Comments 169
Я как-то на докладе слышал историю от mail.ru про их переход с mysql на postgesql. В числе прочего там были забавные баги mysql (вроде повтора значений, в некоторых условиях, автоинкрементного поля)
Перевод статьи про миграцию Uber с Postgres на MySQL
Вольный краткий пересказ, на истинность не претендую =)
Извиняюсь за оффтоп, но
постгри
так лучше не писать и не говорить
PostgreSQL создана на основе некоммерческой СУБД Postgres… более раннего проекта Ingres… Название расшифровывалось как «Post Ingres»
Да я просто привык уже говорить мускуль и постгря, это большинству разрабов сталкивавшихся с СУБД понятно. Многие разрабы, с которыми мне доводилось работать, говорили либо постгря, либо постгрес, лишь единицы называли полностью постгреэскуэл(ь), и ни разу не слышал «Пост-Грэс-Кью-Эл»
Википедия вполне признаёт /ˈsiːkwəl/ "sequel":
SQL was initially developed at IBM by Donald D. Chamberlin and Raymond F. Boyce after learning about the relational model from Ted Codd in the early 1970s. This version, initially called SEQUEL (Structured English Query Language)...
мускуль и постгря, это большинству разрабов...
Вы добавили непонятное слово «разраб».

Везде есть свой сленг. И ИМХО по русски более правильно будет сформированное слово «постгри» чем «постгрес». Но это тема другого сайта.
Локальная база в какой-то степени обычно используется. И, подозреваю, что с ней тоже могут быть тайм-ауты, и надо немного думать про идемпотентность.
Если, например, изменять заказы сначала локально, а потом синкать на сервер, то либо придётся жертвовать мультидевайсностью (показывать все заказы на всех устройствах), либо решать проблему синхронизации изменений при изменении заказа с двух устройств около-одновременно.
продуктово было согласовано, что недоставка нотификаций лучше, чем их дублирование
Мне кажется, лучше получить две смски о том, что такси приехало, чем ни одной.
В простейшей реализации выбор стоит не между 0 и 2 SMS, а между 0 и n (например, 100) SMS. Я сталкивался на одном из прошлых мест работы с тем, как пользователю приходят десятки сообщений из-за подобной логики.
Можно пытаться запоминать в базе число попыток отправить SMS и применять at least once семантику на первые 3 попытки, а потом отбрасывать. Но здесь есть схожая проблема: что если произошел таймаут при запоминании факта попытки отправки SMS: выбирать at least once, или at most once семантику.
Обычно, семантика выбирается в зависимости от важности конкретного типа SMS.
На самом деле введением кучи ограничений на consumer-ов и небольшим количеством сносок к термину «exactly once» (exactly once гаранитируется только на ветке producer->kafka и только в смысле «в кафке не будет дублирования сообщений» при этом не гарантируется что при отправке следующего дубля producer узнает что отправляет дубль)
Васе нужно было не прогуливать институт, научился бы рисовать алгоритм в виде ромбиков, прямоугольников и параллелепипедов. Наструячил бы фломастерами на доске это API целиком и глядишь попроще жизнь оказалась бы.
Вот, когда читал доки мелкомягких по REST API, особо не обратил внимание на принцип идемпотентности, а зря. Казалось бы, ан нет…
По-хорошему, Васе нужно было на нулевом шаге сообщить менеджерам, что нужен аналитик
Если Вася всего лишь кодер — то да.
Если он все же разработчик — аналитик тут не нужен. Тут задача не такая уж и сложная, чтобы квалифицированный разработчик сам не разрешил.
Ну очевидно, что прогер работающий только по разжеванному ТЗ, ценится меньше. А дальше уже каждому решать кем ему быть…
Очевидно, я был неправильно понят. Я не говорю, что хорошему прогеру всё нужно разжёвывать до уровня псевдокода. Но, тем не менее, он НЕ ДОЛЖЕН сам пытаться понять все требования к системе, потому что это, в общем-то, не его работа. Если программиста бросить на какую-то задачу, не сообщив НИЧЕГО хотя бы о требованиях к системе, то там прод будет с каждым обновлением падать. Это как сказать столяру: «А бахни-ка мне, голубчик, кухонный гарнитур», не уточнив, кухня на 6 квадратов или на 60. Бахнуть-то он, может, и бахнет, только не то, что надо.
а достаточно хранить только айдишник последнего запроса клиента и потом когда клиент после разрыва связи снова соединится с сервером он должен в первую очередь загрузить этот айдишник и проверить совпадает ли он с последним отправленным запросом и если совпадает тогда отменить запросы которые ждут повторной отправки
Любая проблема имеет очень простое для понимания неправильное решение (с)
Сценарий: было TCP-соединение, отправлялись запросы, дальше:
в полёте запросы 7 и 8
соединение разрывается, но сначала у клиента
клиент открывает новое соединение
в этот момент сервер читает из буфера сокета запрос 7
клиент запрашивает id последнего, получает 6 или 7, для дальнейшего некритично
сервер дочитывает из буфера сокета 7 и 8, исполняет их
клиент отправляет по новому соединению, возможно, запрос 7, и точно запрос 8
сервер получил ошибку разрыва первого соединения
сервер заново обрабатывает запросы 8 и мб 7 из нового соединения - OOPS!
Итого. Даже если в эту схему вводить нюансы типа "это номер обработанного запроса или еще только полученног", всё равно дубликаты будут.
Правильное решение - только уникальные идентификаторы сообщений, не завязыватьсян а их порядок, и система подтверждений, как в MQTT на QoS 1 или 2.
