
С китайского языка я еще не переводил:) Но мимо статьи ребят из ByteDance, которые разработали технологию VDUSE, пройти не смог. И хотя в название авторы вынесли «технологии виртуализации сети», на самом деле эти технологии применимы и к другим типам устройств — например, к дискам и видеокартам. Статья последовательно разбирает, как и почему развивались технологии виртуализации устройств, параллельно объясняя, как эти технологии работают, какие у них есть сильные и слабые стороны.
Через неделю после выхода этой статьи мы опубликовали собственное исследование о создании CSI-драйвера для Deckhouse Virtualization. Предлагаемый перевод служит отличным введением и помогает быстрее разобраться в тонкостях виртуализации устройств.
Виртуализация оборудования — одна из важнейших и фундаментальных технологий в области облачных вычислений. Без нее не смогло бы работать ни одно «устройство» внутри виртуальных машин: ни сетевая карта, ни диск, ни клавиатура, ни мышь и т. п. В статье мы проследим развитие технологий виртуализации оборудования в Linux.
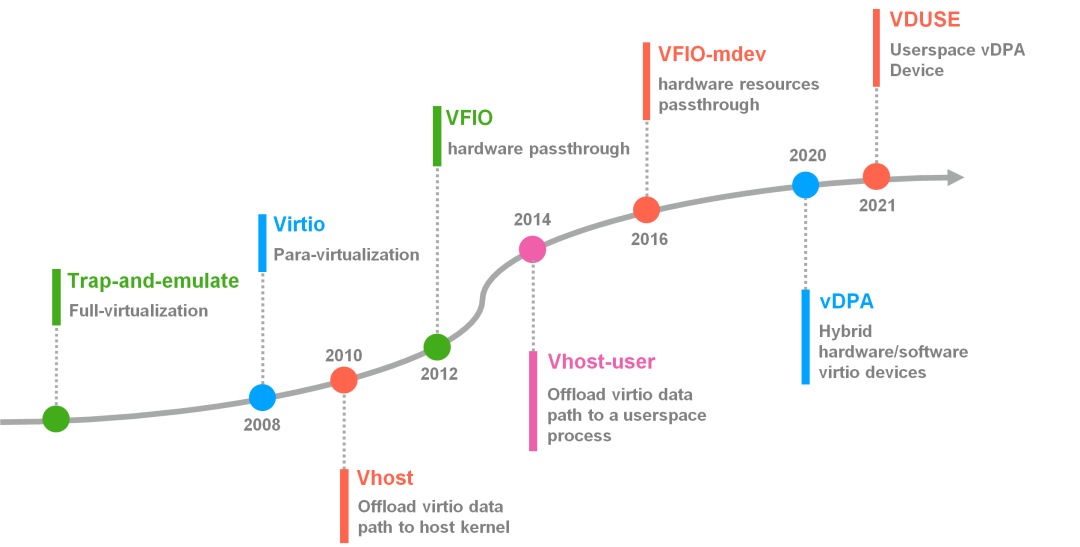
Содержание
Trap-and-emulate
На ранних этапах развития виртуализации оборудования технологии эмуляции машин, например, QEMU, часто использовали полную виртуализацию оборудования. С помощью QEMU мы можем эмулировать полный набор регистров и процедур управления реальных устройств. Когда драйвер внутри виртуальной машины обращается к регистрам устройства, инструкция перехватывается и обрабатывается QEMU. В итоге драйвер устройства внутри виртуальной машины работает с виртуальным устройством, как с реальным «железным», и может использоваться как есть, без каких-либо изменений (Прим. пер.: грубо говоря, можно скачать и использовать драйвер с сайта производителя конкретной модели реального устройства).

VirtIO
VirtIO — это уже технология паравиртуализации, которая была разработана для решения проблем с производительностью, присущих предыдущему подходу — trap-and-emulate. VirtIO была включена в основную ветку ядра Linux в 2008 году.
VirtIO не использует драйверы реальных устройств — вместо этого она определяет собственные драйверы, специально предназначенные для виртуальных устройств. В отличие от подхода trap-and-emulate, драйвер устройства VirtIO прекрасно знает, что оперирует виртуальным устройством, а не реальным. Это позволило избежать многочисленных ненужных операций MMIO/PIO, которые замедляли работу виртуальной машины при использовании trap-and-emulate из-за частых прерываний и обращений к ядру. Результат — повышение производительности ввода-вывода.
