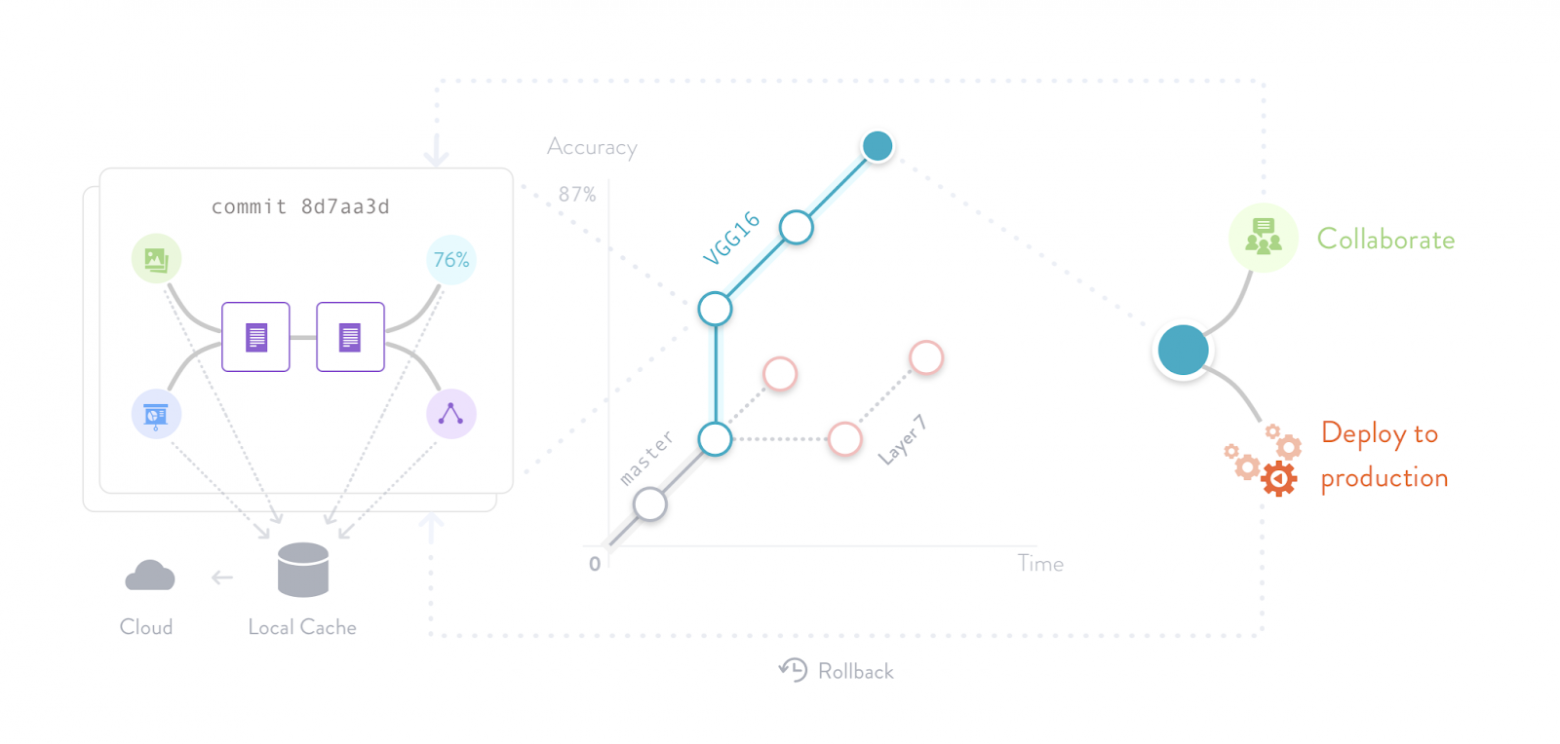
Data-science развивается очень быстро, в том числе благодаря росту объема доступных данных для анализа или построения моделей. Но для создания сложных моделей командам аналитиков нужно работать совместно и эффективно управлять большими датасетами. И вот здесь может помочь, например, DVC — open-source система контроля версий для проектов машинного обучения.
