

Привет, меня зовут Мялкин Максим, я занимаюсь мобильной разработкой в KTS.
Не за горами выпуск новой версии Kotlin 2.0, основной частью которого является изменение компилятора на K2.
По замерам JB, K2 ускоряет компиляцию на 94%. Также он позволит ускорить разработку новых языковых фич и унифицировать все платформы, предоставляя улучшенную архитектуру для мультиплатформенных проектов.
Но мало кто погружался в то, как работает K2, и чем он отличается от K1.
Эта статья более освещает нюансы работы компилятора, которые будут полезны разработчикам для понимания, что же JB улучшают под капотом, и как это работает.
Контент статьи основывается на выступлении и овервью, но с добавлением дополнительной информации.
Оглавление
Как работает компилятор
Для начала поговорим о компиляторах в целом. По сути, компилятор — это программа. Она принимает код на языке программирования и превращает его в машинный код, который компьютер может исполнить.
Чтобы превратить исходный код в машинный, компилятор проводит несколько промежуточных преобразований. Если очень упростить, то компилятор делает две вещи:
меняет формат данных (compiling)
упрощает его (lowering)

Иногда стандартных функций Kotlin недостаточно. В таких случаях разработчики выходят за рамки стандартных инструментов и используют плагины компилятора.
Плагины встраиваются в работу компилятора Kotlin на различных фазах компиляции и меняют стандартное преобразование кода компилятором.

Плагины компилятора используют такие библиотек как Jetpack Compose, Kotlinx serialization.
Kotlin компилятор состоит из 2 частей:
Frontend
отвечает за построение синтаксического дерева (структуры кода) и добавление семантической информации (смысл кода)
Backend
отвечает за генерацию кода для целевой (target) платформы: JVM, JS, Native, WASM (экспериментальный)

Остановимся подробнее на каждой из частей.
Frontend
У компилятора Kotlin есть две фронтенд-реализации:
K1 (FE10-)
K2 (Fir-)
Упрощенно весь процесс работы фронтенда выглядит так:
Компилятор принимает исходный код
Производит синтаксический и семантический анализ кода
Отправляет данные на бэкенд для последующей генерации IR (Intermediate representation) и целевого кода платформы (target)

Обе реализации похожи, но K2 вводит дополнительное форматирование данных перед тем, как отправить преобразованный код на бэкенд.
Реализация K1

Реализация K1 работает c:
PSI (Programming Structure Interface)
PSI — это слой платформы IntelliJ, который занимается парсингом файлов и созданием синтаксических и семантических моделей кода (что такое синтаксис и семантика рассмотрим позже)
В зависимости от типа элемента дескрипторы могут содержать разную информацию о нем. Например дескриптор класса: контент класса, overrides, companion object и тд.
BindingContext — это Map, которая содержит информацию о программе и дополняет PSI.
Во время обработки K1 отправляет PSI и BindingContext на Backend, который на входе использует преобразование PSI в IR (Psi2Ir) для дальнейшей работы.
Как работает K1
Общая схема работы выглядит следующим образом

Есть 2 фазы:
Parsing Phase — разбирает что именно написал разработчик. На этой фазе еще неизвестно, будет ли компилироваться написанный код. Здесь проверяется, что код написан синтаксически верно.
Resolution Phase — производит анализ, необходимый для понимания, будет ли код компилироваться и является ли он семантически правильным (более детальный разбор Resolution Phase).
Разберём дальше разницу между синтаксисом и семантикой.
Чтобы разобраться в работе компилятора K1, предположим, что у нас есть исходный код
fun two() = 2 Пока что для компилятора это только строка текста.
Parsing Phase
Задача синтаксического парсинга
Задача парсинга — проверить структуру программы и убедиться, что она верная и следует грамматическим правилам языка.
Пример:

Этапы Parsing phase

Все начинается с лексического анализа (Lexer Analysis). Сначала Kotlin Parser сканирует исходный код (строку) и разбивает его на лексические части (KtTokens). Например:
(—>KtSingleValueToken.LPAR)—>KtSingleValueToken.RPAR=—>KtSingleValueToken.EQ
В нашем примере разбиение на токены выглядит так:

Пробелы тоже превращаются в токены. Но они не обозначены, чтобы не перегружать лишней информацией.
Далее начинается синтаксический анализ (Syntax Analysis). Его первый этап — это построение абстрактного синтаксического дерева (AST), которое состоит из лексических токенов. Важная особенность: дерево уже представляет из себя не последовательность символов, а имеет структуру.
Обратите внимание, что структура этого дерева совпадает со структурой нашего исходного кода. В нашем примере это выглядит так:

Следующим этапом мы накладываем PSI на узлы абстрактного синтаксического дерева. Теперь у нас есть PSI-дерево, которое содержит дополнительную информацию по каждому элементу:

На этом этапе мы ищем только синтаксические ошибки. Другими словами, мы видим правильно написанный код, но пока не можем предсказать, скомпилируется он или нет и самое главное не понимаем смысл этого кода.
В IntelliJ IDEA, вы можете загрузить плагин PSIViewer чтобы смотреть PSI для кода, написанного вами.

