

 В нашей прошлой статье — «11 «рецептов приготовления» MySQL в Битрикс24» — мы, в основном, рассматривали архитектурные решения: стоит ли использовать облачные сервисы (типа Amazon RDS), какой форк MySQL выбрать и т.п.
В нашей прошлой статье — «11 «рецептов приготовления» MySQL в Битрикс24» — мы, в основном, рассматривали архитектурные решения: стоит ли использовать облачные сервисы (типа Amazon RDS), какой форк MySQL выбрать и т.п.Судя по отзывам, тема грамотной эксплуатации MySQL в больших «хайлоад» проектах — очень большая и важная. Поэтому мы решили рассказать еще о некоторых нюансах настройки и администрирования БД, с которыми сталкивались при разработке «Битрикс24» и которые используем ежедневно.
Еще раз напомню, что эта статья (как и предыдущая) не является универсальным «рецептом» идеальной настройки MySQL на все случаи жизни. :) Такого не бывает. :) Но искренне верю, что она будет полезной для вас для решения отдельных конкретных задач.
А в конце статьи — сюрприз для самых терпеливых читателей. :)
1. Настройка QUERY CACHE
Написано огромное количество статей, описывающих, как именно работает Query Cache в MySQL, и как его настраивать и использовать.
И все равно, несмотря на это, самое частое заблуждение системных администраторов, настраивающих базу данных — "Чем больше дадим памяти под кэш, тем лучше".
Это не так.
MySQL плохо оперирует Query Cache'м большого размера. На практике сталкивались с тем, что при query_cache_size более 512M все чаще появляются процессы, кратковременно подвисающие в состоянии «waiting for query cache lock» (видно в SHOW PROCESSLIST).
Кроме того, если все ваши запросы попадают в кэш, неразумно увеличивать его. RAM в системе драгоценна!
Поэтому всегда важно понимать, что происходит в вашем проекте, и насколько эффективно используется Query Cache с текущими настройками.
Ключевая информация для вас — здесь:
mysql> SHOW STATUS LIKE 'Qcache%';
+-------------------------+----------+
| Variable_name | Value |
+-------------------------+----------+
| Qcache_free_blocks | 10541 |
| Qcache_free_memory | 36381984 |
| Qcache_hits | 18888719 |
| Qcache_inserts | 5677585 |
| Qcache_lowmem_prunes | 1725258 |
| Qcache_not_cached | 6096307 |
| Qcache_queries_in_cache | 36919 |
| Qcache_total_blocks | 97285 |
+-------------------------+----------+
8 rows in set (0.00 sec)Самое важное — соотношения Qcache_hits и Qcache_inserts, Qcache_inserts и Qcache_not_cached, а также Qcache_lowmem_prunes — количество вытесненных из кэша запросов — и Qcache_free_memory.
Лучше всего не просматривать эту статистику лишь эпизодически, а иметь под рукой аналитику. Ее можно собирать с помощью тех или иных средств мониторинга. Например, Munin:
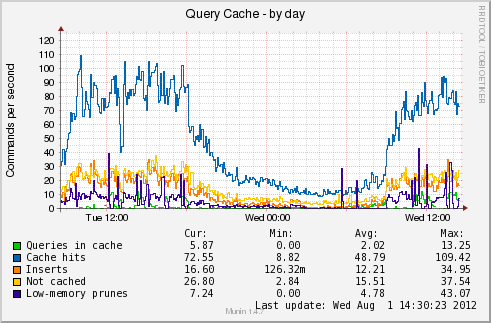
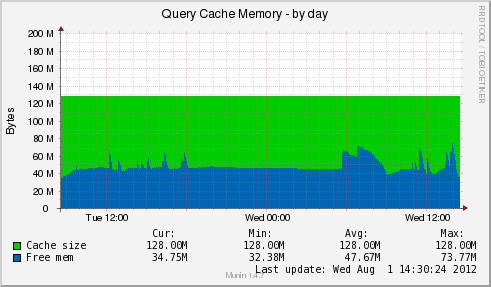
Просматривая графики в динамике — раз в день, например, мы в итоге пришли к тому, что для нас вполне хватает таких настроек для одного сервера:
query_cache_size = 128M
query_cache_limit = 2MКонечно, возможно, для вашего проекта картина будет иной.
