Идея реактивного программирования появилась сравнительно недавно, лет 10 назад. Что вызвало популярность этого относительно нового подхода и почему сейчас он в тренде, рассказал на конференции РИТ++ 2020 эксперт и тренер Luxoft Training Владимир Сонькин.
В режиме мастер-класса он продемонстрировал, почему так важен неблокирующий ввод-вывод, в чем минусы классической многопоточности, в каких ситуациях нужна реактивность, и что она может дать. А еще описал недостатки реактивного подхода.
В этой статье мы поговорим о том, что такое реактивное программирование, и зачем оно нужно, обсудим подходы и посмотрим примеры.
Почему реактивное программирование получило такую популярность? В какой-то момент перестала расти скорость процессоров, а значит разработчикам уже не приходится рассчитывать на то, что скорость их программ станет увеличиваться сама по себе: теперь их нужно распараллеливать.
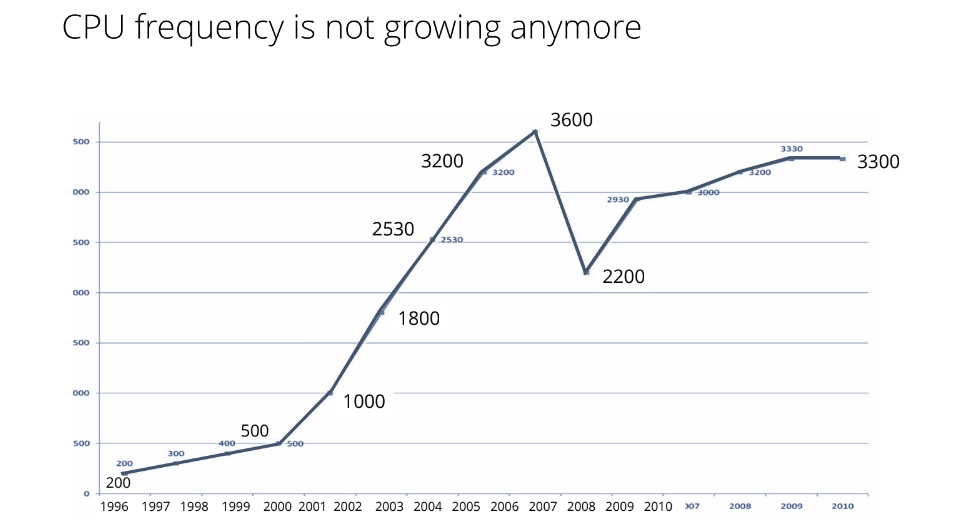
На рисунке видно, что график частоты процессоров рос в 90-х, а в начале 2000-х частота резко увеличилась. Оказалось, что это был потолок.
Почему же рост частоты остановился?
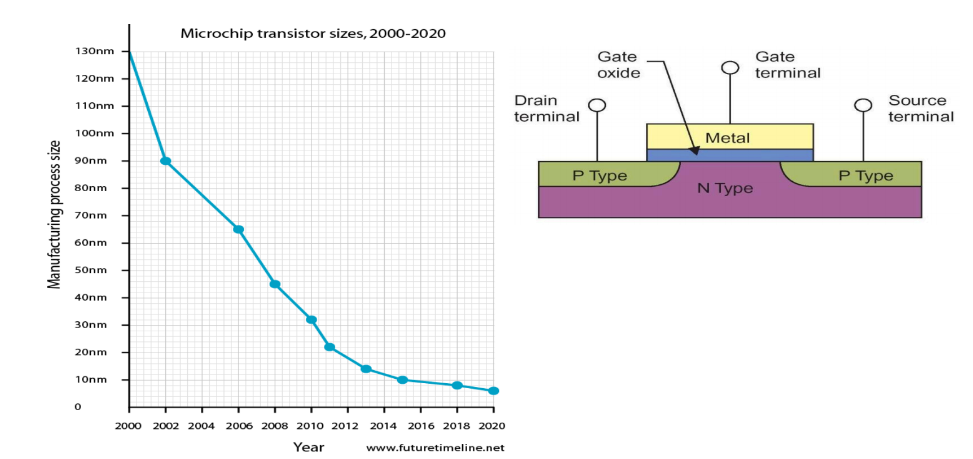
Транзисторы начали делать максимально малого размера. PN-переход, который используется в них, получился настолько тоненьким, насколько это вообще возможно. На графике размеров транзисторов внутри процессора мы видим: размер все меньше и меньше, транзисторов в процессоре все больше и больше.
