
Машинное обучение занимается поиском скрытых закономерностей в данных. Растущий рост интереса к этой теме в ИТ-сообществе связан с исключительными результатами, получаемыми благодаря ему. Распознавание речи и отсканированных документов, поисковые машины — всё это создано с использованием машинного обучения. В этой статье я расскажу о текущем проекте нашей компании: как применить методы машинного обучения для увеличения производительности СУБД.
В первой части этой статьи разбирается существующий механизм планировщика PostgreSQL, во второй части рассказывается о возможностях его улучшения с применением машинного обучения.
Что такое план выполнения SQL-запроса?
Напомним, что SQL — декларативный язык. Это означает, что пользователь указывает только то, какие операции должны быть проделаны с данными. За выбор способа выполнения этих операций отвечает СУБД. Например, запрос
SELECT name FROM users WHERE age > 25;
можно выполнить двумя способами: прочесть все записи из таблицы users и проверить каждую из них на выполнение условия age > 25 или использовать индекс по полю age. Во втором случае мы не просматриваем лишние записи, зато тратим больше времени на обработку одной записи из-за операций с индексами.

Рассмотрим более сложный запрос
SELECT messages.text FROM users, messages WHERE users.id = messages.sender_id;
Этот JOIN можно выполнить уже тремя способами:
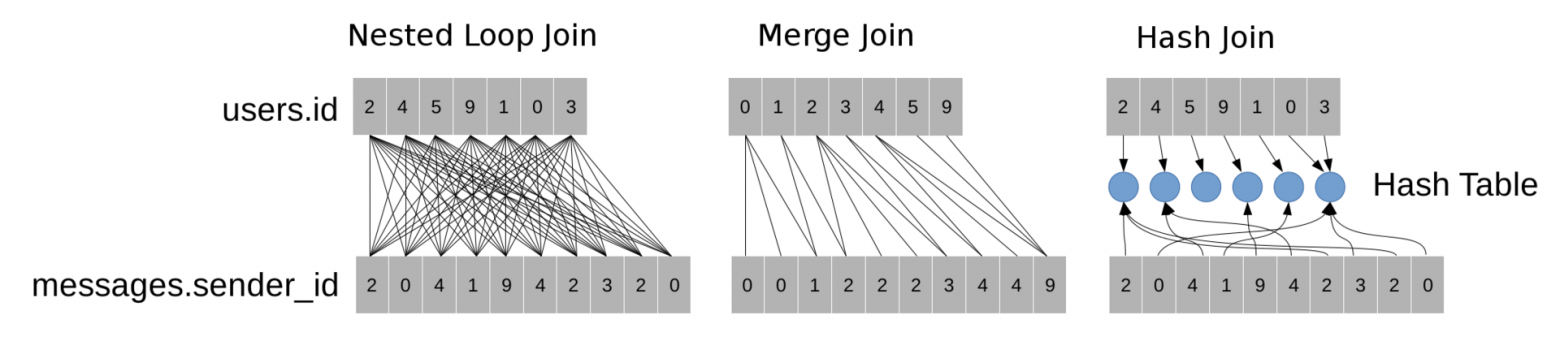
- Вложенный цикл (NestedLoopJoin) просматривает все возможные пары записей из двух таблиц и проверяет для каждой пары выполнение условия.
- Слияние (MergeJoin) отсортирует обе таблицы по полям id и sender_id соответственно, а затем использует метод двух указателей для поиска всех пар записей, удовлетворяющих условию. Этот метод аналогичен методу сортировки слиянием (MergeSort).
- Хеширование (HashJoin) строит хэш-таблицу по полю наименьшей таблицы (в нашем случае это поле users.id). Хеш-таблица позволяет для каждой записи из messages быстро найти запись, в которой users.id = messages.sender_id.
Если же в запросе требуется выполнить более одной операции Join, то можно также выполнять их в разном порядке, например, в запросе
SELECT u1.name, u2.name, m.text FROM users as u1, messages as m, users as u2
WHERE u1.id = m.sender_id AND u2.id = m.reciever_id;
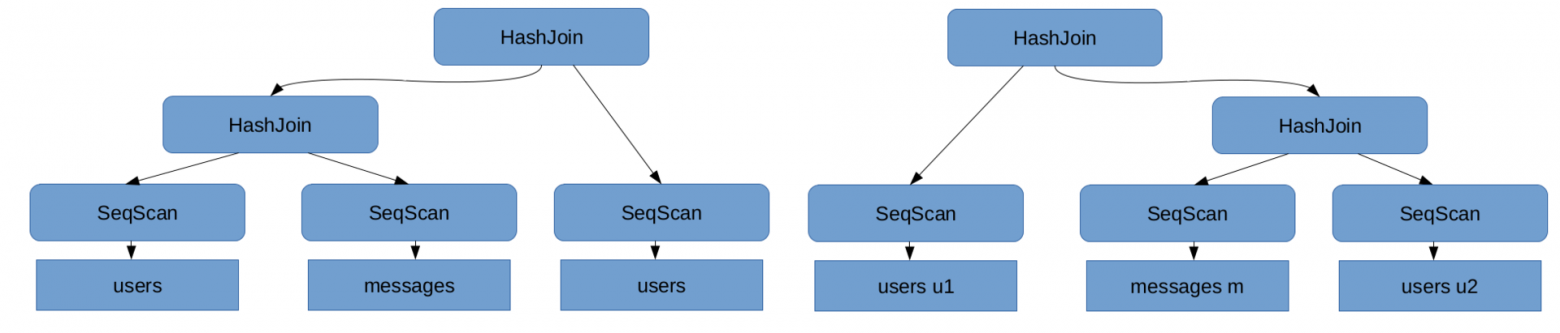
Дерево выполнения запроса называется планом выполнения запроса.
