Комментарии 192
Скажите пожалуйста а ваше утверждение, что у варианта «Двухуровневое дерево» будет «Быстрее доступ к значениям отдельных колонок, так как не нужно парсить строку.» проверено на каких объёмах данных и на каких паттернах данных?
Это теоретическое предположение, основанное на понимании внутренней структуры глобалов.
Я предполагаю, что оно будет справедливо на числе колонок большем, чем 10. Или на объёме колонки с несколькими столбцами большем 10KБ.
Будет интересно увидеть комментарии от сотрудников InterSystems, которые имеют дело с глобалами каждый день.
Я предполагаю, что оно будет справедливо на числе колонок большем, чем 10. Или на объёме колонки с несколькими столбцами большем 10KБ.
Будет интересно увидеть комментарии от сотрудников InterSystems, которые имеют дело с глобалами каждый день.
Как раз теоритически всё будет зависить от паттерна данных и настроек хранения глобалов(думаю что их в кашэ можно менять каки в gt.m).
Может проведёте тесты?
Может проведёте тесты?
А почему бы и нет. Уже на 2-х колонках выигрыш 11,4%. При чтении 100M значений. Чем больше колонок или объём полей, тем больше будет выигрыш 2-х ярусного дерева. Тестировал в GT.M.
Тестовый код на M такой:
Второй подход побеждает.
mytest1
set ^a(1)="abcd bla bla #asdf bla bla "
for i=0:1:100000000 do
. set b=$piece(^a(1),"#",2)mytest2
set ^a(1)="abcd#asdf"
set ^a(1,1)="abcd bla bla "
for i=0:1:100000000 do
. set b=^a(1,1)Второй подход побеждает.
Но это кажется неверный пример для сравнения. Должно быть что-то типа:
mytest1 for i=0:1:100000000 do . set ^a(i) = "bla bla bla" _ "#" _ i for i=0:1:100000000 do . set b=$piece(^a(i),"#",2) mytest2 for i=0:1:100000000 do . set ^a(i,1) = "bla bla bla" . set ^a(i,2) = i for i=0:1:100000000 do . set b=^a(i,1)
В моём случае я сравнивал скорости чтения.
Если делать по вашей методе — мы включим в общее время ещё и время вставки.
На таких значениях никакие кеши уже не сработают и поэтому разница будет микроскопическая.
Так как начнут шуршать винты, которые будут конкретно замедлять систему.
Если рассматривать с точки зрения, что у нас настолько большая БД, что никакие данные не закешированы, то разница будет, дай бог, в 1-2%.
В своём тесте я специально читал одну ячейку, чтобы исключить фактор винтов и проверить только скорость чтения свойства.
То, что на вставку будет медленнее второй вариант — очевидно.
Если делать по вашей методе — мы включим в общее время ещё и время вставки.
На таких значениях никакие кеши уже не сработают и поэтому разница будет микроскопическая.
Так как начнут шуршать винты, которые будут конкретно замедлять систему.
Если рассматривать с точки зрения, что у нас настолько большая БД, что никакие данные не закешированы, то разница будет, дай бог, в 1-2%.
В своём тесте я специально читал одну ячейку, чтобы исключить фактор винтов и проверить только скорость чтения свойства.
То, что на вставку будет медленнее второй вариант — очевидно.
Вообще-то, в большинстве баз данных такие чтения одной ячейки миллион раз кэшируются, неужели нет в языке возможности замерить время конкретных циклов чтения? Каких нибудь getTime функций?
В моём тесте тоже всё закешировалось. И в первом и во втором, поэтому я посчитал, что можно доверять. Тем более практика совпала с теорией.
Мы исключили время на перемещение головок и чтение с поверхности, и осталось только время разбора структуры глобала и парсинга строки.
Мы исключили время на перемещение головок и чтение с поверхности, и осталось только время разбора структуры глобала и парсинга строки.
Тогда что вы вообще мерили? В первом тесте запрос к дереву один, но идет обработка результатов в памяти, во втором запросов к дереву два (точнее запрос идет к двум деревьям), но нет обработки результатов в памяти.
Естественно, если все запросы к деревьям закешировались, второй будет всегда работать быстрее, так как в нем просто читается значение кэша, а в первом читается значение кэша и идет ещё какая-то обработка. Да, логично что получить константу из памяти проще чем получить константу и ещё с ней что-то делать, только как часто в реальном приложении нужно миллион раз работать с одной константой?
Так же естественно, что в реальном приложении скорее всего проиграет второй запрос, который будет дважды перемещать головки и читать с диска, в то время как первый лишь один раз, а дальше работать только с памятью.
Естественно, если все запросы к деревьям закешировались, второй будет всегда работать быстрее, так как в нем просто читается значение кэша, а в первом читается значение кэша и идет ещё какая-то обработка. Да, логично что получить константу из памяти проще чем получить константу и ещё с ней что-то делать, только как часто в реальном приложении нужно миллион раз работать с одной константой?
Так же естественно, что в реальном приложении скорее всего проиграет второй запрос, который будет дважды перемещать головки и читать с диска, в то время как первый лишь один раз, а дальше работать только с памятью.
Вы что-то путаете. Тот код, который вы прокомментировали, предложил 4dmonster. Мой код — первый в треде.
У глобалов кешируются не значения, а блоки базы.
Вопрос был в том, что быстрее сработает — проход по двухуровневому дереву, или по одноуровневому с парсингом строки.
А измерялось это для того, чтобы доказать моё утверждение о том, что доступ к отдельным свойствам у второго типа таблиц на глобалах быстрее. В реальных базах кеш широко используется. И все частоиспользуемые области в нём.
У глобалов кешируются не значения, а блоки базы.
Вопрос был в том, что быстрее сработает — проход по двухуровневому дереву, или по одноуровневому с парсингом строки.
А измерялось это для того, чтобы доказать моё утверждение о том, что доступ к отдельным свойствам у второго типа таблиц на глобалах быстрее. В реальных базах кеш широко используется. И все частоиспользуемые области в нём.
Ещё раз, категорически неверно брать значение одной ячейки миллион раз и считать что это тест, так как этот тест ничего реального не покажет. Ведь вы же не берете в реальных приложениях значение одной ячейки столько раз? Поэтому сначала заполняете миллион значений в таблице, а потом тестируйте чтение из каждой ячейки. Чтобы чтение не влияло, заполняете таблицу ДО замеров времени теста.
Я тестировал скорость доступа к отдельному свойству без влияния HDD.
Доступа к закешированному значению. Это было сознательно.
Если влезет винт, то разница будет маленькой, незаметной. Это вопрос чисто теоретический, нужный только для сравнительной таблицы.
Доступа к закешированному значению. Это было сознательно.
Если влезет винт, то разница будет маленькой, незаметной. Это вопрос чисто теоретический, нужный только для сравнительной таблицы.
Вы не тестировали вообще НИЧЕГО. Плохо, что не понимая даже основ тестирования, вы пытаетесь писать статьи и что-то кому-то доказывать.
Вот код:
Вот результаты:
GTM>DO alltests^tests
for mytest1 62
for mytest2 45
for msrtest1 write 646
for msrtest1 read 88
for msrtest2 write 1041
for msrtest2 read 89
Я не спец в MUMPS, подскажите где я ошибся в коде.
Иначе выходит на выбранном вами паттерне $PIECE выгоднее.
Заголовок спойлера
cat tests.m alltests DO mytest1 DO mytest2 DO msrtest1 DO msrtest2 DO cleanUp QUIT cleanUp set start=$PIECE($HOROLOG,",",2) kill ^a kill ^aa kill ^ma kill ^na set stop=$PIECE($HOROLOG,",",2) write "for cleanUP "_(stop-start),! QUIT repeatsCount() QUIT 100000000 mytest1 set start=$PIECE($HOROLOG,",",2) set ^a(1)="abcd bla bla #asdf bla bla " set repeats=$$repeatsCount() for i=0:1:repeats do . set b=$piece(^a(1),"#",2) set stop=$PIECE($HOROLOG,",",2) write "for mytest1 "_(stop-start),! QUIT mytest2 set start=$PIECE($HOROLOG,",",2) set repeats=$$repeatsCount() set ^aa(1)="abcd#asdf" set ^aa(1,1)="abcd bla bla " for i=0:1:repeats do . set b=^aa(1,1) set stop=$PIECE($HOROLOG,",",2) write "for mytest2 "_(stop-start),! QUIT msrtest1 set start=$PIECE($HOROLOG,",",2) set repeats=$$repeatsCount() for i=0:1:repeats do . set ^ma(i)="bla bla bla"_"#"_i set stop=$PIECE($HOROLOG,",",2) write "for msrtest1 write "_(stop-start),! set start=$PIECE($HOROLOG,",",2) for i=0:1:repeats do . set b=$piece(^ma(i),"#",2) set stop=$PIECE($HOROLOG,",",2) write "for msrtest1 read "_(stop-start),! QUIT msrtest2 set start=$PIECE($HOROLOG,",",2) set repeats=$$repeatsCount() for i=0:1:repeats do . set ^na(i,1)="bla bla bla" . set ^na(i,2)=i set stop=$PIECE($HOROLOG,",",2) write "for msrtest2 write "_(stop-start),! set start=$PIECE($HOROLOG,",",2) for i=0:1:repeats do . set b=^na(i,1) set stop=$PIECE($HOROLOG,",",2) write "for msrtest2 read "_(stop-start),! QUIT
Вот результаты:
GTM>DO alltests^tests
for mytest1 62
for mytest2 45
for msrtest1 write 646
for msrtest1 read 88
for msrtest2 write 1041
for msrtest2 read 89
Я не спец в MUMPS, подскажите где я ошибся в коде.
Иначе выходит на выбранном вами паттерне $PIECE выгоднее.
Я тоже не спец в M. Вообще в вашем тесте есть методологическая погрешность: дело в том, что нужно чтобы M полностью сбрасывал буфера перед тем как проводить чтение. Во втором случае буфера значительно больше, и поэтому они сбрасываются во время чтения, что приводит к тому, что на чтение второй подход проиграл секунду.
Т.е. нужно было сделать программки на заполнение глобалов отдельными.
Тест на запись: нужно мерять время не внутренними функциями, а командой линукса time. Тоже из-за буферов. Так как ваш тест может показать что работа выполнена, а на самом деле буфера ещё не сброшены.
Далее: вообще-то из ваших тестов видно, что mytest2 быстрее, как я и говорил.
То что на вставку 2-я реализация таблиц будет медленнее — это я тоже говорил.
Теперь смотрим результат по чтению: 88 и 89 секунд — слишком мало отличие. Если сделать тесты на чтение отдельными программками, то тогда вы увидите истинный результат.
Т.е. нужно было сделать программки на заполнение глобалов отдельными.
Тест на запись: нужно мерять время не внутренними функциями, а командой линукса time. Тоже из-за буферов. Так как ваш тест может показать что работа выполнена, а на самом деле буфера ещё не сброшены.
Далее: вообще-то из ваших тестов видно, что mytest2 быстрее, как я и говорил.
То что на вставку 2-я реализация таблиц будет медленнее — это я тоже говорил.
Теперь смотрим результат по чтению: 88 и 89 секунд — слишком мало отличие. Если сделать тесты на чтение отдельными программками, то тогда вы увидите истинный результат.
FWIW
Вот результаты того-же самого на Haswell-ULT ноутбуке (в режиме экономии батареи) под Cache' 2015.2
Вот результаты того-же самого на Haswell-ULT ноутбуке (в режиме экономии батареи) под Cache' 2015.2
DEVLATEST:12:22:59:USER>do ^gtmtests for mytest1 34 for mytest2 31 for msrtest1 write 335 for msrtest1 read 152 for msrtest2 write 520 for msrtest2 read 185 for cleanUP 0
Это я очень осторожно ответил. На самом деле я думаю, что выигрыш уже будет с 2-х колонок. Так как для поиска нужного индекса (substring) достаточно линейно просмотреть несколько байт (так устроен глобал), а для парсинга строки придётся выделить память под всю строку, распарсить строку, выделить память под нужное поле.
Работать такие таблицы будут также быстро как и в традиционных БД (или даже быстрее), если функции вставки/обновления/удаления строк написать на COS/M и скомпилировать.
Нет, ну опять? Вы можете это утверждение чем-нибудь подтвердить, тестами там какими-нибудь?
Если нужно создать какую-то нестандартную БД минимальными усилиями, то стоит взглянуть в сторону глобалов.
В чем преимущество глобалов по сравнению с другими БД для «создания нестандартных БД»? Предположим у меня в проекте уже есть три разнотипных БД (Event Store, RDBMS, key-value) — что я выиграю, добавив в этот зоопарк еще и глобалы?
Это область традиционного применения глобалов. В медицинской сфере огромно число болезней, лекарств, симптомов, методов лечения. Создавать на каждого пациента таблицу с миллионом полей нерационально. Тем более, что 99% полей будут пустыми. Представьте SQL БД из таблиц: «пациент» ~ 100 000 полей, «Лекарство» — 100 000 полей, «Терапия» — 100 000 полей, «Осложнения» — 100 000 полей и т.д. и т.п.
Типично неправильно декомпонованная предметная область. Не нужно там тысяч полей. Достаточно представить ту же информацию не в виде дерева, а в виде E-R, как станет видно, как ее реализовывать.
