
“Если в ваших руках молоток, все вокруг кажется гвоздями”
Как практикующие дата саентисты мы занимаемся анализом данных, их сбором, очисткой, обогащением, строим и обучаем модели окружающего мира, основываясь на данных, находим внутренние взаимосвязи и противоречия между данными, порою даже там, где их нет. Безусловно такое погружение не могло не сказаться на нашем видении и понимании мира. Профессиональная деформация присутствует в нашей профессии точно также, как и в любой другой, но что именно она нам приносит и как влияет на нашу жизнь?
Дисклеймер
Данная статья не претендует на научность, не выражает единую точку зрения сообщества "ODS" и является личным мнением автора.
Преамбула

Если вы интересуетесь тем, как устроен наш мозг, как мы воспринимаем окружающий мир, да и вообще, что мы тут все делаем, то многие вещи, описанные в этой статье, не будут для вас чем-то совершенно новым. В том или ином виде все это уже было описано не раз под совершенно разными углами. Моя задача — попытаться посмотреть на все это с позиции аналитика данных, а также провести параллели между теми инструментами и подходами, которыми мы пользуемся в нашей работе, и реальной жизнью за пределами монитора.
Введение

Для начала представим себе такой, несколько упрощенный, сетап:
Вокруг нас есть окружающий мир, чтобы выжить и успешно в нем функционировать, человеку необходимо понимать, что он (мир) из себя представляет, как с ним можно взаимодействовать, и какие результаты получаются от различных взаимодействий. То есть, другими словами, человеку нужна модель окружающего мира, адекватно решающая его текущие задачи. Ключ — “текущие задачи”. Когда задача выживания стояла на первом месте, модель мира строилась, в первую очередь, на быстром распознавании опасности и адекватной реакции на нее. Т.е., у кого модель была похуже — не смогли передать ее дальше, у кого получше — передали потомкам. С улучшением условий существования акцент в модели стал меняться с чисто выживания на что-то более высокоорганизованное, и, чем безопаснее окружающая среда, тем более разноплановым становится это “что-то”. Спектр “чего-то” очень широк — от биткоина и DS до радикального феминизма и толерантности.
Природа создала наш мозг для решения задачи выживания в условиях ограниченных ресурсов — еды было мало, энергии на всякую фигню не хватало, поэтому, чтобы выжить, нужно было решить две взаимоисключающие задачи:
- Познавать мир, улучшая модель, увеличивая шансы на выживание (очень энергозатратная задача)
- Не сдохнуть от нехватки энергии
Природа решила эту дилемму очень изящно, внедрив в наш мозг возможность кеширования потоков данных и реакций, когда для решения базовых задач (в рамках текущей модели) взаимодействия с окружающим миром энергия практически не тратится.
Более подробно про такой метод кеширования и “ресурсную теорию внимания” можно прочитать в прекрасных работах Д. Канемана “Думай медленно, решай быстро” [1] и “Внимание и усилие” [3]
По Д. Канеману:
Психологи выделяют два режима мышления, которые мы назовём Система 1 и Система 2.
Система 1 срабатывает автоматически и очень быстро, не требуя или почти не требуя усилий и не давая ощущение намеренного контроля
Система 2 выделяет внимание, необходимое для сознательных умственных усилий, в том числе и для сложных вычислений. Действия Системы 2 часто связаны с субъективным ощущением деятельности, выбора и концентрации
Шаблоны поведения, реакции и ответы программируются в нашем мозгу (формируют и меняют модель мира) с самого детства и до самой смерти. От того, на какой стадии находится формирование модели, зависят два фактора — скорость принятия изменений и количество энергии, необходимое для изменения. В детстве, когда модель гибка и податлива, — скорость высока, а затраты энергии минимальны. Чем плотнее модель, тем больше энергии нужно для того, чтобы ее изменить. Даже больше того, энергия нужна также и для того, чтобы человек просто захотел что-то поменять в модели. А любая трата энергии контролируется мозгом, и он оооочеенььь неохотно разрешает ее тратить.