Посмотреть тот план, который выбирает СУБД для конкретного запроса, можно, используя команду
explain:EXPLAIN SELECT u1.name, u2.name, m.text FROM users as u1, messages as m, users as u2
WHERE u1.id = m.sender_id AND u2.id = m.reciever_id;
Для того, чтобы выполнить запрос и посмотреть выбранный для него план, можно использовать команду
explain analyse:EXPLAIN ANALYSE SELECT u1.name, u2.name, m.text FROM users as u1, messages as m, users as u2
WHERE u1.id = m.sender_id AND u2.id = m.reciever_id;
Время выполнения разных планов одного и того же запроса может отличаться на много порядков. Поэтому правильный выбор плана выполнения запроса оказывает серьезное влияние на производительность СУБД. Разберемся подробнее, как происходит выбор плана в PostgreSQL сейчас.
Как СУБД ищет оптимальный план выполнения запроса?
Можно разделить процесс поиска оптимального плана на две части.
Во-первых, нужно уметь оценивать стоимость любого плана — количество ресурсов, необходимых для его выполнения. В случае, когда на сервере не выполняются другие задачи и запросы, оцениваемое время выполнения запроса прямо пропорционально количеству потраченных на него ресурсов. Поэтому можно считать, что стоимость плана — это его время выполнения в некоторых условных единицах.
Во-вторых, требуется выбрать план с минимальной оценкой стоимости. Легко показать, что число планов растет экспоненциально с увеличением сложности запроса, поэтому нельзя просто перебрать все планы, оценить стоимость каждого и выбрать самый дешевый. Для поиска оптимального плана используются более сложные алгоритмы дискретной оптимизации: динамическое программирование по подмножествам для простых запросов и генетический алгоритм для сложных.
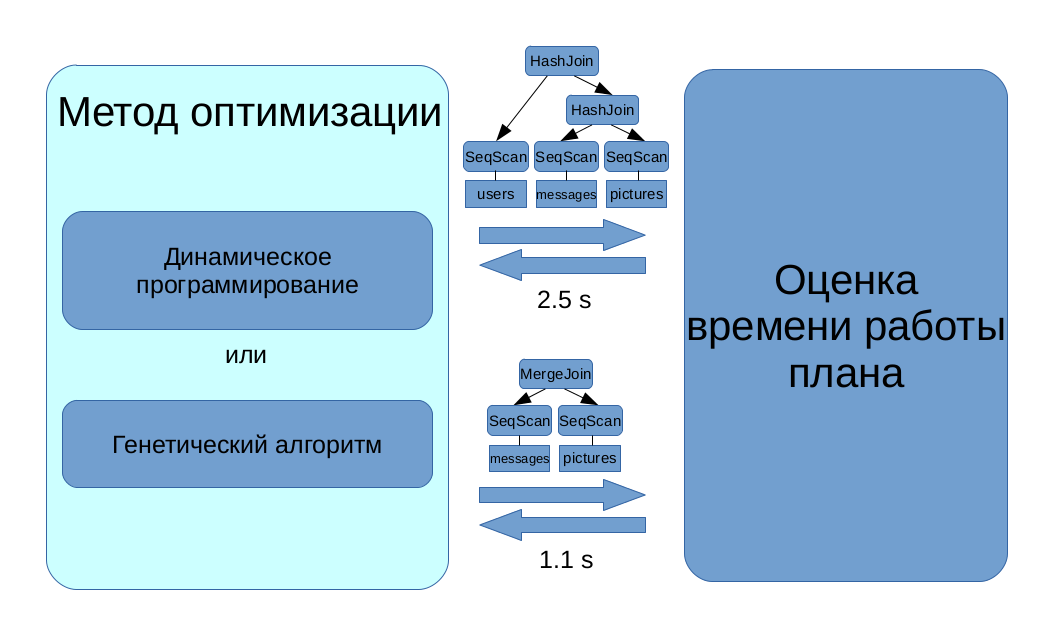
В нашем проекте мы сосредоточились на первой задаче: по данному нам плану надо предсказать его стоимость. Как это можно сделать, не запуская план на выполнение?
На самом деле
В PostgreSQL для плана предсказываются две стоимости: стоимость запуска (start-up cost) и общая стоимость (total cost). Стоимость запуска показывает, сколько ресурсов план потратит до того, как выдаст первую запись, а общая стоимость — сколько всего ресурсов потребуется плану для выполнения. Однако это не принципиально для настоящей статьи. В дальнейшем под стоимостью выполнения будем понимать общую стоимость.
Эта задача также разделяется на две подзадачи. Сначала для каждой вершины плана (plan node) предсказывается, сколько кортежей будет отобрано в ней. Затем на основе этой информации оценивается стоимость выполнения каждой вершины, и, соответственно, всего плана.