Поэтому, когда речь идёт о хранении объектов с огромным количеством необязательных свойств, глобалы — отличный выбор.
Ага. Вот только
Общая длина ключа (сумма длин всех индексов) может достигать 511 байт [...] Число уровней в дереве (число измерений) — 31.
Максимальный размер карты в 16МБ сразу ставит крест на пациентах, в карту болезней которых включены файлы МРТ, сканы ренгенографии и других исследований. В одной ветви глобала же можно иметь информацию на гигабайты и терабайты.
Да-да-да-да, конечно же.
Общая длина [...] значения 3.6 МБ для Caché.
При множестве свойств в документе и его многоуровневой структуре доступ к отдельным свойствам будет быстрее за счёт того, что каждый путь в глобале это B-tree. В BSON же придётся линейно распарсить документ, чтобы найти нужное свойство.
Ну так индексы же.
Но в принципе, спор «иерархический kv против документо-ориентированой БД», очевидно, определяется сценарием использования. Если обычно документ достается для обработки целиком (например, возможно, врач открывает карту пациента перед приемом), то ДОБД неплохо справится. Если чаще нужны конкретные части — то нужна декомпозиция, и дальше начинаются варианты (кстати, ДОБД тоже неплохо декомпонуются, тут все упирается в транзакционную семантику).
Иерархические документы: XML, JSON [...] Также легко хранятся в глобалах.
Вот только в них легко можно встретить вложенность больше 31 уровня. И что делать?
Нужно создать нестандартную БД.
И все-таки я не понимаю, что такое «нестандартная БД». Ну или наоборот, что такое «стандартная»?
В прошлом посте я приводил свои тесты на вставку на 1M и 100M значений. Это аналогично двухколоночной таблице.
Выигрыш: в конце статьи есть таблица, где показано для каких случаев вы получите выигрыш.
Хранить целиком, без декомпозиции на глобал. Как и делают JSON СУБД. Или использовать специализированную JSON СУБД.
Выигрыш: в конце статьи есть таблица, где показано для каких случаев вы получите выигрыш.
Вот только в них легко можно встретить вложенность больше 31 уровня. И что делать?
Хранить целиком, без декомпозиции на глобал. Как и делают JSON СУБД. Или использовать специализированную JSON СУБД.
В прошлом посте я приводил свои тесты на вставку на 1M и 100M значений. Это аналогично двухколоночной таблице.
С индексами? А если полей порядка пятидесяти, индексов полтора десятка, и из них половина — покрывающие (что и активно используется запросами)?
Хранить целиком, без декомпозиции на глобал.
А ограничение на размер?
Тут всё просто. В двухколоночном варианте достаточно 1-го дерева. В этом варианте глобалы выигрывают по вставке. А в таблице также строится 1 индекс (тоже B*-tree)
Для эмуляции каждого дополнительного индекса потребуется ещё дерево. Но оно также будет строиться для индекса в реляционной базе.
Число индексов и индексных глобалов будет одинаковым. Вывод: глобал будет быстрее.
Глобал, сам по себе, более низкоуровневая технология, поэтому тут нет ничего удивительного.
Для эмуляции каждого дополнительного индекса потребуется ещё дерево. Но оно также будет строиться для индекса в реляционной базе.
Число индексов и индексных глобалов будет одинаковым. Вывод: глобал будет быстрее.
Глобал, сам по себе, более низкоуровневая технология, поэтому тут нет ничего удивительного.
Не, не убедили. Вы сравниваете яблоки с бочками, и говорите, что яблоки дешевле.
Во-первых, вы исходите из того, что деревья в глобалах и индексы в реляционных базах работают с одинаковой скоростью. Но почему? На чем основано это убеждение?
Во-вторых, вы совершенно забываете про сценарии массовых операций, где в глобалах вам придется иметь дело с каждой записью отдельно, а в реляционной БД — группой, со всеми вытекающими отсюда оптимизациями.
Так что тесты и только тесты, и ничего кроме тестов.
(И это мы еще не затронули тот занимательный вопрос, сколько кода вам придется написать, чтобы это реализовать, и сколько ошибок будет при его поддержке. Кто говорил «не надо разрабатывать свою БД»?)
Во-первых, вы исходите из того, что деревья в глобалах и индексы в реляционных базах работают с одинаковой скоростью. Но почему? На чем основано это убеждение?
Во-вторых, вы совершенно забываете про сценарии массовых операций, где в глобалах вам придется иметь дело с каждой записью отдельно, а в реляционной БД — группой, со всеми вытекающими отсюда оптимизациями.
Так что тесты и только тесты, и ничего кроме тестов.
(И это мы еще не затронули тот занимательный вопрос, сколько кода вам придется написать, чтобы это реализовать, и сколько ошибок будет при его поддержке. Кто говорил «не надо разрабатывать свою БД»?)
Во-первых, вы исходите из того, что деревья в глобалах и индексы в реляционных базах работают с одинаковой скоростью
Уже скоро язык отвалится объяснять. Когда я делал таблицу с одним индексом и глобал из одного дерева глобал был в разы быстрее.
Во-вторых, вы совершенно забываете про сценарии массовых операций, где в глобалах вам придется иметь дело с каждой записью отдельно, а в реляционной БД — группой, со всеми вытекающими отсюда оптимизациями.
Всё я помню. С группой — это только в SQL. А уровнем ниже будет тот же поиск строк по дереву и та же обработка строк.
И это мы еще не затронули тот занимательный вопрос, сколько кода вам придется написать, чтобы это реализовать
Если бы вы прочитали мою статью, то увидели бы, что я рекомендую работать с табличными данными через SQL.
Уже скоро язык отвалится объяснять. Когда я делал таблицу с одним индексом и глобал из одного дерева глобал был в разы быстрее.
И почему вы считаете, что этот ваш опыт масштабируется?
С группой — это только в SQL. А уровнем ниже будет тот же поиск строк по дереву и та же обработка строк.
Какая обработка строк, о чем вы? Не говоря уже о том, что когда мы имеем дело с группой операций, мы можем оптимизировать наши действия (начиная с банальной преаллокации нужного места и заканчивая последовательной, а не рандомной вставкой в индекс).
Если бы вы прочитали мою статью, то увидели бы, что я рекомендую работать с табличными данными через SQL.
Что и говорит нам о том, что не надо реализовывать табличные структуры на глобалах, ибо незачем. А SQL-решений вокруг и так хватает, чего уж.
И почему вы считаете, что этот ваш опыт масштабируется?
Тоже уже объяснил. Каждый индекс эквивалентен индексному глобалу. Если на одном выигрывает, то и на 10 выиграет.
Какая обработка строк, о чем вы?
Например UPDATE t SET a=a+b WHERE b=5
Нужно найти строки по индексу b (если есть), а далее каждую строку обработать. Какие тут можно сделать улучшения, которые невозможны для глобалов?
Тоже уже объяснил. Каждый индекс эквивалентен индексному глобалу. Если на одном выигрывает, то и на 10 выиграет.
Вы почему-то считаете, что это линейная зависимость. Почему бы? Никаких доказательств.
Тесты, только тесты.
Нужно найти строки по индексу b (если есть), а далее каждую строку обработать. Какие тут можно сделать улучшения, которые невозможны для глобалов?
Например, получить в качестве результата прохода по индексу не значение основного ключа, а сразу физический адрес, где это лежит.
Вот вам контрпример:
INSERT Customers (Name, City)
SELECT CustomerName, CustomerCity
FROM OtherSystemCustomers
По City — индекс IX_City. Первичный ключ не указан и создается автоматически. Так вот, вместо того, чтобы делать столько рандомных вставок в IX_City, сколько у нас записей вставлено, мы можем собрать массив туплов (City, ID), сгруппировать его по City, а затем вставить получившиеся группы, тем самым уменьшив количество проходов по индексу.
Вы, конечно, можете сделать это на глобалах. Руками. Для каждой отдельной операции, с которой вы столкнетесь.
Для каждой отдельной операции, с которой вы столкнетесь.
Я точно также могу получить выборку отсортированную по City и последовательно её вставить. Никаких проблем.
Только я таблицы на глобалах буду использовать в крайнем случае, когда у меня 99% глобалов и тут нужен 1% таблиц.
Руками кодить не хочу. Делать таблицы на глобалах — это принципиальная возможность, а не рекомендованная. В статье об этом написано.
Я точно также могу получить выборку отсортированную по City и последовательно её вставить. Никаких проблем.
… и дальше снова будет вопрос, почему вы считаете, что ваши операции (которые в пользовательском коде) равноэффективны операциям в ядре RDBMS.
Тесты, тесты, тесты. Ничего кроме тестов.
Это не пользовательский код. А код, который компилируется в машинные коды у GT.M, и в байт-коды в Caché (там как и в Java есть своя виртуальная машина).
Обычный SQL — это интерпретатор (хранимые процедуры у всех по разному). А COS/M компилируется. Две большие разницы.
Обычный SQL — это интерпретатор (хранимые процедуры у всех по разному). А COS/M компилируется. Две большие разницы.
А код, который компилируется в машинные коды у GT.M, и в байт-коды в Caché (там как и в Java есть своя виртуальная машина).
Он все равно пользовательский, а не системный.
Обычный SQL — это интерпретатор (хранимые процедуры у всех по разному). А COS/M компилируется. Две большие разницы.
А обычный SQL тут никого не волнует. Обычный SQL закончился в тот момент, когда мы сказали INSERT, а парсер на той стороне это обработал. А все индексы — они уже внутри ядра, сильно позже и на другом уровне.
Он все равно пользовательский, а не системный.
Чем отличается скомпилированный в машинные коды пользовательский код от системного?
Оптимизациями, конечно. Вы же утверждали, в свое время, что программа, написанная на ассемблере, быстрее, чем программа, написанная на ЯПВУ. А компилируются они в одни и те же машинные коды. Вот и тут то же самое: то, на чем вы пишете работу с глобалами — это ЯПВУ.
(не говоря уже о том, что пользовательский код работает только с дозволенными абстракциями, а системный — с теми, с которыми хочет системный программист)
(не говоря уже о том, что пользовательский код работает только с дозволенными абстракциями, а системный — с теми, с которыми хочет системный программист)
Код, который написан на COS/М, компилируется в высокооптимизированный системными программистами код. Было бы иначе, я бы не получил 789К/сек инсертов в «пользовательском» коде.
Вы это серьезно? Вы правда не понимаете, что ваш ^SET компилируется просто в вызов системной (предоставленной движком) функции?
А такое ощущение, что вы не можете догнать. Даже, если и вызывается функция движка, а не inline она в коде, то эта функция и есть высокооптимизированный системными программистами код.
А теперь задумайтесь о разнице между десятью вызовами «высокооптимизированного кода», и одним вызовом «высокооптимизированного кода» (выполняющего такую же работу, как те десять). Во втором случае, очевидно, больше пространство для оптимизаций.
Вообще неочевидно.
В таком случае бы все высокоуровневые языки, где каждая команда выполняет много работы, были бы быстрее низкоуровневых.
Больше пространство для оптимизаций там, куда можно залезть руками.
Ну и глобалы работали бы медленнее таблиц. Но по моим тестам всё не так. Так что тестируйте, тестируйте…
В таком случае бы все высокоуровневые языки, где каждая команда выполняет много работы, были бы быстрее низкоуровневых.
Больше пространство для оптимизаций там, куда можно залезть руками.
Ну и глобалы работали бы медленнее таблиц. Но по моим тестам всё не так. Так что тестируйте, тестируйте…
В таком случае бы все высокоуровневые языки, где каждая команда выполняет много работы, были бы быстрее низкоуровневых.
Вообще никак не связано.
Больше пространство для оптимизаций там, куда можно залезть руками.
Так там и залезли.
Как по вашему, что эффективнее:
foreach(var item in source)
target.Add(item);
или
target.AddRange(source);
Если первое написать написать на ASM, а второе на Basic, то первое.
У какого SQL, из которых вы знаете, есть компиляция SQL-запросов в машинные коды? Или хотя бы в байт-коды с возможностью сохранения между сессиями?
У какого SQL, из которых вы знаете, есть компиляция SQL-запросов в машинные коды? Или хотя бы в байт-коды с возможностью сохранения между сессиями?
Если первое написать написать на ASM, а второе на Basic, то первое.
Это один и тот же язык, если что.
У какого SQL, из которых вы знаете, есть компиляция SQL-запросов в машинные коды?
А зачем мне компилировать SQL-запрос в машинные коды?
Вот смотрите. У меня есть таблица на, скажем, полсотни полей, с парой десятков индексов. Я делаю в нее один инсерт:
INSERT INTO Target VALUES (...). Это одна команда, пятьдесят один аргумент (имя таблицы + значения колонок). Эта команда превращается в один вызов системной функции блаблаблаPerformInsert с этими же 51 аргументом. Дальше внутри этой функции программист БД (который, наверное, умнее меня и лучше знает ее внутренности) может делать что угодно, применять любые оптимизации, напрямую работать с физическими адресами и так далее. Его воля.А теперь все то же самое для псевдотаблиц на глобалах: нужно сделать порядка пятидесяти вставок в глобал с данными, плюс пара десятков вставок в «индексы». Порядка семидесяти независимых вызовов системной функции «вставка в глобал», где каждый из них не знает о соседнем (и, как следствие, не может делать кросс-оптимизации).