Команда на изменение модели будет отвергаться мозгом (еще бы, это ведь энергозатратно, а зачем?, ведь у нас и так все хорошо) до тех пор, пока функционирование в рамках старой модели не будет угрожать выживанию. Ну или до получения энергии спонтанным выплеском (шок от чего-либо, психологический удар, и т.д.)
TL/DR:
- Для выживания человек строит у себя в голове модель окружающего мира, решающую его текущие задачи
- При решении любой задачи мозг старается минимизировать энергозатраты
- Наименее энергозатратно функционирование в рамках Системы-1 (Канеман), непринятие решений на изменение
- Наиболее энергозатратно — функционирование в рамках Системы-2, принятие решения на изменение модели и само изменение модели
Метамодель (модель модели)

Итак, чтобы взаимодействовать с окружающим миром, человек строит у себя в мозгу модель мира и действует в соответствии с ней настолько долго, насколько это возможно (вспомним еще раз про минимизацию энергозатрат). Но человек, к сожалению или к счастью, животное социальное — не взаимодействовать с другими людьми мы не можем и, зачастую, такое взаимодействие ставит нас в тупик.
Чтобы эффективно взаимодействовать с другими людьми, мы строим у нас в голове поведенческую модель этих людей, то есть модель того, как они себя поведут в тех или иных обстоятельствах при наличии тех или иных данных. То есть мы строим модель модели окружающего мира этого конкретного человека.
Остановитесь и подумайте — модель мира в голове у человека несовершенна и отвечает только его собственным критериям достаточности и адекватности, а мы строим модель этой (странной) модели и взаимодействуем с этим человеком согласно нашей модели. Да, и еще хотим, чтобы человек поступал так, как подсказывает нам наша “модель его модели”. Оптимистично? Да более чем….
Чтобы построить и натренировать адекватную модель, не мне вам рассказывать, нужно много времени, энергии и данных. А у нас зачастую нет ни того ни другого, да и чем больше степеней свободы (параметров) у модели, тем больше нужно данных — проклятие размерности, помните?
А жизнь летит, а времени мало, поэтому (работает Система-1), встречая человека, да и даже общаясь с ним в каких-то условиях, мы подбираем к нему одну из наших пред-скомпилированных шаблонов моделей, которые уже есть у нас в голове (“стерва”, “нормальный пацан”, “рохля”, “просто “№; ак”, и т.д.), может быть, чуть-чуть файнтюня ее под конкрентный случай.
Да, конечно, есть исключения, есть люди, для которых нам не жалко ни времени ни энергии, и которых мы узнаем всю жизнь. Но и в этом случае мы знаем о человеке только то, что есть в нашей модели этого человека.
Что отсюда следует? Несколько очевидных вещей:
Ну, во-первых, дата саентист не испытывает чувства обиды на других людей.
Совершенно от слова полностью. В его лексиконе термин “обида” отсутствует. Почему? Все просто — в основе любой обиды лежит наше непонимание:
- Как он(она) мог так (сказать, сделать, поступить)?
- Или НЕ (сказать, сделать, поступить)?
То есть в нашей модели этого человека он в конкретных обстоятельствах с конкретным входным пакетом информации должен был поступить так, а он так не поступил. Вот гад, да? Угу, не он гад, а наша модель этого человека неверна. Что-то мы в ней упустили, либо вообще не фантюнили на конкретные обстоятельства, а взяли просто шаблон, либо входные данные в текущей ситуации отличаются от тех, на которых мы модель тренировали.
Что делать в этом случае? То же, что и обычно — смотрим, что в данных не так, и перетренировываем модель с учетом новой информации.
Во-вторых, у дата саентиста отсутствует рефлекс “в интернете кто-то неправ”.
Работает не только в интернете, но и на работе, в социуме и т.д. Если человек что-то не понимает (как вам кажется), или понимает, но не так, как вы — возможно, у него просто совершенно другая модель для этой части мира. И переубедить такого, т.е. заставить его изменить свою модель, (особенно, если он не хочет) — очень сложно и очень энергозатратно. Оно вам надо?