Механизм взаимодействия между драйвером VirtIO внутри виртуальной машины и виртуальным устройством, эмулированным QEMU, базируется на использовании общей памяти и кольцевой очереди. Базовая структура данных (split virtqueue) включает в себя два кольцевых буфера (avail ring и used ring), а также таблицу дескрипторов.
Узнать больше об устройстве технологии VirtIO можно из статей на английском языке:
• Buffers and notifications: The work routine (Red Hat)
• Introduction to VirtIO (Oracle)
Механика работы VirtIO схожа с DMA (Direct memory access). Внутри виртуальной машины драйвер VirtIO сначала записывает в дескрипторную таблицу адрес и длину буфера, который необходимо передать в память. После этого он записывает в кольцевой буфер доступных дескрипторов (avail ring) индекс дескрипторной таблицы, соответствующий этим дескрипторам, и уведомляет серверную часть VirtIO на хосте через механизм eventfd.
Поскольку все эти кольцевые буферы (ring-buffer), таблица дескрипторов (descriptor table) и буферы находятся в общей памяти — виртуальная машина, по сути, является процессом пользовательского пространства (user space), а ее память может взаимодействовать с другими процессами, например, с теми, которые управляются SPDK, DPDK и т. д. — VirtIO Backend тоже может напрямую обращаться к участкам этой общей памяти, чтобы сначала получить адрес и длину буфера, а затем и прямой доступ к буферу.
После обработки запроса VirtIO Backend заполняет соответствующие буферы, записывает индексы дескрипторов в кольцевой буфер used ring и отправляет прерывание с помощью механизма eventfd для уведомления драйвера VirtIO внутри виртуальной машины.

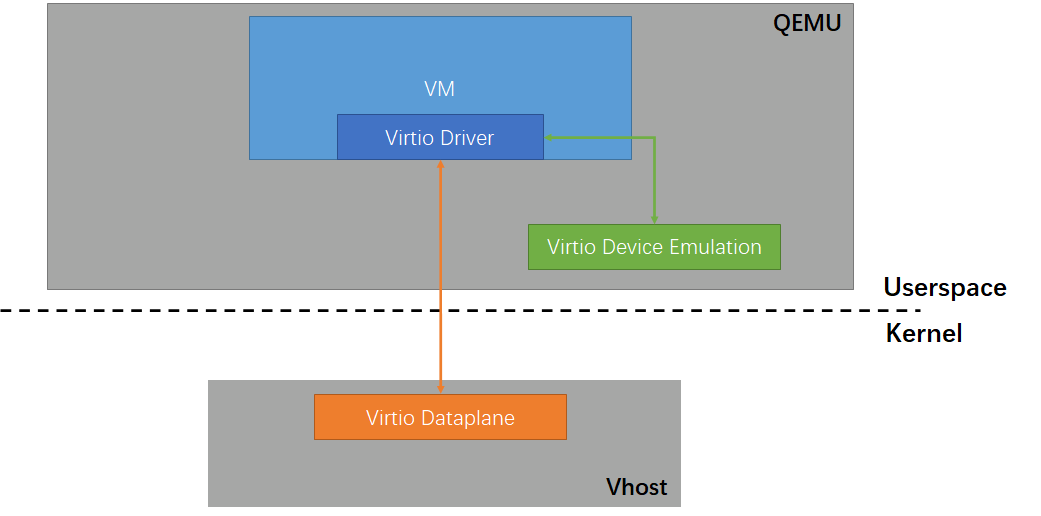
Vhost
После появления технологии VirtIO устройства чаще всего эмулировались самим QEMU. Поэтому процесс передачи и приёма данных проходил непосредственно через QEMU, так как он эти данные обрабатывал, а затем передавал внутрь виртуальной машины. Однако со временем разработчики подметили, что при эмуляции сетевых карт передача и прием данных сначала проходит через QEMU, а затем опять требует выполнения дополнительных системных вызовов и прерываний ядра для фактической передачи и приема данных на аппаратном уровне. Возник вопрос: можно ли оптимизировать эту операцию, чтобы избежать лишних накладных расходов на переключение контекста между QEMU и ядром, а также дополнительного копирования данных?
