В деле удалённого вызова процедур дела уже давно обстоят в точности как в известном комиксе «14 стандартов» — чего только тут ни напридумано: древние DCOM и Corba, странные SOAP и .NET Remoting, современные REST и AMQP (да, я знаю, что кое-что из этого формально не RPC, для того чтобы обсудить терминологию даже вот специальный топик недавно создали, тем ни менее всё это используется как RPC, а если что-то выглядит, как утка и плавает, как утка — ну, вы в курсе).
И конечно же, в полном соответствии со сценарием комикса, на рынок пришел Google и заявил что вот теперь наконец он создал ещё один, последний и самый правильный стандарт RPC. Google можно понять — продолжать в 21-ом веке гонять петабайты данных по старому и неэффективному HTTP+REST, теряя на каждом байте деньги — просто глупо. В то же время взять чужой стандарт и сказать «мы не смогли придумать ничего лучше» — совершенно не в их стиле.
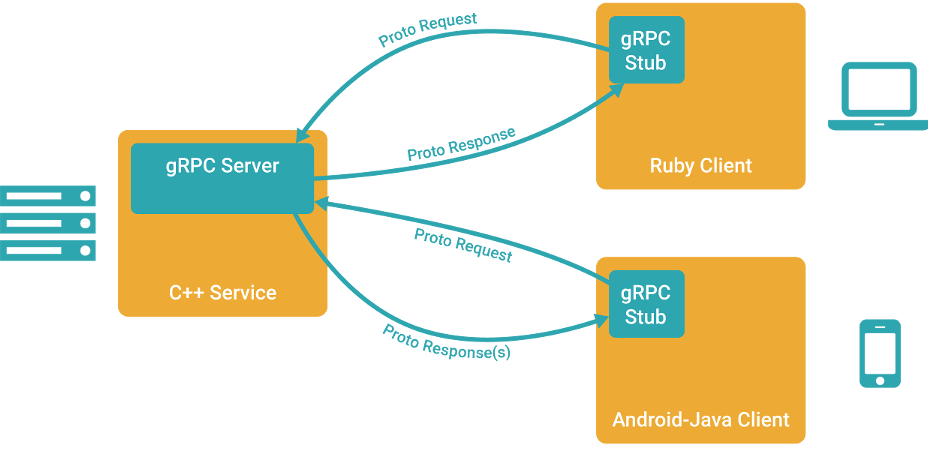
Поэтому, встречайте, gRPC, что расшифровывается как «gRPC Remote Procedure Calls» — новый фреймворк для удалённого вызова процедур от Google. В этой статье мы поговорим о том, почему же он, в отличии от предыдущих «14 стандартов» всё-таки захватит мир (ну или хотя бы его часть), попробуем собрать билд gRPC под Windows + Visual Studio (и даже не говорите мне, что инструкция не нужна — в официальной документации упущено штук 5 важных шагов, без которых ничего не собирается), а также попробуем написать простенький сервис и клиент, обменивающиеся запросами и ответами.
Зачем нужен ещё один стандарт?
Прежде всего давайте оглянемся вокруг. Что мы видим? Мы видим REST + HTTP/1.1. Нет, есть всякое, но именно эта туча закрывает добрых три четверти небосвода клиент-серверных коммуникаций. Присмотревшись ещё чуть пристальнее, мы видим, что REST в 95% случаев вырождается в CRUD.
В итоге мы имеем:
- Неэффективность протокола HTTP/1.1 — несжатые заголовки, отсутствие полноценной двусторонней связи, неэффективный подход к использованию ресурсов ОС, лишний трафик, лишние задержки.
- Необходимость натягивать нашу модель данных и событий на REST+CRUD, что часто получается, как воздушный шарик на глобус и вынуждает Яндекс писать вот такие, бесспорно, очень хорошие статьи, которые, однако, были бы не нужны, если бы людям не приходилось думать «Чем же вызвать заклинание для призыва элементаля — PUT'ом или POST'ом? И какой же HTTP-код вернуть, чтобы он означал „Перейдите на 3 клетки вперёд и тяните новую карту“ ?»
Именно с этого места и начинается gRPC. Итак, из коробки мы имеем:
- Protobuf в качестве инструмента описания типов данных и сериализации. Очень классная и хорошо зарекомендовавшая себя на практике штука. Собственно говоря, те, кому была нужна производительность — и раньше брали Protobuf, а дальше уже отдельно заморачивались транспортом. Теперь всё в комплекте.
- HTTP/2 в качестве транспорта. И это невероятно мощный ход! Вся прелесть полного сжатия данных, контроля трафика, инициации событий с сервера, переиспользования одного cокета для нескольких параллельных запросов — красотища.
- Статические пути — никаких больше «сервис/коллекция/ресурс/запрос? параметр=значение». Теперь только «сервис», а что внутри — описывайте в терминах вашей модели и её событий.
