Цикл for в R может быть очень медленным, если он применяется в чистом виде, без оптимизации, особенно когда приходится иметь дело с большими наборами данных. Есть ряд способов сделать ваш код быстрее, и вы, вероятно, будете удивлены, узнав насколько.
Эта статья описывает несколько подходов, в том числе простые изменения в логике, параллельную обработку и
Давайте попробуем ускорить код с циклом for и условным оператором (if-else) для создания колонки, которая добавляется к набору данных (data frame, df). Код ниже создает этот начальный набор данных.
В первой части: векторизация, только истинные условия, ifelse.
В этой части: which, apply, побайтовая компиляция, Rcpp, data.table, результаты.
Используя команду
Используем функцию
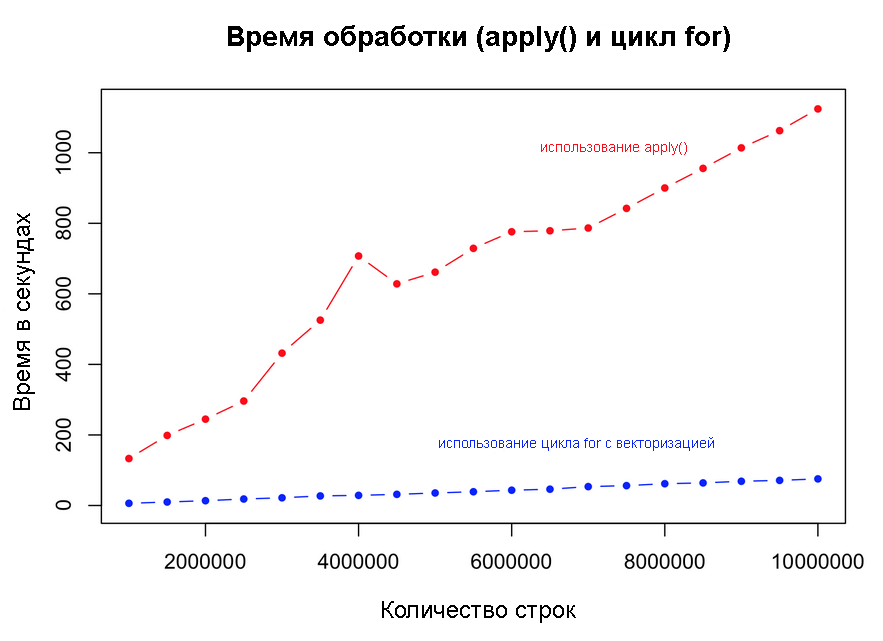
Использование apply и цикла for в R
Это, наверное, не лучший пример для иллюстрации эффективности побайтовой компиляции, поскольку полученное время немного выше, чем обычная форма. Однако, для более сложных функций побайтовая компиляция доказала свою эффективность. Думаю, стоит попробовать при случае.
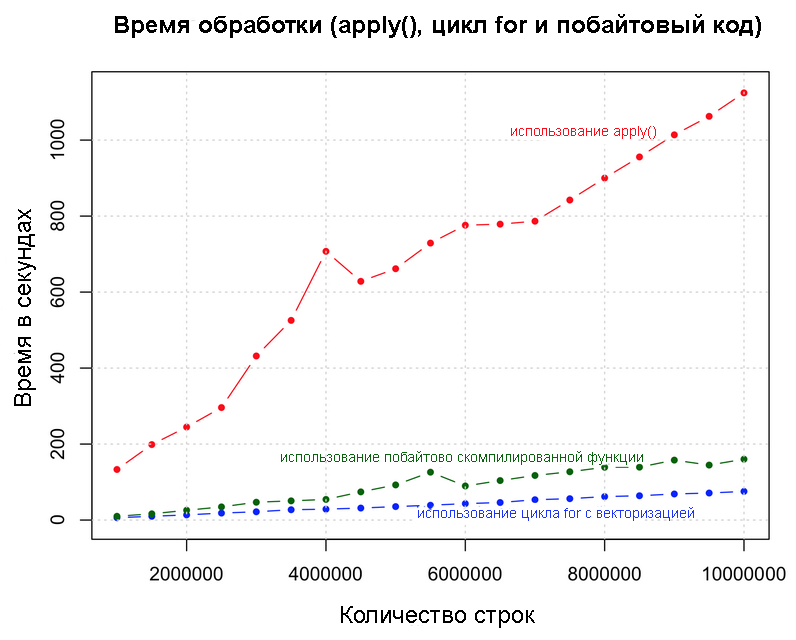
Apply, цикл for и побайтовая компиляция кода
Давайте выйдем на новый уровень. До этого мы увеличивали скорость и производительность с помощью различных стратегий и обнаружили, что использование
Ниже приведена та же логика, реализованная на С++ с помощью пакета Rcpp. Сохраните код ниже как «MyFunc.cpp» в вашей рабочей директории сессии R (или вам придется применять sourceCpp, используя полный путь). Обратите внимание, комментарий
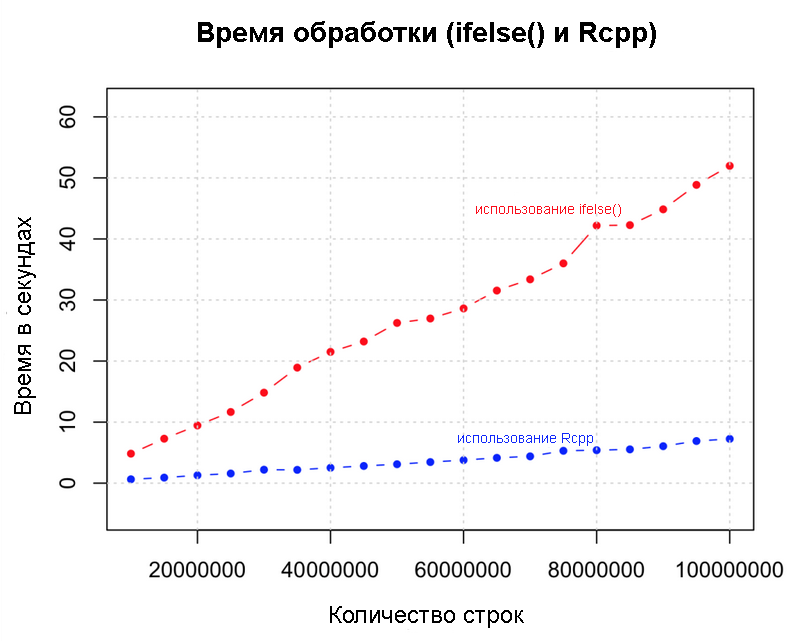
Производительность
Параллельная обработка:
Удаляйте больше ненужные объекты в коде с помощью

Dataframe и data.table
Метод: Скорость, количество строк в df / затраченное время = n строк в секунду
Исходный: 1X, 120000/140.15 = 856.2255 строк в секунду (нормализировано к 1)
Векторизированный: 738X, 120000/0.19 = 631578.9 строк в секунду
Только истинные условия: 1002X, 120000/0.14 = 857142.9 строк в секунду
ifelse: 1752X, 1200000/0.78 = 1500000 строк в секунду
which: 8806X, 2985984/0.396 = 7540364 строк в секунду
Rcpp: 13476X, 1200000/0.09 = 11538462 строк в секунду
