Квинтет — это способ записать атомарные фрагменты данных с указанием их роли в нашей жизни. Квинтетами можно описать любые данные, при этом каждый из них содержит исчерпывающую информацию о себе и о связях с другими квинтетами. Он представляет термины предметной области, независимо от используемой платформы. Его задача — упростить хранение данных и улучшить наглядность их представления.
Я расскажу о новом подходе к хранению и обработке информации и поделюсь мыслями о создании платформы разработки в этой новой парадигме.
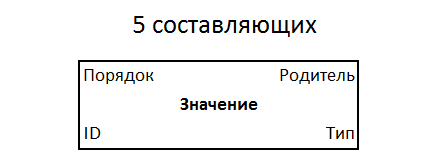
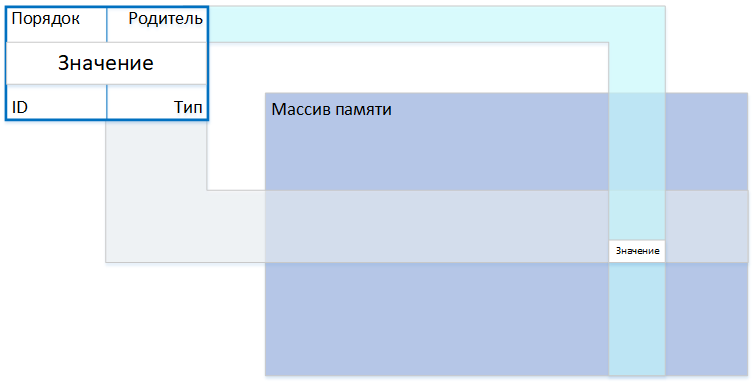
Квинтет имеет свойства: тип, значение, родитель, порядок среди братьев. С идентификатором получается всего 5 составляющих. Это простейшая универсальная форма записи информации, новый стандарт, который потенциально может устроить всех. Квинтеты хранятся в файловой системе единой структуры, в сплошном однообразном индексированном информационном поле.
Для записи информации есть бесконечное множество стандартов, подходов и правил, знание которых необходимо для работы с этими записями. Стандарты описаны отдельно и не имеют непосредственной связи с данными. В случае с квинтетами, взяв любой из них, можно получить актуальную информацию о его природе, свойствах и правилах работы с его предметной областью. Его стандарт един и неизменен для всех областей. Квинтет скрыт от пользователя — ему доступны метаданные и данные в виде, привычном для многих.
Квинтет — это не только информация, но и исполняемые команды. Но прежде всего это данные, которые требуется хранить, записывать и извлекать. Поскольку они в нашем случае непосредственно адресуемые, связанные и индексированные, хранить мы их будем в некоем подобии базы данных. Для тестирования прототипа системы хранения данных квинтетами мы, например, использовали обычную реляционную базу данных.
Основной идеей этой статьи является замена машинных типов человеческими терминами и замещение переменных объектами. Не теми объектами, которым нужен конструктор, деструктор, интерфейсы и сборщик мусора, а чистокристаллическими единицами информации, которыми оперирует заказчик. То есть если заказчик говорит «Заявка», то для сохранения сути этой информации на носителе не требовалось бы экспертизы программиста.
Полезно фокусировать внимание пользователя только на Значении объекта, а его тип, родитель, порядок (среди равных по подчиненности) и идентификатор должны быть очевидны из контекста или просто скрыты. Это означает, что пользователь вообще ничего не знает о квинтетах, он просто излагает свою задачу, убеждается, что она принята корректно, и затем запускает её выполнение.