- Никакого привязывания методов к HTTP-методам, никакого привязывания возвращаемых значений к HTTP-статусам. Пишите, что хотите.
- SSL/TLS, OAuth 2.0, аутентификация через сервисы Google, плюс можно прикрутить свою (например, двухфакторную)
- Поддержка 9-ти языков: C, C++, Java, Go, Node.js, Python, Ruby, Objective-C, PHP, C# плюс, конечно, никто не запрещает взять и реализовать свою версию хоть для брейнфака.
- Поддержка gRPC в публичных API от Google. Уже работает для некоторых сервисов. Нет, REST-версии, конечно, тоже останутся. Но посудите сами, если у вас будет выбор — использовать, скажем, из мобильного приложения REST-версию, отдающие данные за 1 сек или с теми же затратами на разработку взять gRPC-версию, работающую 0.5 сек — что вы выберете? А что выберет ваш конкурент?
Сборка gRPC
Нам понадобитья:
- Git
- Visual Studio 2013 + Nuget
- CMake
Забираем код
- Забираем репозипорий gRPC с Гитхаба
- Выполняем команду
git submodule update --init
— это нужно для того, чтобы скачать зависимости (protobuf, openssl и т.д.).
Собираем Protobuf
- Переходим в папку grpc\third_party\protobuf\cmake и создаём там папку build, переходим в неё.
- Выполняем команду
cmake -G «Visual Studio 12 2013» -DBUILD_TESTING=OFF… - Открываем созданный на предыдущем шаге файл protobuf.sln в Visual Studio и собираем (F7).
На этом этапе мы получаем ценные артефакты — утилиту protoc.exe, которая понадобиться нам для генерации кода сериализации\десериализации данных и lib-файлы, которая будут нужны при линковке gRPC. - Копируем папку grpc\third_party\protobuf\cmake\build\Debug в папку grpc\third_party\protobuf\cmake.
Ещё раз — папку Debug нужно скопировать на 1 уровень выше. Это какая-то неконсистентность в документациях gRPC и Protobuf. В Protobuf говорится, что всё билдить надо в папке build, а вот исходники проектов gRPC ничего об этой папке не знают и ищут библиотеки Protobuf прямо в grpc\third_party\protobuf\cmake\Debug
Собираем gRPC
- Открываем файл grpc\vsprojects\grpc_protoc_plugins.sln и собираем его.
Если вы верно прошли сборку Protobuf на предыдущем этапе — всё должно пройти гладко. Теперь у вас есть плагины к protoc.exe, которые позволяют ему не только генерировать код сериализации\десериализации, но и добавлять в него функционал gRPC (собственно говоря, удалённый вызов процедур). Плагины и protoc.exe нужно положить в одну папку, например, в grpc\vsprojects\Debug. - Открываем файл grpc\vsprojects\grpc.sln и собираем его.
По ходу сборку должен запуститься Nuget и скачать необходимые зависимости (openssl, zlib). Если у вас нет Nuget или он почему-то не скачал зависимости — будут проблемы.
По окончанию билда у нас появятся все необходимые библиотеки, которые мы сможем использовать в нашем проекте для коммуникаций через gRPC.
Наш проект
Давайте напишем такой себе API для Хабрахабра с применением gRPC
Методы у нас будут такие:
- GetKarma будет получать строку с именем пользователя, а возвращать дробное число со значением его кармы
- PostArticle будет получать запрос на создание новой статьи со всеми её метаданными, а возвращать результат публикации — структуру со ссылкой на статью, временем публикации ну и текстом ошибки, если публикация не удалась
Это всё нам нужно описать в терминах gRPC. Это будет выглядеть как-то так (описание типов можно посмотреть в документации на protobuf):
syntax = "proto3";
package HabrahabrApi;
message KarmaRequest {
string username = 1;
}
message KarmaResponse {
string username = 1;
float karma = 2;
}
message PostArticleRequest {
string title = 1;
string body = 2;
repeated string tag = 3;
repeated string hub = 4;
}
message PostArticleResponse {
bool posted = 1;
string url = 2;
string time = 3;
string error_code = 4;
}
service HabrApi {
rpc GetKarma(KarmaRequest) returns (KarmaResponse) {}
rpc PostArticle(PostArticleRequest) returns (PostArticleResponse) {}
}
Переходим в папку grpc\vsprojects\Debug и запускаем там 2 команды (кстати, обратите внимание, в официальной документации в этом месте ошибка, неверные аргументы):
protoc --grpc_out=. --plugin=protoc-gen-grpc=grpc_cpp_plugin.exe habr.proto
protoc --cpp_out=. habr.proto
На выходе мы получим 4 файла:
- habr.pb.h
- habr.pb.cc
- habr.grpc.pb.h
- habr.grpc.pb.cc
Это, как не сложно догадаться, заготовки наших будущих клиента и сервиса, которые смогут обмениваться сообщениями по описанному выше протоколу.
Давайте уже создадим проект!
- Создаём в Visual Studio новый solution, назовём его HabrAPI.