Простой вопрос: что быстрее, команда
(естественно, мы считаем, что функциональность идентична — один набор и структура данных, индексы, транзакции, блаблабла)
INSERT из Caché SQL, или аналогичная по функциональности «процедура», написанная вами на M или COS/M?(естественно, мы считаем, что функциональность идентична — один набор и структура данных, индексы, транзакции, блаблабла)
Скорее всего так:
Если требуется абсолютная функциональная идентичность — они будут одинаково работать.
А если достаточно того, чтобы потом Caché SQL мог бы сделать SELECT — тогда написанная на M или COS/M.
Если требуется абсолютная функциональная идентичность — они будут одинаково работать.
А если достаточно того, чтобы потом Caché SQL мог бы сделать SELECT — тогда написанная на M или COS/M.
Недавно проводил тестирование «для одного большого банка», где, конечно же, мы проверяли в очередной раз разницу между CacheSQL vs Direct Global Access. В 2015.1 разница, для того простого случая что мы смоделировали, в разы (x2-x3), для 2015.2 на примерно 15%.
Т.е. сейчас, в 2015.2, я легко пожертвую 15% ухудшения по сравнению с идеальным случаем на голом глобале, но буду использовать более высокий уровень абстракции. Ибо так проще в долговременном плане.
Т.е. сейчас, в 2015.2, я легко пожертвую 15% ухудшения по сравнению с идеальным случаем на голом глобале, но буду использовать более высокий уровень абстракции. Ибо так проще в долговременном плане.
Т.е. CacheSQL медленнее? Это при полном сохранении функциональности?
А что удивительного в том, что более высокоуровневое средство (CacheSQL) медленнее низкоуровневого прямого доступа к глобалам?
Да, в случае голой заливки данных (я не говорю про запросы), INSERT в CacheSQL всегда будет медленнее чем прямая манипуляция глобалом, т.к. добавляется некоторый объем дополнительной работы необходимый для эмуляции ACID. Программист, работающий с глобалом напрямую обычно игнорирует некоторую транзакционную строгость, выигрывая по скорости. Иногда, при первичной загрузке данных, или в монопольном режиме на это можно закрыть глаза.
(Ну т.е. нет, конечно, полного сохранения функциональности, COS/M программист обычно дяже не знает о таких деталях о которых должен заботиться транслятор SQL в Cache' для правильной поддержки транзакционной целостности в SQL)
Еще раз, относитесь к прямому доступу к глобалам в Cache'/GT.M как к «ассемблеру», а SQL/объектной обертке в Cache' как C/C++. Большие системы правильнее писать, применяя абстракции более высокого уровня, но иногда, на критичном участке, «можно и на ассемблере пописать».
(Ну т.е. нет, конечно, полного сохранения функциональности, COS/M программист обычно дяже не знает о таких деталях о которых должен заботиться транслятор SQL в Cache' для правильной поддержки транзакционной целостности в SQL)
Еще раз, относитесь к прямому доступу к глобалам в Cache'/GT.M как к «ассемблеру», а SQL/объектной обертке в Cache' как C/C++. Большие системы правильнее писать, применяя абстракции более высокого уровня, но иногда, на критичном участке, «можно и на ассемблере пописать».
Да, в случае голой заливки данных (я не говорю про запросы), INSERT в CacheSQL всегда будет медленнее чем прямая манипуляция глобалом, т.к. добавляется некоторый объем дополнительной работы необходимый для эмуляции ACID. [...] (Ну т.е. нет, конечно, полного сохранения функциональности, COS/M программист обычно дяже не знает о таких деталях о которых должен заботиться транслятор SQL в Cache' для правильной поддержки транзакционной целостности в SQL)
Тогда это не то, что меня интересовало. Я изначально ставил вопрос о сохранении функциональности. Понятно, что если мы выкинем оптимизации под чтение и ACID, то простые операции вставки дешевле, чем более сложная структура, но автор-то утверждал, что даже в режиме функциональной имитации глобалы все равно быстрее:
Работать такие таблицы будут также быстро как и в традиционных БД (или даже быстрее), если функции вставки/обновления/удаления строк написать на COS/M и скомпилировать.
Программист, работающий с глобалом напрямую обычно игнорирует некоторую транзакционную строгость, выигрывая по скорости.
Вот этот компромис мне очень хорошо понятен, да. Одним пожертвовали, другое выиграли. Меня просто второй пост подряд удивляют (неявные) утверждения, что глобалы — это выиграй все, пожертвовав ничем.
Вы сами признали уровень изоляции аналогичным snapshot (что весьма высокий уровень), а также с ACID (вопрос не в том, есть ли в глобалсах ACID. Вопрос в том, какой именно).
Я не понимаю, зачем вы теперь отказываетесь от своих слов.
Никто ACID не выкидывает. И про какие оптимизации, которые на уровне глобалов, сделать принципиально невозможно тоже не ясно.
Я не понимаю, зачем вы теперь отказываетесь от своих слов.
Понятно, что если мы выкинем оптимизации под чтение и ACID
Никто ACID не выкидывает. И про какие оптимизации, которые на уровне глобалов, сделать принципиально невозможно тоже не ясно.
Ну вы уж как-нибудь обсудите это с tsafin, который утверждает, что INSERT добавляет дополнительный объем работы именно на ACID, и что в его тестах функциональность INSERT и прямой работы с глобалами отличается.
Что возвращает нас к вопросу — а какова же будет сравнительная скорость «ручных» операций на глобалах и INSERT с одинаковой функциональностью? (не умозрительно, а в реальных тестах)
Я не отказываюсь от своих слов, просто вы почему-то считаете, что если вы в одном сценарии доказали, что ACID достижим, то он (ACID) автоматически будет везде. Удивительно, но реальный сотрудник InterSystems утверждает обратное.
Что возвращает нас к вопросу — а какова же будет сравнительная скорость «ручных» операций на глобалах и INSERT с одинаковой функциональностью? (не умозрительно, а в реальных тестах)
Я не отказываюсь от своих слов, просто вы почему-то считаете, что если вы в одном сценарии доказали, что ACID достижим, то он (ACID) автоматически будет везде. Удивительно, но реальный сотрудник InterSystems утверждает обратное.
А в чем фундаментальные отличия?
SQL слой накручен поверх глобалов и, вероятно, требует дополнительных условий / проверок для своей работы.
Например, для ссылочной целостности.
Например, для ссылочной целостности.
До ссылочной целостности мы даже не доходили еще, пока ограничились одной таблицей и индексами.
Я, на всякий случай, повторю предмет спора: inetstar утверждал, что таблицы, написанные на самих глобалах вручную (примеры есть в статье), не медленнее, а то и быстрее, чем таблицы в традиционных БД. Я утверждаю, что при сохранении функциональности для этого нет никаких логических оснований, и я хотел бы увидеть подтверждающие утверждение inetstar тесты.
Ключевой пункт тут — при сохранении функциональности. tsafin, приводя свои результаты, признал, что функциональность различна.
Я, на всякий случай, повторю предмет спора: inetstar утверждал, что таблицы, написанные на самих глобалах вручную (примеры есть в статье), не медленнее, а то и быстрее, чем таблицы в традиционных БД. Я утверждаю, что при сохранении функциональности для этого нет никаких логических оснований, и я хотел бы увидеть подтверждающие утверждение inetstar тесты.
Ключевой пункт тут — при сохранении функциональности. tsafin, приводя свои результаты, признал, что функциональность различна.
Это зависит от того какая функциональность имеется в виду. Ну и конечно от того, ограничиваемся ли мы одной таблицей и её индексами.
Я в статью вставил спойлер, где несколько раскрыл на основании каких тестов я утверждаю, что таблицы на глобалах будут работать также или быстрее.
И я нигде не постулировал абсолютно идеентичную функциональность таблиц в SQL-базах и таблиц на глобалах, на которую вы так напираете.
Например, в моих тестах я не делал защиты от вставки строки с тем же ID. Это, наверное, бы замедлило бы мои тесты на несколько процентов.
Глобалы — низкоуровневое средство, дающее отличные скоростные характеристики.
Я специально сказал в статье, что с таблицами лучше работать на SQL. Удобнее.
Программист на глобалах должен знать, что о всех их потенциальных возможностях. В том числе и о той, что на глобалах можно сделать таблицы.
СтОит или не стоит — вопрос уже другой. Если нужно сверхбыстро сохранять информацию, идущую от какого-то источника, то похоже что стоит.
А если вам нужны конкурентные и очень хитрые транзакции над табличными данными, то не факт. Незачем программировать вручную, то что уже запрограммировано в SQL.
И я нигде не постулировал абсолютно идеентичную функциональность таблиц в SQL-базах и таблиц на глобалах, на которую вы так напираете.
Например, в моих тестах я не делал защиты от вставки строки с тем же ID. Это, наверное, бы замедлило бы мои тесты на несколько процентов.
Глобалы — низкоуровневое средство, дающее отличные скоростные характеристики.
Я специально сказал в статье, что с таблицами лучше работать на SQL. Удобнее.
Программист на глобалах должен знать, что о всех их потенциальных возможностях. В том числе и о той, что на глобалах можно сделать таблицы.
СтОит или не стоит — вопрос уже другой. Если нужно сверхбыстро сохранять информацию, идущую от какого-то источника, то похоже что стоит.
А если вам нужны конкурентные и очень хитрые транзакции над табличными данными, то не факт. Незачем программировать вручную, то что уже запрограммировано в SQL.
Я в статью вставил спойлер, где несколько раскрыл на основании каких тестов я утверждаю, что таблицы на глобалах будут работать также или быстрее.
Угу.
Это утверждение я проверял тестами на массовых INSERT и SELECT в одну таблицу, в том числе с использованием команд TSTART и TCOMMIT (транзакций).
Без использования транзакций скорость инсертов была на миллионе значений 778 361 вставок/секунду.
При 300 миллионов значений — 422 141 вставок/секунду.
При использовании транзакций — 572 082 вставок/секунду. Все операции проводились из скомпилированного M-кода.
И с чем вы это сравниваете?
И я нигде не постулировал абсолютно идеентичную функциональность таблиц в SQL-базах и таблиц на глобалах, на которую вы так напираете.
Тогда какой смысл говорить, что вы реализовали «таблицы» или вообще сравнивать производительность?
Ну да, есть какая-то операция вставки чего-то куда-то, которая в глобалах выполняется за x. Есть какая-то другая операция вставки чего-то куда-то, которая в другой СУБД выполняется за y. x < y… ну и что? Апельсин легче танкера с нефтью, это правда.
СтОит или не стоит — вопрос уже другой. Если нужно сверхбыстро сохранять информацию, идущую от какого-то источника, то похоже что стоит.
Зачем для этого «таблицы»? Для таких задач лучше всего append-only хранилища.
Незачем программировать вручную, то что уже запрограммировано в SQL.
Бинго.
Добавил в спойлер сравнение с MySQL. Хранимая процедура с циклом, котрая делает вставки — 11К вставок в секунду.
Операции вставки в глобалах и MySQL семантически идентичны? Если нет, то в этих цифрах нет никакого смысла.
Идеентичны.
Set ^a(10) = «blabla»
INSERT INTO a(id, txt) Values(10, «blabla»)
Set ^a(10) = «blabla»
INSERT INTO a(id, txt) Values(10, «blabla»)
Во-первых, для RDBMS это вырожденный пример, в котором она заведомо лишена смысла. Сравнивайте с KV, потому что это все, что вы тут делаете. Чтобы говорить о «таблицах», нужно реализовывать поведение реляционной системы.
Во-вторых, выше этого сравнения вы говорите об имитации индексов через глобалы. Ваша фраза «Работать такие таблицы будут также быстро как и в традиционных БД (или даже быстрее)» относится к каким «таким» таблицам — с имитацией индексов или без?
Во-вторых, выше этого сравнения вы говорите об имитации индексов через глобалы. Ваша фраза «Работать такие таблицы будут также быстро как и в традиционных БД (или даже быстрее)» относится к каким «таким» таблицам — с имитацией индексов или без?
К обоим вариантам. Но таблицы с несколькими индексами я не тестировал.
В любом случае таблица с 2-мя индексами быстрее работать не станет, а вставка в глобал замедлится в 2 раза. Допустим даже в 3, с учётом транзакции.
Учитывая 70-ти кратное преимущество по скорости при одной вставке в глобал, результат будет таким же — глобалы победят. В сравнении с MySQL.
Учитывая 70-ти кратное преимущество по скорости при одной вставке в глобал, результат будет таким же — глобалы победят. В сравнении с MySQL.
Ещё я хочу напомнить, что я говорил о скорости эмулированных таблиц, я говорил не про CacheSQL, подразумевая чистый MUMPS.
Я предполагаю что CacheSQL в интерактивном режиме — как и любой SQL — интерпретаторный язык. Не вижу ничего удивительного, что он на 15% медленнее глобалов, программы для работы с которыми компилируемы.
Я предполагаю что CacheSQL в интерактивном режиме — как и любой SQL — интерпретаторный язык. Не вижу ничего удивительного, что он на 15% медленнее глобалов, программы для работы с которыми компилируемы.
То есть вы утверждаете, что 15% разницы (а в предыдущей версии — 200-300% разницы) между CacheSQL и прямым обращением к глобалам возникают только из-за разницы «интерпретаторный-компилируемый»?