Такая миниатюризация раньше приводила к тому, что росла частота. Поскольку электроны бегут со скоростью света, за счет уменьшения размера, время, которое требовалось электрону, чтобы пробежать весь путь внутри процессора, уменьшалось. Но техпроцессы уткнулись в физический потолок. Пришлось придумывать что-то другое.
Многопоточность
И мы уже знаем, что удалось придумать: начали делать многоядерные процессоры. Вместо того, чтобы опираться на то, что производительность процессора будет расти, стали рассчитывать увеличение их количества. Но для эффективного использования множества процессоров нужна многопоточность.
Тема многопоточности — сложная, но неизбежная в современном мире. Типичный современный компьютер имеет от 4 ядер и множество потоков. В современном мощном сервере может быть и 100 ядер. Если в вашей программе не используется многопоточность, вы не получаете никаких преимуществ. Поэтому все мировые индустрии постепенно двигаются к тому, чтобы задействовать эти возможности.
При этом нас подстерегает множество опасностей. Программировать с учетом многопоточности сложно: синхронизации, гонки, затрудненная отладка и т.д. попортили немало крови разработчикам. К тому же, стоимость такой разработки становится выше.
В Java многопоточность появилась давным-давно, она существует с самой первой версии.
Выглядит она так:
Писать большую систему, используя примитивы многопоточности, мягко говоря, сложно. Сейчас так уже никто не делает. Это все равно, что кодить на Ассемблере.
Во многих случаях эффект, который приносит многопоточность, не улучшает производительность, а ухудшает ее.
Что же с этим делать?
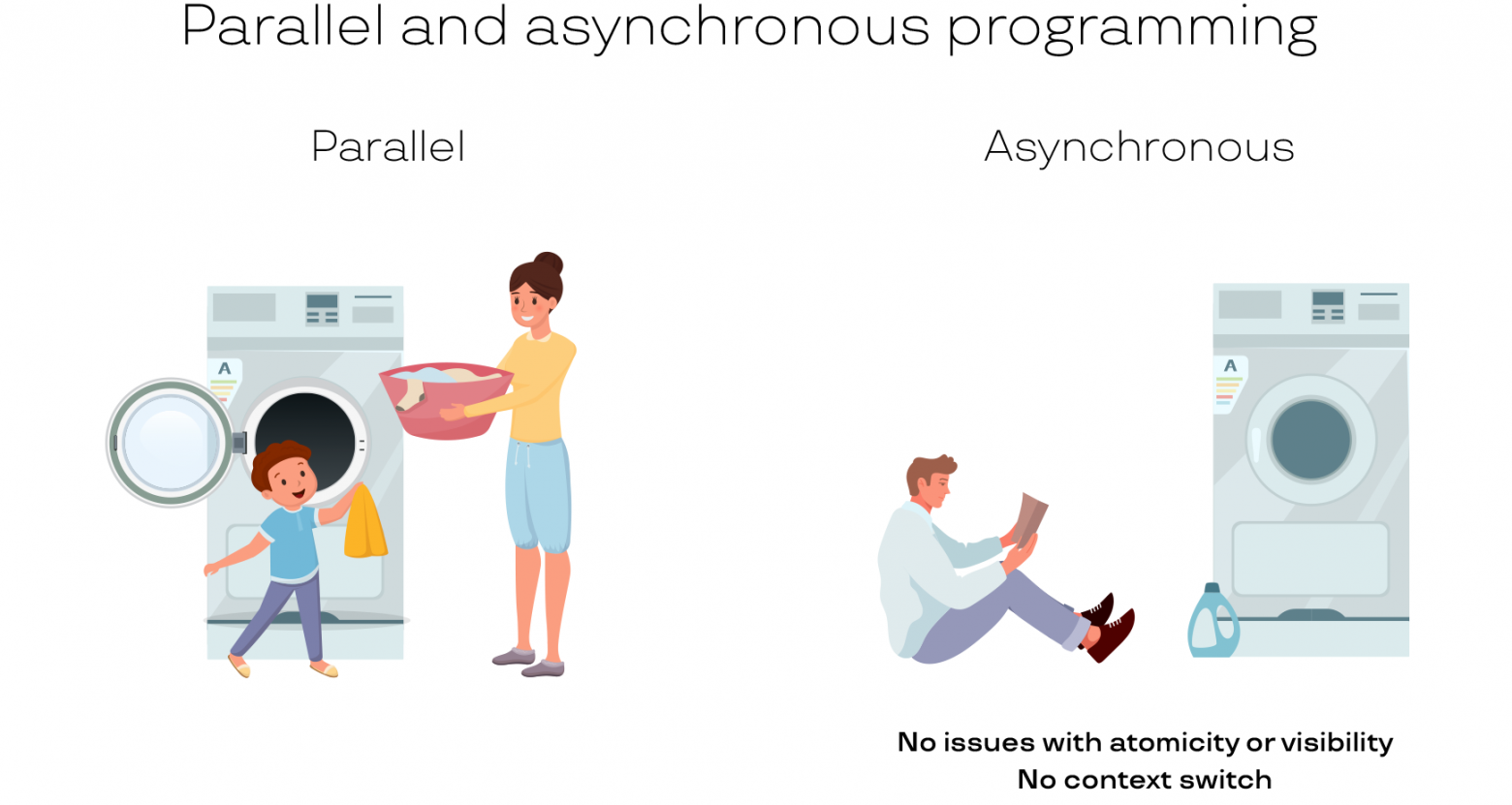