Есть набор типов данных, понятных любому: строка, число, файл, текст, дата и так далее. Такого простого набора вполне достаточно для формулирования задачи, и «программирования» её и необходимых для её реализации типов. Базовые типы, представленные квинтетами, могут выглядеть так:
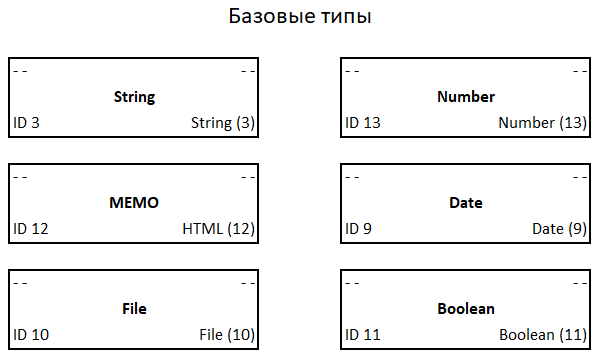
В данном случае часть составляющих квинтета не используются, а в качестве базового типа используется он сам. Это позволяет ядру системы легче ориентироваться при навигации в метаданных.
Из-за аналитического разрыва между пользователем и программистом на этапе постановки задачи происходит существенная деформация понятий. Недосказанность, недопонятость и непрошеная инициатива зачастую превращает простую и понятную мысль заказчика в логически невозможную мешанину, если судить с точки зрения пользователя.

Передача знаний должна происходить без потерь и искажения. Более того, в дальнейшем при организации хранения этих знаний, необходимо избавиться от ограничений, накладываемых выбранной системой управления данными.
На сервере, как правило, существует множество баз данных, в каждой из них хранится описание структуры сущностей с конкретным набором реквизитов — взаимосвязанных данных. Они хранятся в определенном порядке, в идеале оптимальном для формирования выборки.
Предлагаемая система хранения информации — некий компромисс между различными известными способами: колоночными, строковыми и NoSQL. Она призвана решать задачи, обычно выполняемые каким-то одним из этих способов.
Например, теория колоночных баз выглядит красиво: читаем только нужную колонку, а не все строки записей целиком. Однако на практике так разместить данные на носителе, чтобы это было применимо при десятках различных разрезов анализа, вряд ли получится. Заметим, что атрибуты и аналитические метрики могут добавляться и удаляться, причем иногда быстрее, чем мы сможем перестроить это колоночное хозяйство. Не говоря уже о том, что данные в базе могут корректироваться, что также будет нарушать красоту плана выборки из-за неизбежной фрагментации.
Мы ввели понятие — термин — для описания любых объектов, которыми мы оперируем: сущность, реквизит, запрос, файл и т.д. Мы определим все термины, которые используем в нашей предметной области. А с их помощью мы опишем все сущности, имеющие реквизиты, в том числе в виде связей между сущностями. Например, реквизит — ссылка на запись справочника статусов. Термин записывается квинтетом данных.
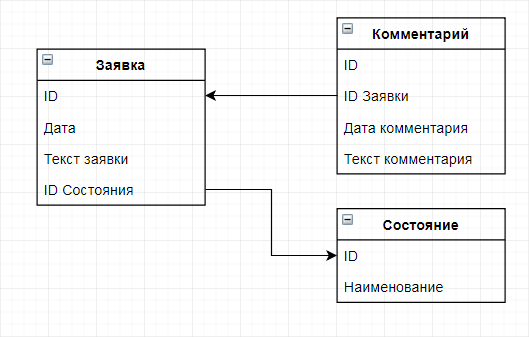
Совокупность описаний терминов — это метаданные, задающие структуру таблиц и полей обычной БД. Например, есть следующая структура данных: заявка от какой-то даты, у которой есть содержание (текст заявки) и Состояние, к которой участники производственного процесса добавляют комментарии с указанием даты. В конструкторе традиционной базы данных это будет выглядеть примерно так:
Поскольку мы решили скрывать от пользователя все несущественные детали, такие как связующие ID, например, схема будет несколько упрощена: удалены упоминания ID и объединены названия сущностей и их ключевые значения.