2. innodb_buffer_pool_size
Размер Buffer Pool'а — одна из важнейших настроек InnoDB. Это размер буфера памяти, который используется MySQL в процессе работы для кэша данных и индексов таблиц (сразу напомним, что для того, чтобы избежать двойного кэширования — самим MySQL и операционной системой, стоит указать в настройках innodb_flush_method = O_DIRECT).
Со стороны разработчиков MySQL одно из величайших преступлений — поставить значение по умолчанию 8M. :)
На самом деле, в идеале значение innodb_buffer_pool_size должно быть таким, чтобы в память помещалась вся ваша база. При этом важно помнить о сбалансированности системы по памяти (об этом мы говорили в прошлой статье) — если «задрать» значение innodb_buffer_pool_size так, что вся система уйдет в swap, ничего хорошего не получится.
Хорошим индикатором правильной настройки служит Buffer pool hit rate:
mysql> SHOW ENGINE InnoDB STATUS\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
...
Buffer pool hit rate 994 / 1000, young-making rate 6 / 1000 not 0 / 1000
...Если значение близко к «1000 / 1000» — все хорошо. Иначе — надо увеличивать innodb_buffer_pool_size. Если при этом не хватает памяти — добавлять память.
3. innodb_buffer_pool_instances
По умолчанию InnoDB использует для Buffer Pool один инстанс.
При этом есть возможность выделить несколько блоков — и работает с ними MySQL в InnoDB в ряде случаев гораздо эффективнее.
Buffer Pool стоит разбивать на несколько инстансов в том случае, если он у вас превышает 2 Гб. Размер каждого инстанса стоит делать 1 Гб и более.
И вот здесь важный вопрос, с которым многие путаются: innodb_buffer_pool_size — это общий размер пула или размер одного инстанса?
Ответ есть прямо в документации — это общий размер. Поэтому, например, вот такая конфигурация:
innodb_buffer_pool_size = 4096M
innodb_buffer_pool_instances = 4… говорит о том, что каждый инстанс будет занимать 1 Гб.
Будьте внимательны, чтобы не было казусов (один товарищ, подписывающийся MySQL DBA, описывал свой опыт эксплуатации MySQL с настройками innodb_buffer_pool_size = 1024M, innodb_buffer_pool_instances = 64 — планируя выделить 64 Гб — и возмущался, что как-то плоховато с производительностью… :))
4. innodb_io_capacity
Интересный параметр, который, вроде бы (если верить официальной документации :)), и не очень сильно влияет на производительность, тем не менее на практике дает некоторый выигрыш, если его правильно настроить.
innodb_io_capacity задает предел операций ввода-вывода (в IOPS'ах) для тех операций InnoDB, которые выполняются в бэкграунде (например, сброс страниц из Buffer Pool'а на диск).
Значение по умолчанию — 200.
Слишком маленькое значение приведет к тому, что эти операции будут «отставать». Слишком большое приведет к тому, что данные из Buffer Pool'а будут сбрасываться слишком быстро.
В идеале стоит поставить значение, соответствующее реальной производительности вашей дисковой системы (опять же — в IOPS'ах).
5. innodb_file_per_table
По умолчанию MySQL в InnoDB хранит данные и индексы всех таблиц в одном тейблспейсе — файле ibdata1.
Если же в настройках используется опция innodb_file_per_table, то в этом случае для каждой таблицы создается отдельный файл table_name.ibd, в котором хранятся данные и индексы.
Есть ли смысл в этой опции?
На мой личный взгляд: если использовать стандартный MySQL, то использовать ее не нужно. Хранение таблиц в отдельных файлах может снизить производительность, так как в системе кардинально возрастет количество «дорогих» ресурсоемких операций открытия файла.
Мы сами используем Percona Server. И используем innodb_file_per_table.
- Если в обычном MySQL по каким-то причинам побьется одна или несколько таблиц — «встанет» вся база. В Перконе можно использовать опцию innodb_corrupt_table_action = assert, и тогда при использовании innodb_file_per_table «битая» таблица будет помечена, но вся база в целом продолжит работать.
- Уже сейчас есть возможность «ускорить» некоторые операции, которые явно проигрывают в производительности при использовании innodb_file_per_table. Например, удаление таблиц. Для таких целей в Перконе есть опция innodb_lazy_drop_table = 1, которая позволяет проводить такие операции в фоне и не снижает общей производительности системы.
- С включенной опцией innodb_file_per_table с помощью XtraBackup можно делать быстрый бинарный импорт/экспорт таблиц.
6. max_connect_errors
Еще один преступный :) заговор разработчиков MySQL. Значение max_connect_errors по умолчанию равно 10.
Это значит, что в любом более-менее активном проекте в случае какого-либо неожиданного сбоя — даже кратковременного (например, прописали неверный пароль в скриптах; или случились какие-то сетевые проблемы) — после указанного числа неуспешных попыток установить соединение хост, устанавливающий соединение, будет заблокирован. До тех пор, пока не будет рестартован сервер MySQL или не будет выполнена команда FLUSH HOSTS.
Это значит, что до ручного вмешательства (только если вы заранее не повесили на cron скрипт, который раз в несколько минут выполняет FLUSH HOSTS :)) ваш проект не будет работать. Неприятно, если такое случится ночью, а у вас нет круглосуточного мониторинга.
Лучше обезопасить себя заранее и поставить значение max_connect_errors большим. Например:
max-connect-errors = 100007. Временные таблицы
Если количество RAM в системе позволяет — с временными таблицами лучше всегда работать в памяти.
Организовать это достаточно просто. В настройках MySQL:
tmpdir = /dev/shmВ настройках файловых систем и разделов (если речь идет про Linux — в файле /etc/fstab):
# <file system> <mount point> <type> <options> <dump> <pass>
tmpfs /dev/shm tmpfs defaults 0 08. Размер временных таблиц
Есть два похожих параметра, отвечающих за размер таблиц в памяти:
max_heap_table_size = 64M
tmp_table_size = 64Mmax_heap_table_size — максимальный размер таблиц типа MEMORY, которые может создавать пользователь.
tmp_table_size — максимальный размер временной таблицы, которая будет создана в памяти (больше — на диске).
Чем меньше дисковой активности, тем лучше. Поэтому, если позволяет количество RAM в системе (помним о сбалансированности по памяти), лучше со всеми временными таблицами работать в памяти.
9. table_cache и table_definition_cache
table_cache = 4096
table_definition_cache = 4096Эти две опции отвечают за то, какое максимальное количество таблиц будет храниться в кэше открытых таблиц.
Значение table_cache напрямую зависит от количества таблиц в вашей системе, от количества открываемых таблиц в запросе (связанных через JOIN'ы, например) и от количества открытых коннектов к базе.
table_definition_cache определяет размер кэша для структур таблиц (.frm) файлов. Чем больше их в системе, тем больше значение table_definition_cache нужно установить.
10. Борьба за долгие запросы
В прошлой статье мы уже упоминали о том, что в Percona Server есть хороший инструмент определения общей производительности системы (SELECT * FROM INFORMATION_SCHEMA.QUERY_RESPONSE_TIME).
Кроме того, в любом MySQL есть возможность логировать все «медленные» запросы и отдельно разбирать их.
При использовании Percona Server лог медленных запросов становится гораздо более информативным.
log_output = FILE
slow_query_log = 1
slow_query_log_file = mysql_slow.log
long_query_time = 1
#percona
log_slow_verbosity = microtime,query_plan,innodbВсе запросы, выполняющиеся дольше 1 секунды, мы записываем в файл mysql_slow.log. В отличие от стандартного лога, выглядит он примерно так:
# Time: 120712 9:43:47
# User@Host: user[user] @ [10.206.66.207]
# Thread_id: 3513565 Schema: user Last_errno: 0 Killed: 0
# Query_time: 1.279800 Lock_time: 0.000053 Rows_sent: 0 Rows_examined: 1 Rows_affected: 0 Rows_read: 0
# Bytes_sent: 52 Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# InnoDB_trx_id: 33E7689B
# QC_Hit: No Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No
# Filesort: No Filesort_on_disk: No Merge_passes: 0
# InnoDB_IO_r_ops: 0 InnoDB_IO_r_bytes: 0 InnoDB_IO_r_wait: 0.000000
# InnoDB_rec_lock_wait: 0.000000 InnoDB_queue_wait: 0.000000
# InnoDB_pages_distinct: 4
UPDATE b_user_option SET 'COMMON' = 'N', 'VALUE' = 'a:19', 'NAME' = 'openTab', 'CATEGORY' = 'IM' WHERE ID=1719;Мы видим не только время выполнения запроса, количество «просмотренных» строк и т.п., но и гораздо более детальную информацию — Full Scan'ы, использование временных таблиц, состояние InnoDB.