Параллельное программирование во многих ситуациях можно заменить асинхронностью. Посмотрите на иллюстрацию. На левой картинке малыш очень хочет помогать маме в домашних делах. Мама достает из стиральной машинки белье, дает ребенку, и он его укладывает в корзину. Так работает программа на 2 потока: поток-мама и поток-малыш. Теоретически производительность в этом случае должна возрастать: два человека лучше, чем один, ведь мы задействовали два ядра. Но представьте себе такую ситуацию в реальной жизни: мама подает ребенку белье и ждет, пока он его уложит в машинку. Или ребенок ждет белье от мамы. На деле они постоянно мешают друг другу. Плюс, нужно отвести время на передачу белья. Мама быстрее разобралась бы с бельем сама.
Примерно такая же ситуация происходит в компьютере. Поэтому работа с параллельностью совсем не так проста, как кажется. Все синхронизации между потоками выполнения на самом деле занимают кучу времени.
На картинке справа одинокий парень, который купил себе автоматическую машинку. Она стирает, а он в это время может почитать книжку. Здесь однозначно есть преимущество для юноши, потому что он занимается своим делом и при этом не следит за тем, завершилась ли стирка. Когда стирка завершится, он услышит звуковой сигнал и отреагирует на него. То есть параллельность есть, а синхронизации нет. Стало быть нет и траты времени на синхронизацию, сплошная выгода!
Это и есть подход с асинхронностью. Есть отдельный исполнитель, и мы дали ему не часть нашей задачи, а свою собственную. На левой картинке мама и мальчик делают общую задачу, а на правой стиральная машина и парень делают разные, каждый свою. В какой-то момент они соединятся: когда стиральная машина достирает, юноша отложит свою книгу. Но все 1,5 часа, пока белье стиралось, он прекрасно себя чувствовал, читал и ни о чем не думал.
Примеры параллельного и асинхронного подходов
Рассмотрим 2 варианта выполнения потоков: параллельный и асинхронный.