Числа, приведенные выше, приблизительны и основаны на случайных запусках. Нет расчетов результатов для
Эта статья описывает несколько подходов, в том числе простые изменения в логике, параллельную обработку и
Rcpp, увеличивая скорость на несколько порядков, так что можно будет нормально обрабатывать 100 миллионов строк данных или даже больше. Давайте попробуем ускорить код с циклом for и условным оператором (if-else) для создания колонки, которая добавляется к набору данных (data frame, df). Код ниже создает этот начальный набор данных.
# Создание набора данных
col1 <- runif (12^5, 0, 2)
col2 <- rnorm (12^5, 0, 2)
col3 <- rpois (12^5, 3)
col4 <- rchisq (12^5, 2)
df <- data.frame (col1, col2, col3, col4)
В первой части: векторизация, только истинные условия, ifelse.
В этой части: which, apply, побайтовая компиляция, Rcpp, data.table, результаты.
Использование which()
Используя команду
which() для выбора строк, можно достичь одной третьей скорости Rcpp.# Спасибо Гейб Бекер
system.time({
want = which(rowSums(df) > 4)
output = rep("less than 4", times = nrow(df))
output[want] = "greater than 4"
})
# количество строк = 3 миллиона (примерно)
user system elapsed
0.396 0.074 0.481
Используйте семейство функций apply вместо циклов for
Используем функцию
apply() для реализации этой же логики и сравним с векторизированным циклом for. Результаты растут с увеличением количества порядков, но они медленнее, чем ifelse() и версии, где проверка делалась за пределами цикла. Это может быть полезно, но возможно, потребуется определенная изобретательность для сложной бизнес-логики. # семейство apply
system.time({
myfunc <- function(x) {
if ((x['col1'] + x['col2'] + x['col3'] + x['col4']) > 4) {
"greater_than_4"
} else {
"lesser_than_4"
}
}
output <- apply(df[, c(1:4)], 1, FUN=myfunc) # применить 'myfunc' к каждой строке
df$output <- output
})
Использование apply и цикла for в R
Используйте побайтовые компиляции для функций cmpfun() из пакета compiler вместо собственно функции
Это, наверное, не лучший пример для иллюстрации эффективности побайтовой компиляции, поскольку полученное время немного выше, чем обычная форма. Однако, для более сложных функций побайтовая компиляция доказала свою эффективность. Думаю, стоит попробовать при случае.