Совершенно другой вариант, когда человек готов менять свою модель, хочет ее расширить или подтюнить, и у него есть для этого силы и энергия. Можете помочь — помогайте, не можете — направьте к тому, кто сможет. Не можете ни помочь ни направить — не мешайте.
В следующий раз не агритесь на человека, если он, по вашему мнению, “неправ” или что-то “не понимает”. В его модели мира все по-другому. Чем заскорузлее и “проще” модель, тем бОльшие энергозатраты необходимы, чтобы ее хотя бы вывести из точки равновесия, не говоря уже о том, чтобы что-то поменять.
Ну и в третьих, дата саентист помнит принцип “Вещи всегда не те, чем кажутся.”
Понимая, как работает эта система, есть возможность смимикрировать, подстроиться под какой-то базовый шаблон, привычный для того социума, в котором вы в данный момент находитесь, и, пока вы не будете из него сильно выбиваться, все будет нормально. Это работает в обе стороны, так что не забывайте — “Сова не то, чем кажется.”
“Восприятие веревки как змеи так же ложно, как восприятие веревки как веревки” (С)
Построение и обучение модели
Как дата саентисты мы хорошо понимаем, насколько сложно построить, натренировать и постоянно до-обучать более-менее адекватную модель. И поэтому дата саентист спокойно и терпеливо относится к несовершенству моделей в головах других людей и постоянно совершенствует свою. А поскольку он все-таки профессионал, то он прекрасно помнит основные принципы успешного моделирования:
Что посеешь, то и пожнешь (Garbage in — garbage out. )
Точность и адекватность модели зависит от чистоты данных больше, чем от чего-бы то ни было еще. Мы все это знаем, мы тратим огромное количество времени на очистку данных, препроцессинг, нормализацию и прочее и прочее и прочее. Корми модель мусором — и результат предсказуем. Корми ее очищенными нормализованными данными — и инсайты у тебя в кармане. Модели в наших головах работают точно так же. Понимая это, мы стараемся использовать максимально верные и чистые данные для обработки и обучения, постоянно используем критический взгляд для анализа адекватности данных и стремимся не допускать в свою модель грязной и зашумленной информации. Кратко говоря — читайте хабр и не смотрите первый канал.
Различие между Train и Test (наша головная боль)
Дата саентист понимает, что применимость модели напрямую зависит от схожести распределений, на которой модель училась и для которой она применяется. Правила поведения в одном социуме не работают в другом, принципы успеха в одной области неприменимы к другой, построенная по маминым рассказам “типовая модель поведения” противоположного пола вдруг оказывается не совсем верна, ну и т.д.
Мы всегда принимаем в расчет возможную несхожесть тренировочного датасета, на котором мы обучали нашу модель мира, и реального датасета, на котором мы применяем нашу модель.
Короче говоря, мы понимаем причину несоответствия и готовы тратить энергию на до-обучение модели для более точного соответствия реальному миру.
Выбор целевой функции и multidomain-learning
Практически любую задачу можно перевести в другой домен, поменяв целевую функцию. Не решается задача как регрессия? Переделайте таргет на классы и решайте как задачу классификации. А еще лучше — сделайте две головы у сетки, одна пусть решает одну задачу, вторая — переформулированную. На одном и том же наборе данных можно обучить две разные модели, заточенные на совершенно разные вещи. Помните об этом, лучший вариант, как и в жизни, multidomain-learning, когда ваша итоговая целевая функция охватывает сразу несколько доменов. На работе, например, можно просто зарабатывать деньги, можно при этом еще качать профессиональные скиллы, можно еще улучшать навыки социального взаимодействия. Как и в случае с обычными моделями, такой подход позволяет, в конечном итоге, обогатить и улучшить все мультидомен цели, как если бы мы качали их по отдельности. И не забывайте про время — три модели на отдельные цели требуют в три раза больше времени, а в реальной жизни его не то, чтобы очень много, и распараллелить обучение на десяток-другой TPU-шек, к сожалению, не получится.