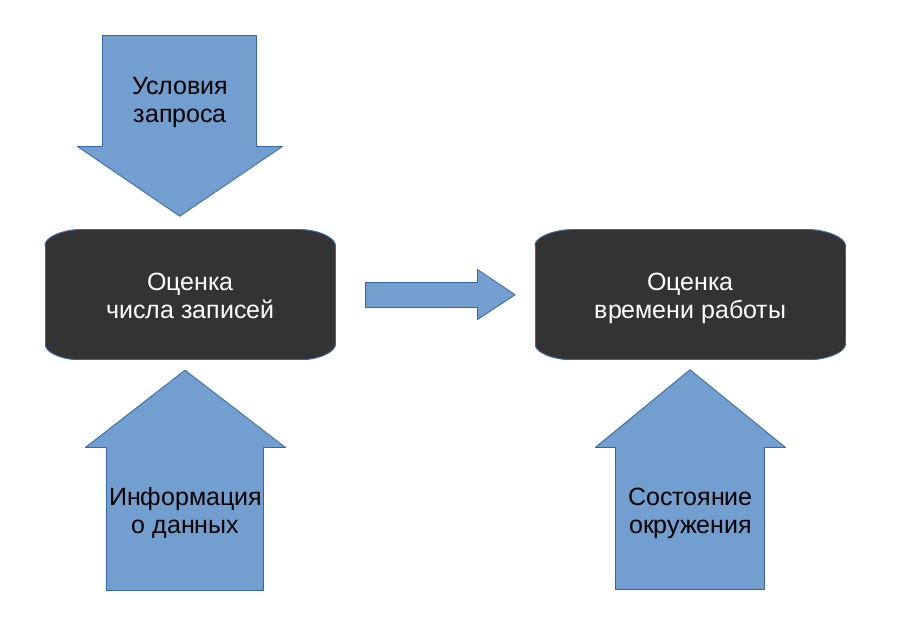
Мы провели небольшое исследование, чтобы установить, какая из двух подзадач в PostgreSQL решается хуже.
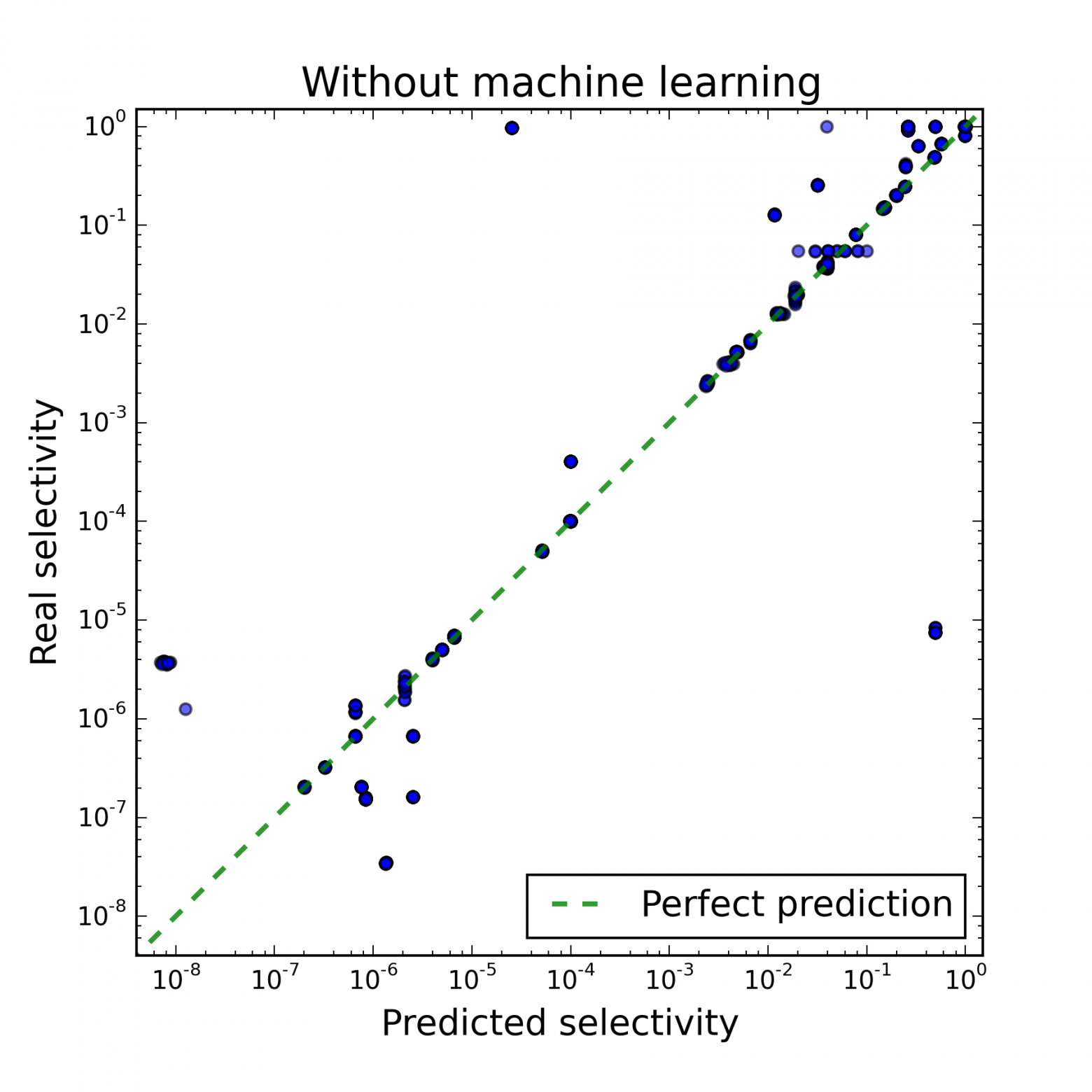
Каждая точка на рисунках ниже соответствует одной вершине плана. Для каждой вершины были предсказаны количество отобраных в ней кортежей и стоимость ее выполнения, а затем измерены реальное количество отобранных кортежей и время выполнения. На правой картинке отображены только те вершины, для которых количество кортежей предсказано правильно, поэтому по ней можно судить о качестве оценки стоимости.
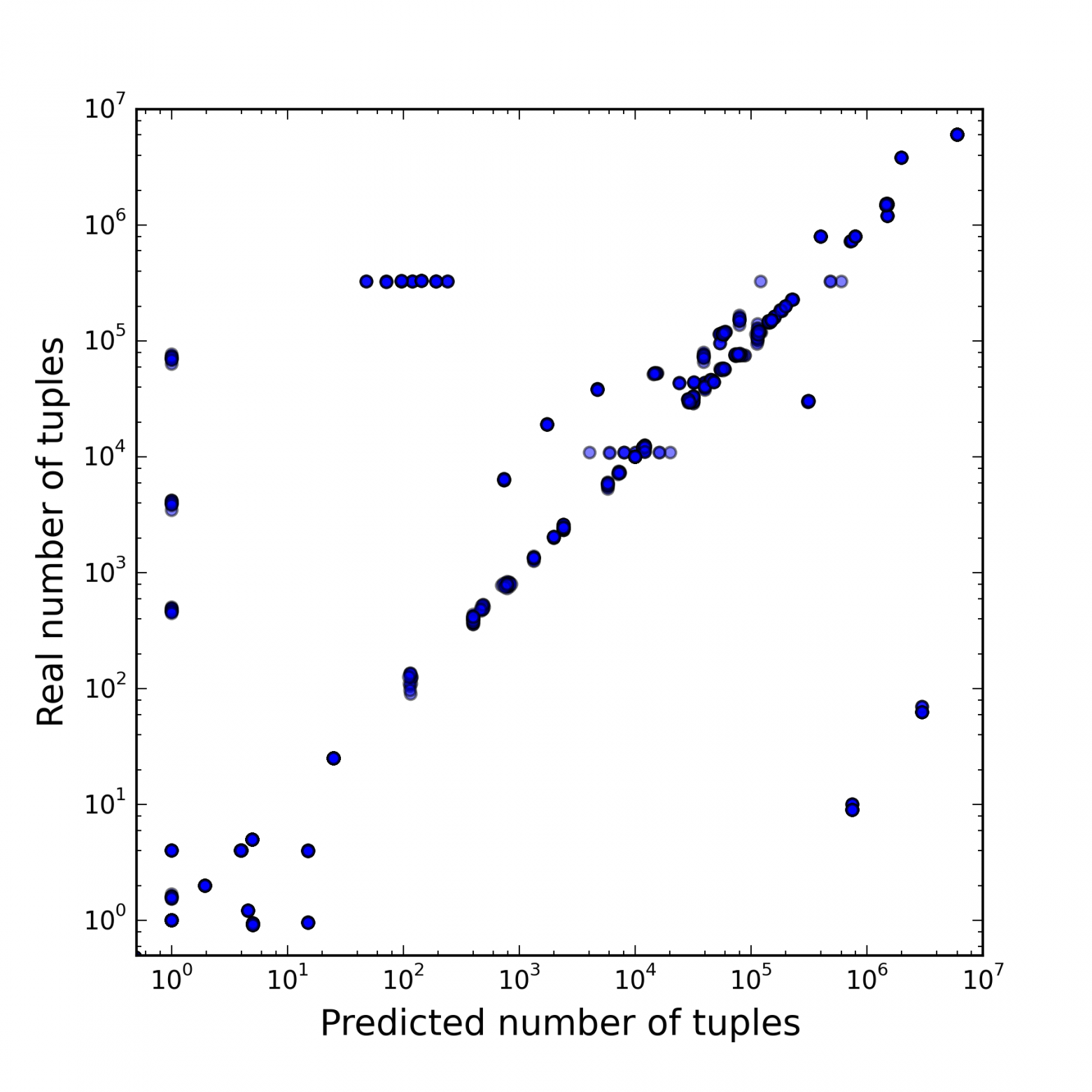 |
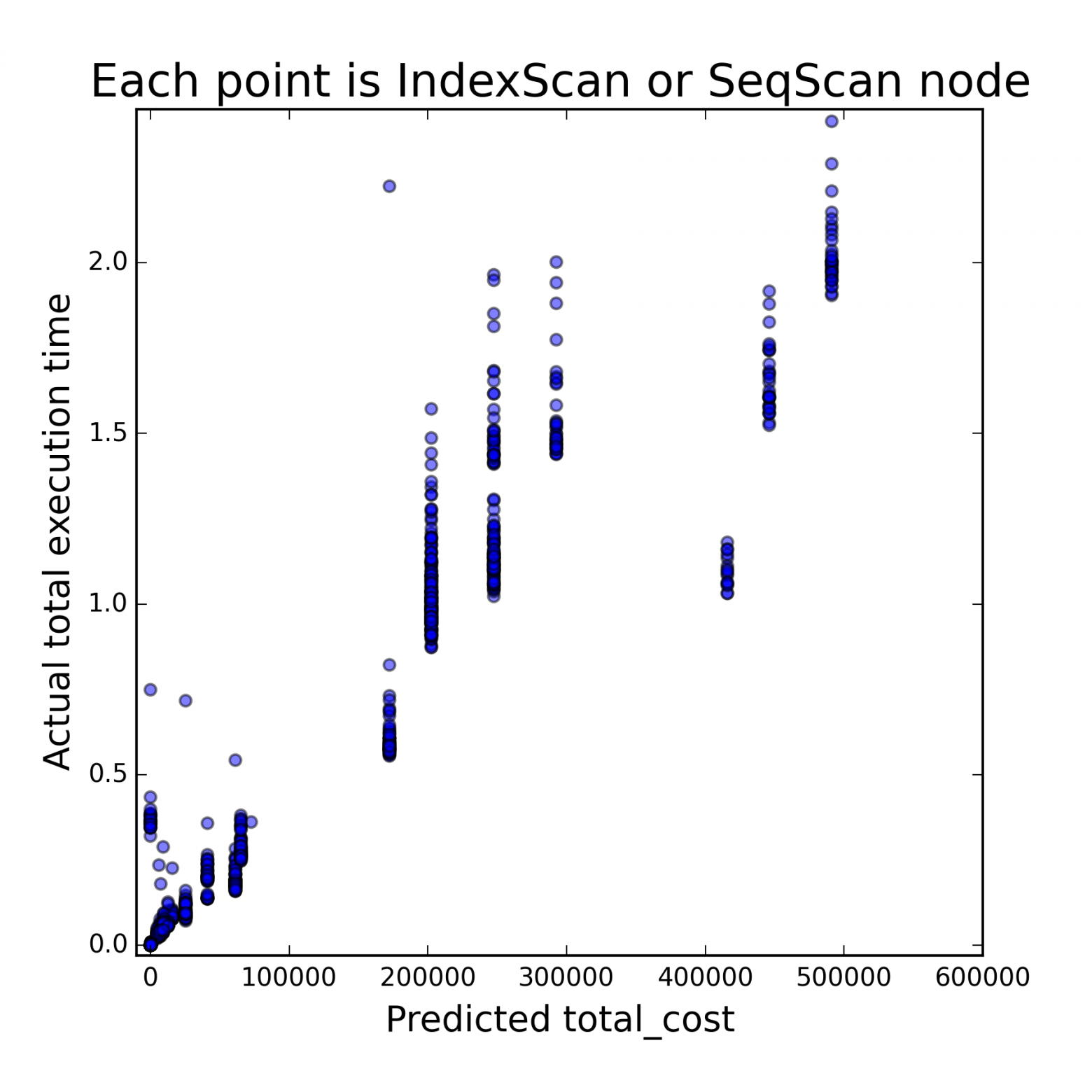 |
|---|---|
| Зависимость истинного количества кортежей от предсказанного | Зависимость времени работы плана от стоимости, если количество кортежей предсказано правильно |
На первом рисунке видно, что результат решения первой подзадачи отличается от истинного на несколько порядков. На втором рисунке видно, что при правильном решении первой подзадачи модель PostgreSQL достаточно адекватно оценивает стоимость выполнения того или иного плана, поскольку видна сильная корреляция со временем выполнения. В итоге было установлено, что от неточных решений обоих подзадач страдает производительно��ть СУБД, но от неверно установленного количества кортежей в каждой вершине она страдает больше.
Рассмотрим использующееся в PostgreSQL решение первой подзадачи.
Как СУБД оценивает количество кортежей в вершинах?
Для начала попытаемся предсказать количество кортежей, отбираемых простым запросом
SELECT name FROM users WHERE age < 25;
Для того, чтобы была хоть какая-то возможность это сделать, нам нужна какая-то информация о данных, статистика по ним. В PostgreSQL в качестве этой информации о данных используются гистограммы.
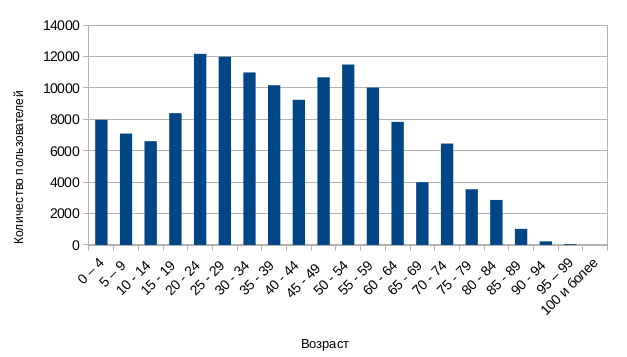
Используя гистограмму, мы легко можем восстановить долю тех пользователей, которые младше 25 лет. Для каждой вершины плана доля всех отобранных кортежей по отношению ко всем обработанным кортежам называется выборочностью (selectivity). В приведенном примере выборочность SeqScan будет равна примерно 0.3. Для получения количества кортежей, отбираемых вершиной, достаточно будет умножить выборочность вершины на количество обрабатываемых кортежей (в случае SeqScan'а это будет количество записей в таблице).
Рассмотрим более сложный запрос
SELECT name FROM users WHERE age < 25 AND city = 'Moscow';
В этом случае с помощью гистограмм по возрасту и городам мы сможем получить только маргинальные выборочности, то есть долю пользователей младше 25 лет и долю москвичей среди пользователей. В модели PostgreSQL все условия (кроме пар условий вида
5 < a AND a < 7, которые автоматически превращаются в условие 5 < a < 7), считаются независимыми. Математики называют два условия A и B независимыми, если вероятность того, что выполняются оба условия одновременно, равна произведению их вероятностей: P(A и B) = P(A)P(B). Однако в прикладном смысле можно понимать независимость двух величин как то, что от значения одной величины не зависит распределение на другую величину.В чем же проблема?
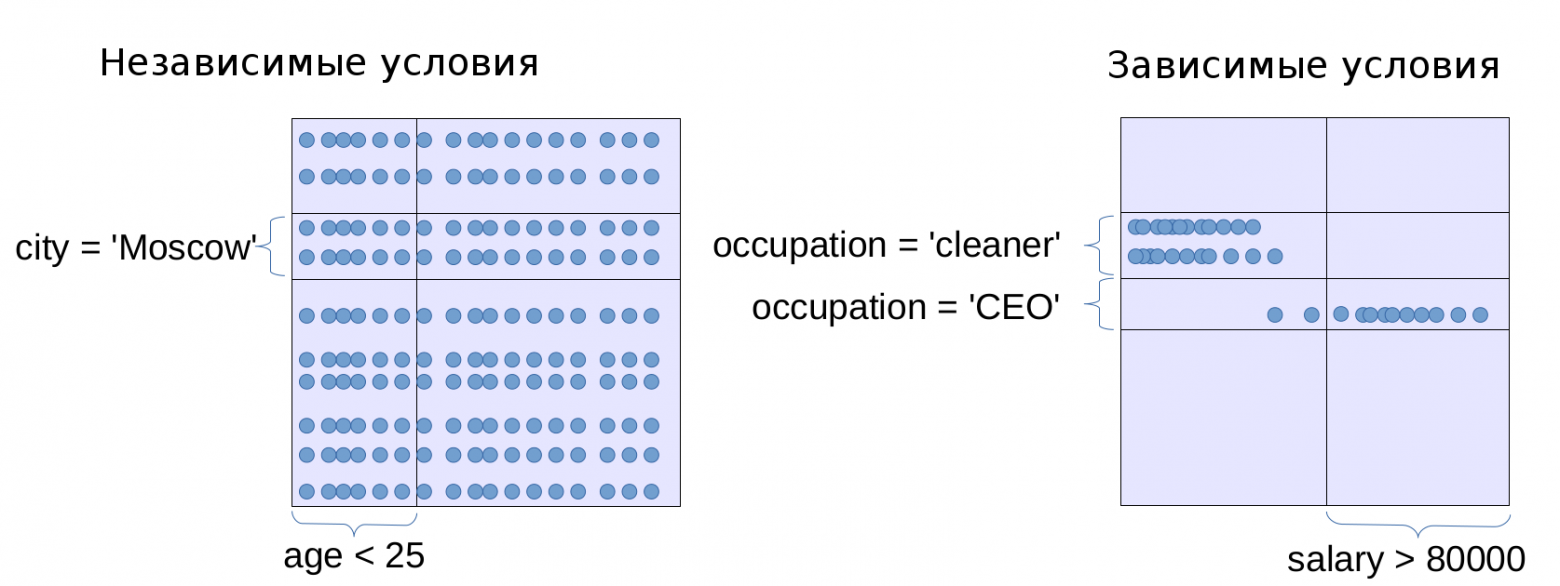
В некоторых случаях предположение о независимости условий не выполняется. В таких случаях модель PostgreSQL работает не очень хорошо. Есть два способа бороться с этой проблемой.
Первый способ заключается в построении многомерных гистограмм. Проблема этого способа заключается в том, что с увеличением размерности многомерная гистограмма требует экспоненциально растущее количество ресурсов для сохранения той же точности. Поэтому приходится ограничиваться гистограммами маленькой размерности (2-8 измерений). Отсюда следует вторая проблема этого метода: нужно каким-то образом понять, для каких пар (или троек, или четверок...) столбцов имеет смысл строить многомерные гистограммы, а для каких необязательно.
Чтобы решить эту проблему, требуется либо хороший администратор, который будет изучать планы ресурсоемких запросов, определять корреляции между столбцами и вручную указывать, какие гистограммы нужно достроить, либо программное средство, которое с помощью статистических тестов попытается найти зависимые друг от друга столбцы. Однако не для всех зависимых столбцов имеет смысл строить гистограммы, поэтому программное средство также должно анализировать совместную встречаемость столбцов в запросах. В настоящий момент существуют патчи, позволяющие использовать в PostgreSQL многомерные гистограммы, но в них администратору требуется вручную задавать, для каких столбцов эти многомерные гистограммы должны быть построены.
Используем машинное обучение для оценки выборочности
Однако эта статья посвящена альтернативному подходу. Альтернативный подход — это применение машинного обучения для нахождения совместной выборочности нескольких условий. Как уже говорилось выше, машинное обучение занимается поиском закономерностей в данных. Данные — это набор объектов. В нашем случае объектом является совокупность условий в одной вершине плана. По этим условиям и их маргинальным выборочностям нам требуется предсказать совместную выборочность.
Наблюдаемыми признаками вершины плана будут являться маргинальные выборочности всех её условий. Будем считать эквивалентными между собой все условия, отличающиеся только в константах. Можно рассматривать данное допущение как типичный прием машинного обучения — hashing trick — примененный для уменьшения размерности пространства. Однако за этим стоит более мощная мотивация: мы предполагаем, что вся необходимая для предсказания информация о константах условия содержится в его маргинальной выборочности. Можно показать это строго для простых условий вида a < const: здесь по выборочности условия мы можем восстановить значение константы, то есть потери информации не происходит.