# побайтовая компиляция кода
library(compiler)
myFuncCmp <- cmpfun(myfunc)
system.time({
output <- apply(df[, c (1:4)], 1, FUN=myFuncCmp)
})
Apply, цикл for и побайтовая компиляция кода
Используйте Rcpp
Давайте выйдем на новый уровень. До этого мы увеличивали скорость и производительность с помощью различных стратегий и обнаружили, что использование
ifelse() наиболее эффективно. Что если мы добавим еще один ноль? Ниже мы реализуем эту же логику с Rcpp, с набором данных в 100 миллионов строк. Мы сравним скорости Rcpp и ifelse().library(Rcpp)
sourceCpp("MyFunc.cpp")
system.time (output <- myFunc(df)) # функция Rcpp ниже
Ниже приведена та же логика, реализованная на С++ с помощью пакета Rcpp. Сохраните код ниже как «MyFunc.cpp» в вашей рабочей директории сессии R (или вам придется применять sourceCpp, используя полный путь). Обратите внимание, комментарий
// [[Rcpp::export]] обязателен, и его нужно поместить непосредственно перед функцией, которую вы хотите выполнить из R.// Источник для MyFunc.cpp
#include
using namespace Rcpp;
// [[Rcpp::export]]
CharacterVector myFunc(DataFrame x) {
NumericVector col1 = as(x["col1"]);
NumericVector col2 = as(x["col2"]);
NumericVector col3 = as(x["col3"]);
NumericVector col4 = as(x["col4"]);
int n = col1.size();
CharacterVector out(n);
for (int i=0; i 4){
out[i] = "greater_than_4";
} else {
out[i] = "lesser_than_4";
}
}
return out;
}
Производительность
Rcpp и ifelseИспользуйте параллельную обработку, если у вас многоядерный ком��ьютер
Параллельная обработка:
# параллельная обработка
library(foreach)
library(doSNOW)
cl <- makeCluster(4, type="SOCK") # for 4 cores machine
registerDoSNOW (cl)
condition <- (df$col1 + df$col2 + df$col3 + df$col4) > 4
# параллелизация с векторизацией
system.time({
output <- foreach(i = 1:nrow(df), .combine=c) %dopar% {
if (condition[i]) {
return("greater_than_4")
} else {
return("lesser_than_4")
}
}
})
df$output <- output
Удаляйте переменные и очищайте память как можно раньше
Удаляйте больше ненужные объекты в коде с помощью
rm(), как можно раньше, особенно перед длинными циклами. Иногда может помочь применение gc() в конце каждой итерации цикла.Используйте структуры данных, занимающие меньше памяти
Data.table() — отличный пример, поскольку не перегружает память. Это позволяет ускорять операции, подобные объединению данных.dt <- data.table(df) # создать data.table
system.time({
for (i in 1:nrow (dt)) {
if ((dt[i, col1] + dt[i, col2] + dt[i, col3] + dt[i, col4]) > 4) {
dt[i, col5:="greater_than_4"] # присвоить значение в 5-й колонке
} else {
dt[i, col5:="lesser_than_4"] # присвоить значение в 5-й колонке
}
}
})
Dataframe и data.table
Скорость: результаты
Метод: Скорость, количество строк в df / затраченное время = n строк в секунду
Исходный: 1X, 120000/140.15 = 856.2255 строк в секунду (нормализировано к 1)
Векторизированный: 738X, 120000/0.19 = 631578.9 строк в секунду
Только истинные условия: 1002X, 120000/0.14 = 857142.9 строк в секунду
ifelse: 1752X, 1200000/0.78 = 1500000 строк в секунду
which: 8806X, 2985984/0.396 = 7540364 строк в секунду
Rcpp: 13476X, 1200000/0.09 = 11538462 строк в секунду
Числа, приведенные выше, приблизительны и основаны на случайных запусках. Нет расчетов результатов для
data.table(), побайтовой компиляции кода и параллелизации, поскольку они будут сильно отличаться в каждом конкретном случае и в зависимости от того, как вы их применяете.
