Привет, Хабр! Недавно мы делали доклад на конференции HighLoad 2023 — «Мифы и реалии Мультимастера в архитектуре СУБД PostgreSQL». Мы — это Павел Конотопов (@kakoka) и Михаил Жилин (@mizhka), сотрудники компании Postgres Professional. Павел занимается архитектурой построения отказоустойчивых кластеров, а Михаил — анализом производительности СУБД. У каждого за плечами более десяти лет опыта в своей области.

Далеко не все читатели Хабра смогли посетить конференцию или посмотреть трансляцию нашего доклада, поэтому мы решили поделиться рассказанным в статье. Порассуждаем о том, как развивалась технология «Мультимастер» в экосистеме PostgreSQL, остановимся на том, что она из себя представляет, на каких внутренних механизмах PostgreSQL основана и как её можно использовать.
Мы также поговорим о том, существует ли «Честный Мультимастер» (само понятие «Честный Мультимастер» достаточно специфично и в основном употребляется в кругу разработчиков), какие реализации у него есть и как его следует применять.
Статья будет сфокусирована на производительности «Мультимастера», ведь если СУБД работает медленней черепахи, то это уже не база данных, а черепаха ?
Часть 1. Что такое «Мультимастер»?
Разберёмся с терминологией: что есть что в распределенных системах, таких как кластеры РСУБД?
В мире баз данных несколько узлов СУБД (виртуальных машин или физических серверов) объединены в сущность, которую называют кластер. В кластере каждому узлу присваивается определённая роль, обычно роли бывают двух типов:
ведущий сервер — «master» или «primary», генерирующий поток изменений;
ведомый сервер или «репликация» — «slave», «standby» или «реплика», принимающий поток изменения данных от ведущего узла, и применяющий их у себя.
На всех узлах такой системы будет находиться одинаковый набор данных, и изменять данные можно только через один узел — «мастер». Само понятие «мастер» предполагает, что должна быть сущность, которую можно назвать «не-мастер». Если обе эти сущности встречаются в одном кластере, то перед нами — распределённая система.
Таким образом, термин «Мультимастер» означает, что кластер РСУБД будет состоять только из узлов одного типа — «ведущий узел», или «мастер» (например, «мастер №1», «мастер №2», «мастер №3» и т.д.). Изменять данные в таком кластере можно через любой узел, при этом изменения будут применены на всех узлах кластера, следовательно, на всех узлах будет одинаковый набор данных.
Тогда «Мультимастер» выглядит как отказоустойчивое решение для реляционной БД, которое:
хорошо масштабируется: больше узлов — больше производительность;
распределение нагрузки между узлами: как для чтения, так и для записи;
надежно: выход одного из узлов не влияет на доступность БД.
Сама по себе технология «Мультимастер» не нова: на сцене HighLoad про нее сделал хороший доклад делал Илья Космодемьянский в 2017 году.
Однако из большинства докладов можно сделать вывод, что «Мультимастер» для PostgreSQL – технология, обладающая большой сложностью, низкой производительностью, надёжностью и доступностью, но она не годится для промышленной эксплуатации. А если её всё же внедряют в промышленный контур, то у вас явно что-то не так с архитектурой информационной системы. Правда, с 2017 года прошло достаточно много времени, и приведённые выше утверждения успели либо обрасти мифами, либо потеряли свою актуальность.
Чтобы отличить миф от реальности нужно рассмотреть современное состояние «Мультимастера». Прежде всего опишем базовые механизмы PostgreSQL, на которые опирается технология «Мультимастер».
Начнём с физической или потоковой репликации, которая в PostgreSQL появилась очень давно. Её суть в том, что изменение физических страниц БД ведущего узла передаётся на ведомый. Но есть нюанс: при таком типе репликации передаются все изменения всех БД экземпляра PostgreSQL.