А еще CacheSQL может исполняться во встроенном режиме, где, как утверждается," SQL statements are converted to optimized, executable code at compilation time".
Интересно, какой из режимов тестировал tsafin, и есть ли существенная разница по производительности между одни и другим.
Интересно, какой из режимов тестировал tsafin, и есть ли существенная разница по производительности между одни и другим.
Ок, попытаюсь объяснить.
Высокоуровневая идея всегда применяемая во всех надстройках Cache' — любой другой язык должен d bnjut транслироваться в INT-код (Cache' ObjectScript) и объектный код, вне зависимости от количества препроцессинга и кодогенерации. Будь это SQL, манифест инсталлятора или описание домена iKnow. В случае компиляции встроенного SQL работает макро-препроцессор (так получилось исторически), в большинстве других случаев работают методы генераторы.
(Вам не удастся встроиться в препроцессор, но генераторы, если надо, Вам помогут реализовать еще какой встроенный доменный язык для любой вашей цели. Степеней свободы достаточно)
Возвращаясь к SQL — кроме упомянутого уже выше и ниже встроенного SQL (embedded SQL), компилируемого препроцессором в низкоуровневый COS в момент компиляции MAC программы или класса, есть еще и динамический SQL, компилируемый в похожую программу в момент первого исполнения.
Если вам интересно посмотреть, то вот упрощенный пример:
1. Создадим персистентный класс
И для такого простого метода со встроенным SQL выражением:
после компиляции получаем следующий сгенерированный код (Ctrl+Shift+V в Студии):
Я не представляю себе COS программиста, который будет в своем коде так заботиться об уровнях транзакции, блокировках, откатах и обработке ошибок. COS/M код, созданный человеком, будет значительно короче и проще, и не будет заботиться (скорее всего) о всех граничных условиях. Хотя и не факт, что будет более читабельным (вон смотрите, там даже комментарии иногда генерируются :) )
В любом случае, прошу запомнить — у нас нет интерпретации при работе с SQL, транслятор SQL генерирует COS код, и, при разборе запросов, применяет все полагающиеся оптимизирующие эвристики. SQL это не просто и борьба за улучшения в генерируемом коде происходит постоянная.
P.S.
Большая просьба к участникам дискуссии — давайте попытаемся не выходить за пределы компетенции, и, в любом случае, попытаемся вести себя уважительно.
Мне нравится тенденция, наблюдаемая у некоторых участников дискуссии, пойти и почитать документы про Cache' (что я всячески приветствую), и давайте все остальные вопросы, которые возникнут по результатам тестирования задавать нам по другим каналам (письмом или через социальные сети). С удовольствием ответим!
Высокоуровневая идея всегда применяемая во всех надстройках Cache' — любой другой язык должен d bnjut транслироваться в INT-код (Cache' ObjectScript) и объектный код, вне зависимости от количества препроцессинга и кодогенерации. Будь это SQL, манифест инсталлятора или описание домена iKnow. В случае компиляции встроенного SQL работает макро-препроцессор (так получилось исторически), в большинстве других случаев работают методы генераторы.
(Вам не удастся встроиться в препроцессор, но генераторы, если надо, Вам помогут реализовать еще какой встроенный доменный язык для любой вашей цели. Степеней свободы достаточно)
Возвращаясь к SQL — кроме упомянутого уже выше и ниже встроенного SQL (embedded SQL), компилируемого препроцессором в низкоуровневый COS в момент компиляции MAC программы или класса, есть еще и динамический SQL, компилируемый в похожую программу в момент первого исполнения.
Если вам интересно посмотреть, то вот упрощенный пример:
1. Создадим персистентный класс
Class User.Habra.BankData Extends %Persistent
{
Property Amount As %Numeric;
Property Account As %String;
}
И для такого простого метода со встроенным SQL выражением:
ClassMethod InsertAsSQL(Value As %Numeric, AccountName As %String) As %Status
{
&sql(insert into User_Habra.BankData(account, amount) values (:AccountName,:Value))
return $$$OK
}
после компиляции получаем следующий сгенерированный код (Ctrl+Shift+V в Студии):
...
zInsertAsSQL(Value,AccountName) [ AccountName,SQLCODE,Value ] public { New %ROWCOUNT,%ROWID,%msg,SQLCODE
;---&sql(insert into User_Habra.BankData(account, amount) values (:AccountName,:Value))
;--- ** SQL PUBLIC Variables: %ROWCOUNT, %ROWID, %msg, AccountName, SQLCODE, Value
Do %0Fo
return 1 }
q
%0Fo try { n sqldata5d
if $zu(115,1)=1||('$TLEVEL&&($zu(115,1)=2)) { TSTART s sqldata5d=1 }
n %i
s %i(2)=$g(AccountName),%i(3)=$g(Value)
s %ROWID=##class(User.Habra.BankData).%SQLInsert(.%i,$c(0,0,0,0,0,0,0),,,'$g(sqldata5d)),%ROWCOUNT='SQLCODE
if $zu(115,1)=1,$g(sqldata5d) { TCOMMIT:SQLCODE'<0 TROLLBACK:SQLCODE<0 1 }
}
catch { d SQLRunTimeError^%apiSQL($ze,.SQLCODE,.%msg) if $zu(115,1)=1,$g(sqldata5d) { TROLLBACK 1 } }
quit // From %0Fo
...
%SQLInsert(%d,%check,%inssel,%vco,%tstart=1,%mv=0)
new bva,%ele,%itm,%key,%l,%n,%nc,%oper,%pos,%s,sqlcode,sn,subs,icol set %oper="INSERT",sqlcode=0,%l=$c(0,0,0)
if $a(%check,7) { new %diu merge %diu=%d }
if $d(%d(1)),'$zu(115,11) { if %d(1)'="" { set SQLCODE=-111,%msg=$$FormatMessage^%occMessages(,"%SQL.Filer","SQLFiler6",,"ID","User_Habra"_"."_"BankData") QUIT "" } kill %d(1) }
if '$a(%check),'..%SQLValidateFields(.sqlcode) { set SQLCODE=sqlcode QUIT "" }
do ..%SQLNormalizeFields()
if %tstart { TSTART:($zu(115,1)=1)||('$TLEVEL&&($zu(115,1)=2)) } set $zt="ERRORInsert"
if '$a(%check) {
do {
if $g(%vco)'="" { d @%vco quit:sqlcode<0 }
} while 0
if sqlcode<0 { set SQLCODE=sqlcode do ..%SQLEExit() QUIT "" } // A constraint failed
}
if '$d(%d(1)) { set %d(1)=$i(^User.Habra.BankDataD) } elseif %d(1)>$g(^User.Habra.BankDataD) { if $i(^User.Habra.BankDataD,$zabs(%d(1)-$g(^User.Habra.BankDataD))) {}} elseif $d(^User.Habra.BankDataD(%d(1))) { set SQLCODE=-119,%msg=$$FormatMessage^%occMessages(,"%SQL.Filer","SQLFiler33",,"ID",%d(1),"User_Habra"_"."_"BankData"_"."_"ID") do ..%SQLEExit() QUIT "" }
set:'($d(%d(4))#2) %d(4)=""
if '$a(%check,2) {
new %ls lock +^User.Habra.BankDataD(%d(1))#"E":$zu(115,4) set %ls=$s('$t:0,1:$case($SYSTEM.Lock.ReturnCode(),0:1,4:2,2:2,1:3,:""))
set:%ls=2 $e(%check,2)=$c(1) set:%ls=2&&($tlevel) %0CacheLock("User.Habra.BankData","E")=1 set:$case(%ls,1:1,2:1,:0) $e(%l)=$c(1)
if '%ls||(%ls=3) { set SQLCODE=-110,%msg=$$FormatMessage^%occMessages(,"%SQL.Filer",$s('%ls:"SQLFiler40",1:"SQLFiler55"),,%oper,"User_Habra"_"."_"BankData",$g(%d(1))) do ..%SQLEExit() QUIT "" }
}
set ^User.Habra.BankDataD(%d(1))=$lb($g(%d(4)),$g(%d(3)),$g(%d(2)))
lock:$a(%l) -^User.Habra.BankDataD(%d(1))#"E"
TCOMMIT:%tstart&&($zu(115,1)=1)
set SQLCODE=0
QUIT %d(1) // %SQLInsert
Я не представляю себе COS программиста, который будет в своем коде так заботиться об уровнях транзакции, блокировках, откатах и обработке ошибок. COS/M код, созданный человеком, будет значительно короче и проще, и не будет заботиться (скорее всего) о всех граничных условиях. Хотя и не факт, что будет более читабельным (вон смотрите, там даже комментарии иногда генерируются :) )
В любом случае, прошу запомнить — у нас нет интерпретации при работе с SQL, транслятор SQL генерирует COS код, и, при разборе запросов, применяет все полагающиеся оптимизирующие эвристики. SQL это не просто и борьба за улучшения в генерируемом коде происходит постоянная.
P.S.
Большая просьба к участникам дискуссии — давайте попытаемся не выходить за пределы компетенции, и, в любом случае, попытаемся вести себя уважительно.
Мне нравится тенденция, наблюдаемая у некоторых участников дискуссии, пойти и почитать документы про Cache' (что я всячески приветствую), и давайте все остальные вопросы, которые возникнут по результатам тестирования задавать нам по другим каналам (письмом или через социальные сети). С удовольствием ответим!
Да, в случае голой заливки данных (я не говорю про запросы), INSERT в CacheSQL всегда будет медленнее чем прямая манипуляция глобалом, т.к. добавляется некоторый объем дополнительной работы необходимый для эмуляции ACID. Программист, работающий с глобалом напрямую обычно игнорирует некоторую транзакционную строгость, выигрывая по скорости. Иногда, при первичной загрузке данных, или в монопольном режиме на это можно закрыть глаза.
То есть все же полная функциональность не сохраняется? Так зачем вы об этом пишете?
>> Вот только в них легко можно встретить вложенность больше 31 уровня. И что делать?
На самом деле не легко, если только искусственно создать или спецом не оптимально, даже в самых монстрах не будет и 20. А 31 уровня более чем достаточно чтобы систематизировать все знания человечества.
На самом деле не легко, если только искусственно создать или спецом не оптимально, даже в самых монстрах не будет и 20. А 31 уровня более чем достаточно чтобы систематизировать все знания человечества.
Вы просто не встречались с, прости г-ди, энтерпрайзным xml, где внутри подряд три вложенных конверта, а только потом данные начинаются.
Это же не структура классификатора, это программные данные, а там всякое случается.
Это же не структура классификатора, это программные данные, а там всякое случается.
А вот здесь подробнее, пожалуйста! Ну 3 вложенных конверта, и данные, как тут больше 31 уровня подындексов получается?
Можно примерчик (чисто для развития)
Можно примерчик (чисто для развития)
Вложенность html тегов в произвольной странице сети может зашкаливать и за 50 уровень, при использовании кучи div'ов и table для верстки.
Это я понимаю, но я спрашивал про другой тип данных — xml структуру данных, представляющее собой сериализацию (в xml, json, yaml, toml, что-нибудь еще более модное) какой-то определенной иерархии объектов с полями и с вложенностью. Что предполагает немного другой сценарий использования, и больший, скажем так, «порядок».
Хотелось бы посмотреть именно на «enterprise xml» с адской вложенностью, чтобы понять где наши ограничения будут упираться в пределы движка.
Хотелось бы посмотреть именно на «enterprise xml» с адской вложенностью, чтобы понять где наши ограничения будут упираться в пределы движка.
Ну вы же понимаете, что вам никто реальный «enterprise xml» реальной компании никогда не покажет. Ну примерно, в одной фирме где я работал xml выглядели как-то так (сознательно извратил насколько мог, но принцип понятен, причем в нем может быть бесконечная вложенность устройств друг в друга):
Внимание большой xml
<soap:Envelope
xmlns:soap="http://www.w3.org/2001/12/soap-envelope"
soap:encodingStyle="http://www.w3.org/2001/12/soap-encoding">
<soap:Body xmlns:m="http://www.example.org/stock">
<m:GetInventoryResponse>
<m:Countries>
<m:Country>
<m:Name>Russia</m:Name>
<m:Regions>
<m:Region>
<m:Name>Omsk</m:Name>
<m:Cities>
<m:City>
<m:Name>Omsk</m:Name>
<m:Offices>
<m:Office>
...
<m:Networks>
<m:Network>
<m:Servers>
<m:Server>
<m:cards>
<m:card>
<m:ports>
<m:port>
<m:links>
<m:link>
<m:devices>
<m:device>
<m:cards>
<m:card>
<m:ports>
<m:port>
// Вложенная структура других device
</m:port>
</m:ports>
</m:card>
</m:cards>
</m:device>
</m:devices>
</m:link>
</m:links>
</m:port>
</m:ports>
</m:card>
</m:cards>
</m:Server>
</m:Servers>
</m:Network>
</m:Networks>
</m:Office>
</m:Offices>
</m:City>
</m:Cities>
</m:Region>
</m:Regions>
</m:Country>
</m:Countries>
</m:GetInventoryResponse>
</soap:Body>
</soap:Envelope>
Собственно говоря, это тоже SOAP. Не вижу смысла такое декомпозировать на глобалы. Подобного рода сообщения удобнее хранить целиком.