Потоки выполняются параллельно;

Потокам thread 1 и 2 нужно обращаться к одному и тому же общему разделяемому ресурсу. Допустим, это какая-то база данных, и она не позволяет потокам подключаться к ней одновременно. Или позволяет, но это сразу снижает скорость ее работы, поэтому потокам лучше обращаться к ней по очереди. Никакой параллельности здесь нет: потокам приходится работать по очереди. А третий поток ждет ответа от базы данных, и тоже заблокирован — такая система малоэффективна.
Вроде бы параллельность есть, а преимуществ от нее не так много.
Потоки выполняются асинхронно.
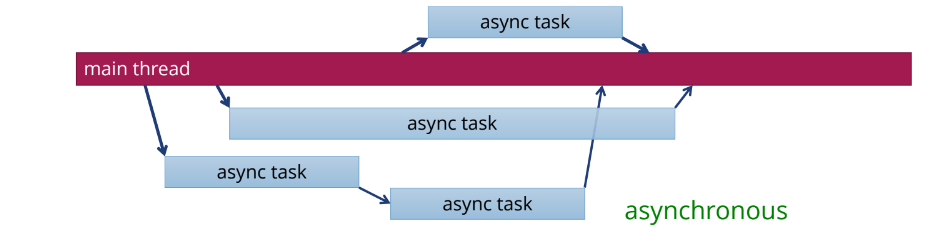
Если использовать асинхронность, мы ставим задачу, и она выполняется где-то в другом потоке. Например, другим ядром процессора или другим процессором. Мы поставили задачу и занимаемся другими делами, а потом в какой-то момент, когда эта задача завершится, получим результаты. Это можно проиллюстрировать работой организации. Начальник — поток main — ставит задачу Пете, и говорит: «Как только ты ее выполнишь, передай Коле, а тот после завершения работы над задачей пусть доложит мне. В результате Петя и Коля заняты работой, а начальник может ставить новые задачи другим сотрудникам».
Еще один пример: конкуренция и параллелизм.
Представим себе офис, утро, всем хочется выпить кофе. Concurrency (конкуренция) — это когда выстраивается очередь к одной на всех кофемашине. Люди конкурируют: «Эй, я тут первый стоял!» — «Нет, я!». Они друг другу мешают.
В параллелизме есть две кофемашины и две очереди: каждый стоит в своей. Но все равно сотрудники тратят время на то, чтобы постоять там.
Как найти правильное решение для этого сценария, если использовать асинхронность?
Доставка кофе прямо к столу — хороший вариант, в очереди вы не стоите, но придется нанимать официанта, который будет разносить напитки.
Другой возможный вариант — фиксированный график. Например, один сотрудник подходит за кофе в 11:10, следующий — в 11:20 и т.д. Но это не асинхронность. Будут происходить простои, а значит это не полная загрузка кофемашины. Кто-то не успел к своему времени, а кому-то не хватило 10 минут, чтобы сделать себе кофе, и в итоге весь график сдвигается. А если сделать
большие зазоры, кофемашина будет недогружена. И потом, все хотят прийти в 10 утра и выпить кофе, а это растягивается на 2 часа, и кому-то его чашка достанется только в 12.
Еще один вариант — записывать всех желающих в «виртуальную очередь». Когда кофемашина освободится от предыдущих любителей кофе, человек получает уведомление и подходит к кофемашине без очереди. Сейчас во многих организациях так делают. Например, в интернет-магазинах с самовывозом. Берешь талончик и занимаешься своими делами, а когда приходит время, подходишь и получаешь товар. Вот это и есть асинхронность: никто никого не ждет, все работают и получают свой кофе настолько быстро, насколько возможно. И кофемашина тоже не простаивает.
С асинхронностью разобрались. Но есть еще одна важная проблема: блокирующий ввод-вывод.
Блокирующий ввод-вывод
Традиционный ввод-вывод — блокирующий. А что же такое блокирующий ввод-вывод?
Допустим, вы читаете файл или базу данных. Вызывается метод, который это делает, и он блокирует поток: мы больше ничего не делаем, мы ждем. Например, вы вызвали readFile() и ждете, когда это наконец произойдет. Поток блокируется и не прогрессирует: он находится в ожидании. Но на самом деле процессор не занят.