Пользователь «рисует» задание: заявку от сегодняшнего числа у которой есть состояние (справочное значение) и к которой можно добавлять комментарии с указанием даты:
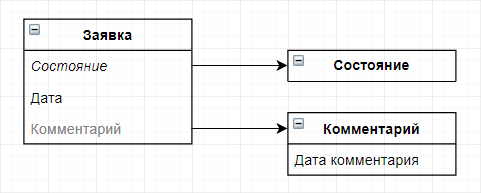
Теперь мы видим 6 разных полей данных вместо 9, а вся схема предлагает нам прочитать и осмыслить 7 слов вместо 13. Хотя это далеко не главное, разумеется.
Ниже приведены квинтеты, сгенерированные управляющим ядром для описания этой структуры:
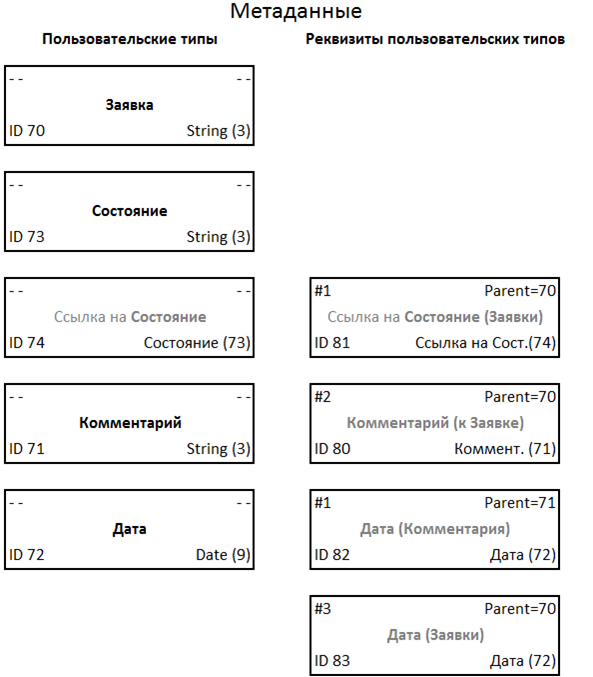
Пояснения на месте значений квинтетов, выделенные серым, приведены для понятности. Эти поля не заполняются, потому что вся необходимая информация однозначно определена остальными составляющими.
Рассмотрим хранение такого набора данных для описанной выше задачи:
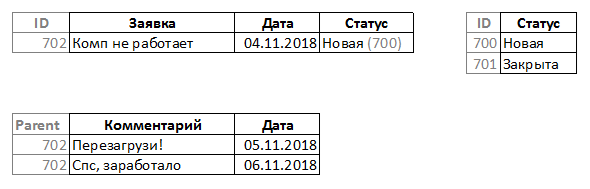
Сами данные хранятся в квинтетах согласно структуре с указанием принадлежности к определенным терминам в виде такого набора:
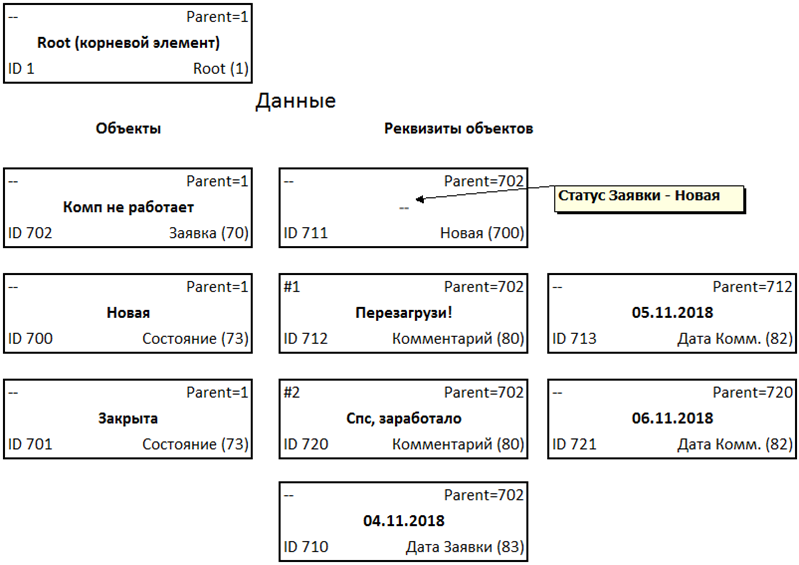
Мы видим знакомую многим иерархическую структуру, хранимую методом списка смежных вершин (aka Adjacency List).