… а потом вам надо в этом «хранить целиком» найти ответ, в котором содержится узел, удовлетворяющим конкретным критериям. Желательно все-таки не полным перебором и десериализацией.
(и да, это реальный сценарий использования, я такую систему разработал и внедрил)
(и да, это реальный сценарий использования, я такую систему разработал и внедрил)
Это обычная inventory.xml, описывающая обычную сеть обычной распределенной компании. Иногда уровни вложенности могут быть бесконечными, особенно если там прибавить связи разными сервисами в облаках, один из которых указывает на другой и т.д… Это рядовая задача энтерпрайза.
Разве есть смысл такое декомпозировать на глобалы для быстрого доступа к отдельным узлам?
Глобалы и XML — это специфичные ситуации, а не волшебная пилюля от всего.
Глобалы и XML — это специфичные ситуации, а не волшебная пилюля от всего.
Если вы хотите конкурировать с mongoDB, то естественно нужно. Смысл mongoDB в том что она очень быстро записывает и отдает как целый документ, так и его отдельные части. Предлагать клиентам вон ту структуру данных пишите нам, а с вон с той идите лесом в другую базу — верный способ их потерять. Проблема в том что ваши глобалы предлагают либо писать все целиком, либо отдельными узлами, но при этом с ограничениями вложенности, размера и не факт что сборка целого json'a документа будет быстрой.
Отдельные части Mongo не сможет отдать так же быстро как глобалы, из-за того, что придётся парсить документ и вынимать из него отдельную часть. Я не проводил тестов. Мне это ясно из устройства баз. Моё мнение.
У Mongo для JSON свои сильные преимущества. К ней не нужно реализовывать свой язык запросов.
Глобалы тоже прекрасно хранят JSON, но для этого нужно писать свой код или использовать EWD, например.
Этот пост вообще не для клиентов. Просто о возможностях глобалов для разработчиков.
У Mongo для JSON свои сильные преимущества. К ней не нужно реализовывать свой язык запросов.
Глобалы тоже прекрасно хранят JSON, но для этого нужно писать свой код или использовать EWD, например.
Этот пост вообще не для клиентов. Просто о возможностях глобалов для разработчиков.
Мне это ясно из устройства баз. Моё мнение.
Боюсь ваше устройство баз весьма слабое, в монге храниться не обычный JSON, специально проиндексированный и заранее распарсенный BSON (как я понимаю с индексом с помощью того же бинарного дерева). Так что чье кун-фу сильнее должны решать тесты, а не чье-то мнение о неправильном устройстве баз.
Возьмем простой SOAP (неймспейсы я повырезаю):
Посмотрим, сколько уровней нам надо для его представления:
(Откуда нули? Из того банального соображения, что элементов с одним наименованием может быть много, а глобалы, насколько я понял, не умеют несколько одинаково названных подиндексов. Ну и порядок тегов тоже имеет значение. Плюс надо атрибуты отдельно выносить, для них тоже поможет, благо, вот они не имеют порядка.)
Итого один уровень вложенности в XML дает нам два индекса, соответственно, чтобы получить 31 уровень, нужно, округляя, 16 уровней вложенности.
Вот вам пример сообщения в СМЭВ при обмене с одним малоизвестным ведомством:
Я насчитал 13 уровней. И это не самый заковыристый вариант (в нем только три конверта — SOAP, СМЭВ, ведомство, в реальности я видел ситуации, когда внутри конверта ведомства лежал следующий конверт с семантикой «пакет», а еще дальше — отдельный документ со структурой). И да, в СМЭВ 3 будет веселее, потому что там другие требования к структуре объектов.
Для пущего развлечения хочу заметить, что в этой же структуре легко могут быть бинарные элементы объемом до 5 (а иногда и больше) Мб.
<s:Envelope>
<s:Body>
<MessagePart/>
</s:Body>
</s:Envelope>
Посмотрим, сколько уровней нам надо для его представления:
"156" //идентификатор сообщения
"156","s:Envelope" //корневой элемент
"156","s:Envelope", "0", "s:Body" //тело SOAP
"156","s:Envelope", "0", "s:Body", "0", "MessagePart" //добрались до собственно данных
(Откуда нули? Из того банального соображения, что элементов с одним наименованием может быть много, а глобалы, насколько я понял, не умеют несколько одинаково названных подиндексов. Ну и порядок тегов тоже имеет значение. Плюс надо атрибуты отдельно выносить, для них тоже поможет, благо, вот они не имеют порядка.)
Итого один уровень вложенности в XML дает нам два индекса, соответственно, чтобы получить 31 уровень, нужно, округляя, 16 уровней вложенности.
Вот вам пример сообщения в СМЭВ при обмене с одним малоизвестным ведомством:
<S:Envelope>
<S:Body>
<ws:DXSmev>
<smev:MessageData>
<smev:AppData>
<dx:DXBox>
<dx:DXPack>
<dx:Documents>
<ns2:exitRestrictionActRequest>
<data>
<AddressData>
<Address>
<OKATO>46248501000</OKATO>
</Address>
</AddressData>
</data>
<data>
<personDatum>
<FIO>
<Surname>Коняв</Surname>
</FIO>
</personDatum>
</data>
</ns2:exitRestrictionActRequest>
</dx:Documents>
</dx:DXPack>
</dx:DXBox>
</smev:AppData>
</smev:MessageData>
</ws:DXSmev>
</S:Body>
</S:Envelope>
Я насчитал 13 уровней. И это не самый заковыристый вариант (в нем только три конверта — SOAP, СМЭВ, ведомство, в реальности я видел ситуации, когда внутри конверта ведомства лежал следующий конверт с семантикой «пакет», а еще дальше — отдельный документ со структурой). И да, в СМЭВ 3 будет веселее, потому что там другие требования к структуре объектов.
Для пущего развлечения хочу заметить, что в этой же структуре легко могут быть бинарные элементы объемом до 5 (а иногда и больше) Мб.
Хороший пример, имеет смысл, спасибо!
(Есть некоторые «стилистичекие» замечания к авторам _такого_ формата, но раз уж выросло такое...)
При десериализации такого в объекты я бы в нескольких местах пропускал лишние промежуточные конверты (например, smev:MessageData/smev:AppData, или AddressData/Address), но наверное я чего-то не понимаю, и они там действительно нужны.
В-любом случае, я пока не вижу как, даже при таком адовом дизайне схемы, мы упрёмся в 32 вложенных подындекса. Все же хотелось бы примера из жизни, который имел бы смысл.
P.S.
И да, для больших BLOB-ов всегда и везде придется разбивать блоки на подузлы. В этом нет ничего специального — везде есть верхний предел блока базы, или страницы в хранилище, или ограничения по длине примитива, которые приходится обходить разбивая на куски, например, по 32КБ.
Трюк, при работе с базами данных, минимизировать количество обращений к диску, при заданных параметрах файловой системы и дискового хранилища. Понятно, что ни в какой ОС, нет возможности прочитать 32МБ BLOB за одно обращение к IO. И, понятно, что на практике придется читать блоками определенного размера (приближенными, например, к размеру блока файловой-системы). Так вот, при большом количестве возможных вариантов оказывается что хранение BLOB-ов кусками по 32КБ вполне хороший вариант. :)
(Есть некоторые «стилистичекие» замечания к авторам _такого_ формата, но раз уж выросло такое...)
При десериализации такого в объекты я бы в нескольких местах пропускал лишние промежуточные конверты (например, smev:MessageData/smev:AppData, или AddressData/Address), но наверное я чего-то не понимаю, и они там действительно нужны.
В-любом случае, я пока не вижу как, даже при таком адовом дизайне схемы, мы упрёмся в 32 вложенных подындекса. Все же хотелось бы примера из жизни, который имел бы смысл.
P.S.
И да, для больших BLOB-ов всегда и везде придется разбивать блоки на подузлы. В этом нет ничего специального — везде есть верхний предел блока базы, или страницы в хранилище, или ограничения по длине примитива, которые приходится обходить разбивая на куски, например, по 32КБ.
Трюк, при работе с базами данных, минимизировать количество обращений к диску, при заданных параметрах файловой системы и дискового хранилища. Понятно, что ни в какой ОС, нет возможности прочитать 32МБ BLOB за одно обращение к IO. И, понятно, что на практике придется читать блоками определенного размера (приближенными, например, к размеру блока файловой-системы). Так вот, при большом количестве возможных вариантов оказывается что хранение BLOB-ов кусками по 32КБ вполне хороший вариант. :)
(Есть некоторые «стилистичекие» замечания к авторам _такого_ формата, но раз уж выросло такое...)
Это бесполезно. Спорить с госуровнем — гиблое дело. Я пробовал, не помогло.
При десериализации такого в объекты я бы в нескольких местах пропускал лишние промежуточные конверты (например, smev:MessageData/smev:AppData, или AddressData/Address), но наверное я чего-то не понимаю, и они там действительно нужны.
Иногда нужны, если вам нужен полный аудит.
В-любом случае, я пока не вижу как, даже при таком адовом дизайне схемы, мы упрёмся в 32 вложенных подындекса.
Ну, от этого конкретного примера до предела три уровня осталось. К сожалению, я не могу взять реальные данные из обмена, где было и побольше, пришлось публично доступные искать.
И да, для больших BLOB-ов всегда и везде придется разбивать блоки на подузлы.
Ключевой вопрос — кому придется. Лично я предпочитаю, чтобы это за меня делала БД (включая оптимизацию этого доступа и прочее счастье). То есть я понимаю, что у БД есть страницы, а у хранилища ниже уровнем — блоки, но можно я об этом не буду думать?
То есть я понимаю, что у БД есть страницы, а у хранилища ниже уровнем — блоки, но можно я об этом не буду думать?
Так в Cache' и не надо об этом думать: поточные поля (символьные или бинарные) автоматически при сохранении бьются на куски.
Но в этом случае мы уже оперируем не чистым иерархическим хранилищем/глобалами, описанными автором, а пользуемся надстройкой над ними в виде объектов/классов, предоставленными Cache', но в основе своей использующими те же самые глобалы.
В-любом случае, я пока не вижу как, даже при таком адовом дизайне схемы, мы упрёмся в 32 вложенных подындекса. Все же хотелось бы примера из жизни, который имел бы смысл.
На самом деле, в xml мы заодно влетаем в соседнее ограничение: максимальная длина ключа в 511 байт. Предположим, что мы добрые, и у нас однобайтовая кодировка (на самом деле, конечно, нет; ненавижу тебя, госуха) — это все равно 511 символов, а по-хорошему, имена надо хранить квалифицированными (я подозреваю, что если пример выше квалифицировать — то он уже вылетит за длину).
Со СМЭВом этим вы заинтриговали, коллега, который этим занимается сейчас в отпуске, но у меня было впечатление что эта адовая XML схема вообще без проблем использовалась ими в их инсталляциях HealthShare/Ensemble в России. Вернется из отпуска — посмотрю на то как это проецируется в Cache'. Интересно.
А у некоторых БД на глобалах — 1019 байт. У GT.M.
Чтобы упереться даже в 511, нужно чтобы каждый индекс глобала был в среднем больше 16.5 байт.
Глобалы — это специфический инструмент, весьма универсальный, но со своими ограничениями.
Чтобы упереться даже в 511, нужно чтобы каждый индекс глобала был в среднем больше 16.5 байт.
Глобалы — это специфический инструмент, весьма универсальный, но со своими ограничениями.
Вообще я не говорил, что глобалы самый лучший способ хранения XML. Это один из способов, когда приемлемая вложенность и нужен быстрый доступ к узлам.
Вы говорили, что xml легко хранится в глобалах. Легко-то легко, только есть ограничения. Специализированные хранилища справляются с этим сущееественно лучше.
Что же это вы исключений не обозначили? Вы утверждаете что специализированные хранилища справляются с этим существенно лучше в абсолютно всех случаях?
Нет, зачем же во всех? В общих.
Вообще расплывчатое определение. Общий случай.
Что это такое общий случай?
Если нужно хранить документы целиком, то я не удивлюсь, если кто-нибудь выберет глобалы из-за их скорости.
А если нужно менять/добавлять/удалять отдельные узлы в документах, то глобалы прямо созданы для этого.
Есть бесконечное множество сценариев использования иерархических документов. И для приличной части этого бесконечного количества могут подойти глобалы. Всё зависит от задачи.
Что это такое общий случай?
Если нужно хранить документы целиком, то я не удивлюсь, если кто-нибудь выберет глобалы из-за их скорости.
А если нужно менять/добавлять/удалять отдельные узлы в документах, то глобалы прямо созданы для этого.
Есть бесконечное множество сценариев использования иерархических документов. И для приличной части этого бесконечного количества могут подойти глобалы. Всё зависит от задачи.
Если нужно хранить документы целиком, то я не удивлюсь, если кто-нибудь выберет глобалы из-за их скорости.
… ограничение в 3.6Мб.
А если нужно менять/добавлять/удалять отдельные узлы в документах, то глобалы прямо созданы для этого.
… ограничение по глубине вложенности.
Нет, несомненно, глобалы могут подойти. Просто каждый раз есть вопрос — а нет ли чего-то, что подойдет лучше?
Ограничения есть у всех баз. Если хранить документы целиком, то 16МБ, на весь документ, очень жёсткое ограничение.