В этом примере заблокированы потоки:
На чтение файла (blocked on reading file);
На чтение из базы данных (blocked on reading from DB);
На сложных вычислениях (blocked on heavy calculations);
На ответе от клиента (blocked on responding the client).
Эта ситуация сродни той, когда вы пришли в супермаркет, там есть четыре кассы, но система обслуживания касс тормозит. Кассирши сидят, ничего не делают и просто ждут, пока на кассе сработает нажатие на кнопку.
Что делать, если все потоки заблокированы? Как подобные проблемы решаются в супермаркете?
Synchronous I/O
Вариант обычный: синхронный ввод-вывод. Хорошего мало, в этом варианте образуются очереди к кассам.
Что сделать, чтобы возле касс не собирались огромные очереди? Например, можно открыть больше касс, или создать больше потоков.
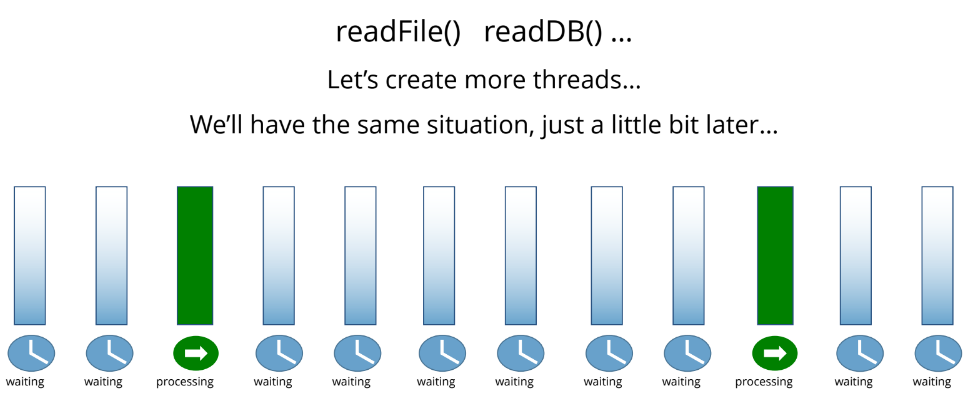
Больше потоков — больше касс. Это рабочий вариант. Но нагрузка получается неравномерной.
Мы открыли много касс (создали много потоков), и получается, что кто-то простаивает. На самом деле, это не просто простой: когда у нас много потоков, есть дополнительный расход ресурсов. Увеличивается расход памяти. Кроме того, процессору нужно переключаться между потоками.

Чем больше потоков, тем чаще между ними нужно переключаться. Получается, что потоков у нас гораздо больше, чем ядер. Допустим, у нас 4 ядра, а потоков мы насоздавали сотню, потому что все остальные были заблокированы чтением данных. Соответственно, происходит переключение, так называемый context switching, чтобы разные потоки получали свою порцию машинного времени.
Но у такого подхода есть минусы. Context switching не бесплатен. Он занимает время. Плодить неограниченное количество потоков было бы неплохим вариантом в теории. Но на практике мы получаем упадок скорости работы и рост потребляемой памяти.
В Java есть разные подходы, которые позволяют с этим бороться — это блокирующие очереди и пулы потоков (ThreadPool). Можно ограничивать количество потоков, и тогда все остальные клиенты встают в очередь. При старте у нас может быть минимальное количество потоков, потом их количество растет.
Вернемся к примеру магазина: если народа нет, в магазине открыты две кассы, а в час пик работает десять. Но больше мы открыть не можем, потому что тогда пришлось бы арендовать дополнительную площадь и нанимать людей. А это ударит по бизнесу.
Теперь поговорим о более современных подходах: кассах самообслуживания, предзаказах и так далее. А значит, мы подбираемся к асинхронному подходу.
Asynchronous I/O
Асинхронный ввод-вывод известен достаточно давно, ведь асинхронность необходима, когда мы работаем с самым медленным инструментом ввода-вывода. А наиболее медленным девайсом ввода-вывода, с которым постоянно приходится работать, является не консоль или клавиатура, а человек. В системах, которые работают с человеком, асинхронность появилась давным-давно.