Вышеописанный пример очень прост, но что будет, когда встретится структура в тысячи раз сложнее, а данных будут гигабайты?
Нам понадобится:
Таким образом, все записи нашей базы данных будут проиндексированы, включая и данные, и метаданные. Такая индексация необходима для сохранения свойств реляционной базы данных — самого простого и популярного инструмента. Индекс по родителю на самом деле составной (ID родителя + тип). Индекс по типу также составной (тип + значение) для быстрого поиска объектов заданного типа.
Метаданные позволяют нам избавиться от рекурсии: например, чтобы найти все реквизиты заданного объекта мы используем индекс по ID родителя. Если же требуется поиск объектов определенного типа, то используется индекс по ID типа. Тип — это аналог имени таблицы и поля в реляционной СУБД.
В любом случае мы не сканируем весь набор данных, и даже при большом количестве значений какого-либо типа нужное значение находится за небольшое количество шагов.
Сама по себе такая база данных не самодостаточна для прикладного программирования, не полная, как говорится, по Тьюрингу. Но мы здесь ведем речь не только о БД, а пытаемся охватить все аспекты: объекты — это, в том числе, произвольные управляющие алгоритмы, которые можно запустить, и они будут работать.
В итоге вместо сложных структур базы данных и отдельно хранящегося исходного кода управляющих алгоритмов мы получим однообразное поле информации, ограниченное объемом носителя и размеченное метаданными. Сами данные представлены пользователю в понятном ему виде — структура предметной области и соответствующие записи в ней. Пользователь произвольно меняет структуру и данные, в том числе делая массовые операции с ними.
Для работы с таким представлением данных понадобится очень компактное ядро — движок нашей базы по размеру на порядок меньше BIOS компьютера, и, значит, его можно сделать если не в железе, то как минимум быстрым и в максимально вылизанном виде. В целях безопасности еще и доступным только для чтения.
Добавив в сборку моего любимого .Net новый класс, мы можем наблюдать потерю 200-300 Мб оперативной памяти только на описание этого класса. Эти мегабайты не поместятся в кэш правильного уровня, провоцируя систему засвопиться с вытекающими отсюда последствиями. Аналогичная ситуация с Java. Описание того же самого класса квинтетами займет десятки или сотни байт, поскольку класс использует только примитивные приемы работы с данными, которые уже знакомы ядру.
Использование описанного подхода не ограничивается только квинтетами, но пропагандирует иную парадигму, чем та, к которой привыкли программисты. На смену императивному, декларативному или объектному языку предлагается язык запросов, как более привычный для человека и позволяющий ставить задачу непосредственно компьютеру, минуя программистов и непробиваемую прослойку существующих сред разработки.
Разумеется, переводчик со свободного пользовательского языка на язык четких требований будет по-прежнему необходим в большой части случаев.
Подробнее эта тема будет раскрыта в отдельных статьях с примерами и существующими наработками.
Итак, если коротко, работает это следующим образом:
Полнота по Тьюрингу всей системы обеспечивается воплощением основных требований: ядро умеет делать последовательные операции, ветвление по условию, обработку наборов данных и останов работы по достижении определенного результата.
Для человека выгода в простоте восприятия, например, вместо объявления цикла с задействованием переменных
используется более понятная человеку конструкция вроде
Мы мечтаем абстрагироваться от низкоуровневых тонкостей реализации информационной системы: циклы, конструкторы, функции, манифесты, библиотеки — всё это занимает слишком много пространства в мозгу программиста, оставляя мало места для творческой работы и развития.
Современное приложение немыслимо без средств масштабирования: требуется неограниченная возможность расширять нагрузочную способность информационной системы. В описываемом подходе, в виду предельной простоты организации данных, масштабирование получается организовать не сложнее, чем в существующих архитектурах.
В рассмотренном выше примере с заявками можно разделить их, например, по их ID, сделав генерацию ID с фиксированными старшими байтами для разных серверов. То есть, при использовании 32 битов под хранение ID, старшие два-три-четыре или больше битов, сколько понадобится, будут указывать сервер, на котором хранятся эти заявки. Таким образом, у каждого сервера будет свой пул ID.
Ядро отдельного сервера может функционировать независимо от других серверов, ничего не зная о них. При создании заявки она будет с большим приоритетом попадать на сервер с минимальным количеством используемых ID, обеспечивая равномерное распределение нагрузки.
Учитывая ограниченный набор возможных вариаций запросов и ответов при единой организации данных, потребуется достаточно компактный диспетчер, распределяющий запросы по серверам и агрегирующий их результаты.
Я расскажу о новом подходе к хранению и обработке информации и поделюсь мыслями о создании платформы разработки в этой новой парадигме.
Квинтет имеет свойства: тип, значение, родитель, порядок среди братьев. С идентификатором получается всего 5 составляющих. Это простейшая универсальная форма записи информации, новый стандарт, который потенциально может устроить всех. Квинтеты хранятся в файловой системе единой структуры, в сплошном однообразном индексированном информационном поле.
Для записи информации есть бесконечное множество стандартов, подходов и правил, знание которых необходимо для работы с этими записями. Стандарты описаны отдельно и не имеют непосредственной связи с данными. В случае с квинтетами, взяв любой из них, можно получить актуальную информацию о его природе, свойствах и правилах работы с его предметной областью. Его стандарт един и неизменен для всех областей. Квинтет скрыт от пользователя — ему доступны метаданные и данные в виде, привычном для многих.
Квинтет — это не только информация, но и исполняемые команды. Но прежде всего это данные, которые требуется хранить, записывать и извлекать. Поскольку они в нашем случае непосредственно адресуемые, связанные и индексированные, хранить мы их будем в некоем подобии базы данных. Для тестирования прототипа системы хранения данных квинтетами мы, например, использовали обычную реляционную базу данных.
Структура квинтета
Основной идеей этой статьи является замена машинных типов человеческими терминами и замещение переменных объектами. Не теми объектами, которым нужен конструктор, деструктор, интерфейсы и сборщик мусора, а чистокристаллическими единицами информации, которыми оперирует заказчик. То есть если заказчик говорит «Заявка», то для сохранения сути этой информации на носителе не требовалось бы экспертизы программиста.
Полезно фокусировать внимание пользователя только на Значении объекта, а его тип, родитель, порядок (среди равных по подчиненности) и идентификатор должны быть очевидны из контекста или просто скрыты. Это означает, что пользователь вообще ничего не знает о квинтетах, он просто излагает свою задачу, убеждается, что она принята корректно, и затем запускает её выполнение.
Базовые понятия
Есть набор типов данных, понятных любому: строка, число, файл, текст, дата и так далее. Такого простого набора вполне достаточно для формулирования задачи, и «программирования» её и необходимых для её реализации типов. Базовые типы, представленные квинтетами, могут выглядеть так:
В данном случае часть составляющих квинтета не используются, а в качестве базового типа используется он сам. Это позволяет ядру системы легче ориентироваться при навигации в метаданных.
Предпосылки
Из-за аналитического разрыва между пользователем и программистом на этапе постановки задачи происходит существенная деформация понятий. Недосказанность, недопонятость и непрошеная инициатива зачастую превращает простую и понятную мысль заказчика в логически невозможную мешанину, если судить с точки зрения пользователя.
Передача знаний должна происходить без потерь и искажения. Более того, в дальнейшем при организации хранения этих знаний, необходимо избавиться от ограничений, накладываемых выбранной системой управления данными.