Обучение блоками (Batch-learning)
Обучение модели батчами давно доказало свою эффективность. Если не брать в расчет специфические области, требующие онлайн обучения, то нет смысла обновлять веса только после прохода полностью всей эпохи. Да, обучение батчами дает высокочастотный шум, но это нивелируется более высокой скоростью сходимости практически с той же точностью.
Что нам это дает? Понимание, что нет смысла ждать долго перед тем, как слегка изменить свою модель мира на основе новых данных. Не надо ждать всю эпоху, ну не знаю, год на новой работе, год отношений с новым человеком, меняйтесь чаще — получите более быстрое движение к своей конечной цели, ну и exploration даст больше возможностей. Также бессмысленно кричать, что “все пропало” после какого-то единичного случая, возможно, это просто выброс, возможно, звезды так сложились, подождите до конца батча, саккумулируйте ошибки — и вот тогда меняйте модель.
Методы поиска гиперпараметров (Grid search VS random search)
Существует много статей (пример) на тему того, что при поиске лучших гиперпараметров, перебор случайным образом лучше, чем поиск по сетке. Так и в нашем случае выбор “случайного” действия лучше действительно делать “псевдо случайно”, а не строго в соответствии с какой-то заранее определенной сеткой. Любители и адепты строгих подходов меня сейчас затопчут, но серьезно, миром правит случай, и использование такого метода, как ни странно, может быть даже более рационально.
Еще лучше, конечно, использовать байесовскую оптимизацию. Но тут у меня нет понимания, как ее можно применить к реальной жизни. Не сам байесовский подход к осмыслению информации, а именно байесовскую оптимизацию при выборе гиперпараметров.
Ансамбли (Ensemble)
Мы все знаем про силу ансамблей, в котором каждая модель по своему смотрит на данные, вытаскивая из них какой-то сигнал, и лучший результат достигается использованием метамодели поверх моделей первого уровня. В жизни все точно так же, свою модель мира можно строить не только на основе собственного опыта, но и вбирая все лучшее (или наоборот, понимая и отрезая все худшее) из моделей мира других людей. Эти модели описаны в книгах, фильмах, да и просто, наблюдая за поведением других людей, можно понять, что у них за модель, взять лучшее и встроить себе.
Вспомним “Многие вещи нам непонятны не потому, что наши понятия слабы, но потому, что сии вещи не входят в круг наших понятий.” Козьма Петрович понимал проблему ограниченности моделей, даже не будучи практикующим дата саентистом. :)
Разные люди, разные окружения, разные данные — разные модели даже на, казалось бы, очевидные вещи. Если вы работали в крупных компаниях, вы наверняка помните все эти бесконечные тренинги про поведение, правила общения, харрасмент и прочее. Что за херня, думали вы. Ан нет, не херня. В крупных международных компаниях (из-за различий в культуре, менталитете и ценностях) просто необходимо внедрить в модель каждого сотрудника слой базовых принципов для обеспечения нормального взаимодействия и работы.
TL/DR
- В том, что происходит с вами в этом мире, виноваты только вы и ваша модель мира
- Модели мира других людей совсем не обязаны коррелировать с вашей собственной
- Ваши мета-модели моделей мира других людей скорее всего совсем не соответствуют реальности
- Создать у себя в голове открытую модель мира, готовую к изменениям по байесовскому принципу, сложно. Еще сложнее поддерживать ее в этом открытом состоянии в течение жизни. Совсем сложно — оставаться при этом человеком
Что осталось за кадром
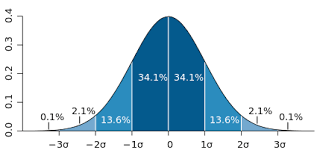
Центральная предельная теорема
Как гласит нам ЦПТ, сумма случайных событий, семплированных из любого типа слабо зависимых распределений, сама является случайной величиной и в пределе распределена нормально.