В итоге в 2010 году сообщество разработчиков ядра Linux представило технологию vhost. Эта технология оптимизирует весь процесс за счет того, что data plane VirtIO (передающий уровень, плоскость данных) выносится в отдельный поток ядра (kernel thread), который занимается исключительно обработкой данных.
Таким образом, механизм коммуникации VirtIO изменился: драйвер виртуальной машины теперь взаимодействует не с потоком пользовательского процесса QEMU, который эмулирует устройство, а с отдельным потоком ядра, обслуживающим vhost. После того, как поток ввода-вывода ядра, который обслуживает vhost для конкретной виртуальной машины, получает пакет данных, он передаёт их напрямую в стек сетевых протоколов ядра и драйвер сетевой карты для обработки, устраняя потери на переключение контекста между процессом QEMU и ядром.
VFIO
Масштабы облачных вычислений неуклонно росли, и пользователей перестала удовлетворять производительность, которую предлагали устройства, работающие по технологии VirtIO. В то же время все чаще возникала потребность в устройствах вроде GPU, которые сложно виртуализировать с использованием VirtIO. Так и появилась технология VFIO (Virtual Function I/O), которая была включена в основное ядро Linux в 2012 году. По сути, это фреймворк пользовательского пространства для драйверов устройств, то есть VFIO позволяет напрямую обращаться к драйверам устройств из процессов пользовательского пространства (user space), минуя ядро.
По сравнению с более ранним фреймворком UIO (Userspace I/O), VFIO способна эффективно использовать механизм аппаратного IOMMU (input/output memory management unit) для обеспечения безопасной изоляции процессов. Это позволяет использовать VFIO в облачных вычислениях, где необходима мультиарендность (multitenancy).
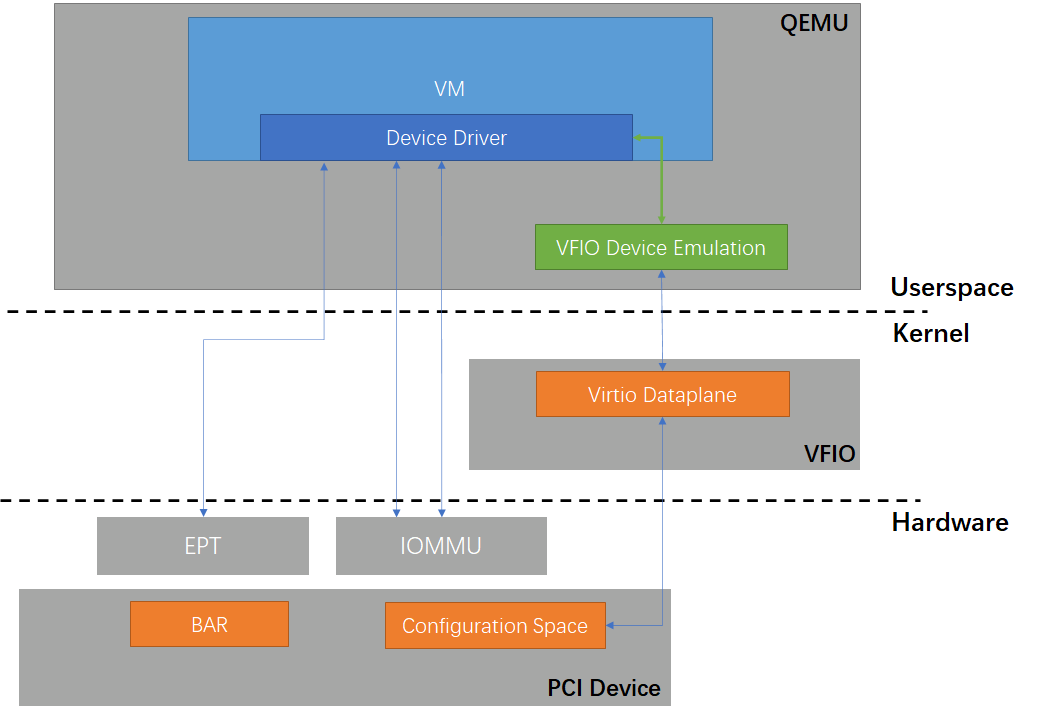
На вышеприведенной схеме видно, что благодаря VFIO QEMU может непосредственно связать свое виртуальное PCI-устройство с физическим PCI-устройством и обеспечить между ними прямой канал передачи данных. Когда драйвер устройства внутри виртуальной машины обращается к пространству BAR (Base Address Register) виртуального PCI-устройства, это MMIO-обращение благодаря механизму EPT (Extended Page Tables) перенаправляется на адрес в пространстве BAR, соответствующий реальному физическому устройству, и для QEMU отпадает необходимость перехватывать это обращение. То есть драйвер виртуальной машины может напрямую обращаться к реальному физическому устройству практически без накладных расходов, что обеспечивает оптимальную производительность.