Блокирующие интерфейсы использовались когда-то и при работе с человеком. Например, старый DOS’овский интерфейс командной строки. И сейчас существуют такие утилиты, которые задают вопрос, блокируются и больше ничего не делают, а ждут, пока человек ответит. С тех пор, как стали появляться оконные интерфейсы, появился асинхронный ввод-вывод. В настоящее время большинство интерфейсов именно асинхронные.
Как работает асинхронность?
Мы регистрируем функцию-callback, но на сей раз не говорим: «Человек, введи данные, а я буду ждать». Это звучит иначе: «Когда человек введет данные, вызови, пожалуйста, эту функцию — callback». Такой подход используется в любых библиотеках пользовательского интерфейса. Но в JavaScript он был изначально. В 2009 году, когда движок JavaScript стал работать гораздо быстрее, умные ребята решили использовать его на сервере, и сделали инструмент под названием Node.js.
Node.js
Идея Node.js в том, что на серверную часть переносится JavaScript, и весь ввод-вывод становится асинхронным. То есть вместо того, чтобы поток блокировался, например, при обращении к файлу, мы получаем асинхронный ввод-вывод. Обращение к файлу тоже становится асинхронным. Например, если потоку нужно получить содержимое файла, он говорит: «Дайте мне, пожалуйста, содержимое файла, а когда оно будет прочитано, вызовите эту функцию». Мы поставили задачу и занимаемся своими делами.
Такой асинхронный подход оказался весьма действенным, и Node.js быстро набрал популярность.
Как работает Node.js?

На входе есть приемщик — это цикл. JavaScript однопоточный язык. Но это не значит, что там ничего нельзя делать в других потоках. В нем поддерживаются потоки через Web Workers и т.д. Но на входе стоит один поток.
Вычислительные задачи для Node.js обычно очень маленькие. Основная работа идет с вводом-выводом (в базу данных, в файловую систему, в сторонние сервисы и т.д.). Сами вычисления занимают мало времени. Когда данные получили из базы или из файловой системы, вызывается callback, то есть какая-то функция, в которую передаются данные.
Но в этой схеме нет ожидания. Сравним ее с традиционной моделью многопоточного сервера в Java.
What happens in Java?

Здесь есть пул потоков. Сначала обращение попадает в первый поток, потом какой-то поток заблокировался, и мы создали еще один. Он тоже заблокировался, создаем следующий. А блокируются они потому, что обращаются к блокирующим операциям ввода-вывода. Например, поток запросил файл или данные из БД и ждет, когда эти данные придут.
Модель Node.js очень быстро стала популярной. Естественно, в этот момент люди стали переписывать ее на других языках. Node.js в какой-то момент вырвался вперед в нагруженных системах с большим объемом ввода-вывода. Но подходит он не для любых систем. Если у вас много вычислений или небольшое количество запросов, то большого преимущества вы не увидите. Соответственно, в Java стали появляться аналогичные решения, в том числе платформа для работы с асинхронным вводом-выводом Vert.x. Сервер Vert.x построен на таком же принципе, что и Node.js.
Решение Node.js интересное, оно действительно помогает повышать производительность. Когда пришла реактивность, стали применять сервер, который называется Netty. Такой подход оказался очень выгодным.
История многопоточности
Как работает многопоточность в Java? Старая добрая многопоточность в Java — это базовые примитивы многопоточности:
Threads (потоки);
Synchronization (синхронизация);
Wait/notify (ожидание/уведомление).
Сложно писать, сложно отлаживать, сложно тестировать.
Java 5
Future interface:
V get()
boolean cancel()
boolean isCancelled()
boolean isDone()
Executors
Callable interface
BlockingQueue
В пятой версии появился интерфейс Future. Future — это обещание, или будущее: что-то, что мы можем получить из функции, результат какой-то еще не завершенной асинхронной работы.