- Добавляем в него два консольных приложения — HabrServer и HabrClient.
- Добавляем в них сгенерированные на предыдущем шаге h и сс-файлы. В сервер надо включать все 4, в клиент — только habr.pb.h и habr.pb.cc.
- Добавляем в настройках проектов в Additional Include Directories путь к папкам grpc\third_party\protobuf\src и grpc\include
- Добавляем в настройках проектов в Additional Library Directories путь к grpc\third_party\protobuf\cmake\Debug
- Добавляем в настройках проектов в Additional Dependencies библиотеку libprotobuf.lib
- Выставляем тип линковки таким же, с каким был собран Protobuf (свойство Runtime Library на вкладке Code Generation). В этом месте может оказаться, что вы не собрали Protobuf в нужной вам конфигурации, и придётся вернуться и пересобрать его. Я выбирал и там и там /MTd.
- Добавляем через Nuget зависимости на zlib и openssl.
Теперь у нас всё собирается. Правда, ничего пока ещё не работает.
Клиент
Здесь всё просто. Во-первых, нам нужно создать класс, унаследованный от заглушки, сгенерированной в habr.pb.h. Во-вторых, реализовать в нём методы GetKarma и PostArticle. В-третьих, вызывать их и, к примеру, выводить результаты в консоль. Получится как-то так:
#include <iostream>
#include <memory>
#include <string>
#include <grpc/grpc.h>
#include <grpc++/channel.h>
#include <grpc++/client_context.h>
#include <grpc++/create_channel.h>
#include <grpc++/credentials.h>
#include "habr.grpc.pb.h"
using grpc::Channel;
using grpc::ChannelArguments;
using grpc::ClientContext;
using grpc::Status;
using HabrahabrApi::KarmaRequest;
using HabrahabrApi::KarmaResponse;
using HabrahabrApi::PostArticleRequest;
using HabrahabrApi::PostArticleResponse;
using HabrahabrApi::HabrApi;
class HabrahabrClient {
public:
HabrahabrClient(std::shared_ptr<Channel> channel)
: stub_(HabrApi::NewStub(channel)) {}
float GetKarma(const std::string& username) {
KarmaRequest request;
request.set_username(username);
KarmaResponse reply;
ClientContext context;
Status status = stub_->GetKarma(&context, request, &reply);
if (status.ok()) {
return reply.karma();
} else {
return 0;
}
}
bool PostArticle(const std::string& username) {
PostArticleRequest request;
request.set_title("Article about gRPC");
request.set_body("bla-bla-bla");
request.set_tag("UFO");
request.set_hab("Infopulse");
PostArticleResponse reply;
ClientContext context;
Status status = stub_->PostArticle(&context, request, &reply);
return status.ok() && reply.posted();
}
private:
std::unique_ptr<HabrApi::Stub> stub_;
};
int main(int argc, char** argv) {
HabrahabrClient client(
grpc::CreateChannel("localhost:50051", grpc::InsecureCredentials(),
ChannelArguments()));
std::string user("tangro");
std::string reply = client.GetKarma(user);
std::cout << "Karma received: " << reply << std::endl;
return 0;
}
Сервер
С сервером похожая история — мы наследуемся от класса сервиса, сгенерированного в habr.grpc.pb.h и реализуем его методы. Дальше мы запускаем слушателя на определённом порту, ну и ждём клиентов. Как-то вот так:
#include <iostream>
#include <memory>
#include <string>
#include <grpc/grpc.h>
#include <grpc++/server.h>
#include <grpc++/server_builder.h>
#include <grpc++/server_context.h>
#include <grpc++/server_credentials.h>
#include "habr.grpc.pb.h"
using grpc::Server;
using grpc::ServerBuilder;
using grpc::ServerContext;
using grpc::Status;
using HabrahabrApi::KarmaRequest;
using HabrahabrApi::KarmaResponse;
using HabrahabrApi::PostArticleRequest;
using HabrahabrApi::PostArticleResponse;
using HabrahabrApi::HabrApi;
class HabrahabrServiceImpl final : public HabrApi::Service {
Status GetKarma(ServerContext* context, const KarmaRequest* request,
KarmaResponse* reply) override {
reply->set_karma(42);
return Status::OK;
}
Status PostArticle(ServerContext* context, const PostArticleRequest* request,
PostArticleResponse* reply) override {
reply->set_posted(true);
reply->set_url("some_url");
return Status::OK;
}
};
void RunServer() {
std::string server_address("0.0.0.0:50051");
HabrahabrServiceImpl service;
ServerBuilder builder;
builder.AddListeningPort(server_address, grpc::InsecureServerCredentials());
builder.RegisterService(&service);
std::unique_ptr<Server> server(builder.BuildAndStart());
std::cout << "Server listening on " << server_address << std::endl;
server->Wait();
}
int main(int argc, char** argv) {
RunServer();
return 0;
}
Удачи вам в использовании gRPC.