Resolution Phase
Задача семантического парсинга
Чтобы понять смысл написанного кода используется Resolution Phase.
Здесь PSI-дерево проходит набор этапов, в процессе которых генерируется семантическая информация, позволяющая понять (resolving) имена функций, типов, переменных и откуда они взялись.
Все мы в коде видели ошибки из этой стадии.

Семантическая информация содержит данные о:
Переменных и параметрах

На стадии семантического анализа нужно понять, что, используя pet внутри функции play, мы используем параметр функции, объявленный в первой строке
Типах

Семантическая информация содержит данные о том, на какие типы ссылается код, в каком месте они объявлены.
Вызовах функций

Может существовать много функций meow, и требуется определить, какую именно функцию нужно вызвать. Эта стадия занимает большую часть семантического анализа. Тк meow может быть: обычной функцией внутри класса, extension, property. Функция может находиться внутри текущего модуля, другого модуля или в библиотеке. На этапе семантического анализа нужно найти все функции с нужным названием и выбрать наиболее подходящую функцию для конкретной ситуации.
Эта стадия отвечает на похожие вопросы:
Откуда появилась эта функция/переменная/тип для использования
Точно ли две строки относятся к одной и той же переменной или это разные переменные в зависимости от контекста где они используются?
Какой тип у конкретного объекта?
Производится выведение типов
val list1 = listOf(1, 2, 3)
val list2 = listOf("one", "two", "three")Представим, что у нас есть такая запись.
Тут используется generic-функция listOf
public fun <T> listOf(vararg elements: T): List<T>Задача семантического анализа — вывести аргументы типа для каждого использования
val list1 = listOf(1, 2, 3)В первом случае T = Int
val list2 = listOf("one", "two", "three")Во втором — T = String.
Этапы Resolution Phase
Реализация K1 выполняет вычисление на PSI-дереве, создает дескрипторы и BindingContext map, а затем передает все это на бэкенд. В итоге бэкенд преобразует полученную информацию в IR с помощью Psi2Ir.
Вся эта информация будет использоваться дальше на бэкенде:

Пример с деревом PSI и семантической информацией BindingContext
В этом примере можно увидеть как исходный код (строка) преобразуется в структуру (дерево) и по каждому узлу дерева добавляется дополнительная информация (семантика).

Проблемы K1
Мы разобрались с тем, как работает фронтенд-реализация K1. Обозначим этот процесс на схеме K1:

У этой реализации есть свои недостатки (объяснение Дмитрия Новожилова в kotlin slack). Преобразование через PSI и BindingContext приводит к проблемам с производительностью компилятора.
Тк компилятор работает с ленивыми дескрипторами, то выполнение постоянно прыгает между разными частями кода, это сводит на нет некоторые JIT-оптимизации. Кроме этого много информации resolution phase хранится в большом BindingContext, из-за этого ЦП не может хорошо кэшировать объекты.
Все это ведет к проблемам с производительностью.
Реализация K2
Чтобы повысить производительность компилятора и улучшить архитектуру решения, JB создала новую фронтенд-реализацию K2 (Fir frontend).
Изменение произошло в структурах данных. Вместо старых структур (PSI + BindingContext) реализация K2 использует Fir (Frontend Intermediate Representation). Это семантическое дерево (дерево, в узлах которого к структуре кода добавлена семантическая информация). Оно представляет исходный код.

Как работает K2
Вместо того, чтобы как раньше отправлять PSI и BindingContext в Backend, в K2 на Frontend происходят дополнительные преобразования:
В случае с K2, мы рассмотрим более сложный случай и пропустим те фазы, в которых K1 и K2 работают одинаково.
Для примера возьмем исходный код
private val kotlinFiles = mutableListOf(1, 2, 3)
Parsing
Начнем с уровня PSI (до этого K1 и K2 схожи):

В этом случае, реализация K1 просто генерировала бы дополнительные данные для отправки PSI на бэкенд.
Psi2Fir
В отличие от нее, K2 компилирует этот промежуточный формат данных перед созданием Ir. В итоге получается Fir — это mutable-дерево, построенное из результатов парсера (PSI-дерева):

Тут видно сходство между PSI и raw Fir.