На схеме выше изображен кластер БД из двух узлов: с узла «основной сервер (мастер)» на узел «резервный сервер (реплика)» передаётся поток изменения физических страниц БД.
Очевидно, что «Мультимастер» на такой технологии не построить, так как все изменения реплицируются: PostgreSQL на данном уровне репликации не даёт гранулярности в её настройке. Следовательно, запись данных при таком типе репликации возможна только в один узел — ведущий. А хочется использовать все узлы кластера для записи данных, поэтому придумали логическую репликацию.
При логической или транзакционной репликации изменения передаются в виде транзакций, изменяющих данные (INSERT, DELETE, UPDATE). В PostgreSQL логическая репликация появилась в 10-й версии (2017 год). Этот тип репликации более гибкий: в нём реализована модель «публикатор – подписчик», или источник и приёмник репликации, которыми могут быть отдельная база данных, схема или таблица, соответственно можно выбирать, что и куда реплицировать. Но и тут есть особенность: поток изменений такой репликации — однонаправленный, на этой технологии полноценный «Мультимастер» тоже не построить.

Но мысль разработчиков сообщества PostgreSQL не стояла на месте! Во времена, когда не было встроенной логической репликации создали расширение pgLogical. А поверх него построили BDR (Bi-Directional Replication) — двунаправленную логическую репликацию с разрешением конфликтов. В более поздних версиях связка pgLogical/BDR превратилась в закрытый коммерческий код (про это будет рассказано ниже).
Следующий виток эволюции передачи изменений с узла на узел заключается в появлении технологии двунаправленной логической репликации. Технология появилась в 16-й версии PostgreSQL, то есть совсем недавно, в 2023 году. И в этот момент горячие головы энтузиастов PostgreSQL сказали: «О! Вот он — встроенный Мультимастер!». Но всё оказалось не так просто, давайте разберёмся, почему.
Что должно быть в «Мультимастере»?

Есть такое понятие — «Честный Мультимастер». На наш взгляд он должен обязательно отвечать следующим требованиям:
сохранять порядок транзакций (strong consistency);
предотвращать распределённые взаимные блокировки (conflict resolution);
исключать split-brain (fault tolerance);
обязательно должен быть доступен (availability) хотя бы один рабочий узел при сбоях.
А ещё хорошо бы иметь автоматическое восстановление узлов, защиту от повторного применения транзакций. Если с узлом что-то случилось, и он вдруг «сломался», то, «починившись», он должен автоматически восстановиться и снова стать рабочим узлом кластера «Мультимастер». Поэтому «Мультимастер», с нашей точки зрения, должен выглядеть следующим образом:

Если разобрать схему подробней, то в ней должны быть показаны дополнительные процессы внутри инстанса PostgreSQL. Эти процессы должны соответствовать предъявленным выше требованиям, как минимум должны быть процесс управления БД и процесс координации транзакций (для упрощения схемы приведен всего лишь один процесс — mtm-worker).
На текущий момент в Open Source можно найти примеры «Мультимастера», построенного на двунаправленной логической репликации 16-й версии PostgreSQL: Traktor, pgEdge/spock. При кратком рассмотрении этих проектов вы не обнаружите ни строгой согласованности данных, ни отказоустойчивости узлов, ни автоматического их восстановления. А главное — не будет строгой транзакционной согласованности данных в масштабах всего кластера.
pgEdge/spock — расширение, которое реализует фоновый процесс внутри PostgreSQL, а также некоторый набор модификаций (патчей) ядра PostgreSQL. Поддерживается логическая репликация из нескольких БД, некоторые виды конфликтов могут быть разрешены автоматически, для этого предусмотрено использование различных стратегий. Изюминка данного решения — реализация работы с бесконфликтными типами данных (патчи в ядро), а также доступна репликация секций партицированных таблиц и несколько других интересных возможностей, про которые можно прочитать на странице проекта на Github. Однако когда у вас возникает конфликт, разрешение которого не предусмотрено выбранной стратегией, репликация останавливается, пока вы вручную этот конфликт не устраните. Проект предлагает отказоустойчивость узлов, каждый узел в таком развёртывании будет кластером на базе Patroni. Для автоматизации развёртывания авторами написана отдельная утилита.
Tractor — другой вариант «Мультимастера» поверх встроенной двунаправленной логической репликации. Решение представляет собой внешний сервис, базирующийся на отслеживании журнала работы PostgreSQL. Если вдруг в журнале обнаруживается конфликт, то сервис пытается перезапустить логическую репликацию и требует разрешение конфликта.
Эволюционировали ли мы с 2017 года, и появился ли у нас наконец встроенный в ванильный PostgreSQL «Честный Мультимастер»? Очевидный ответ — скорее нет, чем да. Но, полагаем, что сообщество постепенно движется к его реализации.
Выше мы описали минимальные требования к «Честному Мультимастеру». Но, честно говоря, хочется большего:
уметь параллельно применять транзакции для ускорения работы всего кластера ;
разрешать конфликты изменений одних и тех же данных в один момент времени, но на разных узлах;
управлять узлом, восстанавливать его в случае сбоя, и много что ещё.
Суммируя эти требования, получаем набор специальных компонент внутри PostgreSQL.
Если смотреть с точки зрения предъявляемых требований на реализации ванильного «Мультимастера», то можно отметить его минусы:
нет строгой согласованности данных;
ограниченное определение и разрешение конфликтов;
нет отказоустойчивости узлов;
нет автоматического восстановления узлов;
нет транзакционности в масштабах кластера.
«Честный Мультимастер»

