Объемы баз данных и сложность запросов к ним всегда росли быстрее, чем скорость их обработки. Поэтому лучшие умы человечества много лет думали о том, что произойдет, когда оперативной памяти станет столько, что можно будет всю базу данных взять и поместить в кэш оперативной памяти.
В последние годы логический момент для этого, казалось бы, настал. Стоимость оперативной памяти падала, падала, и упала совсем. Еще в начале века казалось, что 256 МБ памяти для сервера — это нормально, и даже много. Сегодня нас не удивишь параметром 256 ГБ оперативной памяти на сервере начального уровня, а с промышленными серверами вообще настал полный коммунизм, любой благородный дон может набрать хоть терабайт оперативной памяти на сервере, если захочет.
Но дело не только в этом — появились новые технологии индексирования данных, новые технологии компрессии данных — OLTP-компрессия, компрессия неструктурированных данных
(LOB Compression). В Oracle Database 11g, например, появилась технология Result Cache, которая позволяет кэшировать не просто строки таблиц или индексы, но и сами результаты запросов и подзапросов.
То есть, с одной стороны, наконец-то можно использовать оперативную память по ее прямому назначению, но с другой стороны — не так все просто. Чем больше кэш, тем больше накладные расходы на его сопровождение, включая процессорное время. Вы ставите больше памяти, увеличиваете объем кэша, а система работает медленнее, и это, в общем-то, логично, потому что алгоритмы управление памятью, разработанные в Раннем средневековье нашими прапрадедушками, попросту не годятся для эпохи Возрождения, и все тут. Что же делать?
А вот что. Давайте вспомним о том, что существует, по сути дела, две категории баз данных: строчные базы данных, которые и в буферном кэше в оперативной памяти, и на диске хранят информацию в строчном виде — Oracle Database, Microsoft SQL Server, IBM DB/2, MySQL и т.д.; и колоночные СУБД, в которых информация хранится по столбцам, и которые большого распространения в индустрии, к сожалению, не нашли. Строчные базы данных хорошо обрабатывают OLTP-операции, а вот для обработки аналитики больше подходят, вы будете смеяться, колоночные базы данных — зато DML-операции для них проблема, ну вы поняли, почему. Промышленность, как вы знаете, по��ла по пути строчных баз данных, на которые в виде компромисса навешиваются аналитические возможности.
И вот, появилась технология Oracle Database In-Memory, в которой преимущества обоих подходов наконец-то совмещены.
Получается фантастика. Обработка транзакций ускоряется в два раза, вставка строк происходит в 3–4 раза быстрее, запросы для аналитики выполняются в реальном времени, практически мгновенно! Маркетологи говорят, что аналитика стала в сто раз быстрее, но это они скромничают, чтобы не пугать рынок, реальные результаты куда более впечатляющие.
А теперь давайте разбираться, как и в чем это работает.
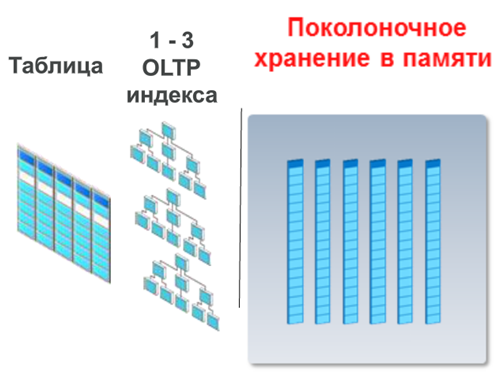
Итак, технология появилась в версии Oracle Database 12.1.0.2, и смысл ее в том, что рядом с нашим привычным буферным кэшем, который хранит строки таблиц и блоки индексов, находится новый кэш, точнее новая разделяемая область для данных в оперативной памяти, в которой данные из таблиц хранятся в колоночном формате! Вы поняли, да? И строчный и колоночный формат хранения в памяти для одних и тех же данных и таблиц! Причем данные одновременно активны и транзакционно согласованы. Все изменения, как обычно, сначала производятся в обычном буферным кэше, после чего отражаются в колоночном, или, как его называют наши англоязычные друзья, «колумнарном» кэше.
Несколько важных деталей. Во-первых, в колумнарном кэше отражаются только таблицы, то есть индексы не кэшируется — это первое. Во-вторых, технология не делает ненужную работу. Если данные читаются, но не изменяются, то в обычном, то есть в строчном буферном кэше хранить их незачем. А вот если данные изменяются, тогда их надо хранить в обоих кэшах, буферном и колоночном. Ну, и соответственно быстрее работает аналитика потому что для нее более эффективно именно колоночное представление информации. Это второе. И в-третьих — еще раз, чтобы было понятно. В колоночном кэше хранятся не блоки данных с диска. В блоках на диске информация хранится по строкам. В колумнарном кэше информация хранится по столбцам, в своем собственном представлении, в так называемых In-Memory «компресс юнитах». Это третье.
Мы поняли, что аналитика работает в сотни раз быстрее, потому что колоночное представление для нее более эффективно — а, собственно говоря, почему?