В то же время драйвер VFIO использует IOMMU для переадресации DMA и прерываний устройства. С одной стороны, это обеспечивает строгую изоляцию — одна виртуальная машина не может получить прямой доступ к памяти устройства другой виртуальной машины, поднятой на том же хосте. С другой стороны, это гарантирует, что устройство, выполняющее DMA, может получить прямой доступ только к конкретной физической памяти определенной для этой виртуальной машины через предоставленные ей виртуальные адреса. В то же время драйвер VFIO использует IOMMU для реализации перенаправления DMA и прерываний устройства.
Vhost-user
Хотя VFIO и обеспечивает виртуальным машинам производительность операций ввода-вывода, близкую к физической машине, у этой технологии есть недостаток: она не поддерживает горячую миграцию (live-миграцию). То есть виртуальная машина с VFIO-устройствами не может быть смигрирована так же просто, как и виртуальная машина с обычными VirtIO-устройствами. Это привело к разработке новых технологий виртуализации устройств, которые одновременно были бы столь же производительными как VFIO и столь же гибкими как VirtIO.
Одной из таких технологий как раз и стала vhost-user, представленная в сообществе QEMU в 2014 году. Модель потоков QEMU и vhost не оптимизированы для работы с операциями ввода-вывода, а традиционный подход с выделением отдельного потока под обработку I/O-запросов для каждой виртуальной машины не всегда является оптимальным с точки зрения системы в целом. Поэтому в рамках технологии vhost-user разработчики предложили новый подход: вынести data plane VirtIO-устройств в отдельный процесс пользовательского пространства (user space).
Поскольку это отдельный процесс, он не ограничивается моделью потоков, которая традиционно используется в QEMU и vhost (QEMU выделяет под каждое устройство отдельный поток). А значит, этот процесс можно организовать и реализовать так, как нам удобно. Более того, такой процесс может обрабатывать I/O-запросы сразу от нескольких виртуальных машин в режиме 1:M, то есть когда один процесс (сервер) может обслуживать запросы от нескольких клиентов (виртуальных машин). И это уже куда более эффективный и масштабируемый подход к обработке I/O-запросов от виртуальных машин.
По сравнению с vhost, когда процесс выполняется в пространстве ядра (kernel space), пользовательские процессы обладают большей гибкостью в контексте управления и обслуживания. Фреймворк vhost-user быстро привлек внимание сообщества и стал фундаментом для построения новых моделей обслуживания I/O-запросов виртуальных машин, таких как SPDK и OVS-DPDK. Их особенность — драйверы, работающие в пользовательском пространстве, с которыми программы могут взаимодействовать, минуя ядро. Кроме того, в ходе работы эти драйверы не ожидают сообщений о завершении операций, а самостоятельно опрашивают устройства (polling).