2 Приложение получает ответ-подтверждение запроса (в ответе содержится уникальный ключ)
Если ответ не получен — повторяем запрос, пока не получим ответ(естетвенно обрабатываем ошибки таймауты и т.п. чтобы пользователь не озверел от ожидания)
3 показывает пользователю что заказ принят
4 Получив ответ посылает запрос об успешном получении ответа с заказом
5 сервер считает заказ принятым только если от приложения пришел запрос об успешном получении ответа
шаги 4 -5 могут идти фоново, пользователь думает что все в порядке
приложение периодичеки обновляет информацию о заказе
если шаг 4 так и не прошел до сервера, то через 1-2 минуты статус заказ меняется на ошибку(очень маловероятно). Если пользователь закрыл приложение а заказ не потвердился — звоним ему, пишем смс
Здесь та же проблема: на шаге 5 сервер мог получить подтверждение о получении заказа, но клиент об этом не узнает (не получив ответ). Если тогда через 1-2 минуты клиент покажет ошибку — пользователь подумает, что такси заказать не удалось, но машина неожиданно приедет.
Если каждый из них позвонит в техподдержку и проматерится всего лишь 3 минуты, нагрузка на колл-центр будет 1000*3/60 = 50 часов.
Процентов 20 из этих клиентов рано или поздно оставит в интернетах комментарий в стиле «вот уроды», процентов 5 не поленится поставить приложению минимальную отметку. Счастливчики, попавшие на этот баг второй раз, 100% уйдут к конкурентам.
Сначала хипсторы возьмут неправильную технологию (stateless REST), потом придумывают умные слова почему задачу нельзя решить.
Сколько десятилетий протоколу TCP? Ну да, немодно это… зато будет работать и без 0,0001% ошибок.
Мобильное приложение открыло TCP соединение, в нем отправило ID клиента, ID поездки (чтобы можно было несколько машин вызывать), адрес. [в СУБД начинается транзакция]
Сервер шлёт «stage1»
клиент отвечает «stage1confirmed» [клиент начинает писать «бронирование авто»]
сервер шлёт «stage2»
клиент отвечает «stage2confirmed»
клиент отправляет FIN, если сервер его получает, СУБД делает COMMIT, если нет, то ROLLBACK. Если клиент не ловит финальный ACK, мобильное приложение через несколько секунд делает обычный REST запрос статуса заказа (это те самые 0.000001%). Они тоже учтены.
[мобильное приложение пишет «машина выехала»]
>После разрыва TCP-соединения сервер тоже не сможет отправить клиенту уточняющий запрос.
Когда заказ создан, клиент poll-ит сервер через rest, серверу ничего не надо отправлять.
Если клиент не ловит финальный ACK, мобильное приложение через несколько секунд делает обычный REST запрос статуса заказа (это те самые 0.000001%)
А если нет связи?
Давайте посмотрим примеры из обсуждаемой статьи. Пользователь нажал "заказать такси" и тут пропала связь. Вы будете разблокировать кнопку или нет?
Ну и ещё момент. Всё, что вы написали, может быть реализовано в рамках HTTP-запросов. Вы нигде не использовали особые фичи TCP.
100% надежный детект того, что «что-то пошло не так» я предложил.
KYuri, Вы серьёзно? БД колом встанет
Вы серьёзно используете СУБД которая встаёт колом от 3.9 транзацкий в сек? 10000000/30/84600
>Вы нигде не использовали особые фичи TCP
У TCP нет «особых фич», потому что это надстройка над IP.
Хипсторам конечно по душе над statefull TCP громоздить stateless REST, потом костыльнуть поверх него statefull протокол. Приправить умными словечками, брейнстормить, пучить, таращить, попивать смузи,
писать статьи как правильно строить хайлоад.
Вы серьёзно используете СУБД которая встаёт колом от 3.9 транзацкий в сек?БД встаёт колом не от требуемой скорости обработки транзакций, а от наличия взаимоблокировок.
Каждая взаимная блокировка увеличивает шанс, что произойдёт следующая — происходит лавинообразный рост блокировок и БД встаёт колом.
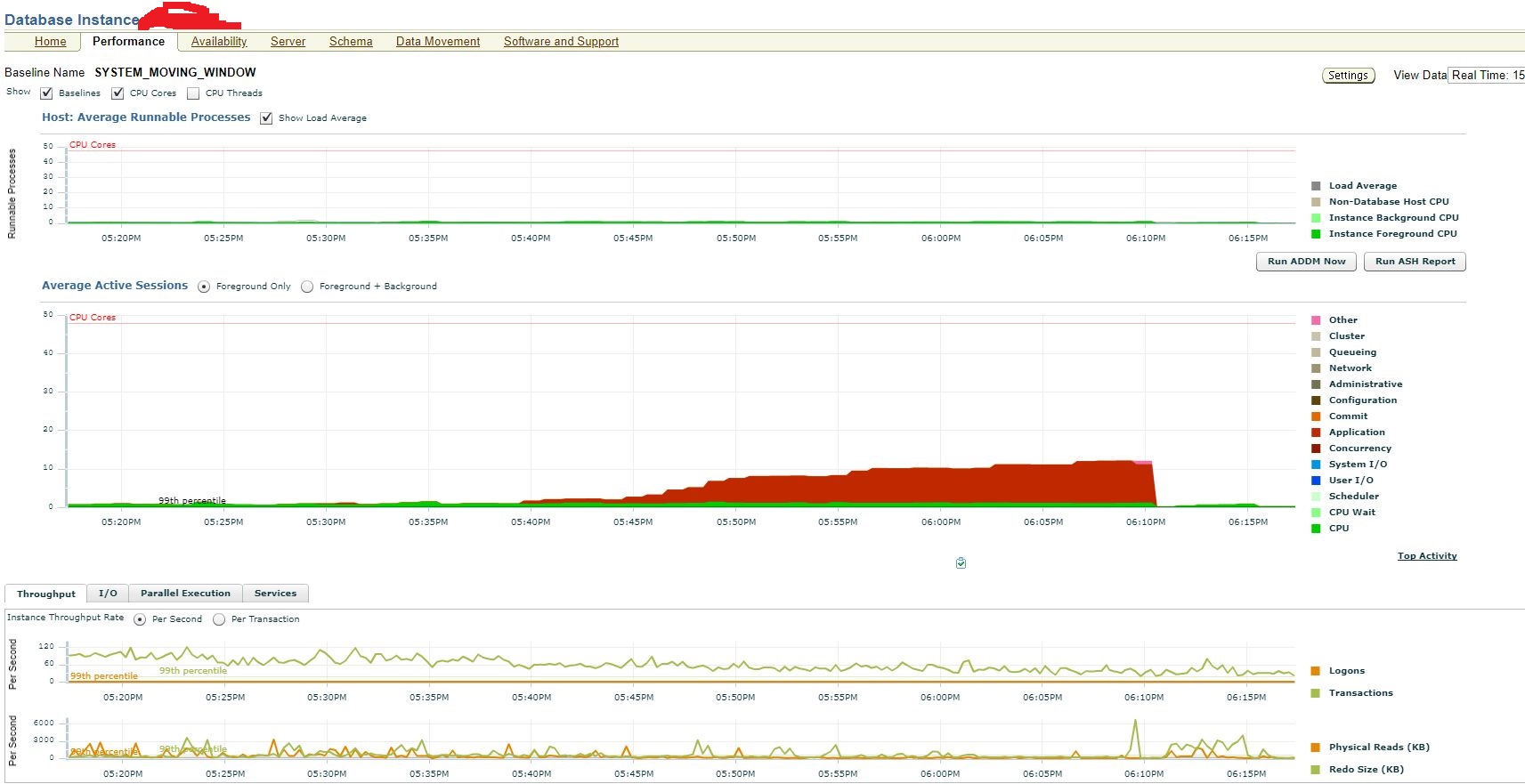

Именно поэтому транзакции должны быть как можно более короткими, и уж точно никак не зависеть от внешних условий.
А то, что Вы продолжаете утверждать, что «при 3.9 транзакций в секунду» (3.9 — это средняя нагрузка, при допущении, что «десятки миллионов» = «десять миллионов», а не, допустим, «девяносто миллионов»; пиковая же нагрузка может быть и на два, а то и на три порядка больше) можно на всё забить, говорит лишь о том, что практического опыта у Вас нет.
БД встаёт колом не от требуемой скорости обработки транзакций, а от наличия взаимоблокировок
Коли взялся поучать, следи за своими словами. У пряморукого ДБА база колом встаёт как раз от количества транзакций, большим количеством которых реляционные СУБД похвастать не могут.
Дедлоки ещё приплёл. Они возникают не от мифического «Каждая взаимная блокировка увеличивает шанс, что произойдёт следующая», а когда две или более совершенно чётко прописанные в доках блокировки начинают ждать друг друга.
С временем нахождения в транзакции это связано очень слабо, а с косорукостью очень сильно.
Подрастёшь, узнаешь, что в ORM например вообще не управляешь транзакциями СУБД и ничего, живёт как-то народ.
Совсем подрастёшь, узнаешь, что бывают штуки навроде JTA XA Transactions, транзакции размазанные на большое число бэкендов. И ничего, живут как-то.
С временем нахождения в транзакции это связано очень слабо, а с косорукостью очень сильно.
Со временем нахождения в транзакции это связано напрямую: при постоянном потоке транзакций вероятность неудачного пересечения транзакций прямо пропорциональна средней длительности транзакций.
Подрастёшь, узнаешь, что в ORM например вообще не управляешь транзакциями СУБД и ничего, живёт как-то народ.
Если программист оставил транзакции на ORM — значит, ORM будет использовать короткие транзакции. Проблема в том, что тремя комментариями выше вы предложили схему, в которой транзакция может неограниченно растягиваться.
У пряморукого ДБА...
это связано… с косорукостью очень сильно
К какой категории своё предложение (стартануть транзакцию, и уйти в сетевой обмен) отнесёте?
…Вы серьёзно? Держать активную транзакцию всё время сетевого обмена? Не боитесь, что БД колом встанет?
[в СУБД начинается транзакция]
Сервер шлёт…
клиент отвечает…
сервер шлёт…
клиент отвечает…
клиент отправляет FIN, если сервер его получает, СУБД делает COMMIT, если нет, то ROLLBACK.
Открыли TCP соединение, в нем отправили свой ID клиента, ID поездки (чтобы можно было несколько машин вызывать), адрес. В СУБД начинается транзакция.
Сервер шлёт «stage1»
клиент отвечает «stage1confirmed» [с этого момента у клиента начинает писать «начато бронирование авто»]
сервер шлёт «stage2» [с этого момента у клиента начинает писать «авто в пути»]
клиент отвечает «stage2confirmed»
с клиента должен прилететь FIN, если это происходит СУБД делает COMMIT, если нет, то ROLLBACK. Финальный ACK мобильному приложению уже не роляет, в любом случае процесс пошёл.
Слово математикам, что может пойти не так?
>После разрыва TCP-соединения сервер тоже не сможет отправить клиенту уточняющий запрос
Для обновлений статуса (где едет машина) REST уже вполне уместен.
