
Пользователи ClickHouse знают, что его главное преимущество — высокая скорость обработки аналитических запросов. Но как мы можем выдвигать такие утверждения? Это должно подтверждаться тестами производительности, которым можно доверять. О них мы сегодня и поговорим.
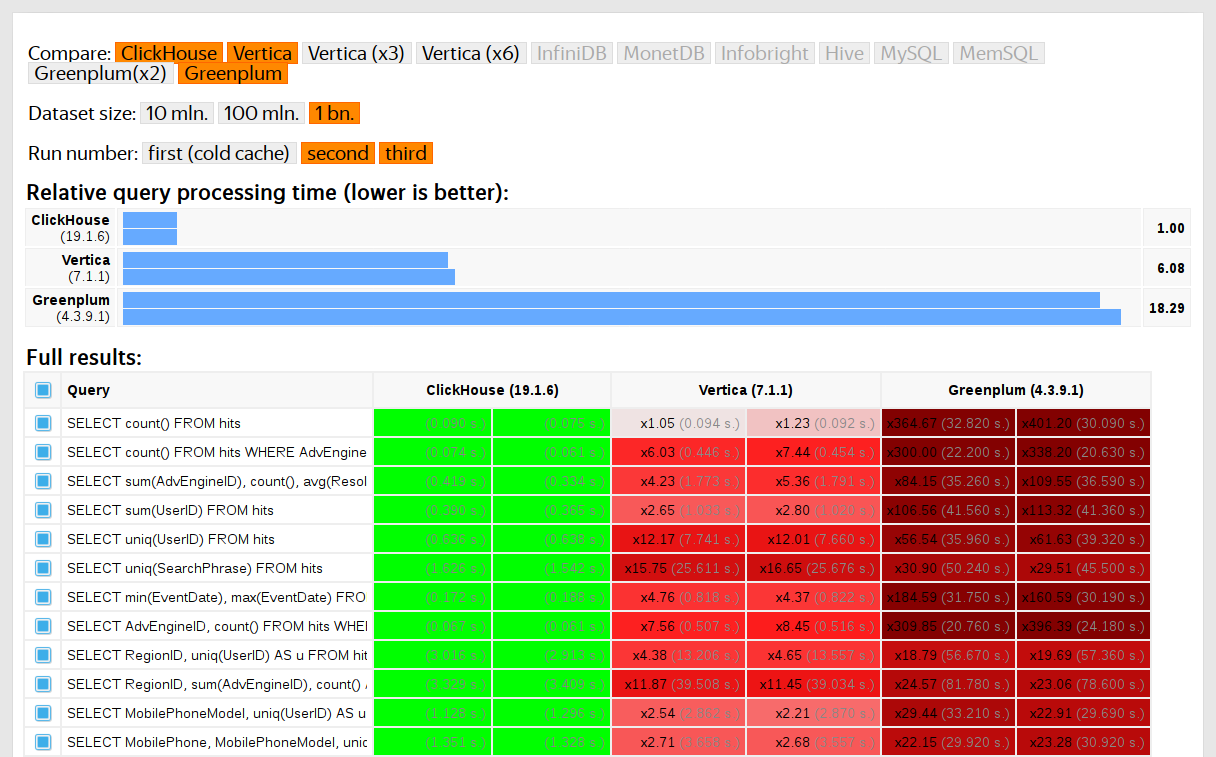
Такие тесты мы начали проводить в 2013 году, задолго до того, как продукт стал доступным в опенсорсе. Как и сейчас, тогда нас больше всего интересовала скорость работы данных сервиса Яндекс.Метрика. Мы уже хранили данные в ClickHouse с января 2009 года. Часть данных записывалась в базу с 2012 года, а часть — была переконвертирована из OLAPServer и Metrage — структур данных, которые использовались в Яндекс.Метрике раньше. Поэтому для тестов мы взяли первое попавшееся подмножество из 1 миллиарда данных о просмотрах страниц. Запросов в Метрике ещё не было, и мы придумали запросы, больше всего интересные нам самим (всевозможные виды фильтрации, агрегации и сортировки).
ClickHouse тестировался в сравнении с похожими системами, например, Vertica и MonetDB. Для честности тестирования его проводил сотрудник, который до этого не был разработчиком ClickHouse, а частные случаи в коде не оптимизировались до получения результатов. Похожим образом мы получили набор данных и для функциональных тестов.
После того, как ClickHouse вышел в опенсорс в 2016 году, к тестам стало больше вопросов.
Тесты производительности:
Можно решить эти проблемы — выкинуть старые тесты и сделать новые на основе открытых данных. Среди открытых данных можно взять данные перелётов в США, поездок такси в Нью-Йорке или использовать готовые бенчмарки TPC-H, TPC-DS, Star Schema Benchmark. Неудобство в том, что эти данные далеки от данных Яндекс.Метрики, да и тестовые запросы хотелось бы сохранить.
Тестировать производительность сервиса нужно только на настоящих данных с продакшена. Рассмотрим несколько примеров.
Пример 1
Предположим, вы заполняете базу данных равномерно распределёнными псевдослучайными числами. В этом случае сжатие данных не будет работать. Но сжатие данных — важное свойство для аналитических СУБД. Выбор правильного алгоритма сжатия и правильного способа интеграции его в систему — нетривиальные задачи, в которых нет одного верного решения, потому что сжатие данных требует компромисса между скоростью сжатия и разжатия и потенциальной степенью сжатия. Системы, которые не умеют сжимать данные, проигрывают гарантированно. Но если использовать для тестов равномерно распределённые псевдослучайные числа, этот фактор не рассматривается, и все остальные результаты будут искажены.
Вывод: тестовые данные должны обладать реалистичным коэффициентом сжатия.
Про оптимизацию алгоритмов сжатия данных в ClickHouse я рассказывал в предыдущем посте.
Пример 2
Пусть нас интересует скорость работы SQL-запроса:
Это типичный запрос для Яндекс.Метрики. Что важно для скорости его работы?
Но ещё очень важно, что количество данных для разных регионов распределено неравномерно. (Наверное, оно распределено по степенному закону. Я построил график в шкале log-log, но не уверен.) А если так, то нам важно, чтобы состояния агрегатной функции uniq с маленьким количеством значений использовали мало памяти. Когда разных ключей агрегации много, счёт идёт на единицы байт. Как получить сгенерированные данные, которые обладают всеми этими свойствами? Конечно, лучше использовать настоящие данные.
Многие СУБД реализуют структуру данных HyperLogLog для приближённого расчёта COUNT(DISTINCT), но все они работают сравнительно плохо, потому что эта структура данных использует фиксированное количество памяти. А в ClickHouse есть функция, которая использует комбинацию из трёх разных структур данных, в зависимости от размера множества.
Вывод: тестовые данные должны репрезентовать свойства распределения значений в данных — кардинальности (количество значений в столбцах) и взаимной кардинальности нескольких разных столбцов.
Пример 3
Ладно, пусть мы тестируем производительность не аналитической СУБД ClickHouse, а чего-нибудь попроще, например, хэш-таблиц. Для хэш-таблиц очень важен правильный выбор хэш-функции. Для std::unordered_map он чуть менее важен, потому что это — хэш-таблица на основе цепочек, а в качестве размера массива используется простое число. В реализации стандартной библиотеки в gcc и clang в качестве хэш-функции по умолчанию для числовых типов используется тривиальная хэш-функция. Но std::unordered_map — не лучший выбор, когда мы хотим получить максимальную скорость. При использовании open-addressing хэш-таблицы правильный выбор хэш-функции становится решающим фактором, и мы не можем использовать тривиальную хэш-функцию.
Легко найти тесты производительности хэш-таблиц на случайных данных, без рассмотрения используемых хэш-функций. Так же легко найти тесты хэш-функций с упором на скорость вычисления и некоторые критерии качества, правда, в отрыве от используемых структур данных. Но факт в том, что для хэш-таблиц и для HyperLogLog требуются разные критерии качества хэш-функций.
Подробнее об этом — в докладе «Как устроены хэш-таблицы в ClickHouse». Он чуть устарел, так как в нём не рассматриваются swiss-таблицы.
Мы хотим получить данные для тестирования производительности по структуре такие же, как данные Яндекс.Метрики, для которых сохранены все свойства важные для бенчмарков, но так, чтобы в этих данных не осталось следов настоящих посетителей сайтов. То есть данные должны быть анонимизированы, при этом должны сохраняться:
А что нужно, чтобы у данных был похожий коэффициент сжатия? Например, если используется LZ4, то подстроки в бинарных данных должны повторяться примерно на таких же расстояниях и повторения должны быть примерно такой же длины. Для ZSTD добавляется совпадение энтропии байтов.
Задача-максимум: сделать инструмент, доступный для внешних людей, с помощью которого каждый сможет анонимизировать свой набор данных для публикации. Чтобы мы отлаживали и тестировали производительность на чужих данных аналогичных данным с продакшена. А ещё хотелось бы, чтобы сгенерированные данные было интересно смотреть.
Это — неформальная постановка задачи. Впрочем, формальную постановку никто давать не собирался.
Не следует преувеличивать важность этой задачи для нас. На самом деле её никогда не было в планах и никто даже не собирался её делать. Я просто не оставлял надежд, что что-нибудь само собой придумается, и вдруг у меня будет хорошее настроение и много дел, которые можно отложить на потом.
Первая идея — для каждого столбца таблицы выбрать семейство вероятностных распределений, которое его моделирует. Затем, исходя из статистики данных, подобрать параметры (model fitting) и с помощью подобранного распределения генерировать новые данные. Можно использовать генератор псевдослучайных чисел с предопределённым seed, чтобы получать воспроизводимый результат.
Для текстовых полей можно использовать марковские цепи — понятную модель, для которой можно сделать эффективную реализацию.
Правда потребуются некоторые трюки:
Всё это представляется в виде программы, в которую hard coded все распределения и зависимости — так называемый «скрипт на C++». Впрочем, марковские модели всё-таки вычисляются из суммы статистики, сглаживания и загрубления с помощью шума. Я начал писать этот скрипт, но почему-то после того, как написал в явном виде модели для десяти столбцов, внезапно стало невыносимо скучно. А в таблице hits в Яндекс.Метрике ещё в 2012 году было более 100 столбцов.
Такой подход к задаче был провальным. Если бы я к ней старательнее подошёл, наверняка скрипт был бы написан.
Достоинства:
Недостатки:
А я бы хотел более общее решение — чтобы его можно было применить не только для данных Яндекс.Метрики, но и для обфускации любых других данных.
Впрочем, улучшения тут возможны. Можно не вручную подбирать модели, а реализовать каталог моделей и выбирать среди них лучшую (best fit + какая-то регуляризация). А может быть, можно использовать марковские модели для всех типов полей, а не только для текста. Зависимости между данными тоже можно понять автоматически. Для этого нужно посчитать относительные энтропии (относительное количество информации) между столбцами, либо проще — относительные кардинальности (что-то типа «как много в среднем разных значений A для фиксированного значения B») для каждой пары столбцов. Это позволит понять, например, что URLDomain полностью зависит от URL, а не наоборот.
Но от этой идеи я тоже отказался, потому что слишком много вариантов того, что нужно учесть, и это долго надо будет писать.
Я уже рассказывал, насколько эта задача важна для нас. Никто даже не думал о том, чтобы сделать какие-то поползновения к её реализации. К счастью, коллега Иван Пузыревский тогда работал преподавателем в ВШЭ и одновременно занимался разработкой ядра YT. Он спросил, нет ли у меня каких-нибудь интересных задач, которые можно предложить студентам в качестве темы диплома. Я предложил ему эту, и он заверил меня, что она подходит. Так я дал эту задачу хорошему человеку «с улицы» — Шарифу Анвардинову (для работы с данными подписывается NDA).
Рассказал ему про все свои идеи, но главное — объяснил, что решать задачу можно любым способом. И как раз хорошим вариантом было бы использовать те подходы, в которых я не разбираюсь абсолютно: например, генерировать текстовый дамп данных с помощью LSTM. Это выглядело обнадёживающим благодаря статье The Unreasonable Effectiveness of Recurrent Neural Networks, которая тогда мне попалась на глаза.
Первая особенность задачи в том, что требуется генерировать структурированные данные, а не просто текст. Было неочевидно, сможет ли рекуррентная нейронная сеть генерировать данные с нужной структурой. Решить это можно двумя способами. Первый — использовать для генерации структуры и для «наполнителя» отдельные модели: нейронная сеть должна только генерировать значения. Но этот вариант отложили на потом, после чего никогда не сделали. Второй способ — просто генерировать TSV-дамп как текст. Практика показала, что в тексте часть строк будет не соответствовать структуре, но эти строки можно выкидывать при загрузке.
Вторая особенность — рекуррентная нейронная сеть генерирует последовательность данных, и зависимости в данных могут следовать только в порядке этой последовательности. Но в наших данных, возможно, порядок столбцов обратный по отношению к зависимостям между ними. С этой особенностью мы ничего делать не стали.
Ближе к лету появился первый рабочий скрипт на Python, который генерировал данные. На первый взгляд, качество данных приличное:

Правда обнаружились сложности:
Шариф попробовал изучить качество данных сравнением статистик. Например, посчитал, с какой частотой в исходных и в сгенерированных данных встречаются разные символы. Результат получился сногсшибательным — самыми частыми символами являются Ð и Ñ.
Не беспокойтесь — он защитил диплом на отлично, после чего об этой работе мы благополучно забыли.
Предположим, что постановка задачи уменьшилась до одного пункта: нужно сгенерировать данные, у которых коэффициенты сжатия будут точно такие же, как у исходных данных, при этом данные должны разжиматься точно с такой же скоростью. Как это сделать? Нужно редактировать байты сжатых данных напрямую! Тогда размер сжатых данных не поменяется, а сами данные поменяются. Да ещё и всё быстро работать будет. Когда появилась эта идея, я сразу захотел её реализовать, несмотря на то, что она решает какую-то другую задачу вместо исходной. Так всегда бывает.
Как редактировать сжатый файл напрямую? Допустим, нас интересует только LZ4. Сжатые с помощью LZ4 данные состоят из команд двух видов:
Исходные данные:
Сжатые данные (условно):
В сжатом файле оставим match как есть, а в literals будем менять значения байтов. В результате после разжатия получим файл, в котором все повторяющиеся последовательности длиной не менее 4 тоже повторяются, причём повторяются на таких же расстояниях, но при этом состоят из другого набора байтов (образно выражаясь, в изменённом файле не было взято ни одного байта из исходного файла).
Но как менять байты? Это не очевидно, потому что кроме типов столбцов данные имеют также и свою внутреннюю, неявную структуру, которую хотелось бы сохранить. Например, текст часто хранится в кодировке UTF-8 — и мы хотим, чтобы в сгенерированных данных тоже был валидный UTF-8. Я сделал простую эвристику, чтобы выполнялось несколько условий:
Особенность этого подхода в том, что моделью для данных выступают сами исходные данные — значит, модель нельзя публиковать. Она позволяет сгенерировать объём данных не больше исходного. Для сравнения, в предыдущих подходах можно было создать модель и генерировать на её основе неограниченное количество данных.
Пример для URL:
Результат меня порадовал — на данные было интересно смотреть. Но всё-таки что-то было не так. В адресах URL сохранилась структура, но кое-где было слишком легко угадать yandex или avito. Сделал эвристику, которая иногда переставляет какие-то байты местами.
Беспокоили и другие соображения. Например, sensitive-информация может быть представлена в столбце типа FixedString в бинарном виде и почему-то состоять из ASCII control characters и пунктуации, которую я решил сохранить. А типы данных я не учитываю.
Ещё одна проблема: если в одном столбце хранятся данные вида «длина, значение» (так хранятся столбцы типа String), то как обеспечить, чтобы после мутации длина осталась правильной? Когда я попытался это исправить, задача сразу же стала неинтересной.
Но задача не решена. Мы провели несколько экспериментов, и стало только хуже. Остаётся только ничего не делать и читать случайные страницы в интернете, ведь настроение уже испорчено. К счастью, на одной из таких страниц оказался разбор алгоритма отрисовки сцены гибели главного героя в игре Wolfenstein 3D.

Красивая анимация — экран заполняется кровью. В статье объясняется, что на самом деле это псевдослучайная перестановка. Случайная перестановка — случайно выбранное взаимнооднозначное преобразование множества. То есть отображение всего множества, в котором результаты для разных аргументов не повторяются. Иными словами, это способ перебрать все элементы множества в случайном порядке. Именно такой процесс и показан на картинке — мы закрашиваем каждый пиксель, выбранный в случайном порядке из всех, без повторений. Если бы мы просто на каждом шаге выбирали случайный пиксель, то нам бы потребовалось много времени, чтобы закрасить последний.
В игре используется очень простой алгоритм для псевдослучайной перестановки — LFSR (linear feedback shift register). Как и генераторы псевдослучайных чисел, случайные перестановки, а точнее их семейства, параметризованные ключом, могут быть криптографически стойкими — нам как раз это и требуется для преобразования данных. Хотя здесь могут быть неочевидные детали. Например, криптографически стойкое шифрование N байт в N байт с заранее фиксированным ключом и initialization vector, казалось бы, можно использовать в качестве псевдослучайной перестановки множества N-байтовых строк. Действительно, такое преобразование взаимнооднозначное и выглядит случайным. Но если мы используем одно и то же такое преобразование для всех наших данных, то результат может быть подвержен возможности анализа, потому что одно и то же значение initialization vector и ключа используется несколько раз. Это аналогично режиму Electronic Codebook работы блочных шифров.
Какие есть способы получить псевдослучайную перестановку? Можно взять простые взаимнооднозначные преобразования и собрать из них достаточно сложную функцию, которая будет выглядеть случайной. Приведу в качестве примера некоторые из моих любимых взаимнооднозначных преобразований:
Так, например, из трёх умножений и двух операций xor-shift собран финализатор murmurhash. Эта операция — псевдослучайная перестановка. Но на всякий случай замечу, что хэш-функции, даже N бит в N бит, вовсе не обязаны быть взаимнооднозначными.
Или вот ещё интересный пример из элементарной теории чисел с сайта Джеффа Прешинга.
Как можно использовать псевдослучайные перестановки для нашей задачи? Можно преобразовать с их помощью все числовые поля. Тогда удастся сохранить все кардинальности и взаимные кардинальности всех комбинаций полей. То есть COUNT(DISTINCT) будет возвращать то же значение, что и до преобразования, причём с любым GROUP BY.
Стоит заметить, что сохранение всех кардинальностей немного противоречит постановке задачи по анонимизации данных. Например, мы знаем, что в исходных данных о посещениях сайтов есть пользователь, который заходил на сайты из 10 разных стран, и мы хотим найти его в преобразованных данных. Но в преобразованных данных он тоже заходил на сайты из 10 разных стран — это важная информация, которая позволит сузить поиск. Даже если мы найдём, во что преобразовался пользователь, это будет не сильно полезно, потому что все остальные данные тоже были преобразованы — например, мы не сможем понять, какие сайты он посещал. Но такие правила можно применять по цепочке. Например, мы можем априори знать, что самым популярным сайтом в наших данных является Яндекс, а на втором месте Google, и исключительно за счёт сохранения рангов понять, что какие-то преобразованные идентификаторы сайтов на самом деле означают Яндекс и Google. Но в этом нет ничего удивительного — напомню, что постановка задачи не является формальной, и мы хотим найти некий баланс между анонимизацией данных (сокрытием информации) и сохранением их свойств (раскрытием информации). О том, как можно надёжнее подойти к задаче анонимизации данных, читайте в статье.
К тому же я хочу оставить исходными не только кардинальности значений, но и примерные порядки их величин. Например, если исходные данные были числами меньше 10, то пусть после преобразования будут тоже небольшие числа. Как этого добиться?
Например, попробуем разбить множество возможных значений на size classes и выполнять перестановки в пределах каждого класса отдельно (классы размеров остаются). Для этого проще всего принять за size class ближайшую степень двух или позицию старшего бита числа, что то же самое. Числа 0 и 1 всегда останутся как есть. Числа 2 и 3 с вероятностью 1/2 иногда останутся как есть и с вероятностью 1/2 будут переставлены местами друг с другом. Множество чисел 1024..2047 будет переставлено одним из 1024! (факториал) вариантов. И так далее. Для знаковых чисел можно сохранять знак как есть.
Также неочевидно, нужна ли нам взаимнооднозначная функция. Вероятно, можно использовать просто криптографически стойкую хэш-функцию. Преобразование получится не взаимнооднозначным, но кардинальности будут отличаться не сильно.
Правда нам нужна криптографически стойкая случайная перестановка, чтобы можно было выбрать ключ, а по этому ключу получить перестановку, так чтобы из переставленных данных было трудно восстановить исходные данные без знания ключа.
Но есть проблема — я же не только ничего не понимаю в нейронных сетях и машинном обучении, но и в криптографии я тоже дилетант. Остаётся только отвага. В это время я как раз продолжил читать случайные страницы в интернете. На страницу Fabien Sanglard была ссылка c Hackers News, а там были комментарии с обсуждением. В них была ссылка на статью в блоге разработчика Redis — Сальваторе Санфилиппо. Там говорилось о том, что для получения случайных перестановок есть замечательный обобщённый способ под названием сеть Фейстеля.
Сеть Фейстеля состоит из раундов. Каждый раунд — удивительное преобразование, которое позволяет из любой функции получить взаимнооднозначную функцию. Рассмотрим, как это работает.
Также существует утверждение, что если в качестве F взять криптографически стойкую псевдослучайную функцию и применить раунд Фейстеля хотя бы 4 раза, то получится криптографически стойкая псевдослучайная перестановка.
Выглядит как чудо: берём функцию, которая выдаёт случайный мусор на основе данных, подставляем её в сеть Фейстеля — и теперь у нас есть функция, которая выдаёт случайный мусор на основе данных, но при этом полностью обратима!
Сеть Фейстеля находится в основе некоторых алгоритмов шифрования данных. И то, что мы будем делать, как раз станет неким подобием шифрования, но только очень плохим. На это есть две причины:
Так мы можем обфусцировать числовые поля с сохранением нужных нам свойств. Например, коэффициент сжатия с помощью LZ4 должен остаться примерно таким же, потому что повторяющиеся значения в исходных данных будут повторяться и в преобразованных данных, причём на тех же расстояниях друг от друга.
Для задач сжатия данных, предиктивного ввода, распознавания речи, а также для генерации случайных строк используются текстовые модели. Текстовая модель — вероятностное распределение всех возможных строк. Представьте себе, например, воображаемое вероятностное распределение текстов всех книг, которые человечество может написать. Для генерации строки мы просто разыгрываем случайную величину с этим распределением и возвращаем полученную строку (случайную книгу, которую человечество может написать). Но откуда нам знать это вероятностное распределение всех возможных строк?
Во-первых, в явном виде оно требовало бы слишком много информации: например, существует 256^10 всех возможных строк длины 10 байт, и потребовалось бы довольно много памяти, чтобы в явном виде записать таблицу с вероятностью каждой строки. Во-вторых, у нас нет достаточного объёма статистики, чтобы достоверно оценить это распределение.
Поэтому в качестве текстовой модели используется вероятностное распределение, которое получается из более грубых статистик. Например, можно отдельно посчитать вероятность, с которой каждая буква встречается в тексте. А затем генерировать строки, выбирая каждую следующую букву с такой вероятностью. Такая примитивная модель работает, но строки всё-таки получаются очень неестественными.
Для небольшого улучшения этой модели можно располагать вероятностью не только каждой отдельной буквы, но и условной вероятностью встречаемости буквы — при условии, что перед ней стоит N некоторых предыдущих букв. N — заранее фиксированная константа. Например, N = 5, и мы считаем вероятность встретить букву «е» после букв «сжати». Такая текстовая модель называется марковской моделью Order-N.
Вы можете наблюдать работу марковских моделей на сайте Яндекс.Рефераты (бывший vesna.yandex.ru). В отличие от нейронных сетей LSTM, у них хватает памяти только на небольшой контекст фиксированной длины N, поэтому они генерируют смешной, бессвязный текст. Марковские модели также применяются в примитивных методах генерации спама — сгенерированные тексты можно легко отличить от настоящих с помощью подсчёта статистик, выходящих за рамки модели. Отметим достоинство: марковские модели работают на порядки быстрее, чем нейросети, а именно это нам и надо.
Пример для Title:
Итак, мы можем посчитать статистики по исходным данным, создать марковскую модель и генерировать на её основе новые данные. Из нюансов сразу отметим необходимость огрубления (сглаживания) модели, чтобы не раскрывать информацию о редких комбинациях в исходных данных — это не проблема. Я использую комбинацию из моделей порядка от 0 до N, где в случае недостаточности статистики для модели порядка N используется модель порядка N − 1).
Но мы ещё хотим сохранять кардинальность данных. Например, если в исходных данных было 123456 уникальных значений URL, то пусть и в результате их будет примерно столько же. Для этого в качестве генератора случайных чисел для разыгрывания случайных величин мы будем использовать детерминированным образом инициализированный генератор случайных чисел. Для этого проще всего взять хэш-функцию. Её мы будем применять к исходному значению. То есть мы получим псевдослучайный результат, однозначно определяющийся исходным значением.
Ещё одно требование: пусть в исходных данных было множество различных адресов URL, которые начинаются на один и тот же префикс, но продолжаются по-разному. Например:
Получается как раз то, что нужно. Посмотрим на примере заголовков страниц:
После четырёх опробованных способов задача надоела мне настолько, что пришло время выбрать какой-нибудь вариант, оформить его в виде удобного инструмента и наконец-то объявить его решением. Я выбрал решение с помощью случайных перестановок и марковских моделей, параметризованных ключом. Оно оформлено в виде программы clickhouse obfuscator, которая очень проста в использовании: на вход подаётся дамп таблицы в любом поддерживаемом формате (например, CSV, JSONEachRow), в параметрах командной строки указывается структура таблицы (имена и типы столбцов) и секретный ключ (произвольная строка, её можно забыть сразу же после использования). На выходе получаем такое же количество строк обфусцированных данных.
Программа устанавливается вместе с clickhouse-client, не имеет зависимостей и работает почти на любом Linux. Применять её можно к дампам любых баз данных, не только ClickHouse. Например, вы можете использовать её для генерации тестовых данных MySQL или PostgreSQL баз, а также для создания разработческих баз аналогичных продакшену.
Не всё так однозначно, ведь преобразование данных этой программой почти полностью обратимо. Можно ли осуществить обратное преобразование, не зная ключ? Если бы преобразование осуществлялось криптостойким алгоритмом, то сложность такой операции была бы такой же, как сложность полного перебора. И хотя для преобразования используются некоторые криптографические примитивы, они используются неправильным способом, и данные подвержены некоторым методам анализа. Чтобы избежать проблем, в документации к программе (доступной по
Мы преобразовали нужный нам датасет для функциональных тестов, и директор по данным Яндекса одобрил его публикацию.
clickhouse-datasets.s3.yandex.net/hits/tsv/hits_v1.tsv.xz
clickhouse-datasets.s3.yandex.net/visits/tsv/visits_v1.tsv.xz
Разработчики за пределами Яндекса используют эти данные для настоящих тестов производительности при оптимизации алгоритмов внутри ClickHouse. Сторонние пользователи могут предоставить нам свои данные в обфусцированном виде, чтобы мы могли сделать для них ClickHouse ещё быстрее.
Такие тесты мы начали проводить в 2013 году, задолго до того, как продукт стал доступным в опенсорсе. Как и сейчас, тогда нас больше всего интересовала скорость работы данных сервиса Яндекс.Метрика. Мы уже хранили данные в ClickHouse с января 2009 года. Часть данных записывалась в базу с 2012 года, а часть — была переконвертирована из OLAPServer и Metrage — структур данных, которые использовались в Яндекс.Метрике раньше. Поэтому для тестов мы взяли первое попавшееся подмножество из 1 миллиарда данных о просмотрах страниц. Запросов в Метрике ещё не было, и мы придумали запросы, больше всего интересные нам самим (всевозможные виды фильтрации, агрегации и сортировки).
ClickHouse тестировался в сравнении с похожими системами, например, Vertica и MonetDB. Для честности тестирования его проводил сотрудник, который до этого не был разработчиком ClickHouse, а частные случаи в коде не оптимизировались до получения результатов. Похожим образом мы получили набор данных и для функциональных тестов.
После того, как ClickHouse вышел в опенсорс в 2016 году, к тестам стало больше вопросов.
Недостатки тестов на закрытых данных
Тесты производительности:
- Не воспроизводимы снаружи, потому что для их запуска нужны закрытые данные, которые нельзя опубликовать. По этой же причине часть функциональных тестов недоступна для внешних пользователей.
- Не развиваются. Есть потребность в существенном расширении их набора, чтобы можно было изолированным образом проверять изменения в скорости работы отдельных деталей системы.
- Не запускаются покоммитно и для пул-реквестов, внешние разработчики не могут проверить свой код на регрессии производительности.
Можно решить эти проблемы — выкинуть старые тесты и сделать новые на основе открытых данных. Среди открытых данных можно взять данные перелётов в США, поездок такси в Нью-Йорке или использовать готовые бенчмарки TPC-H, TPC-DS, Star Schema Benchmark. Неудобство в том, что эти данные далеки от данных Яндекс.Метрики, да и тестовые запросы хотелось бы сохранить.
Важно использовать настоящие данные
Тестировать производительность сервиса нужно только на настоящих данных с продакшена. Рассмотрим несколько примеров.
Пример 1
Предположим, вы заполняете базу данных равномерно распределёнными псевдослучайными числами. В этом случае сжатие данных не будет работать. Но сжатие данных — важное свойство для аналитических СУБД. Выбор правильного алгоритма сжатия и правильного способа интеграции его в систему — нетривиальные задачи, в которых нет одного верного решения, потому что сжатие данных требует компромисса между скоростью сжатия и разжатия и потенциальной степенью сжатия. Системы, которые не умеют сжимать данные, проигрывают гарантированно. Но если использовать для тестов равномерно распределённые псевдослучайные числа, этот фактор не рассматривается, и все остальные результаты будут искажены.
Вывод: тестовые данные должны обладать реалистичным коэффициентом сжатия.
Про оптимизацию алгоритмов сжатия данных в ClickHouse я рассказывал в предыдущем посте.
Пример 2
Пусть нас интересует скорость работы SQL-запроса:
SELECT RegionID, uniq(UserID) AS visitors
FROM test.hits
GROUP BY RegionID
ORDER BY visitors DESC
LIMIT 10
Это типичный запрос для Яндекс.Метрики. Что важно для скорости его работы?
- Как выполняется GROUP BY.
- Какая структура данных используется для расчёта агрегатной функции uniq.
- Сколько разных RegionID есть и сколько оперативки требует каждое состояние функции uniq.
Но ещё очень важно, что количество данных для разных регионов распределено неравномерно. (Наверное, оно распределено по степенному закону. Я построил график в шкале log-log, но не уверен.) А если так, то нам важно, чтобы состояния агрегатной функции uniq с маленьким количеством значений использовали мало памяти. Когда разных ключей агрегации много, счёт идёт на единицы байт. Как получить сгенерированные данные, которые обладают всеми этими свойствами? Конечно, лучше использовать настоящие данные.
Многие СУБД реализуют структуру данных HyperLogLog для приближённого расчёта COUNT(DISTINCT), но все они работают сравнительно плохо, потому что эта структура данных использует фиксированное количество памяти. А в ClickHouse есть функция, которая использует комбинацию из трёх разных структур данных, в зависимости от размера множества.
Вывод: тестовые данные должны репрезентовать свойства распределения значений в данных — кардинальности (количество значений в столбцах) и взаимной кардинальности нескольких разных столбцов.
Пример 3
Ладно, пусть мы тестируем производительность не аналитической СУБД ClickHouse, а чего-нибудь попроще, например, хэш-таблиц. Для хэш-таблиц очень важен правильный выбор хэш-функции. Для std::unordered_map он чуть менее важен, потому что это — хэш-таблица на основе цепочек, а в качестве размера массива используется простое число. В реализации стандартной библиотеки в gcc и clang в качестве хэш-функции по умолчанию для числовых типов используется тривиальная хэш-функция. Но std::unordered_map — не лучший выбор, когда мы хотим получить максимальную скорость. При использовании open-addressing хэш-таблицы правильный выбор хэш-функции становится решающим фактором, и мы не можем использовать тривиальную хэш-функцию.
Легко найти тесты производительности хэш-таблиц на случайных данных, без рассмотрения используемых хэш-функций. Так же легко найти тесты хэш-функций с упором на скорость вычисления и некоторые критерии качества, правда, в отрыве от используемых структур данных. Но факт в том, что для хэш-таблиц и для HyperLogLog требуются разные критерии качества хэш-функций.
Подробнее об этом — в докладе «Как устроены хэш-таблицы в ClickHouse». Он чуть устарел, так как в нём не рассматриваются swiss-таблицы.
Задача
Мы хотим получить данные для тестирования производительности по структуре такие же, как данные Яндекс.Метрики, для которых сохранены все свойства важные для бенчмарков, но так, чтобы в этих данных не осталось следов настоящих посетителей сайтов. То есть данные должны быть анонимизированы, при этом должны сохраняться:
- коэффициенты сжатия,
- кардинальности (количества различных значений),
- взаимные кардинальности нескольких разных столбцов,
- свойства вероятностных распределений, с помощью которых можно моделировать данные (например, если мы считаем, что регионы распределены по степенному закону, то показатель степени — параметр распределения — у искусственных данных должен быть примерно такой же, как у настоящих).
А что нужно, чтобы у данных был похожий коэффициент сжатия? Например, если используется LZ4, то подстроки в бинарных данных должны повторяться примерно на таких же расстояниях и повторения должны быть примерно такой же длины. Для ZSTD добавляется совпадение энтропии байтов.
Задача-максимум: сделать инструмент, доступный для внешних людей, с помощью которого каждый сможет анонимизировать свой набор данных для публикации. Чтобы мы отлаживали и тестировали производительность на чужих данных аналогичных данным с продакшена. А ещё хотелось бы, чтобы сгенерированные данные было интересно смотреть.
Это — неформальная постановка задачи. Впрочем, формальную постановку никто давать не собирался.
Попытки решения
Не следует преувеличивать важность этой задачи для нас. На самом деле её никогда не было в планах и никто даже не собирался её делать. Я просто не оставлял надежд, что что-нибудь само собой придумается, и вдруг у меня будет хорошее настроение и много дел, которые можно отложить на потом.
Явные вероятностные модели
Первая идея — для каждого столбца таблицы выбрать семейство вероятностных распределений, которое его моделирует. Затем, исходя из статистики данных, подобрать параметры (model fitting) и с помощью подобранного распределения генерировать новые данные. Можно использовать генератор псевдослучайных чисел с предопределённым seed, чтобы получать воспроизводимый результат.
Для текстовых полей можно использовать марковские цепи — понятную модель, для которой можно сделать эффективную реализацию.
Правда потребуются некоторые трюки:
- Мы хотим сохранить непрерывность временных рядов — значит, для некоторых типов данных нужно моделировать не само значение, а разность между соседними.
- Чтобы смоделировать условную кардинальность столбцов (например, что на один идентификатор посетителя обычно приходится мало IP-адресов), придётся также выписывать зависимости между столбцами в явном виде (к примеру, для генерации IP-адреса в качестве seed используется хэш от идентификатора посетителя, но ещё добавляется немного других псевдослучайных данных).
- Непонятно, как выразить зависимость, что один посетитель примерно в одно время часто посещает адреса URL с совпадающими доменами.
Всё это представляется в виде программы, в которую hard coded все распределения и зависимости — так называемый «скрипт на C++». Впрочем, марковские модели всё-таки вычисляются из суммы статистики, сглаживания и загрубления с помощью шума. Я начал писать этот скрипт, но почему-то после того, как написал в явном виде модели для десяти столбцов, внезапно стало невыносимо скучно. А в таблице hits в Яндекс.Метрике ещё в 2012 году было более 100 столбцов.
EventTime.day(std::discrete_distribution<>({
0, 0, 13, 30, 0, 14, 42, 5, 6, 31, 17, 0, 0, 0, 0, 23, 10, ...})(random));
EventTime.hour(std::discrete_distribution<>({
13, 7, 4, 3, 2, 3, 4, 6, 10, 16, 20, 23, 24, 23, 18, 19, 19, ...})(random));
EventTime.minute(std::uniform_int_distribution<UInt8>(0, 59)(random));
EventTime.second(std::uniform_int_distribution<UInt8>(0, 59)(random));
UInt64 UserID = hash(4, powerLaw(5000, 1.1));
UserID = UserID / 10000000000ULL * 10000000000ULL
+ static_cast<time_t>(EventTime) + UserID % 1000000;
random_with_seed.seed(powerLaw(5000, 1.1));
auto get_random_with_seed = [&]{ return random_with_seed(); };
Такой подход к задаче был провальным. Если бы я к ней старательнее подошёл, наверняка скрипт был бы написан.
Достоинства:
- идейная простота.
Недостатки:
- трудоёмкость реализации,
- реализованное решение подходит только для одного вида данных.
А я бы хотел более общее решение — чтобы его можно было применить не только для данных Яндекс.Метрики, но и для обфускации любых других данных.
Впрочем, улучшения тут возможны. Можно не вручную подбирать модели, а реализовать каталог моделей и выбирать среди них лучшую (best fit + какая-то регуляризация). А может быть, можно использовать марковские модели для всех типов полей, а не только для текста. Зависимости между данными тоже можно понять автоматически. Для этого нужно посчитать относительные энтропии (относительное количество информации) между столбцами, либо проще — относительные кардинальности (что-то типа «как много в среднем разных значений A для фиксированного значения B») для каждой пары столбцов. Это позволит понять, например, что URLDomain полностью зависит от URL, а не наоборот.
Но от этой идеи я тоже отказался, потому что слишком много вариантов того, что нужно учесть, и это долго надо будет писать.
Нейронные сети
Я уже рассказывал, насколько эта задача важна для нас. Никто даже не думал о том, чтобы сделать какие-то поползновения к её реализации. К счастью, коллега Иван Пузыревский тогда работал преподавателем в ВШЭ и одновременно занимался разработкой ядра YT. Он спросил, нет ли у меня каких-нибудь интересных задач, которые можно предложить студентам в качестве темы диплома. Я предложил ему эту, и он заверил меня, что она подходит. Так я дал эту задачу хорошему человеку «с улицы» — Шарифу Анвардинову (для работы с данными подписывается NDA).
Рассказал ему про все свои идеи, но главное — объяснил, что решать задачу можно любым способом. И как раз хорошим вариантом было бы использовать те подходы, в которых я не разбираюсь абсолютно: например, генерировать текстовый дамп данных с помощью LSTM. Это выглядело обнадёживающим благодаря статье The Unreasonable Effectiveness of Recurrent Neural Networks, которая тогда мне попалась на глаза.
Первая особенность задачи в том, что требуется генерировать структурированные данные, а не просто текст. Было неочевидно, сможет ли рекуррентная нейронная сеть генерировать данные с нужной структурой. Решить это можно двумя способами. Первый — использовать для генерации структуры и для «наполнителя» отдельные модели: нейронная сеть должна только генерировать значения. Но этот вариант отложили на потом, после чего никогда не сделали. Второй способ — просто генерировать TSV-дамп как текст. Практика показала, что в тексте часть строк будет не соответствовать структуре, но эти строки можно выкидывать при загрузке.
Вторая особенность — рекуррентная нейронная сеть генерирует последовательность данных, и зависимости в данных могут следовать только в порядке этой последовательности. Но в наших данных, возможно, порядок столбцов обратный по отношению к зависимостям между ними. С этой особенностью мы ничего делать не стали.
Ближе к лету появился первый рабочий скрипт на Python, который генерировал данные. На первый взгляд, качество данных приличное:
Правда обнаружились сложности:
- Размер модели составляет около гигабайта. А мы пробовали создать модель для данных, размер которых был порядка нескольких гигабайт (для начала). То, что полученная модель такая большая, вызывает опасения: вдруг из неё можно будет достать реальные данные, на которых она обучалась. Скорее всего, нет. Но я ведь не разбираюсь в машинном обучении и нейронных сетях и код на Python от этого человека так и не прочитал, поэтому как я могу быть уверенным? Тогда как раз выходили статьи о том, как сжимать нейронные сети без потери качества, но это осталось без реализации. С одной стороны, это не выглядит проблемой — можно отказаться от публикации модели и опубликовать только сгенерированные данные. С другой, в случае переобучения, сгенерированные данные могут содержать какую-то часть исходных данных.
- На одной машине с CPU скорость генерации данных составляет примерно 100 строк в секунду. У нас была задача — сгенерировать хотя бы миллиард строк. Расчёт показал, что это не удастся сделать до защиты диплома. А использовать другое железо нецелесообразно, ведь у меня была цель — сделать инструмент генерации данных доступным для широкого использования.
Шариф попробовал изучить качество данных сравнением статистик. Например, посчитал, с какой частотой в исходных и в сгенерированных данных встречаются разные символы. Результат получился сногсшибательным — самыми частыми символами являются Ð и Ñ.
Не беспокойтесь — он защитил диплом на отлично, после чего об этой работе мы благополучно забыли.
Мутация сжатых данных
Предположим, что постановка задачи уменьшилась до одного пункта: нужно сгенерировать данные, у которых коэффициенты сжатия будут точно такие же, как у исходных данных, при этом данные должны разжиматься точно с такой же скоростью. Как это сделать? Нужно редактировать байты сжатых данных напрямую! Тогда размер сжатых данных не поменяется, а сами данные поменяются. Да ещё и всё быстро работать будет. Когда появилась эта идея, я сразу захотел её реализовать, несмотря на то, что она решает какую-то другую задачу вместо исходной. Так всегда бывает.
Как редактировать сжатый файл напрямую? Допустим, нас интересует только LZ4. Сжатые с помощью LZ4 данные состоят из команд двух видов:
- Литерал (literals): скопировать следующие N байт как есть.
- Матч (match, минимальная длина повторения равна 4): повторить N байт, которые были в файле на расстоянии M.
Исходные данные:
Hello world Hello.Сжатые данные (условно):
literals 12 "Hello world " match 5 12.В сжатом файле оставим match как есть, а в literals будем менять значения байтов. В результате после разжатия получим файл, в котором все повторяющиеся последовательности длиной не менее 4 тоже повторяются, причём повторяются на таких же расстояниях, но при этом состоят из другого набора байтов (образно выражаясь, в изменённом файле не было взято ни одного байта из исходного файла).
Но как менять байты? Это не очевидно, потому что кроме типов столбцов данные имеют также и свою внутреннюю, неявную структуру, которую хотелось бы сохранить. Например, текст часто хранится в кодировке UTF-8 — и мы хотим, чтобы в сгенерированных данных тоже был валидный UTF-8. Я сделал простую эвристику, чтобы выполнялось несколько условий:
- нулевые байты и ASCII control characters сохранялись как есть,
- сохранялась некоторая пунктуация,
- ASCII переводилось в ASCII, а для остального сохранялся старший бит (или можно явно написать набор if для разных длин UTF-8). Среди одного класса байтов новое значение выбирается равномерно случайно;
- а ещё чтобы сохранялись фрагменты
https://и похожие, а то всё слишком глупо выглядит.
Особенность этого подхода в том, что моделью для данных выступают сами исходные данные — значит, модель нельзя публиковать. Она позволяет сгенерировать объём данных не больше исходного. Для сравнения, в предыдущих подходах можно было создать модель и генерировать на её основе неограниченное количество данных.
Пример для URL:
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXeAyAx
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXe
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwdbknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu-702130
Результат меня порадовал — на данные было интересно смотреть. Но всё-таки что-то было не так. В адресах URL сохранилась структура, но кое-где было слишком легко угадать yandex или avito. Сделал эвристику, которая иногда переставляет какие-то байты местами.
Беспокоили и другие соображения. Например, sensitive-информация может быть представлена в столбце типа FixedString в бинарном виде и почему-то состоять из ASCII control characters и пунктуации, которую я решил сохранить. А типы данных я не учитываю.
Ещё одна проблема: если в одном столбце хранятся данные вида «длина, значение» (так хранятся столбцы типа String), то как обеспечить, чтобы после мутации длина осталась правильной? Когда я попытался это исправить, задача сразу же стала неинтересной.
Случайные перестановки
Но задача не решена. Мы провели несколько экспериментов, и стало только хуже. Остаётся только ничего не делать и читать случайные страницы в интернете, ведь настроение уже испорчено. К счастью, на одной из таких страниц оказался разбор алгоритма отрисовки сцены гибели главного героя в игре Wolfenstein 3D.
Красивая анимация — экран заполняется кровью. В статье объясняется, что на самом деле это псевдослучайная перестановка. Случайная перестановка — случайно выбранное взаимнооднозначное преобразование множества. То есть отображение всего множества, в котором результаты для разных аргументов не повторяются. Иными словами, это способ перебрать все элементы множества в случайном порядке. Именно такой процесс и показан на картинке — мы закрашиваем каждый пиксель, выбранный в случайном порядке из всех, без повторений. Если бы мы просто на каждом шаге выбирали случайный пиксель, то нам бы потребовалось много времени, чтобы закрасить последний.