В обычном буферном кэше информация хранится по строкам. Вот пример — из четырехколоночной таблицы нужно извлечь колонку №4. Для этого придется полностью просканировать всю эту табличку в оперативной памяти:
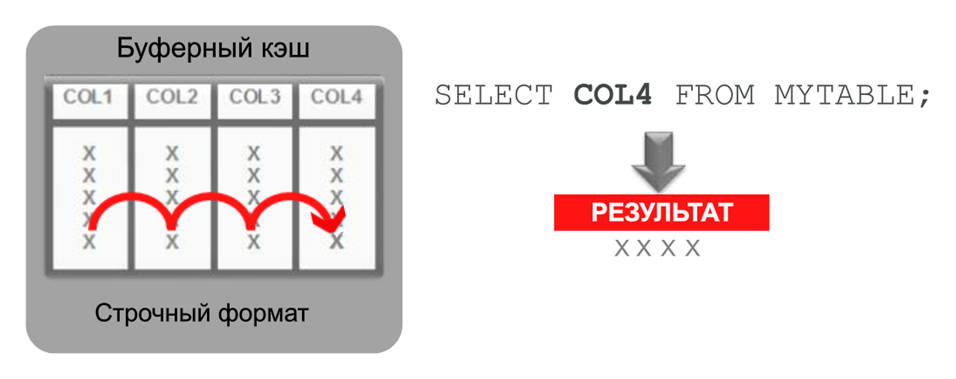
А что происходит, если та же таблица хранится в колоночном формате? Вся четвертая колонка нашей таблички находится в одном экстенте, т.е. в одном блоке памяти. Мы можем сразу выделить ее, тут же прочитать и вернуть приложению. Уменьшаются затраты на сканирование, на пересылку этих данных процессору, снижается загрузка процессора. Все работает значительно быстрее.
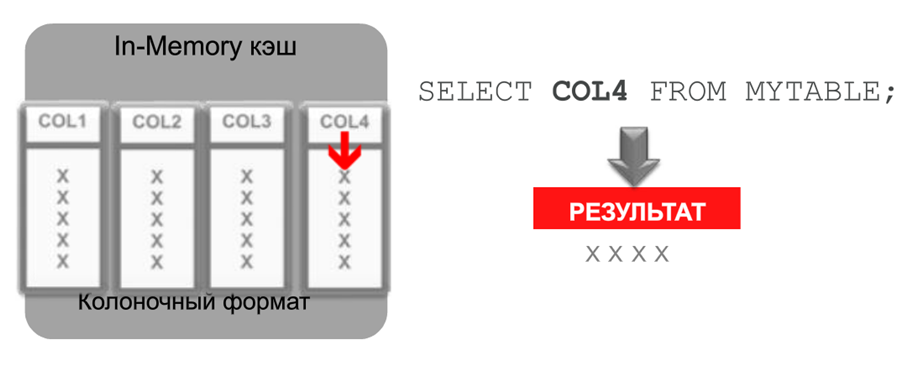
Такие операции сканирования очень характерны для ERP-приложений, для хранилищ данных в аналитических системах. Согласитесь, нужная штука для прогресса человечества.
Технически, чтобы это запустить, нужно включить кэширование для нужных столбцов в таблице. Для этого предназначено специальное расширение синтаксиса команды ALTER TABLE:
Делается это один раз, информация записывается в системный словарь СУБД Oracle, после чего автоматически используется базой данных в процессе своей работы. В вышеприведенном примере служебные столбцы не участвуют в отчетах, они нужны только для внутреннего аудита приложения, и поэтому мы их не кэшируем.
Можно указать кэширование по всем столбцам для материализованного представления:
SQL> ALTER MATERIALIZED VIEW cities_mv INMEMORY
Materialized view altered.
Можно включить кэширование на уровне всего табличного пространства:
А можно гибко кэшировать таблицы по столбцам на уровне секций, чтобы увязать стратегию кэширования с бизнес-правилами:
Например, есть у нас исторические данные, и они секционированы по дате. Когда у происходит закрытие периода, допустим, операционного дня, данные в этой секции таблицы уже не меняются, и по ним может начинать работать аналитика. Вот для этого нужно кэширование по секциям таблицы, по которым период закрыт. А для данных, по которым идут интенсивные операции изменения и удаления, включать кэширование пока незачем.
Что происходит, когда мы включаем кэширование и информация записывается в словарь СУБД Oracle? Происходит волшебство — SQL-оптимизатор перестраивает план запроса. В первый раз, когда запрос приходит из приложения, на этапе так называемого жесткого парсинга (hard parse), генерируется план выполнения запроса.
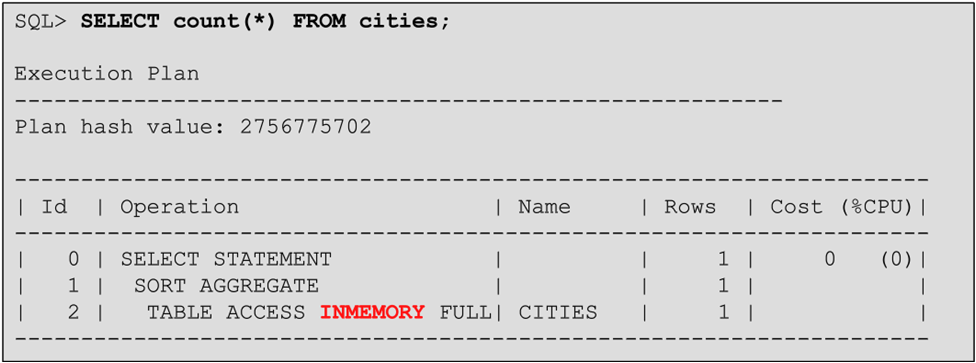
В данном примере подсчитывается общее количество строк в табличке справочника городов CITIES. Оптимизатор видит, что выгодно выполнить запрос по колоночному представлению, и выполняет сканирование TABLE ACCESS INMEMORY FULL. Для приложения это полностью прозрачно, переписывания или модификации приложения не требуется!