Нашел не так много информации по ней в рунете, поэтому под катом на примере простого ML-проекта расскажу, как работать с инструментом для хранения и обновления датасета.
Что ещё за DVC?
DVC (Data Version Control) предназначен для версионирования данных, моделей и экспериментов с их загрузкой в удаленное хранилище, а также специализированные инструменты для воспроизводимости экспериментов.
Инструмент нужен, если изменений в экспериментах становится много, а знания о версиях датасетов и моделей хранятся часто только в головах data-scientist'ов. DVC может хранить данные в локальном кэше или удаленном репозитории. Вариантов remote много: s3, gdrive, свой сервер с доступом по ssh и так далее.
По сути, мы отделяем код от данных и экспериментов вторым инструментом версионирования. DVC хранит данные отдельно от Git, но в Git-репозитории необходимо хранить сами хеши (md5) актуальных данных и экспериментов. Таким образом, в Git хранятся лишь ссылки на данные и эксперименты последней закомиченной версии — это позволяет работать с разными данными или моделями в разных ветках просто сохраняя нужные хеши в файлах .dvc.
Далее разберемся, как работать с DVC на примере простого ML-проекта.
ML-проектом в нашем случае будет классификатор котов и собак по фотографии — рассмотрим применение DVC как системы версионирования датасета с этими животными. По аналогии DVC может версионировать другие датасеты или сами модели классификаторов. Например, в FunCorp мы используем DVC для хранения размеченного датасета контента с nsfw-классами для задач автоматической модерации.
Установка
DVC можно установить для MacOS, Linux, Windows. Или он может быть загружен как библиотека в Python:
pip install dvcВ conda:
conda install -c conda-forge dvcПодробнее про установку можно прочитать на официальном сайте.
Но есть нюанс: если заранее знаете, что будете использовать как удаленное хранилище — лучше ставить пакет с необходимыми зависимостями: [s3], [azure], [gdrive], [gs], [oss], [ssh] или [all] для загрузки всех возможных. Для такой загрузки нужно набрать, например, pip install "dvc[s3]" — в таком случае дополнительно будет установлена библиотека boto3 для работы с s3.
Для удаленных хранилищ могут потребоваться ключи доступа и предварительная настройка.
Запуск
Предполагается, что DVC будет использоваться в корне папки под контролем Git, то есть рядом должна быть папка .git/. Но есть и другие варианты. Например, можно для экспериментов инициализировать DVC без Git, используя флаг --no-scm. Далее предполагается первый вариант настройки в корне и совместно с Git.
Инициализируем DVC в папке проекта:
dvc initТут как раз и возникает ошибка, так как папка не под Git.
olegsokolov@Olegs-MacBook-Pro dvc_demo_project % dvc init
ERROR: failed to initiate DVC - /Users/olegsokolov/dvc_demo_project is not tracked by any supported SCM tool (e.g. Git).
Use `--no-scm` if you don't want to use any SCM or `--subdir` if initializing inside a subdirectory of a parent SCM repository.Возьмем проект под контроль Git и попробуем снова.
olegsokolov@Olegs-MacBook-Pro dvc_demo_project % git init
Initialized empty Git repository in /Users/olegsokolov/dvc_demo_project/.git/
olegsokolov@Olegs-MacBook-Pro dvc_demo_project % dvc init
You can now commit the changes to git.Список файлов и папок внутри проекта теперь выглядит следующим образом:
olegsokolov@Olegs-MacBook-Pro dvc_demo_project % ls -f
. .. .dvc .git .dvcignoreТо есть при инициализации DVC создал папку .dvc с дефолтной конфигурацией и прочими необходимыми файлами, а также свой аналог .gitignore — .dvcignore.