А если нужно декомпозировать на иерархическую структуру с быстрым доступом к свойствам, то 3.6Мб на отдельное свойство не такое и большое ограничение.
Технологию подбирают подзадачу. Я постарался систематизировать сильные стороны глобалов.
А если нужно декомпозировать на иерархическую структуру с быстрым доступом к свойствам, то 3.6Мб на отдельное свойство не такое и большое ограничение.
Технологию подбирают подзадачу. Я постарался систематизировать сильные стороны глобалов.
Если хранить документы целиком, то 16МБ, на весь документ, очень жёсткое ограничение.
Ну так возьмите БД, в которой нет такого ограничения. Это не обязательно глобалы.
А если нужно декомпозировать на иерархическую структуру с быстрым доступом к свойствам, то 3.6Мб на отдельное свойство не такое и большое ограничение.
… пока мы не пытаемся хранить в свойствах файлы.
Я постарался систематизировать сильные стороны глобалов.
Ну вот XML, файлы и индексы — как-то не сильная сторона оказалась.
Сильная, только для специфических случаев. Каких — уже говорил.
Специализированная БД для файлов — это файловая система.
Специализированная БД для файлов — это файловая система.
Если хранить документы целиком, то 16МБ, на весь документ, очень жёсткое ограничение.
Ну так возьмите БД, в которой нет такого ограничения. Это не обязательно глобалы.
16МБ — это у Mongo. У подобных Mongo баз есть ограничения на объём документа, весьма жёсткие. И на число уровней (у Mongo — 100). Так как иначе парсер (при доступе к конкретным свойствам) будет вешать сервер.
У подобных Mongo баз есть ограничения на объём документа, весьма жёсткие.
Ага. Вот например у RavenDB нет (точнее, есть — около пары гигабайт).
Конечно, можно сказать, что равен не подобен монге (и в чем-то это правда даже), но равен — честная ДОДБ.
Сказки, у монго доступ к конкретным свойствам очень быстрый. И между 16Мб и 3,6 Мб и 100 и 31 уровней вложенности — четыре большие разницы.
Сказки, у монго доступ к конкретным свойствам очень быстрый.
По сравнению с чем? Сколько выборок в секунду ты можешь сделать из разных документов объёмом 3МБ с 15-го уровня вложенности?
Тут есть чёткие дихотомии.
Упрощённый алгоритм для выбора иерархической документно-ориентированной базы с возможностью быстрого доступа к свойствам.
0) Документы больше 16МБ
— но свойства меньше 3.6 — глобалы
— свойства не укладываются в 16МБ — не то, ни другое (если не использовать разрезание документов на части)
2) Документы целиком больше 3.6 и меньше 16 — Mongo
3) Меньше 3.6МБ и больше 100 уровней вложенности — Mongo
4) Меньше 3.6МБ и менее 31 уровня вложенности — глобалы
5) Документы около 1К — на вкус и цвет товарищей нет
Вы так говорите, как будто кроме монги и глобалов жизни не существует.
Не говоря уже о том, что задача («выбор иерархической документно-ориентированной базы с возможностью быстрого доступа к свойствам») изначально неверна, плясать надо от сценариев использования. Ну и да, polyglot persistence рулит.
Не говоря уже о том, что задача («выбор иерархической документно-ориентированной базы с возможностью быстрого доступа к свойствам») изначально неверна, плясать надо от сценариев использования. Ну и да, polyglot persistence рулит.
vedenin1980 — специалист по Mongo, я пишу про глобалы, и с ним мы обсуждали именно Mongo vs глобалы.
А вот за вами я заметил сомнительную привычку влезать в чужие диалоги. Вы делаете это постоянно. Из-за чего в пылу дискуссии разок я вас уже перепутал.
А вот за вами я заметил сомнительную привычку влезать в чужие диалоги. Вы делаете это постоянно. Из-за чего в пылу дискуссии разок я вас уже перепутал.
Скажите, а для документа выше как надо поступить?
Какая структура для его компонентного хранения?
Мне как не специалисту кажется, что требуется аналог Parent_ID и/или Child_ID а не пытаться уровни иерархии документа вписать в уровни иерархии индексов.
Какая структура для его компонентного хранения?
Мне как не специалисту кажется, что требуется аналог Parent_ID и/или Child_ID а не пытаться уровни иерархии документа вписать в уровни иерархии индексов.
даже в самых монстрах не будет и 20
Максимальная вложенность исходного кода этой страницы как раз 20. Она монстр?
А есть хоть какой-то смысл хранить HTML этой страницы в БД с обеспечением быстрого доступа к каждому узлу?
Подобные документы достаются из БД целиком.
А вот например в XML медкарты добавить новый узел со сканом МРТ будет удобно.
Подобные документы достаются из БД целиком.
А вот например в XML медкарты добавить новый узел со сканом МРТ будет удобно.
А есть хоть какой-то смысл хранить HTML этой страницы в БД с обеспечением быстрого доступа к каждому узлу?
Самое очевидное — если её надо сформировать.
Формировать страницу через то, что записать всё по тэгам в иерархическую БД?
Это будет медленнее, чем формировать напрямую в памяти.
Использовать глобалы как кеш? В этом случае имеет смысл хранить куски документа целиком без разбиения по свойствам.
Это будет медленнее, чем формировать напрямую в памяти.
Использовать глобалы как кеш? В этом случае имеет смысл хранить куски документа целиком без разбиения по свойствам.
Прямо на М и формировать. Данные в глобалах, мета-данные тоже, пусть М программы и формируют страничку.
Можно использовать глобалы во время отладки.
А в продакшене — локальные переменные.
Можно использовать глобалы во время отладки.
А в продакшене — локальные переменные.
Как я понимаю, на Caché Server Pages так и делают.
Вообще я удивлён, что M в своё время не захватил нишу веб-разработки как PHP. Языки-то сильно похожие.
Вообще я удивлён, что M в своё время не захватил нишу веб-разработки как PHP. Языки-то сильно похожие.
Ага, скан у вас помещается в 3.6Мб? Мне когда последний раз выдавали на руки сканы (не МРТ правда, а рентгена) — они как раз заняли половину CD-болванки (какой-то чертов пропьетарный формат для медицинского ПО). Да что там, у меня в 3.6 мегабайта фотографии с моего фотоаппарата не помещаются.
Болванка МРТ состоит из множества файлов в формате DICOM. Как кино из отдельных кадров.
Я открыл свою МРТ — каждый кадр это 586КБ.
Тем более, я не уверен, что есть смысл в медкарте хранить все эти файлы. Достаточно выбрать самый характерный.
Но таких отдельных кадров, сканов анализов может быть очень много.
Я открыл свою МРТ — каждый кадр это 586КБ.
Тем более, я не уверен, что есть смысл в медкарте хранить все эти файлы. Достаточно выбрать самый характерный.
Но таких отдельных кадров, сканов анализов может быть очень много.
К сожалению, то, что отдельный скан может быть больше 3.6Мб — это такая реальность, данная нам в ощущениях. Не МРТ — так рентген, не рентген — так еще что-то.
Нет, я понимаю, что объяснить заказчику можно любое ограничение (чего уж скрывать, все мы так рано или поздно делали), но на этом фоне придирки к аналогичным ограничениям у монги выглядят мелко.
Нет, я понимаю, что объяснить заказчику можно любое ограничение (чего уж скрывать, все мы так рано или поздно делали), но на этом фоне придирки к аналогичным ограничениям у монги выглядят мелко.
Поэтому эти придирки и в спойлере. И там жёстко обозначена область, в которой глобалы подходят лучше.
Структуры хранения в Mongo и глобалы логически идеентичны. Различия только в реализациях и во встроенных языках.
Если интересно, то Mongo хочет влезть на этот рынок и готовит презентации, где говорит, что Mongo — это почти глобалы)
Структуры хранения в Mongo и глобалы логически идеентичны. Различия только в реализациях и во встроенных языках.
Если интересно, то Mongo хочет влезть на этот рынок и готовит презентации, где говорит, что Mongo — это почти глобалы)
И там жёстко обозначена область, в которой глобалы подходят лучше.
Угу. Та, где вам, на самом деле, не нужно хранилище документов, а нужно хранилище свойств. Дальше вопрос к сценариям использования и архитектуре приложения.
Документы состоят из свойств. Глобалы дают возможность красиво и быстро декомпозировать документы по свойствам.
Это и есть ключевое преимущество перед БД, которые хранят целиком.
Глобалы — это одна из самых первых документно-ориентированных баз, если не первая вообще (66г!).
Это и есть ключевое преимущество перед БД, которые хранят целиком.
Глобалы — это одна из самых первых документно-ориентированных баз, если не первая вообще (66г!).
Документы состоят из свойств.
Это неоднозначный вопрос, сводящийся к тому, состоит ли целое из частей. Смысл ДОДБ, обычно, все-таки в том, чтобы работать с документом, как с целым (я приводил сценарий использования, он не единственный).
В любом случае: глобалы позволяют как хранить документ целиком, так и разбивая на части. С известными ограничениями.
По логической структуре глобалы — это надмножество над документно-ориентированными базами, которые хранят документы целиком.
По логической структуре глобалы — это надмножество над документно-ориентированными базами, которые хранят документы целиком.
По логической структуре глобалы — это надмножество над документно-ориентированными базами, которые хранят документы целиком.
Не-а. Глобалы — надмножество над key-value, потому что глобалы не умеют анализ содержимого документа (а именно оно специфично для документо-ориентированных хранилищ).
А может Глобалы — key-value, где key может быть массивом?
Расскажите мне как анализирует, например, MongoDB документы.
Желательно как оно это делает само. Без запросов со стороны.
Так как к любой БД на глобалах также можно написать интерфейс для запросов. И код для анализа.
Желательно как оно это делает само. Без запросов со стороны.
Так как к любой БД на глобалах также можно написать интерфейс для запросов. И код для анализа.
Это лишь простейший пример, на самом деле зачастую в энтерпрайзе вообще требуется бесконечное кол-во уровней иерархии, например вы хотите сделать сервис который строит дерево всех страниц любого сайта инета, доступных с главной страницы сайта, естественно вы должны считать что вложенность тут может быть бесконечной (ну или заведомо очень большой). И таких случаев в реальном энтерпрайзе довольно много.
Как и первая статья — много маркетологической шелухи, никакой конкретики.
Тут что-то про скорость говорили… Так а где повторяемые и открытые тесты?
Где техническое описание, как же оно работает «под капотом»?
Напоминаю, что это хабр, а вовсе не гиктаймс или мегамозг.
Тут что-то про скорость говорили… Так а где повторяемые и открытые тесты?
Где техническое описание, как же оно работает «под капотом»?
Напоминаю, что это хабр, а вовсе не гиктаймс или мегамозг.
Цель этой статьи — обозначить области применения глобалов, поскольку многие вообще не знают об этой технологии и о её сильных сторонах.
На техническое описание формата хранения я дал ссылку в первых же комментах.
По реализации — уже говорилось, что известные БД на глобалах работают на B*-tree, но в принципе могут работать и на других алгоритмах.
Не все читатели тут являются разработчиками БД. Моя цель в этих статьях — показать для чего нужны глобалы, а не как конкретно они работают и какие оптимизации были использованы.
На техническое описание формата хранения я дал ссылку в первых же комментах.
По реализации — уже говорилось, что известные БД на глобалах работают на B*-tree, но в принципе могут работать и на других алгоритмах.
Не все читатели тут являются разработчиками БД. Моя цель в этих статьях — показать для чего нужны глобалы, а не как конкретно они работают и какие оптимизации были использованы.
Давайте, все же я попытаюсь вернуть дискуссию в правильное с методической точки зрения русло?
Моя позиция такова — с логической точки зрения разницы многомерного хранилища (глобалов), документной базы (JSON/BSON) и XML иерархии нет. Они все оперируют эквивалентным множеством моделей и данных.
(Что я попытался донести в своей презентации на RIT 2015 Cache'Conf —
www.slideshare.net/TimurSafin/multimodel-database-cach )
Интересна позиция Mongo в этом отношении osehra.org/sites/default/files/NoSQLtheModernMUMPS.pdf
При разговоре с группой пользователей VistA они пытались донести до аудитории мысль, что Mongo/документные базы, это тоже самое, что и иерархические базы (MUMPS/Cache'). С чем я не могу не согласиться :)
Еще один важный аспект, в большинстве случае движки СУБД оперируют вариациями b-tree формата (когда они не SSTable/LSM, конечно). И Cache' с его b*-tree тут не сильно отличается, хотя и отличается в деталях, облегчающих множество операций с глобалами, упомянутых Сергеем inetstar в этих двух статьях. Детали формата b*-tree мы попытались раскрыть в двух презентациях на недавнем RIT (моей ретроспективной, упомянутой выше, и Сергея Шутова про внутренности собственно Cache' b*-tree. Как оказалось его презентации в онлайне нет, как только исправим ситуацию сообщу в эту ветку)
Моя позиция такова — с логической точки зрения разницы многомерного хранилища (глобалов), документной базы (JSON/BSON) и XML иерархии нет. Они все оперируют эквивалентным множеством моделей и данных.