А всё очень просто - нужно показывать информативные ошибки типа "нет связи с сервером", а не "что-то пошло не так". Тогда пользователь догадается, что машина может и едет.
2. Приложение получает ответ-подтверждение запроса (в ответе содержится уникальный ключ), крутилка превращается в «заказано»
3. Если сервер не ответил за таймаут, отправляем с темже ключом.
4. При получении запроса сервер проверяет, обработано ли сообщение с таким ключом. Если обработано — возвращает результат обработки, если не обработано — обрабатывает. Обработка — транзакционная, при попытке параллельной обработки один запрос отрабатывает, воторой отваливается на юниккей, в обоих случаях приложению возвращается результат обработки (в данном случае — успешно)
1. клиент отправляет заявку, заявка создается, но ответ от сервера не был получен, интернет вообще пропал на какое-то время
2. проходит какое-то время
3. сервер начинает шедулить заявки: искать дубли заявок и выбирать исполнителя.
4. сервер назначает водителя
5. у клиента отвисает интернет и он повторяет исходный запрос создания заявки
6. создается дублирующая заявка
7. по этой дублирующей заявке позже приезжает второе такси
Не понимаю идеи, чем заявки на создание заказа помогают?
на любое количество одинаковых заявок создается один заказ
звучит слишком абстрактно, я привел кейс выше, как в нем избежать дублирования без использования хотя бы ключа идемпотентности?
Клиент заказал такси, а затем кто-то из его же дома и квартиры попросил его заказать еще одну машину. А потом еще одну. Абсолютно нормальная ситуация, которая иногда случается. По-крайней мере, у меня. Система ругается и говорит, что это невозможная ситуация и приезжает одна машина.
Case 2:
Человек встречает гостей и в конце вечера трое из них независимо друг от друга заказывают такси. Приезжает одно такси на всех, потому что у всех один адрес.
Абсолютно нормальная ситуация, которая иногда случается. По-крайней мере, у меня
Конечно, разъезжаются люди с вечеринки, например.
Отображать клиенту что одна машина заказана, перед оптправлением заявки спрашивать: хотите заказать 2-ю машину, отправлять на сервер заявку на заказ _второй_ машины.
Case 2
Как уже было сказано, заявка идентифицируется id клиента и адресом, три человека получат три разных машины.
order handling можно разбить на order negotiation и order fulfillment. Таким образом, заказ на третью машину будет принят, но его можно результировать в нотификацию о лимите вместо выполнения.
И проблема тут фундаментальная: математически доказано что никакое конечное число подтверждений не может дать гарантии, см. задачу о двух генералах.
Клиент заказ N1 -> Сервер подтверждение N1 -> Клиент адрес для N1 -> Сервер номер такси для N1 -> Клиент отобразил заказ.
Первые два этапа установление соединения, только потом данные или разрыв соединения по таймауту или инициативе клиента, сервера. Клиент может одновременно открыть хоть 1, 2… 10 заказов ничего страшного. Все заказы уникальны, сервер и клиент знают их номера, договариваются на первых двух этапах.
Если сравнивать операцию создания заказа с открытием TCP соединения, то в случае ее неидемпотентности либо приезжает лишнее такси, либо создается лишнее соединение. Первое намного критичнее второго.
Если сравнивать операцию изменения заказа с посылкой данных по TCP соединению, то у TCP есть sequence numbers (в какой-то степени аналогия с версионированием списка заказов и ключа идемпотентности) для защиты от дублирования, переупорядочивания и тп.
либо создается лишнее соединениеИсключено т.к. соединение либо создается, либо нет, и такси ищется только один раз. Пока клиент не получит номер такси, он номер заказа не меняет. Только если решил сделать ещё один заказ, установить два соединения.
Клиент заказ N1 -> Сервер подтверждение N1 -> Клиент адрес для N1 -> Сервер (соединение установлено) Ищем такси -> Клиент (соединение установлено) отобразил заказ, номер такси.
Только, если клиент действительно хочет сделать два заказа, клиент работает с двумя номерами заказа. Повторюсь, пока клиент не получит номер такси, он номер заказа не меняет.
Для защиты еще можно ввести команду список заказов, но это, возможно, лишнее. А вот PING заказа на сервере, каждые 1-2 минуты клёвское дело, тем более статус заказа в любом случае мониторить.
Он(кеш) отправляется при каждой посылке пакета в обе стороны, клиенту для установки, на сервер для контроля.
при п1 — кеш = ""
при п5 у клиента кеш = "" а на сайте «заявка1фывфвыфв»
из за разности кеша заявка 5 не выполняется и клиенту отсылается текущее состояние с текущем кешом «заявка1фывфвыфв»
Сервер атомарно с изменением увеличивает версию при любых изменениях заказовНельзя ли в таком случае вместе с запросом отправлять с клиента просто хеш от известного списка заказов, а на сервере сравнивать с хешем актуального серверного списка.
И если это состояние заказов (версия) расходится с тем, что хранится на сервере
Также стоит отметить, что версия может быть как числом (номером последнего изменения), так и хэшом от списка заказов: так, например, работает параметр `fingerprint` в Google Cloud API для изменения тегов инстансов.
Это позволяет не пересылать весь список заказов обратно на сервер и не сравнивать его с текущим положением дел в БД. Если БД при каждом обновлении инфы конкретного клиента увеличивает версию, то это гарантирует, что при отличии версии пришёл старый запрос.
Вы наверно про другую ошибку, когда приехало 2 такси. Я говорю про случай, когда клиент сделал заказ, получил ошибку, потом или он через пуш или диспетчер отменили заказ, он удалился из бд а клиент сделал новый заказ. Почему приехало отменённое такси если записи в бд нету?