Resolution
Итак, мы создаем raw FIR и пересылаем его нескольким обработчикам. Они представляют собой различные этапы пайплайна компилятора и заполняют дерево семантической информацией:

Все файлы в модуле проходят эти этапы одновременно.
В это время выполняются такие действия, как:
Вычисление import’ов
Поиск идентификаторов класса для супертипов и наследников sealed классов
Вычисление модификаторов видимости
Вычисление контрактов функций
Выведение типов возвращаемого значения
Анализ тел функций и свойств
На стадии Resolution компилятор преобразует сгенерированное raw Fir, заполняя дерево семантической информацией:

На этих этапах компилятор выполняет desugaring. Например, `if` можно заменить на `when` или `for` — на `while`.
Раньше мы делали все это на Backend, но благодаря K2 то же самое можно делать на Frontend.
Checking

Мы пришли к последней стадии — стадии проверки. Здесь компилятор берет Fir и проводит диагностику на предмет предупреждений и ошибок.
Если ошибки появились, данные отправляются плагину IDEA — именно он подчеркивает ошибку красной линией. Компиляция останавливается, чтобы не отправлять неверный код на бэкенд.
Fir2Ir
Если ошибок нет

FIR трансформируется в IR

В итоге мы получаем входные данные для бэкенда
Визуальное сравнение результатов K1 и K2

Итого в K2 мы получили Fir (одну структуру данных вместо двух в K1 версии)
Backend
Цели улучшения Backend
Изначально при разработке Kotlin компилятор не использовал промежуточное представление (IR). Тк это необязательная стадия при разработке компиляторов.
Каноничная архитектура компилятора

Отсутствие IR позволило Kotlin быстрее эволюционировать на ранних стадиях. Kotlin компилировался не только в JVM, но так же и в JS. JS высокоуровневый язык и он похож больше на Kotlin, чем на JVM байткод. Поэтому IR бы только тормозило разработку преобразования.

Но вскоре появился еще 1 native backend.

Стало понятно что все 3 бэкенда могут использовать общую логику по трансформации и упрощению кода, что позволит поддерживать фичи для разных бекендов проще. Поэтому начиная с native-backend команда Kotlin решила использовать IR, сначала только для него самого.

Итак, в качестве целей разработки новой версии можно выделить:
переиспользование логики между разными бекендами
упрощение поддержки новых языковых возможностей
Необходимо отметить, что ускорение Backend не являлось целью. В отличие от ускорения Frontend-части.
Новая реализация Backend позволила расширять компилятор с помощью компиляторных плагинов. В частности реализация Jetpack Compose полагается на новую версию бекенда c использованием IR.
Как работает Backend

Сейчас в Kotlin есть четыре реализации backend:
JVM
JS
Native
WASM
Какой бы бэкенд вы ни использовали, обработка в нем всегда начинается с генератора IR и оптимизатора. Затем выбранная конфигурация запускает сгенерированный код:

Для примера выберем бэкенд JVM и продолжим работу с mutableList
IR

IR это также дерево. В IR добавлена вся семантическая информация. Для человека IR на выглядит не очень читабельно, но зато такой вид гораздо понятнее для компилятора. В момент анализа IR создаются поток управления и стеки вызовов.
Можно рассматривать IR как представление кода в виде дерева, которое разработано специально для генерации кода target-платформы. В отличие от Fir на фронтенде, который проверяет смысл написанного кода.
IR lowering
Затем на IR выполняются оптимизации и упрощения это называется lowering. Таким образом упрощается сложность Kotlin. Например в IR отсутствуют local и internal классы, они заменены отдельными классами со специальными именами. С помощью упрощений разным backend’ам не нужно бороться со сложностью языка Kotlin и реализация становится проще.
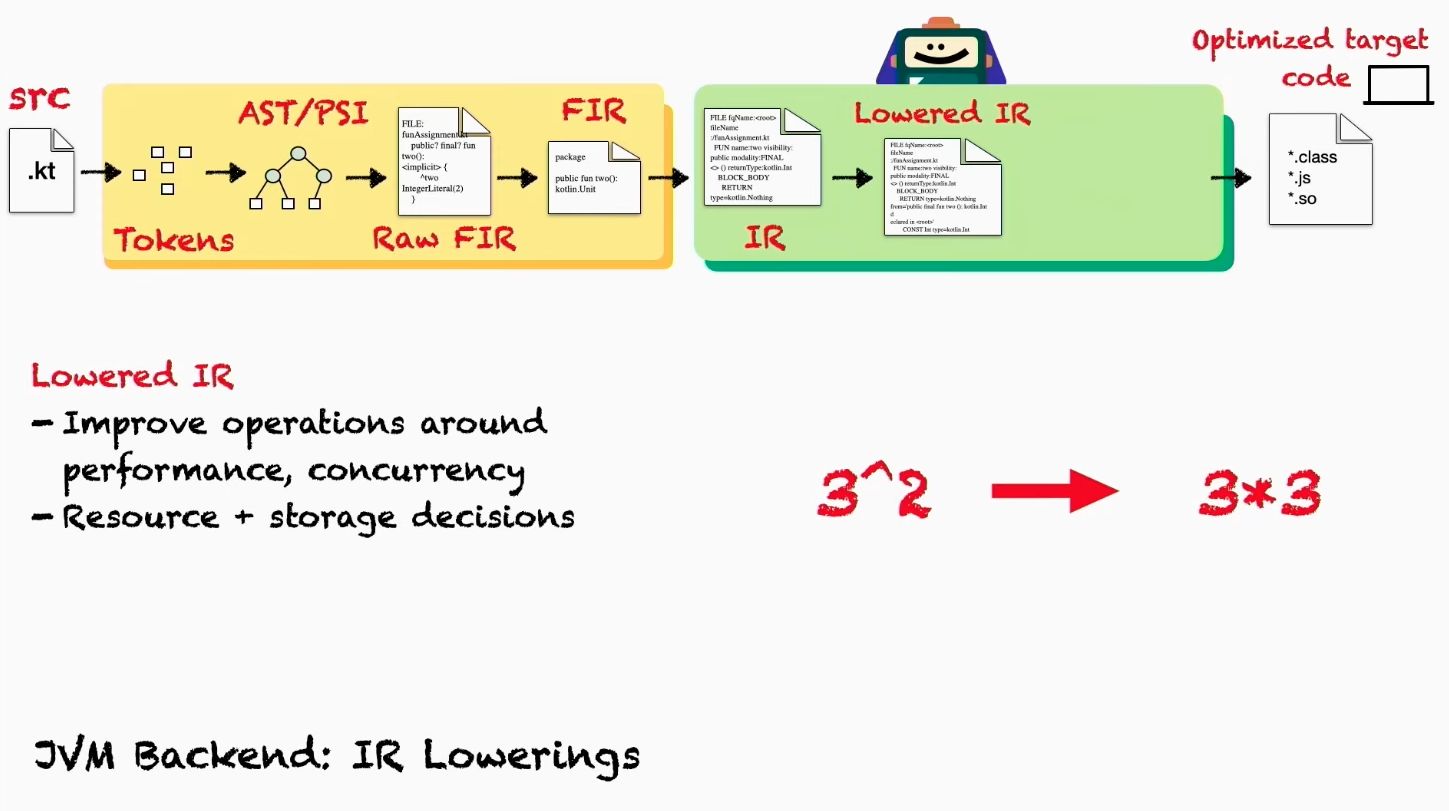
Также на этом этапе упрощаются операции, улучшается производительность и качество машинного кода, особенно с точки зрения многопоточности.
Target code
Теперь у нас есть сгенерированный код целевой платформы. В нашем примере это JVM байт-код. Далее он отправляется на виртуальную машину, где он и будет исполняться:

На этом задачи компилятора считаются выполненными.
Выводы
Что дает новый компилятор:
Единая структура данных Fir для представления кода и семантики
Возможность добавления плагинов компилятора
Упрощение поддержки новых языковых возможностей для разных target-платформ.
Улучшение производительности компилятора и IDE (плагин Kotlin в IDE использует Frontend компилятора). По результатам замеров JB:
ускорение компиляции на 94%
ускорение фазы инициализации на 488%
ускорение фазы анализа на 376%
В этой статье мы рассмотрели как работают разные версии компилятора Kotlin. Непосредственно в эту тему редко углубляются разработчики. Я надеюсь, что материал позволил заглянуть вам под капот и узнать, что же там происходит, когда вы каждый день собираете приложения на работе.
Дополнительные материалы
Видео Crash Course on the Kotlin Compiler by Amanda Hinchman-Dominguez
Видео KotlinConf 2018 - Writing Your First Kotlin Compiler Plugin by Kevin Most
Видео What Everyone Must Know About The NEW Kotlin K2 Compiler
Видео A Hitchhiker's Guide to Compose Compiler: Composers, Compiler Plugins, and Snapshots
Репозиторий Kotlin-Compiler-Crash-Course с заметками об отладке, тестировании и настройке компилятора Kotlin
Цикл статей Crash course on the Kotlin compiler
Книга “Compilers: Principles, Techniques, and Tools” by Alfred Aho, Jeffrey Ullman, Ravi Sethi, Monica Lam

Другие наши статьи по Android разработке:
