Ежегодно Google проводит мероприятие Google Summer of Code, на котором ведущие OpenSource проекты находят себе новых талантливых разработчиков среди студентов. В 2019 нашему проекту CRIU удалось не только пройти отборочный тур, но также привлечь сразу несколько молодых разработчиков. О том, зачем все это, и как проходила работа над CRUI в рамках GSoC — читайте под катом.

У нас в Virtuozzo есть небольшой, но уже довольно популярный проект под названием CRIU. Это довольно сложная системная утилита и комплект патчей ядра (большая часть из их, к слову, уже принята в основное дерево ядра), с помощью которой можно делать такие вещи как, например, живую миграцию контейнеров или обновлять ядро без перезапуска приложений.

Начали мы этот проект ещё в 2011 году. И несмотря на то, что утилита изначально вызывала массу вопросов, а некоторые считали ее реализацию невозможной, CRIU постепенно превратилась в зрелый инструмент. На сегодняшний день в нём успело поучаствовать более полутора сотен контрибьюторов из нескольких десятков компаний, включая таких гигантов как Google и IBM. Несмотря на это поиск новых участников продолжается, и в этом году мы, наконец, попали на Google Summer of Code (GSoC).
GSoC это спонсируемое Google ежегодное мероприятие, цель которого – привлечение студентов в различные opensource-проекты. В мероприятии с одной стороны стремятся принять участие команды из открытых проектов, а с другой стороны – студенты, которые хотят сделать свой вклад в развитие комьюнити и доказать свой профессионализм на реальных проектах.
Чтобы выйти на GSoC команде требуется подать заявку с указанием описания проекта, нескольких тем, над которыми могут потрудиться студенты и список так называемых «менторов» – активных участников проекта, которые будут помогать студенту в его нелёгком труде. От студентов требуется выбрать один или несколько проектов и разослать менторам свои резюме.
В середине учебного года Google рассматривает заявки команд и выбирает проекты, которые будут участвовать, а ближе к летним каникулам команды выбирают студентов, с которыми они готовы работать, после чего Google осуществляет финальную фильтрацию и распределяет студентов по командам. Летом начинается работа, которая длится три месяца. Один раз в 30 дней студенты сдают промежуточные отчёты, а их менторы оценивают результаты и дают рекомендации к продолжению (или прекращению) работы.
Оптимизация памяти и внедрение бинарных логов
Признаюсь, что в 2019 году состоялась отнюдь не первая наша попытка выйти на GSoC. Просто до этого момента нам не удавалось пройти стадию отбора проектов со стороны Google. Но мы не сдавались (в общем-то не сложно ведь подать заявку), и, наконец, у нас всё получилось – в Google признали развитие нашего проекта важным и выпустили CRUI на GSoC.
У нас было много тем для студентов, причем одна другой краше и сложнее. Приятным сюрпризом оказалось то, что для каждой из них в сообществе нашлись исполнители. Были люди, разбирающийся в озвученных вопросах и готовые поработать в роли ментора. На этапе подачи заявок студентами мы получили целый «конкурс» – на каждую из тем претендовало по 2 студента и почти у всех были замечательные входные данные. Финальный отбор позволил нам получить двух студентов, которые взялись за темы оптимизации кода сохранения памяти с выполняющегося процесса, а также внедрения бинарных логов.