Получившаяся задача машинного обучения будет выглядеть так, как представлено на рисунке.
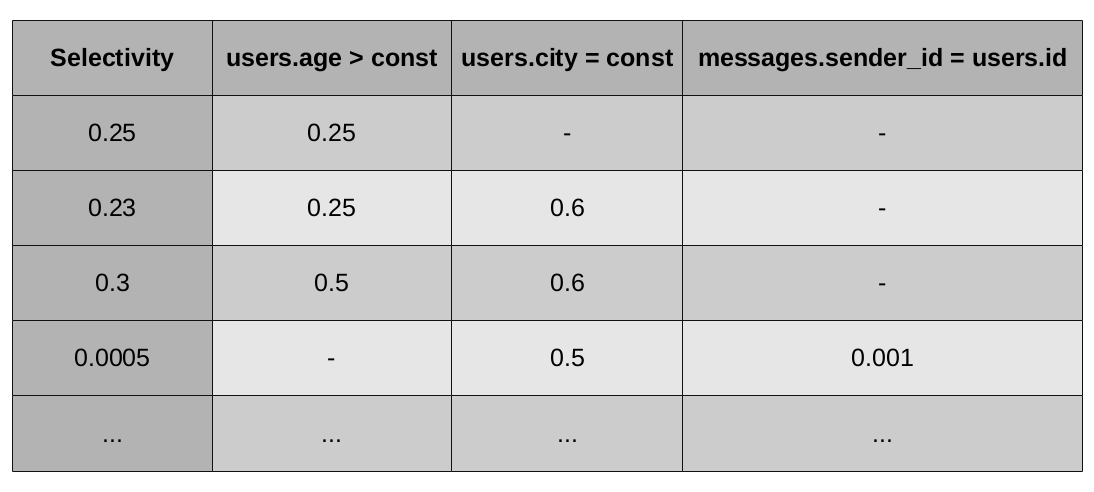
Мы должны предсказать самый левый столбец по известным значениям во всех остальных столбцах. Такая задача, в которой требуется предсказать некоторое вещественное число, в машинном обучении называется задачей регрессии. Метод, решающий её, называется, соответственно, регрессором.
Перейдем к логарифмам во всех столбцах. Заметим, что, если теперь использовать линейную регрессию, то в качестве частного случая мы получим текущую модель PostgreSQL.
Линейная регрессия:
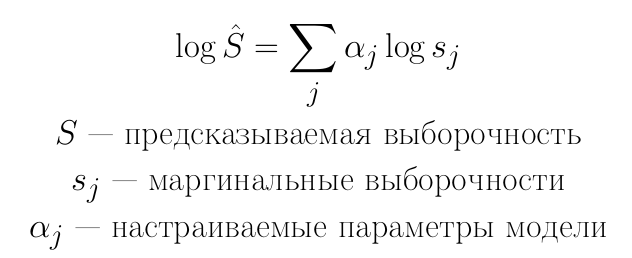
В случае, когда все настраиваемые параметры равны 1, получаем стандартную модель выборочности PostgreSQL:
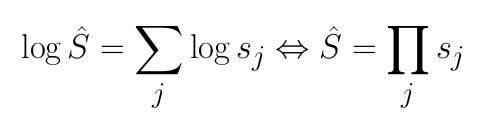
Стандартный метод гребневой регрессии предлагает искать параметры с помощью минимизации следующего функционала:
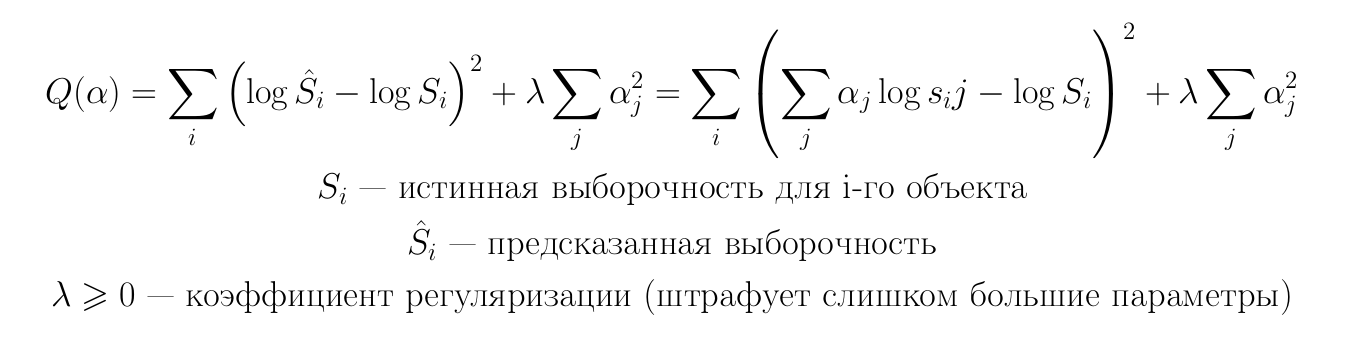
Для тестирования различных подходов мы использовали бенчмарк TPC-H.
В качестве простых регрессоров были использованы следующие методы:
- Гребневая линейная регрессия + стохастический градиентный спуск. Этот метод хорош тем, что позволяет использовать динамическое обучение (online learning), поэтому не требует хранить никаких наблюдаемых объектов.