«Честный Мультимастер» появился достаточно давно. Реализовала его компания 2nd Quadrant, которую купила EnterpriseDB. Первые версии «Мультимастера» BDR она опубликовала в 2012 году. Он устроен гораздо сложнее, чем те реализации Open Source, что мы описывали ранее.
На сегодняшний день можно утверждать, что «Честный Мультимастер» PostgreSQL доступен в виде двух коммерческих продуктов. Первый — от компании EnterpriseDB, второй — от Postgres Professional. Обе компании — крупнейшие контрибьюторы в ванильный PostgreSQL, то есть постоянно делятся своими разработками с сообществом.
Что же внедрили в оба продукта, и чем эти две реализации лучше уже доступных в Open Source?
Добавлена DML+DDL логическая репликация. Логическая репликация в ванильном PostgreSQL умеет переносить данные из базы №1 в базу №2. Но она не умеет переносить изменения схемы данных. Если нужно добавить атрибут в табличку, то логическая репликация тут же остановится из-за ошибки.
Распределенные алгоритмы фиксации транзакций. В «Мультимастер» добавили возможность организовать согласованный распределённый коммит между узлами кластера, чего нет в ванильном варианте двунаправленной логической репликации.
Вспомогательные фоновые процессы. Задумавшись о повышении производительности репликации, добавили вспомогательные фоновые процессы. Они выполняют работу, связанную с параллельным переносом данных и их применением на узлах кластера.
Алгоритмы разрешения конфликтов. Придумали огромное количество алгоритмов, чтобы решать возникающие конфликты.
Управляющий канал между узлами. Одно из самых важных нововведений — канал управления между узлами и соответствующий фоновый процесс для управления PostgreSQL на узле. Это дало возможность легко собирать кластер, быстро понимать, когда в кластере произошел сбой, и нужно ли восстанавливать его работу.
Дополнительные фоновые процессы внутри PostgreSQL можно описать так:
процессы монитора (monitor) отвечают за связь узлов друг с другом, за запуск и остановку других служебных фоновых процессов;
процессы sender и receiver отвечают за согласованную фиксацию транзакций на узлах кластера, предотвращают несогласованное состояние базы данных между узлами;
процесс resolver, предназначен для разрешения конфликтов и отслеживания «оборванных» транзакций, когда один из узлов кластера по каким-либо причинам стал недоступен;
несколько других дополнительных процессов, для обработки потери узла и его восстановления.
Казалось бы, всё предусмотрено для бесперебойной и безошибочной работы кластера, но, увы, мы живём в неидеальном мире: новые возможности имеют и свои ограничения.
Особенности «Мультимастера»
Реплицируется только одна база. «Мультимастер» для одной или нескольких выбранных баз данных пока не реализован ни в Postgres Professional, ни в EDB имплементациях. Признаться, из-за этого довольно неудобно создавать «коммуналку» баз данных. Хочется, чтобы какие-то из этих баз реплицировались, а какие-то — остались локальными.
Большое количество ограничений, связанных с DDL, нет фоновых операций создания индекса. Начиная с 12-й версии PostgreSQL появилась возможность создавать и пересоздавать индексы в фоновом режиме. Если какая-то таблица раздулась (bloat), то можно запустить pg_repack, который использует фоновый процесс переиндексации. В «Мультимастере» это пока недоступно.
Обязательно требуются первичные ключи на таблицах. Для отслеживания конфликтов обязательно требуется создавать первичный ключ на таблице, а это не всегда может быть простой операцией. Порой действительно сложно придумать, какой первичный ключ требуется, настолько сложными бывают данные.
Коммерческие продукты с закрытым кодом. Единственный вариант в котором доступен «Мультимастер», и это замедляет рост популярности этой архитектуры.
Но есть и достоинства, которые дает «Мультимастер»:
почти нулевое время простоя (режим Always On);
бесшовное переключение на другой узел при отказе какого-либо из узлов;
нет ограничений по версиям, можно сочетать разные версии «Мультимастера»;
возможность масштабировать чтение;
отсутствие ограничений на запись.
Одно из самых значимых преимуществ — возможность почти бесшовно обновлять узлы кластера. Можно снять нагрузку с одного узла, выключить его, обновить версию, запустить обратно, и узел автоматически вернётся в кластер, никто даже не заметит отсутствие такого узла.
Другое преимущество — возможность масштабирования по чтению, читать данные можно с каждого узла.
Отметим, что при попытке масштабирования по записи мы можем и не получить значимого преимущества. Даже напротив: может быть снижение производительности, так как при записи данных в какой-либо из узлов кластера данные должны быть синхронно перенесены в другие узлы кластера. При этом возможны случаи, когда масштабирование будет осуществляться и по записи, и по чтению. Например, приложение спроектировано так, что разные его экземпляры, подключенные к разным узлам кластера, обновляют разные части одной большой таблицы (подробнее см. главу Как выявлять конфликты?). Следовательно, для получения выигрыша следует проектировать приложение так, чтобы учитывалась архитектура СУБД.
Создание кластера
Насколько просто развернуть кластер «Мультимастера»? К примеру, «Мультимастер» по умолчанию входит в продукт Postgres Pro Enterprise, начиная с 12-й версии (актуальная версия – 16). Чтобы его установить, достаточно создать расширение (extension) multimaster на каждом узле кластера, далее вызвать команду init_cluster на одном из узлов, перечислив адреса других.
Эта команда обратится ко всем узлам кластера и соберёт кластер, готовый к эксплуатации. Можно посмотреть, как узлы общаются друг с другом с помощью команд status или nodes.
Пример уже собранного трехузлового «Мультимастера» (2 узла + 1 арбитр (referee) или 3 узла):
CREATE EXTENSION multimaster; (на всех узлах)
mtm.init_cluster('node-1','{“node-2”,“node-3”}');
mtm.status() / mtm.nodes();
Ожидаемый вывод последней команды:

В EDB PGD (EnterpriseDB Postgres Distributed — PGD, c версии 3.x, актуальная — 5.3.0) развёртывание кластера выглядит примерно так же, только требуется чуть больше команд:
CREATE EXTENSION bdr;
SELECT bdr.create_node_group('group-1');
SELECT bdr.create_node('node-1');
SELECT bdr.join_node_group('group-1');
SELECT * FROM bdr.node_summary;
Устанавливаем расширение BDR, создаём группу узлов, в которую добавляем узлы, выводим статус кластер с помощью SQL-запроса:

Коллеги из EnterpriseDB пошли дальше: они создали специальную утилиту Trusted PostgreSQL Architect, отдельный инструмент для развертывания «Мультимастера» в различных окружениях, в зависимости от требований. Это могут быть контейнеры, облачные провайдеры или физические сервера. Развернуть кластер можно всего за несколько простых команд.
Обеспечение отказоустойчивости кластера СУБД
В мире PostgreSQL есть несколько популярных решений для построения отказоустойчивого кластера: Corosync/Pacemaker, Patroni, Stolon, pg_auto_failover и т. д. Решение на базе Patroni, пожалуй, наиболее популярно, поэтому рассмотрим схему классического кластера из его документации .
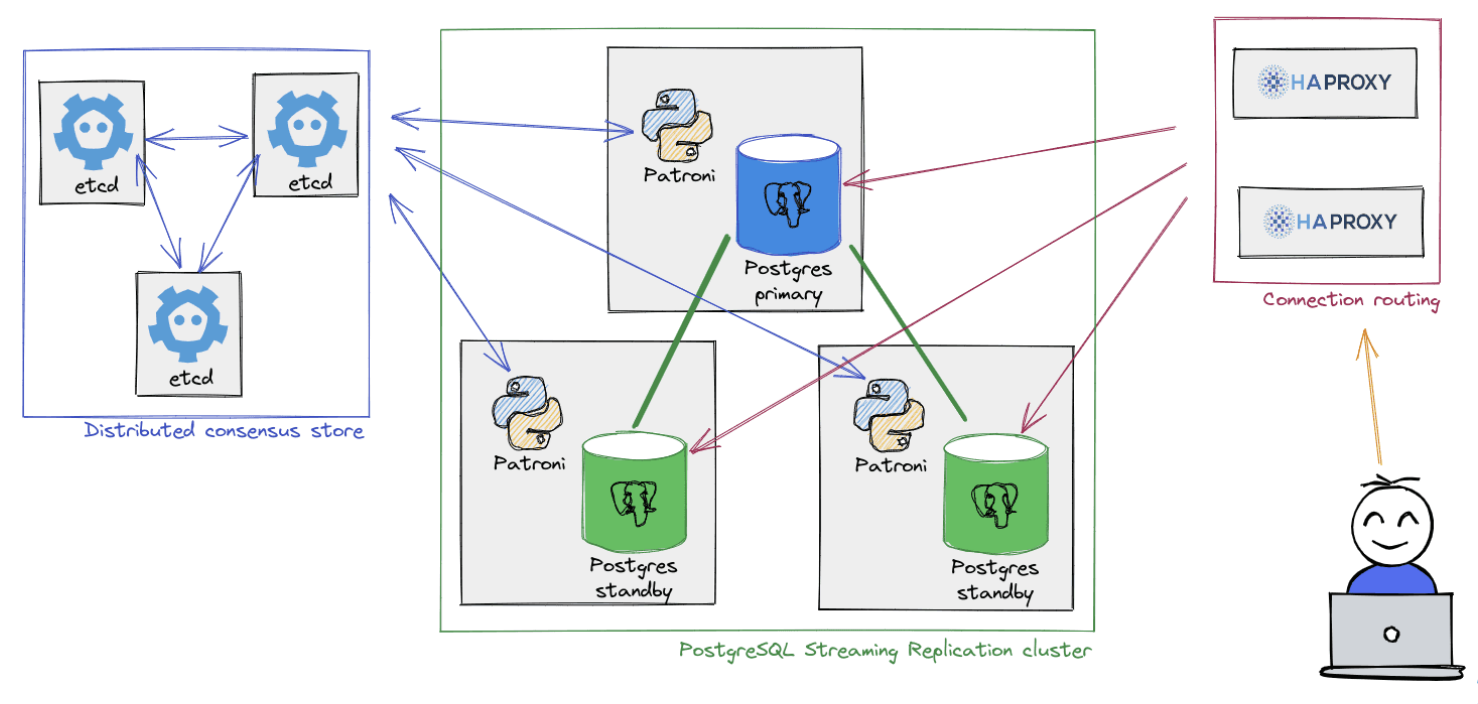
Для обеспечения безотказной работы кластера СУБД дополнительно потребуется etcd кластер: кластерное ПО хранит в нём состояния кластера СУБД и его конфигурации.
В случае с «Мультимастером» согласованный консенсус достигается внутри самого PostgreSQL, узлы умеют это делать сами за счет специальных процессов, которые за это отвечают. Тогда потребность в etcd отпадает.