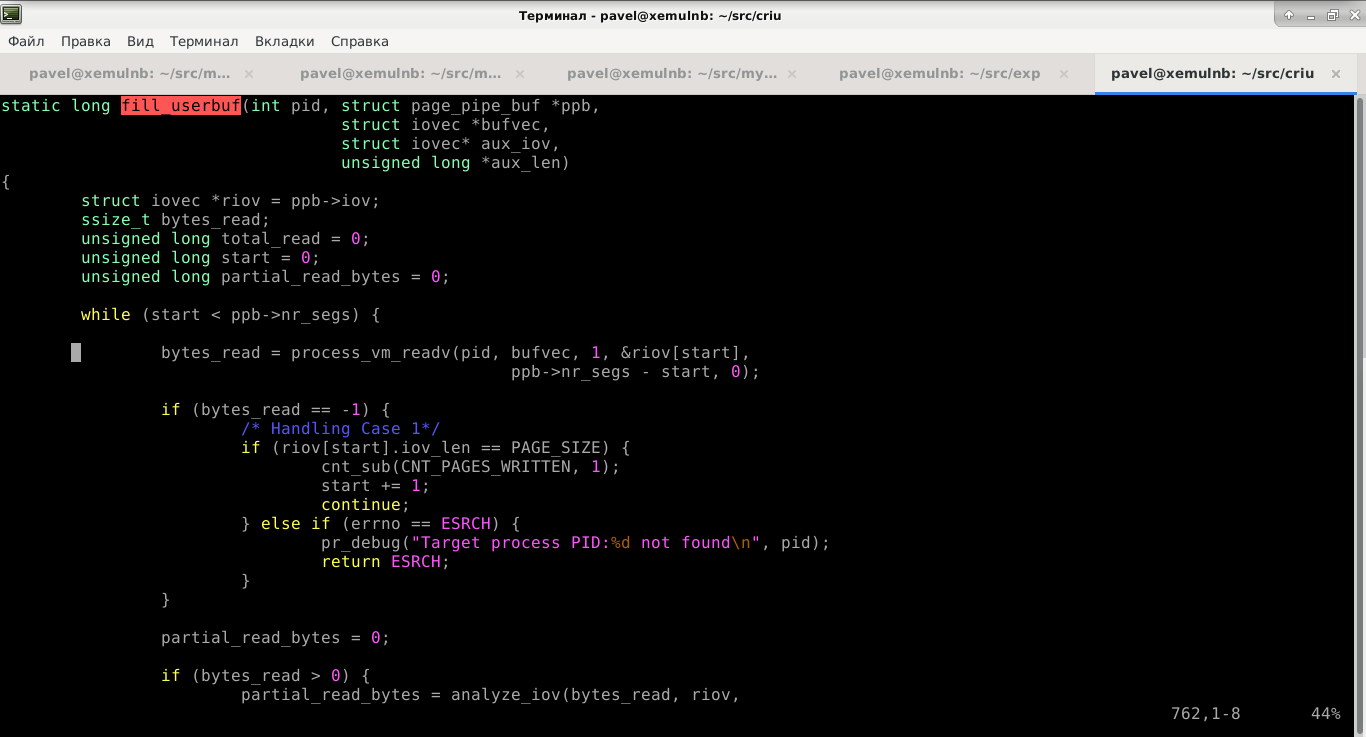
Поскольку CRIU – это система живой миграции приложений, в ней есть такой режим работы, когда память, которую использует процесс, считывается и записывается в файлы-образы параллельно с выполнением самого процесса. Мы называем это “операцией на живом сердце” процесса, ведь он продолжает работать без остановки. До раунда GSoC вся память вытягивалась в пайпы с помощью наделавшего в своё время шума системного вызова vmsplice, а затем процесс продолжал выполнение, а CRIU неспешно сбрасывала эту память в файлы (или в сетевой канал, если речь шла о живой миграции). В принципе это рабочий подход, но проблема заключалась в том, что память, находящаяся в пайпах является эффективно заблокированной (mlock) и ядро не может выгрузить её на диск (swap-out) в случае необходимости.
С точки зрения архитектуры мы хотели заменить пайпы на копирование памяти небольшими порциями с помощью вызова process_vm_readv. Это новшество появилось в ядре Linux не так давно (кстати, у этого вызова есть брат-близнец под названием process_vm_writev). Но при этом позволяет сильно облегчить и ускорить, например, работу утилиты strace и отладчиков, которые могут ковыряться в памяти процессов для решения каких-то других задач.
Работа над оптимизацией была осложнена тем, что код работы с памятью процесса является одним из центральных в утилите, а потому он должен быть абсолютно надёжным. Любая ошибка в сохранении страниц может привести к тому, что процесс получит несогласованное состояние своих внутренних объектов (про которые CRIU, конечно же, ничего не «знает») и после восстановления упадёт без какой-либо внятной диагностики.
Вторая трудность этой разработки состояла в том, что работа с памятью участвует почти во всех «фичах» CRIU. Это и обычные процедуры checkpoint-restore, это и разные оптимизированные её версии, например pre-dump или lazy-restore. Один раз во время очередной отчётной недели мы даже планировали «отчислить» студента из проекта, но, к счастью, не сделали этого и теперь в нашей devel ветке уже есть долгожданная оптимизация.
Второй задачей в рамках GSoC 2019 была разработка и внедрение так называемых бинарных логов. Дело здесь вот в чем: когда CRIU работает, утилита пишет в файл (или на экран, но лучше все-таки в файл) сообщения о своей работе. Важность этих сообщений огромна! Если процедура сохранения или восстановления по каким-то причинам не заканчивается успехом, то единственный способ понять причину – максимально подробно проанализировать каждый шаг, а для этого нужна информация о работе утилиты. В идеале для разбирательства нужны максимально подробные логи и файлы-образы, если они есть. На практике же такие требования оказывается тяжело удовлетворить.
Для получения максимально подробных логов в CRIU предусмотрен соответствующий режим, и подавляющее большинство пользователей (а может быть и вообще все) всегда активируют его. Но количество информации, которое генерирует criu в процессе работы настолько огромно, так что само протоколирование начинает заметно влиять на скорость работы системы. Небольшое исследование показало, что 90% времени в протоколировании мы тратим на операции форматирования вывода – то есть на «те самые» %d, %08s, %.2f и прочие модификаторы семейства функций printf. Выключение логов уменьшает время сохранения и восстановления процессов от 10 до 30 процентов, в зависимости от размера самих процессов.
Для того, чтобы выключить использование такого количества системных ресурсов на протоколирование, но оставить логи настолько же информативными, мы решили избавиться от форматирования и сохранять в лог-файлы двоичные данные. Ведь отформатировать их можно и потом, если потребуется. С этой задачей справился второй студент, чьи патчи тоже уже приняты в development ветку.
И не только на GSoC
Кстати, еще один интересный факт участия в GSoC заключается в том, что к нам пришел и третий студент, выразивший желание решать проблему анонимизации. Ведь получить файлы-образы часто бывает невозможно из-за того, что они содержат секретную информацию, которой пользователь справедливо не хочет ни с кем делиться – содержимое памяти, файлы, с которыми работает процесс, содержимое очередей в сетевых соединениях и так далее. Для того, чтобы решить эту проблему мы подавали в заявке фичу под названием «анонимизация образов», но Google её не принял.
Тем не менее, тема не потеряла актуальности, а студент, который хотел ей заниматься в рамках GSoC, в итоге принял решение работать над вопросом самостоятельно, вне мероприятия Google.
Заключение
Это был, безусловно, позитивный опыт участия в GSoC. Наш инструмент CRIU, который мы очень любим и ценим, получил еще пару мощных импульсов к развитию, стал еще более зрелым и удобным. Так что кому это может быть полезно, пользуйтесь с удовольствием!
С другой стороны, мы убедились в том, что вопрос участия в подобных мероприятиях – дело настойчивости и уверенности в своем проекте. Если вам нужны разработчики, просто не уставайте подавать заявки и формулировать новые, интересные темы. Возможно, вы найдете на них совершенно неожиданных контрибьюторов из другой страны или даже из другой компании.