сценарий 2 сюда скопирую для удобства:
- клиент отправляет запрос на создание заказа, заказ создается, но мобильная сеть лагает, и клиент не получает ответ об успешном создании заказа;
- диспетчер, либо сам клиент через пуш по какой-то причине отменяет заказ: отмена заказа сделана как удаление строки из таблицы базы данных;
- клиент шлет повторный запрос на создание заказа: запрос успешно выполняется и создается еще один заказ, так как ключ идемпотентности, хранившийся в прошлом заказе, больше не существует в таблице.
Почему приехало отменённое такси если записи в бд нету
Потому что на третьем шаге первый запрос успешно повторяется, и он снова инсертит в базу запись о заказе. После этого выезжает машина. Но пользователь уже мог закрыть приложение, убрать телефон. И тогда пользователь может даже не узнать, что к нему такси приехало.
То есть, на шаге 3 приложение отправило повторный запрос и создало еще один заказ.
Т.к. клиент (приложение) не в курсе того, что заказ был создан на шаге 1.
— Отправка заказа на сервер: клиентское приложение стучит на сервер до тех пор, пока не сработает заранее определенный таймаут или не получит нужный ответ
— На сервере проверяем есть ли уже команда с таким уид, если нет, то выполняем
— Если это команда на создание заказа, выставляем ее статус как пока не подтвержденная
— Клиентское приложение спрашивает о состоянии заказа с уид: его просит подтвердить заказ (приложение должно само отправить true например). Заказ помечается как созданный и по нему дальше производятся действия.
Соответственно, любая команда с клиентского устройства должна выполняться таким образом: отправка на сервер, резервирование, ожидание подтверждения от клиентского устройства, выполнение. Либо отвал по таймауту.
Для клиента это будет выглядеть как спиннер, который «подождите, проводится операция», который потом меняется или на «таймаут, нажмите снова» или на «ок, выполнено».
Для верности на клиентский девайс должны приходить актуальные версии того, что происходит — заказы, чаты и т.п., раз в какое-то время (сам забирать)
зачем эта вся идео-както-там, простите, история?
Это все похоже на попытку скрыть плохой алгоритм работы очень хорошим термином, который только что вычитал в интернетах.
Уникальный уид у каждой команды — аналог ключа идемпотентности из статьи.
— На сервере проверяем есть ли уже команда с таким уид, если нет, то выполняем
Важный нюанс: для микросервисной архитектуры может не получиться просто так взять и сделать для всех API в одном месте в коде такую проверку идемпотентности. Потому что часто в микросервисных архитектурах у каждого сервиса своя база данных, а для работы этой логики нужно атомарное сохранение уида и изменения/создания заказа. Для этого нужна распределенная транзакция, что далеко нетривиально.
— Клиентское приложение спрашивает о состоянии заказа с уид: его просит подтвердить заказ (приложение должно само отправить true например). Заказ помечается как созданный и по нему дальше производятся действия.
А зачем этот шаг? Если приложение само отправляет подтверждение всегда, то я выше писал комментарий про задачу о двух генералах, что проблемы остаются те же. Если пользователь должен интерфейсно нажать какое-то подтверждение у заказа, тогда это защитит от ряда дублей, но ценой лишнего клика.
Для этого нужна распределенная транзакция, что далеко нетривиально.
Использовать key-value хранилище, умеющее в шардинг, их много на выбор.
Если пользователь должен интерфейсно нажать какое-то подтверждение у заказа, тогда это защитит от ряда дублей, но ценой лишнего клика.
Он не должен. Приложение должно. Фактически, каждый клик пользователя порождает задачу в очереди на клиентском устройстве. Сообщение считается доставленным тогда, когда с сервера получен ожидаемый ответ или ошибка, или срок доставки истек.
Все сценарии можно проработать.
А не должно быть идемпотентности тут и разных баз данных, тем более с распределенными транзакциями. Более простым образом это называется "система очередей", с обеспечением доставки at least once (QoS=1 в MQTT) и at most once (QoS=2 в MQTT).
Более простым образом это называется "система очередей", с обеспечением доставки at least once (QoS=1 в MQTT) и at most once (QoS=2 в MQTT). А попытка наворотить на идемпотентности, действительно, решение из совершенно другой сферы для других целей.
Но мультизаказ полностью ломал Васину схему защиты от дублейА разве нельзя было сделать так: раз приложение знает, что у же есть какой-то заказ, а пользователь хочет сделать второй, то этот самый пользователь указывает: «да, я хочу вторую машину». Приложение заказа такси шлёт в api дополнительный параметр: это дополнительная вторая машина &additional_taxi=2.
Бэкенд делает такую блокировку:
UPDATE active_orders SET n=2 WHERE user_id={user_id} AND n=1;И у нас больше нет проблемы с ключами идемпотентности, т.к. сразу с тех пор, как вы их внедрили, у вас кажется появилось еще больше проблем, чем было до этого.
Например вот:
Например, при повторном вызове идемпотентного API создания заказа — заказ не будет создаваться еще раз...Вы придумали использовать уникальный ключ идемпотентности, который будет одинаковый для всех заказов этого клиента в течение 24 часов. То есть придумываете ID, который должен быть каждый раз уникальным, но он у вас не уникален. А затем вы боретесь с тем, что этот ваш неуникальный ключ всегда повторяется, и используете кучу костылей для исправления этой неуникальности.
… Вася предложил Феде генерировать новый ключ идемпотентности в таком случае. Но Федя объяснил, что тогда может быть дубль: при сетевой ошибке запроса создания заказа клиент не может знать, был ли действительно заказ создан.Как по мне, это самая хорошая идея — генерировать новый ключ, но не при каждом чихе, а лишь когда сервер точно-точно ответил, что всё ок, заказ создан, и что теперь то можно клиенту наконец-то сгенерировать новый ключ для всех будущих обращений. А если связь лаганула, ответ от сервера не дошел до клиента, и клиент не знает, что заказ сделан, то при следующем возобновлении связи, либо каждые N секунд спрашивать у сервера: «Ну что там с моим ключем идемпотентности? Заказ в итоге создался? А то ответа от тебя не получил...» и в любом случае ответа сервера(да заказ создался/нет заказ не создался), сгенерировать новый ключ для будущих заказов.
А то вы сначала делаете уникальный ID, а затем мучаетесь от того, что этот ID неуникален следующие 24 часа, и снова вводите почти те же костыли что и вводили до этого.
Генерировать новый ключ, но не при каждом чихе, а лишь когда сервер точно-точно ответил, что всё ок, заказ создан, и что теперь то можно клиенту наконец-то сгенерировать новый ключ для всех будущих обращений.
Все же не совсем корректно, клиент может захотеть выполнить две разные операции подряд. Например, написать в чат водителю и заказать еще авто. Ну или дозаказать еще авто.
Само приложение знает что это разные операции, и никто ему не мешает присваивать им разные уиды.
Наличие разных уидов для разных команд позволит спокойно класть все это дело в очередь и пытаться доставить на сервер.
Спасибо, схема с &additional_taxi={n} выглядит интересно. Подозреваю, что дубли и гонки могут быть в сценариях подобных такому:
- пользовател создал заказ №1
- пользователь отправляет запрос на создание заказа №2 с параметром
&additional_taxi={2} - заказ создается, ответ от сервер не доходит до клиента, клиент начинает ретраить запрос
- параллельно диспетчером/водителем отменяется заказ №1, что уменьшает
nв таблицеactive_ordersc 2 до 1 - запрос на создание заказа №2 отретраился и успешно создал дубль
Вы придумали использовать уникальный ключ идемпотентности, который будет одинаковый для всех заказов этого клиента в течение 24 часов. То есть придумываете ID, который должен быть каждый раз уникальным, но он у вас не уникален. А затем вы боретесь с тем, что этот ваш неуникальный ключ всегда повторяется, и используете кучу костылей для исправления этой неуникальности.
Не совсем: ключ идемпотентности надо генерировать новый под каждый уникальный (в интерфейсе) заказ, а не использовать один для всех заказов.
Здравствуйте. Спасибо за статью. С помощью какого интструмента можно эмулировать сетевую ошибку ?
Здравствуйте.
Во-первых, стоит эмулировать как медленные запросы, приводящие к таймаутам, так и просто быстрый connection refused.
Во-вторых, для ручного эмулирования плохой сети на серверной машине я обычно использовал iptables, есть еще netem.
В-третьих, в девелоперской консоли хрома можно сэмулировать медленное мобильное соединение.
В-четвертых, можно протестировать один раз потерю пакетов, но код дописывается постоянно, баги возникают постоянно, и оно уже не тестируется. Есть chaos engineering: эмулировать сетевые ошибки (и не только: падения сервисов и тп) в продакшене регулярно. Например, есть chaos monkey и chaoskube.
Вызвал такси, через пару минут приложение перестало показывать водителя, подумал что водитель отменил, а я не заметил сообщения, заказал еще раз. В итоге в истории две поездки с разницей в несколько минут: первая показывает правильные адреса, но оборвалась на пол пути; вторая доехала куда надо, но в адресах показывает что заказ был с запада Москвы на юг Гонг Конга.
Спасибо, что подняли этот вопрос. А то каждое первое апи неидемпотентно и приходится плясать с бубном, пытаясь сделать адекватное приложение вокруг него.
Однако гуиды, хеши… блокчейн бы ещё сюда прикрутили. Всё, что тут надо — это отразить предметную область в ресурсах. При работе с активными заказами пользователь не "создаёт заказы", а "вызывает такси номер 1", "номер 2" и тд.
PUT /taxi/1
when \2019-01-01T01:00:00+03:00
from \Москва, ул. Садовническая набережная 82с2
to \Аэропорт ВнуковоДалее пользователь может как угодно менять заказ, посылать запрос хоть сотню раз, он взаимодействует лишь с одним "виртуальным" такси. Когда же ему надо заказать ещё одно, то жмёт "ещё одно такси" и вводит данные уже для него.
PUT /taxi/2
when \2019-01-01T02:00:00+03:00
from \Аэропорт Внуково
to \Москва, ул. Садовническая набережная 82с2Пользователь вызвал такси (у него номер 1), заказ завершился, после этого пользователь еще раз вызвал такси (у него тоже номер 1). Как теперь поменять для самого первого заказа оценку, например? PUT /taxi/1 будет менять уже другой заказ.
Это уже поездки:
GET /trip
/trip/34676374
departure_at \2019-01-01T02:00:00+03:00
arrived_at \2019-01-01T03:00:00+03:00
from \Аэропорт Внуково
to \Москва, ул. Садовническая набережная 81
vote 3
/trip/652455
departure_at \2019-01-01T01:00:00+03:00
arrived_at \2019-01-01T02:00:00+03:00
from \Москва, ул. Садовническая набережная 82с2
to \Аэропорт ВнуковоPUT /trip/652455
vote 5Обратите внимание, что структура данных у них совсем разная.
Так всё-таки, зачем слоты? Что в них удобного? Чем плох генерируемый на клиенте номер заказа без возможности переиспользования?