Структура папок внутри .dvc:
olegsokolov@Olegs-MacBook-Pro dvc_demo_project % tree -a .dvc
.dvc
├── .gitignore
├── config
├── plots
│ ├── confusion.json
│ ├── confusion_normalized.json
│ ├── default.json
│ ├── linear.json
│ ├── scatter.json
│ └── smooth.json
└── tmpТеперь можно сделать коммит с изменениями проекта и добавить в проект наш датасет.
Добавление данных
По ссылке скачаем и добавим первый датасет в наш проект внутрь папки для датасетов datasets/. Он содержит фотографии котов и собак.
Структура папки датасетов проекта выглядит так:
.
└── ./datasets
└── ./datasets/PetImages
├── ./datasets/PetImages/Cat
└── ./datasets/PetImages/DogВнутри папок Cat и Dog лежит по 12501 изображений в jpg-формате.
Добавим этот датасет под трекинг DVC.
dvc add ./datasets/PetImageПосле этого DVC создает файл .dvc — слепок текущего состояния папки с данными, а также сохраняет сами данные в локальный кэш.
olegsokolov@Olegs-MacBook-Pro dvc_demo_project % ls ./datasets/
PetImages PetImages.dvcФайл PetImages.dvc выглядит следующим образом:
olegsokolov@Olegs-MacBook-Pro dvc_demo_project % cat ./datasets/PetImages.dvc
outs:
- md5: b2c461b1b0bcb7a0a2318d5be1f13758.dir
size: 866190740
nfiles: 25002
path: PetImagesА внутри папки .dvc/ появился локальный кэш данных, где DVC хранит реальные партиции данных, а не ссылки. Важно, что данный кэш находится в .gitignore, то есть файлы локального кэша, не попадут в Git-репозиторий.
Попробуем запушить локальный кэш в удаленное DVC хранилище командой dvc push.
dvc push data/
ERROR: failed to push data to the cloud - config file error: no remote specified. Create a default remote with
dvc remote add -d <remote name> <remote url>Ошибка! Конечно, ведь мы не добавили никакого удаленного хранилища. Хоть DVC и создал дефолтную конфигурацию, но нам также нужно настроить наш удаленный remote, где будут хранится данные и откуда мы будем их забирать на других машинах.
Добавление remote
Повторюсь, как и Git, DVC может работать, сохраняя все изменения локально. Но для работы в команде необходимо удаленное хранилище (remote) для данных и экспериментов. И вариантов remote много. У каждого могут быть свои специфичные настройки и требования. Ниже приведен пример c настройкой remote как bucket на s3.
Предварительно создаем bucket в s3. Я назвал dvc-demo-project:
olegsokolov@Olegs-MacBook-Pro dvc_demo_project % dvc remote add -d myremote s3://dvc-demo-project
Setting 'myremote' as a default remote.Флаг -d значит, что этот репозиторий будет дефолтным (можно настроить несколько репозиториев, например, для разных датасетов).
Попробуем запушить оригиналы снова:
dvc push
ERROR: failed to push data to the cloud - Unable to find AWS credentials. <https://error.dvc.org/no-credentials>: Unable to locate credentialsДанная ошибка говорит о том, что ни в локальных, ни в глобальных файлах конфигурации DVC нет информации о способе аутентификации в AWS. Необходимо добавить один из вариантов доступа.
Я выбрал доступ по профилю:
dvc remote modify myremote profile myprofileТеперь файл конфигурации DVC выглядит так:
olegsokolov@Olegs-MacBook-Pro dvc_demo_project % cat .dvc/config
[core]
remote = myremote
['remote "myremote"']
url = s3://dvc-demo-project
profile = myprofileТеперь можно пушить файлы в удаленное хранилище.
olegsokolov@Olegs-MacBook-Pro dvc_demo_project % dvc push
24972 files pushedДля того, чтобы убедиться в наличие данных удаленно, можно почистить локальный кэш или клонировать Git-проект с нуля.