Все это очень помогает в аналитике медленных запросов и их отладке.
11. Подробная статистика без Percona
Даже если вы используете стандартный MySQL, то и в нем есть хорошие инструменты отладки запросов (конечно, если вы их уже «поймали» и идентифицировали :) — например, с помощью того же лога медленных запросов).
Есть такая штука, как Profile'ы. Вы их используете? Нет? Зря!
mysql> SHOW PROFILES;
Empty set (0.02 sec)
mysql> SHOW PROFILE;
Empty set (0.00 sec)Включаем профайлинг и смотрим любой запрос:
mysql> SET PROFILING=1;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT COUNT(*) FROM mysql.user;
+----------+
| COUNT(*) |
+----------+
| 3024 |
+----------+
1 row in set (0.09 sec)
mysql> SHOW PROFILES;
+----------+------------+---------------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------------+
| 1 | 0.09104400 | SELECT COUNT(*) FROM mysql.user |
+----------+------------+---------------------------------+
1 row in set (0.00 sec)
mysql> SHOW PROFILE;
+--------------------------------+----------+
| Status | Duration |
+--------------------------------+----------+
| starting | 0.000018 |
| Waiting for query cache lock | 0.000004 |
| Waiting on query cache mutex | 0.000004 |
| checking query cache for query | 0.000041 |
| checking permissions | 0.000007 |
| Opening tables | 0.090854 |
| System lock | 0.000013 |
| init | 0.000012 |
| optimizing | 0.000007 |
| executing | 0.000010 |
| end | 0.000005 |
| query end | 0.000004 |
| closing tables | 0.000031 |
| freeing items | 0.000029 |
| logging slow query | 0.000003 |
| cleaning up | 0.000004 |
+--------------------------------+----------+
16 rows in set (0.00 sec)Сразу видим, что является «узким» местом — сеть, работа с диском, использование кэша или что-либо еще.
12. Как использовать информацию из profile?
Если вы научились находить одиночные долгие запросы (это не так сложно — лог медленных запросов и SHOW PROCESSLIST в помощь), если вы правильно оцениваете состояние системы в целом (SELECT * FROM INFORMATION_SCHEMA.QUERY_RESPONSE_TIME, внешний мониторинг системы, например, nagios – real time, munin – аналитика), то крайне важно понимать, что в системе может влиять на производительность:
- все внутренние ресурсы системы — для базы не бывает «слишком много» ни CPU, ни RAM, ни дисковой системы;
- локировки (на уровне таблиц — чаще в MyISAM, на уровне строк — InnoDB);
- внутренние локировки (например, «waiting for query cache lock»).
Понимая это и анализируя данные из profile или, например, из расширенного лога медленных запросов, вы всегда сможете грамотно оценить дальнейшую стратегию работы с базой — в каких случаях потребуется апгрейд железа, в каких — изменение тех или иных настроек, и где — возможно, реорганизация структуры данных и запросов.
* * *
Удачной отладки и успешной эксплуатации баз данных любого объема и с любой нагрузкой! :)
* * *
Спасибо, что дочитали до этого места! :)

Надеюсь, наши советы по работе с MySQL окажутся полезными для вас!
И раз уж мы рассказываем о нашем опыте эксплуатации MySQL именно в проекте «Битрикс24», мы бы хотели сделать небольшой подарок для всех читателей нашего блога на Хабре.
Зарегистрируйтесь в «Битрикс24» по указанной ссылке и получите в два раза больше диска — 10 Гб — на бесплатном тарифе!
Если вдруг вы еще не знаете, что такое «Битрикс24» — подробное описание есть на нашем сайте. :)