Сама база данных Oracle при этом используют ряд интересных техник оптимизации:
1. Каждое процессорное ядро производит сканирование собственного столбца. При этом используются быстрые векторные SIMD-инструкции, т.е. специальные команды процессора, которые в качестве аргументов используют не скалярные значения, а вектор значений. Это дает сканирование миллиардов строк в секунду.
2. Мы не просто сканируем данные. Происходит сканирование и соединение данных из нескольких таблиц. На колоночном представлении это гораздо эффективнее, чем обычные joins. Такие joins выполняются в среднем в 10 раз быстрее.
3. В процессе выполнения запроса используется технология In-Memory Aggregation: в памяти создается динамический объект — промежуточный отчет. Объект заполняется во время сканирования таблицы и позволяет ускорить выполнение запроса. В результате отчеты строятся в 20 раз быстрее без заранее созданных аналитических кубов.
4. Чтобы не загромождать оперативную память, используется сжатие столбцов в памяти. Есть шесть вариантов:
• NO MEMCOPRESS — без сжатия
• MEMCOMPRESS FOR DML — оптимизированный для DML-операций
• MEMCOMPRESS FOR QUERY LOW — оптимальный вариант, который используется по умолчанию
• MEMCOMPRESS FOR QUERY HIGH — оптимизированный для скорости выполнения запроса и для экономии памяти
• MEMCOMPRESS FOR CAPACITY HIGH — оптимизированный для скорости выполнения запроса
• MEMCOMPRESS FOR CAPACITY LOW — оптимизированный для экономии памяти
Например:
В этом примере выбраны для сжатия столбцы данные в которых часто повторяются, уникальные столбцы не сжимаются.
В системной таблице словаря USER_TABLES появился новый атрибут сегмента INMEMORY. Столбец INMEMORY также появился в системных таблицах *_TAB_PARTITIONS. Чтобы узнать, что и в каком объеме находится в кэше, нужно использовать специальное системное представление V$IM_SEGMENTS:
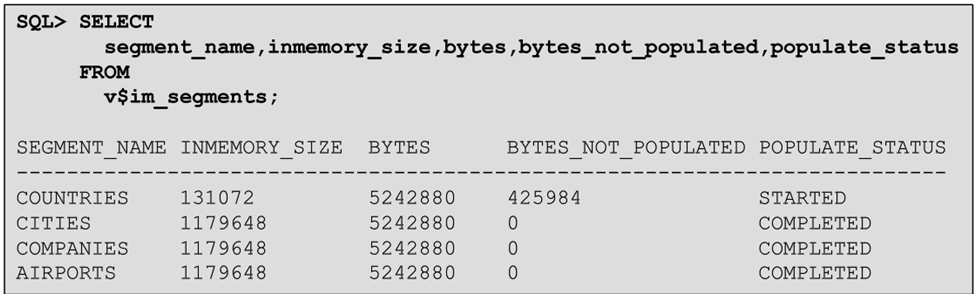
В этом примере мы видим, что в кэше находятся четыре таблицы, причем на диске каждая таблица занимает примерно по 5 МБ, а в памяти, за счет сжатия — от 100 КБ до 1 МБ. Колонка POPULATE_STATUS показывает статус информации. Видим, что таблицы CITIES, COMPANIES, и AIRPORTS уже полностью загрузились в In-Memory-кэш, а COUNTRIES — еще не полностью, 400 КБ осталось загрузить. То есть именно сейчас эта таблица транспонируется в формат по столбцам и загружается в кэш.
С технической точки зрения чтение в память с диска может происходить двумя способами:
• При первом обращении к данным. Это возможность по умолчанию.
• Автоматически после старта экземпляра БД. Эта возможность включается установкой атрибута сегмента PRIORITY.
Во втором варианте чтение производят фоновые процессы ORA_W001_orcl (W001 — номер экземпляра), количество фоновых процессов регулируется с помощью нового параметра INMEMORY_MAX_POPULATE_SERVERS. В результате после рестарта экземпляр сразу доступен для работы в фоновом режиме, и время старта экземпляра при этом не увеличивается. Конечно, в начале возрастает нагрузка на процессор, куда ж деваться. Зато потом будут быстрее работать аналитические запросы.
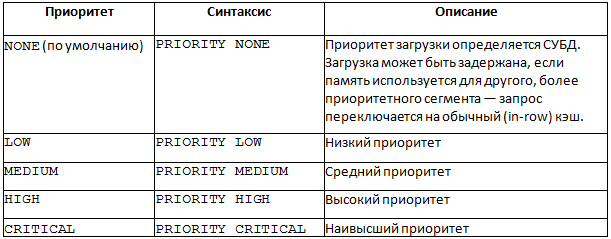
Приоритетом загрузки в кэш можно управлять, вот варианты значений приоритета:
Допустим, мы держим в таблице cities справочник городов, и этот справочник постоянно нужен всем пользователям, он постоянно участвует в отчетах. В этом случае мы должны указать для этой таблицы критический приоритет, тем самым мы заставим систему автоматически считать экземпляр этой таблицы в кэш при старте базы данных:
Как вы прекрасно знаете, чистых OLTP-систем практически не бывает. В любом OLTP-приложении есть поддержка отчетности, а для отчетности нужны дополнительные индексы. А что такое дополнительные индексы? Это ни что иное, как дополнительные накладные расходы на вставку данных.