У нас в Virtuozzo есть небольшой, но уже довольно популярный проект под названием CRIU. Это довольно сложная системная утилита и комплект патчей ядра (большая часть из их, к слову, уже принята в основное дерево ядра), с помощью которой можно делать такие вещи как, например, живую миграцию контейнеров или обновлять ядро без перезапуска приложений.
Начали мы этот проект ещё в 2011 году. И несмотря на то, что утилита изначально вызывала массу вопросов, а некоторые считали ее реализацию невозможной, CRIU постепенно превратилась в зрелый инструмент. На сегодняшний день в нём успело поучаствовать более полутора сотен контрибьюторов из нескольких десятков компаний, включая таких гигантов как Google и IBM. Несмотря на это поиск новых участников продолжается, и в этом году мы, наконец, попали на Google Summer of Code (GSoC).
GSoC это спонсируемое Google ежегодное мероприятие, цель которого – привлечение студентов в различные opensource-проекты. В мероприятии с одной стороны стремятся принять участие команды из открытых проектов, а с другой стороны – студенты, которые хотят сделать свой вклад в развитие комьюнити и доказать свой профессионализм на реальных проектах.
Чтобы выйти на GSoC команде требуется подать заявку с указанием описания проекта, нескольких тем, над которыми могут потрудиться студенты и список так называемых «менторов» – активных участников проекта, которые будут помогать студенту в его нелёгком труде. От студентов требуется выбрать один или несколько проектов и разослать менторам свои резюме.
В середине учебного года Google рассматривает заявки команд и выбирает проекты, которые будут участвовать, а ближе к летним каникулам команды выбирают студентов, с которыми они готовы работать, после чего Google осуществляет финальную фильтрацию и распределяет студентов по командам. Летом начинается работа, которая длится три месяца. Один раз в 30 дней студенты сдают промежуточные отчёты, а их менторы оценивают результаты и дают рекомендации к продолжению (или прекращению) работы.
Оптимизация памяти и внедрение бинарных логов
Признаюсь, что в 2019 году состоялась отнюдь не первая наша попытка выйти на GSoC. Просто до этого момента нам не удавалось пройти стадию отбора проектов со стороны Google. Но мы не сдавались (в общем-то не сложно ведь подать заявку), и, наконец, у нас всё получилось – в Google признали развитие нашего проекта важным и выпустили CRUI на GSoC.
У нас было много тем для студентов, причем одна другой краше и сложнее. Приятным сюрпризом оказалось то, что для каждой из них в сообществе нашлись исполнители. Были люди, разбирающийся в озвученных вопросах и готовые поработать в роли ментора. На этапе подачи заявок студентами мы получили целый «конкурс» – на каждую из тем претендовало по 2 студента и почти у всех были замечательные входные данные. Финальный отбор позволил нам получить двух студентов, которые взялись за темы оптимизации кода сохранения памяти с выполняющегося процесса, а также внедрения бинарных логов.
Поскольку CRIU – это система живой миграции приложений, в ней есть такой режим работы, когда память, которую использует процесс, считывается и записывается в файлы-образы параллельно с выполнением самого процесса. Мы называем это “операцией на живом сердце” процесса, ведь он продолжает работать без остановки. До раунда GSoC вся память вытягивалась в пайпы с помощью наделавшего в своё время шума системного вызова vmsplice, а затем процесс продолжал выполнение, а CRIU неспешно сбрасывала эту память в файлы (или в сетевой канал, если речь шла о живой миграции). В принципе это рабочий подход, но проблема заключалась в том, что память, находящаяся в пайпах является эффективно заблокированной (mlock) и ядро не может выгрузить её на диск (swap-out) в случае необходимости.
С точки зрения архитектуры мы хотели заменить пайпы на копирование памяти небольшими порциями с помощью вызова process_vm_readv. Это новшество появилось в ядре Linux не так давно (кстати, у этого вызова есть брат-близнец под названием process_vm_writev). Но при этом позволяет сильно облегчить и ускорить, например, работу утилиты strace и отладчиков, которые могут ковыряться в памяти процессов для решения каких-то других задач.