Как принято хранить данные
На сервере, как правило, существует множество баз данных, в каждой из них хранится описание структуры сущностей с конкретным набором реквизитов — взаимосвязанных данных. Они хранятся в определенном порядке, в идеале оптимальном для формирования выборки.
Предлагаемая система хранения информации — некий компромисс между различными известными способами: колоночными, строковыми и NoSQL. Она призвана решать задачи, обычно выполняемые каким-то одним из этих способов.
Например, теория колоночных баз выглядит красиво: читаем только нужную колонку, а не все строки записей целиком. Однако на практике так разместить данные на носителе, чтобы это было применимо при десятках различных разрезов анализа, вряд ли получится. Заметим, что атрибуты и аналитические метрики могут добавляться и удаляться, причем иногда быстрее, чем мы сможем перестроить это колоночное хозяйство. Не говоря уже о том, что данные в базе могут корректироваться, что также будет нарушать красоту плана выборки из-за неизбежной фрагментации.
Метаданные
Мы ввели понятие — термин — для описания любых объектов, которыми мы оперируем: сущность, реквизит, запрос, файл и т.д. Мы определим все термины, которые используем в нашей предметной области. А с их помощью мы опишем все сущности, имеющие реквизиты, в том числе в виде связей между сущностями. Например, реквизит — ссылка на запись справочника статусов. Термин записывается квинтетом данных.
Совокупность описаний терминов — это метаданные, задающие структуру таблиц и полей обычной БД. Например, есть следующая структура данных: заявка от какой-то даты, у которой есть содержание (текст заявки) и Состояние, к которой участники производственного процесса добавляют комментарии с указанием даты. В конструкторе традиционной базы данных это будет выглядеть примерно так:
Поскольку мы решили скрывать от пользователя все несущественные детали, такие как связующие ID, например, схема будет несколько упрощена: удалены упоминания ID и объединены названия сущностей и их ключевые значения.
Пользователь «рисует» задание: заявку от сегодняшнего числа у которой есть состояние (справочное значение) и к которой можно добавлять комментарии с указанием даты:
Теперь мы видим 6 разных полей данных вместо 9, а вся схема предлагает нам прочитать и осмыслить 7 слов вместо 13. Хотя это далеко не главное, разумеется.
Ниже приведены квинтеты, сгенерированные управляющим ядром для описания этой структуры:
Пояснения на месте значений квинтетов, выделенные серым, приведены для понятности. Эти поля не заполняются, потому что вся необходимая информация однозначно определена остальными составляющими.
Посмотреть как связаны квинтеты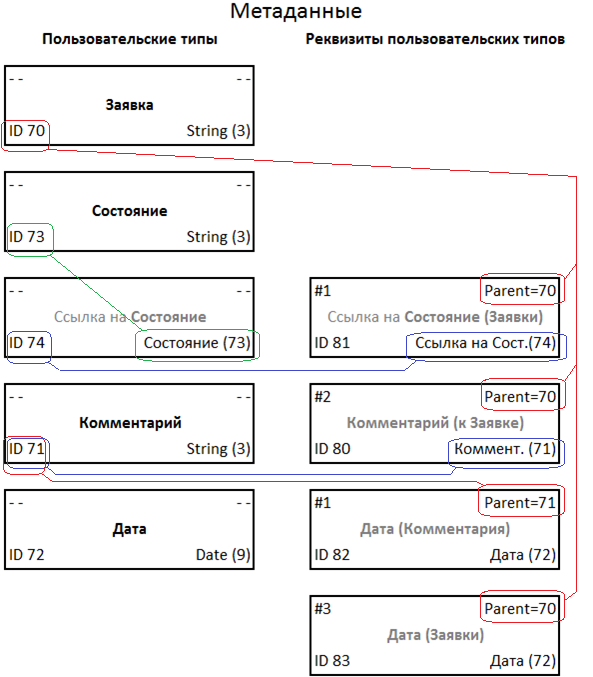
Пользовательские данные
Рассмотрим хранение такого набора данных для описанной выше задачи:
Сами данные хранятся в квинтетах согласно структуре с указанием принадлежности к определенным терминам в виде такого набора:
Мы видим знакомую многим иерархическую структуру, хранимую методом списка смежных вершин (aka Adjacency List).