Вся наша жизнь состоит из случайных событий: время ожидания лифта или автобуса на остановке, пропустили тебя на повороте или нет, и т.д. Можно условно оценить день как успешный или неуспешный (еще одна случайная величина) в зависимости от того, куда в итоговом распределении мы попали — в центр или хвост. На достаточно большой выборке (например, год) видно, что эта наша случайная величина распределена нормально, с центром в “ну так, более-менее все ОК”
Дата сайентист понимает все вышеизложенное и не парится, если попадает в т.н. “Черную полосу”, когда все плохо — и автобус ушел из-под носа, и кофе разлил, и код не сохранил и т.д. Он понимает, что сегодня нам выпал хвост распределения, надо просто пережить этот день, и завтра, возможно, мир нам отсемплит события чуть-чуть по-другому.
Кстати, переходом в новую точку отсчета событий (нового набора семплов) является сон. Не календарный день, не полночь, а субъективный новый день после того, как ты проснулся. Наши предки понимали это интуитивно (хотя и не знали про xgboost и keras), именно отсюда и пошли поговорки “утро вечера мудренее” и “если хочется работать — ляг поспи, и все пройдет”.
Ну и логичный вывод — если “черная полоса” продолжается слишком долго (можете даже попробовать посчитать p-value этого “слишком”), то это значит, что либо какие-то величины в нашем жизненном уравнении смещены (автобус сняли с маршрута, у вас появилась утренняя трясучка рук), либо осуществляется внешнее воздействие на систему.
Регрессия к среднему
Вспомним добрым словом сэра Френсиса Гальтона, который впервые обратил внимание на этот феномен в своей работе “Регрессия к среднему при наследовании”. Также эта тема хорошо освещена в уже упоминавшейся прекрасной книге Д. Канемана [1].
Как дата саентисты мы не обращаем внимания, если сегодня что-то происходит хуже, чем вчера. Мы помним про регрессию к среднему и относимся к сегодняшней неудаче философски, тем более, что сегодняшняя неудача увеличивает вероятность нашего успеха завтра, опять-таки в соответствии с этим же законом )
Ну и опять же, этот закон уже давно был переформулирован в более привычном виде “если дела идут хорошо, значит скоро они пойдут еще хуже”.
Использование и разведка (Exploitation vs Exploration)
Как уже говорилось, наш мозг стремится минимизировать энергозатраты, это обусловлено приоритетом на выживание и продолжение рода. Изначально энергии было мало, чтобы выжить, ее надо было экономить, и мозг за столь долгую эволюцию впечатал принцип дядюшки Оккама себе в базовую прошивку — “работает — не трогай!”. Не надо тратить энергию на построение новой модели мира, если все, что происходит вокруг, вполне объяснимо в рамках текущей, и не надо искать что-то новое, если, в принципе, и так все более-менее неплохо.
Но мы же программ… дата саентисты. Мы-то хорошо знаем, что такое застревание в локальном минимуме. Сложность поверхности оптимизационной функции нашей жизни не поддается осмыслению и описанию (хотя многие сознательно ее упрощают для облегчения существования), и новый лучший локальный минимум может быть вот тут за углом, рядом, в одном-двух несложных действиях. Но мы продолжаем сидеть в неоптимуме, говоря “ну я же знаю, что ничего не изменится”. Ничего подобного мы знать не можем в силу, как уже говорилось, сложности ландшафта целевой функции. Надо просто перестать думать и начать прыгать. Вы не поверите, насколько по-другому может пойти ваша жизнь, если вы периодически будете выходить из своего локального минимума и пробовать подергаться в разных направлениях.
В качестве иллюстрации можно привести проблему застревания в “локальном минимуме” для RL(Reinforcement learning). Используя жадный алгоритм выбора действия в каждом состоянии, мы, конечно, оптимизируем в конечном итоге нашу награду, но оставляем за бортом другие, возможно, более интересные области окружающего пространства. Поэтому мы вносим в алгоритм возможность выбора не лучшего, а случайного действия из данной конкретной ситуации, просто, чтобы посмотреть, а не приведет ли это нас к чему-то новому и, возможно, лучшему. Для задачи RL при бесконечном количестве запусков мы рано или поздно рассмотрим все возможные состояния и награды и выберем максимальную. К сожалению, в реальной жизни у нас ограничено количество попыток (да и время эксперимента тоже конечно), но тем интереснее задача, значит, вместо просто случайного выбора действия можно придумать какие-то более изощренные алгоритмы.