Результат: на три узла (контейнеров или виртуальных машин) в инфраструктуре стало меньше! Освободились ресурсы, которые можно использовать для чего-то другого.
Так же потребуется какой-то TCP-прокси для обращения к текущему лидеру в кластере СУБД, ведь если мы обратимся к реплике с целью записи данных, то получим ошибку. Как правило, в кластерах Patroni используется HAProxy. При изменении роли узла в кластере Patroni tcp-прокси будет направлять запросы от пользователей или приложений к новому лидеру в кластере.
Нужен ли нам tcp-прокси или балансировщик для «Мультимастера»? Требуется ли нам понимать на уровне приложения или пользователя, какова их роль узлов в кластере? Но ведь все узлы в кластере «Мультимастер» — мастера: можно подключиться к любому из них и тут же начать работать.
Правда, следует учесть особенности возможного состояния узлов при работе с кластером «Мультимастера». Например, в продукте Postgres Professional у каждого узла, кроме состояний «всё хорошо, я работаю» и «я не работаю», есть состояния, сигнализирующие о фазе восстановления, если произошел сбой:
CATCHUP – догоняем другие узлы кластера;
RECOVERY – восстанавливаемся из журналов WAL.
В продукте от EDB названия статусов узла могут отличаться, но сути это не меняет. Если попытаться подключить приложение к такому узлу, то приложение получит ошибку: [MTM] multimaster node is not online: current status catchup.
Допустим, наше приложение написано на Java и работает через PostgreSQL JDBC драйвер. После создания TCP-соединения драйвер пошлёт startup-пакет, подключится к узлу, авторизуется и попробует выполнить проставление сессионных переменных. Самая популярная такая переменная — extra_float_digits, работа с данными с плавающей точкой, параметр указывает сколько цифр после запятой выдавать на экран: SET extra_float_digits = 3. На этом этапе он получит ошибку, что с узлом нельзя работать: [MTM] multimaster node is not online: current status catchup. Но есть довольно простой выход из этой ситуации: перечислим все узлы кластера в строке соединения с базой данных, например: jdbc:postgresql://host1,host2,host3/database.
Когда драйвер будет подключаться к узлу в состоянии восстановления и получит после подключения к нему ошибку, то просто перейдёт к следующему перечисленному в строке узлу до тех пор, пока не найдёт рабочий. Переподключение к БД может быть быстрым, если у нас высокоскоростная сеть и выставлены маленькие таймауты на подключение, по истечении которых мы переходим к попытке подключения к другому узлу из строки подключения в случае недоступности предыдущего. Так можно научить приложение быстро перебирать узлы кластера, минуя балансировщик.
Ура! Теперь не нужен ни кластер etcd, ни балансировщики. Убираем лишнее, оставляем только PostgreSQL и приложение: меньше компонентов в инфраструктуре — проще её архитектура, проще внедрение, меньше затраты на сопровождение.

И кажется, вот оно, счастье! …Или нет?
На этом первая часть нашей статьи заканчивается. Во второй части поговорим про надёжность хранения данных. Главным образом о том, как гарантировать строгую консистентность и разрешать конфликты в распределённой модели БД.

{kind=link}