Быстродействие
Вышеописанный пример очень прост, но что будет, когда встретится структура в тысячи раз сложнее, а данных будут гигабайты?
Нам понадобится:
- Рассмотренная выше иерархическая структура — 1 шт.
- B-дерево для поиска по ID, родителю и типу — 3 шт.
Таким образом, все записи нашей базы данных будут проиндексированы, включая и данные, и метаданные. Такая индексация необходима для сохранения свойств реляционной базы данных — самого простого и популярного инструмента. Индекс по родителю на самом деле составной (ID родителя + тип). Индекс по типу также составной (тип + значение) для быстрого поиска объектов заданного типа.
Метаданные позволяют нам избавиться от рекурсии: например, чтобы найти все реквизиты заданного объекта мы используем индекс по ID родителя. Если же требуется поиск объектов определенного типа, то используется индекс по ID типа. Тип — это аналог имени таблицы и поля в реляционной СУБД.
В любом случае мы не сканируем весь набор данных, и даже при большом количестве значений какого-либо типа нужное значение находится за небольшое количество шагов.
Основа для платформы разработки
Сама по себе такая база данных не самодостаточна для прикладного программирования, не полная, как говорится, по Тьюрингу. Но мы здесь ведем речь не только о БД, а пытаемся охватить все аспекты: объекты — это, в том числе, произвольные управляющие алгоритмы, которые можно запустить, и они будут работать.
В итоге вместо сложных структур базы данных и отдельно хранящегося исходного кода управляющих алгоритмов мы получим однообразное поле информации, ограниченное объемом носителя и размеченное метаданными. Сами данные представлены пользователю в понятном ему виде — структура предметной области и соответствующие записи в ней. Пользователь произвольно меняет структуру и данные, в том числе делая массовые операции с ними.
Мы не изобрели ничего нового: все данные уже хранятся в файловой системе и поиск в них осуществляется с помощью B-деревьев, что в файловой системе, что в базах данных. Мы только реорганизовали представление данных, чтобы с ними было проще и нагляднее работать.
Для работы с таким представлением данных понадобится очень компактное ядро — движок нашей базы по размеру на порядок меньше BIOS компьютера, и, значит, его можно сделать если не в железе, то как минимум быстрым и в максимально вылизанном виде. В целях безопасности еще и доступным только для чтения.
Добавив в сборку моего любимого .Net новый класс, мы можем наблюдать потерю 200-300 Мб оперативной памяти только на описание этого класса. Эти мегабайты не поместятся в кэш правильного уровня, провоцируя систему засвопиться с вытекающими отсюда последствиями. Аналогичная ситуация с Java. Описание того же самого класса квинтетами займет десятки или сотни байт, поскольку класс использует только примитивные приемы работы с данными, которые уже знакомы ядру.
Как быть с разными форматами: РСУБД, NoSQL, колоночные базы
Описанный подход покрывает два основных направления: РСУБД и NoSQL. При решении задач, использующих преимущества колоночных баз данных, нам понадобится сообщить ядру, что те или иные объекты следует хранить с учетом оптимизации массовой выборки значений определенного типа данных (нашего термина). Так ядро сможет разместить данные на диске наиболее выгодно.
Таким образом, для колоночной базы мы можем значительно сэкономить пространство, занимаемое квинтетами: использовать только одну-две его составляющих для хранения полезных данных вместо пяти, а также использовать индекс только для указания начала цепочек данных. Во многих случаях для выборок из нашего аналога колоночной базы будет использоваться только индекс, без необходимости обращения к данным самой таблицы.
Следует заметить, что задумка не ставит цели собрать все передовые разработки из этих трех типов баз данных. Наоборот, движок новой системы будет максимально редуцирован, воплощая только необходимый минимум функций — всё, что покрывает запросы DDL и DML в описанной здесь концепции.