(Что я попытался донести в своей презентации на RIT 2015 Cache'Conf —
www.slideshare.net/TimurSafin/multimodel-database-cach )
Интересна позиция Mongo в этом отношении osehra.org/sites/default/files/NoSQLtheModernMUMPS.pdf
При разговоре с группой пользователей VistA они пытались донести до аудитории мысль, что Mongo/документные базы, это тоже самое, что и иерархические базы (MUMPS/Cache'). С чем я не могу не согласиться :)
Еще один важный аспект, в большинстве случае движки СУБД оперируют вариациями b-tree формата (когда они не SSTable/LSM, конечно). И Cache' с его b*-tree тут не сильно отличается, хотя и отличается в деталях, облегчающих множество операций с глобалами, упомянутых Сергеем inetstar в этих двух статьях. Детали формата b*-tree мы попытались раскрыть в двух презентациях на недавнем RIT (моей ретроспективной, упомянутой выше, и Сергея Шутова про внутренности собственно Cache' b*-tree. Как оказалось его презентации в онлайне нет, как только исправим ситуацию сообщу в эту ветку)
Это потому что вы вставили колонки без значений по-умолчанию.
Попробуйте задать такие значения.
Далее, для корректности вашего теста, вам нужно было определить в каждой строке случайным образом один аттрибут и посмотреть на какой размер изменилась таблица.
P.S. Я тестировал на MySQL 5.5.
Ждёт результатов тестирований. Надеюсь, таблица slnx_job у вас большая.
Попробуйте задать такие значения.
Далее, для корректности вашего теста, вам нужно было определить в каждой строке случайным образом один аттрибут и посмотреть на какой размер изменилась таблица.
P.S. Я тестировал на MySQL 5.5.
Ждёт результатов тестирований. Надеюсь, таблица slnx_job у вас большая.
Это потому что вы вставили колонки без значений по-умолчанию.
А зачем использовать значения по умолчанию в БД? Точнее, не так: значение по умолчанию — это не пустая колонка, это именно имеющее смысл значение (например, текущая дата). И неудивительно, что на него тратится место. А на несуществующие значения — не тратится (точнее, зависит от реализации).
А зачем использовать значения по умолчанию в БД?
Во многих БД таблицы, где NULL не используются работают существенно быстрее.
Во многих БД таблицы, где NULL не используются работают существенно быстрее.
У вас, конечно же, есть тесты, подтверждающие это заявление. Скажем, в MS SQL я такого никогда не наблюдал (и, собственно, не понимаю, откуда там этому логически взяться).
For best performance, and to reduce potential code bugs, columns should ideally be set to NOT NULL. For example, use of the IS NULL keywords in the WHERE clause makes that portion of the query non-sargeble, which means that portion of the query cannot make good use an index.
И подобных статей много. Ещё одна:
И подобных статей много. Ещё одна:
Using NULL values has the following drawbacks:
1) Using NULL values in the Database is always going to be overhead in terms of querying the tables’ columns containing the NULL values especially the larger tables. This is because, to query the column which has the NULL values from the table, index won’t be used as we need to query using IS NULL clause. As a result full table scan is performed.
2) When NULL value is used as one of the value for the column, it takes up the whole length of the column size if the column is of fixed length. However, using variable length column does not have this impact but otherwise with fixed length columns, always to store NULL value it occupies the entire column length resulting in growing the Database size which is totally unnecessary.
3) Using NULL values in the Columns of the tables lead to convoluted Transact SQL code resulting in code not running efficiently or error prone.
Hence, considering above, always try to avoid using NULL values and instead one can use some constants to represent NULL values like N/A.
Еще раз спрашиваю, тесты есть?
По мелочам:
По мелочам:
- В статье, на которую вы ссылаетесь первой ссылкой, нет приведенного вами текста («For best performance....»; собственно, в ней вообще нет слова «performance»)
- Что касается второй «статьи», то она говорит, что при поиске по
NULL(обратите внимание, не просто по колонке, которая может содержать такие значения, а именно поиск строк содержащих такие значения) индексы не используются, т.е. стоимость такого поиска (и того такого, а не любого другого) эквивалентна полному перебору. Во-первых, она ничего не говорит о любых других операциях по такой таблице. Во-вторых, просветите меня, пожалуйста, какова алгоритмическая сложность поиска узла, не содержащего заданный подиндекс, в глобале? Т.е., как найти всех пользователей, у которых не задан город?
А в глобалах я легко могу сделать подобный индекс. В индексном глобале (и только в нём), например, в качестве NULL буду использовать "\0"
Set ^index_global("\0", id1) = 1
Set ^index_global("Moscow", id2) = 1В RDBMS тоже можно сделать подобный индекс, технически ничего не мешает.
(кстати, а что вы будете делать, когда \0 — валидное значение?)
(кстати, а что вы будете делать, когда \0 — валидное значение?)
Собственно, постгре и индексирует: «Also, an
IS NULL or IS NOT NULL condition on an index column can be used with a B-tree index.»Даже больше, есть мнение, что
NULL не только не замедляют, но и ускоряют работу постгре.NOT NULL, в некоторых случаях, действительно ускоряет работу постгреса. Если в таблице в начале идут NOT NULL атрибуты фиксированной длины, то доступ к этим атрибутам осуществляется по предвычисленным значениям. Однако, почувствовать это преимущество на паре десятков атрибутов, вряд ли получится.
P.S. Умоляю вас, «постгрес» :)
P.S. Умоляю вас, «постгрес» :)
Разговор был о MS SQL.
Условный индекс — это не то. Придётся для каждого столбца делать 2 индекса — по колонкам и условия. Это убьёт производительность. А в моём случае это будет один индексный глобал на одну колонку (set колонок).
Напоминаю исходную точку разговора: не рекомендуется вручную программировать таблицы на глобалах. Не к тому цепляетесь.
Условный индекс — это не то. Придётся для каждого столбца делать 2 индекса — по колонкам и условия. Это убьёт производительность. А в моём случае это будет один индексный глобал на одну колонку (set колонок).
Напоминаю исходную точку разговора: не рекомендуется вручную программировать таблицы на глобалах. Не к тому цепляетесь.
Разговор был о MS SQL.
Разговор был о «во многих БД». Впрочем, вы и в MS SQL падение производительности не подтвердили.
Условный индекс — это не то.
А я и не про условные индексы.
Придётся для каждого столбца делать 2 индекса — по колонкам и условия. Это убьёт производительность.
С чего вы это взяли?
Напоминаю исходную точку разговора: не рекомендуется вручную программировать таблицы на глобалах.
Я вообще не понимаю, зачем программировать таблицы на глобалах, когда есть нормальные табличные инструменты.
Разговор был о MS SQL.
… который тоже поддерживает индексы с
NULL.SELECT [Id], [Text]
FROM [dbo].[NV]
WHERE Text IS NULL
// Execution plan
Index Seek(OBJECT:([Speed].[dbo].[NV].[IX_NV]), SEEK:([Speed].[dbo].[NV].[Text]=NULL) ORDERED FORWARD)
Передаю пламенный привет (устаревшим) статьям, которые вы цитировали.
1) Вы не показали определение таблицы, в котором это поле указано как индексируемое
2) Приведите ссылку на документацию
3) И что это действительно не только для текстовых полей.
4) Сделайте ещё поиск по NOT NULL по текстовому и не по текстовому полю
5) Вы не сможете сделать строку из 10 000 столбцов, размером более 8КБ. Так что глобалы на разреженных данных MS SQL в общем случае заменить не сможет.
2) Приведите ссылку на документацию
3) И что это действительно не только для текстовых полей.
4) Сделайте ещё поиск по NOT NULL по текстовому и не по текстовому полю
5) Вы не сможете сделать строку из 10 000 столбцов, размером более 8КБ. Так что глобалы на разреженных данных MS SQL в общем случае заменить не сможет.
Вы не показали определение таблицы, в котором это поле указано как индексируемое
Вы серьезно считаете, что MS SQL способен использовать индекс, который не задан? Но мне не сложно.
CREATE TABLE [dbo].[NV](
[Id] [uniqueidentifier] NOT NULL,
[Text] [nvarchar](50) NULL,
CONSTRAINT [PK_NV] PRIMARY KEY CLUSTERED ([Id] ASC)
) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_NV] ON [dbo].[NV] ([Text] ASC) ON [PRIMARY]
GO
Приведите ссылку на документацию
msdn.microsoft.com/en-us/library/ms188783%28v=sql.110%29.aspx
И что это действительно не только для текстовых полей.
StmtText
---------------------------------------------------
SELECT Id, Int
FROM [dbo].[NV]
WHERE Int IS NULL
StmtText
-------------------------------------------------------------------------------------------------------------
|--Index Seek(OBJECT:([Speed].[dbo].[NV].[IX_NV_1]), SEEK:([Speed].[dbo].[NV].[Int]=NULL) ORDERED FORWARD)
Вы не сможете сделать строку из 10 000 столбцов, размером более 8КБ. Так что глобалы на разреженных данных MS SQL в общем случае заменить не сможет.
Чтобы сохранить разреженные данные, не обязательно пихать их в одну строчку одной таблицы. Поэтому как раз в общем случае — сможет.
1) Вообще-то в документации ничего не говорится об ускорении выборок строк с NULL-значениями.
2) И я просил привести примеры с NOT NULL ещё. Я-то легко на глобалах сделаю индексированную выборку по NOT NULL. О чём вы как-то забыли. Приводите.
3) Таблица в общем случае никогда не была деревом. Сэмулировать дерево на таблицах можно, но это нерационально. В этом тоже в статье написано.
2) И я просил привести примеры с NOT NULL ещё. Я-то легко на глобалах сделаю индексированную выборку по NOT NULL. О чём вы как-то забыли. Приводите.
3) Таблица в общем случае никогда не была деревом. Сэмулировать дерево на таблицах можно, но это нерационально. В этом тоже в статье написано.
Вообще-то в документации ничего не говорится об ускорении выборок строк с NULL-значениями.
А должно? Но вот вам: msdn.microsoft.com/en-us/library/ms190457%28v=sql.110%29.aspx
An index is an on-disk structure associated with a table or view that speeds retrieval of rows from the table or view. An index contains keys built from one or more columns in the table or view. These keys are stored in a structure (B-tree) that enables SQL Server to find the row or rows associated with the key values quickly and efficiently.
Никаких специальных оговорок про NULL нет.
И я просил привести примеры с NOT NULL ещё. Я-то легко на глобалах сделаю индексированную выборку по NOT NULL. О чём вы как-то забыли. Приводите.
А вы меньше редактируйте комментарий после отправки, меньше будет «забываться».
CREATE TABLE [dbo].[NV](
[Id] [uniqueidentifier] NOT NULL,
[TextNull] [nvarchar](50) NULL,
[IntNull] [int] NULL,
[TextNotNull] [nvarchar](50) NOT NULL,
[IntNotNull] [int] NOT NULL
)
SELECT Id FROM NV WHERE TextNull IS NULL
|--Index Seek(OBJECT:([Speed].[dbo].[NV].[IX_NV_4]), SEEK:([Speed].[dbo].[NV].[TextNull]=NULL) ORDERED FORWARD)
SELECT Id FROM NV WHERE TextNull IS NOT NULL
|--Index Seek(OBJECT:([Speed].[dbo].[NV].[IX_NV_4]), SEEK:([Speed].[dbo].[NV].[TextNull] IsNotNull) ORDERED FORWARD)
SELECT Id FROM NV WHERE TextNull = '123'
|--Index Seek(OBJECT:([Speed].[dbo].[NV].[IX_NV_4]), SEEK:([Speed].[dbo].[NV].[TextNull]=CONVERT_IMPLICIT(nvarchar(4000),[@1],0)) ORDERED FORWARD)
SELECT Id FROM NV WHERE IntNull IS NULL
|--Index Seek(OBJECT:([Speed].[dbo].[NV].[IX_NV_1]), SEEK:([Speed].[dbo].[NV].[IntNull]=NULL) ORDERED FORWARD)
SELECT Id FROM NV WHERE IntNull IS NOT NULL
|--Index Seek(OBJECT:([Speed].[dbo].[NV].[IX_NV_1]), SEEK:([Speed].[dbo].[NV].[IntNull] IsNotNull) ORDERED FORWARD)
SELECT Id FROM NV WHERE IntNull = 1
|--Index Seek(OBJECT:([Speed].[dbo].[NV].[IX_NV_1]), SEEK:([Speed].[dbo].[NV].[IntNull]=CONVERT_IMPLICIT(int,[@1],0)) ORDERED FORWARD)
SELECT Id FROM NV WHERE TextNotNull = '123'
|--Index Seek(OBJECT:([Speed].[dbo].[NV].[IX_NV_3]), SEEK:([Speed].[dbo].[NV].[TextNotNull]=CONVERT_IMPLICIT(nvarchar(4000),[@1],0)) ORDERED FORWARD)
SELECT Id FROM NV WHERE IntNotNull = 1
|--Index Seek(OBJECT:([Speed].[dbo].[NV].[IX_NV_2]), SEEK:([Speed].[dbo].[NV].[IntNotNull]=CONVERT_IMPLICIT(int,[@1],0)) ORDERED FORWARD)
Таблица в общем случае никогда не была деревом. Сэмулировать дерево на таблицах можно, но это нерационально.
Не более нерационально, чем имитировать таблицы на дереве. Но речь-то не об этом, речь о том, чтобы сохранить конкретные данные в реляционной структуре, а это совсем не то же самое, что «сэмулировать дерево».