У интерфейса Future появился метод get. Он блокирует вызов до завершения вычисления. Например, у нас есть Future, который возвращает данные из БД, и мы обращаемся к методу get:
Future getDBData();
getDBData().get();
В этом месте возникает блокировка. На самом деле никакого преимущества от того, что мы использовали Future, нет. Когда можно получить преимущество? Например, мы ставим какую-то задачу, выполняем ее, обращаемся к методу get и в этот момент блокируемся:
Future f = getDBData();
doOutJob();
f.get();
Если вернуться к метафоре начальника и подчиненных, мы поставили задачу, сделали какую-то работу и дальше ждем, пока задача завершится. А если результат этой работы нужно передать еще какому-то человеку? Ранее мы рассматривали такой сценарий: сделай задачу, передай результаты, а потом уже вернись. В случае параллелизма нет такой возможности.
Возможности интерфейса Future очень ограничены. Например, можно узнать, выполнилась ли эта задача:
Future f = getDBData();
doOutJob();
if (!f.isDone) doOtherJob();
f.get();
Если задача еще не доделана, мы можем еще что-то предпринять. Но в любом случае пропустим этот момент: либо задача опять не успеет завершиться, либо, наоборот, она уже давно завершена, а мы занимались другой работой. Моменты синхронизации здесь получаются не очень четкими.
Интерфейс Future имел очень ограниченные возможности в Java 5, поэтому использовать его было неудобно.
Давайте подумаем, какие бизнес-задачи стоят перед типичным приложением?
Data flow
Обычно типичная задача приложения: прочитать, обработать и записать данные. Если мы хотим это делать асинхронно, нужно использовать асинхронные чтение, обработку и запись.
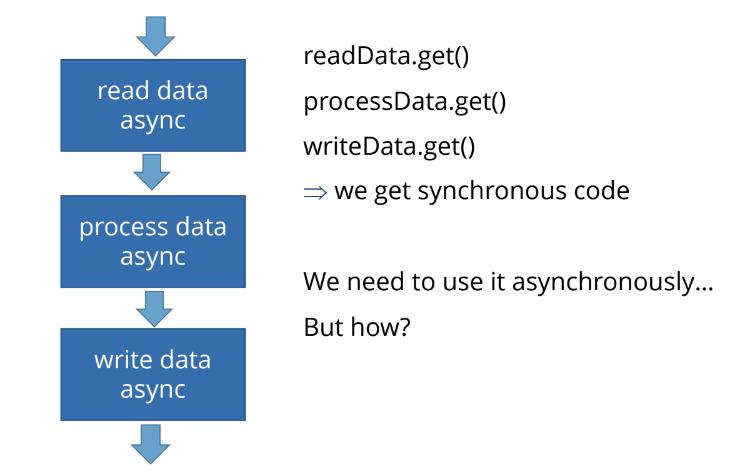
Например, если асинхронная функция блокируется, мы написали прекрасный код:
readData.get() и заблокировались,
processData.get() и заблокировались,
writeData.get() и тут тоже заблокировались.
Получаем синхронный код на выходе. Асинхронности здесь нет, использовать это неудобно.
Рассмотрим типичную задачу, когда есть асинхронное чтение данных, а потом мы хотим обрабатывать их «в три горла»:
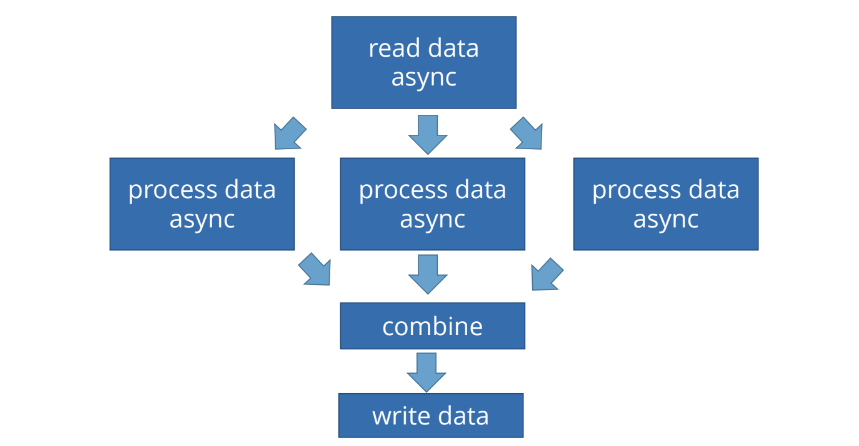
Для того, чтобы дождаться результата чтения, много потоков не нужно. Мы просто должны получить данные. Потом их нужно обрабатывать, а обработка — ресурсоемкая задача с точки зрения процессора, и хорошо бы ее распараллелить. Мы говорим: «Прочитай данные. Когда сделаешь это, обработай их в три потока, после этого соедини результаты выполнения и запиши данные». Хотелось бы, чтобы все это делалось асинхронно.
