В статье рассказываем, как оптимизировать базу данных PostgreSQL на примере Linux на IBM Z. Опираясь на представленные примеры, вы шаг за шагом узнаете, какие опции и параметры конфигурации улучшат установку PostgreSQL с точки зрения:
пропускной способности;
времени отклика;
общих аспектов.

Целевая аудитория и необходимые скилы
Эта статья ориентирована на системных программистов Linux и администраторов баз данных, которые хотят настраивать серверы PostgreSQL, не тратя много времени на изучение параметров ядра Linux, параметров LVM и настроек PostgreSQL.
Представленные параметры конфигурации оптимизированы под транзакционные рабочие нагрузки (системы онлайн-банкинга, сервисы продажи авиабилетов и другие приложения, специализирующиеся на обработке больших объёмов транзакционных баз данных).
Чтобы извлечь максимальную пользу из статьи, вам нужны базовые навыки системного программирования Linux. Базовые навыки администрирования баз данных PostgreSQL желательны, но не обязательны.

Обзор результатов настройки
На диаграмме показаны общие результаты настройки PostgreSQL в тестовой среде:
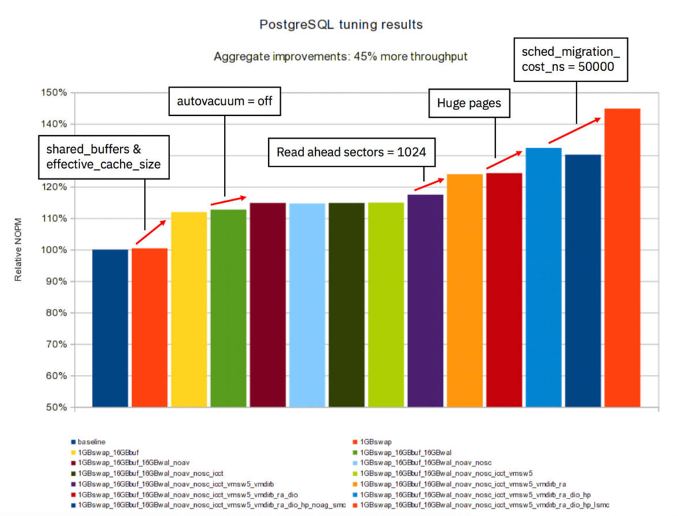
Мы добились увеличения пропускной способности на 45% по сравнению с первоначальными измерениями. Это весомый показатель, если принять во внимание, что мы вообще не настраивали тестовую базу данных.
Обычно значительных улучшений в настройке базы данных можно добиться путем применения изменений на уровне SQL. Например, путём создания индексов или адаптации SQL-запросов. В исследовании мы не прибегали ни к одному из таких приёмов. Вместо этого мы сосредоточились на конфигурационных изменениях в базовой среде: операционной системе (Linux) и промежуточном программном обеспечении (PostgreSQL).
Рекомендации по настройке
Дисклеймер: результаты тестов производительности, показанные на диаграммах, были получены в контролируемой лабораторной среде. Отличия в пропускной способности могут не наблюдаться в реальных сценариях и средах, отличных от собственного LPAR.
Все тестовые прогоны проводились с Ubuntu 16.04.2, PostgreSQL 9.5.7 и HammerDB 2.23. Другие версии продукта могут давать другие результаты производительности.
Все тесты были специально выполнены для PostgreSQL. Влияние на другие системы управления базами данных может быть совершенно иным.
Все тесты были выполнены для транзакционной системы OLTP. Влияние на другие типы систем, например на OLAP, может быть совершенно иным.
Пропускная способность
Вы можете улучшить пропускную способность PostgreSQL, придерживаясь рекомендаций.
Рекомендация №1: увеличьте размер shared buffers PostgreSQL до 1/4 от общего объёма физической памяти и размер effective cache до 3/4 (рекомендации по настройке PostgreSQL).
В ходе исследования выяснилось, что это один из основных регуляторов настройки, повышающий пропускную способность почти на 12%.
Важно: не увеличивайте размер shared buffers слишком сильно (например, до 1/2 от общего объёма физической памяти). Это спровоцирует активность OOM Killer.
Почему влияние больших shared buffers настолько незначительно? Вероятно, потому что PostgreSQL в значительной степени зависит от эффективности кэша страниц Linux. Это несколько раз упоминается в документации PostgreSQL.
Параметр effective cache size не является фактическим выделением памяти, а только «оценкой того, сколько памяти доступно для кэширования диска операционной системой и в самой базе данных». Он используется планировщиком запросов PostgreSQL.
Рекомендация №2: для рабочих нагрузок, предназначенных только для чтения, желательно отключить демона автоочистки (autovacuum daemon) в PostgreSQL.
Обычно демона автоочистки рекомендуется оставлять включенным, так как он выполняет полезные функции:
восстанавливает или повторно использует дисковое пространство, занятое обновлёнными или удалёнными строками;
обновляет статистику данных, используемую планировщиком запросов PostgreSQL.
Этот процесс может стоить вам нескольких CPU-циклов. Отключение демона для рабочей нагрузки HammerDB TPC-C привело к увеличению пропускной способности почти на 2%:
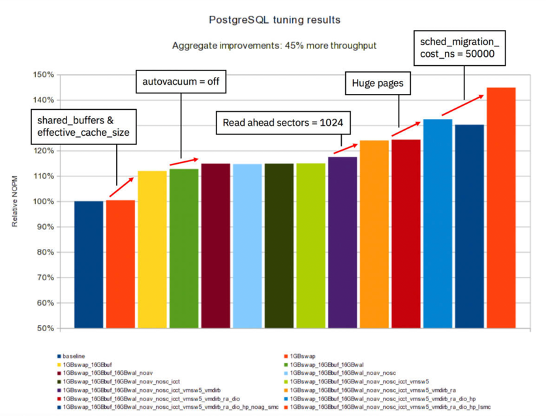
Для рабочих нагрузок с большим объёмом записи (с большим количеством операторов INSERT, UPDATE и DELETE), рекомендуется держать демона автоочистки включенным. В противном случае много места на диске потратится впустую и/или статистика базы данных будет искажена. Единственное исключение из этого правила — ситуации, когда введённые или обновленные данные существенно не меняют статистическую информацию.
Для рабочих нагрузок базы данных, в основном доступных для чтения, статистические данные со временем существенно не меняются, поэтому вы можете запустить PostgreSQL с отключенным демоном автоочистки. Однако ручную операцию VACUUM следует запланировать (например, с помощью джобы cron), когда нагрузка на систему низкая.
Рекомендация №3: включите read ahead для logical volume, содержащего файлы базы данных.
Почему этот параметр заслуживает внимания? Потому что до сих пор чёткой рекомендацией для баз данных было отключать read ahead на уровне LV или блочного устройства. Например, DB2 работает лучше, если read ahead отключено на уровне LV/блочного устройства.
Включение read ahead привело к увеличению пропускной способности почти на 6%. Причиной этого, вероятно, является то, что PostgreSQL сильно зависит от эффективности кэша страниц Linux. Другие базы данных сами решают, какие страницы следует читать заранее, и не полагаются на функциональность read ahead операционной системы.
Рекомендация №4: включите huge pages.
В этом контексте huge pages означают страницы, которые настраиваются с помощью параметра в /etc/sysctl.conf: vm.nr_hugepages=17408 (17 ГБ). Включение huge pages привело к увеличению пропускной способности примерно на 7%.
Почему 17 Гб? Shared buffers потребляют 16 ГБ, плюс память, необходимая PostgreSQL для других целей, и дополнительный «запас» по соображениям безопасности.
Чтобы точно определить, сколько памяти использует PostgreSQL, просмотрите файл /proc/[PID]/task/[TID]/status и найдите запись «VmPeak».
Рекомендация №5: для меньшего числа IFL и большого количества параллельных пользователей желательно снизить стоимость миграции планировщика ядра.
kernel.sched_migration_cost_ns= устанавливает количество наносекунд — столько ядро будет ждать, прежде чем рассмотреть вопрос о переносе потока на другой CPU. Чем выше стоимость миграции, тем дольше планировщик будет ждать, прежде чем рассмотреть вопрос о переносе потока на другой CPU. Это актуально для больших Linux images и/или разбросанных Linux images, охватывающих несколько микросхем PU и/или несколько узлов.
Однако наши тестовые запуски основаны на конфигурации 4 IFL, поэтому все CPU фактически помещались на один и тот же чип PU. Проверено с помощью lscpu --extended.
Важные детали, о которых следует помнить:
все ядра на чипе PU используют один и тот же кэш L3 (и, конечно же, кэш L4);
PostgreSQL создает новый процесс для каждого виртуального пользователя.
Снижение стоимости миграции планировщика увеличивает пропускную способность почти на 9%. Добавьте в /etc/sysctl.conf следующее:
kernel.sched_migration_cost_ns=50000`В конкретной конфигурации для производительности невыгодно позволять отдельным процессам PostgreSQL работать как можно дольше на одном и том же CPU. Даже если они распределены по другому ядру, они все ещё находятся на одном и том же чипе PU. Это значит, что либо кэш L3 содержит много важной информации для процесса, либо кэш L3 полностью заполнен.
Если количество пользовательского времени увеличивается, это явный признак того, что Linux image выполняет более полезную работу с применением этого параметра. Это проверяется с помощью top и/или sar.
Важно: не применяйте параметр без тестирования для больших Linux images и/или Linux images, процессоры которых разбросаны по всей топологии z13 или средам, в которых у вас мало параллельных пользователей. Вы можете проверить текущую топологию с помощью lscpu --extended. В этом контексте небольшое количество пользователей означает #users = #cores.
Время отклика
Графики на рисунках иллюстрируют пропускную способность до и после изменения конфигурации.
До:
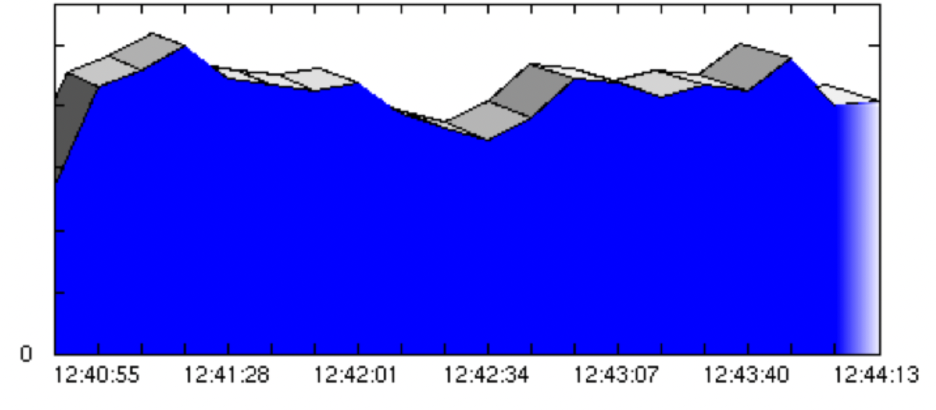
Примечание: время отклика не равно пропускной способности. Однако из графика пропускной способности можно сделать вывод, что время отклика, было очень нестабильным, поскольку количество виртуальных пользователей не изменилось после этапа наращивания.
После:
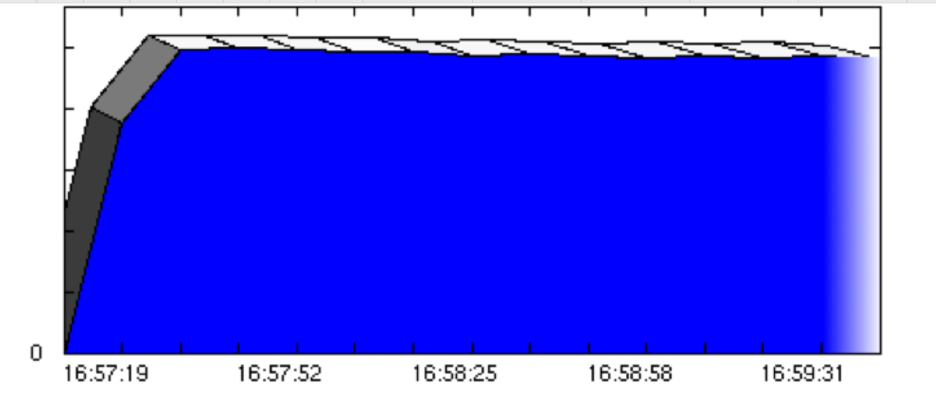
Примечание: стабильный график общей пропускной способности не является абсолютной гарантией того, что время отклика отдельных виртуальных пользователей было на 100% согласованным в течение всего тестового запуска. Однако это важный показатель.
Рекомендация №1: измените настройки ядра в отношении обратной записи dirty pages.
Значения параметров по умолчанию очень высоки:
vm.dirty_background_ratio=10 (10% от 64ГБ = 6.4 ГБ)
vm.dirty_ratio=20 (20% от 64ГБ = 12.8 ГБ)
Мы рекомендуем уменьшить два этим значения в /etc/sysctl.conf:
vm.dirty_background_bytes=67108864 (64 МБ)
vm.dirty_bytes=536870912 (512 МБ)
Эта не только помогает повысить общую пропускную способность примерно на 2%, но и помогает избежать ситуаций резкого увеличения нагрузки в дисковой подсистеме ввода-вывода. Без настройки этих параметров вы увидите всплески количества страниц/килобайт, записываемых на диск в секунду. Применение упомянутых значений приводит к более стабильному времени отклика для конечных пользователей, поскольку сглаживаются всплески ввода-вывода.
Насколько именно вы уменьшите значения, не особенно важно. Но важно значительно снизить их по сравнению со значениями по умолчанию. Например, эксперименты с 32 МБ, 64 МБ и 128 МБ для vm.dirty_background_bytes не привели к существенным изменениям длительности восстановления БД, но оказалось, что 512 МБ снова увеличили продолжительность. 64 МБ считается разумным значением для vm.dirty_background_bytes, а также рекомендуется в других публикациях, связанных с PostgreSQL.
Рекомендация №2: желательно применять настройки PostgreSQL, сглаживающие время отклика конечного пользователя.
Существует ряд настроек PostgreSQL, которые на самом деле не увеличивают пропускную способность, но помогают сгладить время отклика конечного пользователя. Помните, что пропускная способность — не единственный важный показатель производительности.
Примечание: чтобы внести изменения в любой из параметров, нужно отредактировать файл /etc/postgresql/9.5/main/postgresql.conf. У вас путь может отличаться в зависимости от версии и путей установки БД.
Параметр №1: checkpoint_completion_target
значение по умолчанию для этого параметра равно 0,5;
во многих интернет-источниках, связанных с PostgreSQL, рекомендуется значение 0,9;
за: снижает нагрузку ввода-вывода от контрольных точек за счёт распределения контрольной точки на более длительный период времени;
против: продление контрольных точек влияет на время восстановления в случае сбоя.
Параметр №2: max_wal_size
значение по умолчанию для этого параметра — 1 ГБ;
во многих интернет-источниках, связанных с PostgreSQL, рекомендуется значение 16 ГБ;
за: контрольные точки возникают реже (проверьте /var/log/postgresql/postgresql-9.5-main.log), потому что для каждой контрольной точки может быть записано больше Write Ahead Log (WAL);
против: менее частые контрольные точки влияют на время восстановления в случае сбоя.
Параметр №3: wal_buffers
значение по умолчанию равно -1;
во многих интернет-источниках, связанных с PostgreSQL, рекомендуется значение 16 МБ;
за: меньше физических операций записи на диски из-за увеличенной буферизации данных WAL;
против: большее количество потерянных транзакций в случае сбоя.
Параметр №4: synchronous_commit
значение по умолчанию для этого параметра on;
значение, рекомендованное многими интернет-источниками, связанными с PostgreSQL, off;
за: немного улучшает время отклика, так как об успешном выполнении сообщается клиенту до того, как транзакция будет записана на диск;
против: может привести к потере транзакций.