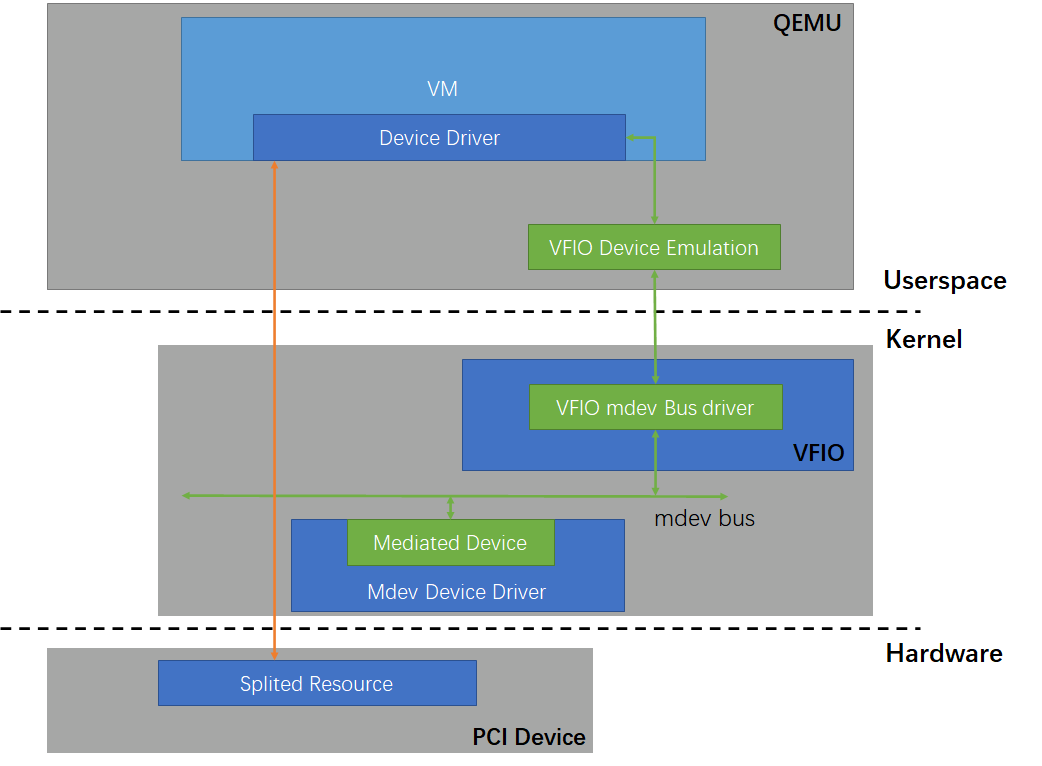
VFIO-mdev
В реальных сценариях использования у технологии VFIO проявляется еще одно ограничение, помимо отсутствия поддержки горячей миграции (live-миграции): одно устройство может быть передано только одной виртуальной машине, что не позволяет обеспечить совместное использование ресурсов. Технология SR-IOV в некоторой степени может решить эту проблему — она позволяет разделить одно физическое PCI-устройство на несколько Virtual Function-устройств и передать их сразу нескольким виртуальным машинам.
Однако большинство устройств не имеет поддержки SR-IOV (она должна обеспечиваться на аппаратном уровне), поэтому в 2016 году сообщество разработчиков ядра Linux включило в ядро фреймворк VFIO-mdev. Он предоставляет стандартизированный интерфейс, благодаря которому можно реализовать разделение физических ресурсов на программном уровне (в драйвере), а после этого передать их в несколько виртуальных машин с помощью VFIO.
Технология VFIO-mdev в основном реализована в ядре и представляет собой шину виртуальных устройств (mediated device), которая расширяет встроенный в ядро фреймворк VFIO. Она добавляет поддержку таких виртуальных устройств, как mdev (mdev bus driver). И если раньше можно было работать с данными, используя BAR-пространства аппаратных PCI-устройств, то теперь с данными можно работать как напрямую из физического устройства, так и через интерфейс виртуальных устройств, определенный драйвером mdev. (Прим. пер.: То есть теперь существует два сценария. В первом сценарии PCI-устройство представляет своё BAR-пространство, и это пространство используется QEMU для работы с этим устройством (классический VFIO). Во втором сценарии драйвер устройства представляет виртуальное устройство (mdev), которое имеет схожий интерфейс для взаимодействия с BAR-пространством и с которым QEMU умеет работать).
Например, если нам необходимо разделить ресурсы PCI-устройства, мы можем реализовать соответствующий драйвер устройства mdev: отрезать от BAR-пространства физического устройства отдельные части объемом кратным размеру страницы 4 КБ и отдавать их как mdev-устройства для использования разными виртуальными машинами.