Если я правильно вас понял, вы предлагаете переиспользовать номера "первое такси", "второе такси", но как тогда определять, какой номер у "очередного такси" и когда оно становится "первым такси". Допустим, первая поездка в аэропорт ещё идёт, вторая уже закончилась, а пользователь вызывает третье такси открывая приложение во второй раз — оно должно отображаться/запрашиваться как "второе" или "третье"?
Приложение, не уведомляя пользователя, сразу сделало перезапрос и получило 404
А зачем делать повторный запрос, не уведомляя пользователя? Таймаут — это, скорее всего, проблема с соединением, которую должен решить пользователь. Подойти к окну, включить вайфай. Если ответы так и не будут доходить, то рано или поздно об этом все равно придется сообщить пользователю. И лучше сделать это раньше, чтобы не заставлять его ждать впустую, не питать ложных надежд, не заставлять перезапускать приложение. Тогда бы и этой проблемы с появлением ошибки при успешном выполнении не возникло бы.
Я просто хочу понять вашу логику. За пост спасибо, интересно.
На масштабах Яндекс.Такси таймауты происходят много раз каждую секунду даже при взаимодействии между микросервисами: где-то у сетевиков роутер подлагнул, где-то на сервере базы данных обращение к диску тормозит из-за битого сектора, где-то CPU перегружен у машины и тд.
Если рассмотреть пользователя такси, то это обычно мобильное приложение. Мобильная сеть обычно ненадежна и имеет большой latency. Легко попасть в зону плохого покрытия, зайти в переход. Особенно проблема актуальна в городах/странах где плохо с 3G.
То есть таймауты это нормальное явление, с ними надо уметь жить. Если на каждый таймаут показывать ошибку, то пользователи будут утекать к конкурентам, не показывающим их.
Но основной мой вопрос про сеть. Допустим, на улице зима, я зашел погреться в подземный переход. Сеть ловит, но очень нестабильно. Хочу вызвать такси. Приложение будет бесконечно молча повторять запросы?
Более простое решение — не показывать сетевые ошибки в GUI. Если до сервера достучаться не удалось, отображать "заказ отправляется" и дать возможность отменить отправку заказа. В логике, соответственно, повторять идемпотентный запрос до получения ответа от сервера. Если пользователь отменил отправку заказа, отправить запрос отмены заказа, так же с ретраями.
А вот случае такси, как такое возможно? Что мешает сделать уникальный ключ в таблице по клиенту, from, to, и доверься надежности БД? Если insert прошел — ок. Если нет — ошибка -дубликат. Про мульти заказ не понятно тоже. Если подразумевается заказ на разные адреса, это это просто два разных заказа. Если по одному маршруту — так это просто атрибут типа автомобиля в одном заказе (типа сколько человек надо перевезти). Можно чтобы мини бас приехал и всех забрал, а можно чтобы одна или несколько машин. Клиенту это параллельно. Ему важно сколько человек должны уехать.
— И, соответственно, до получения состояния с сервера по умолчанию считать, что «заказ» невозможен.
Полная блокировка UI может решать часть проблем, в статье это и описано:
В итоге вдвоем они придумали следующее решение: приложение не дает изменить параметры заказа и бесконечно пытается создать заказ, пока получает коды ответа 5xx или же сетевые ошибки. Вася добавил серверную валидацию, предложенную Федей.
Но есть и другие точки входа в изменение заказов:
- водитель/диспетчер меняет/отменяет заказ
- кнопки действий в пушах
- второе устройство
В идеале просто добавить сразу в ответ сервера, например, хэш всех заказов, которые есть у клиента (чтобы все их параметры не передавать). Насколько я понимаю вашу идею — хэш в данном случае не замена ключу идемпотентности, поскольку в данном случае передаётся не всегда и только от сервера клиенту, но не наоборот. Хэш высчитывать из параметров заказа. Таким образом полную «локальную базу» иметь не надо. Достаточно сравнивать те заказы, которые мы локально создали и не отменили с тем, что есть на сервере.
Допустим клиент отправляет множество запросов из-за плохой сети. В этом нет проблемы, если параметры заказа абсолютно идентичные — все, кроме первого запроса сервером тупо отклоняются. Если клиент чуть изменил параметры заказа, но также продолжает долбить запросами сервер, то на сервере мы видим, что есть разница, но координаты отличаются незначительно — просто обновляем заказ и отвечаем хэщами.
Рано или поздно клиент получит хотя бы один ответ сервера и поймёт, что его заказ отклонён по причине дубля, ему лишь останется запросить актуальный список заказов, чтобы понять какая из версий заказа была принята для актуализации собственных данных. Самый шик в том, что для всего этого не нужно будет много данных передавать, в идеале серверу достаточно только хэши передавать, чтобы клиент мог по ним параметры заказов восстановить (не подбором, естественно, а сравнивая с тем, что уже было создано).
При таком подходе появляется много вариантов как обрабатывать повторные заказы, создаваемые с небольшой разницей в параметрах, но во первых (и в главных) — так как мы разделили методы вначале или добавили обязательный параметр, то легко можно будет отличить случаи для заказ нескольких машин в одно место. Таким образом, фактически, если параметры заказа отличаются незначительно, это практически всегда просто обновление заказа. И, кстати, для клиента в этом случае это тоже упростит логику.
Единственная проблема, которую у меня сходу удалось придумать — если клиент слал множественные запросы, потом изменил параметры заказа, но в итоге дошли пакеты только с первым вариантом заказа. Однако, насколько я могу судить, ваша схема данный конфуз тоже не решает без дополнительной дальнейшей синхронизации.
