Всем привет, меня зовут Евгений Демиденко. Последние несколько лет я занимаюсь разработкой автоматизированной системы тестирования игр в Pixonic. Сегодня я хотел поделиться нашим опытом разработки, поддержки и использования такой системы на проекте War Robots.
Для начала разберемся, что же все-таки мы автоматизируем этой системой.
В первую очередь, это регрессионные UI-тестирования, тестирование core-геймплея и автоматизация бенчмарков. Все три системы в целом дают возможность снизить нагрузку на QA-отдел перед релизами, быть более уверенными в масштабных и глубоких рефакторингах и постоянно поддерживать общую оценку производительности приложения, а также отдельных его частей. Еще одним пунктом хочется отметить автоматизацию рутины, например ― проверку каких-либо гипотез.

Приведу немного цифр. Сейчас для War Robots написано более 600 UI-тестов и порядка 100 core-тестов. Только на этом проекте мы произвели около миллиона запусков наших тестовых сценариев, каждый из которых занимал порядка 80 секунд. Если бы эти сценарии мы проверяли вручную, то потратили бы минимум по пять минут на каждый. Кроме того, мы запустили более 700 тысяч бенчмарков.
Из платформ мы используем Android и iOS ― всего 12 устройств в парке. Разработкой системы и ее поддержкой занимаются два программиста, а написанием и анализом тестов ― один QA-инженер.


Что касается стека ПО, в своей базе мы используем NUnit, но не для unit-тестов, а для интеграционных и системных тестов. Для core-геймплея и build verification тестов применяем встроенное решение от Unity ― Unity Test Tools. Для написания и анализа отчетов после этих тестов используется Allure Test Report от Яндекса, а также TeamCity ― в качестве системы непрерывной интеграции для билда приложения, деплоя сервера и запуска тестов. Для хранения наших артефактов мы используем Nexus Repository и базу данных PostgreSQL.

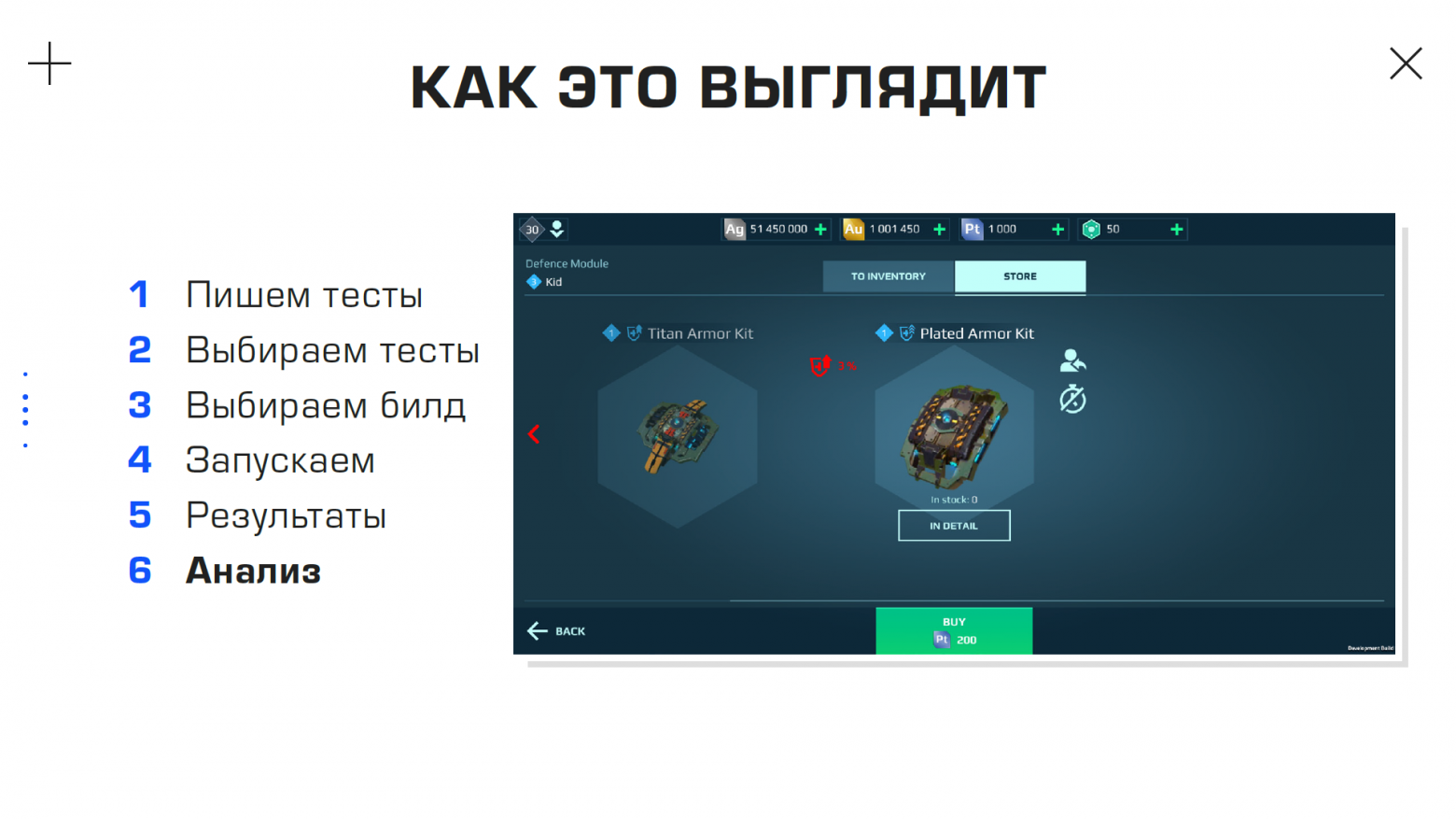
Допустим, мы хотим написать простой тест, который в окне параметров игры проверит иконку включения и выключения звука.
Итак, мы написали тест и закоммитили его в определенную ветку в нашем репозитории с тестами. Выбрали тесты, которые мы хотим запустить, выбрали билд для запуска, а может и конкретный коммит, на котором соберется билд. Теперь запускаем тест, ждем некоторое время и получаем результат.


В данном случае было запущено 575 тестов, из них прошли успешно 97%. На выполнение всех тестов у нас ушло примерно три часа. Для сравнения ― на те же тесты, если выполнять их вручную, ушло бы не менее 50 часов непрерывной работы.
Так что же случилось с теми 3% тестов, которые не прошли?
Открываем конкретный тест и видим сообщение о том, что во время матчинга скриншотов произошла ошибка.

Затем открываем скриншот, который в тот момент был на девайсе, и видим, что красными пикселями отмечены зоны, которые не соответствуют оригиналу. Для сравнения приведем и его.

Естественно, после этого QA-инженер должен либо завести баг о том, что поведение билда не соответствует геймдизайн-документу, либо обновить оригинал скриншотов, потому что геймдизайн-документ изменился, и теперь этих элементов в игре не будет.
Некоторое время назад на проекте War Robots нам потребовалось сделать один небольшой рефакторинг. Он заключался в переписывании некоторых кусков кода стреляющего оружия ― в частности, пулеметов.
Во время тестирования мы обнаружили один интересный нюанс: скорострельность пулеметов напрямую зависела от FPS. Такой баг было бы нереально обнаружить во время ручного тестирования: во-первых, из-за особенностей сетевого расчета урона на проекте, во-вторых, из-за того, что приложение War Robots довольно-таки хорошо оптимизировано и на тот момент запускалось на всех девайсах примерно с одинаковым FPS ― 30 кадров/с. Конечно, были небольшие отклонения, но их было недостаточно, чтобы во время ручного тестирования заметить увеличение урона от стреляющего оружия. Тогда-то мы и задались вопросом: как много таких багов у нас еще есть и сколько может появиться во время рефакторингов?
Так как мы хотели не снижать количество тестов, а наоборот ― его наращивать, поскольку у нас намечались большие обновления и увеличение количества контента, мы не хотели расти горизонтально и увеличивать количество сотрудников QA-отдела. Вместо этого мы планировали вертикальный рост с сокращением рутины у текущих сотрудников и облегчением их жизни во время интеграционного тестирования нового контента.

Когда мы только начинали заниматься автоматизацией тестов, в первую очередь мы обратили внимание на встроенное на тот момент в Unity решение ― Unity Integration Test Tools. Написали несколько UI и core-тестов на нем, закончили начатый ранее рефакторинг и на том удовлетворились, поскольку решение уже работало, а значит ― наши предположения были правильными, и нужно было двигаться дальше. Единственный минус этого решения, но очень существенный для нас, ― тесты нельзя было запускать на мобильных девайсах.
Таким образом мы пришли к идее использования фреймворка Appium. Это форк другого известного фреймворка для тестирования ― Selenium. Он, в свою очередь, является, пожалуй, самым известным фреймворком для тестирования веб-приложений, основная концепция которого заключается в работе с UI-элементами, получении их координат и организации ввода в эти UI-элементы. Appium перенял эту концепцию и в дополнение к существующим в Selenium веб-драйверам добавил еще iOS- и Android-драйвера: они используют нативные фреймворки тестирования для каждой из этих платформ.
Так как в Unity нет никаких нативных UI-элементов, а есть только один UI-элемент, в котором рендерится картинка, пришлось добавить дополнительно к Appium UnityDriver, который позволяет работать с иерархией сцены, получать объекты сцены и много чего еще.
В этот момент на проекте уже появился QA-инженер, дело встало на поток, начало ощутимо расти количество тестовых сценариев, которые мы постепенно автоматизировали. Мы начали их запускать на девайсах, и в целом наша работа уже выглядела примерно так, как мы и хотели.
В дальнейшем начали появляться, помимо тестов UI, еще core-тесты и другие инструменты на базе нашей системы, в результате чего мы уперлись в производительность и качество работы на различных девайсах, добавили поддержку еще нескольких девайсов, параллельные тесты, а также отказались от Appium в пользу собственного фреймворка.

Единственной проблемой, которая у нас осталась ― и остается до сих пор, ― была иерархия UI. Потому что, если в сцене меняется иерархия из-за рефакторинга UI или работ по сцене, это нужно поддерживать в тестах.
После очередных нововведений и переработок архитектура всей системы стала выглядеть следующим образом.

Мы берем билд War Robots, берем наши тесты, которые лежат в отдельном репозитории, добавляем туда кое-какие параметры для запуска, которые позволяют сконфигурировать в каждом конкретном случае запуск тестов, и отправляем все это на TeamCity-агент на удаленном ПК. TeamCity-агент запускает наши тесты, передает им билд «Роботов» и параметры запуска, после чего тесты начинают работать и самостоятельно «общаться» с девайсами, которые проводом подключены к TeamCity-агенту: ставить на них билды запускать их, выполнять определенные сценарии, удалять билды, перезапускать приложение и так далее.
Так как тесты и само приложение запускаются на физически разных устройствах ― на мобильном телефоне и Mac mini, ― нам необходимо было реализовать коммуникацию между нашим фреймворком, War Robots API и Unity API. Мы добавили в приложение небольшой UDP-сервер, который получает команды от фреймворка и посредством обработчиков общается с API приложения и Unity.

Основная задача нашего фреймворка ― организация работы тестов: правильные подготовка, завершение и управление девайсами. В частности ― распараллеливание для ускорения работы, правильный выбор девайсов и скриншотов, коммуникация с билдом. После завершения работы тестов наш фреймворк должен сохранить все сгенерированные артефакты и сформировать отчет.
Отдельно хочу обратить внимание на выбор девайсов для тестирования.
Немаловажное внимание стоит обратить на хабы. Если вы захотите запускать бенчмарки на своих устройствах ― особенно если это устройства на Android, ― они будут сильно разряжаться. Хабы должны обеспечивать необходимую мощность для используемых устройств. Есть и еще одна очень тонкая особенность: некоторые хабы имеют активное питание, и это питание выключается после скачков напряжения, после чего включается только физическим нажатием на кнопку. У нас есть такие хабы, и это очень неудобно.
Если вы хотите запускать регрессионное UI-тестирование и тестировать логику на девайсах, не берите разные устройства. Возьмите одни и те же девайсы ― лучше самые производительные, какие вы можете себе позволить, потому что таким образом вы сэкономите время на тормозах устройств, удобстве работы с ними, и поведение приложения на всех девайсах будет одинаковым.
Отдельно стоит вопрос об использовании облачных ферм. Мы их пока не используем, хотя проводили по ним исследования: какие существуют, сколько стоят и как на них запускать наши тесты, ― но пока нашего парка девайсов in-house нам хватает для того, чтобы покрыть свои запросы.
После завершения тестов мы генерируем allure-отчет, в который попадают все артефакты, которые были созданы во время работы нашего теста.
Основная «рабочая лошадка» по анализу произошедшего и выявлению причин падения во время теста ― это логи. В первую очередь мы их собираем с нашего фреймворка, который говорит нам о состоянии сценария и что происходило в этом сценарии. Логи мы делим на системный (более подробный) и лог для QA (более компактный и удобный для анализа). Также собираем системные логи с девайсов (например, logcat) и логи из Unity-приложения.
Во время падения тестов мы также делаем скриншот, чтобы понять, что происходило на девайсах в момент падения, записываем видео, чтобы понять, что происходило перед падением, и по максимуму стараемся собрать информацию о состоянии девайса, такую как пинги наших серверов и информацию по ifconfig для понимания, есть ли IP у девайса. Вы удивитесь, однако если вы запустите вручную 50 раз приложение, с ним будет все в порядке, ― но если вы запустите его 50 тысяч раз в автоматическом режиме, то обнаружите, что интернет на девайсе может пропасть, и во время теста будет не понятно, было ли соединение до и после падения.
Также мы собираем список процессов, заряд аккумулятора, температуру и вообще все, до чего можем дотянуться.

Некоторое время назад наш QA-инженер предложил, помимо снятия скриншотов при падении, в определенных местах тестов сравнивать эти скриншоты с шаблонами, которые лежат в нашем хранилище. Таким образом он предлагал сэкономить время на количестве прогонов тестов и уменьшить размер кодовой базы. То есть, одним тестом мы могли бы проверить и логику, и визуальную часть. С точки зрения концепции unit-тестирования это не очень правильно, потому что в одном тесте мы не должны проверять несколько гипотез. Но это осознанный шаг: мы знаем, как все это правильно анализировать, так что рискнули добавить подобную функциональность.
В первую очередь мы думали над тем, чтобы добавить библиотеки для матчинга скриншотов, но поняли, что использовать изображения с разным разрешением не очень-то надежно, поэтому остановились на девайсах с одинаковым разрешением и просто попиксельно сравниваем изображения с неким порогом.

Очень интересный эффект от использования матчинга скриншотов заключается в том, что, если какой-то процесс сложно автоматизировать, мы его автоматизируем, насколько это получается, а дальше просто отсматриваем скриншоты вручную. Именно так мы поступили с тестовой локализацией. Нам поступил запрос на тестирование локализации наших приложений, так что мы начали просматривать библиотеки, которые позволяют распознавать текст ― но поняли, что это довольно-таки ненадежно, и в итоге написали несколько сценариев, которые «ходят» по разным экранам и вызывают разные pop-up’ы, и в этот момент создаются скриншоты. Перед запуском такого сценария мы меняем локаль на девайсе, запускаем сценарий, снимаем скриншоты, меняем локаль снова и запускаем сценарий снова. Таким образом, все тесты прогоняются ночью, чтобы с утра QA-инженер мог отсмотреть 500 скриншотов и сразу проанализировать, есть ли где-то проблемы с локализацией. Да, скриншоты еще надо отсмотреть, но это намного быстрее, чем вручную проходить по всем экранам на девайсее.
Иногда скриншотов и логов бывает недостаточно: на девайсах начинает происходить что-то странное, но, поскольку они находятся удаленно, нельзя сходить и оценить, что же там стряслось. Тем более, иногда бывает неясно, что происходило буквально за несколько мгновений до того, как тест упал. Поэтому мы добавили запись видео с девайса, которая стартует вместе с началом теста и сохраняется только в случае падения. При помощи таких видео очень удобно отслеживать падения и зависания приложения.

Некоторое время назад от отдела QA-тестирования нам поступил запрос на разработку инструмента для сбора метрик во время ручных плейтестов.
Для чего это нужно?
Это нужно для того, чтобы QA-инженеры после ручного плейтеста могли дополнительно проанализировать поведение FPS и потребление памяти в приложении, попутно посмотрев скриншоты и видео, отражающие, что происходило на этом девайсе.
Разработанная нами система работала следующим образом. QA-инженер запускал на девайсе War Robots, включал запись playbench-сессии ― нашего аналога gamebench, ― играл плейтест, затем нажимал «завершить playbench-сессию», сгенерированный отчет сохранялся в репозитории, после чего инженер с данными этого плейтеста мог дойти до своей рабочей машины и посмотреть отчет: какие были просадки по FPS, какое потребление памяти, что происходило на девайсе.
Еще мы автоматизировали запуск бенчмарков на проекте War Robots, по сути просто обернув уже существовавшие бенчмарки в автоматический запуск. Результат работы бенчмарков ― как правило, одна цифра. В нашем случае обычно это средний FPS за бенчмарк. Помимо автоматического запуска мы решили добавить еще playbench-сессию и таким образом получили не просто конкретную цифру, как отработал бенчмарк, но и информацию, благодаря которой мы можем проанализировать, что в этот момент происходило с бенчмарком.
Отдельно стоит упомянуть тест pull request’ов. На сей раз это было больше в помощь команде клиентской разработки, а не QA-инженерам. Мы запускаем так называемый build verification test на каждый pull request. Можно запускать их как на девайсах, так и в редакторе Unity, чтобы ускорить работу проверки логики. Также мы запускаем набор core-тестов в отдельных ветках, где происходит своего рода редизайн некоторых элементов либо рефакторинг кода.

Напоследок хочется остановиться на некоторых интересных кейсах, с которыми нам доводилось встречаться в последние несколько лет.
Один из самых интересных кейсов, который появился у нас совсем недавно, ― бенчмарки во время боев с ботами.
Для нового проекта Pixonic Dino Squad была разработала система, в которой QA-инженер мог поиграть плейтест вместе с ботами, чтобы не ждать своих коллег, а проверить самому какую-либо гипотезу. Наш QA-инженер, в свою очередь, попросил добавить возможность не просто играть с ботами, но и чтобы боты могли играть друг с другом. Таким образом мы просто запускаем приложение, и в этот момент бот начинает играть с другими ботами. При этом все взаимодействие сетевое, с настоящими серверами, просто вместо игроков играет компьютер. Все это обернуто бенчмарками и playbench-сессией с триггерами на ночные запуски. Таким образом, ночью у нас запускается несколько боев ботов с ботам, в это время пишутся FPS и потребление памяти, снимаются скриншоты и записываются видео. С утра QA-инженер приходит и может просмотреть, какие плейтесты проводились и что на них происходило.
Также стоит отметить проверку утечки текстур. Это своего рода подвид анализа использования памяти ― но здесь мы в основном проверяем использование, например, гаражных текстур в бою. Соответственно, в бою не должно быть атласов, которые используются в гараже, и, когда мы выходим из боя, в памяти не должно оставаться текстур, которые использовались в бою.
Интересным сайд-эффектом нашей системы является то, что практически с самого начала ее использования мы отслеживали время загрузки приложения. В случае War Robots это время несильно, но непрерывно растет, потому что добавляется новый контент, и качество этого контента улучшается, ― но этот параметр мы можем держать под контролем и быть всегда в курсе, какова его величина.
В конце я бы хотел обратить внимание на те проблемы, которые у нас существуют, о которых мы знаем и которые хотели бы решить в первую очередь.

Первая и самая больная ― это изменения UI. Так как мы работаем с «черным ящиком», мы не встраиваем ничего в приложение War Robots, кроме нашего сервера, ― то есть, мы тестируем все точно так же, как тестировал бы QA-инженер. Но каким-то образом нам нужно обращаться к элементам на сцене. И мы их находим по абсолютному пути. Таким образом, когда на сцене что-то меняется, особенно на высоком уровне иерархии, нам приходится эти изменения поддерживать в большом количестве тестов. К сожалению, сделать с этим сейчас мы ничего не можем. Конечно, есть некоторые варианты решения, но они приносят свои дополнительные проблемы.
Вторая большая проблема ― инфраструктурная. Как я уже говорил, если вы 50 раз запустите ваше приложение руками, вы не заметите большую часть тех проблем, что выявятся, если вы запустите ваше приложение 50 тысяч раз. Те проблемы, которые в ручном режиме решаются легко ― например, переустановкой билдов или перезапуском интернета, ― окажутся настоящей болью при автоматизации, потому что все эти проблемы необходимо правильно обработать, вывести сообщение об ошибке и предусмотреть, что они вообще могут возникнуть. В частности, нам необходимо определять, почему тесты упали: из-за неправильной ли работы логики или какой-либо инфраструктурной проблемы, или по любой другой причине. Очень много проблем с low-end девайсами: на них не ставятся билды, отваливается интернет, девайсы зависают, крашатся, не включаются, быстро разряжаются и так далее.
Также очень хотелось бы взаимодействовать с нативными UI, но пока такой возможности у нас нет. Мы знаем, как это сделать, но наличие других запросов по функциональности не позволяет нам до этого дойти.
И лично мое пожелание ― соответствовать стандартам, которые существуют в индустрии, но это также есть в планах на будущее, может даже на этот год.
Для начала разберемся, что же все-таки мы автоматизируем этой системой.
В первую очередь, это регрессионные UI-тестирования, тестирование core-геймплея и автоматизация бенчмарков. Все три системы в целом дают возможность снизить нагрузку на QA-отдел перед релизами, быть более уверенными в масштабных и глубоких рефакторингах и постоянно поддерживать общую оценку производительности приложения, а также отдельных его частей. Еще одним пунктом хочется отметить автоматизацию рутины, например ― проверку каких-либо гипотез.
Приведу немного цифр. Сейчас для War Robots написано более 600 UI-тестов и порядка 100 core-тестов. Только на этом проекте мы произвели около миллиона запусков наших тестовых сценариев, каждый из которых занимал порядка 80 секунд. Если бы эти сценарии мы проверяли вручную, то потратили бы минимум по пять минут на каждый. Кроме того, мы запустили более 700 тысяч бенчмарков.
Из платформ мы используем Android и iOS ― всего 12 устройств в парке. Разработкой системы и ее поддержкой занимаются два программиста, а написанием и анализом тестов ― один QA-инженер.
Что касается стека ПО, в своей базе мы используем NUnit, но не для unit-тестов, а для интеграционных и системных тестов. Для core-геймплея и build verification тестов применяем встроенное решение от Unity ― Unity Test Tools. Для написания и анализа отчетов после этих тестов используется Allure Test Report от Яндекса, а также TeamCity ― в качестве системы непрерывной интеграции для билда приложения, деплоя сервера и запуска тестов. Для хранения наших артефактов мы используем Nexus Repository и базу данных PostgreSQL.
Как устроены создание, анализ и запуск тестов
Допустим, мы хотим написать простой тест, который в окне параметров игры проверит иконку включения и выключения звука.
Итак, мы написали тест и закоммитили его в определенную ветку в нашем репозитории с тестами. Выбрали тесты, которые мы хотим запустить, выбрали билд для запуска, а может и конкретный коммит, на котором соберется билд. Теперь запускаем тест, ждем некоторое время и получаем результат.
В данном случае было запущено 575 тестов, из них прошли успешно 97%. На выполнение всех тестов у нас ушло примерно три часа. Для сравнения ― на те же тесты, если выполнять их вручную, ушло бы не менее 50 часов непрерывной работы.
Так что же случилось с теми 3% тестов, которые не прошли?
Открываем конкретный тест и видим сообщение о том, что во время матчинга скриншотов произошла ошибка.
Затем открываем скриншот, который в тот момент был на девайсе, и видим, что красными пикселями отмечены зоны, которые не соответствуют оригиналу. Для сравнения приведем и его.
Естественно, после этого QA-инженер должен либо завести баг о том, что поведение билда не соответствует геймдизайн-документу, либо обновить оригинал скриншотов, потому что геймдизайн-документ изменился, и теперь этих элементов в игре не будет.
Выглядит круто. А зачем все это нужно?
Некоторое время назад на проекте War Robots нам потребовалось сделать один небольшой рефакторинг. Он заключался в переписывании некоторых кусков кода стреляющего оружия ― в частности, пулеметов.
Во время тестирования мы обнаружили один интересный нюанс: скорострельность пулеметов напрямую зависела от FPS. Такой баг было бы нереально обнаружить во время ручного тестирования: во-первых, из-за особенностей сетевого расчета урона на проекте, во-вторых, из-за того, что приложение War Robots довольно-таки хорошо оптимизировано и на тот момент запускалось на всех девайсах примерно с одинаковым FPS ― 30 кадров/с. Конечно, были небольшие отклонения, но их было недостаточно, чтобы во время ручного тестирования заметить увеличение урона от стреляющего оружия. Тогда-то мы и задались вопросом: как много таких багов у нас еще есть и сколько может появиться во время рефакторингов?
Так как мы хотели не снижать количество тестов, а наоборот ― его наращивать, поскольку у нас намечались большие обновления и увеличение количества контента, мы не хотели расти горизонтально и увеличивать количество сотрудников QA-отдела. Вместо этого мы планировали вертикальный рост с сокращением рутины у текущих сотрудников и облегчением их жизни во время интеграционного тестирования нового контента.
Какие средства мы используем
Когда мы только начинали заниматься автоматизацией тестов, в первую очередь мы обратили внимание на встроенное на тот момент в Unity решение ― Unity Integration Test Tools. Написали несколько UI и core-тестов на нем, закончили начатый ранее рефакторинг и на том удовлетворились, поскольку решение уже работало, а значит ― наши предположения были правильными, и нужно было двигаться дальше. Единственный минус этого решения, но очень существенный для нас, ― тесты нельзя было запускать на мобильных девайсах.
Таким образом мы пришли к идее использования фреймворка Appium. Это форк другого известного фреймворка для тестирования ― Selenium. Он, в свою очередь, является, пожалуй, самым известным фреймворком для тестирования веб-приложений, основная концепция которого заключается в работе с UI-элементами, получении их координат и организации ввода в эти UI-элементы. Appium перенял эту концепцию и в дополнение к существующим в Selenium веб-драйверам добавил еще iOS- и Android-драйвера: они используют нативные фреймворки тестирования для каждой из этих платформ.
Так как в Unity нет никаких нативных UI-элементов, а есть только один UI-элемент, в котором рендерится картинка, пришлось добавить дополнительно к Appium UnityDriver, который позволяет работать с иерархией сцены, получать объекты сцены и много чего еще.
В этот момент на проекте уже появился QA-инженер, дело встало на поток, начало ощутимо расти количество тестовых сценариев, которые мы постепенно автоматизировали. Мы начали их запускать на девайсах, и в целом наша работа уже выглядела примерно так, как мы и хотели.
В дальнейшем начали появляться, помимо тестов UI, еще core-тесты и другие инструменты на базе нашей системы, в результате чего мы уперлись в производительность и качество работы на различных девайсах, добавили поддержку еще нескольких девайсов, параллельные тесты, а также отказались от Appium в пользу собственного фреймворка.
Единственной проблемой, которая у нас осталась ― и остается до сих пор, ― была иерархия UI. Потому что, если в сцене меняется иерархия из-за рефакторинга UI или работ по сцене, это нужно поддерживать в тестах.
После очередных нововведений и переработок архитектура всей системы стала выглядеть следующим образом.
Мы берем билд War Robots, берем наши тесты, которые лежат в отдельном репозитории, добавляем туда кое-какие параметры для запуска, которые позволяют сконфигурировать в каждом конкретном случае запуск тестов, и отправляем все это на TeamCity-агент на удаленном ПК. TeamCity-агент запускает наши тесты, передает им билд «Роботов» и параметры запуска, после чего тесты начинают работать и самостоятельно «общаться» с девайсами, которые проводом подключены к TeamCity-агенту: ставить на них билды запускать их, выполнять определенные сценарии, удалять билды, перезапускать приложение и так далее.
Так как тесты и само приложение запускаются на физически разных устройствах ― на мобильном телефоне и Mac mini, ― нам необходимо было реализовать коммуникацию между нашим фреймворком, War Robots API и Unity API. Мы добавили в приложение небольшой UDP-сервер, который получает команды от фреймворка и посредством обработчиков общается с API приложения и Unity.
Основная задача нашего фреймворка ― организация работы тестов: правильные подготовка, завершение и управление девайсами. В частности ― распараллеливание для ускорения работы, правильный выбор девайсов и скриншотов, коммуникация с билдом. После завершения работы тестов наш фреймворк должен сохранить все сгенерированные артефакты и сформировать отчет.
Советы по выбору девайсов
Отдельно хочу обратить внимание на выбор девайсов для тестирования.
Немаловажное внимание стоит обратить на хабы. Если вы захотите запускать бенчмарки на своих устройствах ― особенно если это устройства на Android, ― они будут сильно разряжаться. Хабы должны обеспечивать необходимую мощность для используемых устройств. Есть и еще одна очень тонкая особенность: некоторые хабы имеют активное питание, и это питание выключается после скачков напряжения, после чего включается только физическим нажатием на кнопку. У нас есть такие хабы, и это очень неудобно.
Если вы хотите запускать регрессионное UI-тестирование и тестировать логику на девайсах, не берите разные устройства. Возьмите одни и те же девайсы ― лучше самые производительные, какие вы можете себе позволить, потому что таким образом вы сэкономите время на тормозах устройств, удобстве работы с ними, и поведение приложения на всех девайсах будет одинаковым.
Отдельно стоит вопрос об использовании облачных ферм. Мы их пока не используем, хотя проводили по ним исследования: какие существуют, сколько стоят и как на них запускать наши тесты, ― но пока нашего парка девайсов in-house нам хватает для того, чтобы покрыть свои запросы.
Отчетность по тестам
После завершения тестов мы генерируем allure-отчет, в который попадают все артефакты, которые были созданы во время работы нашего теста.
Основная «рабочая лошадка» по анализу произошедшего и выявлению причин падения во время теста ― это логи. В первую очередь мы их собираем с нашего фреймворка, который говорит нам о состоянии сценария и что происходило в этом сценарии. Логи мы делим на системный (более подробный) и лог для QA (более компактный и удобный для анализа). Также собираем системные логи с девайсов (например, logcat) и логи из Unity-приложения.
Во время падения тестов мы также делаем скриншот, чтобы понять, что происходило на девайсах в момент падения, записываем видео, чтобы понять, что происходило перед падением, и по максимуму стараемся собрать информацию о состоянии девайса, такую как пинги наших серверов и информацию по ifconfig для понимания, есть ли IP у девайса. Вы удивитесь, однако если вы запустите вручную 50 раз приложение, с ним будет все в порядке, ― но если вы запустите его 50 тысяч раз в автоматическом режиме, то обнаружите, что интернет на девайсе может пропасть, и во время теста будет не понятно, было ли соединение до и после падения.
Также мы собираем список процессов, заряд аккумулятора, температуру и вообще все, до чего можем дотянуться.
Чем хороши скриншоты и видео
Некоторое время назад наш QA-инженер предложил, помимо снятия скриншотов при падении, в определенных местах тестов сравнивать эти скриншоты с шаблонами, которые лежат в нашем хранилище. Таким образом он предлагал сэкономить время на количестве прогонов тестов и уменьшить размер кодовой базы. То есть, одним тестом мы могли бы проверить и логику, и визуальную часть. С точки зрения концепции unit-тестирования это не очень правильно, потому что в одном тесте мы не должны проверять несколько гипотез. Но это осознанный шаг: мы знаем, как все это правильно анализировать, так что рискнули добавить подобную функциональность.
В первую очередь мы думали над тем, чтобы добавить библиотеки для матчинга скриншотов, но поняли, что использовать изображения с разным разрешением не очень-то надежно, поэтому остановились на девайсах с одинаковым разрешением и просто попиксельно сравниваем изображения с неким порогом.
Очень интересный эффект от использования матчинга скриншотов заключается в том, что, если какой-то процесс сложно автоматизировать, мы его автоматизируем, насколько это получается, а дальше просто отсматриваем скриншоты вручную. Именно так мы поступили с тестовой локализацией. Нам поступил запрос на тестирование локализации наших приложений, так что мы начали просматривать библиотеки, которые позволяют распознавать текст ― но поняли, что это довольно-таки ненадежно, и в итоге написали несколько сценариев, которые «ходят» по разным экранам и вызывают разные pop-up’ы, и в этот момент создаются скриншоты. Перед запуском такого сценария мы меняем локаль на девайсе, запускаем сценарий, снимаем скриншоты, меняем локаль снова и запускаем сценарий снова. Таким образом, все тесты прогоняются ночью, чтобы с утра QA-инженер мог отсмотреть 500 скриншотов и сразу проанализировать, есть ли где-то проблемы с локализацией. Да, скриншоты еще надо отсмотреть, но это намного быстрее, чем вручную проходить по всем экранам на девайсее.
Иногда скриншотов и логов бывает недостаточно: на девайсах начинает происходить что-то странное, но, поскольку они находятся удаленно, нельзя сходить и оценить, что же там стряслось. Тем более, иногда бывает неясно, что происходило буквально за несколько мгновений до того, как тест упал. Поэтому мы добавили запись видео с девайса, которая стартует вместе с началом теста и сохраняется только в случае падения. При помощи таких видео очень удобно отслеживать падения и зависания приложения.
Что еще умеет наша система
Некоторое время назад от отдела QA-тестирования нам поступил запрос на разработку инструмента для сбора метрик во время ручных плейтестов.
Для чего это нужно?
Это нужно для того, чтобы QA-инженеры после ручного плейтеста могли дополнительно проанализировать поведение FPS и потребление памяти в приложении, попутно посмотрев скриншоты и видео, отражающие, что происходило на этом девайсе.
Разработанная нами система работала следующим образом. QA-инженер запускал на девайсе War Robots, включал запись playbench-сессии ― нашего аналога gamebench, ― играл плейтест, затем нажимал «завершить playbench-сессию», сгенерированный отчет сохранялся в репозитории, после чего инженер с данными этого плейтеста мог дойти до своей рабочей машины и посмотреть отчет: какие были просадки по FPS, какое потребление памяти, что происходило на девайсе.
Еще мы автоматизировали запуск бенчмарков на проекте War Robots, по сути просто обернув уже существовавшие бенчмарки в автоматический запуск. Результат работы бенчмарков ― как правило, одна цифра. В нашем случае обычно это средний FPS за бенчмарк. Помимо автоматического запуска мы решили добавить еще playbench-сессию и таким образом получили не просто конкретную цифру, как отработал бенчмарк, но и информацию, благодаря которой мы можем проанализировать, что в этот момент происходило с бенчмарком.
Отдельно стоит упомянуть тест pull request’ов. На сей раз это было больше в помощь команде клиентской разработки, а не QA-инженерам. Мы запускаем так называемый build verification test на каждый pull request. Можно запускать их как на девайсах, так и в редакторе Unity, чтобы ускорить работу проверки логики. Также мы запускаем набор core-тестов в отдельных ветках, где происходит своего рода редизайн некоторых элементов либо рефакторинг кода.
И другие полезные фичи
Напоследок хочется остановиться на некоторых интересных кейсах, с которыми нам доводилось встречаться в последние несколько лет.
Один из самых интересных кейсов, который появился у нас совсем недавно, ― бенчмарки во время боев с ботами.
Для нового проекта Pixonic Dino Squad была разработала система, в которой QA-инженер мог поиграть плейтест вместе с ботами, чтобы не ждать своих коллег, а проверить самому какую-либо гипотезу. Наш QA-инженер, в свою очередь, попросил добавить возможность не просто играть с ботами, но и чтобы боты могли играть друг с другом. Таким образом мы просто запускаем приложение, и в этот момент бот начинает играть с другими ботами. При этом все взаимодействие сетевое, с настоящими серверами, просто вместо игроков играет компьютер. Все это обернуто бенчмарками и playbench-сессией с триггерами на ночные запуски. Таким образом, ночью у нас запускается несколько боев ботов с ботам, в это время пишутся FPS и потребление памяти, снимаются скриншоты и записываются видео. С утра QA-инженер приходит и может просмотреть, какие плейтесты проводились и что на них происходило.
Также стоит отметить проверку утечки текстур. Это своего рода подвид анализа использования памяти ― но здесь мы в основном проверяем использование, например, гаражных текстур в бою. Соответственно, в бою не должно быть атласов, которые используются в гараже, и, когда мы выходим из боя, в памяти не должно оставаться текстур, которые использовались в бою.
Интересным сайд-эффектом нашей системы является то, что практически с самого начала ее использования мы отслеживали время загрузки приложения. В случае War Robots это время несильно, но непрерывно растет, потому что добавляется новый контент, и качество этого контента улучшается, ― но этот параметр мы можем держать под контролем и быть всегда в курсе, какова его величина.
Вместо заключения
В конце я бы хотел обратить внимание на те проблемы, которые у нас существуют, о которых мы знаем и которые хотели бы решить в первую очередь.
Первая и самая больная ― это изменения UI. Так как мы работаем с «черным ящиком», мы не встраиваем ничего в приложение War Robots, кроме нашего сервера, ― то есть, мы тестируем все точно так же, как тестировал бы QA-инженер. Но каким-то образом нам нужно обращаться к элементам на сцене. И мы их находим по абсолютному пути. Таким образом, когда на сцене что-то меняется, особенно на высоком уровне иерархии, нам приходится эти изменения поддерживать в большом количестве тестов. К сожалению, сделать с этим сейчас мы ничего не можем. Конечно, есть некоторые варианты решения, но они приносят свои дополнительные проблемы.
Вторая большая проблема ― инфраструктурная. Как я уже говорил, если вы 50 раз запустите ваше приложение руками, вы не заметите большую часть тех проблем, что выявятся, если вы запустите ваше приложение 50 тысяч раз. Те проблемы, которые в ручном режиме решаются легко ― например, переустановкой билдов или перезапуском интернета, ― окажутся настоящей болью при автоматизации, потому что все эти проблемы необходимо правильно обработать, вывести сообщение об ошибке и предусмотреть, что они вообще могут возникнуть. В частности, нам необходимо определять, почему тесты упали: из-за неправильной ли работы логики или какой-либо инфраструктурной проблемы, или по любой другой причине. Очень много проблем с low-end девайсами: на них не ставятся билды, отваливается интернет, девайсы зависают, крашатся, не включаются, быстро разряжаются и так далее.
Также очень хотелось бы взаимодействовать с нативными UI, но пока такой возможности у нас нет. Мы знаем, как это сделать, но наличие других запросов по функциональности не позволяет нам до этого дойти.
И лично мое пожелание ― соответствовать стандартам, которые существуют в индустрии, но это также есть в планах на будущее, может даже на этот год.