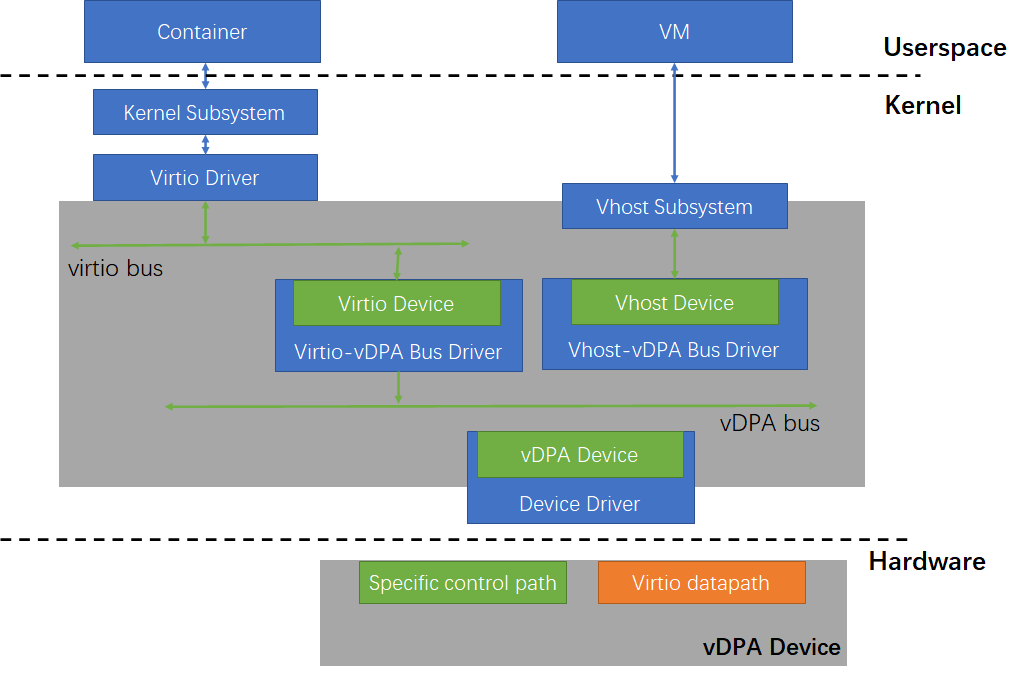
vDPA
VFIO и VirtIO долгое время оставались наиболее популярными технологиями виртуализации устройств. VFIO может напрямую предоставлять аппаратные ресурсы для использования виртуальными машинами и обеспечивать оптимальную производительность. А вот у VirtIO производительность немного ниже, зато эта технология более гибкая. Конечно же, есть соблазн объединить преимущества обеих технологий. Именно поэтому в 2020 году в основную ветку ядра Linux был включен фреймворк vDPA (VirtIO Data Path Acceleration).
vDPA представляет собой набор устройств, в котором data plane (уровень данных) строго соответствует спецификации протокола VirtIO (как мы описывали в соответствующем разделе этой статьи), а вот реализация control plane (управляющий уровень): например, адреса памяти кольцевого буфера (ring buffer) и дескрипторной таблицы (descriptor table), методы уведомления драйвера об изменениях, функции, которые поддерживает устройство, а также то, как всё это воплощено в драйвере — остается на усмотрение производителя устройства и может не следовать протоколу VirtIO. Это позволяет снизить сложность производства подобных устройств.
Фреймворк vDPA, который по своей сути аналогичен VFIO-mdev, также реализует шину виртуальных устройств (vDPA device). Однако в отличие от VFIO-mdev, устройства, виртуализированные с помощью фреймворка vDPA, могут использоваться как виртуальными машинами, так и хост-машиной (например, контейнерами).
Это становится возможным благодаря тому, что data plane vDPA-устройств соответствует протоколу VirtIO, а значит, драйвер VirtIO на хост-машине способен обращаться к подобным устройствам напрямую. Кроме того, этот фреймворк расширяет подсистему vhost в ядре, предоставляя функциональность, аналогичную VFIO: он позволяет предоставлять виртуальной машине прямой доступ к аппаратным ресурсам, которые используются для обмена данными с устройством vDPA (кольцевой буфер, таблица дескрипторов, регистр doorbell и т. д.). И когда драйвер VirtIO в виртуальной машине осуществляет обмен данными, он может напрямую обращаться к аппаратным ресурсам — без необходимости использовать подходы вроде vhost или vhost-user.
Еще более важно то, что если нам нужна поддержка live-миграции, QEMU может гибко переключаться на программную эмуляцию и обеспечивать успешное выполнение горячей миграции, так как драйвер виртуальной машины является обычным VirtIO-драйвером. Таким образом, фреймворк vDPA обеспечивает оптимальную производительность при сохранении гибкости устройств VirtIO, а также унифицирует стек I/O для виртуальных машин и контейнеров.