CompletableFuture brings us to the Async world

В Java 8 появился CompletableFuture. Он построен на базе Fork/Join framework. Так же, кстати, как и распараллеливание потоков. Fork/Join framework появился еще в Java 7, но его было сложно использовать. В 8 версии CompletableFuture стал шагом вперед: в сторону асинхронного мира.
Рассмотрим простенький пример.
В коде оранжевым выделены методы CompletableFuture из стандартного JDK.

Допустим, у нас есть API, который позволяет:
Читать данные (readData) из источника и возвращать CompletableFuture, потому что он асинхронный;
Обрабатывать данные, для чего есть два обработчика: processData1 и processData2;
Объединять данные (mergeData) после того, как они обработаны;
Записать данные (writeData) в приемник (Destination).
Это типичная задача — прочитать данные, обработать их «в два горла», потом соединить результаты этой обработки и куда-то записать.
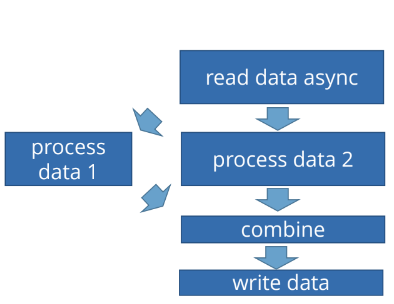
Мы прочитали данные:
CompletableFuture data = readData(source);
Дальше говорим: когда прочитаем данные, нужно отправить их на обработку:
CompletableFuture processData1 = data.thenApplyAsync(this::processData1);
Это значит, что нужно запустить их обработку в отдельном потоке. Так как у нас здесь используется Async постфикс, стартует обработка в двух разных потоках:
CompletableFuture processData2 = data.thenApplyAsync(this::processData2);
То есть функции this::processData1 и this::processData2 будут запущены в двух разных потоках и будут выполняться параллельно. Но после параллельного выполнения их результаты должны соединиться. Это делает thenCombine.
Мы здесь запустили два потока выполнения, и, когда они завершились, скомбинировали их. thenCombine работает так: он дожидается, когда и processData1, и processData2 завершатся, и после этого вызывает функцию объединения данных:
.thenCombine(processData2,
(a, b)->mergeData(a,b))
То есть мы объединяем результаты первой и второй обработки, и после этого записываем данные:
.thenAccept(
data->writeData(data, dest));
Здесь получается цепочка, которая по сути является бизнес-процессом. Мы как бы говорим: «Таня, забери данные из архива, отдай Лене и Грише на обработку. Когда и Леня, и Гриша принесут результаты, передай их Вере, чтобы она соединила их, а потом отдай Вите, чтобы он написал отчет по этим данным».
У нас здесь нет четкого графика, о котором мы говорили в начале: есть возможность передать данные сразу же, как только сможем. Единственный, кто здесь ждет — это thenCombine. Он ожидает, когда оба процесса, результат которых он объединяет, завершатся.
CompletableFuture — это действительно крутой подход, который помогает делать асинхронные системы.
В следующей части нашей статьи поговорим о более высокоуровневых подходах к асинхронности и разберем операторы реактивного программирования.
Конференция HighLoad++ 2020 пройдет 20 и 21 мая 2021 года. Приобрести билеты можно уже сейчас.
Хотите бесплатно получить материалы конференции мини-конференции Saint HighLoad++ 2020? Подписывайтесь на нашу рассылку.