Работа над оптимизацией была осложнена тем, что код работы с памятью процесса является одним из центральных в утилите, а потому он должен быть абсолютно надёжным. Любая ошибка в сохранении страниц может привести к тому, что процесс получит несогласованное состояние своих внутренних объектов (про которые CRIU, конечно же, ничего не «знает») и после восстановления упадёт без какой-либо внятной диагностики.
Вторая трудность этой разработки состояла в том, что работа с памятью участвует почти во всех «фичах» CRIU. Это и обычные процедуры checkpoint-restore, это и разные оптимизированные её версии, например pre-dump или lazy-restore. Один раз во время очередной отчётной недели мы даже планировали «отчислить» студента из проекта, но, к счастью, не сделали этого и теперь в нашей devel ветке уже есть долгожданная оптимизация.
Второй задачей в рамках GSoC 2019 была разработка и внедрение так называемых бинарных логов. Дело здесь вот в чем: когда CRIU работает, утилита пишет в файл (или на экран, но лучше все-таки в файл) сообщения о своей работе. Важность этих сообщений огромна! Если процедура сохранения или восстановления по каким-то причинам не заканчивается успехом, то единственный способ понять причину – максимально подробно проанализировать каждый шаг, а для этого нужна информация о работе утилиты. В идеале для разбирательства нужны максимально подробные логи и файлы-образы, если они есть. На практике же такие требования оказывается тяжело удовлетворить.
Для получения максимально подробных логов в CRIU предусмотрен соответствующий режим, и подавляющее большинство пользователей (а может быть и вообще все) всегда активируют его. Но количество информации, которое генерирует criu в процессе работы настолько огромно, так что само протоколирование начинает заметно влиять на скорость работы системы. Небольшое исследование показало, что 90% времени в протоколировании мы тратим на операции форматирования вывода – то есть на «те самые» %d, %08s, %.2f и прочие модификаторы семейства функций printf. Выключение логов уменьшает время сохранения и восстановления процессов от 10 до 30 процентов, в зависимости от размера самих процессов.
Для того, чтобы выключить использование такого количества системных ресурсов на протоколирование, но оставить логи настолько же информативными, мы решили избавиться от форматирования и сохранять в лог-файлы двоичные данные. Ведь отформатировать их можно и потом, если потребуется. С этой задачей справился второй студент, чьи патчи тоже уже приняты в development ветку.
И не только на GSoC
Кстати, еще один интересный факт участия в GSoC заключается в том, что к нам пришел и третий студент, выразивший желание решать проблему анонимизации. Ведь получить файлы-образы часто бывает невозможно из-за того, что они содержат секретную информацию, которой пользователь справедливо не хочет ни с кем делиться – содержимое памяти, файлы, с которыми работает процесс, содержимое очередей в сетевых соединениях и так далее. Для того, чтобы решить эту проблему мы подавали в заявке фичу под названием «анонимизация образов», но Google её не принял.
Тем не менее, тема не потеряла актуальности, а студент, который хотел ей заниматься в рамках GSoC, в итоге принял решение работать над вопросом самостоятельно, вне мероприятия Google.
Заключение
Это был, безусловно, позитивный опыт участия в GSoC. Наш инструмент CRIU, который мы очень любим и ценим, получил еще пару мощных импульсов к развитию, стал еще более зрелым и удобным. Так что кому это может быть полезно, пользуйтесь с удовольствием!
С другой стороны, мы убедились в том, что вопрос участия в подобных мероприятиях – дело настойчивости и уверенности в своем проекте. Если вам нужны разработчики, просто не уставайте подавать заявки и формулировать новые, интересные темы. Возможно, вы найдете на них совершенно неожиданных контрибьюторов из другой страны или даже из другой компании.