Пузырь интересов, кстати, также как и персонализированные ленты, поисковые выдачи и прочее вредны еще и потому, что отрезают возможности к exploration, замыкая информационный поток в сферу уже изученного контента.
Выборка из генеральной совокупности
Мы понимаем, что все наши оценочные суждения о людях, событиях, вещах строятся не на всей генеральной совокупности, а всего-лишь на некоторой выборке, доступной нам для наблюдения. Отдавая себе в этом отчет, мы очень аккуратно вешаем ярлыки типа “все мужики — парнокопытные” или “все женщины — блондинки”.
Мы также помним, что даже при нормальной выборке вероятность попасть в “хвост” распределения далеко не нулевая. И, если это случилось, мы не расстраиваемся, не рефлексируем на тему “почему опять я”, а учим урок и спокойно идем дальше.
Как уже говорилось, если внезапно ваша выборка чего-либо (людей, событий, ..) вдруг стала состоять из одних “хвостов”, то это повод задуматься над тем, что в вашей собственной модели мира вдруг поменялось, что мир стал реагировать подобным образом.
Когнитивные искажения
Мы все в какой-то мере все еще люди, и наш мозг подвержен всем возможным когнитивным искажениям, обусловленным работой Системы-1. Фундаментальная ошибка атрибуции, ретроспективное искажение, фрейминг, систематическая ошибка выжившего, и т.д., и т.п. Эти и многие другие вуали все также влияют на нас. Но как дата саентисты мы всегда помним про эти ловушки и постоянно стараемся отстроиться от них, напрягая Систему-2. Понимание природы искажений и методов отстройки от них помогает нам и в нашей работе и в реальной жизни. Да, тяжело, энергии на Систему-2 мало, но мышца растет только, когда ее напрягаешь.
“После этого не значит вследствие этого” и другие логические ошибки
Опять же, как и в случае с когнитивными искажениями, мы знаем об этих логических ошибках, помним про них и стараемся развить свою Систему-1 так, чтобы обход таких ловушек происходил автоматически.
Карта не равна территории
Мы все помним про то, что “Все модели неверны, но некоторые полезны” (С). Это касается и наших с вами моделей мира. Как дата саентисты мы отдаем себе отчет в их несовершенстве, понимая, что они всего-лишь блеклое отражение реального мира, но, тем не менее, весьма полезное отражение. Пока они нас устраивают, все замечательно, но, если вдруг мир начинает вести себя не так, как мы предполагаем, это не мир плохой, это просто значит, что мы подошли к границе применимости нашей модели.
TL/DR
- Если существующее явление может быть объяснено в рамках текущей модели мира, то оно будет объяснено в рамках этой модели
- Миром правит случай. Делайте выводы по группе наблюдений, а не по единичным исходам
- Всегда оставляйте себе возможность и ресурсы для исследования (exploration)
- Все модели неверны, но некоторые полезны. Вероятность того, что ваша модель в каких-то аспектах неверна, практически равна 1
- Не давайте когнитивным искажениям и логическим ошибкам влиять на вас
Заключение

Любая профессиональная деятельность деформирует сознание, нам еще в какой-то мере повезло, наша профессиональная деформация в обычной жизни особо не вредит, а наоборот помогает более точно объяснить, что происходит вокруг и, более того, дает нам в руки инструменты и принципы для изменения ситуации в нужную сторону.
Список литературы
- Канеман Д. Думай медленно… решай быстро. — М.: АСТ, 2013. — 625 с.
- Канеман Д., Словик П., Тверски А. Принятие решений в неопределенности: Правила и предубеждения., Харьков: Гуманитарный центр, 2005. — 632 с. — [ISBN 966-8324-14-5]
- Канеман Д. Внимание и усилие / пер. с англ. И. С. Уточкина. — М.: Смысл, 2006. — 288 с.
- Фрит К., “Мозг и душа: как нервная деятельность формирует наш внутренний мир"