Таким образом, для колоночной базы мы можем значительно сэкономить пространство, занимаемое квинтетами: использовать только одну-две его составляющих для хранения полезных данных вместо пяти, а также использовать индекс только для указания начала цепочек данных. Во многих случаях для выборок из нашего аналога колоночной базы будет использоваться только индекс, без необходимости обращения к данным самой таблицы.
Следует заметить, что задумка не ставит цели собрать все передовые разработки из этих трех типов баз данных. Наоборот, движок новой системы будет максимально редуцирован, воплощая только необходимый минимум функций — всё, что покрывает запросы DDL и DML в описанной здесь концепции.
Парадигма программирования
Использование описанного подхода не ограничивается только квинтетами, но пропагандирует иную парадигму, чем та, к которой привыкли программисты. На смену императивному, декларативному или объектному языку предлагается язык запросов, как более привычный для человека и позволяющий ставить задачу непосредственно компьютеру, минуя программистов и непробиваемую прослойку существующих сред разработки.
Разумеется, переводчик со свободного пользовательского языка на язык четких требований будет по-прежнему необходим в большой части случаев.
Подробнее эта тема будет раскрыта в отдельных статьях с примерами и существующими наработками.
Итак, если коротко, работает это следующим образом:
- Мы единожды описали квинтетами примитивные типы данных: строка, число, файл, текст и прочие, а также обучили ядро работе с ними. Обучение сводится к правильному представлению данных и осуществлению простых операций с ними.
- Теперь мы описываем квинтетами пользовательские термины (типы данных) — в виде метаданных. Описание сводится к указанию примитивного типа данных для каждого пользовательского типа и определению подчиненности.
- Заносим квинтеты данных согласно заданной метаданными структуре. Каждый квинтет данных содержит ссылку на свой тип и родителя, что позволяет быстро найти его в хранилище данных.
- Задачи ядра сводятся к выборке данных и осуществлению простых операций с ними для реализации сколько угодно сложных алгоритмов, описанных пользователем.
- Пользователь управляет данными и алгоритмами с помощью визуального интерфейса, наглядно представляющего и первое, и второе.
Полнота по Тьюрингу всей системы обеспечивается воплощением основных требований: ядро умеет делать последовательные операции, ветвление по условию, обработку наборов данных и останов работы по достижении определенного результата.
Для человека выгода в простоте восприятия, например, вместо объявления цикла с задействованием переменных
for (i=0; i<length(A); i++)
if A[i] meets a condition
do something with A[i]используется более понятная человеку конструкция вроде
with every A, that match a condition, do somethingМы мечтаем абстрагироваться от низкоуровневых тонкостей реализации информационной системы: циклы, конструкторы, функции, манифесты, библиотеки — всё это занимает слишком много пространства в мозгу программиста, оставляя мало места для творческой работы и развития.
Масштабирование
Современное приложение немыслимо без средств масштабирования: требуется неограниченная возможность расширять нагрузочную способность информационной системы. В описываемом подходе, в виду предельной простоты организации данных, масштабирование получается организовать не сложнее, чем в существующих архитектурах.
В рассмотренном выше примере с заявками можно разделить их, например, по их ID, сделав генерацию ID с фиксированными старшими байтами для разных серверов. То есть, при использовании 32 битов под хранение ID, старшие два-три-четыре или больше битов, сколько понадобится, будут указывать сервер, на котором хранятся эти заявки. Таким образом, у каждого сервера будет свой пул ID.
Ядро отдельного сервера может функционировать независимо от других серверов, ничего не зная о них. При создании заявки она будет с большим приоритетом попадать на сервер с минимальным количеством используемых ID, обеспечивая равномерное распределение нагрузки.
Учитывая ограниченный набор возможных вариаций запросов и ответов при единой организации данных, потребуется достаточно компактный диспетчер, распределяющий запросы по серверам и агрегирующий их результаты.