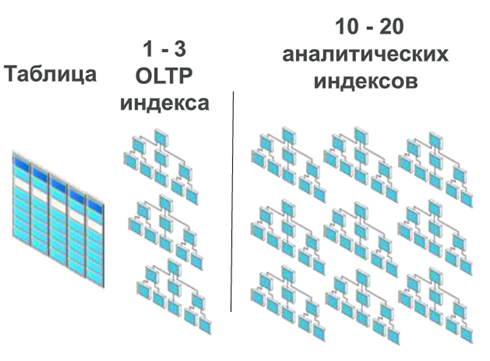
А теперь разрешите мне с гордостью сообщить вам о том, что при переходе на Oracle Database In-Memory решается и эта проблема, потому что в этой технологии — правильно! — не используются индексы. Т.е. мы можем просто удалить те индексы, которые нужны нам для аналитики, и получаем парадоксальный эффект — система, предназначенная для повышения скорости работы хранилищ данных, прекрасно «разгоняет» и OLTP-приложения.
При этом тем операциям, которые и раньше работали хорошо, технология Oracle Database In-Memory не мешает и не пытается помочь (принцип «не надо чинить то, что не сломалось», в действии!), поскольку в ядре базы данных она находится, так сказать, в стороне. То есть на формат данных на диске эта технология никак не влияет, все работает точно так же, как и раньше, какую бы файловую систему вы ни использовали. Файлы данных не меняются, журнал, резервирование, восстановление данных работают по-прежнему. Все технологии, в том числе ASM, RAC, DataGuard, GoldenGate — работают прозрачно.
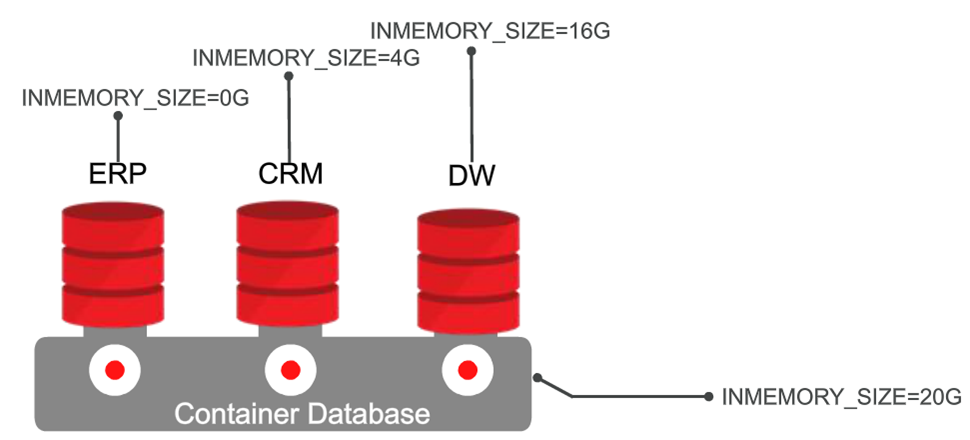
Главное архитектурное новшество в Oracle Database 12c — это контейнерная архитектура. Oracle Database In-Memory полностью поддерживает эту архитектуру. Параметр INMEMORY_SIZE устанавливается на уровне всей контейнерной базы данных, а на уровне конкретных баз данных его можно варьировать в зависимости от конкретного приложения. Например, на уровне контейнерной базы данных вы можете установить INMEMORY_SIZE равным 20 ГБ, а на уровне контейнеров — не включать кэш для ERP, для CRM установить объем кэша 4 ГБ, для хранилища данных — 16 ГБ.
Да, и в кластерах Oracle Real Application Cluster это тоже работает. Можно управлять распределением объектов в кэше In-Memory между узлами в кластере. Например, можно указать опцию DUPLICATE, тогда при изменении кэша на одном из узлов кластера они будут автоматически синхронизироваться со вторым узлом, это нужно для того, чтобы всегда существовала доступная копия кэша с «разогретыми» колумнарными данными:
Другие варианты:
• AUTO DISTRIBUTE — синхронизацией кэша управляет СУБД (используется по умолчанию);
• DUPLICATE ALL — на всех узлах кластера синхронизируется одинаковый кэш;
• DISTRIBUTE BY ROWID RANGE;
• DISTRIBUTE BY PARTITION;
• DISTRIBUTE BY SUBPARTITION.
Опция DUPLICATE и DUPLICATE ALL работает только на Oracle Exadata и Oracle SuperCluster, на обычном сервере эта опция игнорируется. Остальные варианты нужны для более гибкого управления — например, с помощью параметра DISTRIBUTE BY ROWID RANGE можно указать, что часть секций должна находиться в колоночном виде на одном узле, а остальные — на другом узле.
Не могу больше скрывать от вас полный синтаксис команды ALTER TABLE INMEMORY. Вот он:
Можно указать приоритет загрузки в кэш, способ синхронизации кэша между узлами кластера, имена столбцов, которые нужно и не нужно кэшировать в памяти, степень сжатия. Команда, как я уже писал, выполняется один раз, далее информация запоминается.
Для настоящих инженеров есть возможность тонко настраивать свои запросы с помощью хинтов SQL-оптимизатора: INMEMORY,NO_INMEMORY, INMEMORY_PRUNING и NO_INMEMORY_PRUNING.
NO_INMEMORY, как видите, является здесь простейшим хинтом. Например, можно в явном виде дать оптимизатору указание не использовать технологию In-Memory — если вы уверены в том, что это попросту не нужно, потому что у вас хороший запрос, построены индексы и т.д. Еще два интересных хинта — INMEMORY_PRUNING и NO_INMEMORY_PRUNING, они управляют использованием storage-индексов. Storage-индекс хранит минимальное и максимальное значение столбца в каждом экстенте памяти кэша и прозрачно исключает ненужные сканирования столбцов, например: WHERE prod_id> 14 AND prod_id < 29.
В файле инициализации INIT.ORA появились новые параметры, дарю их вам безвозмездно, то есть даром:
• INMEMORY_SIZE
• INMEMORY_FORCE= { DEFAULT | OFF }
• INMEMORY_CLAUSE_DEFAULT= [INMEMORY] [NO INMEMORY] [compression-clauses][priority-clauses]
• INMEMORY_QUERY={ENABLE | DISABLE}
• INMEMORY_MAX_POPULATE_SERVERS
• OPTIMIZER_INMEMORY_AWARE
• INMEMORY TRICKLE REPOPULATE SERVERS PERCENT
INMEMORY_SIZE позволяет указать размер области памяти для колумнарных данных, по умолчанию равен нулю. Например, INMEMORY_MAX_POPULATE_SERVERS — это количество фоновых процессов, которые считывают данные с диска в кэш, по умолчанию он равен количеству процессоров, которые «видит» Oracle Database. Еще один интересный параметр — OPTIMIZER_INMEMORY_AWARE, при его помощи можно указать, видит или не видит оптимизатор In-Memory-кэш. Например, это нужно, если вы нужно оценить накладные расходы. Подробности предлагаю вам найти в документации.
Oracle Database In-Memory больше всего подходит для приложений, в которых много запросов, сканирующих много строк с такими фильтрами как: «=», «<», «>», «IN». Технология очень эффективна, когда приложение запрашивает всего лишь несколько столбцов из большого числа (типично для SAP), соединяет большие факторные таблицы с таблицами измерений, с фильтрами по таблицам измерений. Соответственно, это такие приложения, как хранилища данных, информационно-аналитические системы, включая OLTP-приложения. Кстати, есть полезный дополнительный продукт — Oracle Database In-Memory Advisor, он помогает оценить применимость технологии Oracle Database In-Memory к конкретным приложениям. Oracle Database In-Memory Adviser анализирует статистику работы базы данных и выдает рекомендации по размеру памяти, по типу таблиц, которые необходимо кэшировать в In-Memory-кэше.
Важно понимать, что в отличие от конкурентов, Oracle Database In-Memory не требует переписывания приложений. Нет ограничений на SQL, не нужна миграция данных, технология готова для облака.
Не надо путать Oracle Database In-Memory и Oracle TimesTen In-Memory Database, это разные технологии. TimesTen — это встраиваемая база данных для приложений, она предназначена для чистых, а не смешанных OLTP-систем, для тех случаев, когда приложение должно работать в режиме реального времени, и время ответа должно составлять буквально секунды, а не секунды и не миллисекунды. TimesTen полностью загружает все данные в оперативную память. В отличие от нее Oracle Database In-Memory является расширением классической СУБД Oracle, находится внутри ее ядра и расширяет ее возможности с точки зрения ускорения аналитических запросов за счет колоночного представления.
Мне кажется, я написал достаточно, чтобы пробудить в вас неудержимое желание прочитать документацию к Oracle Database In-Memory. Но тут дело такое — технология новая, экспертизы по ней мало, один я на все ваши вопросы ответить не смогу. Поэтому, друзья, записывайтесь на наши онлайн-тренинги. Мы их будем прямо здесь будем обязательно анонсировать. А у меня пока все.
В последние годы логический момент для этого, казалось бы, настал. Стоимость оперативной памяти падала, падала, и упала совсем. Еще в начале века казалось, что 256 МБ памяти для сервера — это нормально, и даже много. Сегодня нас не удивишь параметром 256 ГБ оперативной памяти на сервере начального уровня, а с промышленными серверами вообще настал полный коммунизм, любой благородный дон может набрать хоть терабайт оперативной памяти на сервере, если захочет.
Но дело не только в этом — появились новые технологии индексирования данных, новые технологии компрессии данных — OLTP-компрессия, компрессия неструктурированных данных
(LOB Compression). В Oracle Database 11g, например, появилась технология Result Cache, которая позволяет кэшировать не просто строки таблиц или индексы, но и сами результаты запросов и подзапросов.
То есть, с одной стороны, наконец-то можно использовать оперативную память по ее прямому назначению, но с другой стороны — не так все просто. Чем больше кэш, тем больше накладные расходы на его сопровождение, включая процессорное время. Вы ставите больше памяти, увеличиваете объем кэша, а система работает медленнее, и это, в общем-то, логично, потому что алгоритмы управление памятью, разработанные в Раннем средневековье нашими прапрадедушками, попросту не годятся для эпохи Возрождения, и все тут. Что же делать?
А вот что. Давайте вспомним о том, что существует, по сути дела, две категории баз данных: строчные базы данных, которые и в буферном кэше в оперативной памяти, и на диске хранят информацию в строчном виде — Oracle Database, Microsoft SQL Server, IBM DB/2, MySQL и т.д.; и колоночные СУБД, в которых информация хранится по столбцам, и которые большого распространения в индустрии, к сожалению, не нашли. Строчные базы данных хорошо обрабатывают OLTP-операции, а вот для обработки аналитики больше подходят, вы будете смеяться, колоночные базы данных — зато DML-операции для них проблема, ну вы поняли, почему. Промышленность, как вы знаете, по��ла по пути строчных баз данных, на которые в виде компромисса навешиваются аналитические возможности.
И вот, появилась технология Oracle Database In-Memory, в которой преимущества обоих подходов наконец-то совмещены.
И что получается?
Получается фантастика. Обработка транзакций ускоряется в два раза, вставка строк происходит в 3–4 раза быстрее, запросы для аналитики выполняются в реальном времени, практически мгновенно! Маркетологи говорят, что аналитика стала в сто раз быстрее, но это они скромничают, чтобы не пугать рынок, реальные результаты куда более впечатляющие.
А теперь давайте разбираться, как и в чем это работает.
Итак, технология появилась в версии Oracle Database 12.1.0.2, и смысл ее в том, что рядом с нашим привычным буферным кэшем, который хранит строки таблиц и блоки индексов, находится новый кэш, точнее новая разделяемая область для данных в оперативной памяти, в которой данные из таблиц хранятся в колоночном формате! Вы поняли, да? И строчный и колоночный формат хранения в памяти для одних и тех же данных и таблиц! Причем данные одновременно активны и транзакционно согласованы. Все изменения, как обычно, сначала производятся в обычном буферным кэше, после чего отражаются в колоночном, или, как его называют наши англоязычные друзья, «колумнарном» кэше.
Несколько важных деталей. Во-первых, в колумнарном кэше отражаются только таблицы, то есть индексы не кэшируется — это первое. Во-вторых, технология не делает ненужную работу. Если данные читаются, но не изменяются, то в обычном, то есть в строчном буферном кэше хранить их незачем. А вот если данные изменяются, тогда их надо хранить в обоих кэшах, буферном и колоночном. Ну, и соответственно быстрее работает аналитика потому что для нее более эффективно именно колоночное представление информации. Это второе. И в-третьих — еще раз, чтобы было понятно. В колоночном кэше хранятся не блоки данных с диска. В блоках на диске информация хранится по строкам. В колумнарном кэше информация хранится по столбцам, в своем собственном представлении, в так называемых In-Memory «компресс юнитах». Это третье.
А теперь детали
Мы поняли, что аналитика работает в сотни раз быстрее, потому что колоночное представление для нее более эффективно — а, собственно говоря, почему?
В обычном буферном кэше информация хранится по строкам. Вот пример — из четырехколоночной таблицы нужно извлечь колонку №4. Для этого придется полностью просканировать всю эту табличку в оперативной памяти:
А что происходит, если та же таблица хранится в колоночном формате? Вся четвертая колонка нашей таблички находится в одном экстенте, т.е. в одном блоке памяти. Мы можем сразу выделить ее, тут же прочитать и вернуть приложению. Уменьшаются затраты на сканирование, на пересылку этих данных процессору, снижается загрузка процессора. Все работает значительно быстрее.
Такие операции сканирования очень характерны для ERP-приложений, для хранилищ данных в аналитических системах. Согласитесь, нужная штука для прогресса человечества.
Технически, чтобы это запустить, нужно включить кэширование для нужных столбцов в таблице. Для этого предназначено специальное расширение синтаксиса команды ALTER TABLE:
SQL> ALTER TABLE cities INMEMORY INMEMORY (Id, Name, Country_Id, Time_Zone) NO INMEMORY (Created, Modified, State); Table altered.
Делается это один раз, информация записывается в системный словарь СУБД Oracle, после чего автоматически используется базой данных в процессе своей работы. В вышеприведенном примере служебные столбцы не участвуют в отчетах, они нужны только для внутреннего аудита приложения, и поэтому мы их не кэшируем.
Можно указать кэширование по всем столбцам для материализованного представления:
SQL> ALTER MATERIALIZED VIEW cities_mv INMEMORY
Materialized view altered.
Можно включить кэширование на уровне всего табличного пространства:
SQL> ALTER TABLESPACE tbs_data DEFAULT INMEMORY MEMCOMPRESS FOR CAPACITY HIGH PRIORITY LOW; Tablespace altered.
А можно гибко кэшировать таблицы по столбцам на уровне секций, чтобы увязать стратегию кэширования с бизнес-правилами:
SQL> CREATE TABLE customers ....... PARTITION BY LIST</b> PARTITION p1 ....... INMEMORY, PARTITION p2 ....... NO INMEMORY);
Например, есть у нас исторические данные, и они секционированы по дате. Когда у происходит закрытие периода, допустим, операционного дня, данные в этой секции таблицы уже не меняются, и по ним может начинать работать аналитика. Вот для этого нужно кэширование по секциям таблицы, по которым период закрыт. А для данных, по которым идут интенсивные операции изменения и удаления, включать кэширование пока незачем.
За сценой
Что происходит, когда мы включаем кэширование и информация записывается в словарь СУБД Oracle? Происходит волшебство — SQL-оптимизатор перестраивает план запроса. В первый раз, когда запрос приходит из приложения, на этапе так называемого жесткого парсинга (hard parse), генерируется план выполнения запроса.
В данном примере подсчитывается общее количество строк в табличке справочника городов CITIES. Оптимизатор видит, что выгодно выполнить запрос по колоночному представлению, и выполняет сканирование TABLE ACCESS INMEMORY FULL. Для приложения это полностью прозрачно, переписывания или модификации приложения не требуется!
Сама база данных Oracle при этом используют ряд интересных техник оптимизации:
1. Каждое процессорное ядро производит сканирование собственного столбца. При этом используются быстрые векторные SIMD-инструкции, т.е. специальные команды процессора, которые в качестве аргументов используют не скалярные значения, а вектор значений. Это дает сканирование миллиардов строк в секунду.
2. Мы не просто сканируем данные. Происходит сканирование и соединение данных из нескольких таблиц. На колоночном представлении это гораздо эффективнее, чем обычные joins. Такие joins выполняются в среднем в 10 раз быстрее.
3. В процессе выполнения запроса используется технология In-Memory Aggregation: в памяти создается динамический объект — промежуточный отчет. Объект заполняется во время сканирования таблицы и позволяет ускорить выполнение запроса. В результате отчеты строятся в 20 раз быстрее без заранее созданных аналитических кубов.
4. Чтобы не загромождать оперативную память, используется сжатие столбцов в памяти. Есть шесть вариантов:
• NO MEMCOPRESS — без сжатия
• MEMCOMPRESS FOR DML — оптимизированный для DML-операций
• MEMCOMPRESS FOR QUERY LOW — оптимальный вариант, который используется по умолчанию
• MEMCOMPRESS FOR QUERY HIGH — оптимизированный для скорости выполнения запроса и для экономии памяти
• MEMCOMPRESS FOR CAPACITY HIGH — оптимизированный для скорости выполнения запроса
• MEMCOMPRESS FOR CAPACITY LOW — оптимизированный для экономии памяти
Например:
SQL> ALTER TABLE cities INMEMORY INMEMORY MEMCOMPRESS FOR CAPACITY HIGH(Country_Id,Time_Zone) INMEMORY NO MEMCOMPRESS (Id, Name, Name_Eng); Table altered.
В этом примере выбраны для сжатия столбцы данные в которых часто повторяются, уникальные столбцы не сжимаются.
В системной таблице словаря USER_TABLES появился новый атрибут сегмента INMEMORY. Столбец INMEMORY также появился в системных таблицах *_TAB_PARTITIONS. Чтобы узнать, что и в каком объеме находится в кэше, нужно использовать специальное системное представление V$IM_SEGMENTS:
В этом примере мы видим, что в кэше находятся четыре таблицы, причем на диске каждая таблица занимает примерно по 5 МБ, а в памяти, за счет сжатия — от 100 КБ до 1 МБ. Колонка POPULATE_STATUS показывает статус информации. Видим, что таблицы CITIES, COMPANIES, и AIRPORTS уже полностью загрузились в In-Memory-кэш, а COUNTRIES — еще не полностью, 400 КБ осталось загрузить. То есть именно сейчас эта таблица транспонируется в формат по столбцам и загружается в кэш.
Первым делом — приоритеты
С технической точки зрения чтение в память с диска может происходить двумя способами:
• При первом обращении к данным. Это возможность по умолчанию.
• Автоматически после старта экземпляра БД. Эта возможность включается установкой атрибута сегмента PRIORITY.
Во втором варианте чтение производят фоновые процессы ORA_W001_orcl (W001 — номер экземпляра), количество фоновых процессов регулируется с помощью нового параметра INMEMORY_MAX_POPULATE_SERVERS. В результате после рестарта экземпляр сразу доступен для работы в фоновом режиме, и время старта экземпляра при этом не увеличивается. Конечно, в начале возрастает нагрузка на процессор, куда ж деваться. Зато потом будут быстрее работать аналитические запросы.
Приоритетом загрузки в кэш можно управлять, вот варианты значений приоритета:
Допустим, мы держим в таблице cities справочник городов, и этот справочник постоянно нужен всем пользователям, он постоянно участвует в отчетах. В этом случае мы должны указать для этой таблицы критический приоритет, тем самым мы заставим систему автоматически считать экземпляр этой таблицы в кэш при старте базы данных:
SQL> ALTER TABLE cities INMEMORY PRIORITY CRITICAL INMEMORY MEMCOMPRESS FOR CAPACITY HIGH(Country_Id, Time_Zone) INMEMORY MEMCOMPRESS NO (Id, Name, Name_Eng); Table altered.
А как же OLTP?
Как вы прекрасно знаете, чистых OLTP-систем практически не бывает. В любом OLTP-приложении есть поддержка отчетности, а для отчетности нужны дополнительные индексы. А что такое дополнительные индексы? Это ни что иное, как дополнительные накладные расходы на вставку данных.
А теперь разрешите мне с гордостью сообщить вам о том, что при переходе на Oracle Database In-Memory решается и эта проблема, потому что в этой технологии — правильно! — не используются индексы. Т.е. мы можем просто удалить те индексы, которые нужны нам для аналитики, и получаем парадоксальный эффект — система, предназначенная для повышения скорости работы хранилищ данных, прекрасно «разгоняет» и OLTP-приложения.
При этом тем операциям, которые и раньше работали хорошо, технология Oracle Database In-Memory не мешает и не пытается помочь (принцип «не надо чинить то, что не сломалось», в действии!), поскольку в ядре базы данных она находится, так сказать, в стороне. То есть на формат данных на диске эта технология никак не влияет, все работает точно так же, как и раньше, какую бы файловую систему вы ни использовали. Файлы данных не меняются, журнал, резервирование, восстановление данных работают по-прежнему. Все технологии, в том числе ASM, RAC, DataGuard, GoldenGate — работают прозрачно.
Контейнерная архитектура
Главное архитектурное новшество в Oracle Database 12c — это контейнерная архитектура. Oracle Database In-Memory полностью поддерживает эту архитектуру. Параметр INMEMORY_SIZE устанавливается на уровне всей контейнерной базы данных, а на уровне конкретных баз данных его можно варьировать в зависимости от конкретного приложения. Например, на уровне контейнерной базы данных вы можете установить INMEMORY_SIZE равным 20 ГБ, а на уровне контейнеров — не включать кэш для ERP, для CRM установить объем кэша 4 ГБ, для хранилища данных — 16 ГБ.
Кластерная архитектура
Да, и в кластерах Oracle Real Application Cluster это тоже работает. Можно управлять распределением объектов в кэше In-Memory между узлами в кластере. Например, можно указать опцию DUPLICATE, тогда при изменении кэша на одном из узлов кластера они будут автоматически синхронизироваться со вторым узлом, это нужно для того, чтобы всегда существовала доступная копия кэша с «разогретыми» колумнарными данными:
SQL> ALTER TABLE cities INMEMORY DUPLICATE; Table altered.
Другие варианты:
• AUTO DISTRIBUTE — синхронизацией кэша управляет СУБД (используется по умолчанию);
• DUPLICATE ALL — на всех узлах кластера синхронизируется одинаковый кэш;
• DISTRIBUTE BY ROWID RANGE;
• DISTRIBUTE BY PARTITION;
• DISTRIBUTE BY SUBPARTITION.
Опция DUPLICATE и DUPLICATE ALL работает только на Oracle Exadata и Oracle SuperCluster, на обычном сервере эта опция игнорируется. Остальные варианты нужны для более гибкого управления — например, с помощью параметра DISTRIBUTE BY ROWID RANGE можно указать, что часть секций должна находиться в колоночном виде на одном узле, а остальные — на другом узле.
Резюме
Не могу больше скрывать от вас полный синтаксис команды ALTER TABLE INMEMORY. Вот он:
SQL> ALTER TABLE cities INMEMORY PRIORITY CRITICAL</b> DUPLICATE</b> INMEMORY MEMCOMPRESS FOR CAPACITY HIGH (Country_Id, Time_Zone) INMEMORY MEMCOMPRESS NO (Id, Name, Name_Eng) NO INMEMORY (Created, Modified, State); Table altered.
Можно указать приоритет загрузки в кэш, способ синхронизации кэша между узлами кластера, имена столбцов, которые нужно и не нужно кэшировать в памяти, степень сжатия. Команда, как я уже писал, выполняется один раз, далее информация запоминается.
Для настоящих инженеров есть возможность тонко настраивать свои запросы с помощью хинтов SQL-оптимизатора: INMEMORY,NO_INMEMORY, INMEMORY_PRUNING и NO_INMEMORY_PRUNING.
NO_INMEMORY, как видите, является здесь простейшим хинтом. Например, можно в явном виде дать оптимизатору указание не использовать технологию In-Memory — если вы уверены в том, что это попросту не нужно, потому что у вас хороший запрос, построены индексы и т.д. Еще два интересных хинта — INMEMORY_PRUNING и NO_INMEMORY_PRUNING, они управляют использованием storage-индексов. Storage-индекс хранит минимальное и максимальное значение столбца в каждом экстенте памяти кэша и прозрачно исключает ненужные сканирования столбцов, например: WHERE prod_id> 14 AND prod_id < 29.
В файле инициализации INIT.ORA появились новые параметры, дарю их вам безвозмездно, то есть даром:
• INMEMORY_SIZE
• INMEMORY_FORCE= { DEFAULT | OFF }
• INMEMORY_CLAUSE_DEFAULT= [INMEMORY] [NO INMEMORY] [compression-clauses][priority-clauses]
• INMEMORY_QUERY={ENABLE | DISABLE}
• INMEMORY_MAX_POPULATE_SERVERS
• OPTIMIZER_INMEMORY_AWARE
• INMEMORY TRICKLE REPOPULATE SERVERS PERCENT
INMEMORY_SIZE позволяет указать размер области памяти для колумнарных данных, по умолчанию равен нулю. Например, INMEMORY_MAX_POPULATE_SERVERS — это количество фоновых процессов, которые считывают данные с диска в кэш, по умолчанию он равен количеству процессоров, которые «видит» Oracle Database. Еще один интересный параметр — OPTIMIZER_INMEMORY_AWARE, при его помощи можно указать, видит или не видит оптимизатор In-Memory-кэш. Например, это нужно, если вы нужно оценить накладные расходы. Подробности предлагаю вам найти в документации.
Oracle Database In-Memory больше всего подходит для приложений, в которых много запросов, сканирующих много строк с такими фильтрами как: «=», «<», «>», «IN». Технология очень эффективна, когда приложение запрашивает всего лишь несколько столбцов из большого числа (типично для SAP), соединяет большие факторные таблицы с таблицами измерений, с фильтрами по таблицам измерений. Соответственно, это такие приложения, как хранилища данных, информационно-аналитические системы, включая OLTP-приложения. Кстати, есть полезный дополнительный продукт — Oracle Database In-Memory Advisor, он помогает оценить применимость технологии Oracle Database In-Memory к конкретным приложениям. Oracle Database In-Memory Adviser анализирует статистику работы базы данных и выдает рекомендации по размеру памяти, по типу таблиц, которые необходимо кэшировать в In-Memory-кэше.
Важно понимать, что в отличие от конкурентов, Oracle Database In-Memory не требует переписывания приложений. Нет ограничений на SQL, не нужна миграция данных, технология готова для облака.
Не надо путать Oracle Database In-Memory и Oracle TimesTen In-Memory Database, это разные технологии. TimesTen — это встраиваемая база данных для приложений, она предназначена для чистых, а не смешанных OLTP-систем, для тех случаев, когда приложение должно работать в режиме реального времени, и время ответа должно составлять буквально секунды, а не секунды и не миллисекунды. TimesTen полностью загружает все данные в оперативную память. В отличие от нее Oracle Database In-Memory является расширением классической СУБД Oracle, находится внутри ее ядра и расширяет ее возможности с точки зрения ускорения аналитических запросов за счет колоночного представления.
Мне кажется, я написал достаточно, чтобы пробудить в вас неудержимое желание прочитать документацию к Oracle Database In-Memory. Но тут дело такое — технология новая, экспертизы по ней мало, один я на все ваши вопросы ответить не смогу. Поэтому, друзья, записывайтесь на наши онлайн-тренинги. Мы их будем прямо здесь будем обязательно анонсировать. А у меня пока все.