Важно! Не забывайте добавлять .dvc файлы и конфигурации (кроме приватных) под версионирование в .git. Чтобы после команды git pull можно было выполнить загрузку датасетов через dvc pull. Без этих файлов локально DVC не сможет скачать файлы при стандартной настройке. Также важно не забывать коммитить в Git .dvc-файлы после обновления датасетов (после каждой команды dvc add), иначе DVC скачает прошлую версию файла по хэшам из .dvc файлов, только если вы специально не хотите подгрузить старую версию модели или датасета из DVC-хранилища.
Загрузка данных
В нашем примере для загрузки датасета локально из удаленного хранилища можно выполнить загрузку всех данных.
dvc pullИли конкретного датасета.
dvc pull datasets/PetImages.dvcПосле этого папка PetImages с оригиналами изображений появится в datasets/
Обновление данных
Если мы убрали часть данных в датасете, то DVC обсчитывает именно входящие файлы в папку и сам это мониторит.
При удалении делаем dvc add, в локальный кэш добавляются сведения об удалении файлов, и когда потом делаем пуш — он просто особым образом пересчитывает хэш, а при загрузке на новых машинах по новому хэшу скачает то, что нужно без дополнительных манипуляций. Хэш привязывается к текущему состоянию файлов и отражает все изменения — весь датасет качать не придется, а изменения скачиваются достаточно быстро. Таким образом, упрощается работа с датасетом, папками и их дистрибуцией на разные машины.
Также можно хранить и модели. Есть, конечно, Git Large File, но обычный Git имеет ограничение 100 мб, а DVC имеют массу специфичных фич для data-science
Например, DVC позволяет делать оценки и тест моделей, сохранить их состояние до обучения и это состояние потом воспроизвести. Легко организовать воспроизводимые эксперименты. Бывают задачи по воспроизведению экспериментов, чтобы посмотреть, что все нормально при, допустим, изменении окружения. Есть пайплайн, который это запускает.
Особенности и минусы
У DVC отличная документация, все основные команды описаны, поэтому лучше первым делом прочитать ее на официальном сайте.
DVC часто выкатывает апдейты и фиксит баги, но нужно следить, чтобы функциональность не пострадала. Если в Docker файле делать pip install dvс, он поставит последнюю версию — так что стоит зафиксировать стабильную версию и ее периодически обновлять, чтобы старые конфигурации не сломали новую версию. А меняться там может многое, например, в файлы .dvc добавляются новые поля и названия конфигураций.Также могут быть проблемы с кэшем — он может разрастаться. Если датасет весит 1 Гб и его периодически меняем, совсем не факт, что удаленный кэш будет равен всем изменениям — может быть больше, биться на файлы. Будет непонятно, из-за чего это произошло и придется чистить.Еще могут быть проблемы с данными при переезде в новый remote — их нужно перезагружать и проверять. Бывает легче запушить по новой, будто это новые файлы, чем синхронизировать кэш на новом удаленном хранилище.
Следующий момент связан с использованием инструмента в команде. Вещь может показаться очевидной, но она очень важная. Обо всех обновлениях и изменениях нужно сообщать команде где-то еще. Например, обновление датасета или создание новой ветки описывать словами — что за изменения и зачем они нужны. Сам DVC не особо много подписывает — хэш из файла dvc вам ничего не скажет (видны только файлы, но не суть изменений). Но в каждой команде это может работать по-разному.
Заключение
DVC быстроразвивающийся (7500 звезд на GitHub) и удобный инструмент для нужд data-science и не только. Он отлично подходит для хранения датасетов и моделей машинного обучения. Документация понятная и содержит информацию по частым ошибкам конфигурации. Инструмент имеет множество прочих специальных команд для организации экспериментов (см. dvc run).
Также для более сложных ML-пайплайнов с деплоем сервисов у iterative.ai есть еще инструмент для CICD моделей — CML.