VDUSE
Фреймворк vDPA позволил решить старые наболевшие проблемы, связанные с технологией виртуализации устройств в сценариях использования виртуальных машин, а также, что немаловажно, принес технологию VirtIO в мир контейнеров. Однако в этом фреймворке все же оставалась проблема — необходимость поддержки со стороны физических устройств. А между тем, технологии VirtIO, vhost, vhost-user работают именно на программном уровне и не зависят от «железа».
Естественно, возникает вопрос: а можно ли и в фреймворке vDPA использовать программно-определяемые устройства? Для решения этой задачи и была разработана технология VDUSE. С ее помощью мы можем создать в пользовательском пространстве программно-определяемое устройство vDPA и подключить его к подсистемам VirtIO или vhost через тот же фреймворк vDPA. Это позволяет использовать такие устройства как в виртуальных машинах, так и в контейнерах.
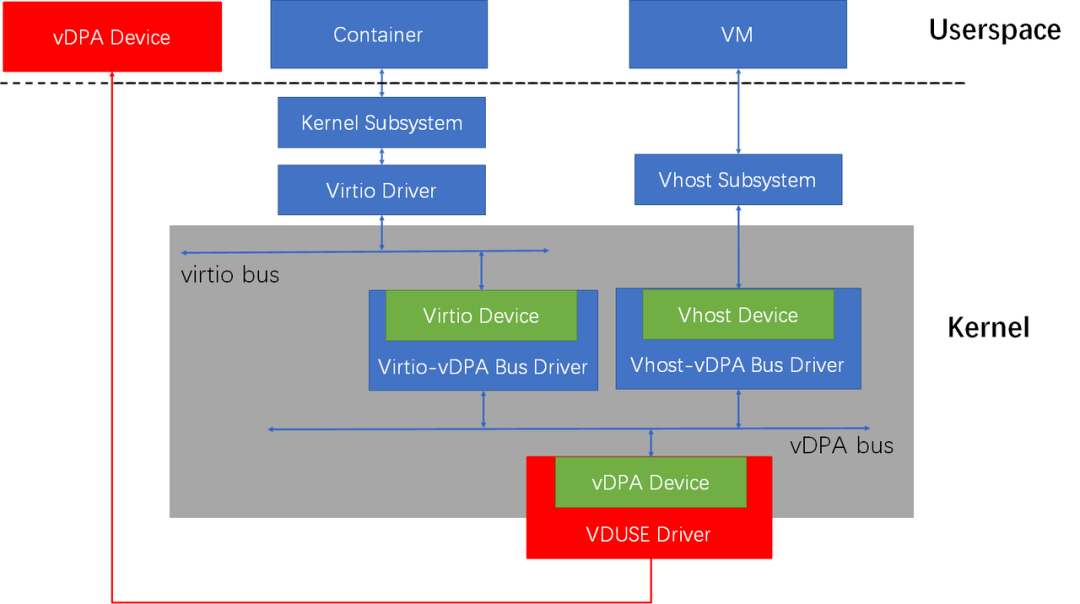
Эта технология была разработана нами (ByteDance), и мы официально представили ее Linux-сообществу в октябре 2020 года. На сегодняшний день наша реализация VDUSE уже включена в основное ядро Linux и будет представлена в версии Linux 5.15 (Прим. пер.: эта версия ядра вышла осенью 2021 года). Кроме того, мы планируем представить наше решение на высокопрофильной конференции виртуализации KVM Forum, которая пройдет 15 сентября 2021 года (Прим. пер.: уже есть видео доклада).
Заключение
В течение нескольких десятилетий технология виртуализации устройств Linux постоянно развивалась в разных направлениях: начиная с обслуживания виртуальных машин и поддержки контейнеров — и заканчивая сочетанием программного и аппаратного подходов, которые позволили достичь максимальной производительности и гибкости. Благодаря лавинообразному росту популярности облачных технологий и содействию крупных вендоров аппаратного обеспечения продолжают появляться новые удивительные технологии, которые объединяют софт и «железо».
Дополнительные источники:
P. S.
Читайте также в нашем блоге:
LVM+QCOW2, или Попытка создать идеальный CSI-драйвер для shared SAN в Kubernetes
В Kubernetes-платформе Deckhouse появилась система виртуализации нового поколения
KubeVirt: внутреннее устройство и сеть. Как достигнуть совершенства? (обзор и видео доклада)
Container Networking Interface (CNI) — сетевой интерфейс и стандарт для Linux-контейнеров
Смотрите также на нашем YouTube-канале:
