Привет Хабр! В предыдущих частях цикла (раз, два) мы рассматривали тайловую архитектуру мобильных GPU, а также классифицировали различные семейства GPU, представленные у пользователей. В этой части мы рассмотрим приемы, которые помогут писать быстрые шейдеры для мобильных GPU.

В мобильной экосистеме оптимальный код — всегда хорошо. Ведь даже в случае достижения требуемой частоты формирования кадров более оптимальный код позволяет переводить CPU и GPU на пониженные частоты, за счет чего снижается расход заряда и увеличивается среднее время сессий. Это, в свою очередь, положительно сказывается на доходе от игр со встроенной монетизацией.
Чтобы лучше ориентироваться в оптимизационных подходах, применяемых при написании шейдеров, полезно знать об основных категориях шейдерных инструкций. Первая категория — арифметические инструкции. Эти инструкции, как правило, работают с регистрами GPU и выполняются предсказуемое количество тактов. Обычно это 1 такт. При этом в современных конвейерах может выполняться по нескольку арифметических инструкций за 1 такт. Вторая категория — текстурные инструкции. Они осуществляют текстурную выборку — чтение из текстур с применением определенной фильтрации. Время выполнения этих инструкций значительно дольше, чем арифметических, и зависит от наличия запрашиваемых текселей в текстурном кэше. Современные архитектуры маскируют длительное время выполнения текстурных инструкций за счет переключения на другие шейдерные потоки и выполнения их арифметических инструкций. Рекомендуемое соотношение количества арифметических инструкций к текстурным может быть 10 к 1 и выше.
Кроме арифметических и текстурных инструкций, ещё выделяют Load & Store инструкции. К ним относятся, например, инструкции записи вершинных атрибутов в вершинном шейдере и чтение интерполированных значений этих атрибутов во фрагментном шейдере. Время выполнения таких инструкций больше, чем у арифметических, но меньше, чем у текстурных.
В типичной архитектуре GPU имеется общий банк регистров (register file), используемый множеством параллельно выполняемых потоков. Каждый такой поток рассчитывает один вертекс или пиксель. От количества регистров, требуемых для выполнения шейдера, зависит максимальное количество одновременно выполняемых потоков. Например, на архитектуре Mali Midgard имеется следующая зависимость:
Дальнейшее увеличение потребности в регистрах приводит к записи промежуточных значений во временную память (так называемый register spilling). Иногда компилятор Mali может предпочесть небольшой register spilling переходу в менее выгодную конфигурацию потоков.
Оценить количество используемых регистров для Mali можно при помощи Mali Offline Compiler:
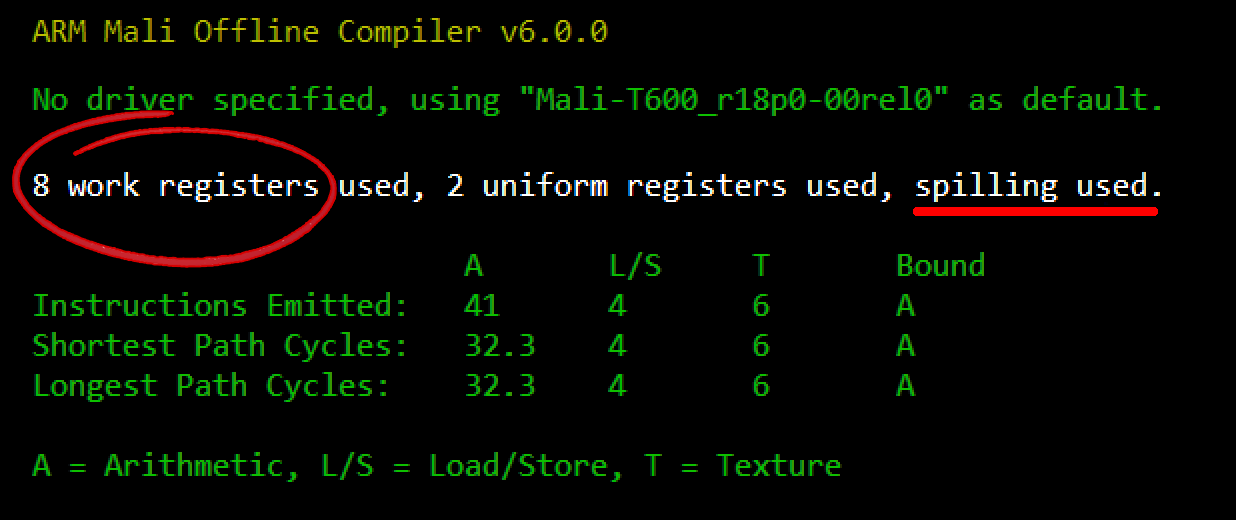
В OpenGL ES предусмотрена возможность задавать точность величин при помощи квалификаторов lowp, mediump и highp.
Применение пониженной точности позволяет задействовать меньше регистров и добиться повышенной плотности вычислений за такт. Как было рассказано в предыдущей статье, применение точности lowp сегодня нежелательно. Она поддерживается на аппаратном уровне только в устаревающих моделях PowerVR, а на всех современных GPU вместо lowp фактически используется mediump. Такая ситуация напрасно усложняет процессы QA, если в шейдерах используется lowp.
Есть ли смысл применять mediump? В самых актуальных рекомендациях по оптимизации для мобильных GPU по-прежнему предлагается по возможности использовать mediump во фрагментных шейдерах. Остановимся подробнее на этой точности.
Как мы показали выше, в GLSL ES точность можно задать отдельным переменным — uniform-ам и varying-ам. Кроме того, есть возможность задать точность по умолчанию для всех величин определенного типа. Например, используя такую строчку в начале шейдера, можно задать точность mediump для всех float:
С такой строкой в начале фрагментного шейдера можно получить заметное ускорение на большинстве мобильных видеокарт (при условии, что в шейдере большое количество арифметических инструкций).
Приведем пример выдачи утилиты Mali Offline Compiler для архитектуры Midgard для шейдера, содержащего большое количество арифметики.
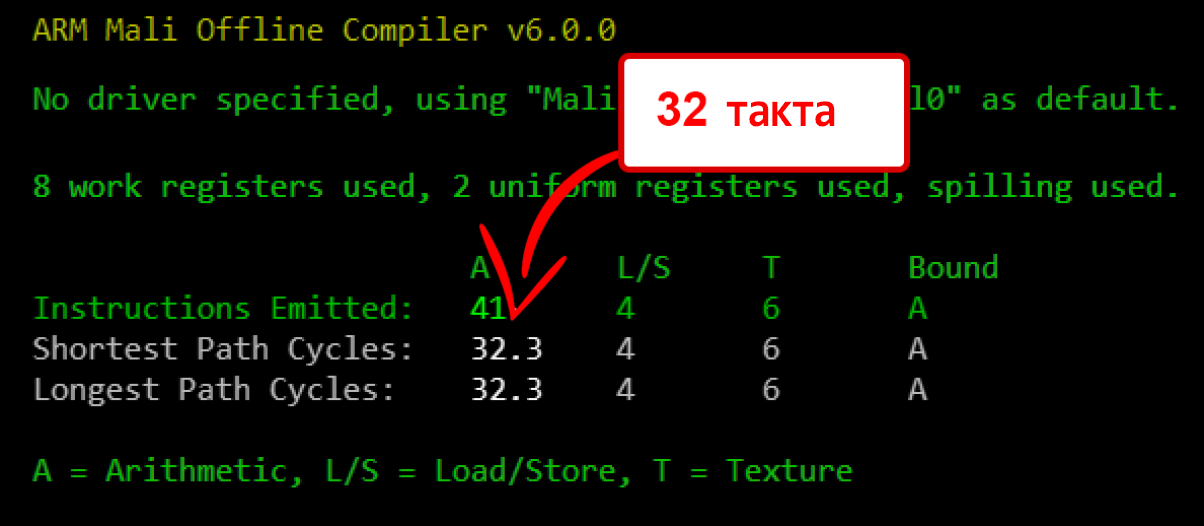
С точностью highp (precision highp float;) получаем 32 такта на выполнение шейдера:
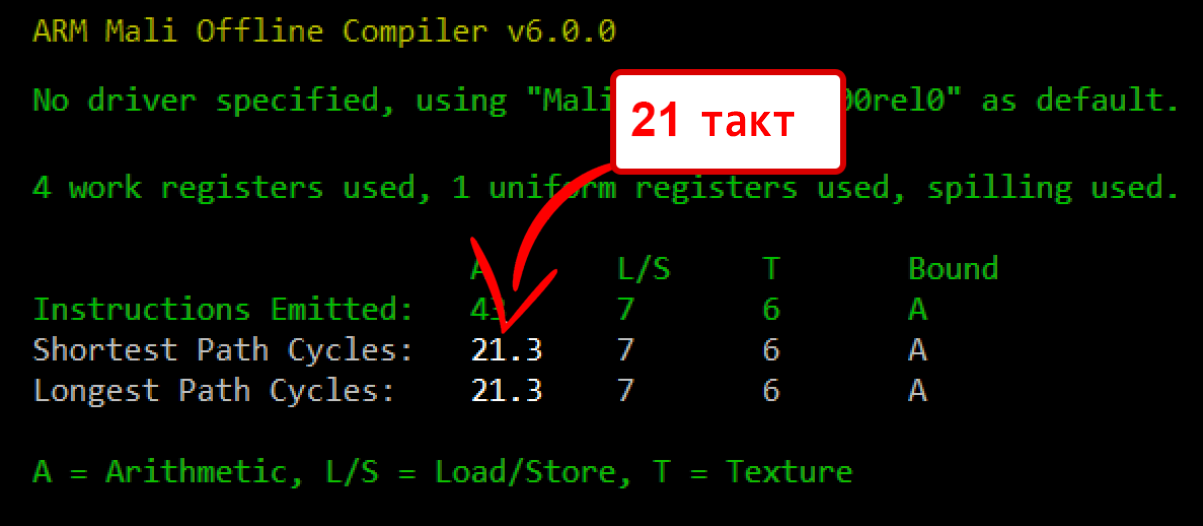
С точностью mediump — 21 такт:
Отметим, что, несмотря на немного возросшее количество инструкций, оценочное время выполнения шейдера сократилось. Это связано с тем, что за 1 такт с точностью mediump выполняется больше инструкций, чем с highp.
Похожую картину можно наблюдать в PVRShaderEditor от Imagination для видеокарт PowerVR Rogue.
С «precision highp float;» получаем:

Используются умножения с полной точностью, выполняемые по 2 за такт.
Если же начинать такой же шейдер строчкой «precision mediump float», можно увидеть, что операции были упакованы в 16-битные суммы произведений (SOP). Это операции вида a * b + c * d. Архитектура PowerVR Rogue позволяет выполнять 2 такие операции за такт, что дает большую плотность операций по сравнению с точностью highp:

Вместо 20 тактов с точностью highp, с mediump получили 15 тактов.
Смешанное использование точностей
Установка точности highp по умолчанию и выборочное понижение точности до mediump работает плохо. Лучший результат дает установка mediump по умолчанию и выборочное повышение точности там, где это необходимо. Приведем некоторые часто встречающиеся случаи, где требуется высокая точность:
Напомним, что имеется достаточно распространенное на сегодня семейство GPU Mali Utgard (Mali-400 и др.), где во фрагментных шейдерах точность highp не поддерживается. В видеокартах этого семейства во фрагментных шейдерах доступна только fp24 точность на varying. Если highp varying текстурную координату использовать без модификаций, то артефактов mediump при текстурировании из больших текстур можно избежать. Если же с такими текстурными координатами произвести какие-то вычисления, то артефакты появятся.
Типичный сценарий рендера на GPU предполагает следующее соотношение сущностей:
Количество объектов, которому соответствует количество вызовов отрисовки и установки шейдерных констант, значительно меньше количества вершин, а количество вершин — значительно меньше количества пикселей.
Исходя из этого, можно сформулировать такие принципы:
К линейным преобразованиям относятся вычисления вида «с0 * Att0 + с1 * Att1 + … + сn», где cn — константы, а Attn — атрибуты вершин. Линейно интерполированные результаты таких вычислений равны вычислениям над интерполированными значениями атрибутов. Т.е. условно:
Эта особенность и позволяет переносить такие вычисления в вершинный шейдер. За счет того, что количество инвокаций вершинного шейдера меньше, чем фрагментного, получаем ускорение. Отметим, что преобразование вида Att0 * Att1 уже не является линейным.
Пример:
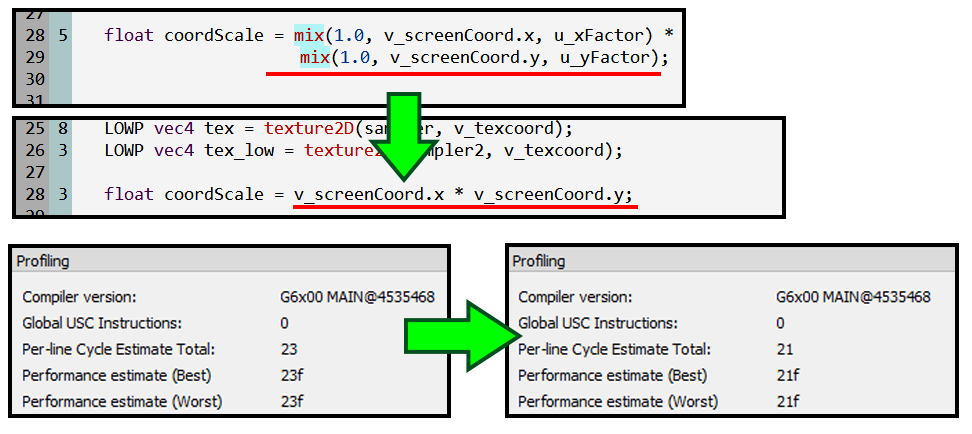
Здесь функция mix является линейным преобразованием varying v_screenCoord, поэтому её можно вызвать в вершинном шейдере, передав во фрагментный шейдер подготовленные значения в v_screenCoord.xy. Во фрагментном шейдере остается сделать только преобразование, нелинейно зависящее от двух интерполируемых величин: v_screenCoord.x * v_screenCoord.y
Если при переносе вычислений в вершинный шейдер появляются новые varying, важно отслеживать баланс между экономией арифметических инструкций и появлением новых Load & Store операций, загружающих дополнительные интерполируемые величины. Load & Store операции в целом более накладные, чем арифметические инструкции.
Как было показано в предыдущей статье цикла, почти на трети мобильных устройств установлены видеокарты, использующие векторный конвейер инструкций. При этом эти видеокарты можно отнести к средним и слабым по производительности, а значит, приведение кода к «векторному виду» в целом целесообразно.
Векторизация производится путем упаковки разнородных скалярных величин в векторы и совмещения нескольких скалярных операций в одну операцию с вектором.
Пример:
Можно переписать так:
В данном случае не стоит полностью полагаться на оптимизатор, поскольку качество последнего варьируется от производителя к производителю и от драйвера к драйверу. Ведь в OpenGL ES компиляция GLSL полностью делегирована драйверу видеокарты.
Приведем пример тривиального шейдера в скалярном и векторном исполнении и результаты его профилирования для видеокарт Mali архитектуры Midgard.
«Скалярный» вариант:
Результаты Mali Offline Compiler:
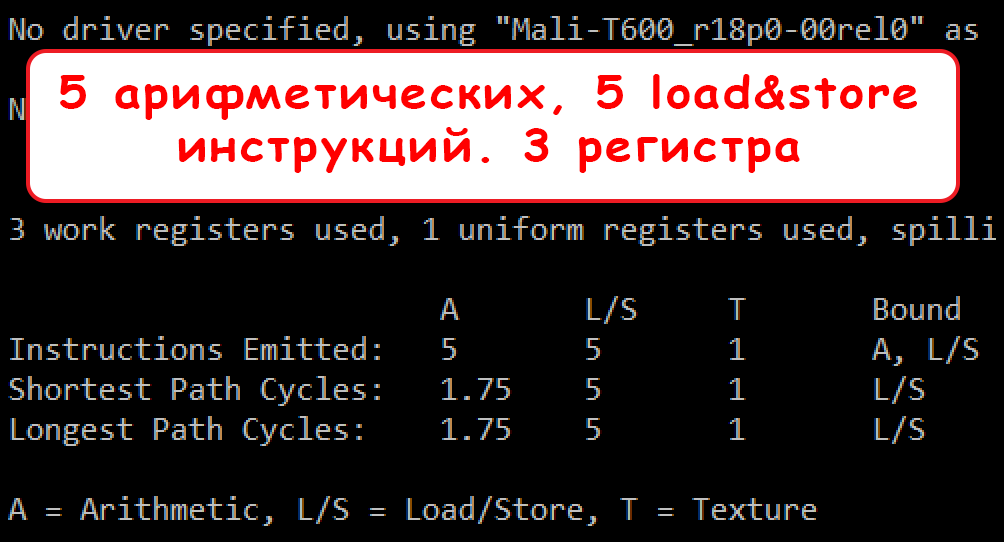
«Векторный» вариант:
Результаты:
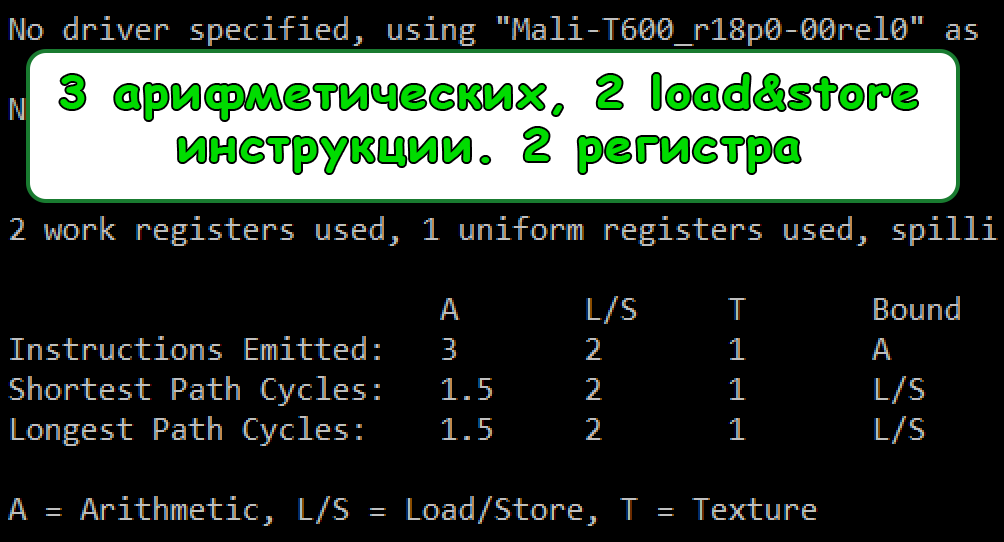
В векторном исполнении получилось на 2 арифметические и 3 загрузочные инструкции меньше, а также задействовано 2 регистра вместо 3-х. При этом сократилось количество требуемых тактов на выполнение шейдера.
Архитектура конвейеров шейдерных ядер рассчитана на выполнение большого количества линейных преобразований. Типичные операции в компьютерной графике, такие как трансформация или рассчет освещения, в основном состоят из подобных операций. Из-за такой фокусировки для многих трансцендентных функций не делается «железной» реализации на чипе и вычисление значения может происходить при помощи полиномиальных приближений. Вычисление таких функций становится дорогостоящим. Приведем пример на PowerVR Rogue, для которого имеется официальный дизассемблер в PVRShaderEditor. Вычисление синуса компилируется в блок из нескольких инструкций, требующих 5 тактов на выполнение. В приведенном примере вычисление аргумента sin находится за пределами выделенной области. Примечательно, что в блоке находятся инструкции ветвления.
Намного хуже обстоят дела с обратными тригонометрическими функциями. Пример вычисления арксинуса:
Осторожность стоит соблюдать со всеми трансцендентными функциями. Даже те из них, которые обычно реализованы в железе, например, натуральный логарифм (log), часто требуют выделенный такт на свое выполнение и не пакуются вместе с другими инструкциями.
Здесь пойдет речь об использовании конструкций вроде if (){} или цикла for (;;) {} в шейдерах. Консервативный подход к ветвлению в шейдерах предполагает полный отказ от него. В былые времена ветвление считалось серой зоной и приводило к глюкам и багам на определенных комбинациях драйвер/видеокарта. В достаточно свежих рекомендациях от ARM предлагается, к примеру, вместо использования конструкций вида if(uniform) создавать несколько предкомпилированных экземпляров шейдера с разными #define.
Совершенно другим явлением является динамическое ветвление, результат которого зависит от неконстантных вычислений в шейдере. Если такое ветвление сделано в целях оптимизации, важно помнить, что на старых архитектурах GPU для получения оптимизационного эффекта во фрагментном шейдере важна «локальная однородность» результатов этого ветвления. Т.е. поток управления должен передаваться в одну и ту же ветку у всех пикселей, расположенных в определенной области изображения. В противном случае для этой области могут быть выполнены обе ветки для всех пикселей, и результат будет хуже.
На этом пока что всё, спасибо всем за внимание :)
В мобильной экосистеме оптимальный код — всегда хорошо. Ведь даже в случае достижения требуемой частоты формирования кадров более оптимальный код позволяет переводить CPU и GPU на пониженные частоты, за счет чего снижается расход заряда и увеличивается среднее время сессий. Это, в свою очередь, положительно сказывается на доходе от игр со встроенной монетизацией.
Шейдерные инструкции
Чтобы лучше ориентироваться в оптимизационных подходах, применяемых при написании шейдеров, полезно знать об основных категориях шейдерных инструкций. Первая категория — арифметические инструкции. Эти инструкции, как правило, работают с регистрами GPU и выполняются предсказуемое количество тактов. Обычно это 1 такт. При этом в современных конвейерах может выполняться по нескольку арифметических инструкций за 1 такт. Вторая категория — текстурные инструкции. Они осуществляют текстурную выборку — чтение из текстур с применением определенной фильтрации. Время выполнения этих инструкций значительно дольше, чем арифметических, и зависит от наличия запрашиваемых текселей в текстурном кэше. Современные архитектуры маскируют длительное время выполнения текстурных инструкций за счет переключения на другие шейдерные потоки и выполнения их арифметических инструкций. Рекомендуемое соотношение количества арифметических инструкций к текстурным может быть 10 к 1 и выше.
Кроме арифметических и текстурных инструкций, ещё выделяют Load & Store инструкции. К ним относятся, например, инструкции записи вершинных атрибутов в вершинном шейдере и чтение интерполированных значений этих атрибутов во фрагментном шейдере. Время выполнения таких инструкций больше, чем у арифметических, но меньше, чем у текстурных.
Учет количества используемых регистров
В типичной архитектуре GPU имеется общий банк регистров (register file), используемый множеством параллельно выполняемых потоков. Каждый такой поток рассчитывает один вертекс или пиксель. От количества регистров, требуемых для выполнения шейдера, зависит максимальное количество одновременно выполняемых потоков. Например, на архитектуре Mali Midgard имеется следующая зависимость:
| 0-4 регистра | максимальное количество потоков |
| 5-8 регистров | половина максимального количества |
| 8-16 регистров | четверть максимального количества |
Дальнейшее увеличение потребности в регистрах приводит к записи промежуточных значений во временную память (так называемый register spilling). Иногда компилятор Mali может предпочесть небольшой register spilling переходу в менее выгодную конфигурацию потоков.
Оценить количество используемых регистров для Mali можно при помощи Mali Offline Compiler:
Точность mediump
В OpenGL ES предусмотрена возможность задавать точность величин при помощи квалификаторов lowp, mediump и highp.
| uniform lowp sampler2D u_texture0; varying mediump v_pos; … mediump float temporary; |
Применение пониженной точности позволяет задействовать меньше регистров и добиться повышенной плотности вычислений за такт. Как было рассказано в предыдущей статье, применение точности lowp сегодня нежелательно. Она поддерживается на аппаратном уровне только в устаревающих моделях PowerVR, а на всех современных GPU вместо lowp фактически используется mediump. Такая ситуация напрасно усложняет процессы QA, если в шейдерах используется lowp.
Есть ли смысл применять mediump? В самых актуальных рекомендациях по оптимизации для мобильных GPU по-прежнему предлагается по возможности использовать mediump во фрагментных шейдерах. Остановимся подробнее на этой точности.
Как мы показали выше, в GLSL ES точность можно задать отдельным переменным — uniform-ам и varying-ам. Кроме того, есть возможность задать точность по умолчанию для всех величин определенного типа. Например, используя такую строчку в начале шейдера, можно задать точность mediump для всех float:
| precision mediump float; |
С такой строкой в начале фрагментного шейдера можно получить заметное ускорение на большинстве мобильных видеокарт (при условии, что в шейдере большое количество арифметических инструкций).
Приведем пример выдачи утилиты Mali Offline Compiler для архитектуры Midgard для шейдера, содержащего большое количество арифметики.
С точностью highp (precision highp float;) получаем 32 такта на выполнение шейдера:
С точностью mediump — 21 такт:
Отметим, что, несмотря на немного возросшее количество инструкций, оценочное время выполнения шейдера сократилось. Это связано с тем, что за 1 такт с точностью mediump выполняется больше инструкций, чем с highp.
Похожую картину можно наблюдать в PVRShaderEditor от Imagination для видеокарт PowerVR Rogue.
С «precision highp float;» получаем:
Используются умножения с полной точностью, выполняемые по 2 за такт.
Если же начинать такой же шейдер строчкой «precision mediump float», можно увидеть, что операции были упакованы в 16-битные суммы произведений (SOP). Это операции вида a * b + c * d. Архитектура PowerVR Rogue позволяет выполнять 2 такие операции за такт, что дает большую плотность операций по сравнению с точностью highp:
Вместо 20 тактов с точностью highp, с mediump получили 15 тактов.
Смешанное использование точностей
Установка точности highp по умолчанию и выборочное понижение точности до mediump работает плохо. Лучший результат дает установка mediump по умолчанию и выборочное повышение точности там, где это необходимо. Приведем некоторые часто встречающиеся случаи, где требуется высокая точность:
- Текстурирование большими текстурами или текстурирование с повторением (GL_TEXTURE_WRAP_S/T = GL_REPEAT). Точности mediump текстурных координат хватает на 1024 пикселя. В случае использования GL_REPEAT это утверждение справедливо для текстурных координат, начинающихся с нуля.
- Параметр времени для анимации. Минимально возможные инкременты времени, передаваемого как mediump, быстро увеличиваются с ростом его значения. Типичный сценарий — через несколько минут после начала анимации, где у времени точность mediump, анимация становится «дерганой». Решить эту проблему можно зацикливанием передаваемого времени, если анимация основана на периодических функциях.
- Попиксельное освещение в 3D с использованием позиций источника света и освещаемой точки. По возможности все вычисления с большими величинами нужно делать на полной точности в вершинном шейдере, передавая во фрагментный только нормированные векторы с пониженной точностью.
Напомним, что имеется достаточно распространенное на сегодня семейство GPU Mali Utgard (Mali-400 и др.), где во фрагментных шейдерах точность highp не поддерживается. В видеокартах этого семейства во фрагментных шейдерах доступна только fp24 точность на varying. Если highp varying текстурную координату использовать без модификаций, то артефактов mediump при текстурировании из больших текстур можно избежать. Если же с такими текстурными координатами произвести какие-то вычисления, то артефакты появятся.
Перемещение вычислений выше по pipeline
Типичный сценарий рендера на GPU предполагает следующее соотношение сущностей:
| Кол-во объектов < Кол-во вершин < Кол-во пикселей |
Количество объектов, которому соответствует количество вызовов отрисовки и установки шейдерных констант, значительно меньше количества вершин, а количество вершин — значительно меньше количества пикселей.
Исходя из этого, можно сформулировать такие принципы:
- Если имеется вычисление в шейдере, которое зависит только от констант (uniform), т.е. его результат одинаков для всех вершин и пикселей, то его стоит производить в коде для CPU и устанавливать как готовую константу.
- Если имеется вычисление во фрагментном шейдере, которое является линейным преобразованием переданных из вершинного шейдера величин (varying), то его стоит производить в вершинном шейдере и передавать во фрагментный шейдер готовый результат в varying.
К линейным преобразованиям относятся вычисления вида «с0 * Att0 + с1 * Att1 + … + сn», где cn — константы, а Attn — атрибуты вершин. Линейно интерполированные результаты таких вычислений равны вычислениям над интерполированными значениями атрибутов. Т.е. условно:
| interp(c0 * Att0 + c1 * Att1 + … + cn) == c0 * interp(Att0) + c1 * interp(Att1) + … cn |
Эта особенность и позволяет переносить такие вычисления в вершинный шейдер. За счет того, что количество инвокаций вершинного шейдера меньше, чем фрагментного, получаем ускорение. Отметим, что преобразование вида Att0 * Att1 уже не является линейным.
Пример:
Здесь функция mix является линейным преобразованием varying v_screenCoord, поэтому её можно вызвать в вершинном шейдере, передав во фрагментный шейдер подготовленные значения в v_screenCoord.xy. Во фрагментном шейдере остается сделать только преобразование, нелинейно зависящее от двух интерполируемых величин: v_screenCoord.x * v_screenCoord.y
Если при переносе вычислений в вершинный шейдер появляются новые varying, важно отслеживать баланс между экономией арифметических инструкций и появлением новых Load & Store операций, загружающих дополнительные интерполируемые величины. Load & Store операции в целом более накладные, чем арифметические инструкции.
Векторизация вычислений
Как было показано в предыдущей статье цикла, почти на трети мобильных устройств установлены видеокарты, использующие векторный конвейер инструкций. При этом эти видеокарты можно отнести к средним и слабым по производительности, а значит, приведение кода к «векторному виду» в целом целесообразно.
Векторизация производится путем упаковки разнородных скалярных величин в векторы и совмещения нескольких скалярных операций в одну операцию с вектором.
Пример:
uniform float u_a;
uniform float u_b;
uniform float u_c;
uniform float u_d;
...
float val = 0.5 * u_a + 2.0*u_b - 3.0*u_c + 4.0 * u_d;
Можно переписать так:
uniform vec4 u_abcd;
...
float val = dot( u_abcd, vec4(0.5, 2.0, -3.0, 4.0));
В данном случае не стоит полностью полагаться на оптимизатор, поскольку качество последнего варьируется от производителя к производителю и от драйвера к драйверу. Ведь в OpenGL ES компиляция GLSL полностью делегирована драйверу видеокарты.
Приведем пример тривиального шейдера в скалярном и векторном исполнении и результаты его профилирования для видеокарт Mali архитектуры Midgard.
«Скалярный» вариант:
precision mediump float;
varying vec2 v_texc;
varying float v_coef0, v_coef1, v_coef2, v_coef3;
varying float v_coef4, v_coef5, v_coef6, v_coef7;
uniform float u_coef0, u_coef1, u_coef2, u_coef3;
uniform float u_coef4, u_coef5, u_coef6, u_coef7;
uniform sampler2D u_sampler;
void main()
{
vec4 col = texture2D(u_sampler, v_texc);
col.x = col.x * v_coef0 + u_coef0; col.y = col.y * v_coef1 + u_coef1;
col.z = col.z * v_coef2 + u_coef2; col.w = col.w * v_coef3 + u_coef3;
col.x = col.x * v_coef4 + u_coef4; col.y = col.y * v_coef5 + u_coef5;
col.z = col.z * v_coef6 + u_coef6; col.w = col.w * v_coef7 + u_coef7;
gl_FragColor = col;
}Результаты Mali Offline Compiler:
«Векторный» вариант:
precision mediump float;
varying vec2 v_texc;
varying vec4 v_coef0_3;
varying vec4 v_coef4_7;
uniform vec4 u_coef0_3;
uniform vec4 u_coef4_7;
uniform sampler2D u_sampler;
void main()
{
vec4 col = texture2D(u_sampler, v_texc);
col = col * v_coef0_3 + u_coef0_3;
col = col * v_coef4_7 + u_coef4_7;
gl_FragColor = col;
}Результаты:
В векторном исполнении получилось на 2 арифметические и 3 загрузочные инструкции меньше, а также задействовано 2 регистра вместо 3-х. При этом сократилось количество требуемых тактов на выполнение шейдера.
Трансцендентные функции в шейдерах
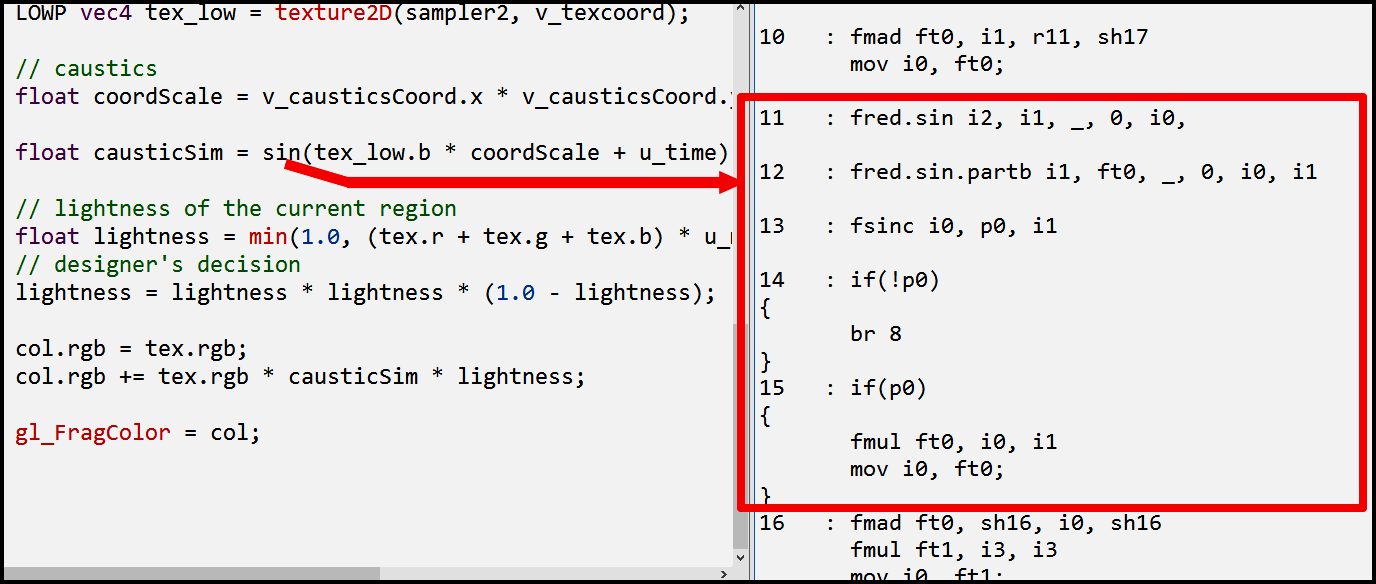
Архитектура конвейеров шейдерных ядер рассчитана на выполнение большого количества линейных преобразований. Типичные операции в компьютерной графике, такие как трансформация или рассчет освещения, в основном состоят из подобных операций. Из-за такой фокусировки для многих трансцендентных функций не делается «железной» реализации на чипе и вычисление значения может происходить при помощи полиномиальных приближений. Вычисление таких функций становится дорогостоящим. Приведем пример на PowerVR Rogue, для которого имеется официальный дизассемблер в PVRShaderEditor. Вычисление синуса компилируется в блок из нескольких инструкций, требующих 5 тактов на выполнение. В приведенном примере вычисление аргумента sin находится за пределами выделенной области. Примечательно, что в блоке находятся инструкции ветвления.
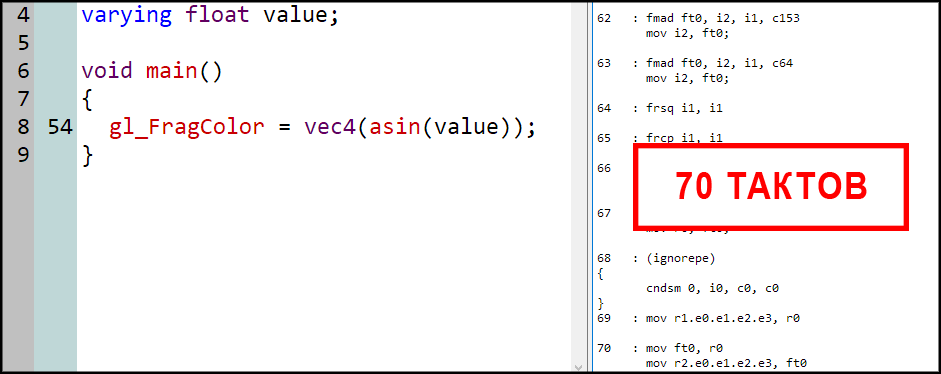
Намного хуже обстоят дела с обратными тригонометрическими функциями. Пример вычисления арксинуса:
Осторожность стоит соблюдать со всеми трансцендентными функциями. Даже те из них, которые обычно реализованы в железе, например, натуральный логарифм (log), часто требуют выделенный такт на свое выполнение и не пакуются вместе с другими инструкциями.
Грамотное использование ветвления
Здесь пойдет речь об использовании конструкций вроде if (){} или цикла for (;;) {} в шейдерах. Консервативный подход к ветвлению в шейдерах предполагает полный отказ от него. В былые времена ветвление считалось серой зоной и приводило к глюкам и багам на определенных комбинациях драйвер/видеокарта. В достаточно свежих рекомендациях от ARM предлагается, к примеру, вместо использования конструкций вида if(uniform) создавать несколько предкомпилированных экземпляров шейдера с разными #define.
Совершенно другим явлением является динамическое ветвление, результат которого зависит от неконстантных вычислений в шейдере. Если такое ветвление сделано в целях оптимизации, важно помнить, что на старых архитектурах GPU для получения оптимизационного эффекта во фрагментном шейдере важна «локальная однородность» результатов этого ветвления. Т.е. поток управления должен передаваться в одну и ту же ветку у всех пикселей, расположенных в определенной области изображения. В противном случае для этой области могут быть выполнены обе ветки для всех пикселей, и результат будет хуже.
На этом пока что всё, спасибо всем за внимание :)
Ссылки:
- developer.arm.com/tools-and-software/graphics-and-gaming/arm-mobile-studio/components/mali-offline-compiler
- static.docs.arm.com/101863/0700/mali_offline_compiler_user_guide_101863_0700_00_en.pdf
- www.imgtec.com/developers/powervr-sdk-tools/pvrshadereditor/
- developer.qualcomm.com/software/snapdragon-profiler