В игре используется очень простой алгоритм для псевдослучайной перестановки — LFSR (linear feedback shift register). Как и генераторы псевдослучайных чисел, случайные перестановки, а точнее их семейства, параметризованные ключом, могут быть криптографически стойкими — нам как раз это и требуется для преобразования данных. Хотя здесь могут быть неочевидные детали. Например, криптографически стойкое шифрование N байт в N байт с заранее фиксированным ключом и initialization vector, казалось бы, можно использовать в качестве псевдослучайной перестановки множества N-байтовых строк. Действительно, такое преобразование взаимнооднозначное и выглядит случайным. Но если мы используем одно и то же такое преобразование для всех наших данных, то результат может быть подвержен возможности анализа, потому что одно и то же значение initialization vector и ключа используется несколько раз. Это аналогично режиму Electronic Codebook работы блочных шифров.
Какие есть способы получить псевдослучайную перестановку? Можно взять простые взаимнооднозначные преобразования и собрать из них достаточно сложную функцию, которая будет выглядеть случайной. Приведу в качестве примера некоторые из моих любимых взаимнооднозначных преобразований:
- умножение на нечётное число (например, на большое простое число) в two's complement arithmetic,
- xor-shift:
x ^= x >> N, - CRC-N, где N — число бит аргумента.
Так, например, из трёх умножений и двух операций xor-shift собран финализатор murmurhash. Эта операция — псевдослучайная перестановка. Но на всякий случай замечу, что хэш-функции, даже N бит в N бит, вовсе не обязаны быть взаимнооднозначными.
Или вот ещё интересный пример из элементарной теории чисел с сайта Джеффа Прешинга.
Как можно использовать псевдослучайные перестановки для нашей задачи? Можно преобразовать с их помощью все числовые поля. Тогда удастся сохранить все кардинальности и взаимные кардинальности всех комбинаций полей. То есть COUNT(DISTINCT) будет возвращать то же значение, что и до преобразования, причём с любым GROUP BY.
Стоит заметить, что сохранение всех кардинальностей немного противоречит постановке задачи по анонимизации данных. Например, мы знаем, что в исходных данных о посещениях сайтов есть пользователь, который заходил на сайты из 10 разных стран, и мы хотим найти его в преобразованных данных. Но в преобразованных данных он тоже заходил на сайты из 10 разных стран — это важная информация, которая позволит сузить поиск. Даже если мы найдём, во что преобразовался пользователь, это будет не сильно полезно, потому что все остальные данные тоже были преобразованы — например, мы не сможем понять, какие сайты он посещал. Но такие правила можно применять по цепочке. Например, мы можем априори знать, что самым популярным сайтом в наших данных является Яндекс, а на втором месте Google, и исключительно за счёт сохранения рангов понять, что какие-то преобразованные идентификаторы сайтов на самом деле означают Яндекс и Google. Но в этом нет ничего удивительного — напомню, что постановка задачи не является формальной, и мы хотим найти некий баланс между анонимизацией данных (сокрытием информации) и сохранением их свойств (раскрытием информации). О том, как можно надёжнее подойти к задаче анонимизации данных, читайте в статье.
К тому же я хочу оставить исходными не только кардинальности значений, но и примерные порядки их величин. Например, если исходные данные были числами меньше 10, то пусть после преобразования будут тоже небольшие числа. Как этого добиться?
Например, попробуем разбить множество возможных значений на size classes и выполнять перестановки в пределах каждого класса отдельно (классы размеров остаются). Для этого проще всего принять за size class ближайшую степень двух или позицию старшего бита числа, что то же самое. Числа 0 и 1 всегда останутся как есть. Числа 2 и 3 с вероятностью 1/2 иногда останутся как есть и с вероятностью 1/2 будут переставлены местами друг с другом. Множество чисел 1024..2047 будет переставлено одним из 1024! (факториал) вариантов. И так далее. Для знаковых чисел можно сохранять знак как есть.
Также неочевидно, нужна ли нам взаимнооднозначная функция. Вероятно, можно использовать просто криптографически стойкую хэш-функцию. Преобразование получится не взаимнооднозначным, но кардинальности будут отличаться не сильно.
Правда нам нужна криптографически стойкая случайная перестановка, чтобы можно было выбрать ключ, а по этому ключу получить перестановку, так чтобы из переставленных данных было трудно восстановить исходные данные без знания ключа.
Но есть проблема — я же не только ничего не понимаю в нейронных сетях и машинном обучении, но и в криптографии я тоже дилетант. Остаётся только отвага. В это время я как раз продолжил читать случайные страницы в интернете. На страницу Fabien Sanglard была ссылка c Hackers News, а там были комментарии с обсуждением. В них была ссылка на статью в блоге разработчика Redis — Сальваторе Санфилиппо. Там говорилось о том, что для получения случайных перестановок есть замечательный обобщённый способ под названием сеть Фейстеля.
Сеть Фейстеля состоит из раундов. Каждый раунд — удивительное преобразование, которое позволяет из любой функции получить взаимнооднозначную функцию. Рассмотрим, как это работает.
- Биты аргумента разделяются на две половинки:
arg: xxxxyyyy
arg_l: xxxx
arg_r: yyyy - На место левой половинки ставится правая. А на место правой ставится xor от левой половинки и функции от правой половинки:
res: yyyyzzzz
res_l = yyyy = arg_r
res_r = zzzz = arg_l ^ F(arg_r)
Также существует утверждение, что если в качестве F взять криптографически стойкую псевдослучайную функцию и применить раунд Фейстеля хотя бы 4 раза, то получится криптографически стойкая псевдослучайная перестановка.
Выглядит как чудо: берём функцию, которая выдаёт случайный мусор на основе данных, подставляем её в сеть Фейстеля — и теперь у нас есть функция, которая выдаёт случайный мусор на основе данных, но при этом полностью обратима!
Сеть Фейстеля находится в основе некоторых алгоритмов шифрования данных. И то, что мы будем делать, как раз станет неким подобием шифрования, но только очень плохим. На это есть две причины:
- мы шифруем отдельные значения независимо, одинаковым образом, аналогично Electronic Codebook mode of operation;
- мы сохраняем информацию о порядке величины значения (ближайшей степени двух) и его знаке, а это приводит к тому, что некоторые значения вовсе не меняются.
Так мы можем обфусцировать числовые поля с сохранением нужных нам свойств. Например, коэффициент сжатия с помощью LZ4 должен остаться примерно таким же, потому что повторяющиеся значения в исходных данных будут повторяться и в преобразованных данных, причём на тех же расстояниях друг от друга.
Марковские модели
Для задач сжатия данных, предиктивного ввода, распознавания речи, а также для генерации случайных строк используются текстовые модели. Текстовая модель — вероятностное распределение всех возможных строк. Представьте себе, например, воображаемое вероятностное распределение текстов всех книг, которые человечество может написать. Для генерации строки мы просто разыгрываем случайную величину с этим распределением и возвращаем полученную строку (случайную книгу, которую человечество может написать). Но откуда нам знать это вероятностное распределение всех возможных строк?
Во-первых, в явном виде оно требовало бы слишком много информации: например, существует 256^10 всех возможных строк длины 10 байт, и потребовалось бы довольно много памяти, чтобы в явном виде записать таблицу с вероятностью каждой строки. Во-вторых, у нас нет достаточного объёма статистики, чтобы достоверно оценить это распределение.