Мы не рекомендуем отключать synchronous_commit, так как в тестовых случаях это не увеличило производительность. Кроме того, есть риск потери транзакций конечных пользователей.
Общие рекомендации способность
Рекомендация №1: добавьте немного области подкачки (swap space).
Желательно иметь хотя бы небольшой объём свободного swap space, чтобы быть готовым к пикам потребления памяти. В противном случае вы увидите активность OOM Killer. В нашей серии тестов были комбинации настроек, при которых добавление области подкачки увеличивало пропускную способность, а также комбинации настроек, при которых область подкачки не влияла на пропускную способность базы данных.
Хотя добавление swap space не влияло на производительность, оно имеет больше преимуществ, чем недостатков.
Рекомендация №2: используйте прямой ввод-вывод для логов транзакций.
Используя прямой ввод-вывод, база данных обходит кэш страниц Linux и записывает напрямую на диски, что позволяет избежать потери транзакций в случае сбоя.
Рекомендация №3: будьте осторожны с советами по Intel x86 Linux и другим версиям ядра.
В рассылки по производительности PostgreSQL есть популярный пост «Two Necessary Kernel Tweaks for Linux Systems», в котором пользователи говорят об увеличении пропускной способности до 30% . Однако советы касались Linux на Intel x86 и, скорее всего, версии ядра, отличной от той, что использовалась в наших тестовых прогонах. В нашей среде указанные настройки снизили пропускную способность примерно на 2%. Эти настройки были связаны с планировщиком Linux: kernel.sched_migration_cost и kernel.sched_autogroup_enabled.
Будьте осторожны с советами для Intel x86 и других версий ядра — они могут иметь противоположный эффект при применении к вашей среде.
Рекомендация №4. Отделите файлы данных от логов транзакций.
Это общая рекомендация для всех реляционных баз данных. Прирост производительности в «песочнице» был примерно на 10 % выше, потому что:
поведение ввода-вывода файлов данных было отделено от поведения ввода-вывода логов транзакций;
общее использование инфраструктуры сервера хранения стало лучше благодаря большему количеству дисков.
Прирост производительности в большой среде был близок к 0%. Одной из возможных причин этого является то, что мы использовали много разных номеров LUN для LVM, а каждый LUN сам по себе распределён по многим физическим дискам посредством чередования пула носителей DS8K.
Отделять файлы данных от логов транзакций рекомендуется из-за непредсказуемого характера рабочей нагрузки базы данных, которую предстоит развернуть. Кроме того, отделение файлов данных от логов транзакций не снижает производительности.
Важно: убедитесь, что диски для логов физически отличаются от дисков для файлов данных; в противном случае вы не ощутите никакой пользы. С точки зрения DS8K, если вы не можете гарантировать физически разные диски, вы можете использовать диски с разных серверов хранения.
Тестовая среда для измерения производительности и настройки подхода
Для установки PostgreSQL мы использовали систему IBM Z (z13) с подключенным сервером хранения DS8000. Генератор нагрузки, работающий на сервере Intel x86, был подключен к системе IBM Z через коммутатор.