И ещё один момент. Если клиент видит, что отправляемые им пакеты не получают ответа — рисовать ему «проблемы с сетью» и не делать лишнего это, вообще-то, хорошая практика (на мой взгляд). Тут самый смысл в том, чтобы уменьшить требования к сети, уменьшая объём передаваемых данных. Достаточно чтобы порог ошибок сети, при котором будет сообщаться о проблемах был очень высок, чтобы пользователи видели такое только в глухом подвале или в тайге.
P.S. Извините, с утра думается тяжело, могу тупить где-то, буду рад если объясните в каком моменте не прав.
Допустим клиент отправляет множество запросов из-за плохой сети. В этом нет проблемы, если параметры заказа абсолютно идентичные — все, кроме первого запроса сервером тупо отклоняются.
Что значит тупо отклоняются? Как сервер поймет что полученный запрос это повторная отправка одного и того же запроса (после обрыва сети) а не создание нового заказа? Смотрите тут проблема чисто логическая — если есть приложение где юзер может создавать что-то много раз неважно будут ли это поездки или задачи в таск-менеджере или комментарии — всегда возможна ситуация обрыва связи при котором возможны два варианта — а) запрос не успел дойти до сервера и тогда можно безопасно выполнять его повторную отправку б) запрос дошел до сервера и был обработан но обрыв связи произошел на обратном пути — и тогда повторная отправка уже будет небезопасна так как сервер посчитает что это был отдельный запрос и получим дубль. А клиент получив ошибку обрыва соединения никак не сможет понять был ли обрыв связи на пути к серверу или на обратном пути.
И получается что в итоге возможны 3 варианта действий со стороны клиента — а) не пытаться ретраить запрос и понадеяться на успешную доставку записав в издержки редкие потери — это то соответствует семантике «at most once» в кафке или других брокерах сообщений б) при обрыве сети просто ретраить запрос, а в издержки записать возможные дубли при редких случаях когда связь обрывается на обратном пути — это соответсвует семантике «at least once» в) семантика «exactly once» — выполнять ретрай при обрыве связи но с каждым запросом передать серверу дополнительную информацию при котором сервер сможет различить был ли такой запрос обработан или нет чтобы тогда сервер отклонил этот запрос (либо возможен еще вариант когда перед ретраем происходит получение информации из сервера чтобы уже сам клиент без лишней отправки запроса отменил запросы которые успели обработаться)
В зависимости от того что взять в качестве этой дополнительной информации возможны различные подходы:
1) сгенерировать на клиенте рандомный айдишник для нового заказа (guid или uuid) чтобы при повторном запросе база данных выдала ошибку что такой заказ по такому айдишнику уже есть
2) передавать такой же сгенерированный айдишник (ключ идемпотентности) но который не будет сохраняться в качестве primary id а будет храниться где-то в другом месте (но поскольку это накладные расходы то обычно хранят ограниченное время)
3) сервер может не хранить айдишник для каждого запроса/заказа но тогда клиент должен с каждым запросом передавать список айдишников/хеш-заказов всех предыдущих заказов, еще есть вариант — передача версии списка заказов
4) обобщая предыдущий способ — при передаче версии списка заказов или хеша происходит по сути выстраивание запросов клиента в очередь — то есть параллельно отправленные запросы клиента приведут к ошибке так как не совпадут версии/хеши. А в общем случае если у нас не одна сущность «заказы» а сложное crm-приложение с кучей сущностей то придется хранить по айдишнику/хешу версии на каждую таблицу либо можно хранить только один айдишник/хеш по всем запросам для одного юзера (точнее его сессии так как у юзера может быть залогинен с несколько устройств) а на клиенте выстраивать все запросы по всем сущностям в очередь
И получается что минимизируя количество дополнительной информации которую должен хранить сервер мы приходим к тому что в случае ухудшаем производительность при использовании http-протокола — теперь нужно дожидаться результата предыдущего запроса http-запроса прежде чем отправить новый.
Но это в случае http, в случае же вебсокетов — ситуация иная — вебсокеты гарантируют последовательность а значит что отправленные запросы на сервер в одном вебсокет-соединении будут приходить в том же порядке в котором был отправлены из клиента. А это значит что мы можем отправлять запросы сразу же не дожидаясь ответа предыдущего а в случае восстановления сети после обрыва связи достаточно получить от сервера айдишник последнего обработанного запроса и таким образом понять какие запросы успели обработаться и их следует удалить из очереди а какие нужно будет отправить повторно
Как сервер поймет что полученный запрос это повторная отправка одного и того же запроса (после обрыва сети) а не создание нового заказа?Одному человеку нужно больше двух машин по одному и тому же маршруту? Окей, добавляем параметр с количеством машин в запрос, я же написал.
есть приложение где юзер может создавать что-то много разВ том-то и дело, что это банальная логика — если человеку нужно куда-то поехать, ему нужна ровно одна поездка.
Собственно, минимум половина ваших дальнейших рассуждений теряют смысл, стоит нам лишь добавить параметр «количество машин».
Я — единственный трезвый в компании, у меня есть скидка, и я умею пользоваться приложением на смарте (вариант: у меня есть смарт, у других разрядился или нет или они пьяные и не могут тыкать в кнопки). Короче. Я заказываю такси жене со старшеньким на плаванье, а с младшеньким еду сам на рисование, пока жена надевает на наши цветы жизни памперсы, колготы, косички и другие важные части одежды. А если у нас четверо детей и суета? А если я не помню, нажал или нет на эту кнопку, пока мне на ухо орут "папа, я хочу зонтик", при этом на улице -20? И так далее. Ближе к народу надо быть.
Стажёр Вася и его истории об идемпотентности API