- Множество гребневых линейных регрессий + стохастически�� градиентный спуск. Здесь предполагается, что для каждого набора условий создается отдельный гребневый линейный регрессор. Этот метод, как и прошлый, хорош тем, что позволяет использовать динамическое обучение, поэтому не требует хранить никаких наблюдаемых объектов, однако работает несколько точнее предыдущего, поскольку содержит существенно больше настраиваемых параметров.
- Множество гребневых линейных регрессий + аналитическое решение методом Гаусса. Этот метод требует хранить все наблюдаемые объекты, но при этом, в отличие от двух предыдущих, гораздо быстрее настраивается под данные.
Однако в этом же и его минус: он ведет себя достаточно нестабильно.
Объясним природу нестабильности, возникающей при аналитическом решении. Ответы нашего регрессора являются входными значениями для оптимизатора, который ищет оптимальный план. Наблюдаемые нами объекты (исполняемые планы), являются выходными значениями оптимизатора. Поэтому наблюдаемые нами объекты зависят от ответов регрессора. Такие системы с обратной связью намного сложнее для изучения, чем системы, в которых регрессор не влияет на окружающую среду. Именно в этих терминах аналитическое решение методом Гаусса является нестабильным — оно быстро обучается, но предлагает более рискованные решения, поэтому в целом система работает хуже.

После детального изучения линейной модели мы обнаружили, что она недостаточно полно описывает данные. Поэтому наилучшие результаты из опробованных нами методов показал kNN.
- kNN. Существенный минус этого метода заключается в необходимости сохранения в памяти всех объектов с последующей организацией быстрого поиска по ним. Существенно улучшить эту ситуацию можно, используя алгоритм отбора объектов. Идея наивного алгоритма отбора объектов: если предсказание на объекте достаточно хорошее, то запоминать этот объект не нужно.
Также этот метод является более стабильным, чем линейная регрессия: для сходимости на бенчмарке TPC-H требуется всего 2 цикла обучения, приведенных на рисунке выше.
К чему приводит использование машинного обучения
Приведем полученные результаты для алгоритма kNN.
 |
 |
| До машинного обучения | После машинного обучения |
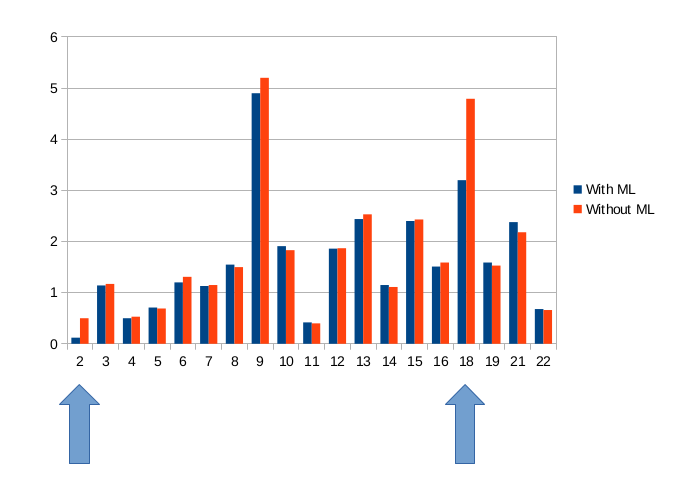
Можно видеть, что предложенный подход в самом деле ускоряет время работы СУБД. На одном из типов запросов бенчмарка ускорение составляет 30-45%, на другом — в 2-4 раза.
Какие есть пути развития?
Есть ещё много направлений для дальнейшего улучшения имеющегося прототипа.
- Проблема поиска планов. Текущий алгоритм гарантирует, что в тех планах, к которым сходится алгоритм, предсказания выборочности будут правильными. Однако это не гарантирует глобальной оптимальности выбранных планов. Поиск глобально оптимальных планов или хотя бы лучшего локального оптимума — это отдельная задача.
- Режим прерываний для прекращения исполнения неудачного плана. В стандартной модели PostgreSQL нам не имеет смысл прерывать выполнение плана, поскольку у нас есть всего один наилучший план, и он не меняется. С внедрением машинного обучения мы можем прервать выполнение плана, в котором были допущены серьезные ошибки в предсказании выборочности, учесть полученную информацию и выбрать новый лучший план для выполнения. В большинстве случаев новый план будет существенно отличаться от предыдущего.
- Режимы устаревания информации. В процессе работы СУБД меняются данные и типичные запросы. Поэтому данные, которые были получены в прошлом, могут быть уже неактуальны. Сейчас в нашей компании ведется работа над хорошей системой определения актуальности информации, и, соответственно, «забывания» устаревшей информации.
Что это было?
В этой статье мы:
- разобрали механизм работы планировщика PostgreSQL;
- отметили проблемы в текущем алгоритме оценки выборочности;
- показали, как можно использовать методы машинного обучения для оценки выборочности;
- экспериментально установили, что использование машинного обучения ведет к улучшению работы планировщика и, соответственно, ускорению работы СУБД.
Спасибо за внимание!

Литература
- Про планировщик PostgreSQL
- Explaining the Postgres Query Optimizer, Bruce Momjian
- Материалы для разработчиков PostgreSQL
- Доклады про внутреннее устройство PostgreSQL, Neil Conway
- Про машинное обучение (из курса лекций К. В. Воронцова)