Поэтому в качестве текстовой модели используется вероятностное распределение, которое получается из более грубых статистик. Например, можно отдельно посчитать вероятность, с которой каждая буква встречается в тексте. А затем генерировать строки, выбирая каждую следующую букву с такой вероятностью. Такая примитивная модель работает, но строки всё-таки получаются очень неестественными.
Для небольшого улучшения этой модели можно располагать вероятностью не только каждой отдельной буквы, но и условной вероятностью встречаемости буквы — при условии, что перед ней стоит N некоторых предыдущих букв. N — заранее фиксированная константа. Например, N = 5, и мы считаем вероятность встретить букву «е» после букв «сжати». Такая текстовая модель называется марковской моделью Order-N.
P(мама | мам) = 0.9
P(мамб | мам) = 0.05
P(мамв | мам) = 0.01
...Вы можете наблюдать работу марковских моделей на сайте Яндекс.Рефераты (бывший vesna.yandex.ru). В отличие от нейронных сетей LSTM, у них хватает памяти только на небольшой контекст фиксированной длины N, поэтому они генерируют смешной, бессвязный текст. Марковские модели также применяются в примитивных методах генерации спама — сгенерированные тексты можно легко отличить от настоящих с помощью подсчёта статистик, выходящих за рамки модели. Отметим достоинство: марковские модели работают на порядки быстрее, чем нейросети, а именно это нам и надо.
Пример для Title:
Модная Пышки — Информер.Ру — национальное ДТП в экспресс фиксикапризы, пробки в Новостинг. Триалы онлайн ногтях, но не пировод, электрошка кадры со скидкой или — Яндекс.Афиша@Mail.Ru — модные знакомств — интернет-магазин СТРИТБОЛКУ в интернет авто. Одесса) — AUTO.ria.ua Базар автомагнитомник фильмы онлайн бесплатно и видео
Итак, мы можем посчитать статистики по исходным данным, создать марковскую модель и генерировать на её основе новые данные. Из нюансов сразу отметим необходимость огрубления (сглаживания) модели, чтобы не раскрывать информацию о редких комбинациях в исходных данных — это не проблема. Я использую комбинацию из моделей порядка от 0 до N, где в случае недостаточности статистики для модели порядка N используется модель порядка N − 1).
Но мы ещё хотим сохранять кардинальность данных. Например, если в исходных данных было 123456 уникальных значений URL, то пусть и в результате их будет примерно столько же. Для этого в качестве генератора случайных чисел для разыгрывания случайных величин мы будем использовать детерминированным образом инициализированный генератор случайных чисел. Для этого проще всего взять хэш-функцию. Её мы будем применять к исходному значению. То есть мы получим псевдослучайный результат, однозначно определяющийся исходным значением.
Ещё одно требование: пусть в исходных данных было множество различных адресов URL, которые начинаются на один и тот же префикс, но продолжаются по-разному. Например:
https://www.yandex.ru/images/cats/?id=xxxxxx. Мы хотим, чтобы в результате получались адреса URL, которые тоже начинаются на одинаковый префикс, но на другой. Например: http://ftp.google.kz/cgi-bin/index.phtml?item=xxxxxx. Тут в качестве генератора случайных чисел для генерации следующего символа с помощью марковской модели мы будем брать хэш-функцию не от всей исходной строки, а от движущегося окна из 8 байт на заданной позиции.https://www.yandex.ru/images/cats/?id=12345
^^^^^^^^
distribution: [aaaa][b][cc][dddd][e][ff][ggggg][h]...
hash("images/c") % total_count: ^
http://ftp.google.kz/cg... Получается как раз то, что нужно. Посмотрим на примере заголовков страниц:
Проградар-детей беременны отправления или Дачна Невестика и МО | Холодеи. - Плакаты пустить в Аксессуаро Проградар-детей бережье — Яндекс.Деньги: Оплатного журнал пять велосипеды на Lore - dfghf — я.ру - недвижимость в Москва) по 473682 объявленов - Продаже Компром Проградар-детей бесплатно! в большом ассоте»в Москве - Вышивку — Омский Оплатно в Самые босоножка рост Проградар-детей бесплатно! в большом ассоте»в Москве, странспортал Проградар-детей бердянский Модов. Рецепт c фотогалерея и прикрыло громной футбола Московье@Mail.Ru - Поиск Проградар-детей бережнева продажа Смотрите лучшей цене, сообществе 2010 | Проектиролабор СНОВНЫЕ. Доста Проградар-детей бесплатно! в большом ассотруди Цена: 820 0000 км., Таганде квартиры в Санкт-Пет Проградар-детей бережный месяцам - DoramaTv.ru - Платья повсему мире. Интернет-продажа авто б.у. и на со скидкой Проградар-детей беремховой комн. в 2013 год, болисменной подержанны в Ставропавлины и коляски -> Магнитаз 80 сотовим.РУ Проградар-детей бережена - Официальный форумы Калинин (Украины. Авториа Бакслера Кудрявцева поставка, вакансионны, продаже отеля Проградар-детей беременность подробная д. 5, 69, общения W*ойчивом - Яндекс.Карты, дома, какой цены эвакуатор форум игры World of Tanks Проградар-детей берец, отечестве и в розовый стр. 2 из кабинет поиск по доровье@Mail.Ru Проградар-детей беремени програда в Китая верты Баре, попогода Манику. Записи в Смоленское
Результат
После четырёх опробованных способов задача надоела мне настолько, что пришло время выбрать какой-нибудь вариант, оформить его в виде удобного инструмента и наконец-то объявить его решением. Я выбрал решение с помощью случайных перестановок и марковских моделей, параметризованных ключом. Оно оформлено в виде программы clickhouse obfuscator, которая очень проста в использовании: на вход подаётся дамп таблицы в любом поддерживаемом формате (например, CSV, JSONEachRow), в параметрах командной строки указывается структура таблицы (имена и типы столбцов) и секретный ключ (произвольная строка, её можно забыть сразу же после использования). На выходе получаем такое же количество строк обфусцированных данных.
Программа устанавливается вместе с clickhouse-client, не имеет зависимостей и работает почти на любом Linux. Применять её можно к дампам любых баз данных, не только ClickHouse. Например, вы можете использовать её для генерации тестовых данных MySQL или PostgreSQL баз, а также для создания разработческих баз аналогичных продакшену.
clickhouse obfuscator \
--seed "$(head -c16 /dev/urandom | base64)" \
--input-format TSV --output-format TSV \
--structure 'CounterID UInt32, URLDomain String, \
URL String, SearchPhrase String, Title String' \
< table.tsv > result.tsv
clickhouse obfuscator --help
Не всё так однозначно, ведь преобразование данных этой программой почти полностью обратимо. Можно ли осуществить обратное преобразование, не зная ключ? Если бы преобразование осуществлялось криптостойким алгоритмом, то сложность такой операции была бы такой же, как сложность полного перебора. И хотя для преобразования используются некоторые криптографические примитивы, они используются неправильным способом, и данные подвержены некоторым методам анализа. Чтобы избежать проблем, в документации к программе (доступной по
--help) приведены эти особенности.Мы преобразовали нужный нам датасет для функциональных тестов, и директор по данным Яндекса одобрил его публикацию.
clickhouse-datasets.s3.yandex.net/hits/tsv/hits_v1.tsv.xz
clickhouse-datasets.s3.yandex.net/visits/tsv/visits_v1.tsv.xz
Разработчики за пределами Яндекса используют эти данные для настоящих тестов производительности при оптимизации алгоритмов внутри ClickHouse. Сторонние пользователи могут предоставить нам свои данные в обфусцированном виде, чтобы мы могли сделать для них ClickHouse ещё быстрее.