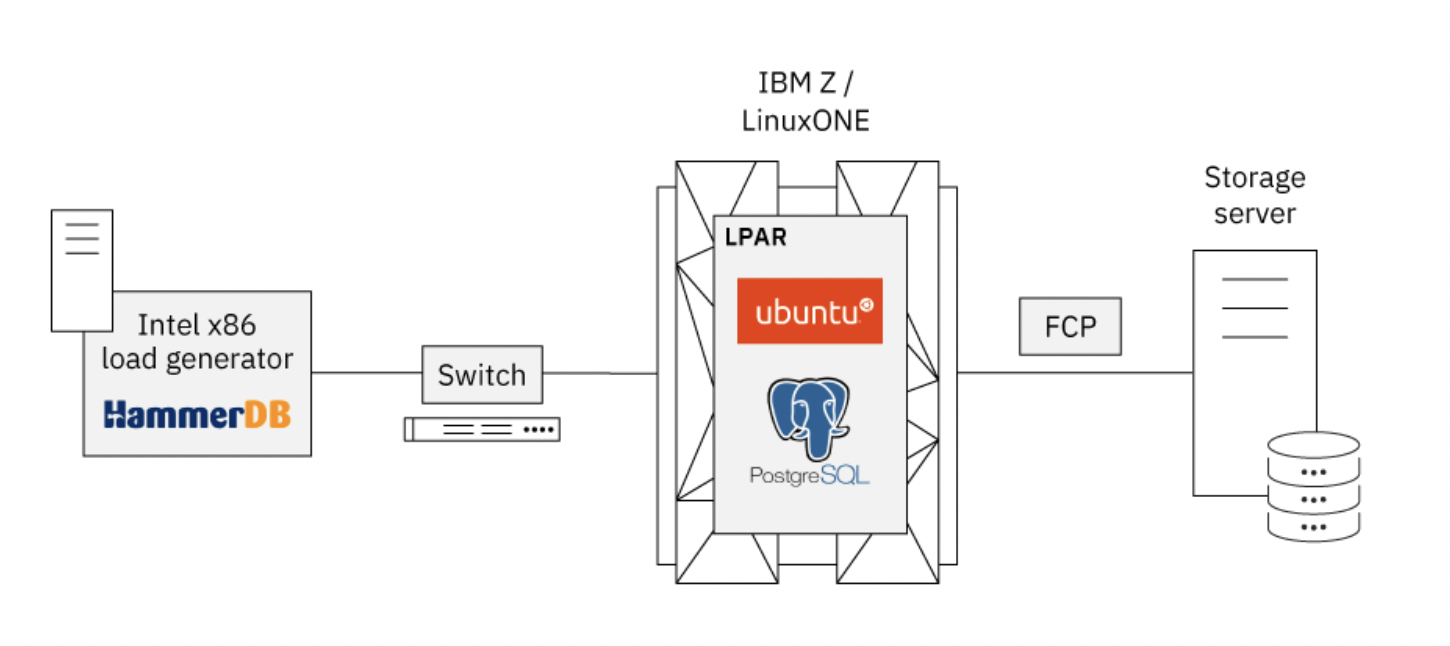
Мы выполнили следующие шаги для настройки тестовой среды:
Установили песочницу (sandbox environment), чтобы познакомиться с Ubuntu, PostgreSQL и HammerDB. Цель — создать как можно более простую среду и начать с готовой конфигурации.
Заполнили тестовую базу данных TPC-C встроенными функциями HammerDB.
Поместили тестируемую систему (SUT) под небольшую нагрузку, чтобы посмотреть, как она ведёт себя во время выполнения. На первый взгляд, PostgreSQL ведёт себя как любая другая современная база данных: она использует CPU и ввод-вывод.
Применили многочисленные параметры настройки на всех уровнях (ОС, ввод-вывод, база данных) в небольших тестовых прогонах, чтобы посмотреть, есть ли у них какой-либо эффект. Цель здесь заключалась в том, чтобы определить, следует ли оценивать параметры в больших тестовых прогонах.
Поработав с песочницей, настроили большую тестовую среду в собственном LPAR. Большая среда означает больше памяти (64 ГБ) и больше места на диске (размер базы данных 256 ГБ).
Применили дополнительные параметры настройки.
Реализовали сценарии автоматизированного тестирования на основе внутренней среды тестирования и собственных сценариев оболочки для выполнения идентичных тестовых прогонов. Результаты сохранили в базе данных вместе с данными sadc/sar и др.
Провели ночные запуски с использованием хоста IBM Z (IBM z13) и сервера хранения (DS8000). Цель — получить воспроизводимые результаты тестов.
Основная идея экспериментов состояла в том, чтобы получить практический набор параметров/переключателей, которые приведут к измеримым улучшениям производительности.
Коротко о главном
Во всех тестовых прогонах мы не столкнулись ни с одним сбоем или чем-то подобным. В рамках статьи мы опирались на работу в Linux на IBM Z, но вы можете значительно повысить производительность базы данных PostgreSQL, адаптируя перечисленные рекомендации под свои кейсы.