1. Для это есть специальный индексный сервер.
Я просто попросил показать определение таблицы
2) Приведите ссылку на документацию
2.https://msdn.microsoft.com/en-us/library/ms142571.aspx
Требовалась ссылка на документацию, в которой было бы явно написано, что поля с NULL-значениями индексируются.
5)идея хранить дерево всего в одной таблице — неверная с архитектурной точки зрения в реляционых базах и мне видится неверной точка зрения что нельзя сохранить медицинскую историю человека в реляционной структуре.
Можно использовать несколько таблиц. И это всё равно будет ошибка с точки зрения архитектуры.
Watson использует DB2достоверной информации о том, что Watson использует DB2 как единственное хранилище не нашёл. Однако у IBM есть технология аналогичная глобалам.
Самая большая медицинская система с самым большим числом пользователей VistA, что говорит в пользу глобалов и об их подходящести для данной сферы. Собственно говоря, глобалы именно для этой сферы и придумали.
Статья откуда цитата про «best perfomance»
Нам лучше вернуться к теме. Так как больше 1024 колонок вы не сделаете в MS SQL. А в спец. типе таблиц wide строка не более 8КБ.
Нам лучше вернуться к теме. Так как больше 1024 колонок вы не сделаете в MS SQL. А в спец. типе таблиц wide строка не более 8КБ.
Статья откуда цитата про «best perfomance»
Это ровно тот же аргумент, что уже обсуждался — про индексы и поиск с IS NULL. Не интересно по второму разу обсуждать.
Так как больше 1024 колонок вы не сделаете в MS SQL.
А надо?
А в спец. типе таблиц wide строка не более 8КБ.
Я вам честно скажу, это ограничение есть во всех таблицах MS SQL, не только в wide. Правда, начиная с 2008-го, есть row overflow для строковых и бинарних типов, но он подтормаживает.
Так как больше 1024 колонок вы не сделаете в MS SQL.
А надо?
В статье была фраза, что глобалы хороши, когда есть много необязательных свойств, например в медкартах, а на таблицах тоже самое было реализовано десятками тысяч столбцов.
Человек мне сказал, что разреженные столбцы не занимают место и похвастался, что мог бы вставить 10 000 колонок в MS SQL. Так вот. Не смог бы. А если и смог бы, то там свои ограничения.
8КБ на строку с пациентом — это абсолютно нереально. И там ещё нельзя по одной новые колонки добавлять в этом типе таблиц.
Во-первых, для медкарт лучше ДОДБ. Но, во-вторых, если бы заказчик настаивал на RDBMS, то немного разумной декомпозиции — и все будет хорошо.
Я ни разу в жизни не видел ни одного объекта, у которого бы реально было хотя бы несколько сотен индивидуальных, недекомпонуемых на группы свойств. Человеческий мозг так не работает, ему некомфортно в таких моделях.
Я ни разу в жизни не видел ни одного объекта, у которого бы реально было хотя бы несколько сотен индивидуальных, недекомпонуемых на группы свойств. Человеческий мозг так не работает, ему некомфортно в таких моделях.
Во-первых, для медкарт лучше ДОДБ
Базы на глобалах — это и есть ДОБД.
Я ни разу в жизни не видел ни одного объекта
А вот я видел. Даже 40 свойств с десятками подсвойств заставляют разработчиков уже сходить с ума.
Я встречал это в базе, где хранилась персональная информация о людям.
Пришлось использовать EAV — я тогда ещё не знал о глобалах.
Базы на глобалах — это и есть ДОБД.
Это не единственные существующие ДОДБ. Более того, я уже писал, почему я не считаю глобалы ДОДБ.
А вот я видел. Даже 40 свойств с десятками подсвойств заставляют разработчиков уже сходить с ума.
Извините, но это не «сотни свойств», это именно «40 свойств с десятками подсвойств». У вас уже есть декомпозиция, но вы ее почему-то не видите.
почему я не считаю глобалы ДОБД
Вы просто не разбираетесь в ДОБД.
Почитайте википедию.
Там есть MUMPS.
У вас уже есть декомпозиция, но вы ее почему-то не видите.
Я вижу многоуровневое дерево. Ясно и отчётчиво.
На таблицах это либо EOV или 160 таблиц (с декомпозицией). А на глобалах — одно красивое дерево.
Вы просто не разбираетесь в ДОБД. Почитайте википедию.
Давайте не будем доставать и меряться, кто в чем разбирается, хорошо?
Я вижу многоуровневое дерево. Ясно и отчётчиво.
...eye of the beholder. Вы привыкли так декомпоновать системы, потому что вы привыкли так работать с глобалами. Это не значит, что это единственная возможная декомпозиция этой системы.
На таблицах это либо EOV или 160 таблиц (с декомпозицией).
Откуда взялась цифра «160»? Вы посчитали сущности в E-R?
Вы просто не разбираетесь в ДОБД. Почитайте википедию.
Давайте не будем доставать и меряться, кто в чем разбирается, хорошо?
Более скромно было сказать: Извиняюсь, вы правы.
Википедия — очень хороший аргумент. В мою пользу. Там за одну фразу может многомесячная борьба идти.
Вы сами себе выдумали определение ДОБД и решили, что оно самое лучшее. Так что ваше определение ДОБД — субъективное, а не то, которое реально используется в мире. А MUMPS — это ДОБД.
Откуда взялась цифра «160»?
Это примерная цифра. Слава богу, хватило ума, не делать полную нормализацию, а использовать EAV.
40 необязательных свойств, у которых у каждого может быть начиная от 4-х вложенных свойств. У которых также могут быть вложенные свойства. Все эти свойства разнотипны, а не просто текстовые поля определённой длины.
Так что при полной нормализации без EAV будет, как минимум, 1 таблица 40 колонками для свойств + 160 таблиц связей с подсвойствами + 4*40 таблиц подсвойствами = 321 даже. И это только при двухкратном уровне вложенности.
А на EAV 4 таблицы (из-за неограниченных вложенностей, а так вообще 3).
Но меня всё время не оставляла мысль, что это решение (EAV) не идеальное. Когда я узнал о глобалах, то понял то, что они то что нужно.
Вы сами себе выдумали определение ДОБД и решили, что оно самое лучшее. Так что ваше определение ДОБД — субъективное, а не то, которое реально используется в мире. А MUMPS — это ДОБД.
Субъективное, говорите?
Document databases store documents in the value part of the key-value store; think about document databases as key-value stores where the value is examinable. [...] Some of the popular document databases we have seen are MongoDB, CouchDB, Terrastore, OrientDB, RavenDB, and of course the well-known and often reviled Lotus Notes that uses document storage.
(Pramod J. Sadalage, Martin Fowler, NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence)
Я же говорю, не надо доставать и меряться. На поле с неустойчивой терминологией это заведомо бесполезное действие.
40 необязательных свойств, у которых у каждого может быть начиная от 4-х вложенных свойств. У которых также могут быть вложенные свойства. Все эти свойства разнотипны, а не просто текстовые поля определённой длины.
Вы мыслите свойствами, а не сущностями. Это опасный подход (хотя я и понимаю, откуда он у вас растет). Повторюсь, есть отличная от нуля вероятность, что существует иная декомпоновка этой модели, позволяющая получить более разумную структуру БД. К сожалению, дать более разумных комментариев, не видя модели, я не могу.
Ограничусь одним примером. Возьмем одну из ваших структур данных:
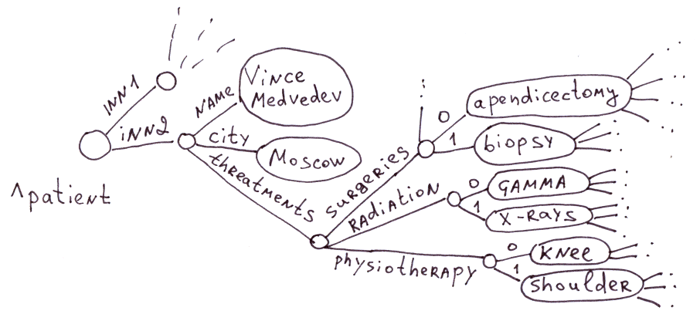
Если бы я это моделировал в ER, то единственными свойствами здесь оказались бы INN, Name и City. Все прочее декомпонуется в связи и сущности (к сожалению, я не вижу, какие семантические атрибуты есть на следующем уровне, и, как следствие, во что их надо отразить).
Хорошо, что вы решили провести тесты.
Однако я не вижу в вашей процедуре вставок значений. Вы просто добавили 900 пустых колонок.
И не вставили ни одного реального значения.
Данные должны быть разреженными, т.е. в некоторых колонках должны быть значения.
В вашем случае просто изменилось описание таблицы, а не её содержимое.
В некоторых БД оно вообще в отдельном файле хранится.
А лучше 1-3 случайных аттрибута.
Я уже писал про ограничение на 8КБ строку в MS SQL в wide типе — это очень мало для документа.
А в обычную таблицу вы 9000 колонок не добавите.
Ещё нужно было размер таблицы в байтах указывать.
Однако я не вижу в вашей процедуре вставок значений. Вы просто добавили 900 пустых колонок.
И не вставили ни одного реального значения.
Данные должны быть разреженными, т.е. в некоторых колонках должны быть значения.
В вашем случае просто изменилось описание таблицы, а не её содержимое.
В некоторых БД оно вообще в отдельном файле хранится.
Далее, для корректности вашего теста, вам нужно было определить в каждой строке случайным образом один аттрибут и посмотреть на какой размер изменилась таблица.
А лучше 1-3 случайных аттрибута.
Я уже писал про ограничение на 8КБ строку в MS SQL в wide типе — это очень мало для документа.
А в обычную таблицу вы 9000 колонок не добавите.
1,626,829 rows
Ещё нужно было размер таблицы в байтах указывать.
Я вижу проблему таблица с 1,626,829 rows и N+900 колонок занимает у вас 291272 байт.
Т.е. 0.17 байт на строку. Вы явно в чём-то ошиблись.
Даже если бы вы в каждую строку вставили по одному int — 4 байта, то размер был бы у вас не менее 6 000 000 байт, а у вас всего 290КБ.
Т.е. явно в чём-то ошибка. Объяснить это рационально предлагаю вам.
Т.е. 0.17 байт на строку. Вы явно в чём-то ошиблись.
Даже если бы вы в каждую строку вставили по одному int — 4 байта, то размер был бы у вас не менее 6 000 000 байт, а у вас всего 290КБ.
Т.е. явно в чём-то ошибка. Объяснить это рационально предлагаю вам.
Если хотите хранить честное дерево то это спасет отца демократии:
msdn.microsoft.com/en-us/library/bb677173.aspx
Это нечестное дерево, так как оно предполагает одинаковую структуру полей для всех узлов, на всех уровнях.
Но я соглашусь, что это хорошее подспорье в некоторых случаях.
То есть нужен цикл по всем id, со вставкой в случайную колонку.
Хранимку придётся писать. Ну или на ASP/PHP.
И ещё. Не знаю как MS SQL, но в MySQL с таблицы с колонками NULL работают медленнее.
Поэтому я, например, их избегаю.
Хранимку придётся писать. Ну или на ASP/PHP.
И ещё. Не знаю как MS SQL, но в MySQL с таблицы с колонками NULL работают медленнее.
Поэтому я, например, их избегаю.
Уверяю вас даже после добавления 10,000 колонок размер не поменяется.
Я могу такое допустить только в случае, когда абсолютно все эти колонки пустые.
Если же вы начнёте их хоть чуть-чуть использовать, то БД сразу начнёт выделять, как минимум, 1 бит на колонку.
В том тесте, что я предложил, если одна неточность. Вставлять нужно не одно значение в случайную колонку, так база может увеличить все строки на 4 байта, а случайное число значений (допустим 1-3) в случайные колонки каждой строки, вот тогда тест будет более менее точным.
Уверяю вас даже после добавления 10,000 колонок
А вот тут вы очень глубоко ошибаетесь. В MS SQL максимум 1024 колонки.
Исключение: есть специальный тип таблиц — wide — там до 30 000 колонок. Но в этом типе строка не больше 8КБ. Что сразу ставит крест на многих видах применений.
Второй минус этого типа — The column set cannot be changed. To change a column set, you must delete and re-create the column set.
И репликацию использовать нельзя для таких таблиц. Остальные детали
Таблицы на двухуровневом дереве vs. на одноуровневом дереве.
Минусы
Медленнее на вставку и удаление, так как нужно устанавливать/удалять число узлов равное числу колонок.
Но:
Удаление поддеревьев — ещё одна сильная сторона глобалов. Для этого не нужна рекурсия. Это происходит невероятно быстро.
Так все-таки, как соотносятся по скорости удаление поддерева и удаление одиночного узла в глобале?
Это вы нашли что-то типа опечатки. Сейчас исправлю.
Устанавливать придётся дольше, конечно, чем удалять.
Групповое удаление работает по моим тестам в 260-455 раз быстрее, чем индивидуальное удаление узлов. Для двухярусного дерева.
Устанавливать придётся дольше, конечно, чем удалять.
Групповое удаление работает по моим тестам в 260-455 раз быстрее, чем индивидуальное удаление узлов. Для двухярусного дерева.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Глобалы — мечи-кладенцы для хранения данных. Деревья. Часть 2