (методов):
1. В указанном направлении можно отправить слово или фразу и получить все словарные статьи из имеющихся словарей либо указать конкретный словарь и получить из него.
2. Можно получить часть словника, соответствующую введенному слову, фразе или части слова
3. Для слова или фразы можно получить краткий перевод, который является самым частотным переводом в имеющихся словарях
4. Искать можно не только по заголовкам словарных статей, но и по содержанию самих статей, т.е. в переводах и примерах
5. Конкретная словарная статья по идентификатору словаря и заголовку.
6. Варианты орфографической коррекции слова.
7. Таблица с формами слова (спряжение/формы по временам/множественное число и прочее).
8. Озвучка для слова.
По сути своей методы API повторяют методы движка Lingvo, упрощая доступ и автоматически подставляя некоторые параметры. Внутри каждого метода есть фильтрация по доступным приложению-клиенту словарям. Так как движок выдаёт всё в формате XML, для каждого метода мы превращаем всю выдачу в JSON.
Примеры запросов выложены здесь.
Как всё устроено внутри
Перед нами стояла задача – реализовать возможность доступа к движку через HTTP с любого устройства, имеющего выход в интернет. Кроме того, мы изначально хотели, чтобы сервис мог горизонтально масштабироваться. Выбрали для этого Microsoft Azure Cloud Services. Он совмещает возможность настроить автоматическое масштабирование с гибкостью настройки виртуальных машин.
Для настройки виртуальных машин в Cloud Service’е мы используем установочный скрипт, написанный на PowerShell. Он вызывается из CMD-скрипта (Azure CloudService умеет вызывать для начальной настройки машин CMD-скрипт, указанный в файле конфигурации) и выполняет следующие операции:
• разрешает выполнение 32-битных приложений (нужно для взаимодействия с движком);
• устанавливает модуль PowerShell для работы с Ажуром, если он ещё не был установлен;
• проверяет, установлен ли LingvoServer, и если нет, то скачивает Zip-архив из Azure BlobStorage, распаковывает его и запускает установщик LingvoServer.
Схематично архитектура решения выглядит так:
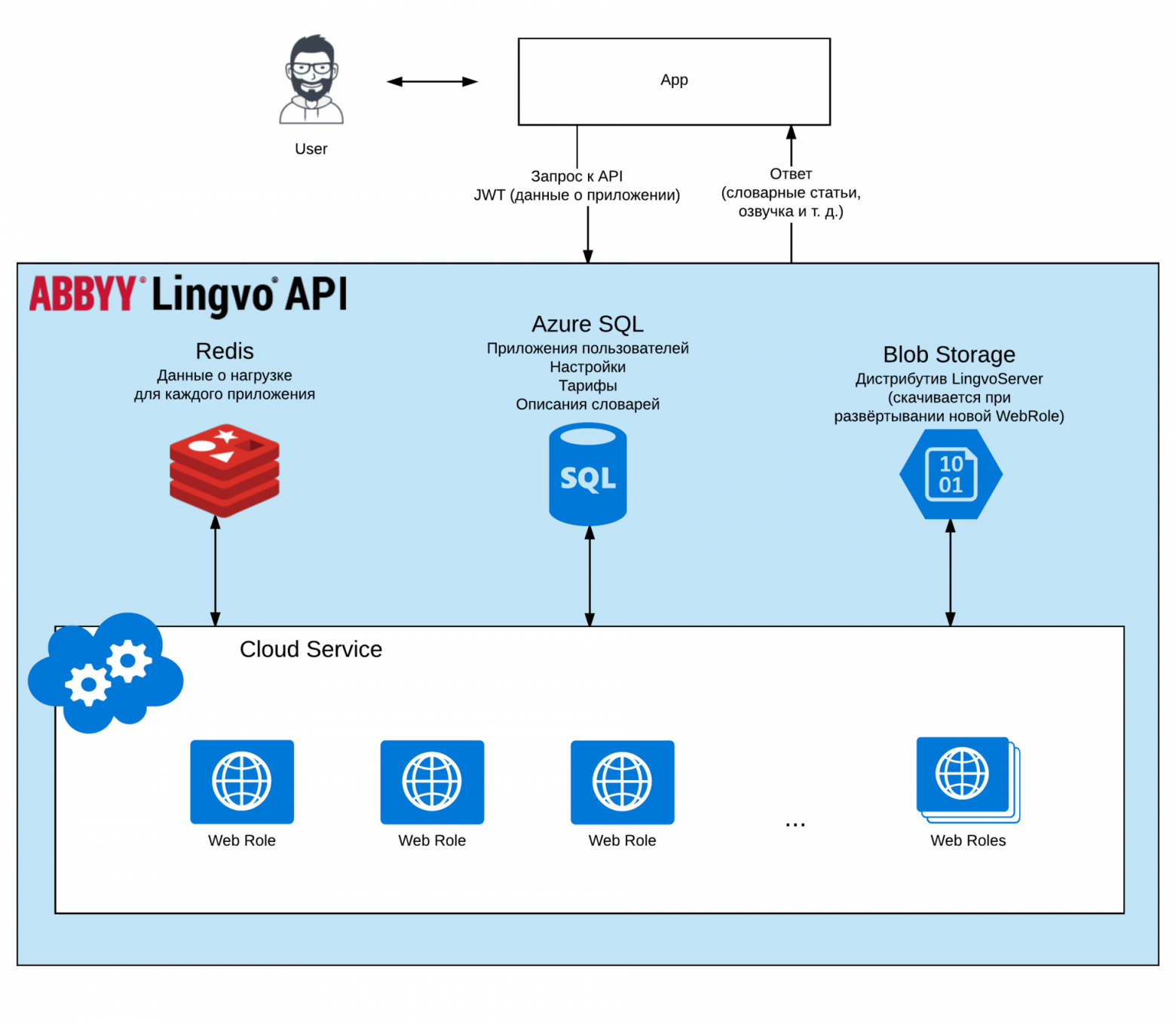
Есть базовая информация о пользовательском приложении, которая нам нужна для работы: это его идентификатор, с каким пользователем он связан и сколько символов ему можно потреблять в день. Эта информация хранится в токене, это JWT-токен, подписанный ключом, который есть только у нас. Зачем нужно держать это в токене? Чтобы не обращаться каждый раз к базе данных (Azure SQL на схеме), база данных одна, она не масштабируется горизонтально, мы не хотим её сильно нагружать.
У нас есть информация о том, сколько символов приложение уже потребило. Класть эту информацию в токен – неправильно, потому что тогда придётся каждый раз обновлять токен (а это лишняя нагрузка на пользователя нашего сервиса – ему придётся писать более сложный код и т.д.). Вместо этого информация хранится в Redis-кэше, это быстрый кэш, который умеет масштабироваться горизонтально, а значит, выдерживает бОльшую нагрузку, чем база данных.
Запрос клиентского приложения, содержащий токен, попадает на виртуальную машину (на схеме обозначена как web role). Это экземпляр виртуалки в MS Azure Cloud Service, на нем разворачивается наш API и движок Lingvo, на котором всё работает. Количество виртуальных машин изменяется в соответствии с параметрами автомасштабирования Cloud Service'а в зависимости от среднего уровня загрузки процессоров. Сам установщик движка (довольно большой по объёму) хранится в Blob Storage. Скачивается он только если ещё не установлен на конкретной виртуалке, чтобы не грузить при каждом обновлении сервиса.
Запрос пользователя проходит несколько этапов: валидация токена (в котором есть информация о том, что это за приложение и сколько символов ему можно вообще потреблять), если токен верный, то мы заглядываем в Redis-кэш и смотрим, сколько он уже потребил на данный момент. Ограничение объема потребляемых знаков делается с помощью алгоритма типа “leaky bucket”. Алгоритм обеспечивает обещанный объём потребления для приложения-клиента, ограничивая при этом возможную пиковую нагрузку. Объём возможной пиковой нагрузки задаётся через конфигурацию. Информация о доступном приложению количестве символов хранится в Redis-кэше и проверяется после проверки авторизации, непосредственно перед выполнением самого метода. Если он прошел проверку, и запрос проходит, то мы обращаемся к движку Lingvo внутри виртуальной машины и достаём ему ответ на его запрос.
Планы на будущее
Самый большой и самый важный план – хотим сделать движок Lingvo более быстрым, легко масштабируемым и улучшить качество поиска и формат поисковой выдачи. На текущий момент, как вы могли убедиться, ему не хватает более чёткой структуры. Как это сделать правильно – ещё думаем. Ну и, конечно, будем пополнять API новыми полезными методами.
Ещё планируем добавить в API обучающий контент и развивать на его базе адаптивные интеллектуальные алгоритмы, которые будут с помощью искусственного интеллекта строить индивидуальную модель обучения в зависимости от потребностей и уровня знаний пользователя.
Нам очень интересны ваши отзывы и пожелания! Пишите их в комментариях к этому тексту или по адресу lingvo.api@abbyy.com.
Примеры интеграции предшествующих версий Lingvo API
В заключение расскажем о нескольких приложениях с интегрированным Lingvo API. Сервис, который мы выпустили сейчас, — первый опыт реализации API наших словарей в облаке. Но несколько лет назад мы уже выпускали похожий продукт, который устанавливался непосредственно в устройства и работал только под Android. Он был встроен в несколько приложений для чтения книг: Yota Reader, Moon+ Reader, Moon+ Reader Pro и другие.
Разработчики Yota встроили Lingvo API в приложение Yota Reader, что позволило пользователям быстро получать перевод выделенного в тексте слова, не отрываясь от чтения.
Разработчик Android приложений для чтения электронных книг Moon+ Reader и Moon+ Reader Pro с помощью API Lingvo добавил в них функцию выдачи карточки с кратким переводом. При чтении книги на иностранном языке можно выделить слово, выбрать в меню «Словарь» и увидеть его перевод в рамках выбранной языковой пары.
Вот как выглядит перевод в приложении Moon+ Reader



Кирилл Крючков,
департамент Mobile & Lingvo Live
